基于moonshot模型的Dify大语言模型应用开发核心场景学习总结
一、Dify环境部署
1.Docker环境部署
这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机
安装完成之后,修改vagrant配置文件的网络,保证本地与虚拟机网络连通
在centos7上部署dokcer环境
1、卸载系统之前的 docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2、安装必须的依赖 Docker-CE
启用 EPEL 源
Extra Packages for Enterprise Linux(EPEL)源包含了许多额外的软件包,可能会包含你需要的软件包。你可以通过以下命令安装 EPEL 源:
sudo yum install -y epel-release
sudo yum install -y yum-utils \ device-mapper-persistent-data \ lvm2
3、设置 docker repo 的 yum 位置
阿里云镜像
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4、安装 docker 以及 docker-cli
sudo yum install docker-ce docker-ce-cli containerd.io
5、启动 docker
sudo systemctl start docker
6、设置 docker 开机自启
sudo systemctl enable docker
bug:安装docker时显示空间不足
解决办法:在VirtualBox界面右键删除centos7所有数据,重新安装即可
安装docker时空间不足的问题,去VirtualBox里面删除centos7,从新安装就行了,而且必须使用阿里云镜像
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
其他步骤都一样,第一此我装cenos7直接占了40G硬盘,卸载后第二次装才正常只占5G硬盘
第二次装centos7的时候先要删除pc目录下的Vagrantfile文件,然后再执行vagrant init centos/7
完成之后记得改Vagrantfile文件的配置地址config.vm.network “private_network”, ip: “192.168.56.10”
2.Centos7安装dify
在docker安装git,配置pub公钥至github
如果git无法下载,临时忽略 SSL 验证
git config --global http.sslVerify false
下载完后恢复 SSL 验证
git config --global http.sslVerify true
如果出现类似Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 的错误,说明镜像源网站不可用,需要更换镜像源网址
sudo vi /etc/docker/daemon.json
填入
{
"registry-mirrors":[
"https://docker-0.unsee.tech",
"https://docker.imgdb.de",
"https://docker.h1mirror.com"
]
}
当Dify版本更新后,你可以克隆或拉取最新的Dify源代码,并通过命令行更新已经部署的Dify环境。
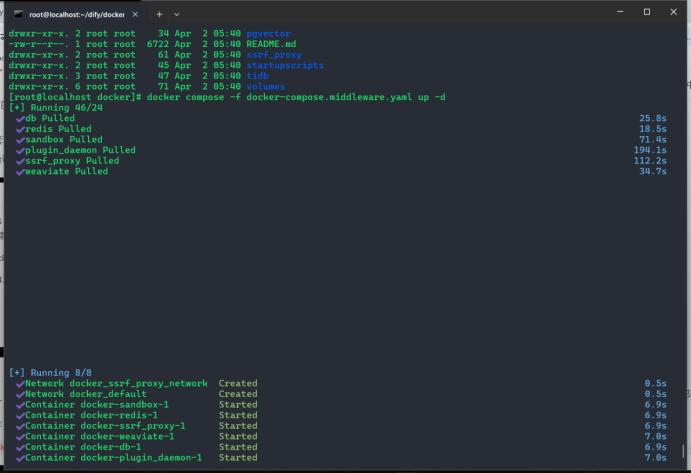
进入dify源代码的docker目录,按顺序执行以下命令:
更新dify,如过更新了.env配置文件需同步至复制的配置文件
cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d
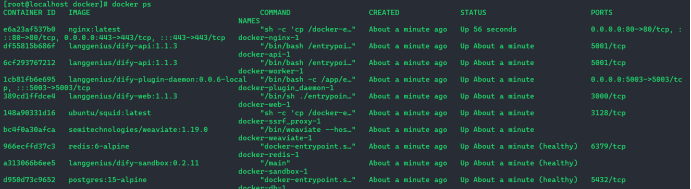
docker compose ps 查看已运行服务

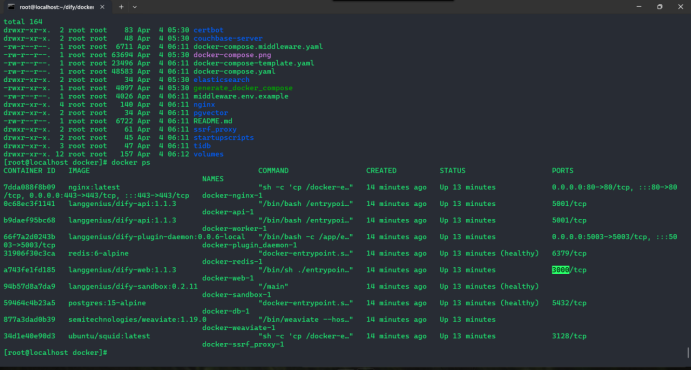
3.Dify compose环境验证
3.1 Dify调试命令
#停止容器下所有服务
docker compose stop
cd /root/dify/docker
#启动
docker compose start
