| 栏目 | 内容 |
|---|---|
| 论文标题 | SayNav: 为新环境中的动态规划到导航进行大型语言模型的基础构建 (SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments) |
| 研究问题 | 自主代理在未知环境中执行复杂导航任务(如MultiON)时,需要大量常识知识和动态规划能力。现有方法(如DRL)训练成本高、泛化能力有限,难以有效应对这类任务。 |
| 核心思想 | 提出SayNav方法,利用大型语言模型(LLM)的常识知识,结合一个在探索过程中增量构建的3D场景图作为LLM的输入和基础(grounding),从而生成可行、上下文合适且动态调整的高级导航计划。 |
| 创新点 | 1. 新颖的LLM基础构建机制:增量构建3D场景图作为LLM的上下文输入,使LLM计划与物理环境约束对齐。 2. 动态分步规划与细化:LLM在导航过程中动态生成逐步指令,并根据新感知到的信息持续优化未来步骤。 3. 高效泛化能力:借助LLM的先验知识,仅需少量上下文学习即可处理复杂导航任务,无需大量特定任务训练。 4. MultiON基准数据集:引入基于ProcTHOR框架的MultiON(多目标导航)任务基准数据集,包含多样化的逼真室内环境和对象。 |
| 主要贡献 | 1. 提出了首个专门针对大规模未知逼真环境中导航任务的基于LLM的高级规划器,能够以动态方式增量生成一致且非冗余的指令。 2. 提出了一种新颖的LLM基础构建机制,通过动态构建和扩展的3D场景图,将LLM的规划能力有效地应用于新环境的导航任务。 3. 引入了一个用于MultiON任务的基准数据集,促进相关研究。 |
| 实验设置 | 在ProcTHOR模拟器中进行MultiON任务评估,任务要求代理在未知房屋中找到3个不同的预定义对象。比较了不同LLM(gpt-3.5-turbo, gpt-4)、不同场景图生成方式(GT真实场景图 vs. VO视觉观察场景图)、不同低层规划器(OrNav预言机规划器 vs. PNav基于模仿学习的规划器)。 |
| 主要结果 | SayNav在MultiON任务上取得了SOTA结果,在成功率(SR)方面甚至优于基于强地面实况假设的预言机基线超过8%(例如,VO场景图+PNav低层规划器+gpt-4的SR为64.34%,而基线SR为56.06%)。 |
| 结论 | SayNav能够有效地利用LLM的常识知识和动态规划能力,通过新颖的3D场景图基础构建机制,在未知的大规模环境中成功完成复杂的多目标导航任务,展现了其强大的泛化性和实用性。 |
具体实现流程
输入 (Input):
- 目标物体列表 (Target Objects): 例如
["笔记本电脑", "叉子", "勺子"]。 - 机器人起始位置 (start_location) 和房屋ID (house_id)。
核心模块与流程 (Algorithm 1: SayNav):
初始化 (Initialization):
unfound_objects初始化为所有目标物体。- 在指定位置生成机器人 (
spawn_robot)。 - 创建空的3D场景图 (
SceneGraph)。
主导航循环 (Main Navigation Loop): 当
len(unfound_objects) > 0时:a. 观察与场景图构建/更新 (Observation & Scene Graph Update):
- 机器人执行
look_around()动作,获取当前环境的视觉观察(RGBD图像、语义分割图等)和自身位姿。 Incremental Hierarchical Scene Graph Generator模块处理观察结果:- 识别视野内的物体、家具及其3D坐标。
- 更新/扩展3D场景图(节点:小物体、大家具、房间、房屋;边:空间关系,如
'near','in', 门连接)。
- 更新
unfound_objects列表(移除已找到的对象)。 - 利用LLM根据观察到的对象识别当前房间类型(如“卧室”、“厨房”)并更新场景图 (
identify_room_type,SceneGraph.update)。
- 机器人执行
b. 高级计划生成 (High-Level Plan Generation - LLM-based Dynamic Planner):
- 判断当前房间是否适合继续寻找剩余的目标物体 (
is_feasible(room_type),由LLM判断)。 - 如果
plan_needed为真(即当前房间适合搜索或需要新计划):- 从
SceneGraph中提取与当前房间/机器人位置相关的子图 (extract_subgraph(room_type))。 - 将该子图转换为文本提示 (prompt),连同
unfound_objects,输入给LLM (query_llm_for_plan)。 - LLM生成一个短期的、分步骤的高级计划 (e.g.,
[("navigate", "桌子"), ("look", "笔记本电脑")])。该计划包含动作类型(navigate,look)和参数(目标位置/对象)。
- 从
- 判断当前房间是否适合继续寻找剩余的目标物体 (
c. 低级计划执行 (Low-Level Plan Execution - Low-Level Planner):
- 遍历LLM生成的高级计划中的每一个
action:- 如果
action.type == 'navigate':低级规划器(PNav或OrNav)将此视为一个短距离点目标导航子任务,导航到action.target_location(例如,桌子的3D坐标)。低级规划器输出一系列原子动作(move_forward,turn_left/right)来完成导航。 - 如果
action.type == 'look':机器人执行look_around(),重新进入步骤 2.a 进行观察和场景图更新,以确认是否找到action.objects。
