ElasticSearch
基础数据管理
核心概念
常用术语
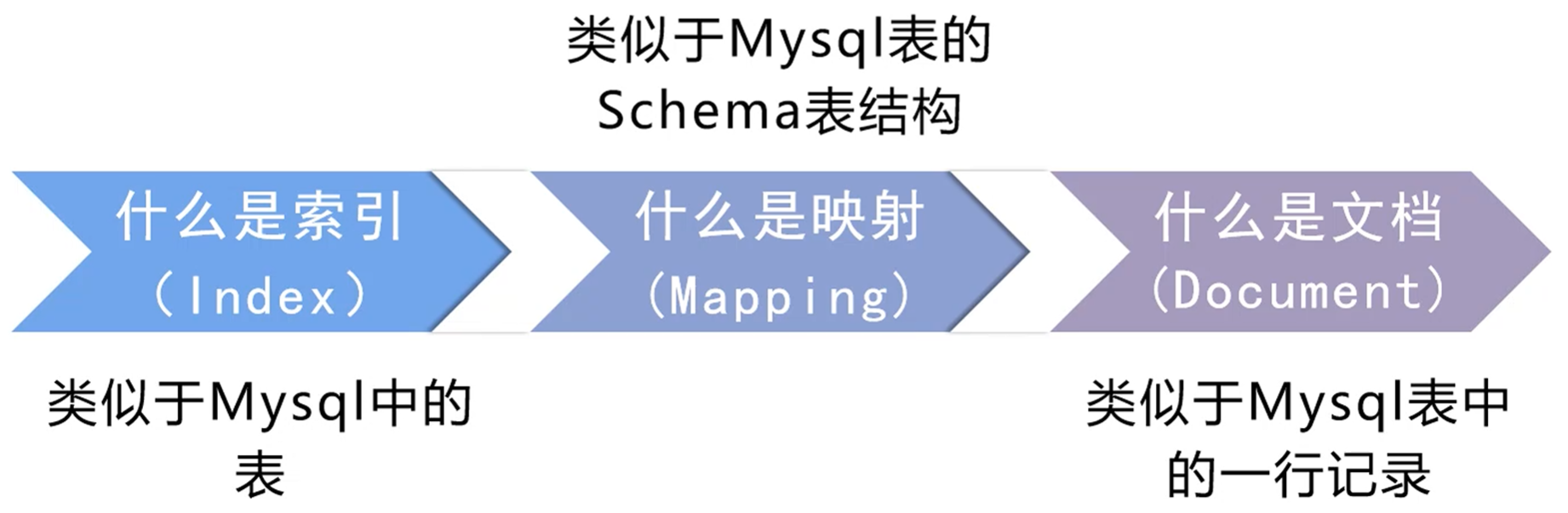
索引:索引是Elasticsearch中用于存储和管理相关数据的逻辑容器。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
注意:在Elasticsearch 6.X之前的版本中,索引类似于SQL数据库,而type(类型)类似于表。然而,从ES 7.x版本开始,类型已经被弃用,一个索引只能包含一个文档类型
映射:ES 中的 mapping 有点类似与关系数据库中表结构的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在 ES 中一个字段可以有多个类型。
文档:作为Elasticsearch的基本存储单元,文档是指存储在Elasticsearch索引中的JSON对象。文档中的数据由键值对构成。
类比关系总结
| Elasticsearch | MySQL | 一句话解释 |
|---|---|---|
| 索引(Index) | 表(Table) | 存放同一类数据的地方,比如“用户表”或“商品表”。 |
| 映射(Mapping) | 表结构(Schema) | 定义每个字段的类型和规则,比如“年龄是数字,名字是文本”。 |
| 文档(Document) | 一行记录(Row) | 具体的一条数据,比如“用户张三的信息”。 |
基础知识
全文检索:全文检索(Full-Text Search)是一种从大量文本数据中快速检索出包含指定词汇或短语的信息的技术。它允许用户输入一个或多个关键词,然后系统会在预先建立好的索引中查找包含这些关键词的文档或文档片段,并返回给用户。
倒排索引:在一个文档集合中,每个文档都可视为一个词语的集合,倒排索引则是将词语映射到包含这个词语的文档的数据结构。

索引操作
实战场景
①将采集到的不同业务类型的数据存储到不同的索引里面
微博业务对应的索引weibo_index。
新闻业务对应的索引news_index。
博客业务对应的索引blog_index
②按日期切分存储日志索引
2024年7月的日志对应logs_202407。
2024年8月的日志对应logs_202408。
基本操作

创建索引
创建索引的方式分为两种,一种是在创建索引的同时就将集群的参数信息以及映射的参数信息就配置好;另外一种就是直创建索引,使用系统自带的参数(默认是分片1,副本1);当然在后续通过这两种方式创建的索引都可以被修改
#创建索引的基本语法示例
PUT /index_name
{
"settings": {
// 索引设置
},
"mappings": {
"properties": {
// 字段映射
}
}
}
#创建索引
PUT /myindex
参数说明:
索引名称 (index_name) 索引名称必须是小写字母,可以包含数字和下划线。
索引设置 (settings)
1)分片数量 (numberofshards) 一个索引的分片数决定了索引的并行度和数据分布
"number_of_shards": 1
2)副本数量 (numberofreplicas) 副本提高了数据的可用性和容错能力。
"number_of_replicas": 1
映射 (mappings) 字段属性 (properties)定义索引中文档的字段及其类型。常用属性包括:
type:数据类型
字符串:text、keyword
数字:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
index:是否进行倒排索引
analyzer:分词器
properties:子字段
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "keyword"
}
}删除索引
删除索引的方式就非常的简单,直接使用DELETE关键字进行删除就可以
DELETE /index_name
查询索引
查询索引包含两种,一种就是查询索引的相关信息,这种查询使用第一种粗略的查询方式就可以实现;另一种是查询索引中的文档信息,这种查询往往是需要进行更加精确的查询指定的,如第二种查询示例所示
//查询索引的基本语法示例
#粗粒度查询
GET /index_name
#细粒度查询
GET /index_name/_search
{
"query": {
// 查询条件
}
}
修改索引