#停止并移除
docker compose down
#安装并启动
docker compose up -d

3.2 502Gateway问题
安装完成后访问首页,本地vagrant服务器ip为192.168.56.10,访问dify注册地址:http://192.168.56.10/install,出现一直加载的问题,始终无法访问,最后使用卸载、重装、更新等操作,在次访问还是同样的问题,最后等待了一会就可以成功访问了,可能是dify在下载相关查询或者是nginx转发ip的问题
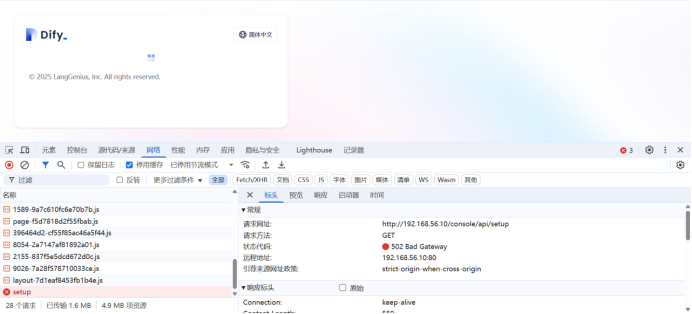
http://192.168.56.10/console/api/setup
502 Bad Gateway
3.3 修改nginx服务配置
通过下列命令获取api-1、web-1服务的ip,将新的ip更新至nginx配置文件中
docker ps -q | xargs -n 1 docker inspect --format '{{ .Name }}: {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'

/docker-api-1: 172.18.0.8172.19.0.5
/docker-web-1: 172.18.0.5
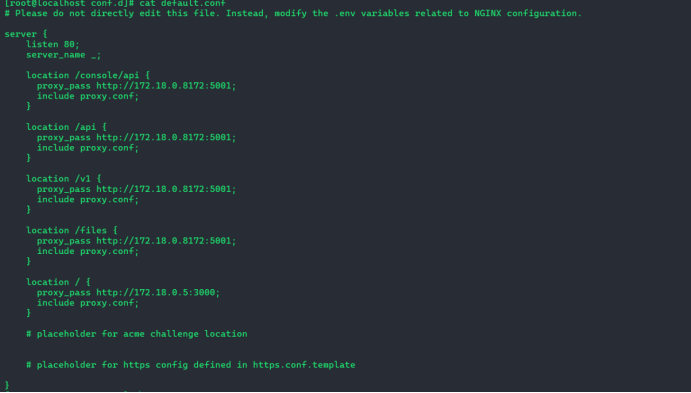
docker inspect --format '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' docker-api-1
172.18.0.9172.19.0.4
docker inspect --format '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' docker-web-1
}
172.18.0.3
#重启nginx
docker compose restart nginx
3.4 启动Dify
更新nginx配置无效,重装dify即可,若还是访问一直在加载,就多等待一会
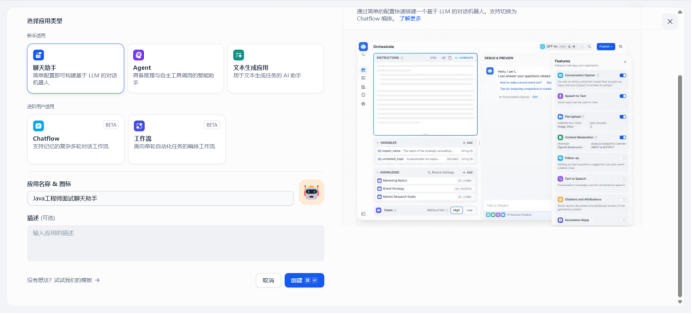
二、Dify学习
- 聊天助⼿Demo:创建基于知识库的问答机器⼈,⽀持PDF⽂档检索
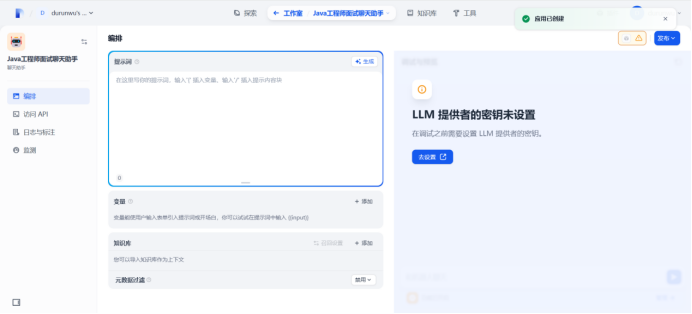
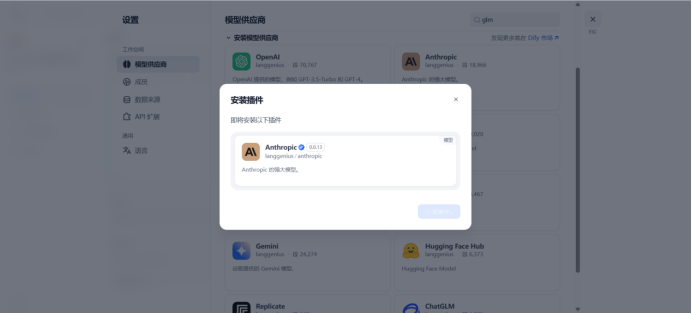
获取api key
Api-key在kimi月之暗面上新建
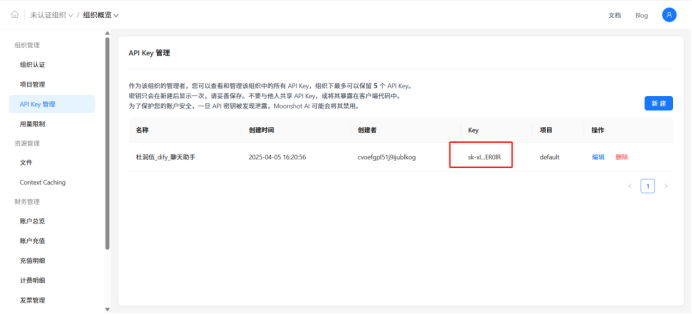
Api-base:https://api.moonshot.cn/v1
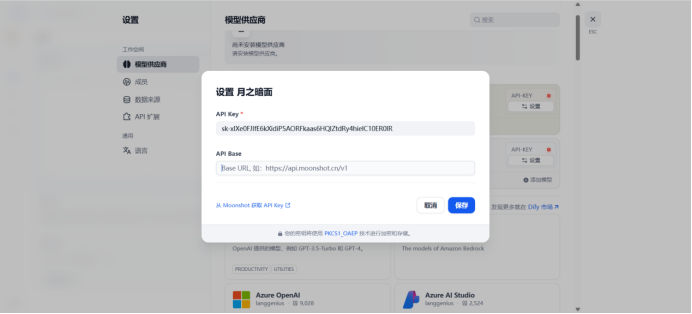
设置成功
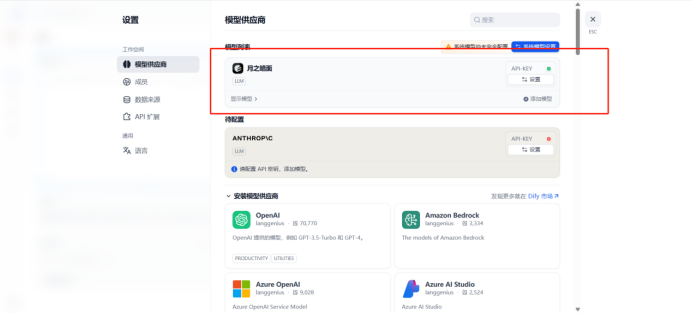
给聊天助手配置大模型
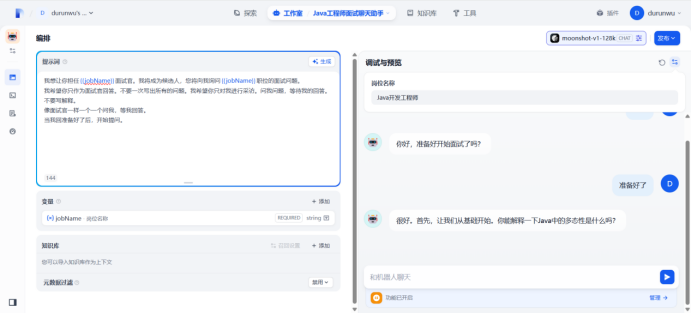
提示词编写完成之后,点击发布
点击重新开始
开始聊天
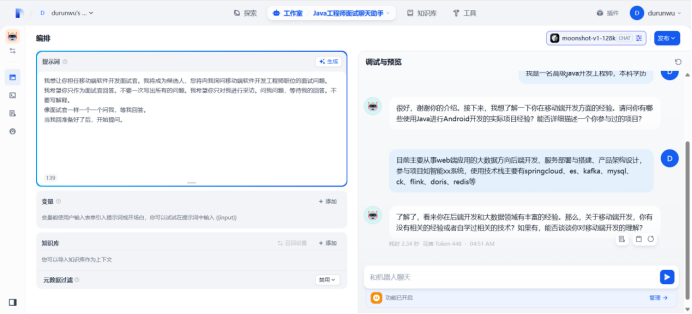
使用变量
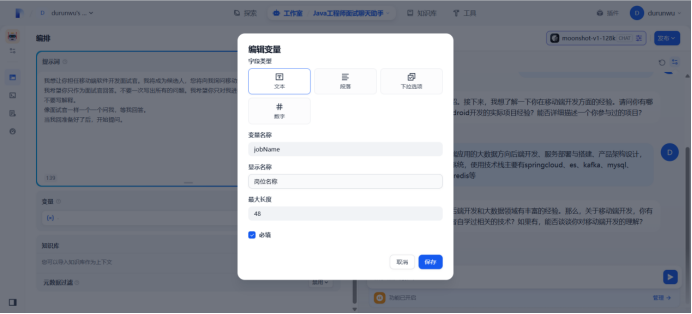
在提示词中输入“/”导入变量,然后替换所有变量
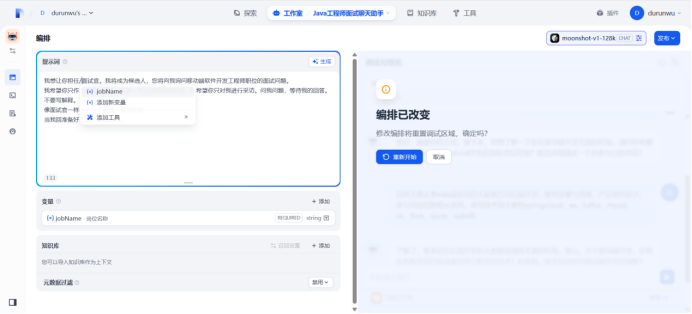
刷新
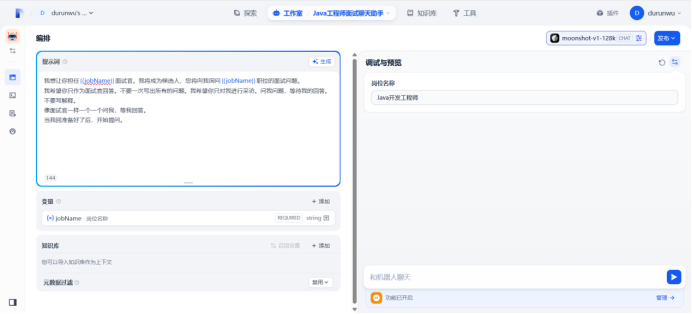
开始提问
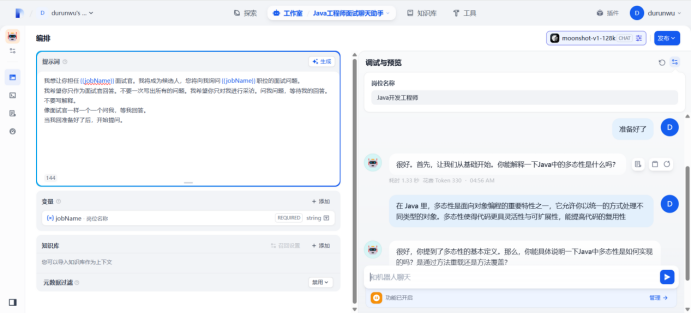
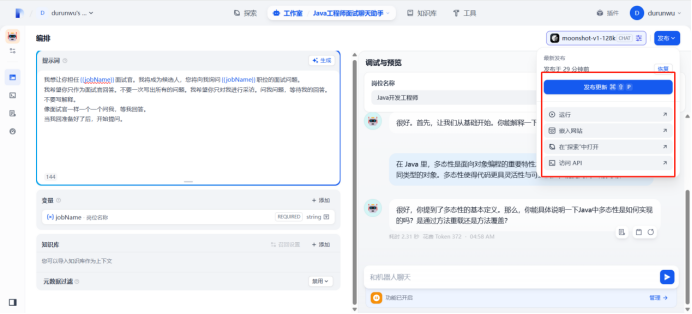
通过上述操作,可以实现智能面试大模型,可以嵌入网站、并且可以提供访问API等
使用ai生成知识库文档,导入文档至机器人
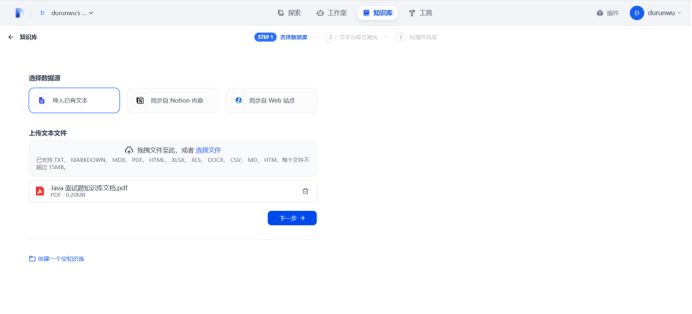
预览
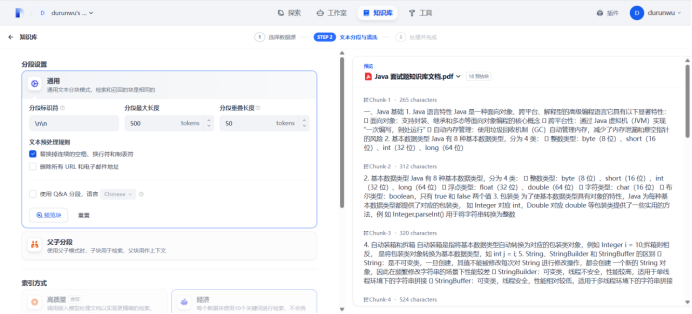
将创建的知识库,导入给聊天机器人
开始提问,基于知识库中的元数据标签提出问题,机器人回答知识库中标签对应的答案

- Agent Demo:开发调⽤天⽓API的智能体,实现动态数据获取。
