视频资料
任务
基于 examdata.csv 数据,建立逻辑回归模型,预测 Exam1 = 75, Exam2 = 60 时,该同学在 Exam3 是 passed or failed;建立二阶边界,提高模型准确度。
数据准备
examdata.csv 【百度网盘下载,提取码: 8497】
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('examdata.csv')
data.head()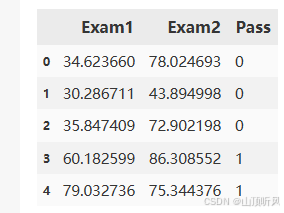
#visualize the data
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(data.loc[:,'Exam1'], data.loc[:,'Exam2'])# 横坐标 为 ‘Exam1’, 纵坐标为 ‘Exam2’
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
plt.show()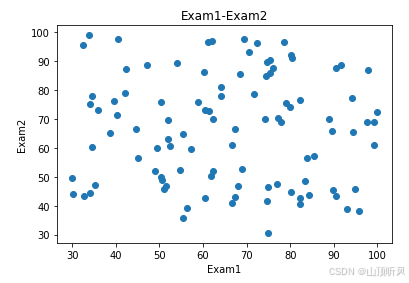
#add lable mask
mask = data.loc[:,'Pass'] ==1 #
# print(type(mask),mask)fig2 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask], data.loc[:,'Exam2'][mask])# 通过的数据
# print(type(passed)) #<class 'matplotlib.collections.PathCollection'>
failed = plt.scatter(data.loc[:,'Exam1'][~mask], data.loc[:,'Exam2'][~mask])# 没有通过的数据
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
# legend()图表添加图例的函数,通过标签(label)区分不同数据系列,提升图表可读性
plt.legend((passed,failed),('passed','failed'))
plt.show()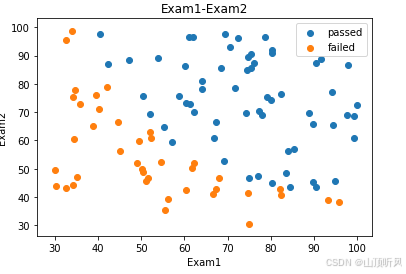
一阶逻辑回归
#数据赋值给 x 和 y 方便后面训练
X = data.drop((['Pass']),axis = 1)
X.head()
y = data.loc[:,'Pass']
X1 = data.loc[:,'Exam1']
X2 = data.loc[:,'Exam2']
X1.head()
print(X.shape,y.shape) #(100, 2) (100,)# establish the model and train it
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(X,y) # 模型训练# show the predicted result and its accuracy
y_predict = LR.predict(X)
print(y_predict)from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)# 两个参数,实际 y 和 预测的 y
print(accuracy) # 0.87# 利用模型进行预测
# exam1=70, exam2=65
y_test = LR.predict([[70,65]])
print('passed' if y_test == 1 else 'failed') # passed## 展示模型的 边界曲线
LR.coef_ # array([[0.03844482, 0.03101855]]),模型 的 theta1,theta2
#截距 theta0
LR.intercept_ # array([-3.89977794])theta0 = LR.intercept_
theta1 = LR.coef_[0][0]
theta2 = LR.coef_[0][1]
print(theta0, theta1,theta2)# [-3.89977794] 0.03844481555459551 0.03101854556230963 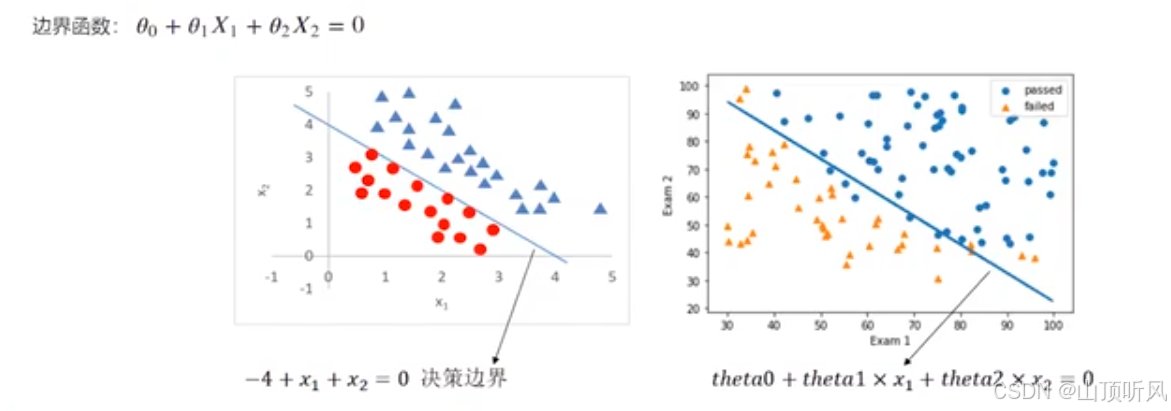

# 边界函数为 theta0 + theta1 * x1 + theta2 * x2 = 0
X2_new = (-theta1 * X1 - theta0)/theta2
# print(X2_new)# 画图,原数据点 + 边界曲线
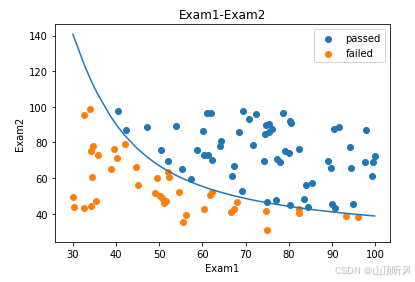