修改索引包含两种,一种是修改原索引的settings参数,主要是有关集群参数的部分;一种是修改原索引的mapping参数,主要是有关索引数据的部分。切记只能进行索引结构的新增不能进行索引数据结构的改变(这样会使得建立的倒排索引全部失效,在企业级的开发中是不能使用的)
#修改索引的settings部分示例代码
PUT /index_name/_settings
{
"index": {
"setting_name": "setting_value"
}
}
#修改索引的mapping部分示例代码
PUT /index_name/_mapping
{
"properties": {
"new_field": {
"type": "field_type"
}
}
}
索引别名
索引别名可以指向一个或多个索引,并且可以在任何需要索引名称的API中使用。 别名提供了极大的灵活性,它允许用户执行以下操作:
在正在运行的集群上的一个索引和另一个索引之间进行透明切换。
对多个索引进行分组组合。
在索引中的文档子集上创建“视图”,结合业务场景,缩小了检索范围,自然会提升检索效率
应用场景

基本操作
设置别名的方式有两种,一种是在创建索引的时候指定其别名;第二种是在已经存在的索引上进行别名指定。跟据具体的情况来使用创建别名的方式。
//创建索引的时候指定别名
PUT myindex
{
"aliases": {
"myindex_alias": {}
},
"settings": {
"refresh_interval": "30s",
"number_of_shards": 1,
"number_of_replicas": 0
}
}
#在已有的索引上为它指定别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "index_name",
"alias": "alias_name"
}
}
]
}
多索引检索的实现方案
不使用别名的方式
#使用逗号的方式对多个索引进行分割
POST tlmall_logs_202401,tlmall_logs_202402,tlmall_logs_202403/_search
#使用通配符来实现
POST tlmall_logs_*/_search使用别名的方式
#使用别名关联索引
PUT tlmall_logs_202401
PUT tlmall_logs_202402
PUT tlmall_logs_202403
POST _aliases
{
"actions": [
{
"add": {
"index": "tlmall_logs_202401",
"alias": "tlmall_logs_2024"
}
},
{
"add": {
"index": "tlmall_logs_202402",
"alias": "tlmall_logs_2024"
}
},
{
"add": {
"index": "tlmall_logs_202403",
"alias": "tlmall_logs_2024"
}
}
]
}#使用别名进行检索
POST tlmall_logs_2024/_search使用别名检索效率与基于索引检索的对比:
若索引和别名指向相同,则在相同检索条件下的检索效率是一致的,因为索引别名只是物理索引的软链接的名称而已。 注意:
对相同索引别名的物理索引建议有一致的映射,以提升检索效率。
推荐充分发挥索引别名在检索方面的优势,但在写入和更新时还得使用物理索引。
文档操作
基本操作
新增文档
在ES8.x中,新增文档的操作可以通过POST或PUT请求完成,具体取决于是否指定了文档的唯一性标识(即ID)。如果在创建数据时指定了唯一性标识,可以使用POST或PUT请求;如果没有指定唯一性标识,只能使用POST请求。
使用POST请求新增文档 当不指定文档ID时,可以使用POST请求来新增文档,Elasticsearch会自动生成一个唯一的ID。语法如下:
POST /<index_name>/_doc
{
"field1": "value1",
"field2": "value2",
// ... 其他字段
}
使用PUT请求新增文档 当指定了文档的唯一性标识(ID)时,可以使用PUT请求来新增或更新文档。如果指定的ID在索引中不存在,则会创建一个新文档;如果已存在,则会替换现有文档。语法如下:
PUT /<index_name>/_doc/<document_id>
{
"field1": "value1",
"field2": "value2",
// ... 其他字段
}