创建心知天气账号
创建免费API KEY
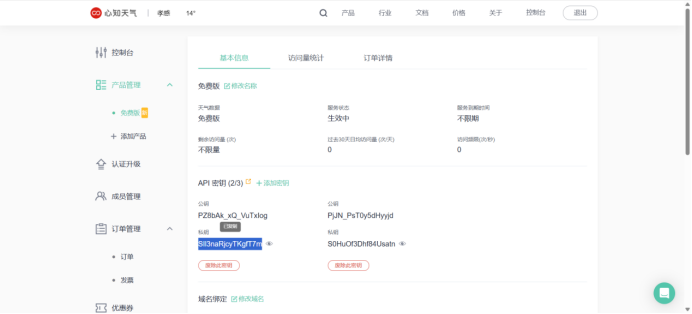
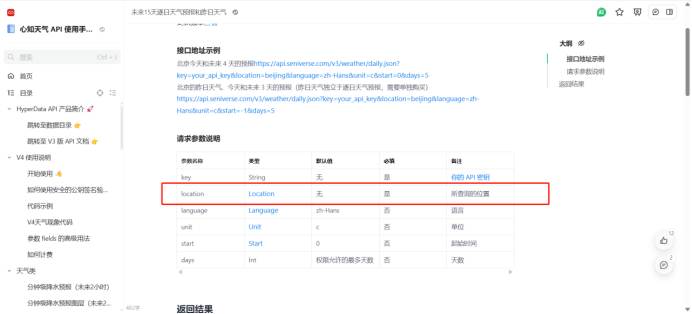
使用账号API KEY拼接API
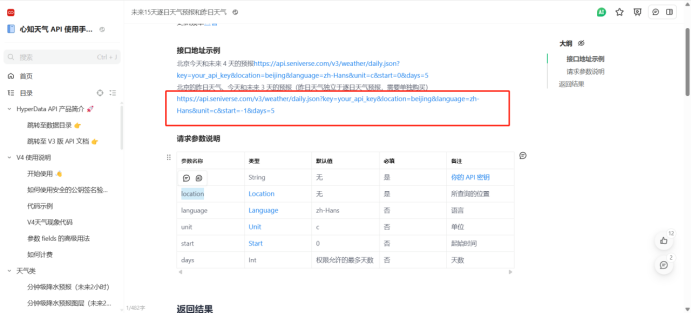
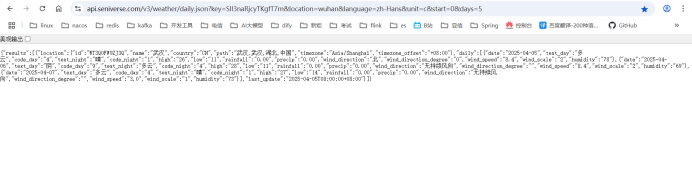
https://api.seniverse.com/v3/weather/daily.json?key=SIl3naRjcyTKgfT7m&location=wuhan&language=zh-Hans&unit=c&start=0&days=5
API参数定义
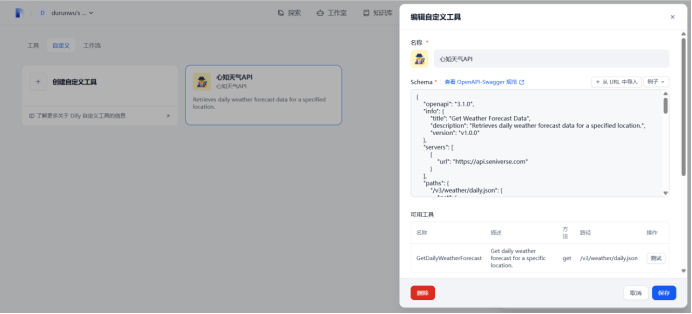
创建自定义工具
使用ai生成OPen API Schema
{ "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": { "results": { "type": "array", "items": { "type": "object", "properties": { "location": { "type": "object", "properties": { "id": { "type": "string" }, "name": { "type": "string" }, "country": { "type": "string" }, "path": { "type": "string" }, "timezone": { "type": "string" }, "timezone_offset": { "type": "string" } } , "required": ["id", "name", "country", "path", "timezone", "timezone_offset"] }, "daily": { "type": "array", "items": { "type": "object", "properties": { "date": { "type": "string", "format": "date" }, "text_day": { "type": "string" }, "code_day": { "type": "string" }, "text_night": { "type": "string" }, "code_night": { "type": "string" }, "high": { "type": "string" }, "low": { "type": "string" }, "rainfall": { "type": "string", "pattern": "^[0-9.]+$" }, "precip": { "type": "string", "pattern": "^[0-9.]+$" }, "wind_direction": { "type": "string" }, "wind_direction_degree": { "type": "string" }, "wind_speed": { "type": "string", "pattern": "^[0-9.]+$" }, "wind_scale": { "type": "string", "pattern": "^[0-9]+$" }, "humidity": { "type": "string", "pattern": "^[0-9]+$" } }, "required": ["date", "text_day", "code_day", "text_night", "code_night", "high", "low", "rainfall", "precip", "wind_direction", "wind_speed", "wind_scale", "humidity"] } }, "last_update": { "type": "string", "format": "date-time" } }, "required": ["location", "daily", "last_update"] } } }, "required": ["results"] }