- 如果
- 遍历LLM生成的高级计划中的每一个
d. 探索新区域 (Exploration - if current plan finishes & objects remain):
- 如果当前计划执行完毕但仍有
unfound_objects:- 检查是否所有门都已探索过 (
SceneGraph.all_doors_explored()):- 如果是,则任务失败 (
return 'Task Failed')。
- 如果是,则任务失败 (
- 否则,从
SceneGraph中找到下一个未探索的门 (find_next_unexplored_door())。 - 导航到该门 (
navigate_to(door)) 进入新房间,然后循环回到步骤 2.a。
- 检查是否所有门都已探索过 (
- 如果当前计划执行完毕但仍有
任务结束 (Task End):
- 如果所有
unfound_objects都被找到,则return 'Success'。
- 如果所有
输出 (Output):
- 任务执行状态:“Success” 或 “Task Failed”。
- (隐式) 机器人在环境中导航的路径以及找到物体的顺序。
关键组件细节:
- 3D场景图 (3D Scene Graph): 一个分层图,包含房屋、房间、大家具(地标)、小物体节点以及它们之间的空间关系(如“物体A在房间B内”,“物体C靠近家具D”)。在探索过程中动态增量构建。
- LLM交互:
- 计划生成: 将场景图子图和未找到的目标作为prompt,LLM输出分步计划。
- 房间识别: 将房间内观察到的对象列表作为prompt,LLM输出房间类型。
- 可行性判断: 将目标对象和房间类型作为prompt,LLM判断在该房间找到该对象的可能性。
- 低级规划器 (Low-Level Planner):
- PNav: 基于模仿学习(DAGGER算法)训练的策略,将RGBD输入和相对目标姿态映射到基本动作。
- OrNav: 预言机规划器,使用A*算法在已知环境地图上规划到目标点的最短路径。
- 动态性与鲁棒性:
- 计划是短期的,并根据新的观察定期重新生成或调整。
- 如果一个计划步骤失败(例如,在预期位置未找到对象),LLM可以生成替代方案或指示探索。
- 场景图中的房间节点会标记已探索状态,避免重复规划。
文章目录
摘要
语义推理和动态规划能力对于自主代理在未知环境中执行复杂导航任务至关重要。这需要大量人类拥有的常识知识才能在这些任务中取得成功。我们提出了SayNav,一种新方法,它利用大型语言模型(LLM)的人类知识,以便有效地泛化到未知大规模环境中的复杂导航任务。SayNav使用一种新颖的基础构建机制,该机制在探索环境中增量构建3D场景图作为LLM的输入,用于生成可行且上下文合适的高级导航计划。然后,LLM生成的计划由预训练的低级规划器执行,该规划器将每个计划步骤视为短距离点目标导航子任务。SayNav在导航过程中动态生成分步指令,并根据新感知到的信息不断完善未来的步骤。我们在多目标导航(MultiON)任务上评估SayNav,该任务要求代理利用大量人类知识在未知环境中有效地搜索多个不同对象。我们还引入了一个采用ProcTHOR框架的MultiON任务基准数据集,该框架提供具有多种对象的大型逼真室内环境。SayNav取得了最先进的结果,甚至在成功率方面比基于强地面实况假设的预言机基线高出8%以上,突显了其为在大规模新环境中成功定位对象生成动态计划的能力。代码、基准数据集和演示视频可在 https://www.sri.com/ics/computer-vision/saynav 获取。
1 引言
在陌生环境中找到多个目标对象对于人类来说是一项相对容易的任务,但对于自主代理来说却是一项艰巨的任务。面对这样的任务,人类能够利用常识性先验知识,如房间布局和可能的物体放置位置,来推断物体的可能位置。例如,在卧室的床上找到枕头,在餐桌上或厨房里找到勺子的机会更大。人类还能够根据新的视觉观察结果动态规划和调整他们的搜索策略和行动。例如,如果进入厨房,人类会首先寻找勺子而不是枕头。
这种推理和动态规划能力对于自主代理在新的环境中完成复杂的导航任务(例如在新的房屋中搜索和定位特定对象)至关重要。然而,当前基于学习的方法,其中最流行的是深度强化学习(DRL)(Anderson et al. 2018; Chaplot et al. 2020; Khandelwal et al. 2022),即使对于更简单的导航任务(例如找到单个对象(对象目标导航)或到达单个目标点(点目标导航)(Anderson et al. 2018)),也需要大量的训练才能使代理达到合理的性能。此外,需要大量的计算资源来复制人类对新环境的泛化能力。这种计算需求阻碍了自主代理在未知地点有效执行复杂任务的发展。
在本文中,我们提出了SayNav,一种利用大型语言模型(LLM)的常识知识来实现对未知大规模环境中复杂导航任务的高效泛化的新方法。最近,配备基于LLM规划器的代理已经显示出仅用少量训练样本就能执行复杂操作任务的卓越能力(Ahn et al. 2022; Song et al. 2022)。SayNav遵循这一趋势,利用LLM开发专门用于导航任务的通用规划代理。为了充分展示和验证SayNav的能力,我们选择了一个复杂的导航任务——多目标导航(MultiON)。对于此任务,代理需要有效地探索一个新的3D环境,以定位给定名称的多个不同对象。这个任务需要大量的先验知识和动态规划能力(类似于人类)才能成功。
MultiON任务最近作为对象目标导航任务的泛化而出现。它由(Wani et al. 2020)引入,作为“导航到有序对象序列”的任务,并且MultiON上的大多数其他工作都遵循相同的定义。(Gireesh et al. 2023)放弃了给定对象必须按有序序列排列的约束,并将目标定义为以任何顺序定位一定数量的对象。这也是我们定义MultiON任务的方式。