PUT和POST的区别 在Elasticsearch 8.x中,PUT和POST请求在新增文档时的行为有所不同,主要体现在以下几个方面:
指定文档ID: PUT请求在创建或更新文档时必须指定文档的唯一ID。如果指定的ID已经存在,PUT请求会替换现有文档;如果不存在,则创建一个新文档。 POST请求在创建新文档时可以指定ID,也可以不指定。如果不指定ID,Elasticsearch会自动生成一个唯一的ID。
幂等性: PUT请求是幂等的,这意味着多次执行相同的PUT请求,即使是针对同一个文档,最终的结果都是一致的。 POST请求不是幂等的,多次执行相同的POST请求可能会导致创建多个文档。
更新行为: PUT请求在更新文档时会替换整个文档的内容,即使是文档中未更改的部分也会被新内容覆盖。 POST请求在更新文档时可以使用_update API,这样可以只更新文档中的特定字段,而不是替换整个文档。
批量新增文档
批量操作可以减少网络连接所产生的开销,提升性能
支持在一次API调用中,对不同的索引进行操作
# 批量操作示例 ## 插入文档 POST /<index_name>/_bulk { "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } } { "field1" : "value1", "field2" : "value2", ... } ## 更新文档 { "update" : { "_index" : "<index_name>", "_id" : "<document_id>" } } { "doc" : {"field1" : "new_value1", "field2" : "new_value2", ... }, "_op_type" : "update" } ## 删除文档 { "delete" : { "_index" : "<index_name>", "_id" : "<document_id>" } } ## 插入新文档 { "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } } { "field1" : "value1", "field2" : "value2", ... }操作中单条操作失败,并不会影响其他操作
返回结果包括了每一条操作执行的结果
在Elasticsearch 8.x中,批量新增文档可以通过bulk API来实现。这个API允许您将多个索引、更新或删除操作组合成一个单一的请求,从而提高批量操作的效率。 以下是使用bulk API的基本语法(或者参考上方的示例):
POST /<index_name>/_bulk
{ "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }
{ "update" : { "_index" : "<index_name>", "_id" : "<document_id>" } }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2", ... }, "_op_type" : "update" }
{ "delete" : { "_index" : "<index_name>", "_id" : "<document_id>" } }
{ "index" : { "_index" : "<index_name>", "_id" : "<optional_document_id>" } }
{ "field1" : "value1", "field2" : "value2", ... }
每个操作都是一个独立的JSON对象,这些对象交替出现,形成一个请求体。每个index操作后面跟着的是要索引的文档内容,update操作包含了更新的文档内容和操作类型,而delete操作则直接指明要删除的文档ID。每个操作对象的开头都必须是index、update或delete,并且每个操作之间用一个空行分隔。
bulk API支持哪些操作类型? Elasticsearch的bulk API支持以下四种操作类型:
Index: 用于创建新文档或替换已有文档。
Create: 如果文档不存在则创建,如果文档已存在则返回错误。
Update: 用于更新现有文档。
Delete: 用于删除指定的文档。
这些操作可以在单个_bulk API调用中对不同的索引进行,而且即使在批量操作中单条操作失败,也不会影响其他操作的执行。返回结果通常包括了每一条操作的执行结果,以便客户端能够处理成功或失败的情况.
查询文档
①跟据id查询文档