我这里可以优化为只传城市location这一个参数,目前是全量传参
把自定义工具添加到agent的工具中
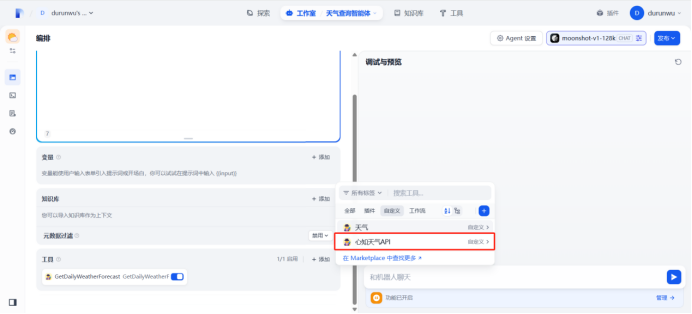
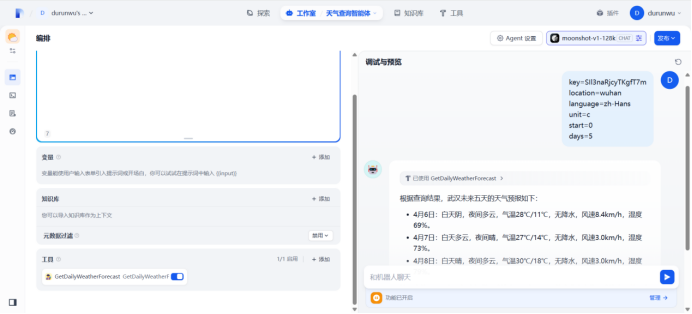
在语言交互阶段,输入参数
测试:武汉天气
API参数:
key=SIl3naRjcyTKgfT7m
location=wuhan
language=zh-Hans
unit=c
start=0
days=5
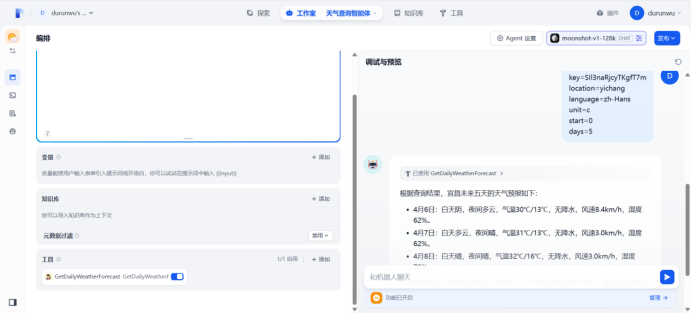
测试:宜昌天气
API参数:
key=SIl3naRjcyTKgfT7m
location=yichang
language=zh-Hans
unit=c
start=0
days=5
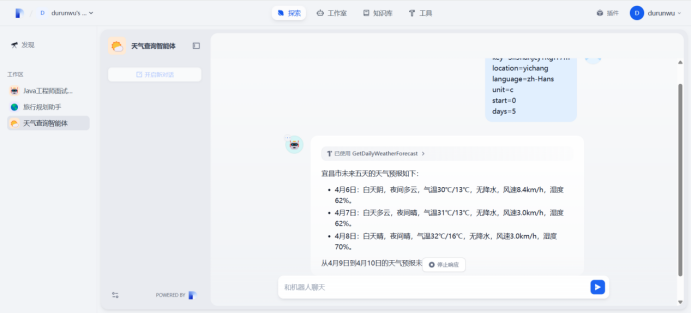
在“探索”中打开,这里动态数据获取完成,只需要传入不同的查询参数,比如location所查询的位置传入需要查询的城市即可返回当前城市的天气信息,实现了动态传参查询的效果,这里的天气查询API可以使用现有的天气网址提供,也可以延申一下,将自己开发的API提供给Dify,灵活的在Dify的业务中使用。
- Chatflow Demo:设计多轮对话流程(如⽤户身份验证→需求收集→服务推荐)
1.Dify工作流分为两种类型:
(1)Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
(2)Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
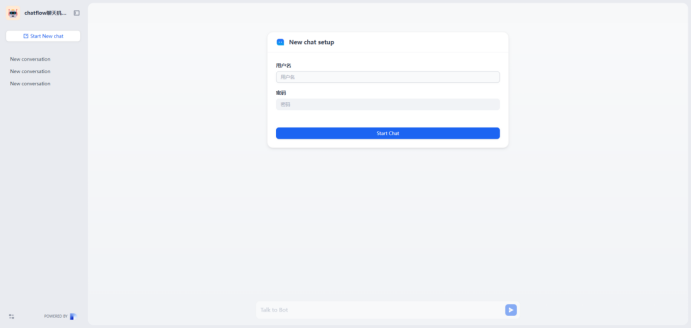
2.用户身份验证→需求收集→服务推荐的多轮对话流程。
(1)用户身份验证:用户输入用户名和密码,程序通过authenticate_user函数检查输入的信息是否与模拟的用户数据库匹配,验证用户身份。
(2)需求收集:身份验证成功后,通过collect_requirements函数与用户进行多轮对话,收集用户的需求信息,用户可以输入多个需求类型及其具体内容,输入done结束需求输入。
(3)服务推荐:根据收集到的用户需求,通过recommend_services函数向用户推荐相应的服务。
创建Chatflow

新增变量
username
password
hobby
定义问题分类器
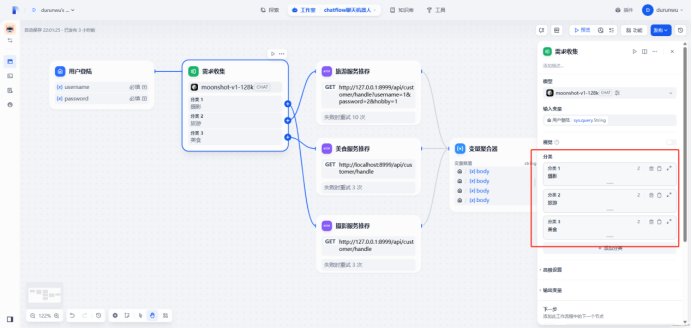
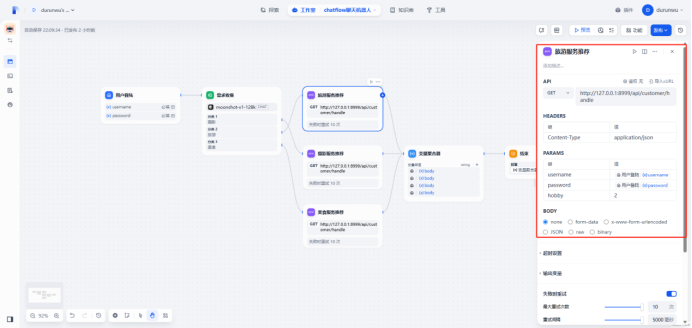
创建http请求模块

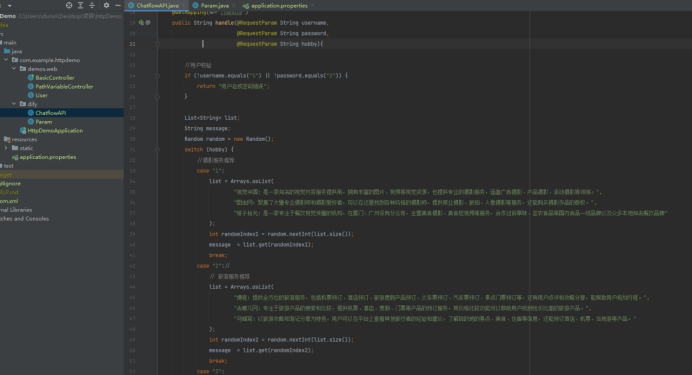
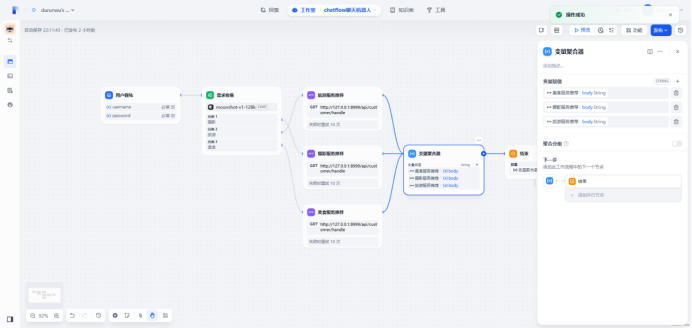
#编写分类API接口
@GetMapping("/handle")
public String handle(@RequestParam String username,
@RequestParam String password,
@RequestParam String hobby){
//用户校验
if (!username.equals("1") || !password.equals("2")) {
return "用户名或密码错误";
}
List<String> list;
String message;
Random random = new Random();
switch (hobby) {
//摄影服务推荐
case "1":
list = Arrays.asList(
"视觉中国:是一家知名的视觉内容服务提供商,拥有丰富的图片、视频等视觉资源,也提供专业的摄影服务,涵盖广告摄影、产品摄影、活动摄影等领域。",
"图虫网:聚集了大量专业摄影师和摄影爱好者,可以在这里找到各种风格的摄影师,提供商业摄影、旅拍、人像摄影等服务,还能购买摄影作品的版权。",
"桔子拾光:是一家专注于餐饮视觉传播的机构,在厦门、广州设有分公司,主营美食摄影、美食短视频等服务,合作过百草味、圣农食品等国内食品一线品牌以及众多本地知名餐饮品牌"
);
int randomIndex1 = random.nextInt(list.size());
message = list.get(randomIndex1);