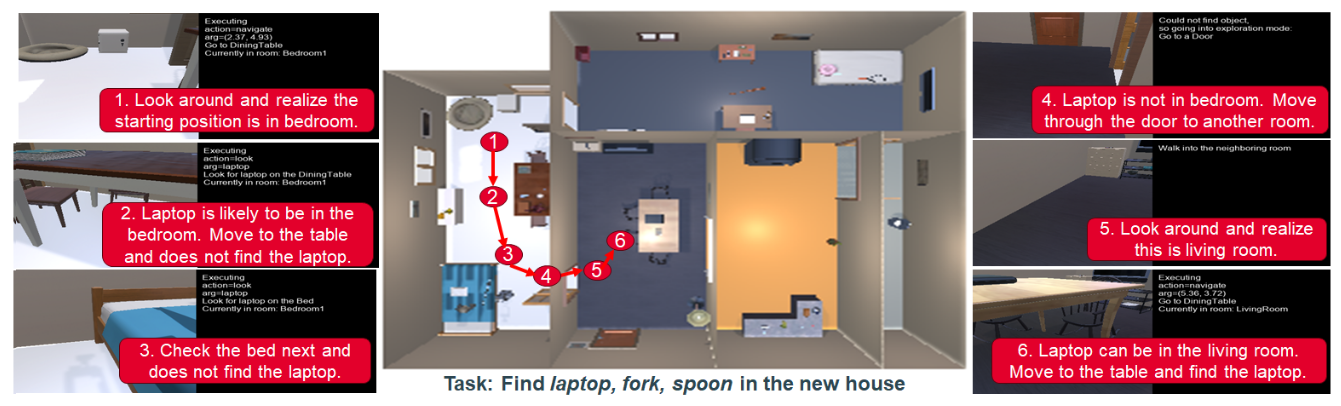
图1:一个SayNav示例:机器人在新房子里使用基于LLM的规划器高效地找到一个目标对象(笔记本电脑)。
因为它比之前的定义带来了更大的规划挑战和任务复杂性。遵循MultiON任务的趋势,我们将在实验中为每个片段使用三个不同的对象作为目标。请注意,SayNav能够在环境中搜索任意数量的对象。
SayNav的关键创新在于,它利用探索过程中感知到的信息,增量地构建和扩展新环境的3D场景图。然后,它将来自LLM的可行且上下文合适的知识进行基础构建,供代理用于导航。这种新的基础构建机制确保LLM遵守新环境中的物理约束,包括感知实体的空间布局和几何关系。3D场景图(Armeni et al. 2019; Kim et al. 2019; Rosinol et al. 2021; Hughes et al. 2022; Wald et al. 2020; Wu et al. 2021)最近已成为支持机器人实时决策的强大3D大规模环境高级表示。3D场景图是一个分层图,它在多个抽象级别(如对象、地点、房间和建筑物)上表示空间概念(节点)及其关系(边)。我们利用这种3D场景图表示来为当前环境中的LLM提供基础,该环境用于在导航过程中不断构建和完善代理的搜索计划。
具体来说,SayNav利用LLM在导航过程中动态生成定位目标对象的逐步指令。为了确保以动态方式进行可行且有效的规划,SayNav持续地从(当前的3D场景图)提取子图并将其转换为文本提示,以输入给LLM。这个提取的子图包括以代理当前位置为中心的局部区域中的空间概念。然后,LLM基于此子图规划下一步,例如推断目标对象的可能位置并对其进行优先级排序。此计划还包括条件语句和备用选项,以防任何步骤无法实现目标。例如,如果代理在桌子上找不到笔记本电脑,它会去下一个可能的位置(床)在卧室里寻找。
SayNav还利用LLM在导航过程中增强和完善场景图,例如根据当前感知到的对象注释房间类型。这改善了场景图中语义信息的层次结构组织,从而支持更好的规划。SayNav根据房间类型计算完成当前目标的可行性,这有助于更好地优化计划。例如,在寻找勺子时,它可能会跳过洗手间,但稍后可能会回来。
SayNav仅需要通过上下文学习(Brown et al. 2020; Ouyang et al. 2022)提供少量示例,即可配置LLM在新环境中执行复杂MultiON任务的高级动态规划。LLM生成的计划随后由预训练的低级规划器执行,该规划器将每个计划步骤视为一个短距离点目标导航子任务(例如移动到感知到的对象)。这种分解降低了导航任务的规划复杂性,因为LLM规划的子任务对于低级规划器来说足够简单,可以成功执行。
图1展示了一个SayNav利用LLM高效探索新环境并定位三个目标对象之一(笔记本电脑)的示例。代理首先环顾四周(即观察以构建场景图)并识别其起始房间的类型。在检查了房间内目标对象的潜在位置后,代理没有找到任何目标。然后它决定穿过门移动到另一个房间。代理在探索过程中不断扩展场景图,并意识到相邻的房间是客厅。在那里,它在桌子上找到了一个目标,并继续搜索其他两个对象。
主要贡献总结如下:
- 据我们所知,我们首次提出了一个专门针对大规模未知逼真环境中导航任务的基于LLM的高级规划器。所提出的LLM规划器在导航过程中以动态方式逐步生成指令。LLM在导航过程中生成的指令是一致且非冗余的。
- 我们提出了一种在新大规模环境中为LLM进行导航的新颖基础构建机制。SayNav在探索过程中逐步构建和扩展3D场景图。通过利用基于所选部分(子图)场景图的文本提示,从LLM生成下一步计划。场景图的某些部分也由LLM持续完善和更新。
- 我们引入了一个跨不同房屋的MultiON任务基准数据集,供我们评估和研究人员未来使用。
2 相关工作
在本节中,我们将简要回顾视觉导航、用于自主代理的基于LLM的高级规划以及MultiON的相关工作。
新环境中的视觉导航是许多自主代理应用的基本能力。最近基于学习的方法和DRL方法在各种视觉导航任务上,如基于SLAM(同时定位与地图构建)和路径规划技术的经典方法(Mishkin et al. 2019),表现出巨大潜力。这些导航任务包括点目标导航(Wijmans et al. 2019)、图像目标导航(Zhu et al. 2017)和对象目标导航(Chaplot et al. 2020)。
然而,这些方法通常需要至少数亿次迭代(Wijmans et al. 2019)才能训练代理在新环境中泛化。这导致了数据收集和计算方面的高成本。此外,它阻碍了能够执行更复杂导航任务(如多对象导航和警戒与搜索)的自主代理的开发,这些任务需要在新环境中利用常识知识并进行动态规划。
利用LLM的常识知识使我们能够避免像以前基于学习的方法那样的高昂训练成本。通过文本提示有效地为LLM(如ChatGPT)提供基础,我们的方法能够在未知环境中实现高效的视觉导航高级规划。为了更好地展示和评估我们提出的方法,我们使用了多对象导航,它比以前的导航任务(如对象目标导航)更复杂。MultiON任务需要常识知识,就像人类一样,才能在大规模未知环境中有效地搜索多个不同对象。
使用LLM进行高级规划已成为机器人领域的一个新兴趋势。LLM凭借其在互联网规模数据上的训练和指令调整,已显示出在未见任务上执行零样本/少样本学习的出色能力(Zhao et al. 2023; Brown et al. 2020)。最近的指令调整模型(如ChatGPT)进一步显示出遵循以提示形式表达的自然指令的强大能力(Chung et al. 2022; Peng et al. 2023)。