fig3 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask], data.loc[:,'Exam2'][mask])# 通过的数据
# print(type(passed)) #<class 'matplotlib.collections.PathCollection'>
failed = plt.scatter(data.loc[:,'Exam1'][~mask], data.loc[:,'Exam2'][~mask])# 没有通过的数据
plt.plot(X1, X2_new) # 边界曲线=================================
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
# legend()图表添加图例的函数,通过标签(label)区分不同数据系列,提升图表可读性
plt.legend((passed,failed),('passed','failed'))
plt.show()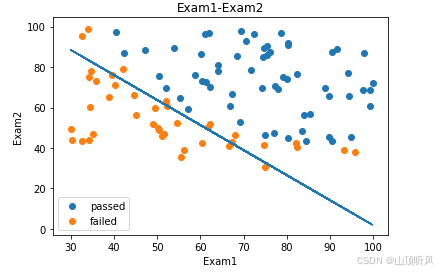
二阶逻辑回归
理论




代码实现
# 前面是 一阶,只有 X1 和 X2,下面做二阶
#create new data
X1_2 = X1*X1
X2_2 = X2*X2
X1_X2 = X1*X2
# print(X1,X1_2)#把 X1, X2, X1平方,X2平方,X1 * X2 放字典里
X_new = {'X1':X1, 'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1_X2':X1_X2}
X_new = pd.DataFrame(X_new)
# print(X_new)
X_new.head()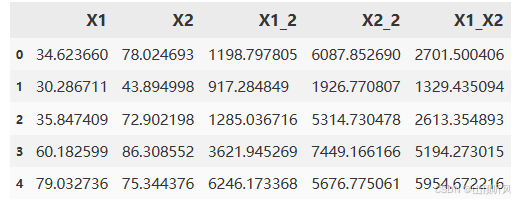
#establish a new model and train it
LR2 = LogisticRegression()
LR2.fit(X_new, y)#用新的模型进行预测
y2_predict = LR2.predict(X_new)
accuracy2 = accuracy_score(y, y2_predict)
print(accuracy2)# 1.0, 全部预测正确LR2.coef_ #系数:array([[-5.62331306e-01, -6.46537214e-01, 5.10961766e-04,
#1.33146067e-03, 1.91678695e-02]])theta0 = LR2.intercept_
theta1 = LR2.coef_[0][0]
theta2 = LR2.coef_[0][1]
theta3 = LR2.coef_[0][2]
theta4 = LR2.coef_[0][3]
theta5 = LR2.coef_[0][4]
print(theta5)X1_sorted = X1.sort_values() # 从小到大排序,不然后面边界直线时会织成乱麻a = theta4
b = theta5*X1_sorted + theta2
c = theta0 + theta1 * X1_sorted + theta3*X1_sorted*X1_sorted
X2_new_boundary = (-b + np.sqrt(b*b - 4*a*c))/(2*a)
X2_new_boundary.head()fig4 = plt.figure()
plt.plot(X1_sorted, X2_new_boundary)
plt.show()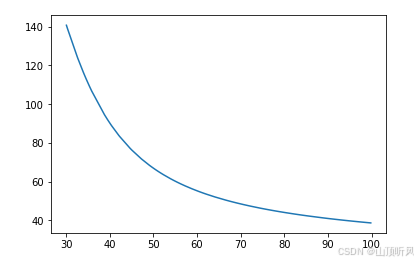
#接下来把原数据点和边界曲线画到同一张图上
fig5 = plt.figure()
passed = plt.scatter(data.loc[:,'Exam1'][mask], data.loc[:,'Exam2'][mask])# 通过的数据
# print(type(passed)) #<class 'matplotlib.collections.PathCollection'>
failed = plt.scatter(data.loc[:,'Exam1'][~mask], data.loc[:,'Exam2'][~mask])# 没有通过的数据
plt.plot(X1_sorted, X2_new_boundary) # 边界曲线=================================
plt.title('Exam1-Exam2')
plt.xlabel('Exam1')
plt.ylabel('Exam2')
# legend()图表添加图例的函数,通过标签(label)区分不同数据系列,提升图表可读性
plt.legend((passed,failed),('passed','failed'))
plt.show()