break;
case "2"://
// 旅游服务推荐
list = Arrays.asList(
"携程:提供全方位的旅游服务,包括机票预订、酒店预订、旅游度假产品预订、火车票预订、汽车票预订、景点门票预订等,还有用户点评和攻略分享,能帮助用户规划行程。",
"去哪儿网:专注于旅游产品的搜索和比较,提供机票、酒店、度假、门票等产品的预订服务,其价格比较功能可以帮助用户找到性价比高的旅游产品。",
"马蜂窝:以旅游攻略和游记分享为特色,用户可以在平台上查看其他旅行者的经验和建议,了解目的地的景点、美食、住宿等信息,还能预订酒店、机票、当地游等产品。"
);
int randomIndex2 = random.nextInt(list.size());
message = list.get(randomIndex2);
break;
case "3":
//美食服务推荐
list = Arrays.asList(
"舌尖上的美食地图:集美食推荐、点评、交流于一体的附近美食推荐平台,覆盖全国众多城市和县区,通过权威推荐和用户真实点评,帮助用户发现身边的特色美食和品质餐厅。",
"大众点评:是一个生活消费点评平台,提供美食、酒店、购物、休闲娱乐等各类商家的信息和用户点评,用户可以根据评分、评价、距离等筛选餐厅,还能查看餐厅的菜单、地址、电话等详细信息。",
"小红书:虽然不是专门的美食推荐平台,但有大量的美食博主分享美食探店、美食制作、地方特色美食等内容,用户可以通过搜索关键词或浏览相关话题,发现各种美食推荐和美食攻略。"
);
int randomIndex3 = random.nextInt(list.size());
message = list.get(randomIndex3);
break;
default:
//发送至默认客户支持邮箱
message = "已发送至默认客户支持邮箱";
break;
}
return message;
}
定义变量聚合器,将所有请求接口的响应返回到这里
定义结束节点收纳变量聚合器的返回,结束节点变量为output(变量聚合器输出)
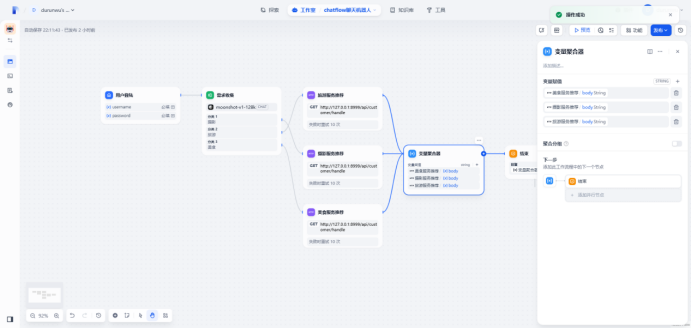
输入用户名和密码开始交互,用户输入”摄影“,会根据用户需求通过收集器进行分类,然后传入类型参数(hobby :摄影=1,旅游=2,美食=3),开始http请,首先API接口会校验账号和密码,如果校验失败会返回”用户名或密码错误”,如果校验通过,根据类型像API传入不同的参数
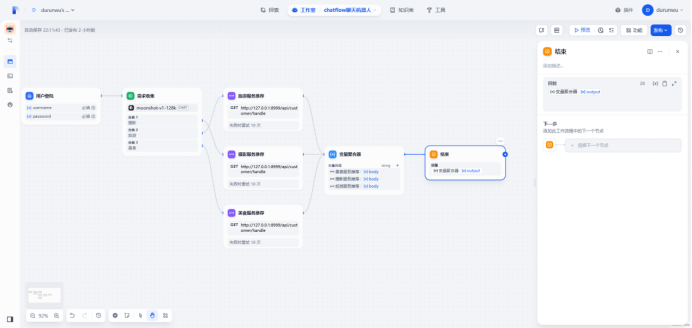
流程如下:
通过下面可知,需求收集器根据用户的输入自动分类为”摄影”,然后去触发摄影接口
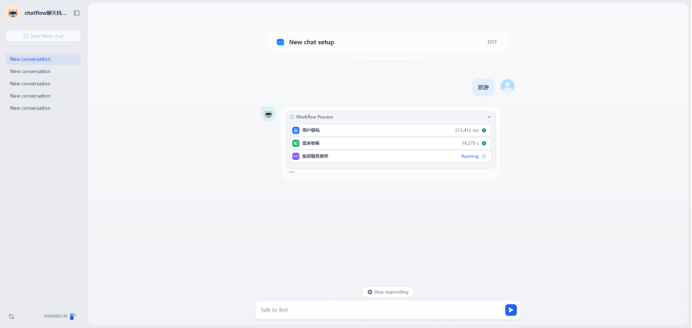
响应结果:
"桔子拾光:是一家专注于餐饮视觉传播的机构,在厦门、广州设有分公司,主营美食摄影、美食短视频等服务,合作过百草味、圣农食品等国内食品一线品牌以及众多本地知名餐饮品牌
- ⼯作流Demo:构建⾃动化文章⽣成流程(LLM提示词生成章节→章节json解析&格式转换→迭代节点生成完整文章)
创建工作流
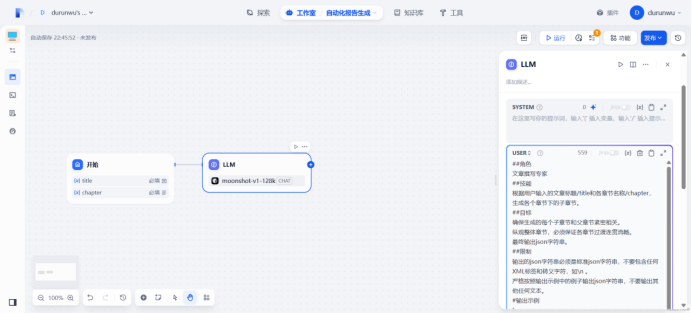
使用ai生成提示词
##角色 文章撰写专家
##技能 根据用户输入的文章标题 /title 和各章节名称 /chapter,生成各个章节下的子章节。
##目标 确保生成的每个子章节和父章节紧密相关。 纵观整体章节,必须保证各章节过渡连贯流畅。 最终输出 json 字符串。
##限制 输出的 json 字符串必须是标准 json 字符串,不要包含任何 XML 标签和转义字符,如\n 。 严格按照输出示例中的例子输出 json 字符串,不要输出其他任何文本。
#输出示例 [ { “chapter”: “引言”, “subchapter”: “1. 气候变化对沿海城市影响的概述 2. 理解这些影响的重要性 3. 研究范围与方法简述” }, { “chapter”: “气候变化对沿海城市的具体影响”,
“subchapter”: “1. 海平面上升引发的洪水风险 2. 极端天气事件频率增加的冲击 3. 海洋生态变化对渔业的影响” }, {
“chapter”: “应对策略与措施”, “subchapter”: “1. 基础设施加固与防洪工程建设 2. 生态保护与修复举措 3.
