目录
一 达人探店
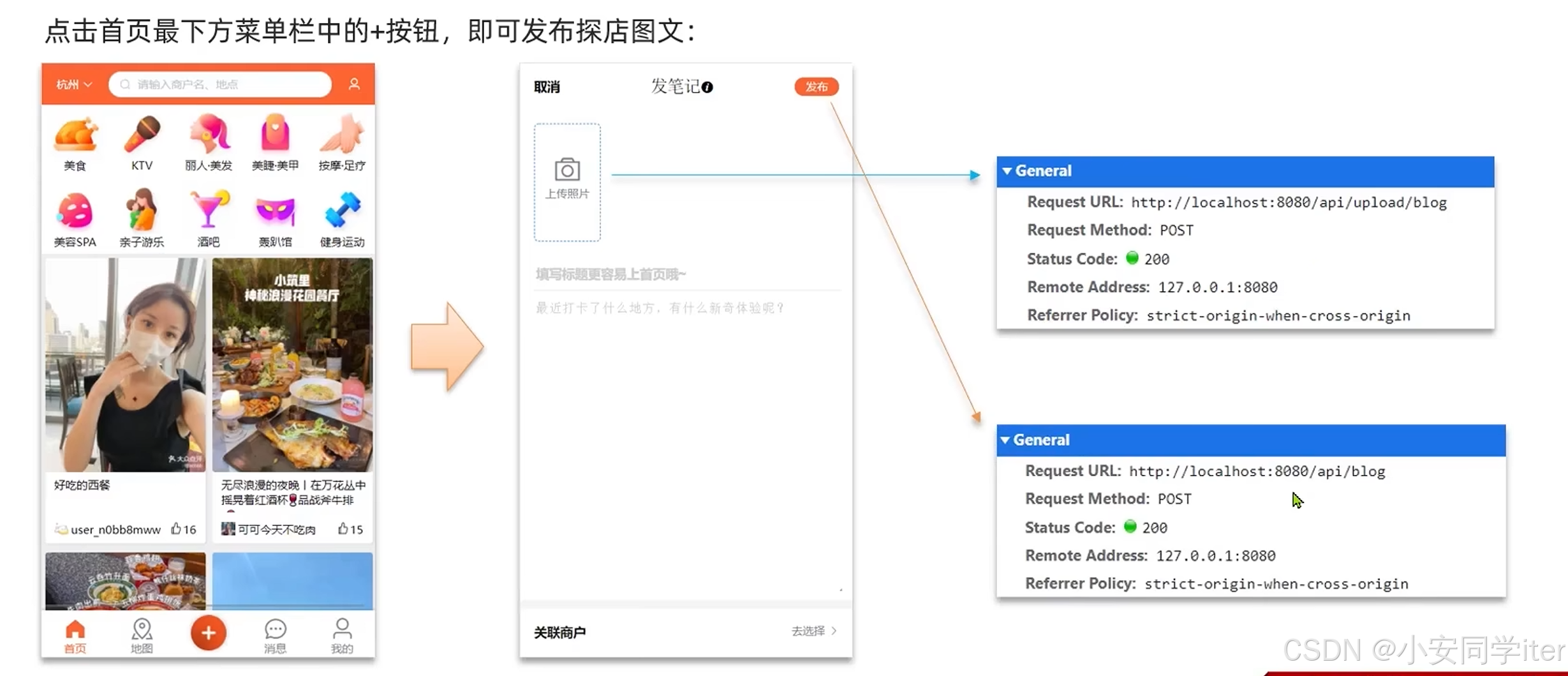
1 发布探店笔记

上传成功并实现回显功能(这里保存到本地当中)
这里定义了相关方法(同时在配置类当中定义了文件保存的地址)
package com.hmdp.controller;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.StrUtil;
import com.hmdp.dto.Result;
import com.hmdp.utils.SystemConstants;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.util.UUID;
@Slf4j
@RestController
@RequestMapping("upload")
public class UploadController {
@PostMapping("blog")
public Result uploadImage(@RequestParam("file") MultipartFile image) {
try {
// 获取原始文件名称
String originalFilename = image.getOriginalFilename();
// 生成新文件名
String fileName = createNewFileName(originalFilename);
// 保存文件
image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName));
// 返回结果
log.debug("文件上传成功,{}", fileName);
return Result.ok(fileName);
} catch (IOException e) {
throw new RuntimeException("文件上传失败", e);
}
}
@GetMapping("/blog/delete")
public Result deleteBlogImg(@RequestParam("name") String filename) {
File file = new File(SystemConstants.IMAGE_UPLOAD_DIR, filename);
if (file.isDirectory()) {
return Result.fail("错误的文件名称");
}
FileUtil.del(file);
return Result.ok();
}
private String createNewFileName(String originalFilename) {
// 获取后缀
String suffix = StrUtil.subAfter(originalFilename, ".", true);
// 生成目录
String name = UUID.randomUUID().toString();
int hash = name.hashCode();
int d1 = hash & 0xF;
int d2 = (hash >> 4) & 0xF;
// 判断目录是否存在
File dir = new File(SystemConstants.IMAGE_UPLOAD_DIR, StrUtil.format("/blogs/{}/{}", d1, d2));
if (!dir.exists()) {
dir.mkdirs();
}
// 生成文件名
return StrUtil.format("/blogs/{}/{}/{}.{}", d1, d2, name, suffix);
}
}
配置类
package com.hmdp.utils;
public class SystemConstants {
public static final String IMAGE_UPLOAD_DIR = "D:\\kaifa\\dianp\\nginx-1.18.0\\nginx-1.18.0\\html\\hmdp\\imgs\\";
public static final String USER_NICK_NAME_PREFIX = "user_";
public static final int DEFAULT_PAGE_SIZE = 5;