自主领域的近期工作已经使用了LLM并展示了重大进展(Ahn et al. 2022; Song et al. 2022; Huang et al. 2022; Liu et al. 2023; Driess et al. 2023; Brown et al. 2020; Ouyang et al. 2022),它们融合了人类知识,从而能够有效地训练自主代理执行移动操作等任务。这些工作通过使用两级规划架构降低了学习复杂性。对于每个分配的任务,它们利用LLM生成一个高级的分步计划。每个计划的步骤,被表述为一个更简单的子任务,可以由一个预言机(地面实况)或一个预训练的低级规划器执行,该规划器将一个步骤映射为一系列基本动作。具有这些基于LLM的规划器的代理能够通过上下文学习(Brown et al. 2020; Ouyang et al. 2022),仅用少量训练示例即可执行新任务。
然而,这些基于LLM的规划器在新的大规模环境中进行视觉导航任务时存在两个主要限制。首先,这些方法(Ahn et al. 2022; Song et al. 2022; Huang et al. 2022; Liu et al. 2023)中的基础构建机制是为小规模环境设计的。例如,像(Song et al. 2022; Singh et al. 2023)这样的工作主要集中在仅包含单个房间的AI-THOR环境。此外,这些方法仅依赖于特定对象的检测。它们不考虑房间布局和房间内感知实体的拓扑排列,而这些对于在物理环境中为LLM进行视觉导航任务的基础构建非常重要。因此,使用这些方法从LLM提取的知识对于代理在像多房间房屋这样的大规模环境中导航可能不具有上下文适用性。
其次,其中一些基于LLM的规划器通常在开始时为分配的任务生成一个多步长时程计划,这对于在未知环境中导航是不可行的。它们也缺乏在任务执行期间更改计划的能力。相反,在新地方进行导航的有效搜索计划需要在探索过程中逐步生成和更新。未来的行动是根据当前感知的场景和先前访问区域的记忆来决定的。
SayPlan (Rana et al. 2023) 通过使用已知大规模场所的预构建地面实况3D场景图来解决第一个问题,为LLM的高级任务规划提供基础。然而,由于在任务执行之前整个地面实况场景图都是可用的,SayPlan的规划复杂性得到了简化。换句话说,SayPlan不能用于未知环境中的任务规划。
我们的方法SayNav,旨在专门利用LLM在未知大规模环境中进行视觉导航。我们提出了一种新的基础构建机制,它将探索环境的3D场景图逐步构建为LLM的输入,用于生成高级计划。SayNav还在导航过程中动态生成分步指令。它通过LLM根据新感知到的信息持续完善未来的步骤。
我们发现唯一专门利用LLM在未知环境中进行导航任务的工作是L3MVN (Yu et al. 2023)。它使用LLM根据检测到的对象找到附近的语义边界,以扩展探索区域,最终找到目标对象。例如,移动到更可能有电视的(沙发、桌子)区域。换句话说,它利用LLM来提示下一个探索方向。它不像一个完整的高级规划器那样使用LLM来生成分步指令。相比之下,我们的SayNav使用3D场景图作为高级规划器来为LLM提供基础。我们基于LLM的规划器以动态方式生成指令,并考虑其先前计划的步骤以生成更好的未来计划。
MultiON任务在过去几年引起了研究人员的关注。
如前所述,它们中的大多数(Chen et al. 2022; Zeng et al. 2023; Marza et al. 2022, 2023)都考虑了预定义的对象序列进行定位,这在很大程度上简化了任务。此外,它们采用纯粹的DRL方法,因此存在前面讨论的问题。(Gireesh et al. 2023) 是唯一考虑MultiON时不带任何对象序列的工作,但它同样使用了DRL方法。
3 SayNav
我们现在描述SayNav的框架以及多对象导航任务。
3.1 任务定义
我们选择多对象导航任务来验证SayNav。此任务的目标是在大规模未知环境中导航代理,以便为三个预定义对象类别(例如“笔记本电脑”、“番茄”和“面包”)中的每一个找到一个实例。代理在环境中的随机位置初始化,并接收目标对象类别( o i , o j , o k o_i, o_j, o_k oi,oj,ok)作为输入。在导航过程中的每个时间步 t t t,代理接收环境观察 e t e_t et 并采取控制动作 a t a_t at。观察包括RGBD图像、语义分割图和代理的姿态(位置和方向)。动作空间包括五个控制命令:turn-left(左转)、turn-right(右转)、move-forward(前进)、stop(停止)和look-around(环顾四周)。turn-left 和 turn-right 动作使代理旋转90度。move-forward 动作使代理移动25厘米。如果代理在一段时间内(通过检测)定位到所有三个对象,则任务执行成功。
请注意,MultiON任务比以前的导航任务(这些任务要么寻找单个对象(Chaplot et al. 2020),要么到达单个目标点(Wijmans et al. 2019))带来了更大的规划挑战和任务复杂性。例如,代理需要根据三个不同对象的优先级顺序动态设置搜索计划。这个计划也可以在具有未知布局的新房子中探索时更改。如图1所示,代理首先意识到它在卧室里,然后决定优先考虑某些位置(例如桌子)来定位笔记本电脑。另一方面,如果代理从厨房开始,那么首先搜索叉子和勺子会更有效。因此,这个新任务需要广泛的语义推理和动态规划能力,就像人类所拥有的那样,以便自主代理能够在大规模未知环境中进行探索。
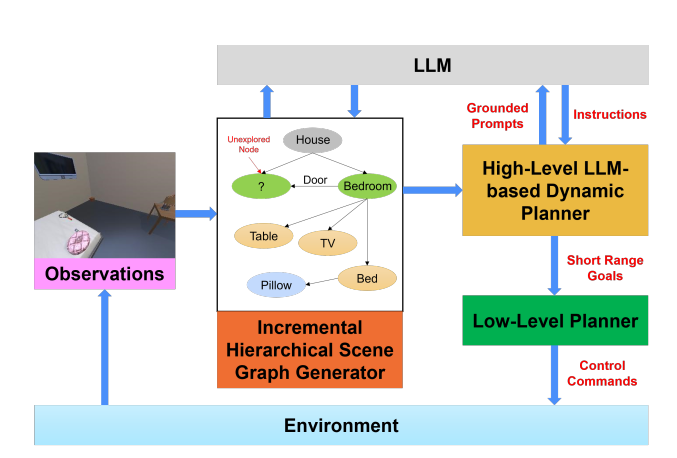
图2:SayNav框架概览。
3.2 概述
SayNav的框架如图2所示。相应的伪代码在算法1中。它包括三个模块:(1)增量场景图生成,(2)基于LLM的高级动态规划器,和(3)低级规划器。增量场景图生成模块累积代理接收到的观察结果,以构建和扩展场景图,该场景图编码了代理已探索区域的语义实体(如对象和家具)。基于LLM的高级动态规划器持续地将场景图中的相关信息转换为文本提示,输入给预训练的LLM,用于动态生成短期高级计划。每个LLM规划的步骤由低级规划器执行,以生成一系列控制命令。
3.3 增量场景图生成