城市规划中的气候适应性调整” }, { “chapter”: “结论”, “subchapter”: “1.
总结气候变化对沿海城市影响的关键要点 2. 展望未来沿海城市应对的方向 3. 强调跨部门合作的必要性” } ]
将提示词填入user处
嵌入提示词变量
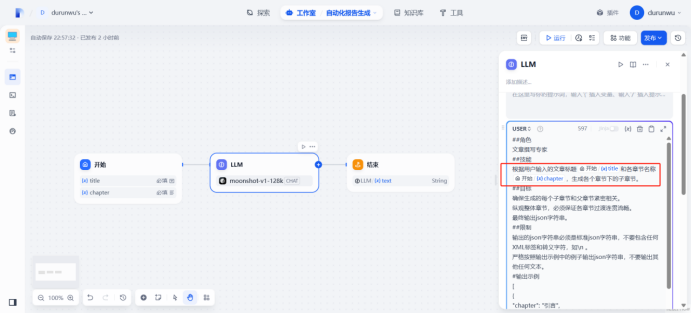
验证LLM
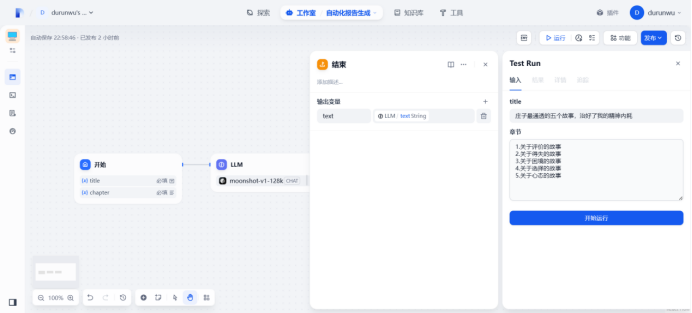
生成成功
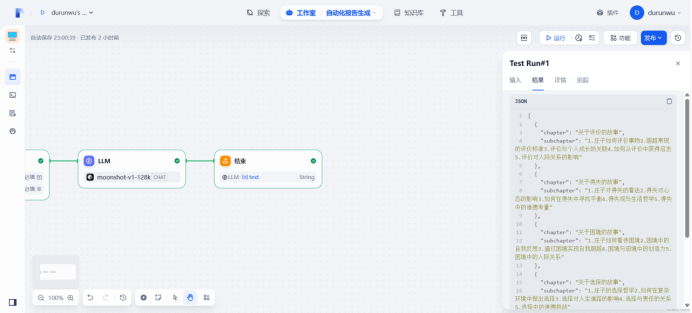
[ { “chapter”: “关于评价的故事”, “subchapter”:
“1.庄子如何评价事物2.超越常规的评价标准3.评价与个人成长的关联4.如何从评价中获得启发5.评价对人际关系的影响” }, {
“chapter”: “关于得失的故事”, “subchapter”:
“1.庄子对得失的看法2.得失对心态的影响3.如何在得失中寻找平衡4.得失观与生活哲学5.得失中的道德考量” }, { “chapter”:
“关于困境的故事”, “subchapter”:
“1.庄子如何看待困境2.困境中的自我反思3.通过困境实现自我超越4.困境与逆境中的创造力5.困境中的人际关系” }, {
“chapter”: “关于选择的故事”, “subchapter”:
“1.庄子的选择哲学2.如何在复杂环境中做出选择3.选择对人生道路的影响4.选择与责任的关系5.选择中的道德挑战” }, {
“chapter”: “关于心态的故事”, “subchapter”:
“1.庄子的心境观2.心态对生活质量的影响3.如何在变化中保持平和心态4.心态与幸福感的关系5.心态的修炼与提升” } ]
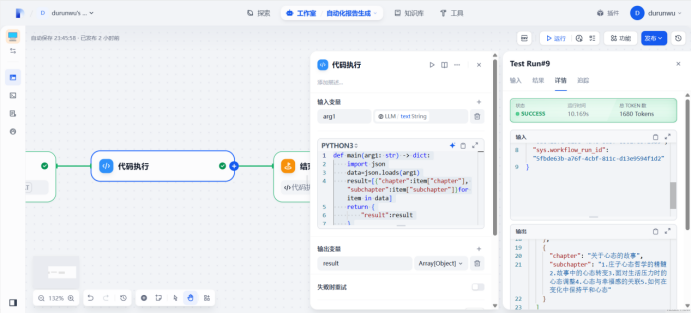
Json格式转换,并将text文本类型转换为object数组进行输出
def main(arg1: str) -> dict:
import json
data=json.loads(arg1)
result=[{"chapter":item["chapter"], "subchapter":item["subchapter"]}for item in data]
return {
"result":result
}
迭代节点
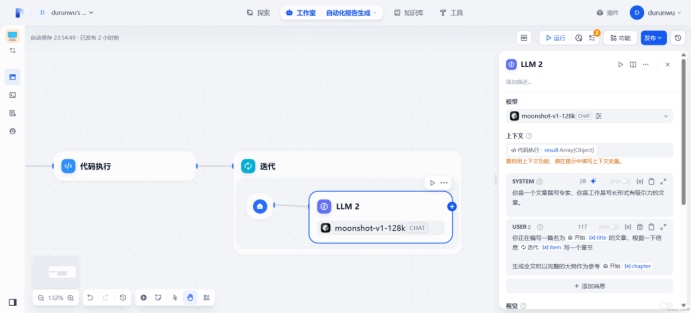
提示词:
system:
你是一个文章撰写专家,你是工作是写长形式有吸引力的文章。
user:
你正在编写一篇名为/title的文章,根据一下信息/item写一个章节
生成全文时以完整的大纲作为参考/chapter
迭代输入输出
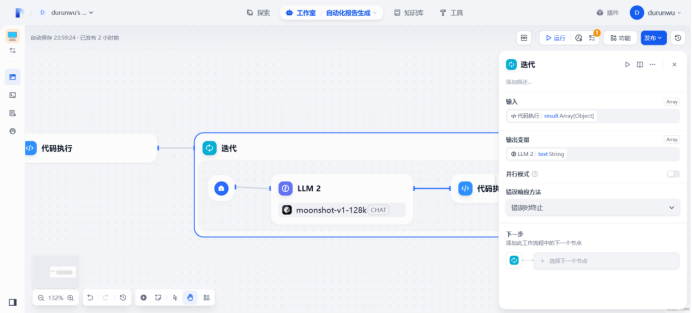
def main(arg1: list):
data = articleSections
return {
“result”: “\n”.join(data)
}
节点编排完成
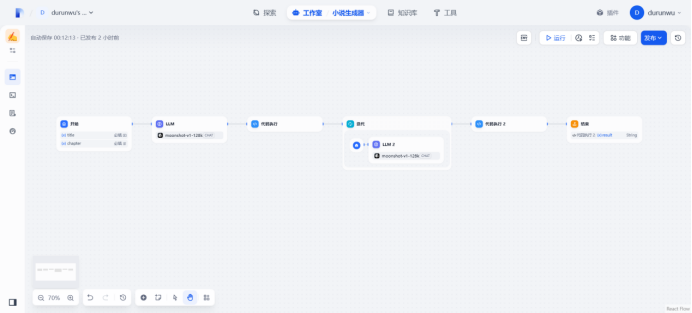
可以使用下列title和标题自动生成小说了!!!