public static final int MAX_PAGE_SIZE = 10;
}
2 查看探店笔记
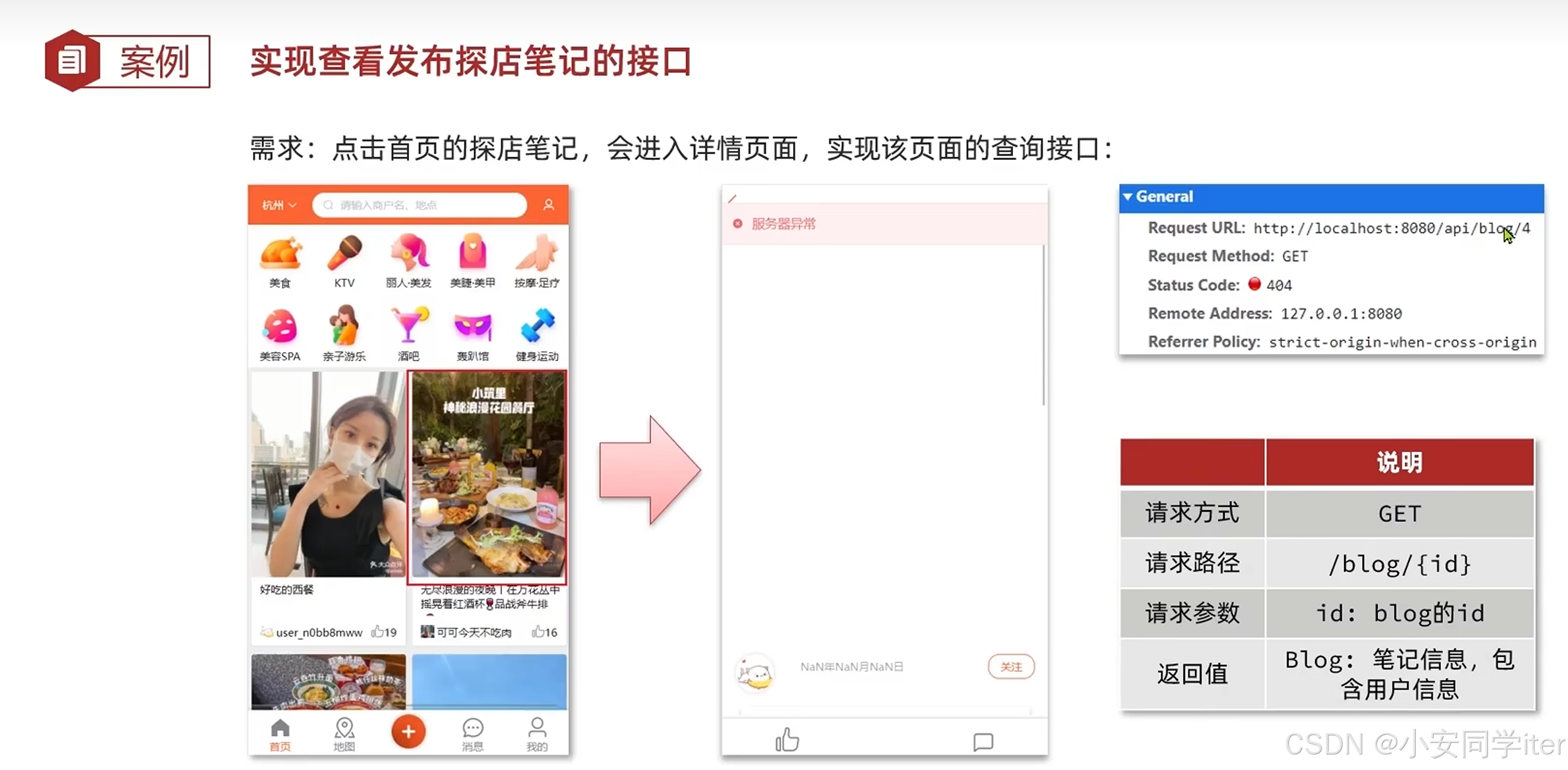
Controller控制层
/**
* 查询博文详情
*
* @param id
* @return
*/
@GetMapping("/{id}")
public Result queryBlogById(@PathVariable("id") Long id) {
return blogService.queryBlogById(id);
}Service业务层
/**
* 根据id查询
* @param id
* @return
*/
Result queryBlogById(Long id);业务层实现类
/**
* 查询笔记详情
*
* @param id
* @return
*/
@Override
public Result queryBlogById(Long id) {
// 查询blog
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在");
}
// 查询用户
queryBlogUser(blog);
//查询blog是否被点赞了被点赞之后需要缓存到redis中
queryBlogLikes(blog);
return Result.ok(blog);
}3 点赞功能
点赞功能使用Redis当中的set(判断用户是否存在点赞过返回数值,没点赞返回空值)
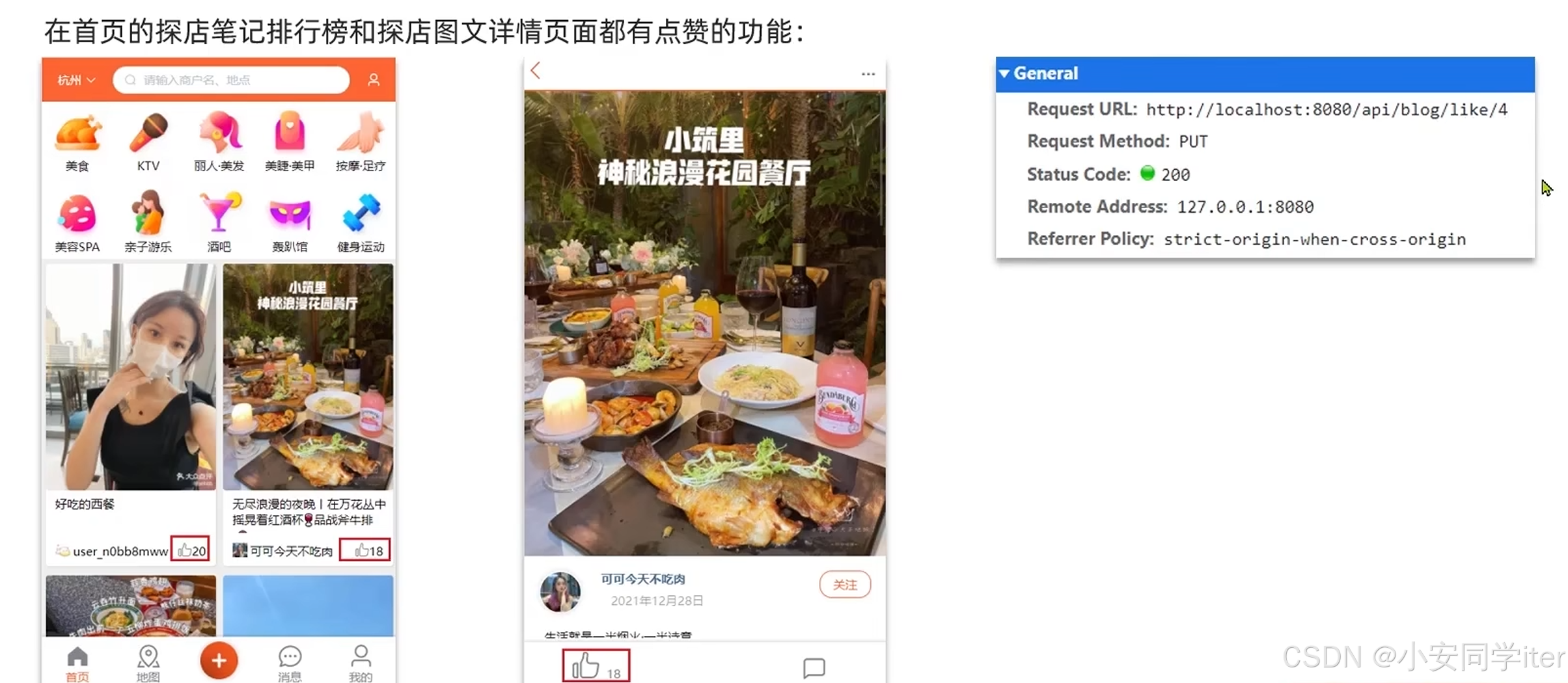

controller控制层
/**
* 点赞博文
*
* @param id
* @return
*/
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
return blogService.likeBlog(id);
}Service业务层
/**
* 点赞博客
* @param id
* @return
*/
Result likeBlog(Long id);Service业务层实现类
/**
* 点赞
*
* @param id
* @return
*/
@Override
public Result likeBlog(Long id) {
// 1判断当前登录用户
Long userId = UserHolder.getUser().getId();
// 2盘带当前用户是否已经点赞
String key = RedisConstants.BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
// 3如果未点赞,可以点赞
if (score == null) {
// 3.1数据库点赞数量加1
boolean update = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2保存用户点赞记录到Redis集合set当中
if (update) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {// 4如果已经点赞
// 4.1数据库点赞数量减1
boolean update = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2删除用户点赞记录
if (update) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
// 5返回点赞结果
return Result.ok();
}4 点赞排行榜(top5)
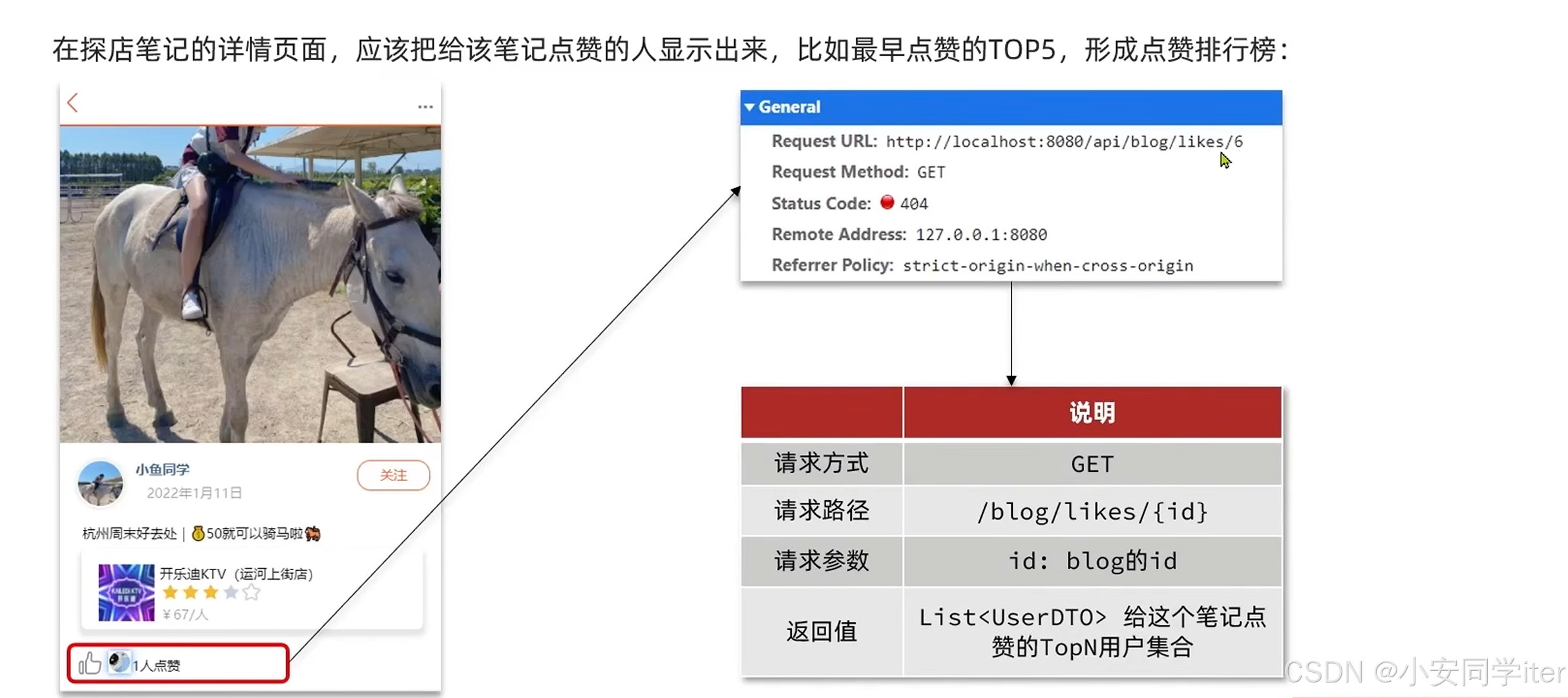
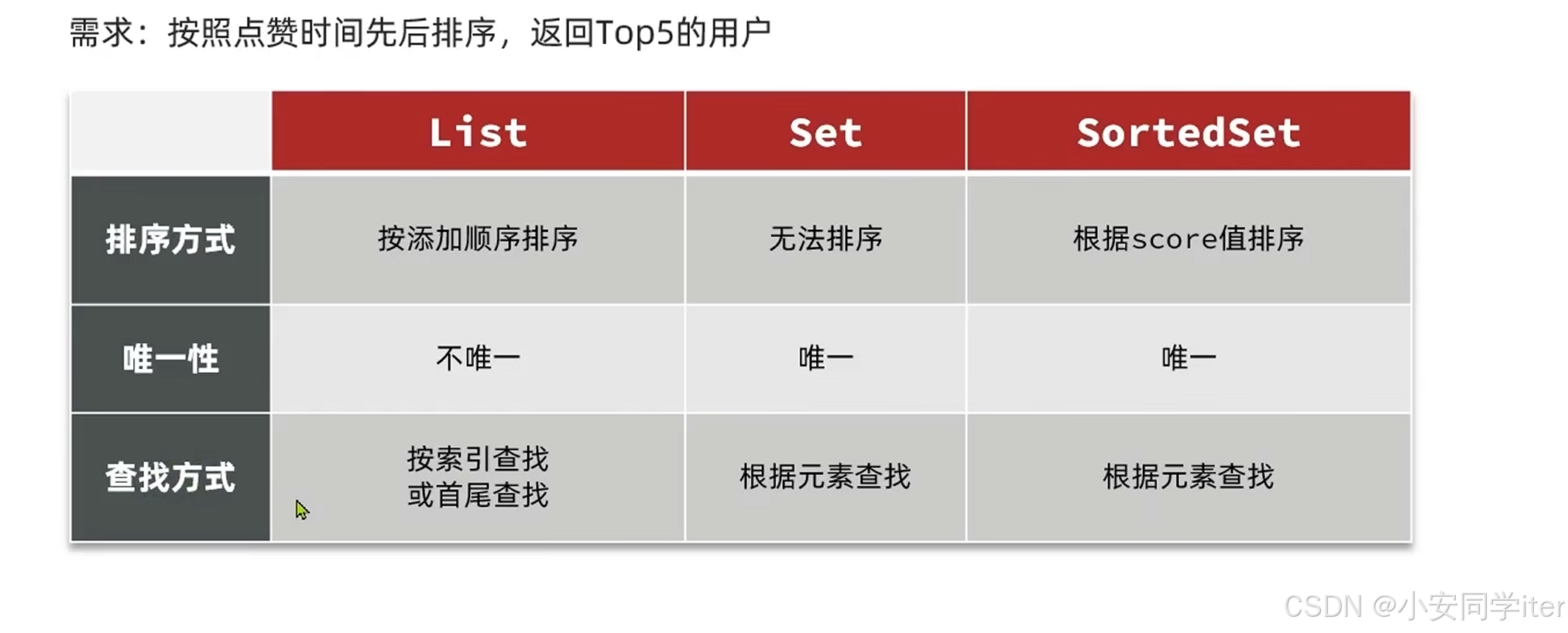
这里我们使用的是SortedSet(这里可以使用时间戳来设置score值)
这里没有set当中的isMember但是有zscore获取元素的分数(有的话就返回分数没有就返回空)
Controller控制层
/**
* 点赞列表top5
*/
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {
return blogService.queryBlogLikes(id);
}Service业务层