该模块持续构建和扩展正在探索的环境的3D场景图。3D场景图是一个分层图,它表示在多个抽象级别上的空间概念(节点)及其关系(边)。这种表示最近已成为机器人学中3D大规模环境的一种强大的高级抽象。在这里,我们在3D场景图中定义了四个级别:小对象、大对象、房间和房屋。每个对象节点都与其3D坐标相关联,每个房间节点都与其边界相关联。每扇门都被视为两个房间之间的边,它也具有相关的3D坐标。所有其他边揭示了不同级别语义概念之间的拓扑关系。图3显示了我们场景图的一个示例。在数学上,我们的场景图可以表示为4种三元组的集合:
{ ( s h , ‘near’ , l i ) , ( l i , ‘in’ , r j ) , ( r j , d j k , r k ) , ( r j , ‘in’ , H ) } \{(s_h, \text{‘near'}, l_i), (l_i, \text{‘in'}, r_j), (r_j, d_{jk}, r_k), (r_j, \text{‘in'}, H)\} {(sh,‘near’,li),(li,‘in’,rj),(rj,djk,rk),(rj,‘in’,H)}
其中, s h s_h sh:小对象, l i l_i li:大对象, r j , r k r_j, r_k rj,rk:房间 ( i ≠ j i \neq j i=j), d j k d_{jk} djk: r j r_j rj 和 r k r_k rk 之间的门, H H H:房屋(根节点)。
大对象充当从远处可见的地标。LLM使用这些大对象来推断附近是否可以找到小对象。例如,走向餐桌寻找刀子可能是合乎逻辑的。小对象与大对象的判定是基于它们的尺寸以及LLM对对象类别的理解。
场景图是通过代理在探索过程中接收到的环境观察构建的。可以基于RGBD图像和语义分割图像获得每个分割对象的深度。然后,可以通过组合其在多个时间戳的深度信息和相应的代理姿态来估计每个感知对象的3D坐标。
我们还利用LLM来增强和完善场景图的高级抽象。例如,我们使用LLM根据其连接的较低级别对象来注释和识别图的房间级别上的空间实体(房间类型)。例如,如果一个房间包含一张床,那么它可能是一个卧室。房间的边界是根据墙壁和地板的检测来计算的。
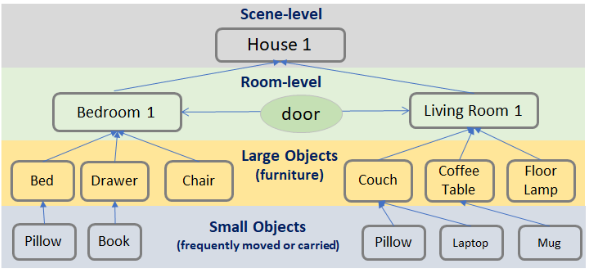
图3:我们的场景图示例。
SayNav还使用3D场景图来支持未来规划的记忆。例如,它会自动注释已经调查过的房间节点。因此,当代理重新访问同一房间时,它不会生成重复的计划。

3.4 基于LLM的高级动态规划器
与先前基于LLM的规划工作类似,SayNav利用两级规划架构来降低分配任务的学习复杂性。然而,SayNav并非在一开始就为整个任务生成完整的高级计划,而是利用LLM根据当前观察和先前访问区域的记忆,定期地增量生成短期计划。这个高级规划器可以通过典型的上下文学习过程(Brown et al. 2020; Ouyang et al. 2022),仅使用少量训练示例即可设置(如图4所示)。
我们的基于LLM的高级动态规划器从完整的3D场景图中提取一个子图,并将其转换为文本提示,然后输入给LLM。提取的子图包含以代理当前位置为中心的局部区域中的空间概念。我们实现了类似于(Singh et al. 2023)的LLM提示,该提示基于提取子图中的文本标签构建编程语言提示。一旦收到提示,LLM规划器就会输出短期的分步指令,作为伪代码。生成的计划基于人类知识,提供了一种在当前感知区域内有效的搜索策略,根据目标对象被发现的可能性对房间内的位置进行优先级排序。例如,LLM可能会提供一个计划,首先检查书桌,然后检查床,以在卧室中找到笔记本电脑。图4显示了用于生成计划的提示结构。我们在提示中提供了两个上下文示例,以约束LLM生成的计划。例如,我们约束每个步骤生成一个带有参数和高级注释的navigate或look函数调用。请注意,我们还让LLM为生成的计划中的每个步骤输出一个描述性注释,以最大限度地减少LLM中普遍存在的幻觉问题。
当先前的计划失败或在执行先前的短期计划后任务目标(找到三个对象)未实现时,基于LLM的规划器还会扩展和更新计划。它尝试通过以下方式更新计划:(i)根据从环境中接收到的新信息生成计划,(ii)将低级规划器置于探索模式(例如:尝试进入下一个房间),或(iii)通过指示低级规划器随机移动并收集更多观察来完善场景图。
在为局部区域(房间)生成高级计划之前,LLM还会推理在检测到的房间类型中定位目标对象的可行性。如果可行性低,它可能会决定跳过搜索特定房间并稍后返回。在这种情况下,它会在场景图中标记相应的房间节点以便稍后返回。
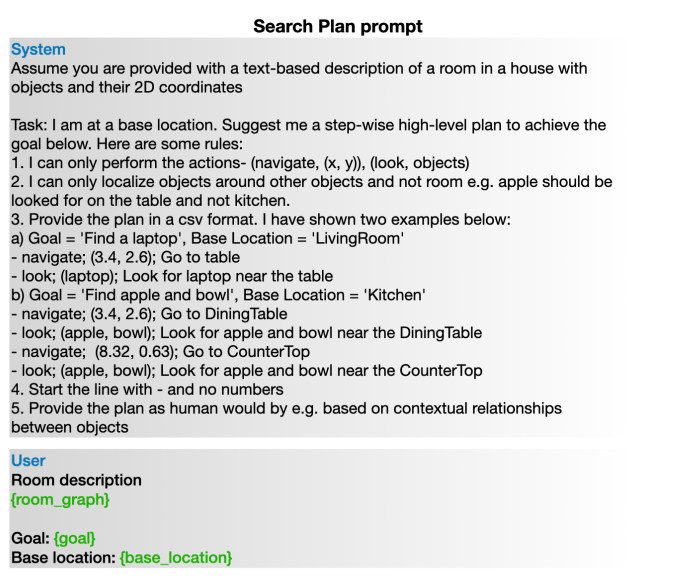
图4:用于为特定房间创建搜索计划的提示。

图5:用于计算在某个房间类型中找到某个对象的可行性以及识别房间类型的提示。
3.5 低级规划器
低级规划器将每个LLM规划的步骤转换为一系列控制命令以供执行。为了集成两个规划器,SayNav将每个LLM规划的步骤表述为低级规划器的短距离点目标导航(POINTNAV)子任务。每个子任务的目标点,例如从当前位置移动到当前房间的桌子,由计划步骤中描述的对象(例如桌子)的3D坐标指定。
SayNav的低级规划器将RGBD图像(分辨率320x240)和代理的姿态(位置和方向)作为输入,并输出move_forward、turn_left和turn_right动作来控制机器人,遵循标准的POINTNAV设置。请注意,大规模DRL方法通常在训练期间需要 10 8 10^8 108到 10 9 10^9 109个模拟步骤才能解决模拟环境中的POINTNAV任务(Wijmans et al. 2019; Weihs et al. 2020),这带来了严峻的训练要求和计算需求。然而,在SayNav中,两级规划架构简化了低级规划器的工作。低级规划器主要输出短程移动的控制命令。基于LLM的高级规划器对低级规划器的故障也具有鲁棒性,它通过定期更新计划来实现。通过这种方式,可以大大减少低级规划器所需的训练负荷。
