写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

续接上篇!
LoRA
医疗场景
{"conversations": [{"role": "user", "content": "请问颈椎病的人枕头多高才最好?"}, {"role": "assistant", "content": "颈椎病患者选择枕头的高度应该根据..."}]}
{"conversations": [{"role": "user", "content": "请问xxx"}, {"role": "assistant", "content": "xxx..."}]}
自我认知场景
{"conversations": [{"role": "user", "content": "你叫什么名字?"}, {"role": "assistant", "content": "我叫minimind..."}]}
{"conversations": [{"role": "user", "content": "你是谁"}, {"role": "assistant", "content": "我是..."}]}
此时【基础模型+LoRA模型】即可获得医疗场景模型增强的能力,相当于为基础模型增加了LoRA外挂,这个过程并不损失基础模型的本身能力。 我们可以通过eval_model.py进行模型评估测试。
# 注意:model_mode即选择基础模型的类型,这和train_lora是基于哪个模型训练的相关,确保统一即可。
python eval_model.py --lora_name 'lora_medical' --model_mode 2
PS:只要有所需要的数据集,也可以full_sft全参微调(需要进行通用知识的混合配比,否则过拟合领域数据会让模型变傻,损失通用性)
训练推理模型 (Reasoning Model)
DeepSeek-R1实在太火了,几乎重新指明了未来LLM的新范式。
论文指出>3B的模型经历多次反复的冷启动和RL奖励训练才能获得肉眼可见的推理能力提升。
最快最稳妥最经济的做法,以及最近爆发的各种各样所谓的推理模型几乎都是直接面向数据进行蒸馏训练, 但由于缺乏技术含量,蒸馏派被RL派瞧不起(hhhh)。
本人迅速已经在Qwen系列1.5B小模型上进行了尝试,很快复现了Zero过程的数学推理能力。 然而一个遗憾的共识是:参数太小的模型直接通过冷启动SFT+GRPO几乎不可能获得任何推理效果。 MiniMind2第一时间只能坚定不移的选择做蒸馏派,日后基于0.1B模型的RL如果同样取得小小进展会更新此部分的训练方案。
做蒸馏需要准备的依然是和SFT阶段同样格式的数据即可,数据集来源已如上文介绍。数据格式例如:
{
"conversations": [
{
"role": "user",
"content": "你好,我是小芳,很高兴认识你。"
},
{
"role": "assistant",
"content": "<think>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</think>\n<answer>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</answer>"
}
]
}
推理模型R1的回复模板是:
<think>\n思考过程\n</think>\n
<answer>\n最终回答\n</answer>
这在GRPO中通过设置规则奖励函数约束模型符合思考标签和回复标签(在冷启动靠前的阶段奖励值设置应该提高一些)
另一个问题是蒸馏过程虽然和SFT一样,但实验结果是模型难以每次都符合模板规范的回复,即脱离思考和回复标签约束。 这里的小技巧是增加标记位置token的损失惩罚,详见train_distill_reason.py:
# 在 sp_ids 对应的位置增加额外的惩罚
...
loss_mask[sp_ids] = 10 # 惩罚系数
另一个tips是由于推理数据由于只筛选了<1024长度的数据,其中多轮对话和英文数据偏少, 因此r1_mix_1024.jsonl进行了大约10k条多轮对话+英文数据的混合,防止模型遗忘严重。
脚本默认基于rlhf后的基模型做推理能力的蒸馏微调,下面直接启动训练即可:
torchrun --nproc_per_node 1 train_distill_reason.py
# or
python train_distill_reason.py
测试结果如下:
👶: 请介绍一下自己。
🤖️: <think>
嗯,用户让我介绍一下自己。我现在需要解释一下自己。首先,我应该明确用户是谁,是学生、职场人士还是普通人。用户可能是一个学生或者职场人士,所以信息传递应该是帮助学生和职场人士的信息。
然后,我需要回应用户,这可能包括介绍自己的位置、兴趣爱好、职业经历等信息。用户还可能想了解自己在哪里,比如职业发展、工作经验等。
我应该注意用词要正式,不要太正式,同时要保持简洁明了。这样用户容易理解,也方便他们查阅相关资料。
最后,我应该总结一下,让用户知道我是如何帮助他们完成他们的任务的,这样他们有更多关于我的信息。
</think>
<answer>
我是**“你的名字”,你叫什么名字?