/**
* 查询博客点赞top5
* @param id
* @return
*/
Result queryBlogLikes(Long id);Service业务层实现类
/**
* 查询笔记点赞用户前五
*
* @param id
* @return
*/
@Override
public Result queryBlogLikes(Long id) {
// 1查询top5的点赞用户 zrange key 0 4
String key = RedisConstants.BLOG_LIKED_KEY + id;
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 2解析出用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
// 将 List<Long> 转换为 List<String>
List<String> idStars = ids.stream().map(String::valueOf).collect(Collectors.toList());
// 使用 String.join 拼接字符串
String idStr = String.join(",", idStars);
// 3根据用户id查询用户
List<UserDTO> userDTOS = userService.query().in("id", ids).last("order by field(id," + idStr + ")")
.list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 4返回用户
return Result.ok(userDTOS);
}二 好友关注
1 关注与取关
判断是否在set集合当中
Controller控制层
/**
* 关注或取关
* @param followUserId
* @param isFollow
* @return
*/
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}Servcie业务层
/**
* 关注或取消关注
* @param followUserId
* @param isFollow
* @return
*/
Result follow(Long followUserId, Boolean isFollow);Service业务层实现类
/**
* 关注或取关
*
* @param followUserId
* @param isFollow
* @return
*/
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是关注还是取关
if (isFollow) {//关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean save = save(follow);
if (save) {
//把关注的用户id保存到redis的set集合中
String key = "follow:" + userId;
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {//取关
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId)
.eq("follow_user_id", followUserId));
if (isSuccess) {
//把关注的用户id从redis的set集合中移除
String key = "follow:" + userId;
stringRedisTemplate.opsForSet().remove(key, followUserId.toString());
}
}
return Result.ok();
}2 共同关注
SINTER user:1001:friends user:1002:friends 利用共同元素的原理
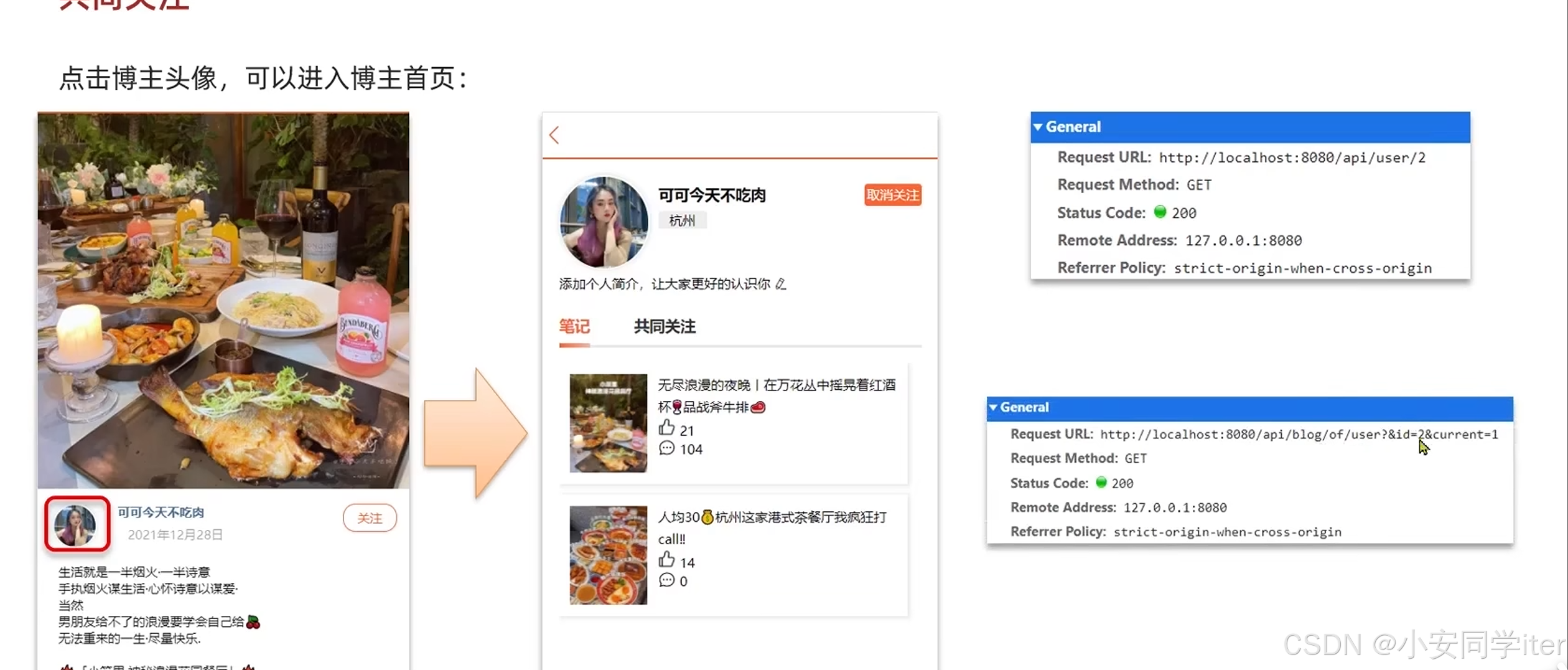
根据id查询用户
/**
* 查询用户
*
* @param —— userid 用户id
* @return
*/
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId) {
