引言
在YOLO系列算法的发展历程中,YOLO v3无疑是一个里程碑式的版本。2018年,Joseph Redmon等人提出的YOLO v3在保持前代速度优势的同时,通过引入残差网络、多尺度预测等创新技术,显著提升了检测性能,特别是在小物体检测方面的表现。本文将全面解析YOLO v3的核心改进、网络架构和技术细节。
YOLO v3的主要改进
YOLO v3在前代基础上进行了全方位的升级,主要改进包括:
1. 新的主干网络:Darknet-53
YOLO v3采用了全新的Darknet-53作为特征提取网络:
- 包含53个卷积层(因此得名)
- 大量使用残差连接(Residual Connections)
- 相比Darknet-19更深但效率更高
- 比ResNet-101更快,比ResNet-152更准确
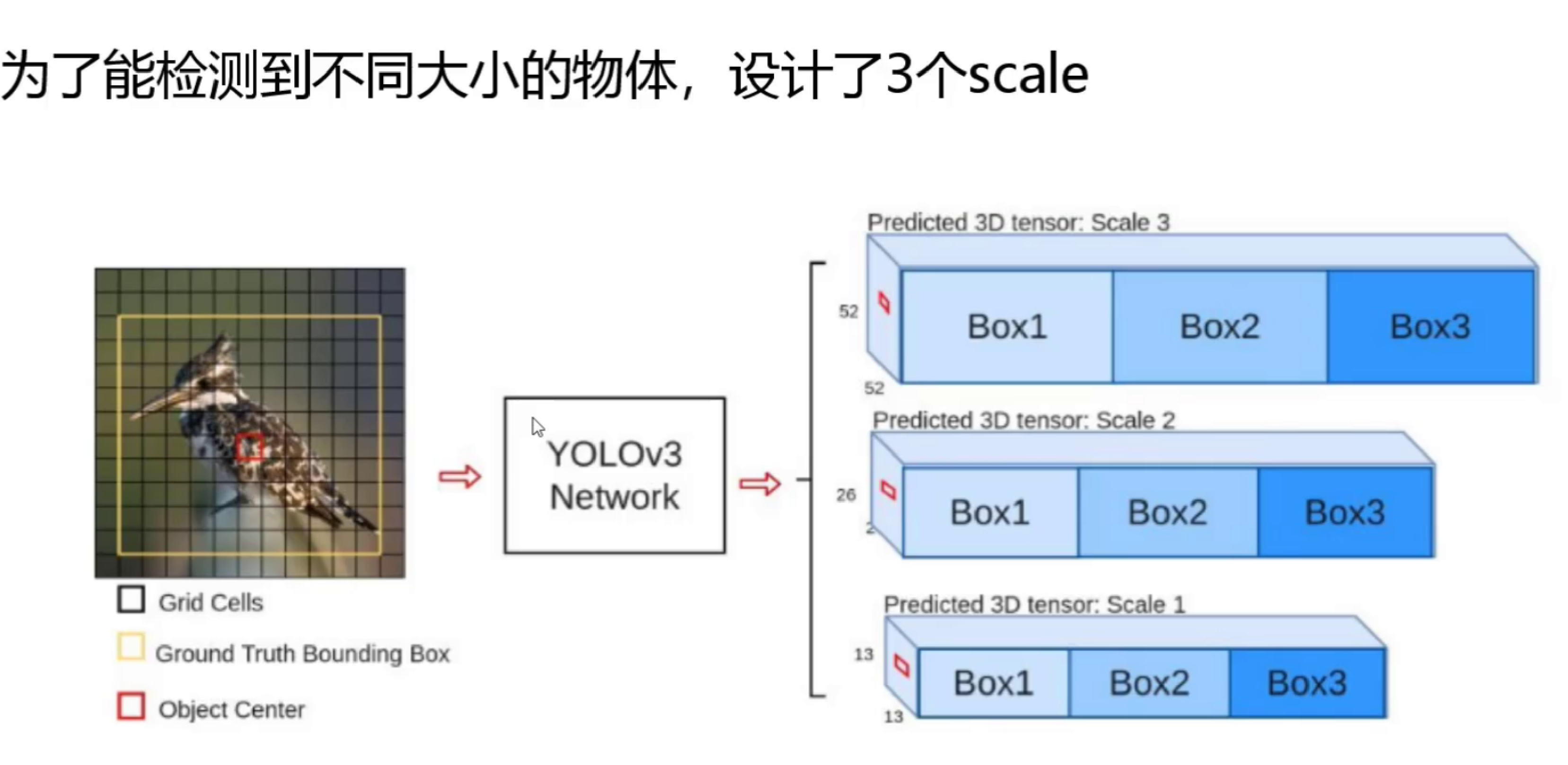
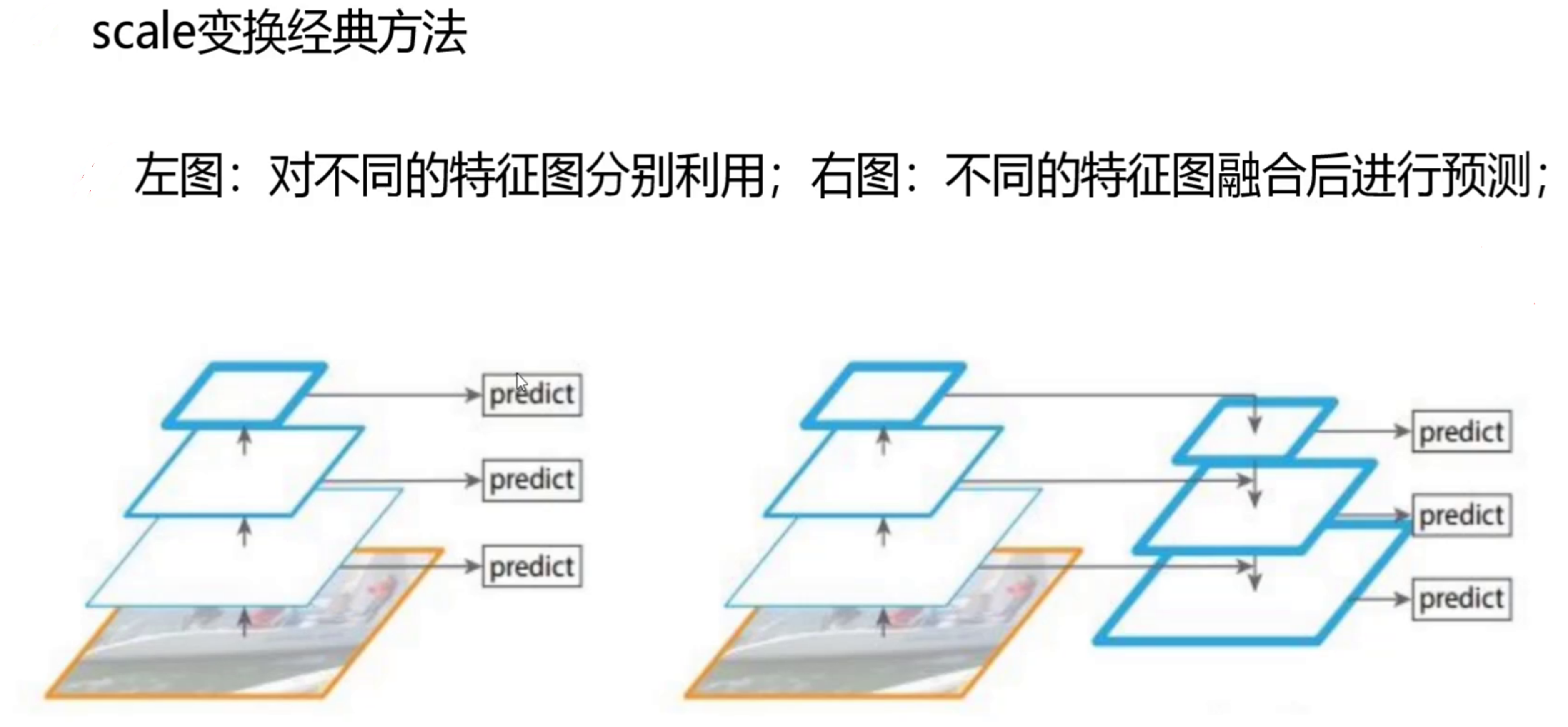