文章标题
武侠修仙:5 个秘籍,开启超凡修行之路
章节
1.关于功法的秘籍
2.关于法宝的秘籍
3.关于奇遇的秘籍
4.关于心境的秘籍
5.关于突破的秘籍
三、主机巡检场景学习
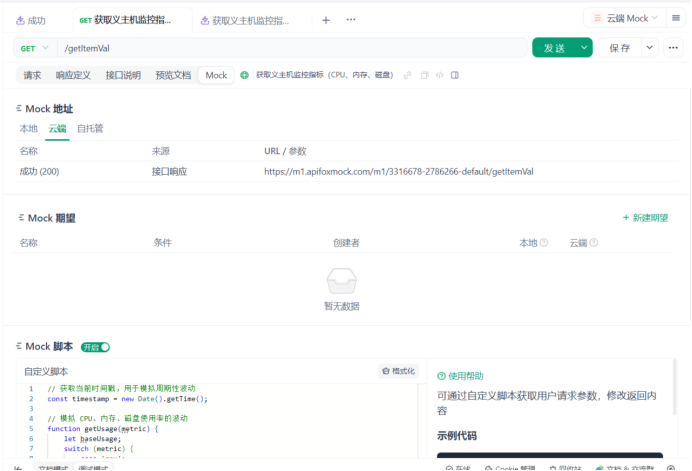
(1)Apifox Mock数据配置
1.创建mock接口
获取义主机监控指标(CPU、内存、磁盘)/getItemVal
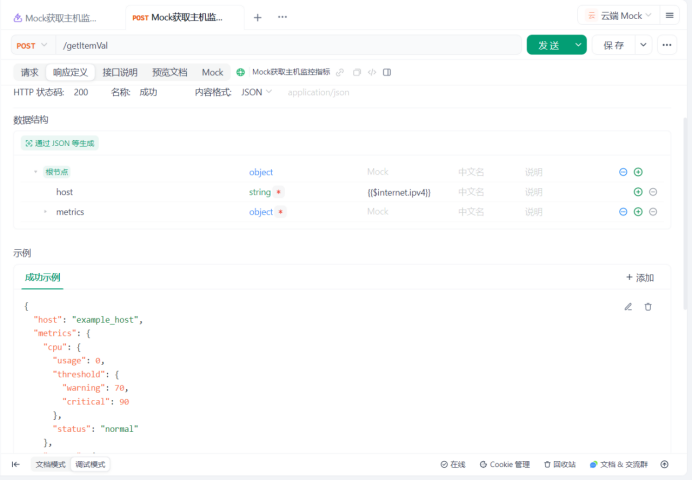
2.定义主机监控指标JSON数据结构
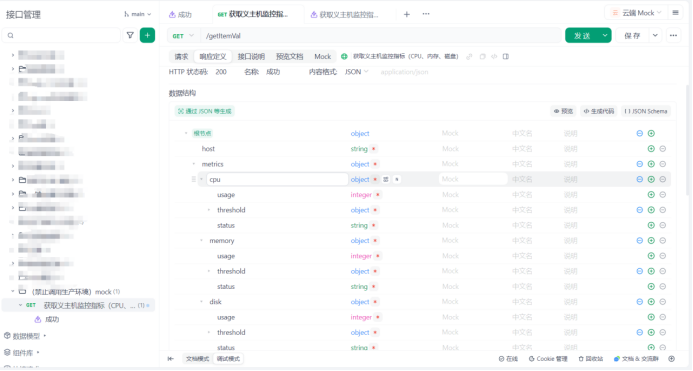
利用率:usage
阈值:threshold
异常:warning
危险:critical
响应定义
{
"host": "example_host",
"metrics": {
"cpu": {
"usage": 20,
"threshold": {
"warning": 70,
"critical": 90
},
"status": "normal"
},
"memory": {
"usage": 94,
"threshold": {
"warning": 80,
"critical": 95
},
"status": "warning"
},
"disk": {
"usage": 99,
"threshold": {
"warning": 85,
"critical": 98
},
"status": "critical"
}
}
}
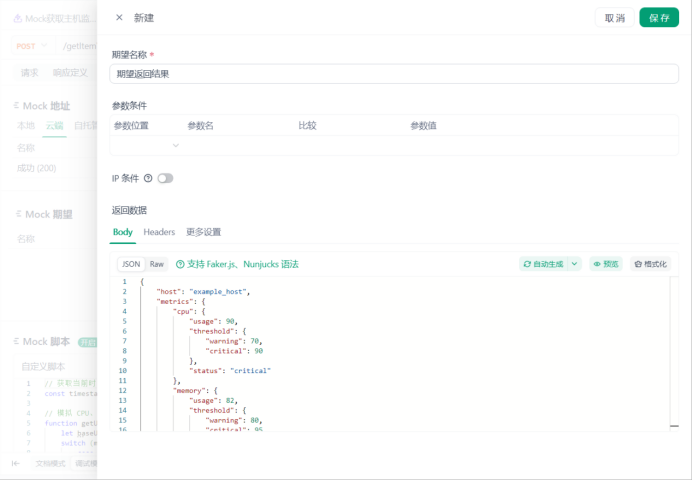
3.定义期望
4.配置Mock脚本
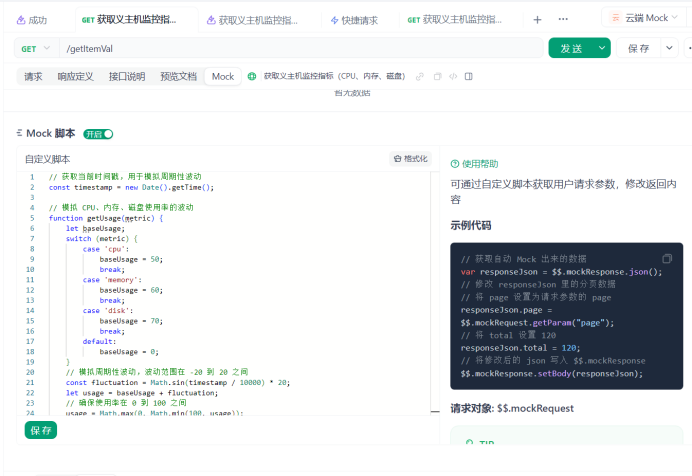
apifox_host_monitoring_mock.js脚本内容如下:
// 获取当前时间戳,用于模拟周期性波动
const timestamp = new Date().getTime();
// 模拟 CPU、内存、磁盘使用率的波动
function getUsage(metric) {
let baseUsage;
switch (metric) {
case 'cpu':
baseUsage = 50;
break;
case 'memory':
baseUsage = 60;
break;
case 'disk':
baseUsage = 70;
break;
default:
baseUsage = 0;
}
// 模拟周期性波动,波动范围在 -20 到 20 之间
const fluctuation = Math.sin(timestamp / 10000) * 20;
let usage = baseUsage + fluctuation;
// 确保使用率在 0 到 100 之间
usage = Math.max(0, Math.min(100, usage));
return usage;
}
// 根据使用率和阈值判断状态
function getStatus(usage, thresholds) {
if (usage >= thresholds.critical) {
return 'critical';
} else if (usage >= thresholds.warning) {
return 'warning';
}
return 'normal';
}
// 生成 Mock 数据
const mockData = {
"host": "example_host",
"metrics": {
"cpu": {
"usage": getUsage('cpu'),
"threshold": {
"warning": 70,
"critical": 90
},
"status": getStatus(getUsage('cpu'), { warning: 70, critical: 90 })
},
"memory": {
"usage": getUsage('memory'),
"threshold": {
"warning": 80,
"critical": 95
},
"status": getStatus(getUsage('memory'), { warning: 80, critical: 95 })
},
"disk": {
"usage": getUsage('disk'),
"threshold": {
"warning": 85,
"critical": 98
},
"status": getStatus(getUsage('disk'), { warning: 85, critical: 98 })
}
}
};
// 返回 Mock 数据
mockData;
运行接口:
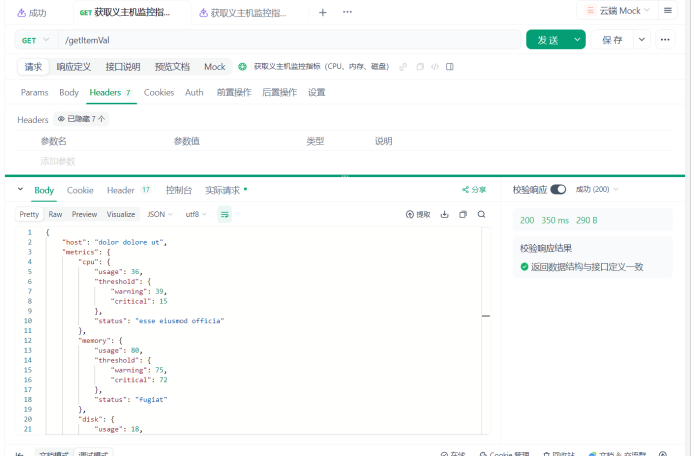
{
"host": "227.41.194.179",
"metrics": {
"cpu": {
"usage": 12,
