目录
针对Vanna的讲解和基础操作参考第一篇:用了都说好!Vanna,助力高速实现Text2SQL技术_vanna 实时反馈-CSDN博客
一、引言
在数据分析工作中,编写复杂 SQL 语句以及准确理解业务术语存在困难。本项目旨在开发一款基于 Vanna的智能问答与数据分析助手,简化 SQL 编写流程,提升数据分析效率和业务洞察力。通过自然语言处理技术,实现从问题到 SQL 的自动转换,并结合业务术语管理,为用户提供更好的数据分析体验。
在数据分析领域,高效准确地从数据库中提取信息是关键任务之一。传统方法要求用户具备专业的 SQL 知识,这限制了许多非技术背景用户的需求。同时,业务术语的理解差异也给数据分析带来了障碍。
二、项目背景
为解决这一难题,我们引入了 Vanna 框架。它结合了大型语言模型的强大自然语言处理能力和数据库交互功能。通过 Vanna 框架,用户只需用自然语言提问,系统就能自动生成 SQL 查询并执行,降低了数据查询的门槛。此外,Vanna 还支持业务术语定义管理,确保了数据分析过程中的语义一致性。这使得即使没有深厚技术背景的用户,也能轻松进行复杂的数据查询和分析,极大地提升了数据分析的效率和可访问性。
三、系统架构与设计
该智能问答与数据分析助手基于 Vanna 框架构建,整体架构分为三层。
应用层:为用户提供了一个直观的 Gradio 前端界面,用户可通过输入自然语言问题发起查询请求。
逻辑层:核心是 Vanna 框架集成的 QwenLLM 模型。用户问题经模型处理后转换为 SQL 查询,同时管理业务术语定义,确保语义准确性。
数据层:连接 MySQL 数据库,负责执行生成的 SQL 查询并返回结果,为上层提供数据支持。
系统设计简洁高效,各层协同工作,实现从自然语言问题到数据库查询的流畅转换,提升了数据分析的效率和易用性。
四、核心功能模块详解
SQL 生成与执行模块:用户在前端输入自然语言问题后,系统通过 QwenLLM 模型将问题转化为 SQL 查询语句。生成的 SQL 可在前端展示,用户确认后系统将其发送至后端,后端连接数据库执行查询,并将结果返回前端展示。若执行失败,会显示错误信息。
问答与回答生成模块:系统根据执行 SQL 查询得到的结果,利用 QwenLLM 模型生成自然语言回答。模型会依据提供的查询结果构建提示词,生成回答时还会融入物品名称或单词的中文翻译,使回答更贴合用户需求和业务背景。
业务术语定义与管理模块:支持加载、更新和删除业务术语定义。初始定义从文件加载,系统提供界面供用户更新或删除术语定义。更新时,先清空原有定义再重新加载;删除时,从术语定义数据结构中移除指定术语。
文件监控与热更新模块:采用 watchdog 库监控业务术语定义文件。文件修改时,触发 FileChangeHandler 类的 on_modified 方法,重新加载文件内容并更新术语定义,确保系统使用最新的业务术语定义,无需重启即可反映修改。
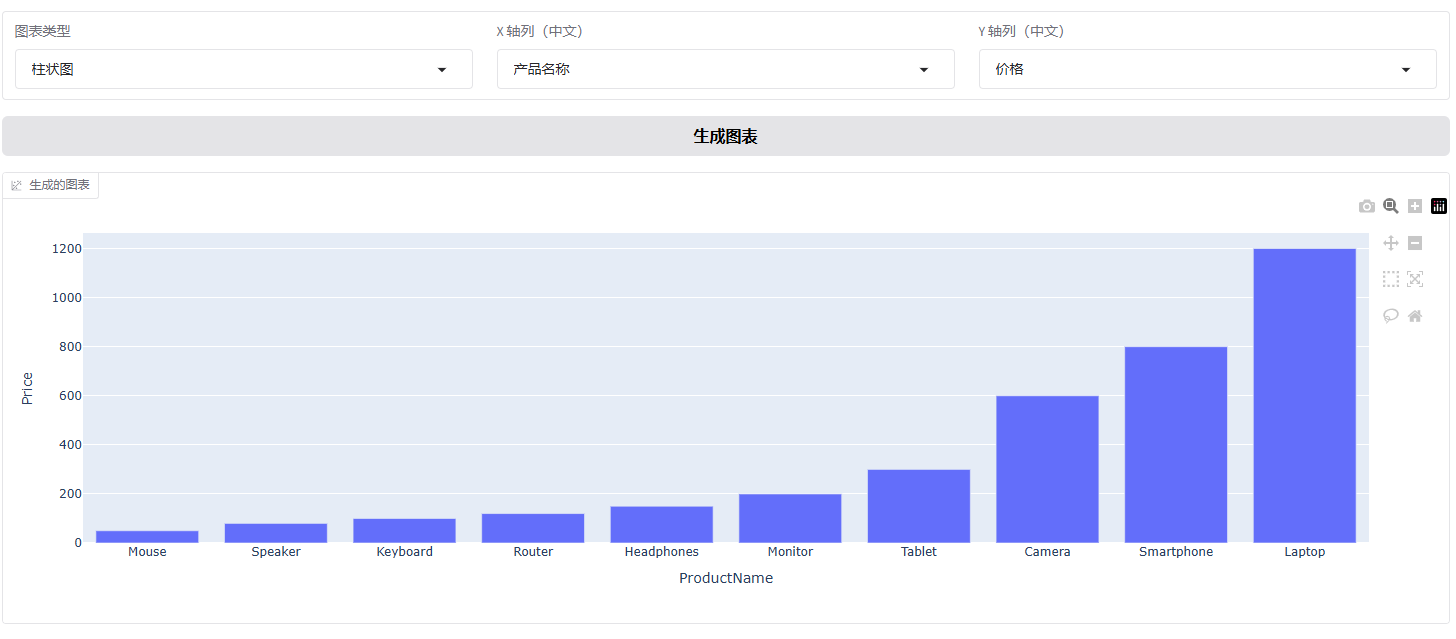
图表生成模块:根据查询结果生成图表。用户选择图表类型及 X、Y 轴列后,系统使用 Plotly Express 库生成相应图表,支持柱状图、折线图等类型,以直观展示数据趋势和分布,便于用户进行数据分析和可视化。
五、代码逻辑解析
构建项目和数据库
项目文件
vanna/
├── .venv/
│ ├── etc/
│ ├── include/
│ ├── lib/
│ ├── Scripts/
│ └── share/
├── .gitignore
├── pyvenv.cfg
├── 663c7487-e2c6-4de9-995a-a465107c4a1e/
├── c771f56a-5baf-4bf1-b9c8-b1e274b5babd/
├── fc9f1301-865c-452c-b7f7-7dd3451e6cbc/
├── sahema_for_quantity.sql # DDL存储位置
├── documents_for_quantity # documentations配置文件
└── vanna_demo.py # 运行文件
另外需要单独配置MySql数据库,可以参考我的DDL:
CREATE TABLE `products` ( `ProductID` int NOT NULL, `ProductName` varchar(100) NOT NULL, `Description` varchar(100) NOT NULL, `Price` decimal(10,2) NOT NULL, `StockQuantity` int NOT NULL, `Productscol` varchar(45) NOT NULL COMMENT '商品表格', PRIMARY KEY (`ProductID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
然后填入数据:
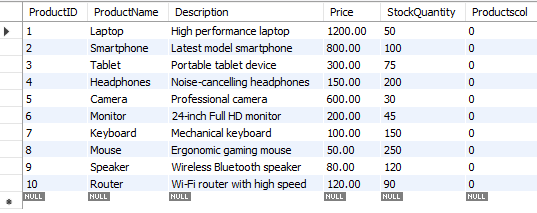
这里就构建好了我们所需要的业务数据库了,解释一下,数据库里最重要的就是物品名称,价格和数量。
配置documents_for_quantity文件
这里是对数据库进行解释说明,方便大模型理解
{
"products": "产品表",
"ProductID":"产品ID",
"ProductName":"产品名称",
"Description":"产品描述",
"Price":"产品价格",
"StockQuantity":"库存数量",
"Productscol":"产品附加"
}核心应用:
接下来我们在vanna_demo.py文件里,仅需10步就可以完成demo搭建:
1. 导入必要的库
import tempfile
import threading
import gradio as gr
from vanna.base import VannaBase
from vanna.chromadb import ChromaDB_VectorStore
from dashscope import Generation
import random
import json
import time
import pandas as pd
import plotly.express as px
import re
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler这些库用于实现文件操作(tempfile)、多线程(threading)、Gradio 界面(gr)、问答系统(VannaBase、ChromaDB_VectorStore)、模型调用(dashscope)、随机数生成(random)、JSON 操作(json)、时间处理(time)、数据处理(pandas)、图表生成(plotly.express)、正则表达式(re)、文件监听(watchdog)。
2. 定义全局变量
DEBUG_INFO = None用于存储调试信息(模型输入和输出)。
3. QwenLLM 类:封装模型调用
class QwenLLM(VannaBase):
def __init__(self, config=None):
self.model = config['model']
self.api_key = config['api_key']
def system_message(self, message: str):
return {'role': 'system', 'content': message}
def user_message(self, message: str):
return {'role': 'user', 'content': message}
def assistant_message(self, message: str):
return {'role': 'assistant', 'content': message}
def submit_prompt(self, prompt, **kwargs):
resp = Generation.call(
model=self.model,
messages=prompt,
seed=random.randint(1, 10000),
result_format='message',
api_key=self.api_key)
answer = resp.output.choices[0].message.content
global DEBUG_INFO
DEBUG_INFO = (prompt, answer)
return answer继承自
VannaBase,封装了 Qwen 模型的调用逻辑。system_message、user_message、assistant_message方法用于构造对话消息。submit_prompt方法调用 Dashscope 的 Generation API,提交提示并返回模型的回答。
4. MyVanna 类:结合问答与向量存储
class MyVanna(ChromaDB_VectorStore, QwenLLM):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
QwenLLM.__init__(self, config=config)
def generate_sql(self, question, allow_llm_to_see_data=False):
self.submit_prompt([self.system_message("清空之前的对话历史")])
return super().generate_sql(question, allow_llm_to_see_data=allow_llm_to_see_data)
def generate_answer(self, question, sql_result):
prompt = [
self.system_message(f"根据以下查询结果生成回答:{sql_result}"),
self.user_message(question)
]
return self.submit_prompt(prompt)继承自
ChromaDB_VectorStore和QwenLLM,结合了向量存储和问答功能。generate_sql方法生成 SQL 查询(通过调用父类方法)。generate_answer方法根据 SQL 查询结果生成自然语言回答。
5. 初始化问答对象
vn = MyVanna({'api_key': 'your API', 'model': 'model_name'})
vn.connect_to_mysql(host='your_sql_ip', dbname='name', user='username', password='your_sql_pw', port=your_sql_port)初始化
MyVanna对象,并连接到 MySQL 数据库。
6. 加载数据和术语
def load_ddl(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
ddl_content = load_ddl('sahema_for_quantity.sql')
vn.train(ddl=ddl_content)
def load_documentations(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return json.load(f)
documentations = load_documentations('documents_for_quantity')
for term, definition in documentations.items():
vn.train(documentation=f'"{term}"是指 {definition}')load_ddl加载数据库模式文件。load_documentations加载业务术语定义,并将其存储到向量数据库中。
7. 文件监听:动态更新术语
class FileChangeHandler(FileSystemEventHandler):
def on_modified(self, event):
if event.src_path == 'documents_for_quantity':
print("documentations.json文件已修改,正在重新加载...")
global documentations
documentations = load_documentations('documents_for_quantity')
vn.train(documentation="清空之前的业务术语定义")
for term, definition in documentations.items():
vn.train(documentation=f'"{term}"是指 {definition}')
print("业务术语定义已更新")
def start_file_observer():
observer = Observer()
event_handler = FileChangeHandler()
observer.schedule(event_handler, path='.', recursive=False)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
file_observer_thread = threading.Thread(target=start_file_observer)
file_observer_thread.daemon = True
file_observer_thread.start()使用
watchdog监听文件变化,当业务术语文件更新时,重新加载并训练。
8. 辅助函数
def clean_filename(filename):
return re.sub(r'[\\/*?:"<>|>\r\n]', "", filename)
def generate_csv_filename():
return f"query_results_{time.strftime('%Y%m%d_%H%M%S')}.csv"
def generate_sql_answer(question, allow_llm_to_see_data):
result = vn.generate_sql(question, allow_llm_to_see_data)
return result
def execute_sql_and_get_results(sql):
try:
df = vn.run_sql(sql=sql)
return df
except Exception as e:
return f"Error executing SQL: {str(e)}"
def generate_response(df, question):
if df is not None and not df.empty:
sql_result = df.to_string()
prompt = [
vn.system_message(f"根据以下查询结果生成回答:{sql_result}"),
vn.user_message(question)
]
answer = vn.submit_prompt(prompt)
# 添加中文翻译
column_map = {
"ProductName": "产品名称",
"Price": "价格",
"Quantity": "数量",
"Date": "日期",
"Category": "类别"
}
for col, translation in column_map.items():
if col in answer:
answer += f" ({translation})"
return answer
else:
return "No data available to generate a response."
def generate_chart(df, chart_type, x_column, y_column):
if df is not None and not df.empty:
df[y_column] = pd.to_numeric(df[y_column], errors='coerce')
df[y_column] = df[y_column].fillna(0)
df[y_column] = df[y_column].abs()
if chart_type == "柱状图":
fig = px.bar(df, x=x_column, y=y_column)
elif chart_type == "折线图":
fig = px.line(df, x=x_column, y=y_column)
else:
fig = px.bar(df, x=x_column, y=y_column)
return fig
else:
return Noneclean_filename清理文件名。generate_csv_filename生成带时间戳的 CSV 文件名。generate_sql_answer生成 SQL 查询。execute_sql_and_get_results执行 SQL 查询并返回结果。generate_response根据查询结果生成回答。generate_chart根据数据生成图表。
9. Gradio 界面
with gr.Blocks(...) as demo:
gr.Markdown("# quantity_demo 问答机器人")
with gr.Tab("SQL 生成与执行"):
# 界面元素定义
question_input = gr.Textbox(label="请输入问题")
allow_data_checkbox = gr.Checkbox(label="允许模型查看数据", value=True)
...
with gr.Tab("提问"):
ask_input = gr.Textbox(label="请输入问题")
ask_output = gr.Textbox(label="回答")
...
with gr.Tab("业务术语定义"):
term_input = gr.Textbox(label="术语")
definition_input = gr.Textbox(label="定义")
...使用 Gradio 创建多标签页界面:
SQL 生成与执行:输入问题,生成 SQL,执行查询,下载结果,生成图表。
提问:直接提问并获取回答。
业务术语定义:添加、删除术语定义。
10. 启动应用
demo.launch()启动 Gradio 应用,提供交互界面。
六、演示效果和功能介绍
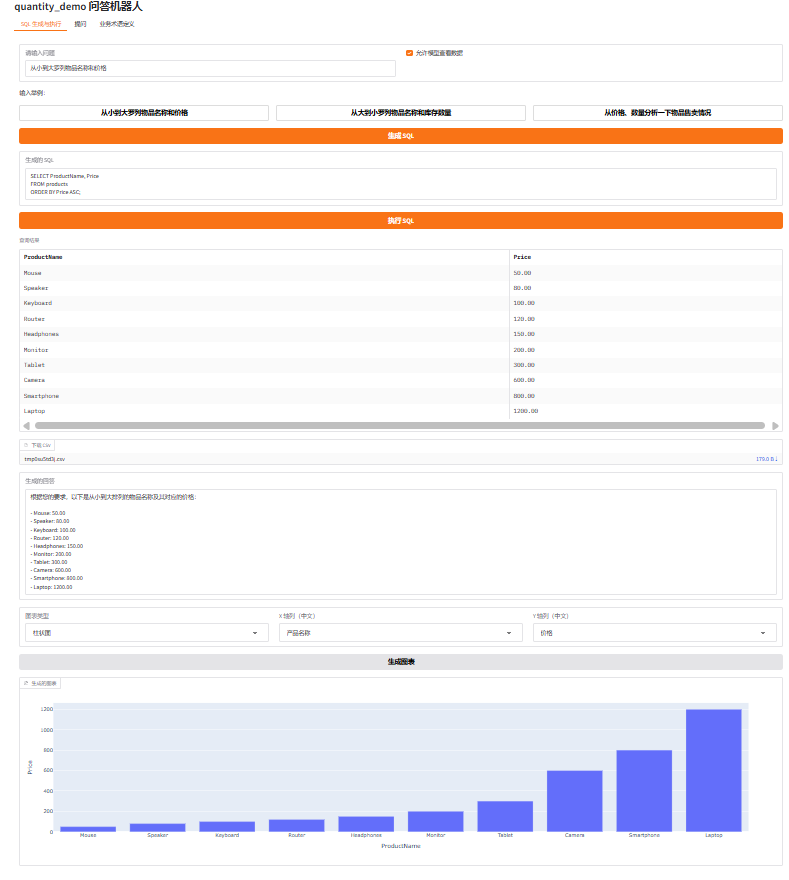
基于自然语言生成SQL语句:
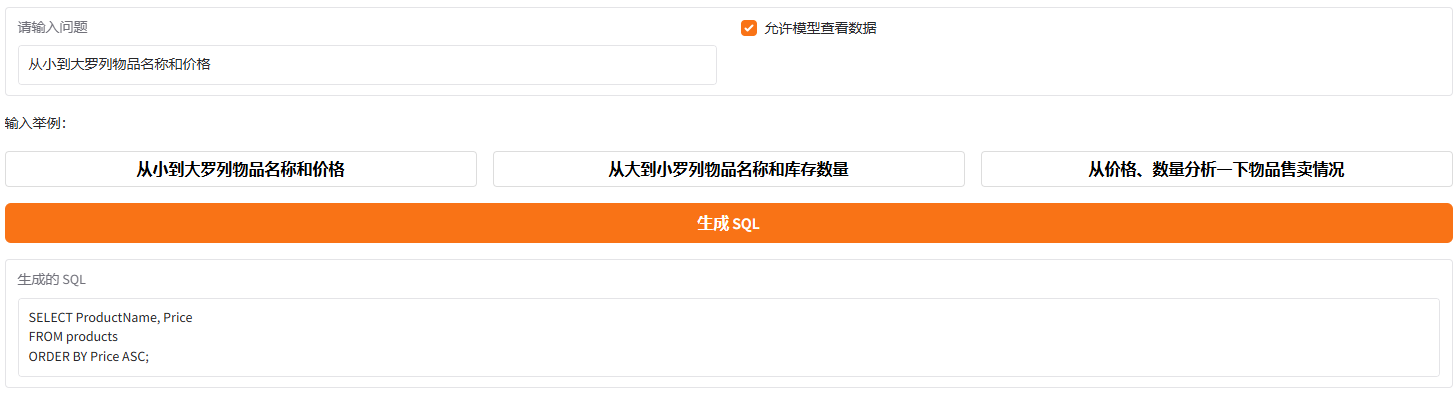
基于SQL语句生成查询结果、自然语言回答,并且支持CSV文件下载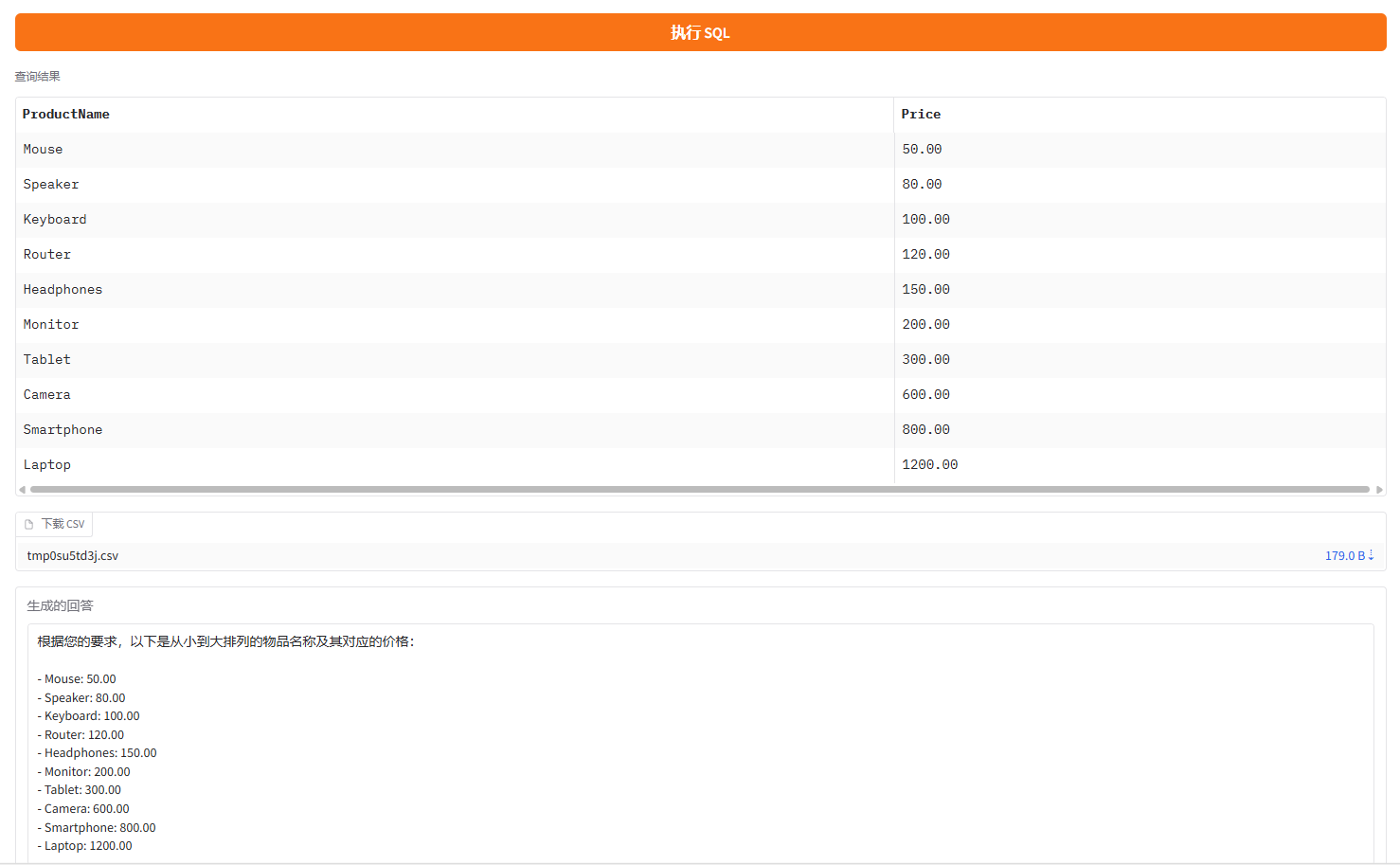
同时可以选择生成图表:
七、总结
相较于第一个案例,优化了DDL和数据库说明,分别用单独的json和sql文件进行存储,方便用户进行集中更新,同时自己搭建gradio界面,让功能更加自定义。