2. 多尺度预测(Multi-Scale Predictions)
YOLO v3引入了3种不同尺度的预测:
- 13×13网格:检测大物体
- 26×26网格:检测中等物体
- 52×52网格:检测小物体
这种金字塔式的预测方式显著提升了小物体的检测能力。

3. 改进的锚框机制
YOLO v3延续了v2的锚框思想但做了重要改进:
- 使用k-means聚类得到9种先验框尺寸(v2是5种)
- 为每种预测尺度分配3种不同尺寸的锚框:
- 大尺度(13×13):(116×90),(156×198),(373×326)
- 中尺度(26×26):(30×61),(62×45),(59×119)
- 小尺度(52×52):(10×13),(16×30),(33×23)
4. 独立的逻辑分类器
YOLO v3用多个独立的逻辑分类器替代了传统的softmax分类器:
- 每个类别使用二元交叉熵损失
- 支持多标签分类(一个物体可以属于多个类别)
- 更适合复杂场景(如"女人"同时也是"人")
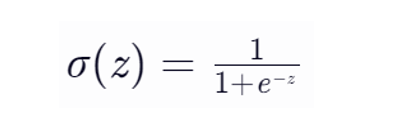
5. 特征金字塔网络(FPN)思想
虽然不完全相同,但YOLO v3吸收了FPN的思想:
- 自顶向下(top-down)的特征融合
- 将深层语义信息与浅层细节信息结合
- 改善了不同尺度物体的检测能力
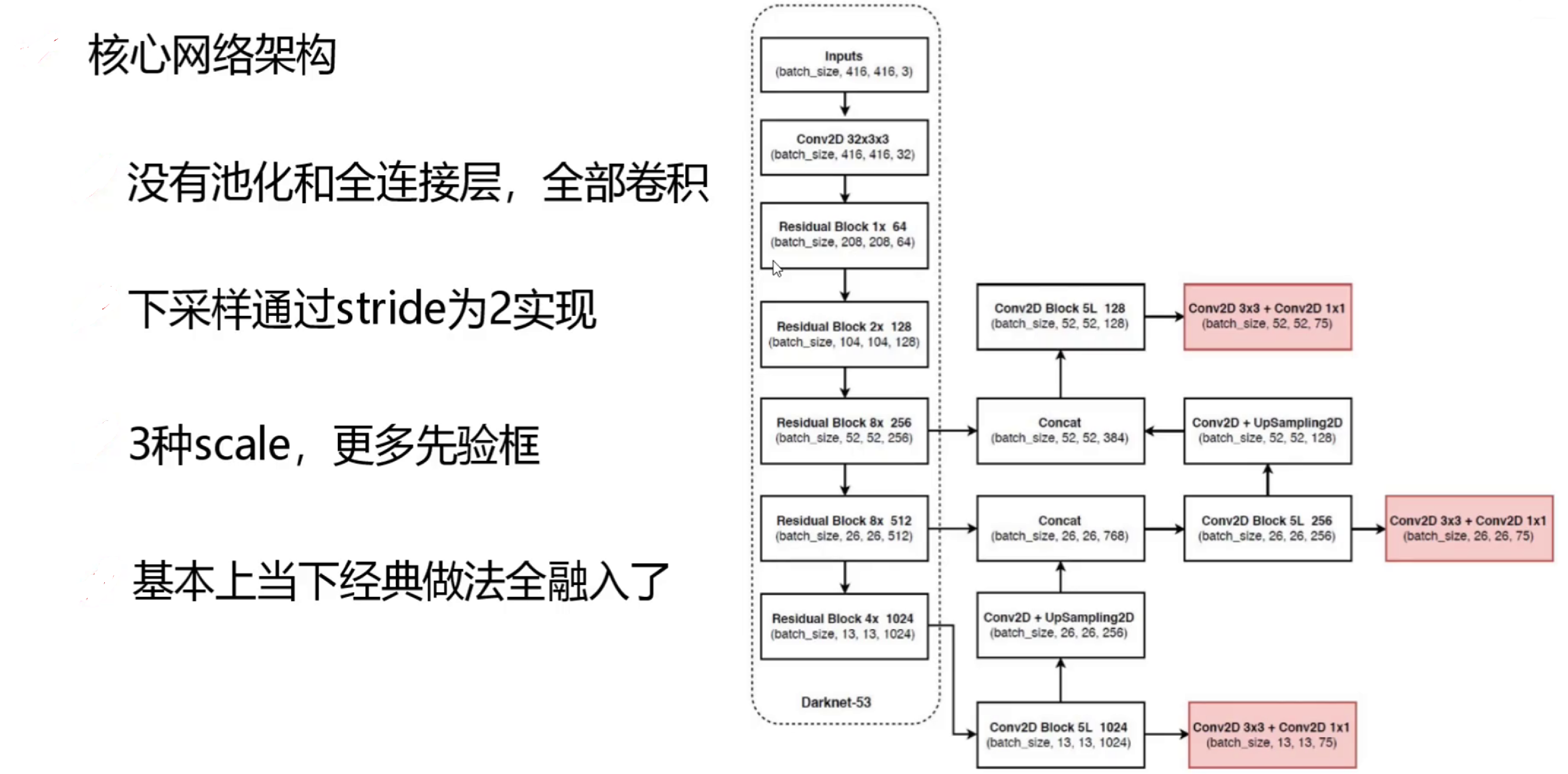
YOLO v3网络架构详解
YOLO v3的网络结构可以分为三部分:
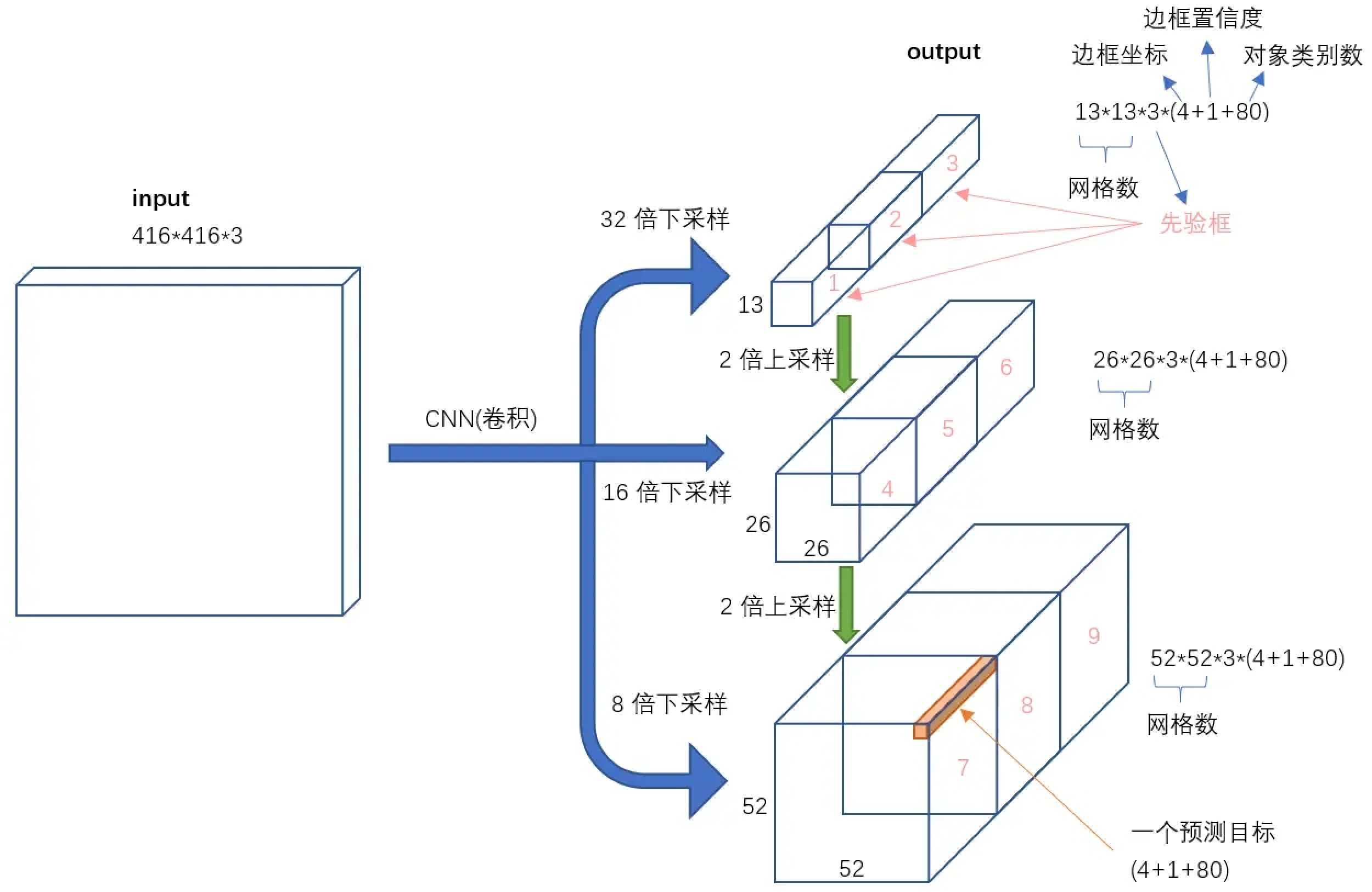
1. 主干网络(Backbone):Darknet-53
输入图像(416×416)
↓
一系列3×3和1×1卷积(带残差连接)
↓
在不同深度处输出三种尺度的特征图:
- 52×52×256(浅层,高分辨率)
- 26×26×512(中层)
- 13×13×1024(深层,低分辨率)
2. 检测头(Detection Head)
每种尺度的特征图都会经过:
1. 几个卷积层处理
2. 1×1卷积产生预测张量:
- 13×13×[3×(4+1+80)] (COCO数据集)
- 26×26×[3×(4+1+80)]
- 52×52×[3×(4+1+80)]
其中:
- 3:每个网格预测3个边界框
- 4:边界框坐标(x,y,w,h)
- 1:置信度分数
- 80:COCO的80个类别概率
3. 特征融合路径
通过上采样和连接操作实现多尺度特征融合:
深层特征(13×13) → 上采样 → 与中层特征(26×26)连接 → 处理
中层特征(26×26) → 上采样 → 与浅层特征(52×52)连接 → 处理
YOLO v3的创新技术
1. 残差块(Residual Block)
YOLO v3大量使用了残差连接:
# 典型残差块结构
def residual_block(input, filters):
shortcut = input
x = Conv2D(filters, (1,1))(input)
x = Conv2D(filters*2, (3,3))(x)
x = Add()([x, shortcut])
return x
这种结构缓解了深层网络的梯度消失问题,使网络可以训练得更深。
2. 边界框预测公式
YOLO v3改进了边界框预测方式:
bx = σ(tx) + cx
by = σ(ty) + cy
bw = pw * e^(tw)
bh = ph * e^(th)
其中:
- (cx,cy)是网格偏移
- (pw,ph)是锚框尺寸
- σ是sigmoid函数,确保预测在0-1范围内
3. 损失函数
YOLO v3的损失函数包含三部分:
- 边界框坐标损失:MSE损失,只计算正样本
- 置信度损失:二元交叉熵,区分有无物体
- 分类损失:独立的二元交叉熵,支持多标签
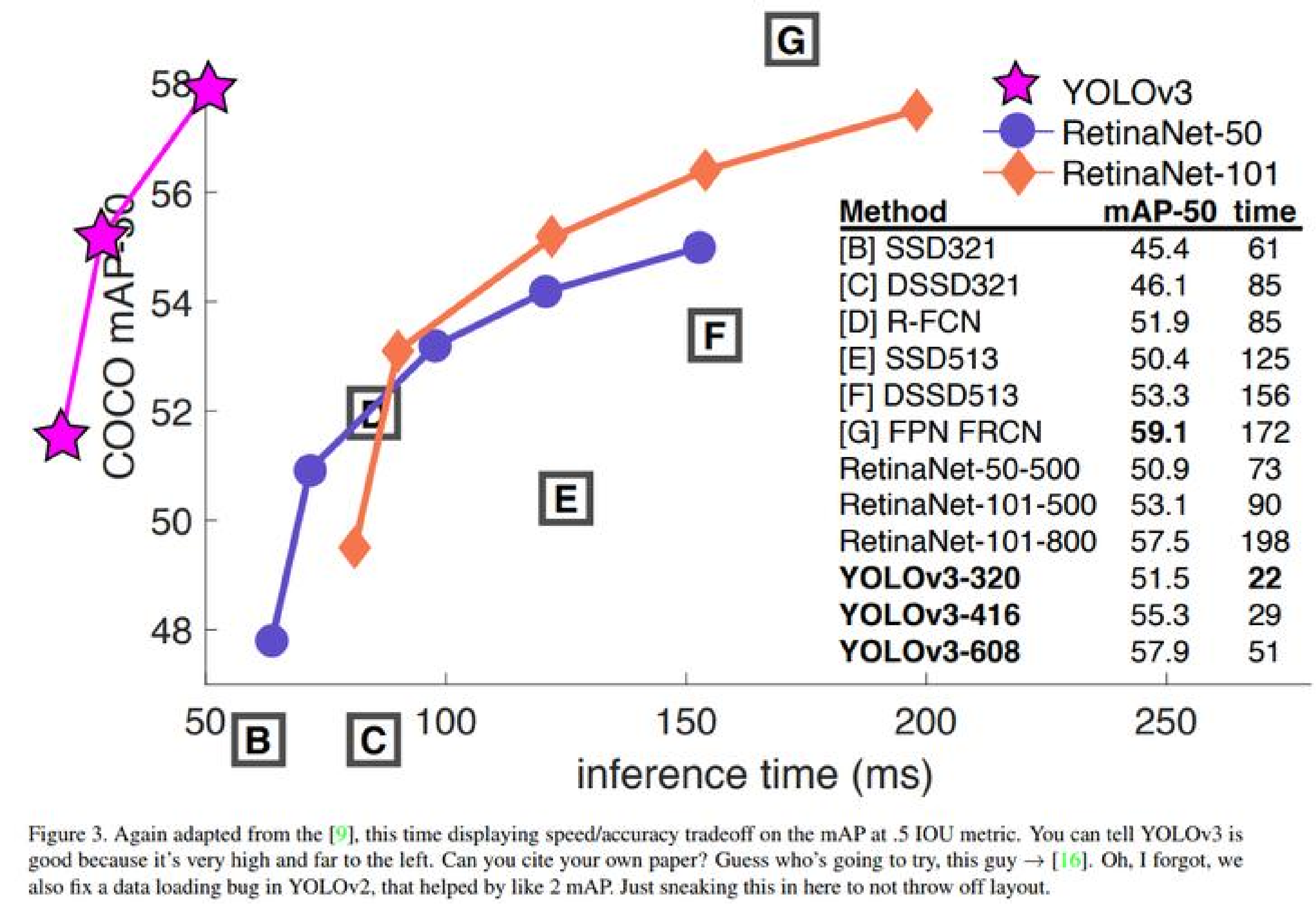
YOLO v3性能表现
在COCO数据集上的表现:
- mAP@0.5:57.9%
- mAP@[.5:.95]:33.0%
- 速度:在Titan X上处理608×608图像约51ms(20FPS)
与前期版本对比:
- 比YOLO v2更准确(特别是小物体)
- 比两阶段检测器(如Faster R-CNN)更快
- 在速度和精度之间取得了更好平衡
YOLO v3的优缺点
优点:
- 多尺度预测显著提升小物体检测能力
- 更深的网络结构提高了特征提取能力
- 独立的逻辑分类器支持多标签分类
- 保持了YOLO系列的高速特性
局限性:
- 对密集小物体检测仍有困难
- 定位精度仍略低于两阶段方法
- 模型尺寸相对较大
实践建议
- 锚框调整:针对特定数据集应重新聚类锚框尺寸
- 输入尺寸选择:
- 608×608:高精度场景
- 416×416:平衡精度和速度
- 320×320:高速场景
- 数据增强:适当使用马赛克增强等技巧提升小物体检测
结语
YOLO v3通过引入Darknet-53、多尺度预测等创新技术,将YOLO系列的性能提升到了新高度。它不仅保持了YOLO算法一贯的速度优势,还在检测精度特别是小物体检测方面取得了显著进步。虽然现在已经有了YOLO v4、v5等后续版本,但YOLO v3仍然是许多实际应用中的首选,因其在速度和精度之间取得了出色的平衡。