受到模仿学习(IL)在资源受限的导航任务上取得成功的鼓舞(Ramrakhya et al. 2022, 2023; Shah et al. 2023),我们研究了一种样本高效的基于IL的方法来训练SayNav中的低级规划器。这个低级规划器从零开始训练(没有预训练),仅使用了2800个片段或 7 × 10 5 7 \times 10^5 7×105个模拟步骤。具体来说,低级规划器使用DAGGER算法(Ross et al. 2011)进行训练,以遵循最短路径预言机作为专家。尽管最短路径预言机缺乏解决复杂环境(例如多房间)中POINTNAV任务所需的探索行为,但我们发现它有助于代理非常快速地学习短距离导航技能,而无需人工干预。
我们首先使用A算法在房屋可达位置网格上实现了一个最短路径预言机,然后使用DAGGER算法(Ross et al. 2011)和A预言机作为专家来训练POINTNAV代理。我们在两轮中执行DAGGER数据集聚合。在第一轮中,使用随机代理收集了2000个片段。在第二轮中,使用从第一轮片段训练的代理收集了额外的800个片段。聚合的数据集总共包含2800个片段或 7 × 10 5 7 \times 10^5 7×105个用于IL的模拟器步骤。对于每个片段,我们从ProcThor-10k训练集中选择一个场景,随机采样一个起始位置,并从场景中随机采样一个对象作为目标位置。然后机器人通过以 p = 0.2 p=0.2 p=0.2的概率执行专家动作和以 p = 0.8 p=0.8 p=0.8的概率执行代理动作来执行任务。机器人的观察和专家动作被存储用于行为克隆。
对于行为克隆,目标函数是最小化每一步预测动作与专家动作之间的交叉熵损失。对于代理架构,我们遵循(Wijmans et al. 2019),使用图6所示的标准架构。如前所述,我们的代理接收RGBD图像和代理相对于目标位置的姿态作为输入。一个GroupNorm(Wu et al. 2018)ResNet18(He et al. 2016)编码输入的RGBD图像,一个2层512隐藏大小的门控循环单元(GRU)(Cho et al. 2014)结合历史和传感器输入来预测下一个动作。我们使用Adamax优化器,学习率为 10 − 4 10^{-4} 10−4,权重衰减为 10 − 4 10^{-4} 10−4。我们用16个片段的批量大小对目标函数进行50个周期的优化。
我们评估代理的POINTNAV性能。
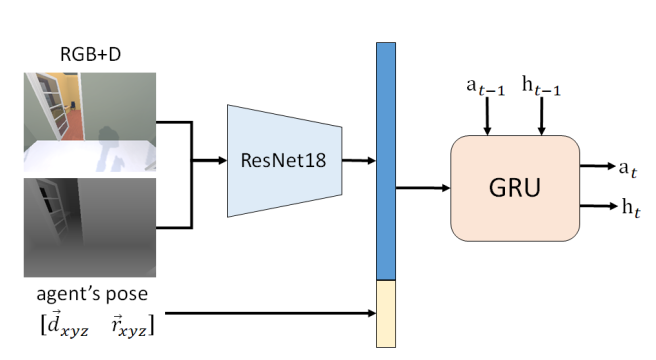
图6:低级POINTNAV架构。
在公开可用的AI2Thor OBJECTNav数据集¹ ProcThor-10k-val分割上,使用对象的地面实况位置作为POINTNAV评估的目标。评估分割包含1550个片段。当目标对象的多个实例可用时,我们任意选择第一个实例作为POINTNAV目标。我们的低级规划器达到了84.5%的SR(成功半径1.5米,最大300步)和0.782的SPL。在起始位置和目标位置在同一房间的片段子集上,性能提高到98.5%的SR和0.930的SPL。
4 实验结果
4.1 多对象导航数据集
大多数先前的具身AI模拟器,如AI2-THOR(Kolve et al. 2017)或Habitat(Szot et al. 2021),要么基于单房间环境,要么缺乏环境中对象的自然放置,要么缺乏与对象交互的能力。对于我们的实验,我们选择了最近引入的ProcTHOR框架(Deitke et al. 2022),它建立在AI2-THOR模拟器之上。ProcTHOR能够根据房间规格(例如:一个有2间卧室、1间厨房和1间浴室的房子)程序化地生成完整的房屋平面图。它还用108种对象类型填充每个平面图,具有逼真、物理上合理和自然的放置。ProcTHOR中的场景是交互式的,允许改变对象的状态、光照和纹理,为感知带来了更大的挑战,并为未来的工作提供了更广阔的范围。我们构建了一个包含132个片段的基准数据集,使用了132个不同的房屋,每个房屋有3-10个房间,并为每个房屋选择3个对象来执行MultiON任务。数据集中的每个片段都由以下属性描述:
data_type:这对应于从ProcThor-10K用于构建片段的数据集是“val”还是“test”。house_idx:这对应于ProcThor-10K数据集中特定房屋的索引。num_rooms:房屋中的房间数量。num_targets:房屋中的目标数量(目前我们将数据集限制为3个目标)。targets:房屋中唯一目标的列表及其地面实况位置。
¹ https://github.com/allenai/object-nav-eval
start_position:从房屋中所有可到达位置随机采样的起始位置。start_heading:从0、90、180和270度随机采样的起始朝向。shortest_path_targets_order:使用A规划器导致最短路径的目标顺序。这是通过在所有可能的目标顺序上运行A规划器来评估的。shortest_path_length:通过A*规划器沿shortest_path_targets_order计算的最短路径长度。
4.2 指标
我们报告了用于评估导航任务的两个标准指标:成功率(SR)和路径长度加权成功率(SPL)(Anderson et al. 2018)。SR衡量代理能够成功找到所有三个对象的案例百分比,而SPL通过最短路径与实际所走路径的比率来规范化成功。我们使用从起点到所有目标对象排列的最短路径的最小值。除了这两个指标,我们还测量了代理获得的对象顺序与地面实况之间的相似性。地面实况对象顺序给出了一个完美代理如何通过首先识别当前房间/场景图中极有可能的对象然后探索其他房间来探索空间的思路。我们使用Kendall距离度量(Lapata 2006),它根据不一致对的数量计算两个排名之间的距离。我们将此距离转换为相关系数的Kendall Tau,并报告其在成功片段(所有三个目标都已定位)上的值。
