本文代码和配置文件实现了一个基于 Streamlit 和 FastAPI 的前后端分离的应用程序,用于管理和展示 VLLM(Very Large Language Model)实例的信息。以下是代码和配置文件的总结摘要:
概要
功能概述
前后端启动方式:
- 使用 Streamlit 启动前端界面,可通过默认端口或指定端口和 IP 启动。
- 使用 Uvicorn 启动 FastAPI 后端服务,用于提供模型数据的 API 接口。
前端功能(Streamlit):
- 支持可选的登录认证功能,通过 YAML 配置文件控制是否启用。
- 展示 VLLM 模型的概览信息,包括模型名称、路径、IP 地址、端口、任务 ID、启动时间等。
- 从后端 API 获取模型数据,并动态展示模型的详细信息。
- 提供刷新按钮,用于重新从后端获取数据并更新前端显示。
后端功能(FastAPI):
- 提供
/models和/models/{model_name}两个 API 接口。 /models接口返回所有 VLLM 模型的列表信息。/models/{model_name}接口根据模型名称返回特定模型的详细信息。- 使用
ps命令解析系统进程信息,提取 VLLM 模型的运行参数和启动时间。
- 提供
配置文件:
counter.yaml:用于配置后端 API 的端口号和是否启用前端登录认证。.streamlit/secrets.toml:存储前端登录认证的用户名和密码。
模型信息展示:
- 模型信息通过
st.expander展开式组件展示,包含模型的基本信息和参数。 - 计算模型的运行时间(
uptime),并以友好的格式显示。
- 模型信息通过
技术栈
- 前端:Streamlit,用于快速搭建交互式 Web 界面。
- 后端:FastAPI,用于构建高效的 API 服务。
- 数据解析:通过
ps命令获取系统进程信息,并解析出 VLLM 模型的运行参数。 - 配置管理:使用 YAML 和 TOML 文件分别管理后端配置和前端认证信息。
使用场景
该应用适用于管理和监控运行在服务器上的 VLLM 模型实例,通过前端界面直观地展示模型的运行状态和参数配置,方便用户进行管理和调试。
代码展示
应用前后端启动方式
#默认启动
streamlit run app.py
#Local URL: http://localhost:8501
#指定端口 ip
streamlit run app.py --server.address 0.0.0.0 --server.port 8501
# unicorn启动后端fastapi
uvicorn api:app --reload --port 8880
Streamlit 代码(前端页面)
import streamlit as st
import requests
from datetime import datetime
# 设置页面配置
st.set_page_config(
page_title="VLLM 概览",
page_icon="📊"
)
# 登录认证
try:
import yaml
with open('counter.yaml') as f:
config = yaml.safe_load(f)
need_auth = config.get('web.auth', False)
except Exception as e:
need_auth = False
if need_auth:
if 'authenticated' not in st.session_state:
st.session_state['authenticated'] = False
if not st.session_state['authenticated']:
st.header("请登录")
username = st.text_input("用户名")
password = st.text_input("密码", type="password")
if st.button("登录"):
if username == st.secrets["auth"]["vstu"] and password == st.secrets["auth"]["vstp"]:
st.session_state['authenticated'] = True
st.rerun()
else:
st.error("用户名或密码错误")
st.stop()
# 页面标题
st.header("📊 VLLM 模型概览")
# 模拟API获取数据函数
def fetch_vllm_models():
# 从配置文件读取端口号
try:
import yaml
with open('counter.yaml') as f:
config = yaml.safe_load(f)
port = config.get('vllm.api.port', 8880)
except Exception as e:
port = 8880
# 调用本地API获取数据
response = requests.get(f"http://localhost:{port}/models")
if response.status_code == 200:
return response.json()
return []
# 获取数据
models = fetch_vllm_models()
# 计算运行时间
def calculate_uptime(start_time_str):
start_time = datetime.fromisoformat(start_time_str)
uptime = datetime.now() - start_time
return str(uptime).split('.')[0]
# 展示模型信息
for model in models:
uptime = calculate_uptime(model['start_time'])
with st.expander(f"模型: {model['sname']} ({model['name']}) [⏱️ {uptime}]"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**路径**: {model['path']}")
st.write(f"**地址**: {model['ip']}")
st.write(f"**端口**: {model['port']}")
st.write(f"**任务ID**: {model['pid']}")
st.write(f"**启动时间**: {model['start_time']}")
with col2:
st.write("**参数**:")
for param, value in model['params'].items():
st.write(f"- {param}: {value}")
# 刷新按钮
if st.button("刷新数据"):
st.rerun()
API 代码
from fastapi import FastAPI
from datetime import datetime
from pydantic import BaseModel
import os
app = FastAPI()
class ModelInfo(BaseModel):
name: str
sname: str
path: str
ip: str
port: int
start_time: str
params: dict
# 模拟数据
models = [
{
"name": "model1",
"sname": "model1",
"path": "/path/to/model1",
"ip": "192.168.1.100",
"port": 8000,
"start_time": "2023-01-01T10:00:00",
"params": {"temperature": 0.7, "max_tokens": 100}
},
{
"name": "model2",
"sname": "model2",
"path": "/path/to/model2",
"ip": "192.168.1.101",
"port": 8001,
"start_time": "2023-01-02T11:00:00",
"params": {"temperature": 0.8, "max_tokens": 200}
}
]
def parse_ps_time(ps_time_str):
"""将ps命令返回的时间字符串转换为ISO格式"""
return datetime.strptime(ps_time_str, "%a %b %d %H:%M:%S %Y").isoformat()
def parse_vllm_ps_output():
"""从ps命令输出解析vllm模型信息"""
try:
# 使用os.popen直接执行ps命令
process = os.popen('ps aux | grep "vllm serve" | grep -v grep')
output = process.read()
process.close()
if not output:
print("No vllm processes found")
return []
models = []
for line in output.splitlines():
