本文目录:
一、人工智能三大概念
AL:人工智能,像人一样机器智能的综合与分析;机器模拟人类;
ML:机器学习,让机器自动学习,而不是基于规则的编程(不依赖特定规则编程);
DL:深度学习,也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物。
三者关系:机器学习是实现人工智能的一种途径,深度学习是机器学习的一种方法。
二、学习方式
基于规则的预测 : 程序员根据经验利用手工的if-else方式进行预测;
基于模型的学习:通过编写机器学习算法,让机器自己学习从历史数据中获得经验、训练模型。
三、人工智能发展史
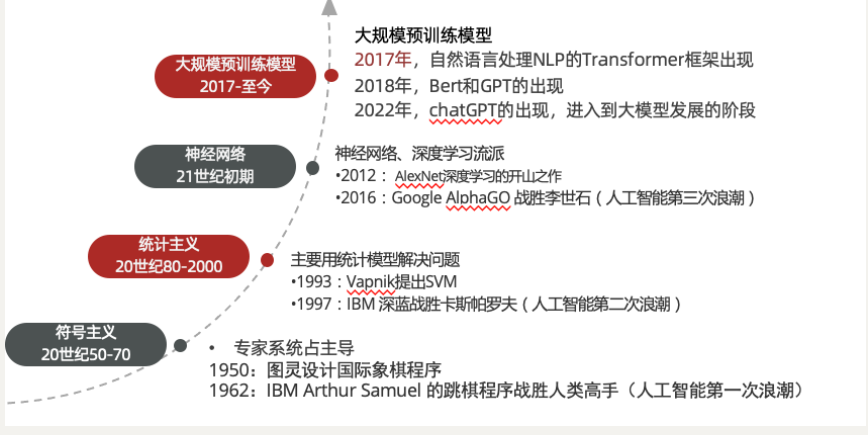
1956年被认为是人工智能元年。
“ 1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。”
1950-1970
符号主义流派:专家系统占主导地位
1950:图灵设计国际象棋程序
1962:IBM Arthur Samuel 的跳棋程序战胜人类高手(人工智能第一次浪潮)
1980-2000
统计主义流派:主要用统计模型解决问题
1993:Vapnik提出SVM
1997:IBM 深蓝战胜卡斯帕罗夫(人工智能第二次浪潮)
2010-2017
神经网络、深度学习流派
2012:AlexNet深度学习的开山之作
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
2017-至今
大规模预训练模型
2017年,自然语言处理NLP的Transformer框架出现
2018年,Bert和GPT的出现
2022年,chatGPT的出现,进入到大规模模型AIGC发展的阶段
四、机器学习三要素
数据:是算法的基石和载体;
算法:是实现业务需求的思路和方法;
算力:是算法效率。
数据、算法、算力三要素相互作用,是AI发展的基石。
五、常见术语
样本:一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录;
特征:是从数据中抽取出来的,对结果预测有用的信息,有时也被称为属性;
标签/目标:模型要预测的那一列数据。