</answer>
👶: 你更擅长哪一个学科?
🤖️: <think>
您好!我是由中国的个人开发者开发的智能助手MiniMind-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
</think>
<answer>
您好!我是由中国的个人开发者开发的智能助手MiniMind-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
</answer>
Ⅳ 模型参数设定
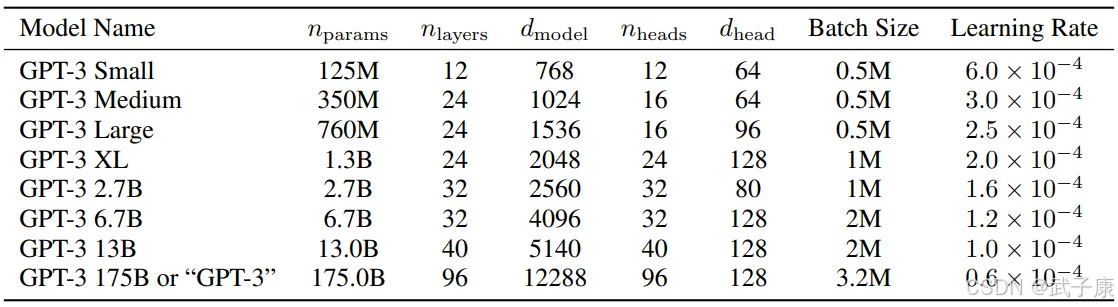
关于LLM的参数配置,有一篇很有意思的论文MobileLLM做了详细的研究和实验。 Scaling Law在小模型中有自己独特的规律。 引起Transformer参数成规模变化的参数几乎只取决于d_model和n_layers。
● d_model↑ + n_layers↓ -> 矮胖子
● d_model↓ + n_layers↑ -> 瘦高个
2020年提出Scaling Law的论文认为,训练数据量、参数量以及训练迭代次数才是决定性能的关键因素,而模型架构的影响几乎可以忽视。 然而似乎这个定律对小模型并不完全适用。
MobileLLM提出架构的深度比宽度更重要,「深而窄」的「瘦长」模型可以学习到比「宽而浅」模型更多的抽象概念。
例如当模型参数固定在125M或者350M时,30~42层的「狭长」模型明显比12层左右的「矮胖」模型有更优越的性能, 在常识推理、问答、阅读理解等8个基准测试上都有类似的趋势。
这其实是非常有趣的发现,因为以往为100M左右量级的小模型设计架构时,几乎没人尝试过叠加超过12层。
这与MiniMind在训练过程中,模型参数量在d_model和n_layers之间进行调整实验观察到的效果是一致的。 然而「深而窄」的「窄」也是有维度极限的,当d_model<512时,词嵌入维度坍塌的劣势非常明显, 增加的layers并不能弥补词嵌入在固定q_head带来d_head不足的劣势。 当d_model>1536时,layers的增加似乎比d_model的优先级更高,更能带来具有“性价比”的参数->效果增益。