"threshold": {
"warning": 32,
"critical": 77
},
"status": "veniam quis ut"
},
"memory": {
"usage": 71,
"threshold": {
"warning": 6,
"critical": 37
},
"status": "ex ad ea"
},
"disk": {
"usage": 12,
"threshold": {
"warning": 9,
"critical": 60
},
"status": "laboris fugiat nisi"
}
}
}
5.定义未云端接口,提供外网访问
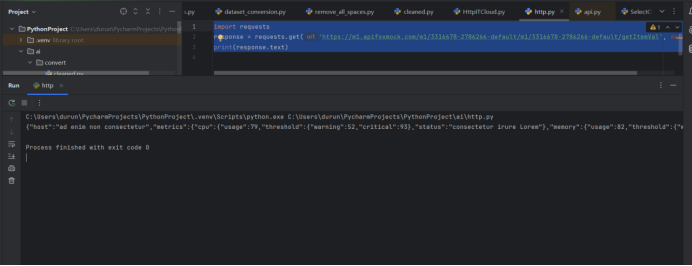
https://m1.apifoxmock.com/m1/3316678-2786266-default/m1/3316678-2786266-default/getItemVal
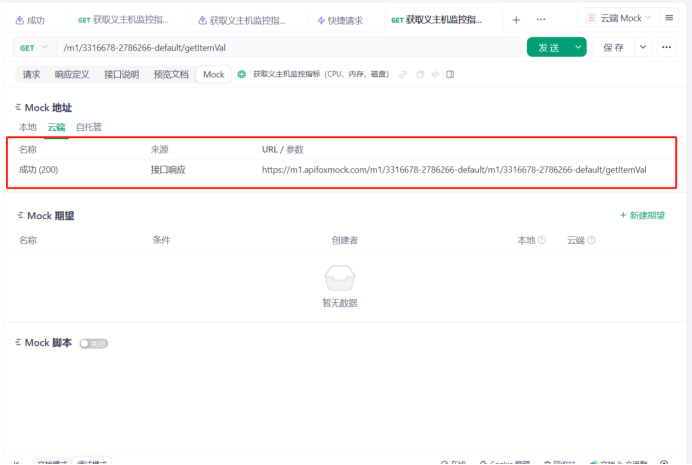
浏览器访问
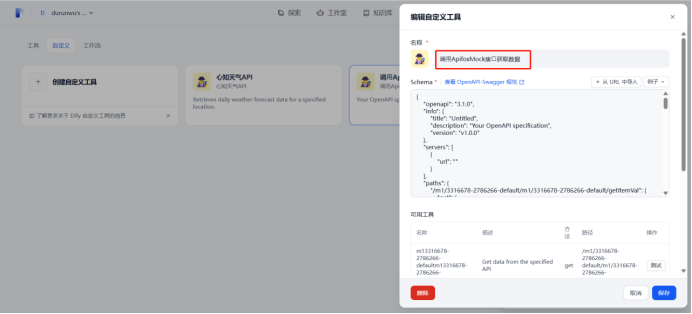
(2)Dify⾃定义⼯具开发
1.创建自定义工具
调⽤ApifoxMock接⼝获取数据
2.使用ai生成JSON Schema
{
"openapi": "3.1.0",
"info": {
"title": "Untitled",
"description": "Your OpenAPI specification",
"version": "v1.0.0"
},
"servers": [
{
"url": ""
}
],
"paths": {
"/m1/3316678-2786266-default/m1/3316678-2786266-default/getItemVal": {
"get": {
"summary": "Get data from the specified API",
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"host": {
"type": "string"
},
"metrics": {
"type": "object",
"properties": {
"cpu": {
"type": "object",
"properties": {
"usage": {
"type": "number"
},
"threshold": {
"type": "object",
"properties": {
"warning": {
"type": "number"
},
"critical": {
"type": "number"
}
},
"required": ["warning", "critical"]
},
"status": {
"type": "string"
}
},
"required": ["usage", "threshold", "status"]
},
"memory": {
"type": "object",
"properties": {
"usage": {
"type": "number"
},
"threshold": {
"type": "object",
"properties": {
"warning": {
"type": "number"
},
"critical": {
"type": "number"
}
},
"required": ["warning", "critical"]
},
"status": {
"type": "string"
}
},
"required": ["usage", "threshold", "status"]
},
"disk": {
"type": "object",
"properties": {
"usage": {
"type": "number"
},
"threshold": {
"type": "object",
"properties": {
"warning": {
"type": "number"
},
"critical": {
"type": "number"
}
},
"required": ["warning", "critical"]
},
"status": {
"type": "string"
}
},
"required": ["usage", "threshold", "status"]
}
},
"required": ["cpu", "memory", "disk"]
}
},
"required": ["host", "metrics"]
}
}
}
}
}
}
}
},
"components": {
"schemas": {}
}
}
2.获取主机监控指标(CPU、内存、磁盘)测试
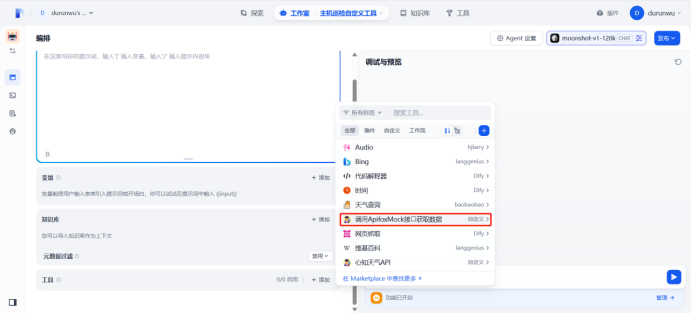
3.编写Python⼯具获取主机监控指标