在Elasticsearch 8.x中,根据文档的ID查询单个文档的标准语法是使用GET请求配合文档所在的索引名和文档ID。以下是具体的请求格式:
GET /<index_name>/_doc/<document_id>
在Elasticsearch 8.x中,使用Multi GET API可以根据ID查询多个文档。该API允许您在单个请求中指定多个文档的ID,并返回这些文档的信息。以下是Multi GET API的基本语法:
GET /<index_name>/_mget
{
"ids" : ["id1", "id2", "id3", ...]
}
②跟据关键词查询文档
在Elasticsearch 8.x中,查询文档通常使用Query DSL(Domain Specific Language),这是一种基于JSON的语言,用于构建复杂的搜索查询。
GET /es_db/_search
{json请求体数据}
以下是一些常用的查询语法:
1.匹配所有文档
GET /<index_name>/_search
{
"query": {
"match_all": {}
}
}
2.文本字段匹配
GET /<index_name>/_search
{
"query": {
"match": {
"<field_name>": "<query_string>" #需要匹配的字段名与值
}
}
}
3.精确匹配(不分词)
GET /<index_name>/_search
{
"query": {
"term": {
"<field_name>": { #精确匹配的字段名称
"value": "<exact_value>" #精确匹配的具体值
}
}
}
}
4.范围查询
GET /<index_name>/_search
{
"query": {
"range": {
"<field_name>": { #指定要查询的字段名称。
"gte": <lower_bound>, #范围查询的下限值。
"lte": <upper_bound> #范围查询的上限值。
}
}
}
}
删除文档
①删除单个文档
在Elasticsearch 8.x中,删除单个文档的基本HTTP请求语法是:
DELETE /<index_name>/_doc/<document_id>
②批量删除文档
在Elasticsearch 8.x中,删除多个文档可以通过两种主要方法实现:
使用 _bulk API
_bulk API允许您发送一系列操作请求,包括删除操作。每个删除请求是一个独立的JSON对象,格式如下:
POST /_bulk
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
{ "delete": {"_index": "{index_name}", "_id": "{id}"} }
使用 _delete_by_query API
_delete_by_query API允许您根据查询条件删除文档。如果您想删除特定索引中匹配特定查询的所有文档,可以使用以下请求格式:
POST /{index_name}/_delete_by_query
{
"query": {
"<your_query>"
}
}
更新文档
①增量修改
在Elasticsearch 8.x版本中,更新操作通常通过_update接口执行,该接口允许您部分更新现有文档的字段。增量修改,只修改指定的字段,未指定的字段保持不变。以下是更新文档的基本语法:
POST /{index_name}/_update/{id}
{
"doc": {
"<field>: <value>"
}
}
②全量修改
基本的执行流程是,先通过索引id查询到对应的文档信息,再通过删除文档的手段将新的文档插入到对应的索引中实现修改全量修改操作。
put /索引库名/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
//...略
}
③批量更新文档
在Elasticsearch 8.x中,更新多个文档可以通过两种主要方法实现:
使用 bulk API
POST /_bulk
{ "update" : {"_index" : "<index_name>", "_id" : "<document_id>"} }
{ "doc" : {"field1" : "new_value1", "field2" : "new_value2"}, "upsert" : {"field1" : "new_value1", "field2" : "new_value2"} }
...