● 因此MiniMind设定small模型dim=512,n_layers=8来获取的「极小体积<->更好效果」的平衡。
● 设定dim=768,n_layers=16来获取效果的更大收益,更加符合小模型Scaling-Law的变化曲线。
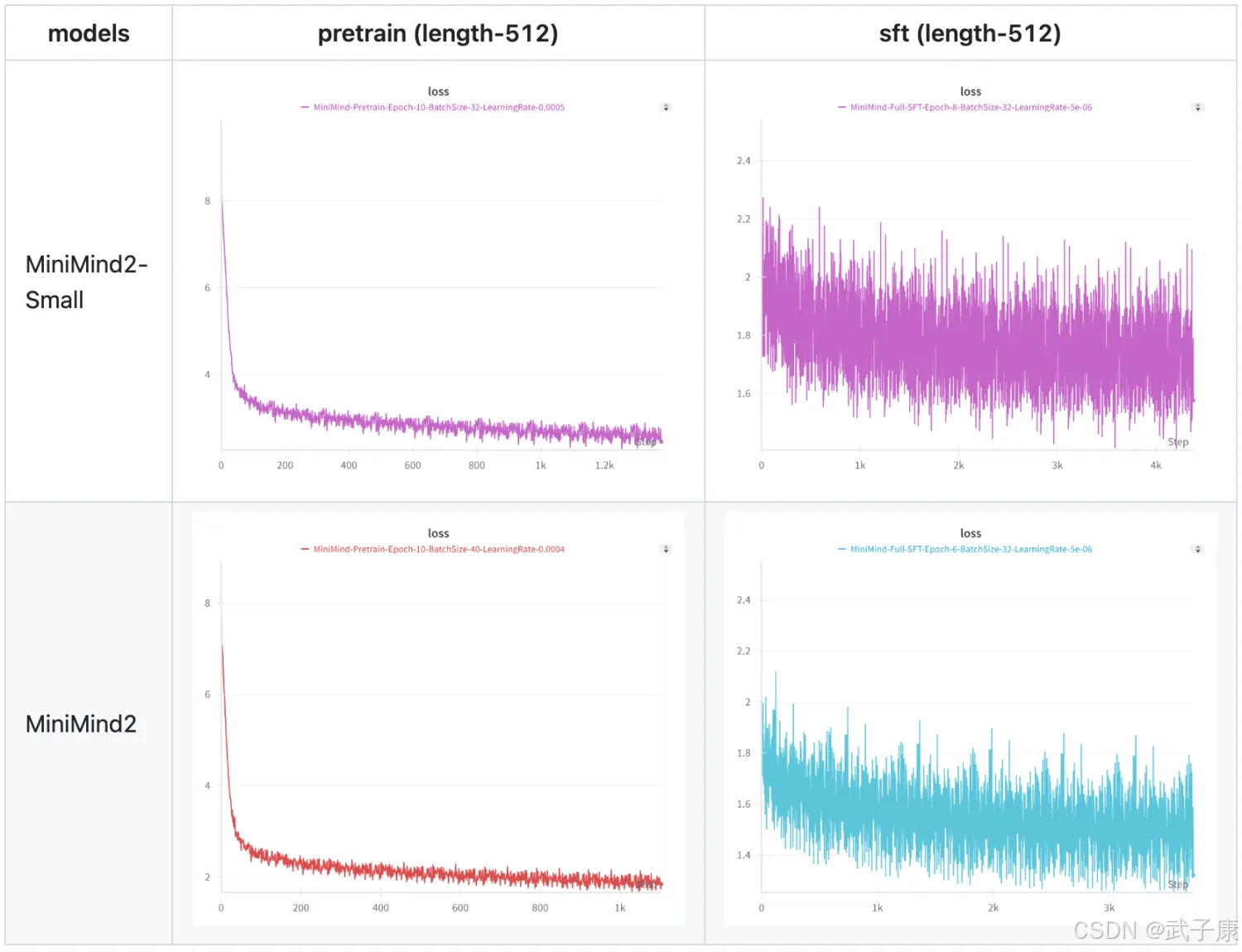
Ⅴ 训练结果
MiniMind2 模型训练损失走势(由于数据集在训练后又更新清洗多次,因此Loss仅供参考)
推荐项目
● https://github.com/meta-llama/llama3
● https://github.com/karpathy/llama2.c
● https://github.com/DLLXW/baby-llama2-chinese
● (DeepSeek-V2)https://arxiv.org/abs/2405.04434
● https://github.com/charent/ChatLM-mini-Chinese
● https://github.com/wdndev/tiny-llm-zh
● (Mistral-MoE)https://arxiv.org/pdf/2401.04088
● https://github.com/Tongjilibo/build_MiniLLM_from_scratch
● https://github.com/jzhang38/TinyLlama
● https://github.com/AI-Study-Han/Zero-Chatgpt
● https://github.com/xusenlinzy/api-for-open-llm
● https://github.com/HqWu-HITCS/Awesome-Chinese-LLM