// 查询详情
User user = userService.getById(userId);
if (user == null) {
// 没有详情,应该是第一次查看详情
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}根据id查询用户的博文
/**
* 查询用户博文
*
* @param current
* @param id
* @return
*/
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}获取共同关注(当前登录用户与被访问的用户的共同关注)
/**
* 获取共同关注
* @param id
* @return
*/
@GetMapping("/common/{id}")
public Result followCommons(@PathVariable("id") Long id) {
return followService.followCommons(id);
}Service业务层
/**
* 共同关注
*
* @param id
* @return
*/
Result followCommons(Long id);Service业务层实现类(使用Redis的Set存储用户的关注列表,键格式为follow:{userId},值为被关注用户的ID集合。)SINTER命令求两个集合的交集,返回共同关注的用户ID集合。
/**
* 查询共同关注
*
* @param id
* @return
*/
@Override
public Result followCommons(Long id) {
Long userId = UserHolder.getUser().getId();
String key = "follow:" + userId;
String key2 = "follow:" + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
return Result.ok(Collections.emptyList());
}
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}3 Feed流实现关注推送
feed直译为投喂的意思。为用户持续的提供沉浸式的体验,通过无线下拉实现获取新的信息。
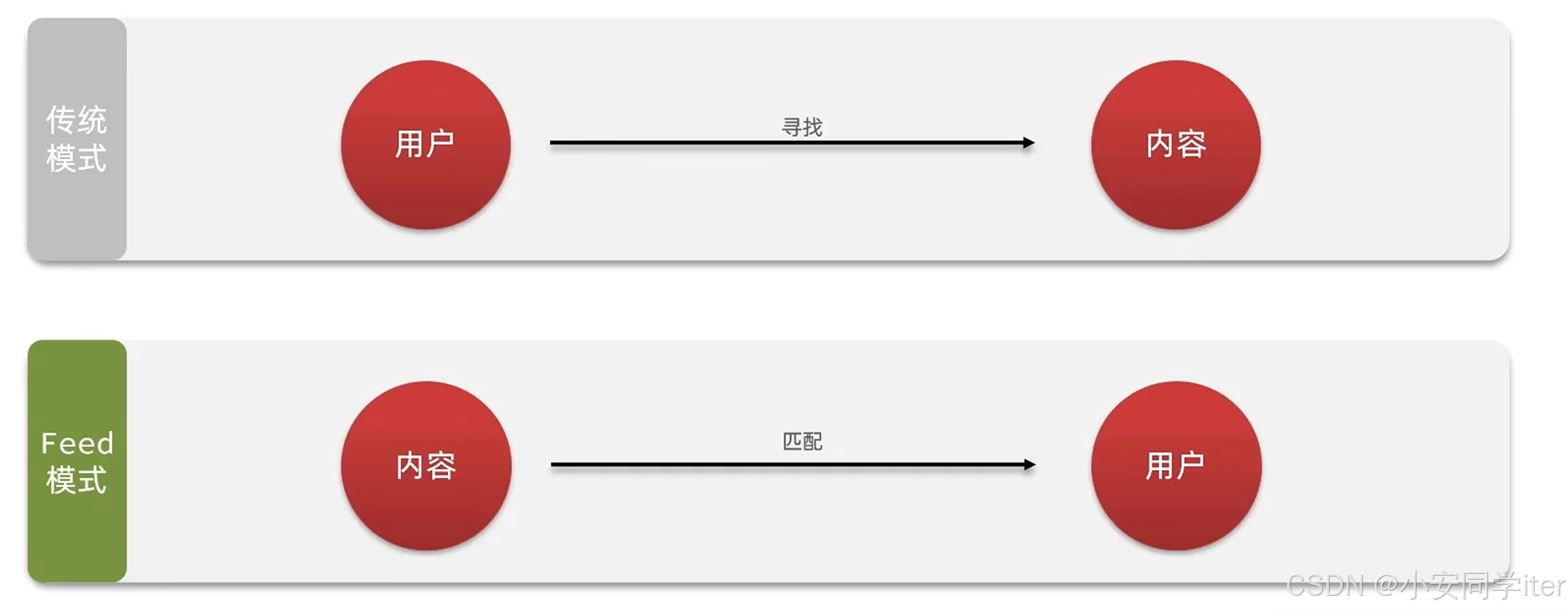
Feed流的模式

我们使用的是对关注列表用户发送博文时间的推送(推模式)
实现方式(推拉)
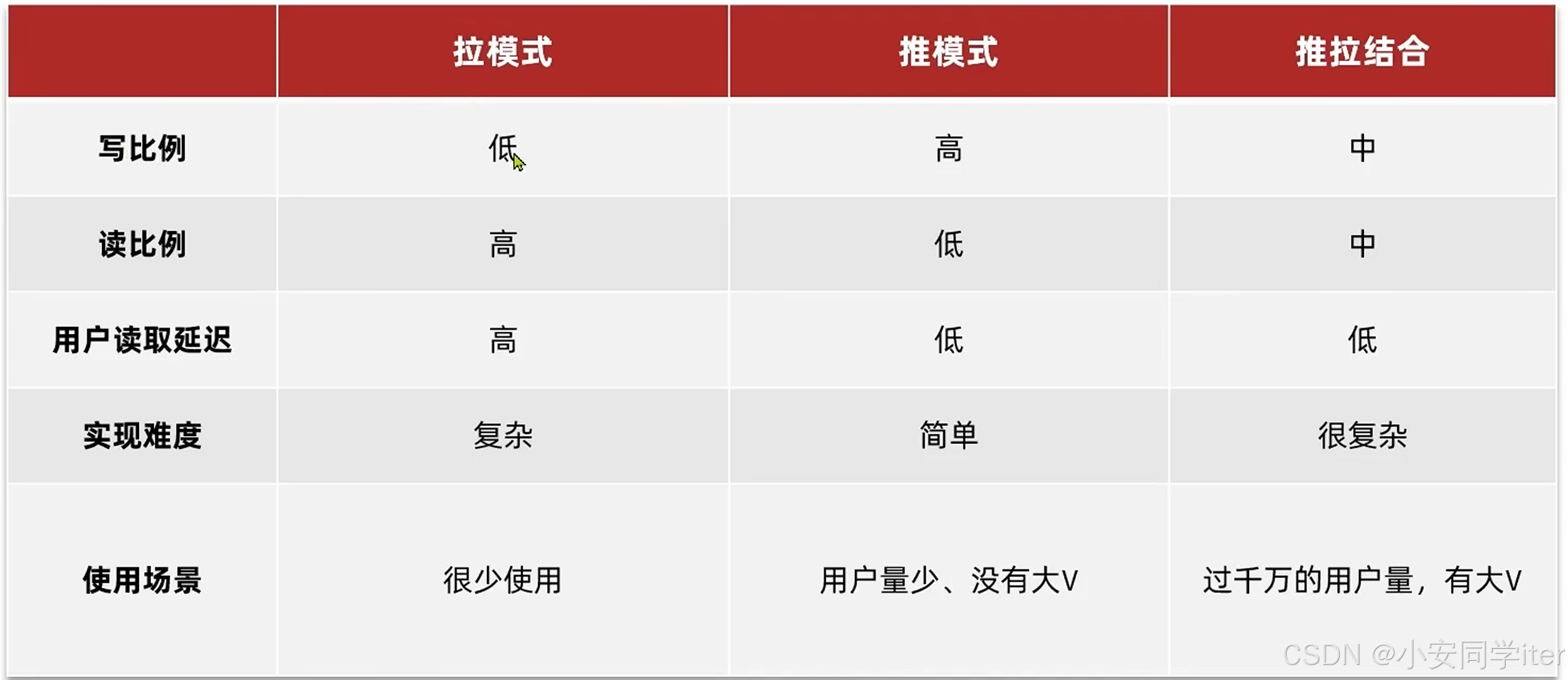
1 推模式:
实现原理当用户发送内容是系统自动会将内容推送到所有关注者的收件箱当中。
会导致写入的压力过大,导致内容在多个收件箱都重复存储,有些不登录的用户也会被推送。
2 拉模式:
用户查看Feed,系统会对用户的关注对象的信息进行拉取。
写入的成本会下降,但是关注数较多的用户会出现查询性能下降的问题。
3 推拉结合:
分用户策略
大V用户:存在一个发件箱,活跃粉丝直接推送给其收件箱,而普通粉丝上线再从发件箱当中拉去信息。
普通用户:采用推模式,推送的压力较小,可直接推送给粉丝用户。
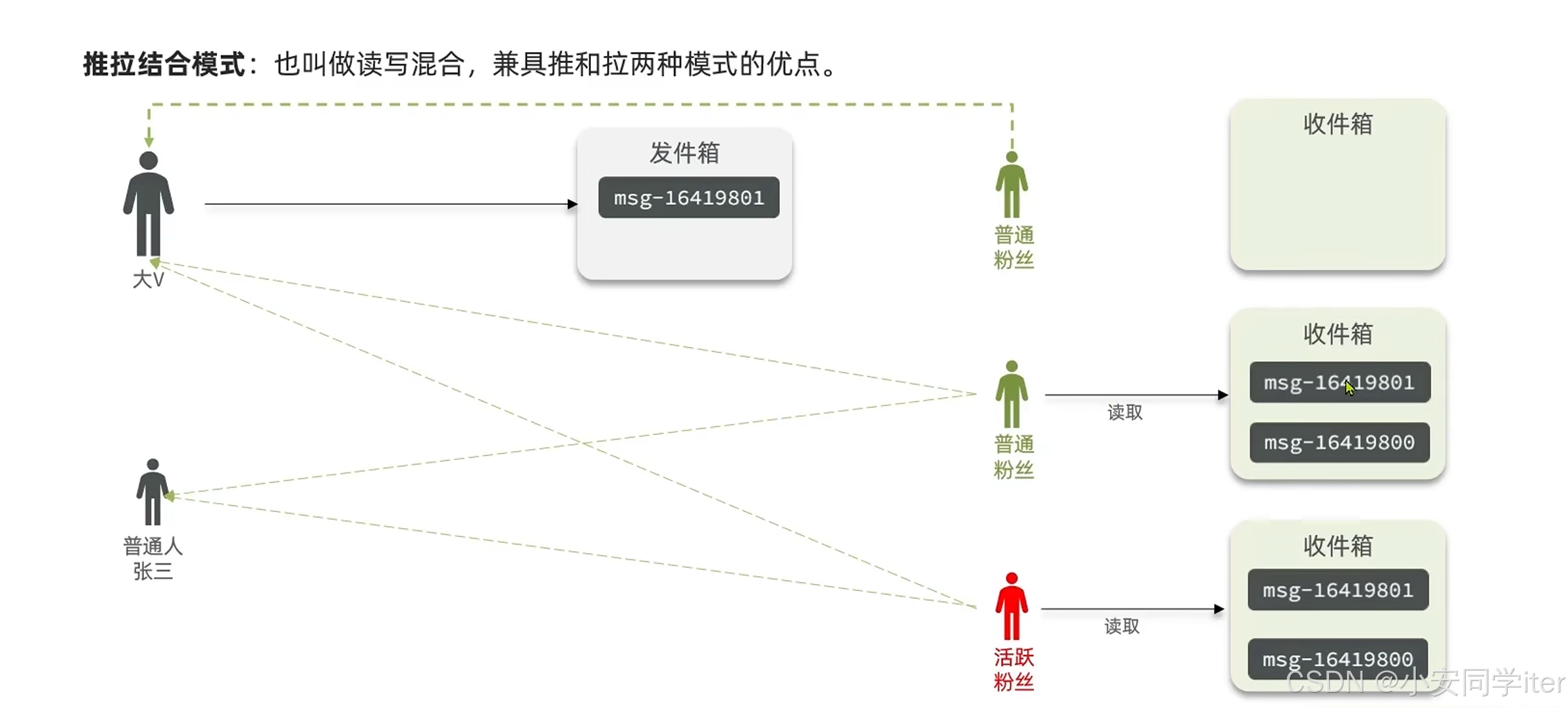
首先修改:在发布博文时需要将信息推送给粉丝用户
/**
* 发布博文
*
* @param blog
* @return
*/
@Override
public Result saveBlog(Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
boolean save = save(blog);
if (!save) {
return Result.fail("新增笔记失败");
}
// 查询笔记作者的所有粉丝
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 将笔记的id给所有粉丝
for (Follow follow : follows) {
// 获取粉丝id
Long userId = follow.getUserId();
// 给粉丝发送消息