4.3 实现细节
我们在AI2-Thor模拟器中使用带有头部安装RGBD摄像头的默认机器人。摄像头具有320 × 240分辨率和90°视场(FoV)。机器人观察和动作的细节可参考第3.1节。
我们使用两种不同的LLM进行实验:gpt-3.5-turbo和gpt-4。对于低级规划器的训练,我们使用了第3.5节中描述的IL方法。它在未见过的ProcThor-10k-val场景中,使用随机起始和目标位置,达到了84.5%的SR(成功半径1.5米,最大300步)和0.782的SPL。对于单个房间内的短程移动,性能提高到98.5%的SR和0.930的SPL。
请注意,SayNav由三个模块组成——增量场景图生成器、基于LLM的规划器和低级规划器。我们实验的主要目标是充分验证和检验SayNav中用于MultiON的基于LLM的规划能力。因此,对于其他两个模块中的每一个,我们都实现了一个使用地面实况信息的替代选项,以避免该模块内的任何错误。这使我们能够进行消融研究,以确定每个模块对整体性能的影响。
首先,我们允许使用地面实况(GT)而不是视觉观察(VO)来生成场景图。我们已经在第3.3节中描述了使用VO生成场景图的过程。GT选项直接使用周围对象的地面实况信息,包括3D坐标和对象之间的几何关系,来增量构建场景图。
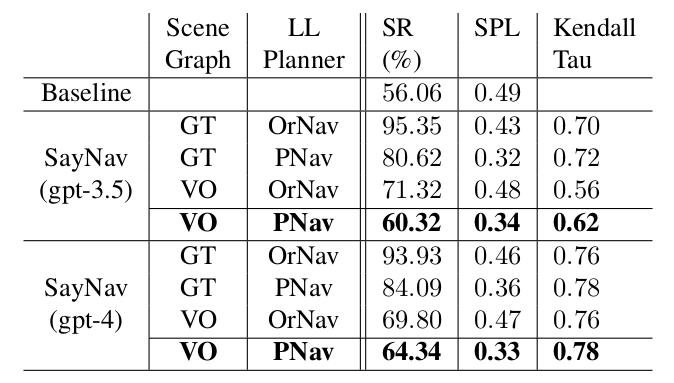
表1:SayNav在多目标导航任务上的结果。Baseline使用PNav代理根据地面实况位置沿目标之间的最短路径导航;GT和VO分别从地面实况对象/房间位置和模拟器提供的视觉观察构建场景图;OrNav和PNav分别使用预言机和IL学习的低级(LL)规划器在高级规划器分配的点之间导航。
这个选项避免了处理视觉观察时可能出现的任何关联和计算模糊性,例如基于RGBD图像及其分割计算每个对象的3D坐标。
其次,我们使用预言机规划器(OrNav)作为低级规划器,而不是我们高效训练的IL代理(PNav)。我们已经在第3.5节中描述了PNav的实现。对于OrNav,我们使用一个A*规划器,它可以访问环境地图。给定一个目标位置,它可以规划从代理当前位置到目标的点的最短路径。
4.4 基线
大多数现有的基于LLM的机器人导航方法都在已知和/或小规模环境中运行。然而,确实存在一些基于RL/IL的方法(例如:(Gireesh et al. 2023))和传统的基于SLAM的方法可以在我们的问题设置中工作。许多先前的工作(例如:(Savva et al. 2019))表明,基于RL/IL的点目标导航(PointNav)在未知环境中比基于SLAM的方法表现好得多(在提到的例子中为80%对62%)。由于缺乏现有工作的开源数据集/代码,我们选择实现最强的可能基线方法,该方法采用基于IL的PointNav策略,这可能反映了使用与我们相同数量训练数据的基于学习的代理的性能上限。基线代理使用了SayNav无法访问的两个特权信息。首先,它可以访问实现最短路径的目标对象的最佳顺序。这简化了MultiON任务,使其成为一系列ObjectNav任务。其次,由于PointNav策略通常比ObjectNav策略表现更好,我们还为基线代理提供了对每个目标对象的地面实况坐标的访问权限,这进一步将任务简化为一系列PointNav任务。换句话说,我们实现了一个PointNav代理,以按最佳顺序导航到对象的地面实况点。
4.5 定量结果
表1显示了基线以及SayNav中不同实现选择的结果。请注意,对于基线方法,即使使用最佳顺序的地面实况对象位置,SR也仅为56.06%,这表明了MultiON任务的难度。这是因为PointNav策略在大规模环境中观察到性能损失。尽管基线可以访问目标对象的位置,但找到每个对象仍然需要它规划跨多个房间的长距离路径。相比之下,SayNav在不使用任何地面实况的情况下,分别使用gpt-3.5-turbo和gpt-4实现了更高的SR(60.32%和64.34%)。这一改进突显了SayNav在未知大规模环境中导航的优越性。

图7:SayNav(OrNav + GT)用于多目标对象导航任务的一个片段的可视化。
SR: 对于SayNav,我们观察到当使用模拟器(GT)的地面实况对象/房间位置生成的场景图以及OrNav时,性能最佳。请注意,在这种情况下,gpt-3.5的SR为95.35%,gpt-4的SR为93.93%,这反映了我们基于LLM的高级规划器的实力,这是实验中唯一不完美的模块。当我们用VO替换GT时,我们确实观察到性能下降。我们发现SR的下降可能与任何基于感知的算法中遇到的各种挑战有关。由于部分观察导致的对象3D位置估计不准确,可能导致目标检测和导航失败。此外,
为了更实际的行为,我们移除了语义分割观察中小于20像素的对象。因此,在通过视觉观察构建场景图时,非常小的对象也可能被忽略。我们还观察到VO中与估计玻璃门位置相关的特定挑战。在深度图中,玻璃门后面的可见对象的深度代表了实际物理门的深度,这导致门位置估计失败。从GT & PNav和VO & PNav的结果中可以找到类似的趋势。当用PNav替换OrNav时,我们也观察到性能下降。这很明显,因为与OrNav相比,PNav无法访问任何地面实况信息。
然而,即使存在所有这些挑战,SayNav的表现也优于基于预言机的基线,并在MultiON任务中取得成功。我们相信这是由于基于LLM的动态规划能力,以及基于增量场景图生成的接地机制。它利用常识知识,就像人类一样,在未知环境中有效地搜索多个不同的对象。它还在计划步骤发生任何故障时优化或纠正计划。
SPL: 查看SPL指标,我们发现与基线相比,SayNav的SPL有所下降。请注意,SPL反映了代理所走的路径长度与最短可能路径的比较。例如,一个片段的SPL=1意味着代理从初始位置开始,以最佳顺序沿着最短路径直接到达目标,探索为零,这在未知环境中实际上是不可能的。由于可以访问最佳顺序的地面实况对象位置,因此基线具有更高的SPL是很明显的。从结果中,我们还观察到低级规划器对SPL有主要影响。与PNav相比,系统使用OrNav时实现了更高的SPL。
Kendall-Tau: Kendall-Tau (τ) 指标衡量代理定位对象的顺序与基于地面实况的最佳顺序之间的相似性。它显示了LLM提供的知识对于找到最佳计划的重要性。我们观察到对象的排序受低级规划器的影响不大。这是合理的,因为排序主要取决于高级规划器生成的计划。正如预期的那样,当我们用VO替换GT时,得分会下降,因为LLM使用场景图来生成计划。使用gpt-4(与gpt-3.5-turbo相比)得分的显著提高表明,使用更好的LLM可以改进常识先验知识的使用,并产生更优的排序。另外,请注意Kendall Tau指标不适用于基线,因为它已经可以访问目标的最佳顺序。
表2:使用LLM内存的SayNav在MultiON任务上的结果
| 场景图 | LL规划器 | SR (%) | SPL | Kendall Tau | |
|---|---|---|---|---|---|
| SayNav | GT | OrNav | 77.86 | 0.37 | 0.72 |
| (gpt-3.5) | GT | PNav | 61.83 | 0.24 | 0.76 |
| VO | OrNav | 58.73 | 0.40 | 0.72 | |
| VO | PNav | 46.77 | 0.29 | 0.82 | |
| SayNav | GT | OrNav | 93.93 | 0.43 | 0.69 |
| (gpt-4) | GT | PNav | 86.36 | 0.35 | 0.77 |
| VO | OrNav | 72.09 | 0.44 | 0.73 | |
| VO | PNav | 61.60 | 0.35 | 0.77 |
4.6 定性结果
我们在图7中展示了一个典型片段的示例,其中要求代理在未知房屋中定位闹钟、笔记本电脑和手机。代理恰好从厨房开始(由LLM根据感知到的对象确定)。规划器推断在那里不太可能找到任何对象,因此决定通过一扇门进入另一个房间。然后,它进入一个客厅,在那里能够定位笔记本电脑和手机。第三个对象仍然未找到,因此它再次决定通过一扇门进入另一个房间。最终,它在最后一个房间定位了闹钟。此示例的完整演示视频可以在我们的项目链接中找到。
4.7 通过LLM实现内存
如第3.3节所述,SayNav使用3D场景图来支持未来规划的内存。例如,它会自动注释已经探索过的房间节点,如果代理恰好再次访问同一房间,则不会为该房间规划。这种支持内存的实现方式非常适合我们选择的任务。然而,我们也想探索让LLM跟踪其自身计划的可能性。因此,我们还通过使用LangChain框架²的会话链模块实现了SayNav的LLM内存。在这里,我们使用两个相同的LLM模型的独立实例,一个用于生成高级计划,另一个用于跟踪生成的计划。跟踪生成计划的LLM使用图8中的“房间跟踪提示”,并且还配备了会话内存。负责生成计划的LLM接收周围环境的详细描述,而另一个LLM实例仅接收执行跟踪所需的最小信息。这种框架的一个关键优势是它避免了达到LLM的最大令牌限制,因为它不依赖于整个会话历史(像通常那样)。我们相信基于LLM的跟踪可能能够更好地泛化到其他任务,因为它消除了对跟踪计划历史的模块的需求,这将需要针对不同任务的不同实现(我们将在未来的工作中测试这一点)。
表2显示了使用gpt-3.5-turbo和gpt-4的LLM内存时SayNav的性能。请注意,在我们的实验中,我们对LLM的两个实例使用相同的模型。我们确实观察到,与表1中报告的结果相比,在使用gpt-3.5-turbo的LLM内存时,SR和SPL指标大幅下降。然而,对于gpt-4,LLM内存能够达到与表1相似的结果。这表明将跟踪任务交给更好的LLM模型是可行的。

图8:用于通过LLM进行房间跟踪的提示。

图10:一个失败案例:左图显示了安装在代理上的摄像头拍摄的RGB图像,右图显示了房屋的俯视图。由于房间的几何形状,代理无法观察到门是打开的,因此无法通过门(用黄色矩形标记)导航。
4.8 真实世界演示
我们还将SayNav移植到了一个真实的机器人上,并在各种设置下进行了测试,以展示SayNav在真实环境中的高效泛化能力。自助餐厅环境的演示视频可在我们的项目链接中找到。

图9:真实机器人上的SayNav。
5 局限性与讨论
本节讨论了我们工作的局限性以及未来改进SayNav的一些想法。如前所述,我们的场景图生成面临着任何基于感知的算法中遇到的各种挑战。除了我们前面描述的玻璃门问题外,图10还显示了由于视觉观察而导致的另一个问题的失败案例。请注意,在我们的实验中,代理没有配备手臂来打开/关闭门。因此,它只能通过打开的门移动到其他房间。在这个片段中,代理在房间中的大多数位置都无法观察到门是打开的(该门连接到有目标对象的另一个房间)。机器人反复尝试走向当前房间的中心并完善场景图。然而,它仍然无法识别门的“打开”状态,因此无法实现目标。
一个更好的验证与场景图中的对象节点(门)相关联的属性(打开/关闭)的机制可以帮助缓解这种情况。例如,代理可以靠近门,从所有可能的角度验证视觉观察,并将门的深度信息与墙壁的深度信息进行比较(关闭的门应具有与连接墙壁几乎相同的深度)。将来,我们希望开发验证和反馈机制来验证LLM生成的计划,以提高SayNav的性能。我们还计划探索更小的LLM(而不是GPT-3.5和GPT-4),这些LLM可以在真实的机器人上本地运行。
6 结论
我们提出了SayNav,一种在新未知大规模环境中高效泛化到复杂导航任务的新方法。SayNav增量构建并将探索环境的3D场景图转换为LLM,用于生成动态且上下文合适的高级导航计划。我们在MultiON任务上评估SayNav,该任务要求代理在未知环境中有效地搜索多个不同对象。我们的结果表明,SayNav甚至优于一个强大的基于预言机的Point-nav基线(64.34% vs 56.06%),能够在大规模新环境中成功定位对象。