六、数据集的划分
数据集可划分两部分:训练集、测试集 比例:8 : 2,7 : 3
训练集(training set) :用来训练模型(model)的数据集;
测试集(testing set):用来测试模型的数据集。
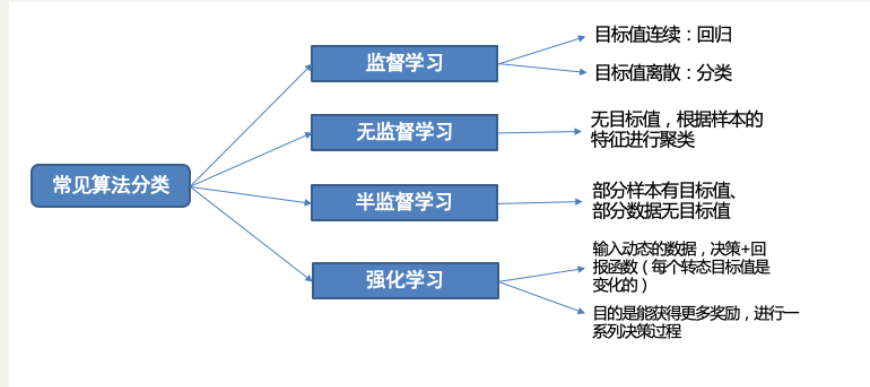
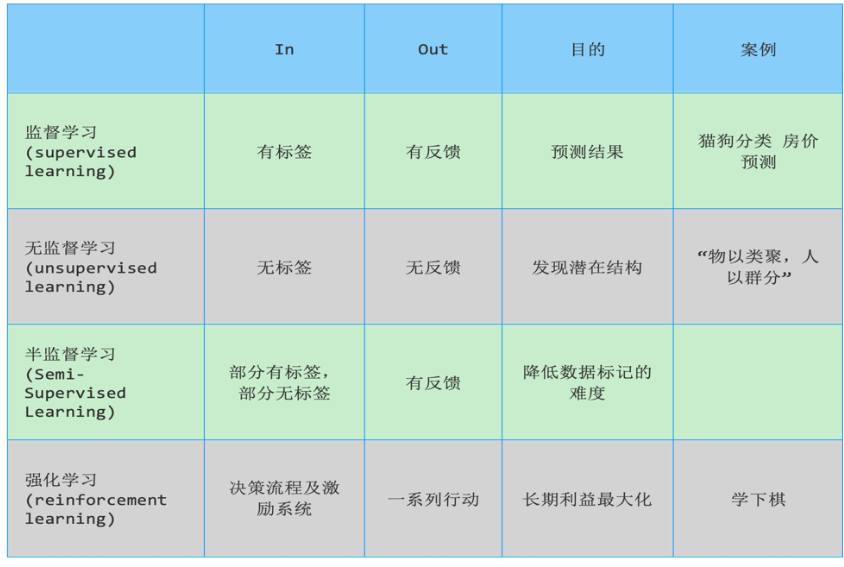
七、常见算法分类
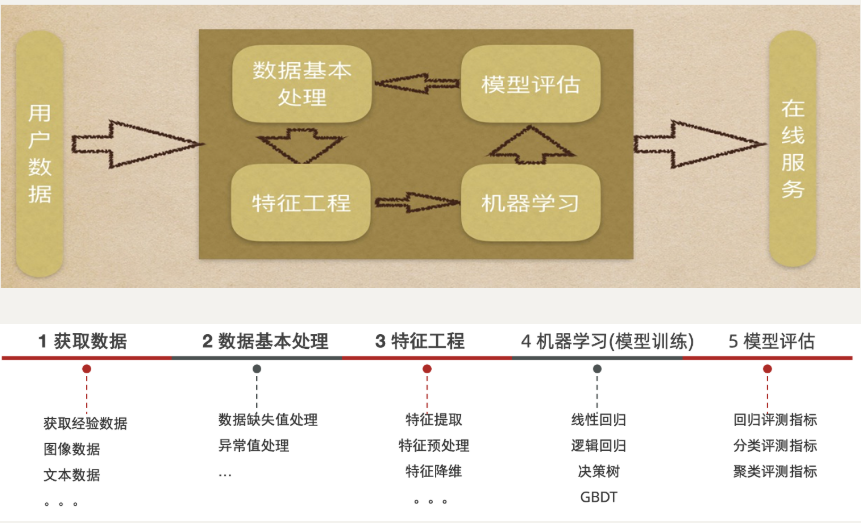
八、机器学习的建模流程
九、特征工程
特征工程:利用专业背景知识和技巧处理数据,让机器学习算法效果最好。
数据和特征决定了机器学习的上限,而模型和算法不断逼近这个上限。
特征工程包括五大步:
(一)特征提取:从原始数据中提取与任务相关的特征,构成特征向量;
(二)特征预处理:将不同单位的特征数据转换成同一个范围内;
(三)特征降维:将原始数据的维度降低;
(四)特征选择:根据一些指标从特征中选择出一些重要特征;
(五)特征组合:通过乘法、加法等方法把多个的特征合并成单个特征。
特征工程的作用:
提升模型性能:让特征更适配算法(如线性模型需要数值特征,树模型可处理类别特征)。
降低计算成本:减少冗余特征,加速训练。
增强可解释性:通过构造有意义的特征帮助理解数据。
特征工程的注意事项:
避免数据泄露:所有特征工程(如标准化、编码)应在训练集上拟合后,再应用到测试集。
评估特征效果:通过交叉验证对比工程前后的模型性能。
平衡自动化与领域知识:自动化工具(如FeatureTools)可提高效率,但人工构造的特征往往更关键。
十、模型拟合问题
- 1.拟合:找到模型参数(如KNN中的 n_neighbors)的最优值,使模型在训练数据上表现良好,同时能泛化到新数据。
- 2.欠拟合:模型在训练集上表现很差、在测试集表现也很差。
原因:模型过于简单。
- 3.过拟合:模型在训练集上表现很好、在测试集表现很差。
原因:模型太过于复杂、数据不纯、训练数据太少。
- 泛化:模型在新数据集(非训练数据)上的表现好坏的能力。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。
今天的分享到此结束。