String key = RedisConstants.FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 返回id
return Result.ok(blog.getId());
}4 实现滚动分页查询
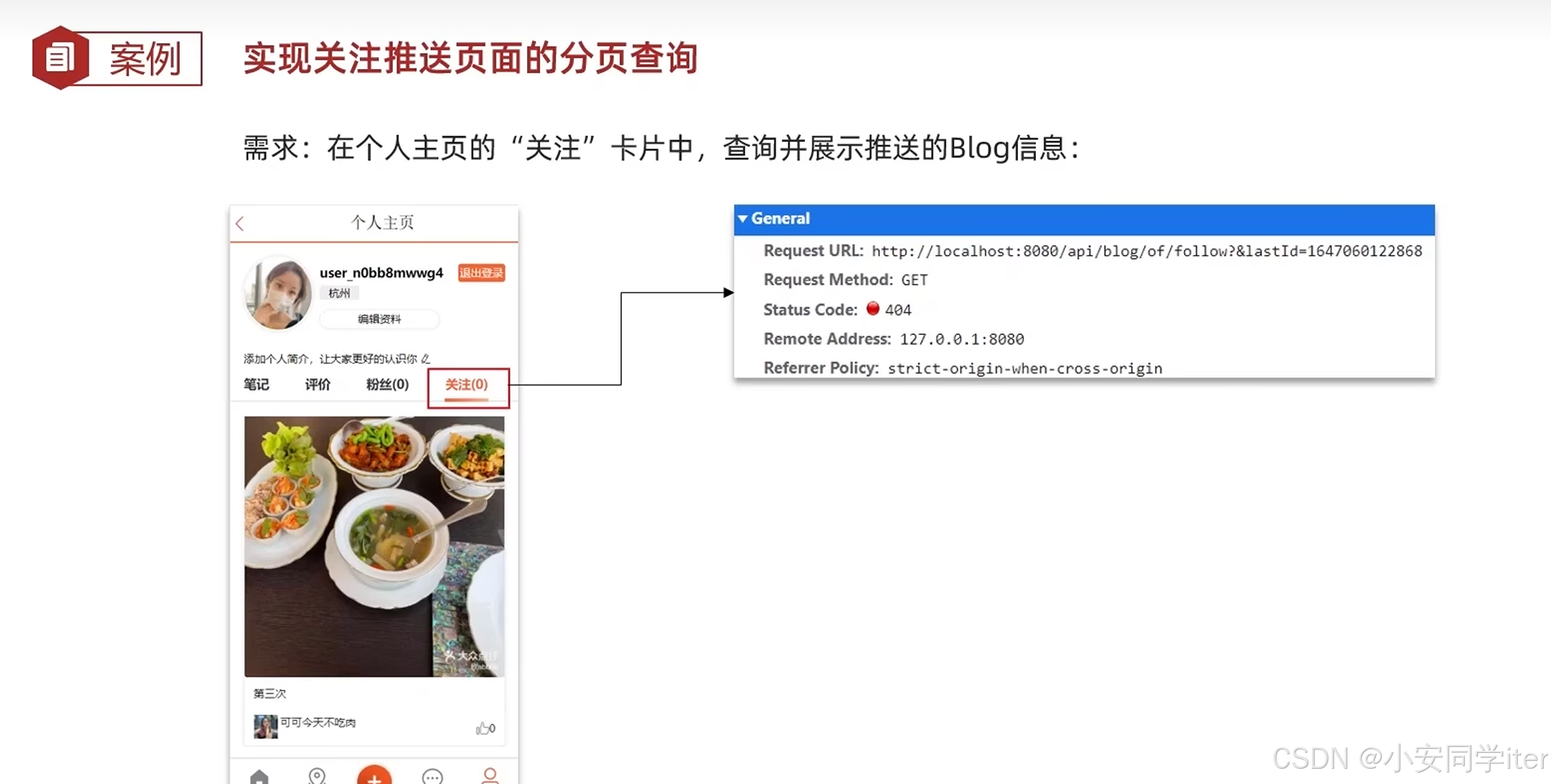
Controller控制层
/**
* 分页滚动查询
* @param max
* @param offset
* @return
*/
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset) {
return blogService.queryBlogOfFollow(max, offset);
}Service业务层接口
/**
* 分页查询博客
* @param max
* @param offset
* @return
*/
Result queryBlogOfFollow(Long max, Integer offset);Service业务层实现类
/**
* 滚动分页查询笔记
*
* @param max
* @param offset
* @return
*/
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1获取当前用户
Long userId = UserHolder.getUser().getId();
String key = RedisConstants.FEED_KEY + userId;
// 2查询收件箱 ZREVRANGEBYSCORE key max min LIMIT offset count
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 3解析数据blogId,minTime,offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
//获取id
ids.add(Long.valueOf(typedTuple.getValue()));
// 获取分数(时间戳)
long time = typedTuple.getScore().longValue();
if (time == minTime) {
os++;
}else {
minTime = time;
os = 1;
}
}
// 4根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("order by field(id," + idStr + ")").list();
for (Blog blog : blogs) {
// 查询用户
queryBlogUser(blog);
//查询blog是否被点赞了被点赞之后需要缓存到redis中
queryBlogLikes(blog);
}
// 5封装blog
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setOffset(os);
scrollResult.setMinTime(minTime);
return Result.ok(scrollResult);
}在传统的角标分页查询中(如LIMIT offset, count),若数据发生增删会导致分页错乱(如重复加载或遗漏数据)。为解决这一问题,我们基于Redis的Sorted Set特性,通过分数(时间戳)范围和偏移量(offset)实现稳定分页。
1. 数据存储与查询基础
Sorted Set结构:以时间戳作为分数(score),动态ID作为值(value),按分数倒序排列(新数据在前)。
分页目标:每次查询固定数量的数据,并精准定位下一页起始位置,避免数据变动导致分页混乱。
Set<TypedTuple<String>> tuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);key:Sorted Set的键名(如用户收件箱
feed:1001)。min=0:分数下限(闭区间),固定为0以查询所有历史数据。
max:分数上限(闭区间),首次查询设为当前时间戳,后续查询使用上一页的最小分数(即更早的时间)。
offset:偏移量,表示从当前分数段的第几条开始取数据。初始值为0(从第一条开始),若上一页存在相同分数的数据,则传递其数量用于跳过已读记录。