在这个请求中,每个update块代表一个更新操作,其中index和id指定了要更新的文档,doc部分包含了更新后的文档内容,upsert部分定义了如果文档不存在时应该插入的内容。
使用 update_by_query API
update_by_query API允许您根据查询条件更新多个文档。这个操作是原子性的,意味着要么所有匹配的文档都被更新,要么一个都不会被更新。
POST /<index_name>/_update_by_query
{
"query": {
<!-- 定义更新文档的查询条件 -->
},
"script": {
"source": "ctx._source.field = 'new_value'",
"lang": "painless"
}
}
在这个请求中,<index_name>是您要更新的索引名称,query部分定义了哪些文档需要被更新,script部分定义了如何更新这些文档的字段。
③并发场景下更新文档如何保证线程的安全性
在Elasticsearch 7.x及以后的版本中,seq_no和primary_term取代了旧版本的version字段,用于控制文档的版本。seqno代表文档在特定分片中的序列号,而primary_term代表文档所在主分片的任期编号。这两个字段共同构成了文档的唯一版本标识符,用于实现乐观锁机制,确保在高并发环境下文档的一致性和正确更新。
当在高并发环境下使用乐观锁机制修改文档时,要带上当前文档的seq_no和primary_term进行更新:
POST /employee/_doc/1?if_seq_no=13&if_primary_term=1
{
"name": "张三xxxx",
"sex": 1,
"age": 25
}如果seq_no和primary_term不对,会抛出版本冲突异常:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]",
"index_uuid": "7JwW1djNRKymS5P9FWgv7Q",
"shard": "0",
"index": "employee"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [13], primary term [1]. current document has seqNo [14] and primary term [1]",
"index_uuid": "7JwW1djNRKymS5P9FWgv7Q",
"shard": "0",
"index": "employee"
},
"status": 409关联关系
Elasticsearch(ES)作为分布式搜索引擎,其设计核心是快速检索而非处理复杂关联关系。但它仍提供了多种方案来应对不同场景下的数据关联需求。
一、嵌套类型(Nested)
原理 将子文档作为独立隐藏文档嵌入父文档,解决对象数组扁平化问题。 适用场景
一对多关系,子对象需独立查询(如订单中的商品)
子数据更新频率低,需与父文档强一致
//创建示例
PUT orders
{
"mappings": {
"properties": {
"products": {
"type": "nested",
"properties": {
"name": {"type": "keyword"},
"price": {"type": "double"}
}
}
}
}
}
//查询示例
GET orders/_search
{
"query": {
"nested": {
"path": "products",
"query": {
"bool": {
"must": [
{"term": {"products.name": "Laptop"}},
{"range": {"products.price": {"gte": 1000}}}
]
}
}
}
}
}二、父子文档(Parent-Child)
原理 通过join类型建立逻辑关联,父子文档独立存储。 适用场景
频繁更新子文档(如博客评论)
一对多且子数据规模大
//创建示例
PUT blog
{
"mappings": {
"properties": {
"post_comment": {
"type": "join",
"relations": {"post": "comment"}
}
}
}
}
//查询示例
GET blog/_search
{
"query": {
"has_child": {
"type": "comment",
"query": {"match": {"text": "Elasticsearch"}}
}
}
}