if "vllm serve" not in line:
continue
# 提取PID
pid = int(line.split()[1])
# 提取完整命令
cmd_start = line.find("vllm serve")
cmd = line[cmd_start:]
# 提取模型路径
model_path = cmd.split("vllm serve ")[1].split()[0]
# 提取参数
params = {}
ip = "localhost" # 默认IP地址
port = 8000 # 默认端口
sname = model_path.split('/')[-1]
parts = cmd.split()
for i, part in enumerate(parts):
if part == "--host":
ip = parts[i+1]
elif part == "--port":
port = int(parts[i+1])
elif part == "--task":
params["task"] = parts[i+1]
elif part == "--tensor-parallel-size":
params["tensor_parallel_size"] = int(parts[i+1])
elif part == "--pipeline-parallel-size":
params["pipeline_parallel_size"] = int(parts[i+1])
elif part == "--trust-remote-code":
params["trust_remote_code"] = True
elif part == "--api-key":
params["api_key"] = True
elif part == "--served-model-name":
sname = parts[i+1]
# 获取进程启动时间
time_process = os.popen(f'ps -p {pid} -o lstart=')
start_time_str = time_process.read().strip()
time_process.close()
models.append({
"name": model_path.split('/')[-1],
"sname": sname,
"path": model_path,
"pid": pid,
"ip": ip,
"port": port,
"start_time": parse_ps_time(start_time_str) if start_time_str else datetime.now().isoformat(),
"params": params
})
return models
except Exception as e:
print(f"Error parsing ps output: {e}")
return []
@app.get("/models")
async def get_models():
return parse_vllm_ps_output()
@app.get("/models/{model_name}")
async def get_model(model_name: str):
for model in models:
if model["name"] == model_name:
return model
return {"error": "Model not found"}
配置文件的内容示例
# counter.yaml
vllm.api.port: 8880
web.auth: false
密码文件的内容示例
# .streamlit\secrets.toml
[auth]
vstu = "admin"
vstp = "your_password"
效果展示
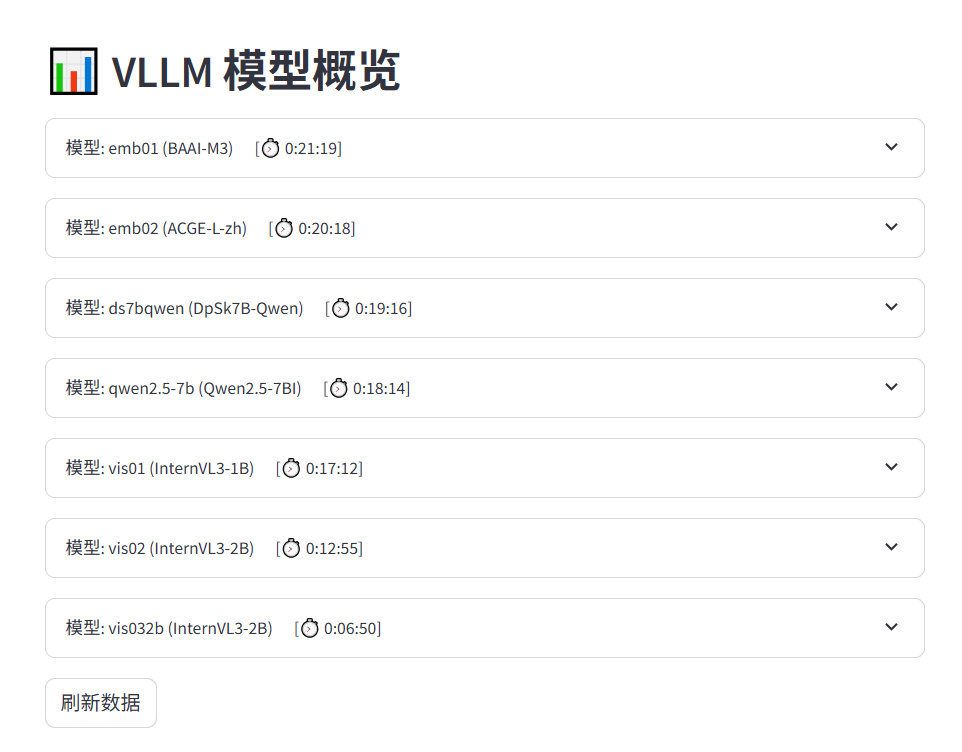
展示所有的运行中的模型信息,包括当前模型已运行的时间。
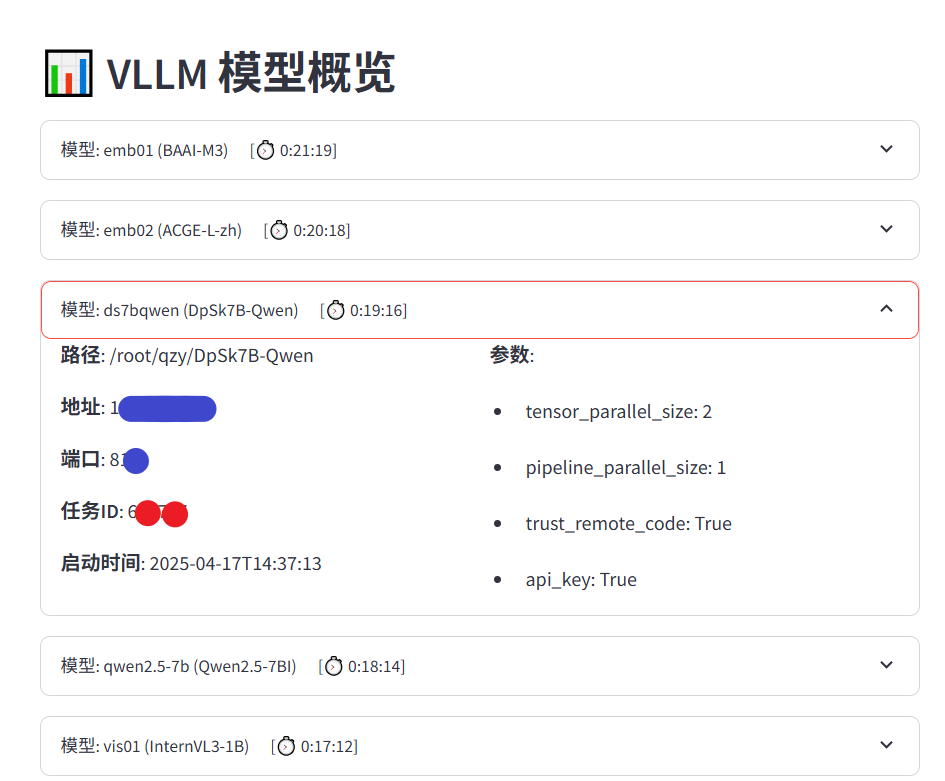
下拉菜单可以展示模型的详细信息,如参数、地址、端口等信息。
总结
这段代码实现了一个基于 Streamlit 和 FastAPI 的应用,用于管理和展示 VLLM 模型实例的信息。前端通过 Streamlit 提供交互式界面,支持登录认证和模型信息的动态展示;后端使用 FastAPI 提供 API 接口,从系统进程解析模型数据。配置文件用于设置端口和认证信息。整体功能包括模型概览、运行时间计算和数据刷新,适合用于监控和管理 VLLM 模型实例。