count=2:每页数量,此处硬编码为2条。
三 附近商店
1 GEO数据结构
Redis 的 GEO 是专门用于处理地理位置信息的数据类型,基于 Sorted Set(有序集合) 实现,并通过 GeoHash 编码 将二维的经纬度信息转换为一维的数值,支持高效的地理位置存储、查询和计算。

2 附近商户搜索功能
这里的登录用户的地址信息便于接口的实现是写死的,同时这里的分页使用的是传统分页
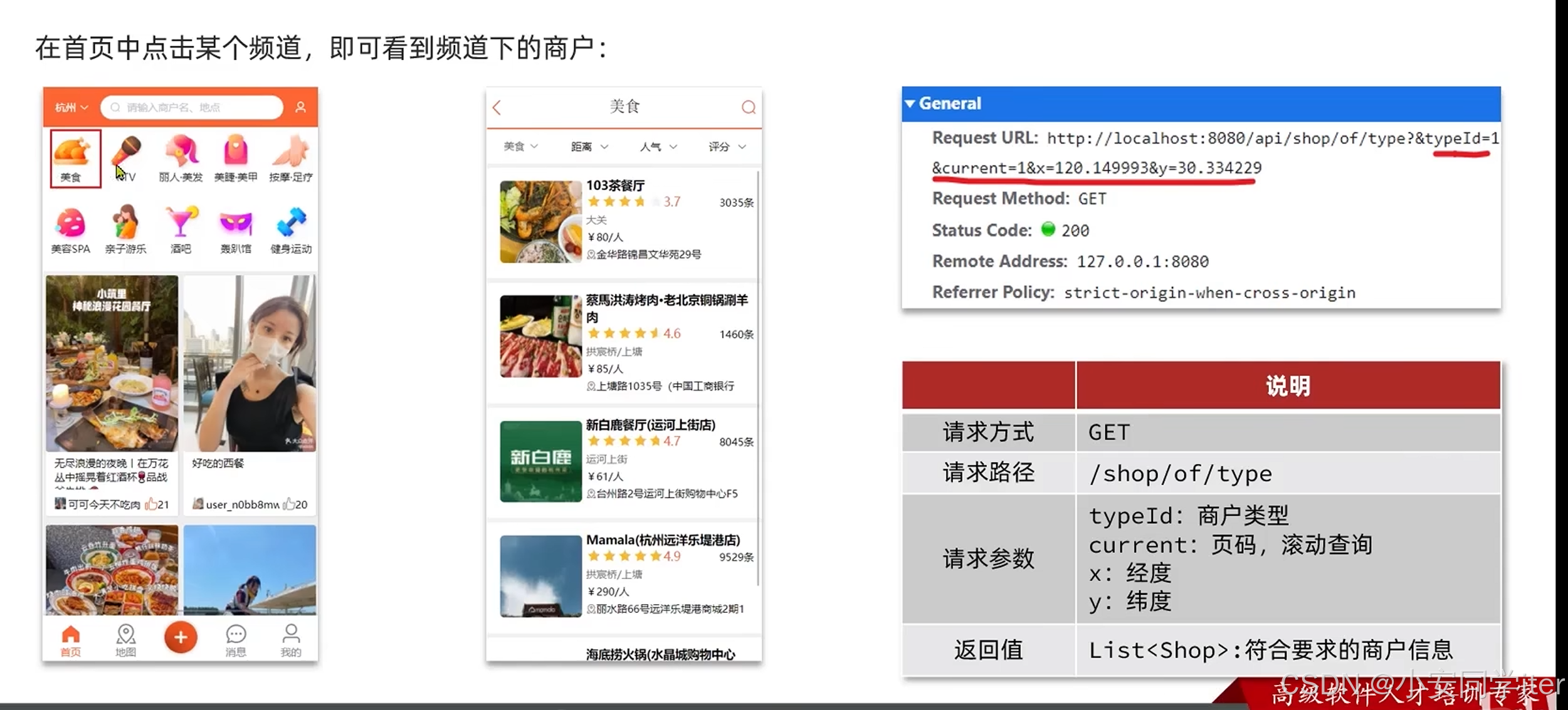
根据商户类型做分组,类型相同的为同一组,一typeId为key存入同一个GEO集合当中即可。
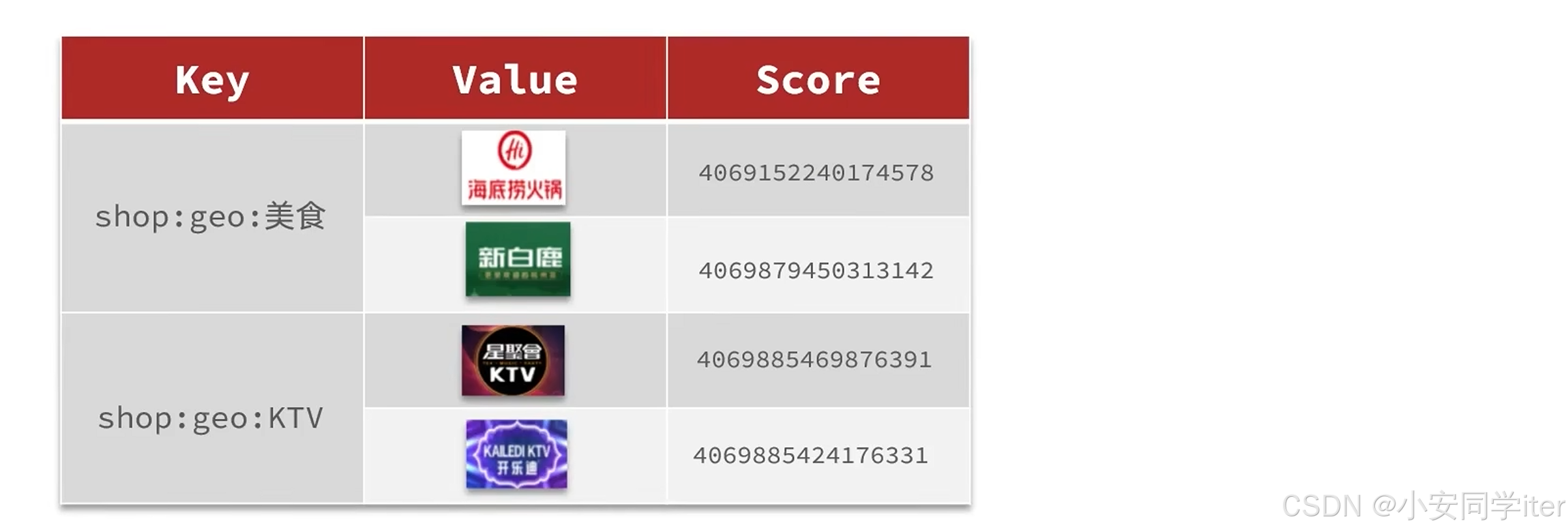
首先为了准备数据先将店铺当中分类好的数据写入Redis当中
@Test
public void loadShopData() {
// 1 查询店铺信息
List<Shop> list = shopService.list();
// 2 将店铺分组(每个Long类型的数值对应一个List集合)
Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));
// 3 分批写入Redis
for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) {
// 3.1 获取类型id
Long typeId = entry.getKey();
String key = "shop:geo:" + typeId;
// 3.2 获取同类型的店铺集合
List<Shop> value = entry.getValue();
List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size());
// 3.3 写入redis geoadd key lng lat member
for (Shop shop : value) {
// 3.3.1 获取店铺的经纬度
Double x = shop.getX();
Double y = shop.getY();
String shopId = shop.getId().toString();
locations.add(new RedisGeoCommands.GeoLocation<>(shopId, new Point(x, y)));
}
stringRedisTemplate.opsForGeo().add(key, locations);
}
}实现结果展示
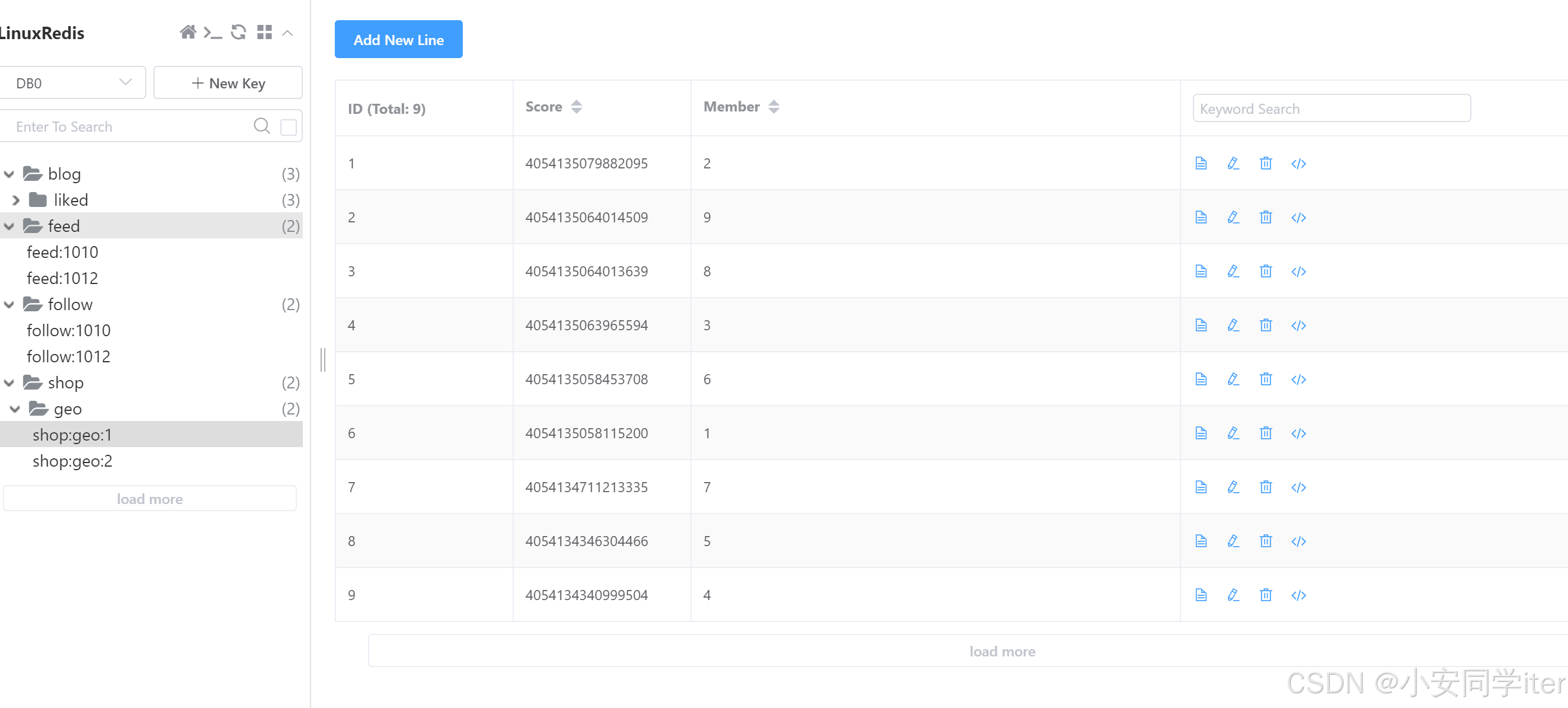
按照距离进行排序分页展示
代码实现:
Controller控制层
/**
* 根据类型分页查询商铺信息
*
* @param typeId 商铺类型
* @param current 页码
* @return 商铺列表
*/
@GetMapping("/of/type")
public Result queryShopByType(
@RequestParam("typeId") Integer typeId,
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam(value = "x", required = false) Double x,
@RequestParam(value = "y", required = false) Double y
) {
return shopService.queryShopByType(typeId, current, x, y);
}Service业务层接口
/**
* 根据商铺类型分页查询商铺信息
*
* @param typeId 商铺类型
* @param current 页码
* @param x 纬度
* @param y 经度
* @return 商铺列表
*/
Result queryShopByType(Integer typeId, Integer current, Double x, Double y);Service业务层实现类
/**
* 根据类型查询店铺信息
*
* @param typeId 类型id
* @param current 页码
* @param x x坐标
* @param y y坐标
* @return Result
*/
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1判断是否需要根据坐标查询
if (x == null || y == null) {//不需要使用坐标查询
Page<Shop> page = query()
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
//返回数据
return Result.ok(page.getRecords());
}
// 2计算分页参数
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3 查询Redis按照距离排序分页 结果:shopId、distance
String key = RedisConstants.SHOP_GEO_KEY + typeId;
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo()
.search(key,
GeoReference.fromCoordinate(x, y),
new Distance(5000),
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)
);
// 4 解析出id
if (results == null) {
return Result.ok(Collections.emptyList());
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();
if (list.size() <= from) {
// 4.1没有下一页数据
return Result.ok(Collections.emptyList());
}
// 4.2截取使用skip
List<Long> ids = new ArrayList<>(list.size());
Map<String, Distance> distanceMap = new HashMap<>(list.size());
list.stream().skip(from).forEach(result -> {
// 4.3获取店铺id
String shopId = result.getContent().getName();
ids.add(Long.valueOf(shopId));
// 4.4获取距离
Distance distance = result.getDistance();
distanceMap.put(shopId, distance);
});
// 5 根据id查询
String idStr = StrUtil.join(",", ids);
List<Shop> shops = query().in("id", ids).last("order by field(id," + idStr + ")").list();
for (Shop shop : shops) {
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
}
// 6 返回
return Result.ok(shops);
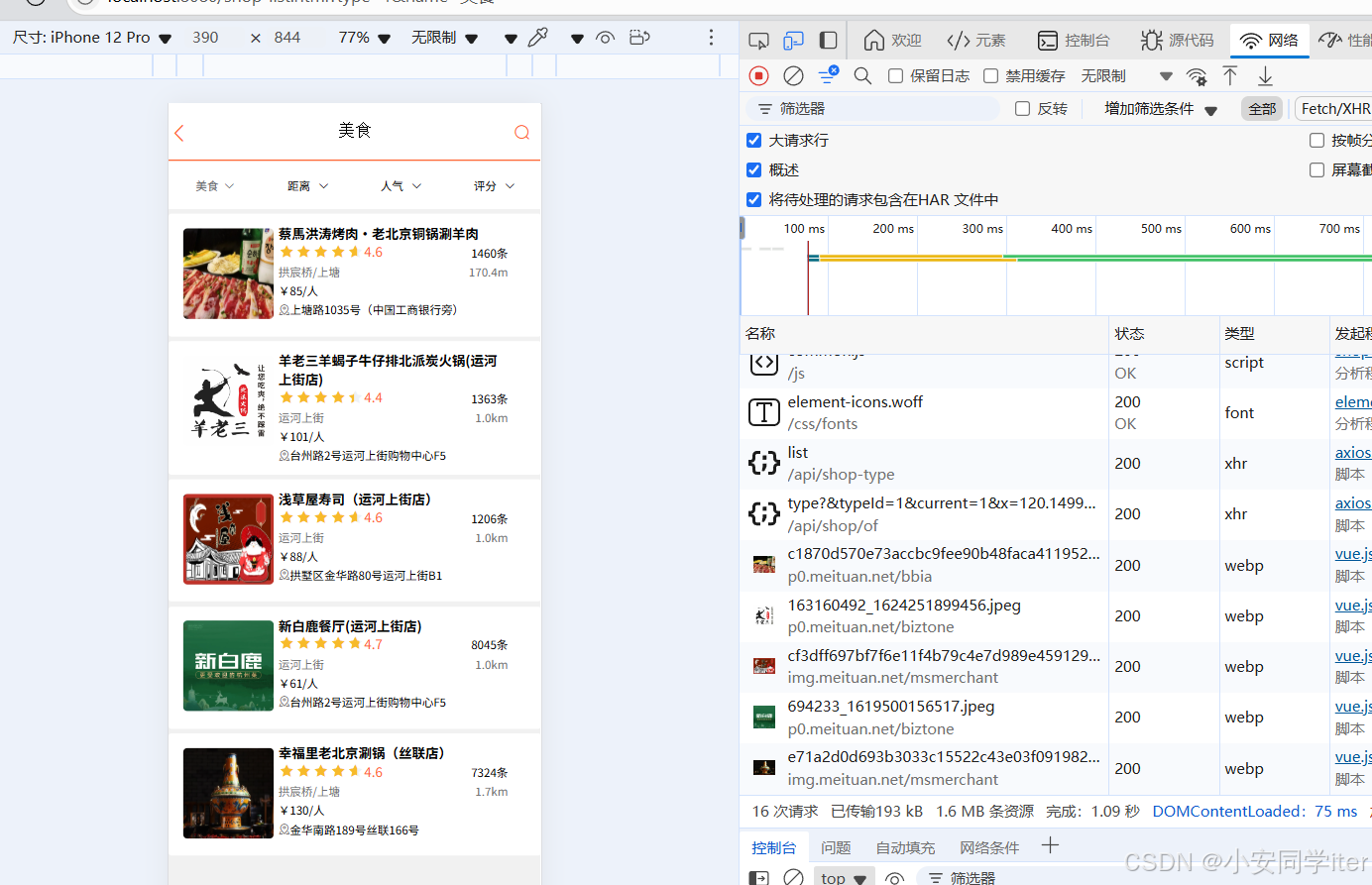
}结果展示:
四 用户签到
1 BitMap
BitMap(位图)是一种基于 二进制位(bit) 的高效数据结构,通过每个二进制位的值(0或1)表示某种状态或标记。Redis 中虽然没有独立的 BitMap 类型,但通过 String 类型 的位操作命令实现了 BitMap 的功能。

常用命令

使用:
| 命令 | 作用 | 示例 |
|---|---|---|
SETBIT key offset 0/1 |
设置指定偏移量的位值(0或1) | SETBIT sign:202310 100 1(用户100已签到) |
GETBIT key offset |
获取指定偏移量的位值 | GETBIT sign:202310 100 → 1 |
BITCOUNT key [start end] |
统计值为1的位数(支持字节范围) | BITCOUNT sign:202310 → 30(30人签到) |
BITOP operation destkey key1 key2 |
对多个BitMap进行位运算(AND/OR/XOR/NOT) | BITOP AND active_users user:day1 user:day2 |
2 签到功能

代码实现:
Controller控制层
/**
* 签到功能
* @return
*/
@PostMapping("/sign")
public Result sign() {
return userService.sign();
}Service业务层接口
/**
* 签到功能
* @return
*/
Result sign();Service业务层实现类
/**
* 签到功能
*
* @return
*/
@Override
public Result sign() {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
String keySuffix = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMM"));
// 3.拼接key
String key = RedisConstants.USER_SIGN_KEY + userId + ":" + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = LocalDateTime.now().getDayOfMonth();
// 5.写入redis setBit key offset value
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}3 签到统计

需求:
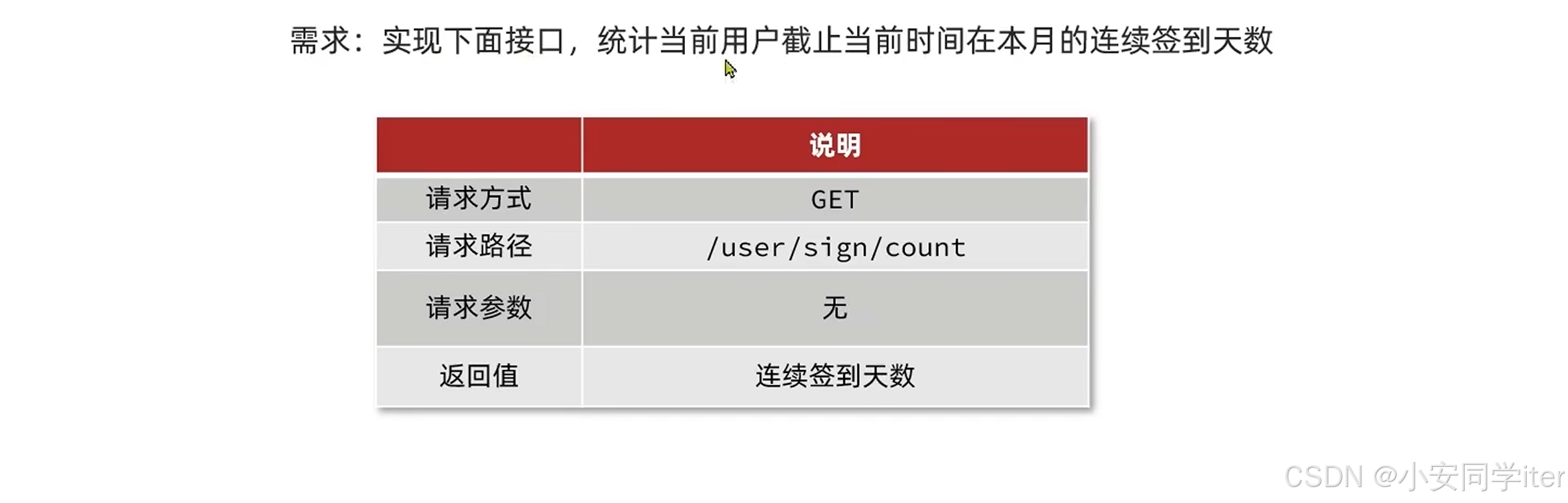
代码实现:
Controller控制层
/**
* 统计当前连续签到天数
* @return
*/
@GetMapping("/sign/count")
public Result signCount() {
return userService.signCount();
}Service业务层接口
/**
* 统计当前连续签到天数
* @return
*/
Result signCount();Service业务层实现类
/**
* 签到
*
* @return {@link Result}
*/
@Override
public Result signCount() {
// 获取本月所有的签到天数记录
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
String keySuffix = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMM"));
// 3.拼接key
String key = RedisConstants.USER_SIGN_KEY + userId + ":" + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = LocalDateTime.now().getDayOfMonth();
// 5.获取本月截至当前为止所有的签到数据,返回数据为一个十进制
List<Long> result = stringRedisTemplate.opsForValue().bitField(
key,
BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0)
);
if (result == null || result.isEmpty()) {
return Result.ok(0);
}
Long num = result.get(0);
if (num == null || num == 0) {
return Result.ok(0);
}
// 6.循环遍历
int dayCount = 0;
while (true) {
// 7.判断当前日期是否被签到
if ((num & 1) == 0) {
break;
} else {
// 8.计数器+1
dayCount++;
// 9.右移
num >>>= 1;
}
}
return Result.ok(dayCount);
}五 UV统计
1 HyperLogLog


实现:
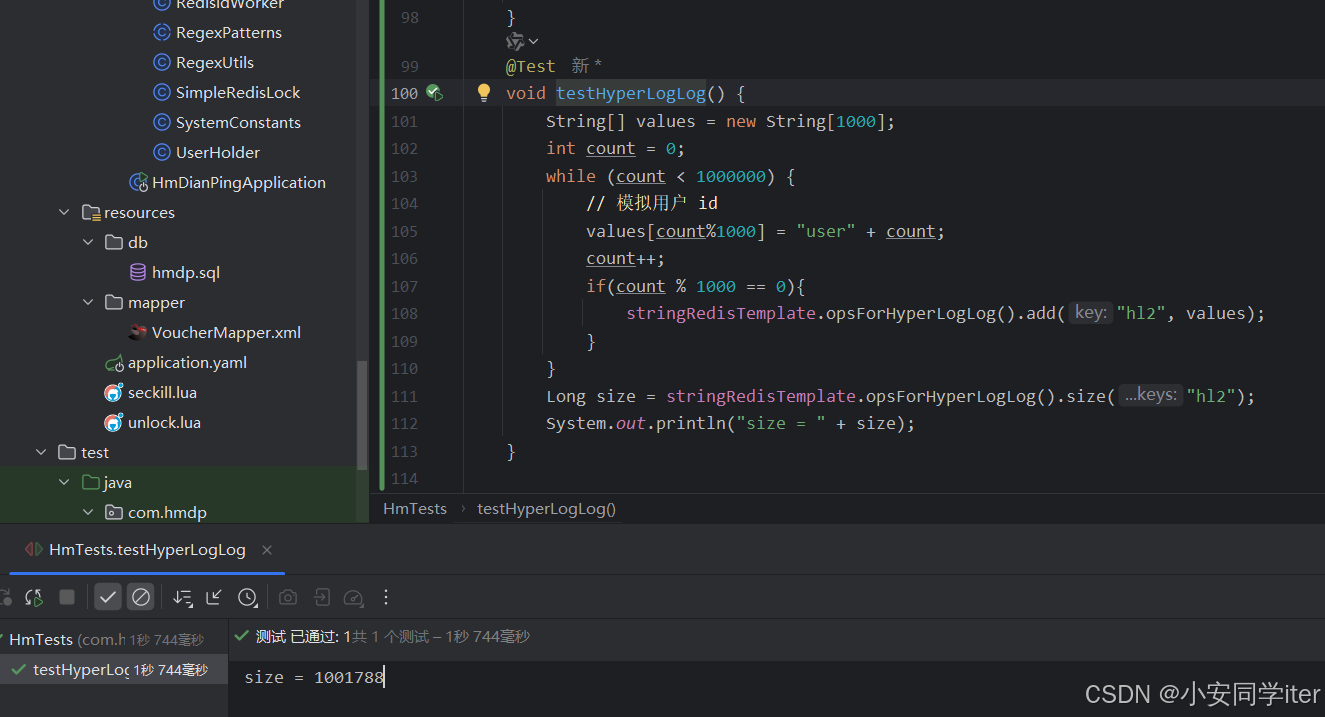
实现结果: