大家读完觉得有帮助记得及时关注和点赞!!!
抽象
传统的安全检测方法难以跟上针对关键基础设施和敏感数据的快速发展的网络威胁形势。这些方法存在三个关键限制:非面向安全的系统活动数据收集无法捕获关键安全事件,不断增长的安全监控需求导致监控系统不断扩大,从而导致资源消耗过度,以及检测算法不足导致无法准确区分恶意和良性活动,从而导致高误报率。
为了应对这些挑战,我们推出了 FEAD ,这是一个攻击检测框架,通过专注于识别和补充安全关键型监控项目并在数据收集期间有效部署它们,以及在异常分析期间潜在异常实体的位置及其周围邻居来改进检测。
FEAD 包含三项关键创新:
(1) 一种攻击模型驱动的方法,从在线攻击报告中提取安全关键型监控项,从而实现更全面的监控项框架;
(2) 高效的任务分解机制,可在现有收集器之间优化分配监控任务,最大限度地提高可用监控资源的利用率,同时最大限度地减少额外的监控开销;
(3) 一种局部感知异常分析技术,利用恶意活动在主动攻击阶段在来源图中形成密集集群的特性,指导我们检测算法中的顶点级权重机制,更好地区分异常顶点和良性顶点,从而提高检测准确率并减少误报。
评估显示,FEAD 的性能优于现有解决方案,F1 分数高出 8.23%,开销高出 5.4%。我们的消融研究还证实,FEAD 基于焦点的设计显著提高了检测性能。
介绍
各种规模的现代计算系统越来越多地成为 APT 攻击等高级网络威胁的目标,这带来了重大的安全挑战。传统的安全措施往往无法解决这些不断演变的威胁,促使学术界和工业界将重点放在轻量级攻击检测系统上。这些系统通常利用运行时日志审计和分析实现有效的安全监控和攻击检测。其中包括基于异常的检测方法,通过分析历史日志来识别与已建立的良性模式的偏差,已成为一种很有前途的解决方案,从而有效应对检测新型和不断发展的攻击变体的挑战。 虽然这些方法显示出前景,但它们面临三个关键挑战:
❶ 缺乏面向安全的高效监控。现有的监控工具(例如,auditd[7,8,9]) 主要是为了性能或故障诊断而设计的,而不是为了安全性。它们侧重于系统故障和资源使用情况,对安全相关活动的可见性有限。尽管像 eAudit 这样的努力[10]尝试通过使用 eBPF 并整合现有监视器(例如 Trace[11]),它们仍然缺乏捕获更高级别安全事件的能力。auditbeat 等企业工具[12]提供一些增强功能,但严重依赖专家优化。缺乏识别关键安全监控点的系统框架会导致覆盖不完整和安全盲点。
❷ 安全监控任务部署成本高。不断演变的威胁需要频繁更新监控策略,通常需要新的监控模块来满足每个新的安全监控要求,并增加系统复杂性。此外,没有一个工具可以满足所有需求,迫使组织部署多个系统,从而导致冗余和性能下降。
❸ 基于异常的攻击检测中的误报率高。当前的检测系统通常难以准确区分合法的系统更改和真正的安全威胁,因为良性和恶意节点在监控数据中经常表现出类似的行为模式。例如,更改网络流量的例行更新或维护活动可能与攻击签名非常相似,从而导致误报。监控盲点会限制可见性并降低系统区分正常变化和实际威胁的能力,从而进一步加剧此问题。这种较差的区分会导致安全团队的警报疲劳,并降低安全监控在企业环境中的实际效用。
为了应对这些挑战,我们提出了 FEAD(焦点增强攻击检测),这是一个通过关注两个关键方面来改进检测的框架:识别和补充安全关键型监控项,然后在数据收集期间有效地部署它们,以及在异常检测期间分析潜在异常实体的位置及其周围的邻居。这种双重关注确保了有针对性、有效的攻击检测,同时最大限度地减少了系统开销。具体来说,对于挑战 1,FEAD 使用攻击效果模型和大型语言模型来分析攻击报告,分解攻击步骤并评估它们对系统和软件的影响,以确定关键监控项。 这种方法通过系统地从实际攻击中提取监控要求来确保全面监控。对于挑战 2,FEAD 引入了一种新的任务分解机制,该机制可以分解复杂的任务并将其分配给现有的收集器,从而协作实现目标监控目标。这最大限度地利用了内置监控功能,同时最大限度地减少了新模块的部署,从而降低了系统开销。对于挑战 3,FEAD 利用来源图中的攻击位置,其中恶意活动在活动阶段形成密集集群,在其他阶段形成稀疏集群。这种洞察力指导检测算法中的顶点级加权机制,重点关注异常顶点及其邻居。与以前不加选择地分析所有顶点的方法不同,FEAD 的方法增强了对良性和恶意行为的区分,针对高风险区域,并在减少误报的同时提高了准确性。
评估表明 FEAD 的卓越性能,与现有解决方案相比,F1 分数平均高出 8.23%,开销低至 5.4%。我们的消融研究进一步验证了我们基于焦点的设计的有效性,表明集成面向安全的监控框架将 F1 分数提高了 12.63% 以上,而利用攻击局部模式实现了 9.52% 的改进。这些结果凸显了 FEAD 在保持系统效率的同时提高检测准确性的能力,使其成为真实世界攻击检测的有前途的解决方案。
我们总结了我们的核心贡献如下:
- •
提出一个攻击检测框架,该框架集成了面向安全的监控和位置感知异常分析,以提高检测准确性。
- •
开发高效的任务分解机制,在最小化开销的同时优化监控覆盖率,以 5.4% 的开销实现全面的安全监控。
- •
评估 FEAD,显示 F1 评分比现有解决方案提高了 8.23%,消融研究证实了监测增强 (12.63%) 和基于局部的检测 (9.52%) 的显着收益。
第二背景和相关工作
II-A 型预赛
攻击效果模型。攻击效果模型被定义为攻击步骤的有序序列T=[(T1,E1),(T2,E2),…,(Tn,En)],其中每个T我表示三元组⟨一个ctor我,一个ct我on我,t一个rget我⟩描述谁对哪个目标执行了什么作,以及E我表示相应的系统影响(例如,Program Execution、File Modification)。每个攻击步骤(T我,E我)可以映射到一组监控项M我检测系统影响所需的。这些步骤按时间顺序排序,以反映攻击的时间进度。
Provenance Graph(来源图)。在系统安全监控中,Provenance 图通过转换审计日志(例如,Linux Auditd[7]) 转换为捕获系统实体和 Activity 之间因果关系的图形。来源图是有向图G=(V,E)哪里V表示系统实体(例如,进程、文件、套接字)和E表示它们之间的交互。具体说来V={v|v∈(Process∪F我le∪Socket)}和E⊆V×V×T捕获实体之间的关系,其中T表示实体行为的类型(例如,读取、写入、执行)。 此结构支持对系统行为进行详细跟踪,有助于进行攻击检测、取证分析和攻击调查。
II-B 型威胁模型
与之前关于来源跟踪和威胁检测的研究类似[13,14,15,16,17,18,19],我们将作系统内核和安全监控组件视为我们的可信计算基础 (TCB) 的一部分。我们假设收集到的来源数据是可靠的,并且没有被攻击者篡改。尽管攻击者可能会试图破坏系统或破坏监控组件,但此类破坏活动可以在被破坏之前在日志中捕获。我们的重点是检测利用应用程序漏洞或利用社会工程技术未经授权访问受害者系统以进行数据泄露或纵的攻击,而不是基于硬件或侧信道的攻击。
我们假设系统最初处于良性状态,攻击源自企业网络外部。攻击者通常通过远程网络利用、泄露的凭据或社会工程获得初始访问权限,并继续执行多阶段作,其中可能包括信息收集、利用易受攻击的软件、有效负载部署、权限提升和横向移动。我们的方法侧重于识别系统行为数据中的这些攻击模式。
II-C 型系统监控工具
我们通过研究现有的系统监控工具来确定它们在安全监控应用程序中的能力和局限性来激发我们的研究。
II-C1 号使用 Snowball 技术进行系统化的工具收集
此方法从 Linux Auditd 开始 [7]作为初始种子,因为它作为 Linux 的默认审计工具而普遍存在。我们构建了一个结构化查询模板,结合了 (1) 与场景相关的术语(例如,“出处图”、“因果图”),(2) 与功能相关的术语(例如,“数据收集”、“日志收集”),以及 (3) 工具名称(例如,“审计”)。然后,我们使用此模板(例如,(出处图或因果图 OR 法医分析或调查)和(数据收集或日志收集)AND Auditd)在多个学术数据库(即 Google Scholar、IEEE Xplore 和 ACM 数字图书馆)中执行系统检索,并删除不相关的文献以构建标准化数据库。
然后,两位具有 3-5 年相关经验的合著者从收集的文献中提取监测工具。新发现的工具被添加到查询模板(即组件 (3))中,并用于后续的搜索迭代,从而扩大了我们的搜索范围,以捕获引用这些新发现工具的文献。当连续两轮没有新工具出现或搜索队列用尽时,该过程将终止。这种迭代方法有效地解决了监控工具的碎片化和快速发展问题。
表 I:系统监控工具使用情况统计
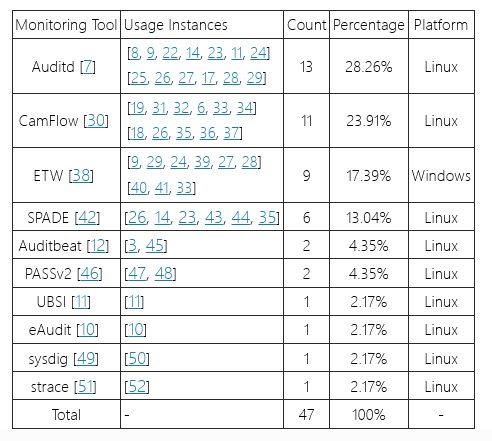
II-C2 型工具收集结果
我们的雪球搜索技术产生了全面的结果,如表 I 所示。统计数据表明,在 Linux 生态系统中,Auditd 是使用最广泛的监控工具,出现在 13 篇论文中 (28.26%) 并排名第一。CamFlow 紧随其后,在 11 篇论文中使用 (23.91%)。对于 Windows 平台,ETW (Event Tracing for Windows) 是主要工具,在 9 篇论文中使用 (17.39%)。 根据我们的分析,我们将这些监控工具分为三大类:
- 1.
全系统来源收集工具(CamFlow、SPADE、PASSv2):这些工具专注于系统级数据流和因果关系跟踪。例如,CamFlow 通过集成 Linux 安全模块 (LSM) 和 NetFilter 来实现高效监控,而 SPADE 则利用 Linux Auditd 日志构建支持分布式环境的来源图。PASSv2 是基于 Linux 2.6 内核(约 2009 年)的分层来源架构,它通过统一的披露来源 API 跨多个抽象层集成来源,展示了尽管受到传统技术限制,但跨层来源收集的早期方法。
- 2.
审计工具(Auditd、Sysdig、ETW、Auditbeat、eAudit):这些工具记录系统行为以支持安全分析和合规性审计。Auditd 是 Linux 的默认审计框架,Sysdig 使用内核模块进行事件捕获,ETW 是 Windows 的标准审计工具,Auditbeat 通过现代功能扩展了 Auditd,而 eAudit 将 Auditd 与 eBPF 技术相结合。
- 3.
细粒度信息收集工具(UBSI、strace):这些工具专注于精确监控特定的系统行为。UBSI 通过静态分析提供单元级行为监控,而 strace 则记录进程与作系统之间详细的系统调用级交互。
在实际应用中,全系统来源收集和审计工具可以直接构建来源图,而细粒度信息收集工具通常通过提供来源图中关键节点的详细参数信息来补充前者。
II-C3 号安全监控能力分析
表 II:系统调用和关系场景分类
| 场景 | 不。 | 监控事件 | 描述 | 源 |
| 文件操作 | 1 | 读 | 读取文件内容 | 审计 |
| 2 | RL_READ | 读取 inode | 凸轮 | |
| 3 | 写 | 写入文件内容 | 审计 | |
| 4 | RL_WRITE | 写入 inode | 凸轮 | |
| 5 | 打开 | 打开文件 | 审计 | |
| 6 | 关闭 | 关闭文件 | 审计 | |
| 目录操作 | 7 | 创造 | 创建新的空文件 | 审计 |
| 8 | 取消链接 | 删除文件 | 审计 | |
| 9 | 链接 | 创建硬链接 | 审计 | |
| 10 | 林卡特 | 创建相对路径硬链接 | 审计 | |
| 11 | 取消链接 | 删除相对目录中的文件 | 审计 | |
| 12 | rmdir | 删除目录 | 审计 | |
| 13 | mkdir | 创建目录 | 审计 | |
| 14 | RL_INODE_CREATE | 创建 inode | 凸轮 | |
| 过程操作 | 15 | 叉 | 创建新流程 | 审计 |
| 16 | 克隆 | 创建新进程(共享地址空间) | 审计 | |
| 17 | 执行 | 执行新程序 | 审计 | |
| 18 | RL_CLONE_MEM | 克隆期间的内存复制 | 凸轮 | |
| 19 | RL_SETUID | 设置 User ID | 凸轮 | |
| 20 | RL_SETGID | 设置进程组 ID | 凸轮 | |
| 21 | 杀 | 发送信号 | 审计 | |
| IO 控制 | 22 | RL_READ_IOCTL | IO 控制读取作 | 凸轮 |
| 23 | RL_WRITE_IOCTL | IO 控制写入作 | 凸轮 | |
| 24 | 管 | 创建管道 | 审计 | |
| 25 | FCNTL | 文件控制作 | 审计 | |
| 网络操作 | 26 | 插座 | Create socket (创建套接字) | 审计 |
| 27 | RL_SOCKET_CREATE | Create socket (创建套接字) | 凸轮 | |
| 28 | RL_SOCKET_PAIR_创造 | 创建 socket 对 | 凸轮 | |
| 29 | 连接 | 连接到远程主机 | 审计 | |
| 30 | RL_CONNECT | 套接字连接作 | 凸轮 | |
| 31 | RL_BIND | 套接字绑定作 | 凸轮 | |
| 32 | RL_LISTEN | 套接字侦听作 | 凸轮 | |
| 33 | RL_ACCEPT | 套接字接受连接作 | 凸轮 | |
| 34 | SendTo | 向指定地址发送数据 | 审计 | |
| 35 | recv从 | 从指定地址接收数据 | 审计 | |
| 36 | 发送消息 | 发送消息 | 审计 | |
| 37 | 发送MMSG | 发送多条消息 | 审计 | |
| 38 | recvmsg | 接收消息 | 审计 | |
| 39 | recvmmsg | 接收多条消息 | 审计 | |
| 40 | getpeername | 获取所连接套接字的远程地址 | 审计 | |
| 记忆操作 | 41 | 重复 | 重复的文件描述符 | 审计 |
| 42 | 重复2 | 将文件描述符复制到指定的描述符 | 审计 | |
| 43 | RL_MMAP | 内存映射挂载 | 凸轮 | |
| 44 | RL_MMAP_PRIVATE | 私有内存映射挂载 | 凸轮 | |
| 45 | RL_SH_READ | 共享内存读取作 | 凸轮 | |
| 46 | RL_PROC_READ | 读取进程内存 | 凸轮 | |
| 消息队列 | 47 | mq_open | 打开消息队列 | 审计 |
| 48 | RL_MSG_CREATE | 创建消息 | 凸轮 | |
| 系统装载 | 49 | RL_LOAD_FILE | 将文件加载到内核 | 凸轮 |
| 50 | RL_LOAD_FIRMWARE | 将固件加载到内核 | 凸轮 | |
| 51 | RL_LOAD_MODULE | 将模块加载到内核 | 凸轮 | |
| 52 | RL_VERSION | Connect 实体对象版本 | 凸轮 |
为了评估这些工具的监控能力,我们选择了两个使用最广泛的系统监控工具并分析了它们的监控能力。 根据表 I 中的统计数据,Auditd 和 CamFlow 是采用最广泛的来源图构建工具。这两个工具具有互补的监控能力:Auditd 使用系统调用跟踪机制来监控文件作、进程行为和网络通信等基本事件,而 CamFlow 则利用 LSM 框架提供更精细的实体关系跟踪,涵盖内存作、IO 控制和系统加载场景。 我们首先将他们的监控能力分为八大维度:文件作、目录作、进程控制、IO 管理、网络通信、内存作、消息队列和系统加载。 表 II 显示了这些工具涵盖的监控事件的详细信息。然后,通过我们的分析,我们确定了每个工具的监控重点和局限性。 基于对表 II 中所示监控事件的综合分析,我们可以得出以下结论:
需求差距:原始设计目标与安全监控需求不一致。 我们的分析表明,现有工具与安全监控要求存在重大不一致。从表 II 中可以明显看出,Auditd 和 CamFlow 最初都是为通用系统监控而设计的,而不是针对特定安全的监控。该表显示,这两种工具都没有充分涵盖与安全相关的关键作,例如环境变量作,这些作经常在攻击中被利用[53].
碎片化的监控生态系统:没有统一的系统提供全面的覆盖。如表 II 所示,没有一个监测系统能够全面实现所有必要的监测功能。例如,Auditd 在 System Loading 维度(第 49-52 项)的覆盖率较弱,而 CamFlow 在这方面表现出色。相反,CamFlow 显示对目录作(第 7-14 项)的监控不完整,Auditd 对此进行了广泛介绍。我们更深入的调查发现,Auditbeat 等安全优化型监控工具试图通过增强 Auditd 对系统事件(用户登录等)和文件完整性监控的支持来解决这些差距[54].然而,这些增强功能主要以专家经验为指导,而不是系统化的方法,这不可避免地导致了常见的安全相关作的盲点。例如,尽管 Auditbeat 注重安全,但它仍然无法监控环境变量作。这种碎片化凸显了迫切需要一种更系统的方法来设计安全监控功能。
我们对现有监控工具的分析揭示了需要立即关注的关键限制。需求差距和碎片化的监控生态系统对有效的安全监控构成了重大挑战。如果不加以解决,这些问题将导致持续的监控盲点,从而导致攻击检测和分析的准确性降低。此外,随着新的监控要求的出现,组织被迫开发自定义监控模块(增加开发成本)或同时部署多个重叠系统(导致冗余数据收集和性能下降)。这些挑战迫切需要:
- •
统一的监控框架,系统地覆盖与安全相关的作,以消除盲点并提高收集的数据和生成的来源图的质量,从而提高攻击检测的准确性。
- •
一种轻量级部署解决方案,可整合基本的监控功能,同时最大限度地减少资源消耗,使组织能够适应不断变化的安全要求,而不会产生令人望而却步的运营开销。
II-D 型基于 Provenance Graph 的异常检测
来源图因其能够捕获系统行为和因果关系而广泛用于异常检测。早期方法,例如 StreamSpot[55]和独角兽[19],依靠图形内核进行聚类,但在罕见异常中难以应对隐蔽的威胁和微妙的结构差异。 基于机器学习的方法[56,57,58]旨在仅使用良性数据从来源图中学习复杂的模式,但通常无法捕获关键结构信息,从而导致对细微或新威胁的检测不佳。 随着图神经网络 (GNN) 技术的快速发展[59],它们已成为来源图中异常检测的热门选择[18,17,60].GNN 可以捕获复杂的结构模式,适应动态系统,并扩展到大型数据集,从而提高检测准确性。但是,许多 GNN 方法对点和边的处理是统一的,难以区分良性和恶意行为,从而导致误报。这些挑战迫切需要:
- •
一个上下文感知检测框架,可根据语义上下文和关系智能地区分正常行为和可疑行为。
第三FEAD:焦点增强攻击检测
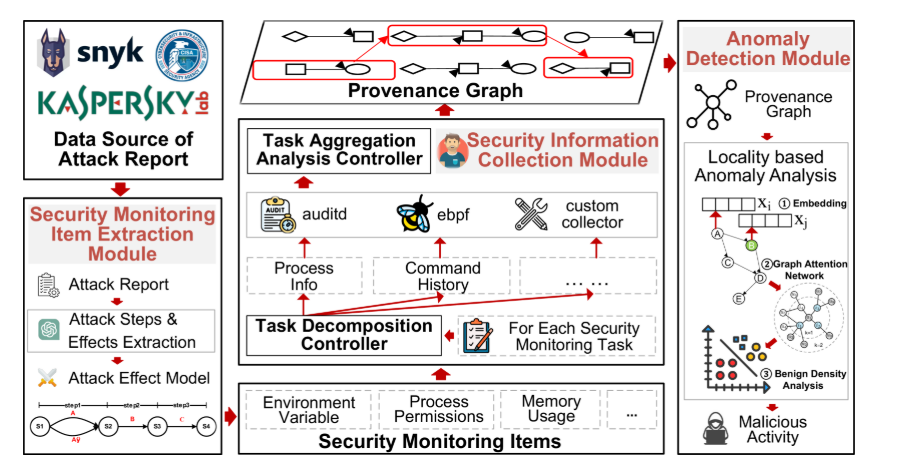
图 1:FEAD.
如图 1 所示。1、FEAD 通过三个关键组件解决了攻击检测中数据收集不面向安全、部署成本高、误报率高等挑战:(1) 安全监控项提取模块,利用攻击效果模型,通过分析攻击步骤和影响,从攻击报告中提取关键安全监控项;(2) 安全信息采集模块,采用自适应安全监控来分解复杂任务,在现有采集器之间分配子任务,并聚合数据进行综合分析,最大限度地减少系统开销;(3) 异常检测模块,它通过利用恶意活动的密集集群来应用基于位置的异常分析,同时在不同的攻击阶段保持稀疏。
III-A 系列Security Monitoring Item Extraction 模块
针对缺乏面向安全的高效监控的问题,我们提出了一种系统的方法,从在线攻击报告中识别安全关键型监控项。此方法涉及两个主要步骤:攻击报告收集和关键信息提取。
III-A1 号攻击报告收集
我们的攻击报告收集遵循两个主要步骤:报告爬取和报告过滤。
报告爬取。在数据采集阶段,我们从多个来源抓取了攻击报告,以构建一个全面的数据集。 以往研究为指导[61,62,63],我们开发了网络爬虫来收集来自 Snyk 等平台的报告[64]、Microsoft 安全智能中心[65]和 CISA[66]等(由于篇幅有限,我们的网站上提供了完整的列表[67]).为了扩大覆盖范围,我们还收录了来自 MITRE ATT&CK 知识库的攻击案例[68].
报告筛选。为了确保所收集报告的相关性和质量,我们根据预定义的标准对报告进行了严格筛选表 III。此过程涉及四位作者(具有 2-3 年的攻击检测经验)和两名行业专家(具有 7-8 年的网络安全经验)之间的合作。经过人工审查,最终数据集包括 260 份 APT 报告和 7,098 个攻击案例,涵盖 268 种 MITRE ATT&CK 技术(参考文献。[67]了解详情)。
表 III:纳入和排除标准
| 类型 | 描述 |
| 包含 | - 包含有关攻击步骤的技术详细信息- 与目标系统、环境或行业相关- 在过去 5 年内出版 |
| 排除 | - 重复的攻击报告- 报告长度不足(少于 200 字) |
III-A2 号关键信息提取
大型语言模型 (LLM) 的最新进展使其具有丰富的知识和语言理解能力,因此在信息提取方面非常有效[69,70,71].然而,LLM 仍然面临幻觉等挑战[72,73],这会影响提取精度。为了解决这个问题,我们使用了 Chain-of-Thought (CoT) 提示技术[74,75,76].通过设计推理流程,我们将复杂的提取任务分解为可管理的、更小的步骤,LLM 可以直接处理,从而减少幻觉,提高非结构化攻击报告向攻击效果模型的转换,并推理出相应的安全监控项。
第 1 步:攻击步骤提取我们要求 LLM 分析输入攻击报告文本 (I) 的句法结构,以识别主语-动词-宾语关系,形成三元组 (T =⟨ 一个ctor我,一个ct我on我,t一个rget我⟩),其中每个 triple 代表一个不同的起音步骤。 如图 1 所示。2,从“使用 IP 104.223.34.98 的威胁行为者获得了对受害者 2 生产环境的初始访问权限”中,我们形成了 (⟨ threat actors、Network Request、Victim 2 的生产环境⟩).
步骤 2:攻击效果识别攻击效果表示作对目标的影响,我们关注 (⟨ 一个ct我on我,t一个rget我⟩) 对。对于每一对,我们进一步要求 LLM 分析上下文以确定其对应的攻击效果(E我).例如,(⟨工具执行、PowerShell⟩) 触发器(E = 程序执行),指示对系统的行为影响。
第 3 步:监控监控项的生成对于每个 (⟨一个ct我on我,t一个rget我,E我⟩),LLM 最终生成相应的监控项(M我).如图所示,当 (E = Program Execution) 时,LLM 会生成 (M = Process creation monitoring)。
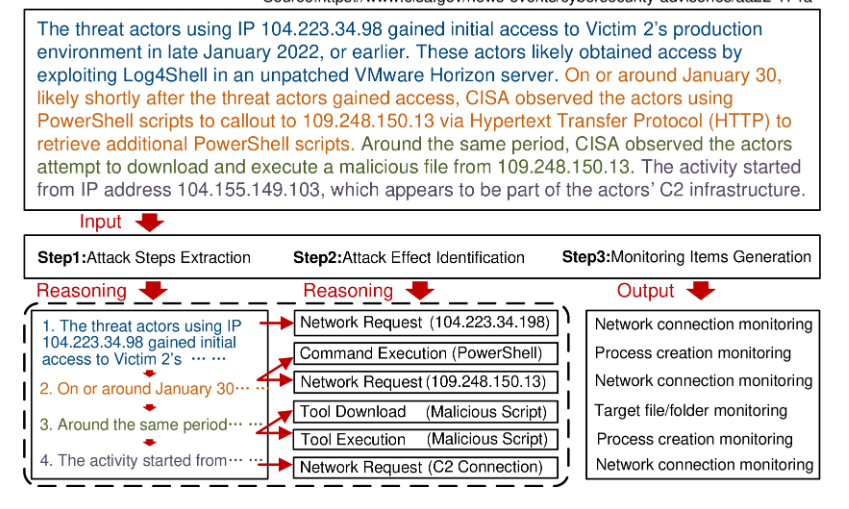
图 2:监控项生成的工作流。
通过将攻击报告文本 (I) 与我们设计的 CoT 提示 (参考 .[67]作为 LLM 的输入,指导 LLM 将攻击描述分解为结构化步骤,推理其系统影响,并得出相应的监控项。
III-B 型安全信息收集模块
在上一节中,我们通过分析攻击报告和应用攻击效果模型确定了安全关键型监控目标。但是,确定要监控的内容只是解决方案的一部分,实施这些监控器的成本仍然很高。
为了解决这个问题,我们提出了一种轻量级的协作安全监控架构。它系统地分解复杂的监控任务,并智能地将它们分配给现有的监控器。通过集成收集的数据以满足最初的目标,这种方法重用了现有功能,减少了对新监控模块的需求,从而最大限度地减少了性能开销。
以下部分首先介绍关键定义,然后介绍我们的任务分解、集成和部署方法。
III-C 系列安全监控能力的符号定义
为了实现我们的监控目标,我们建立了一个符号定义框架,该框架标准化了现有监控工具的功能和我们的监控目标的表示,从而实现了自动分析、任务分解、子任务的适当分配和结果集成。
通过对现有信息收集工具的分析,我们发现这些工具通常通过专门的日志解析算法收集数据以构建来源图。基于这一观察, 我们采用与这些工具和 Provenance Graph 兼容的符号表示格式,从而为定义监控功能提供了一个统一的框架。 这种设计确保了与现有系统的兼容性,同时支持子监控任务的标准化分解和集成。
具体来说,基于第 II-A 节中的 Provenance Graph 模型,我们将监控能力集定义为C={c1,c2,…,cn}.每个监控能力c我的特点是三元组⟨Vc,Oc,Tc⟩:
- •
Vc表示此监视功能可观察的系统实体集
- •
Oc表示受监视实体及其输出类别集的属性描述
- •
Tc表示此监控功能可观察到的系统事件类型集
对于实体属性集Oc在监控能力c我,我们定义:

哪里一个我表示受监控实体的属性,而t我表示该属性的数据类型。具体而言,属性数据类型包括:
- •
基本数据类型:整数 (ℤ)、实数 (ℝ)、布尔值 ({真,假})、字符串 (Σ∗)
- •
复合数据类型:列表、集合、键值对等。
- •
时间序列数据类型:以表单形式表示连续采样的量度值(t,v)哪里t表示时间戳,v表示采样值
为了实现我们的监控目标,我们设计了逻辑运算来分解复杂任务并整合结果。我们定义了运算符 (λ) 灵活地组合现有系统监视器。这些逻辑运算符 (λ) 如下所示:
- •
逻辑运算:AND (∧) 或 (∨)、非 (¬)
- •
Set作:元素包含 (∈)、子集关系 (⊆)、联合作 (∪)、交集作 (∩)
- •
字符串作:字符串匹配 (match)、字符串连接 (concat)、字符串拆分 (split)、子字符串包含 (contains)
- •
数值运算:大于 ()、小于 ()、等于 ()、求和运算 (sum)、平均运算 (avg><=)
这些运算符可确保在将任务分解为子任务供现有监控器收集信息,然后集成这些数据后,生成的监控实体及其属性与我们最初的监控目标保持一致。
III-D 型轻量级协作安全监控框架
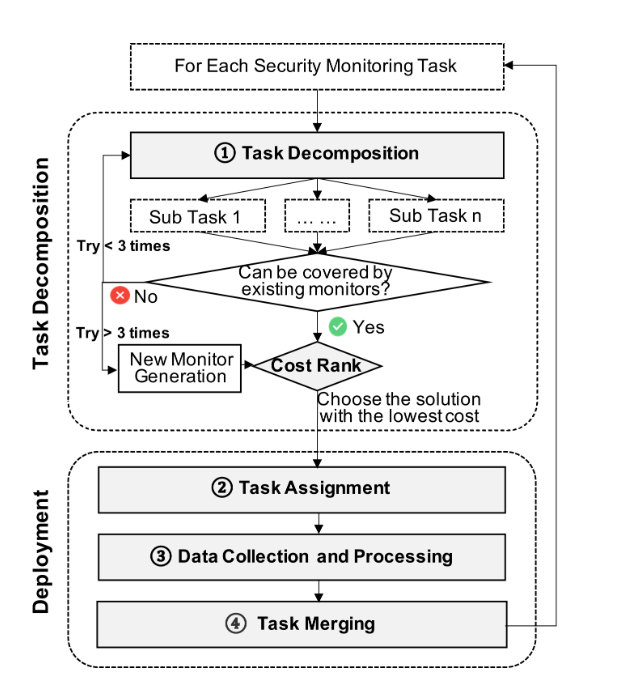
图 3:轻量级协同安全监控框架的工作流程。
基于前面建立的定义,我们提出了一种系统的任务分解和数据集成方法,如图 3 所示。我们的轻量级协同安全监控框架通过递归分解,将复杂的监控需求转化为可管理的子任务。该工作流从 Task Decomposition 开始,其中安全监控任务被分解并根据现有功能进行评估。如果现有监视器可以解决子任务,则 Cost Rank 函数会评估实施解决方案,仅选择成本最低的选项。当现有功能在多次尝试后仍无法满足监控要求时,新监控建议会建议适当的新监控组件。 一旦确定了最佳解决方案,它们就会继续进行任务分配,其中分解的子任务被分配给相应的现有系统监视器。在 Data Collection 和 Processing 阶段,这些监控器收集数据以完成其分配的子任务。最后,在 Task 合并过程中,将采集到的数据按照原来的分解逻辑进行合并,在最小化资源利用率的同时,有效地实现了完整的监控任务。 本节详细阐述了此方法的核心机制,包括 Task Decomposition 和 Deployment。
III-D1 号任务分解
此阶段为可分解任务建立标准化约束,并引入一种算法,用于使用集成逻辑将复杂的监控任务系统地分解为可管理的子任务。此集成逻辑使子任务能够组合其监控输出,从而重建原始复杂任务的结果。
具体来说,给定一个监控任务T,我们将其象征性地表示为三元组⟨VT,OT,TT⟩哪里:
- •
VT表示此监视任务需要观察的目标系统实体
- •
OT表示目标实体及其输出类型的属性描述,OT=(一个T,tT)
- •
TT表示此监视任务需要观察的系统事件
根据这个定义,监控任务分解问题可以具体化为:给定一个监控任务T和现有监控功能集C={c1,c2,…,cn}在系统中,我们的目标是确定监控功能子集C′⊆C和相应的集成作集λ,这样组合就满足任务T要求。
算法 1 任务分解 DecomposeTask
1:监控任务复杂T、现有收集器功能C2:子任务集S、新收集器要求N、集成逻辑P3:function DecomposeTask 函数 (T,C)4: S←∅,N←∅,P←∅5: (Tsub,Pcompose)←GenerateSubtasks(T,C)▷子任务和集成逻辑6: 对于每个 t我在Tsub 做7: 如果 μ(t我,C)=1 然后▷可映射到现有收集器8: S←S∪{t我}9: P←P∪GenerateIntegrationLogic(t我,Pcompose,C)10: 还11: (S′,N′,P′)←DecomposeTask(t我,C)12: 如果 S′≠∅ 然后▷如果 subtask 设置为非空13: S←S∪S′14: N←N∪N′15: P←P∪P′16: 还▷否则需要新的收集器17: N←N∪{t我}▷需要新的收集器18: P←P∪GenerateIntegrationLogic(t我,Pcompose)19: end if20: end if21: end 为22: 返回 (S,N,P)23: end 函数
基于这些约束,我们提出了算法 1,它处理复杂的监控任务T通过递归分解和集成。最初GenerateSubtasks(T,C)(第 3 行)分解T进入 Subtasks 集Tsub和集成逻辑Pcompose.
具体来说,正如算法 2 GenerateSubtasks 所演示的那样,该算法描述了自适应监控任务的分解和集成过程。算法 2 首先遍历现有收集器集C在第 3-8 行中,检查单个 Collector 是否可以直接满足 Monitoring 任务T要求,包括目标实体 (VT)、属性输出类型 (OT) 和事件类型 (TT) 覆盖率。当没有找到直接满足的收集器时,算法 2 在第 9-23 行引入了一个用于任务分解的大型语言模型,构建包含现有收集器能力描述的提示以生成集成逻辑P我′以及相应的监控能力C我′.该算法验证生成的集成方案的可行性;如果满足原来的监控需求,则添加相关子任务Tsub和集成逻辑Pcompose更新,否则最多执行 3 次优化迭代。最后,算法输出优化的 subtask 集Tsub和相应的集成逻辑Pcompose,实现监控任务的自动化分解和动态集成。
算法 2 生成子任务
1:监控任务T、现有收集器集C2:子任务集Tsub、集成逻辑Pcompose3: 函数 GenerateSubtasks(T,C)4: Tsub←∅,Pcompose←∅5: 对于每个收集器 cj∈C 做6: 如果 T.VT⊆cj.Vc ∧ T.OT⊆cj.Oc ∧ T.TT⊆cj.Tc 然后▷ 现有监控器涵盖的目标实体7: Tsub←Tsub∪{T}8: Pcompose←Pcompose∪Tsub9: end if10: end 为11: 如果 Tsub 为空 ,则▷如果没有直接满足收集器12: prompts←创建 LLM 提示13: 对于每个 cj∈C 做14: prompts←prompts+{cj}▷ 添加现有收集器功能描述15: end 为16: prompts←prompts+ 《任务要求》:目标实体VT、属性输出类型OT、事件类型TT,请生成可以结合现有监控功能以满足这些要求的集成逻辑。▷ 利用 LLM 进行任务分解17: P我′,C我′←LLM 生成的集成逻辑,集成监控功能18: 如果 C我′满足T的目标实体VT、属性输出类型OT和系统事件TT 然后▷ 确定生成的集成逻辑是否满足监控要求19:添加涉及的子任务C我′自Tsub并生成集成逻辑20: Pcompose←Pcompose∪P我′21: 还22:请求进一步优化集成逻辑(尝试 3 次)23: end if24: end if25: 返回 Tsub,Pcompose26: end 函数
随后,算法 1 第 4-19 行使用匹配函数评估每个 subtaskμ(t我,C),确定现有收集器是否可以完成监控任务:
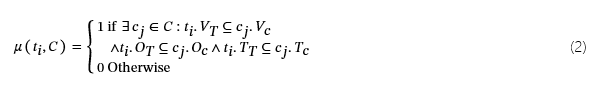
在这里,可映射的子任务 (μ(t我,C)=1,算法 1 第 5-7 行)添加到S通过 GenerateIntegrationLogic(算法 1 第 7 行)使用相应的集成逻辑,该逻辑派生集成作λ需要来合并它们的输出。获取到的集成逻辑记录在P. 具体来说,如算法 3 第 3-8 行所示,该算法遍历现有的基本信息收集器c我∈C、标识与 subtask 匹配的收集器t我,并将它们集成到现有的集成逻辑中Pcompose形成最终的积分逻辑P.
对于不可映射的子任务(算法 1 第 8-18 行),我们尝试使用前面描述的方法进一步分解。如果可以进一步分解(第 10 行),则递归处理生成的 subtask,并将集成逻辑合并到P(算法 1 第 11-13 行)。
如果无法进一步分解,则将任务标记为需要新的收集器功能(算法 1 第 15 行,等效于算法 3 第 9-12 行),并将其集成逻辑添加到P(第 16 行)。此过程将一直持续,直到所有 subtask 都映射到现有收集器或标识为N.
算法 3 生成集成逻辑
1:子任务t我、现有集成逻辑Pcompose、可选参数现有收集器功能C(默认值:None)2:集成逻辑P3: 功能Generate_Integration_Logic(t我,Pcompose,C=没有)4: P←∅5: 如果 C≠没有 然后6: 对于每个基本信息收集器 c我∈C 做7: if 收集器 c我对应 Subtaskt我 找到 ,然后更新 Pcompose,附加相应的收集器c我自t我成形P8: end if9: end 为10: 还▷没有可用的现有基本信息收集器,必须构建新的11: Pnew←CreateNewCollector(t我)▷手动构建新监视器12:更新Pcompose,将新建的Pnew自t我成形P13: 返回 P14: end if15: end 函数
成本排名为了正式确定我们在安全监控框架内的成本优化方法,我们引入了一个综合成本函数,用于量化监控任务分解所涉及的权衡。此功能是我们优化流程中的关键组成部分,指导选择实施策略,以最大限度地减少资源利用率,同时保持有效的安全覆盖。
成本函数C(T)对于监控任务T分解为 Subtask{t1,t2,…,tn}表述为:
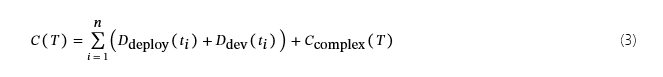
哪里D部署表示部署成本,D开发表示开发成本,以及C复杂捕获集成复杂性。
对于部署成本,我们区分了现有和新的监控组件:

哪里α是现有监视器的加权因子,P开销量化性能影响,以及β小鬼表示特定于 implementation 的权重,这些权重根据 implementation approach (hardware, kernel, or user-space) 而变化。值得注意的是,这种关系β硬件<β内核<β用户反映了我们的观察,即硬件实现通常比内核级实现引入更少的运行时开销,而内核级实现反过来对性能的影响比用户空间实现要小。
开发成本的结构旨在通过优先考虑现有功能来最大限度地减少资源使用:重用现有监视器的成本为零,用户空间、内核级和硬件实现的成本分别增加(即0<γ用户<γ内核<γ硬件).
加权因子满足γ硬件>γ内核>γ用户,反映与每种实施方法相关的相对开发工作量。此公式鼓励尽可能重用现有监控功能,因为这些组件产生的额外开发成本为零。
集成复杂性使用对数函数进行建模,以反映随着组件数量的增加而复杂度的亚线性增长,即C复杂(T)=n, 哪里n表示分解中的 subtask 数。
在通过任务分解生成潜在的实施解决方案后,我们使用上面定义的成本函数评估每个解决方案。让S={S1,S2,…,Sm}表示一组候选解决方案,其中每个解决方案Sj由原始监控任务的特定分解组成。成本评估函数为每个解决方案分配一个数字成本分数,即得分(Sj)=C(Sj)
然后,我们按成本分数升序对所有候选解决方案进行排名。 选择成本得分最低的解决方案作为最佳实施策略。 此过程可确保我们的监控实施在全面的安全覆盖范围与实际资源限制之间取得平衡。通过系统地评估和比较不同的实施策略,我们在保持有效安全监控能力的同时实现最佳资源利用率。
III-D2 号部署
在通过我们的成本感知方法系统地分解监控任务并优化其实施策略后,我们进入部署阶段。此阶段包括三个关键阶段:(1) 将任务分配给适当的收集器,(2) 根据任务规范收集和处理数据,以及 (3) 通过任务合并集成收集的数据。
任务分配。基于μ(t我,C)、子任务t我∈S分配给现有收集器C或标记为 New Collector 要求N.子任务μ(t我,C)=1映射到兼容的收集器以直接收集信息,而μ(t我,C)=0添加到N,相应的自定义收集器是通过专家干预实现的,以满足监控要求。
数据收集和处理。收集器根据t我,生成数据输出Ot.
任务合并。使用集成逻辑P从 Task Decomposition,收集的输出{Ot}组合在一起以重建原始任务结果OT.集成作λ∈P确保与T的输出要求。
通过这种系统的方法,我们的方法可以最大限度地利用现有收集器,减少对新模块和部署的要求,从而优化资源效率。
III-E 型Monitor 构建和部署案例研究
考虑一个 Log4Shell 从零到根的攻击场景(图 4),攻击者利用 Log4Shell 漏洞进行初始访问,然后纵环境变量 (EnvVar) 进行权限提升。一个关键的监控要求是跟踪环境变量修改。传统的安全监控依赖于系统调用事件,但这种方法存在重大限制:环境变量作通常通过不触发系统调用的 shell 内置函数执行。这会产生监控盲点,因为传统的系统呼叫跟踪无法检测到这些作。由于环境变量作在权限提升攻击中通常至关重要,因此这些盲点会显著影响系统安全感知能力。
因此,根据实际攻击场景分析,我们必须增强现有的安全监控框架,以满足这些关键要求。使用算法 1 的任务分解方法,我们将环境变量修改监控分解为基本的可实现子任务。具体来说,我们将其分解为两个基本的子任务Tsub:命令历史监控 (t1) 跟踪输出类型为Ot1={e1,…,en},其中每个e我包含命令字符串、进程 ID 和时间戳;和环境变量列表监控 (t2) 跟踪系统的环境变量名称,输出类型Ot2={v1,…,vm},其中每个v我表示环境变量名称。
此任务分解实现两个关键监控组件:t1负责命令行历史监控,通过 eBPF 技术实现。具体来说,我们利用 eBPF 的动态跟踪功能在 shell 程序关键功能(如 readline、execute_command 等)上执行探测插桩,实时捕获用户输入命令序列。t2专注于环境变量监控,我们开发了一个独立的收集器程序,可以定期以预定的时间间隔获取和记录系统环境变量快照。
集成逻辑Pcompose数据关联分析实现如下:首先通过作λn一个me(Ot1,Ot2)={cmd∈Ot1|∃v一个r∈Ot2:v一个r出现在cmd.cmd_str},它会在命令字符串和环境变量名称之间执行名称匹配,然后分析匹配的命令以识别当前的环境变量作。
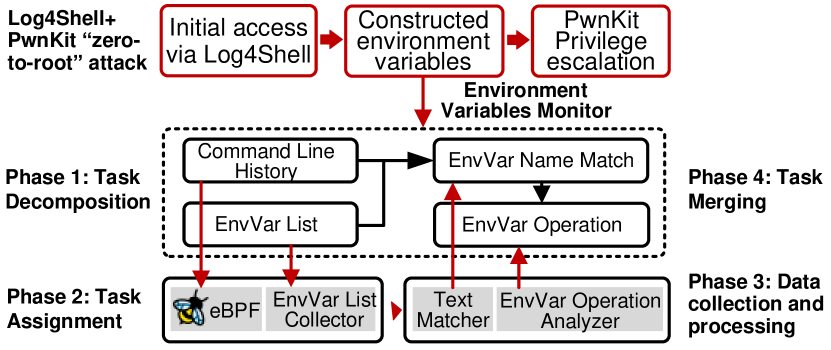
图 4:SMART 方法 Log4Shell Zero-to-Root 攻击示例。
III-F 型异常检测模块
基于我们对攻击位置的观察,我们引入了一种具有攻击位置感知的加权机制,以提高威胁检测的有效性。此机制利用前面提到的来源图中嵌入的终端节点异常信息,并通过异常评分指导权重分配,从而改进对潜在威胁的识别和响应。以下部分详细介绍了我们的方法分为三个阶段:来源图节点嵌入、图神经网络设计和数据后处理。
Provenance Graph 节点嵌入。给定一个来源图G=(V,E)哪里V={v|v∈(Process∪F我le∪Socket)}和E⊆V×V×T、每个顶点v∈V的特征向量对其实体-行为交互模式进行编码:

哪里f我n(v)和fout(v)分别表示传入和传出边缘类型(即行为类型)的分布,以及S(v)是节点的异常分数v如第 II-A 节所述。
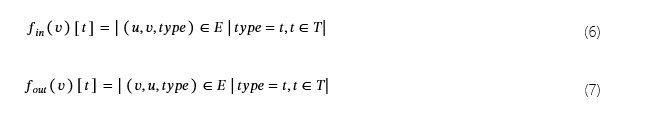
具体说来f我n(v)[t](公式 6)计算t指向 Nodev. 这将捕获其他节点执行的特定类型行为的频率v. 同样地fout(v)[t](公式 7) 计算 类型 的边数t源自节点v.这捕获了该节点的特定类型行为的频率v在其他节点上执行。
从本质上讲,这些公式计算与节点关联的每种行为类型的频率v,归类为传入(从其他节点到v) 和传出(行为来自v朝向其他节点)。生成的特征向量对来源图中节点的行为模式进行编码,有助于识别异常或潜在的恶意活动。
此外,还纳入了异常评分S(v)增强了特征表示的判别能力,有效指导了全局溯源分析过程中的分支权重分配,从而提高了攻击检测的整体准确性和可靠性。
图神经网络设计。在本文中,我们使用了一个两层的图注意力网络 (GAT)[77]在捕获顶点-边缘(即实体-行为)模式时学习顶点特征。在学习过程中,vertex 的特征更新我的计算公式为:
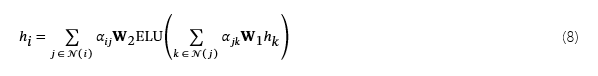
这里𝐖1和𝐖2是第一层和第二层的权重矩阵。注意力系数α我j (αjk) 确定邻居的重要性j的 (k的)特征设置为顶点我 (j).指数线性单元 (ELU) 用作层间激活函数,可增强梯度流,提高表达能力,并在负值范围内提供非线性转换,从而提高模型性能。
对于异常检测,我们首先在良性来源图上训练我们的 GAT。通过根据良性图中的顶点-边缘(即实体行为)模式调整顶点权重,我们获得了一个良性的 GAT 实体行为模型。在预测阶段,我们将多类分类方法应用于 GAT 层的输出。具体来说,在特征聚合之后,我们将 softmax 函数应用于顶点特征hv产生类概率,即zv=softmax(hv).随后,我们使用 argmax 函数从 softmax 输出中获得预测结果。具体来说,我们选择概率最高的类作为模型的最终预测类,即y^v=精 氨 酸麦克斯czvc哪里zvc表示 vertexv属于类c.
数据后处理。我们定义我s_一个nom一个lous(v)检查顶点v.如果其预测的实体类型与其实际类型不同,则我们认为它是异常的,偏离了我们训练的良性实体行为模型。当检测到异常时,我们分析它们的邻居,其中注意力权重在连接的异常顶点之间积累,同时在良性顶点中被稀释。
为了进一步减少误报,对于每个预测的异常顶点v,我们分析其k-跳跳邻里Nk(v)(其中k=2)并计算良性密度分数:
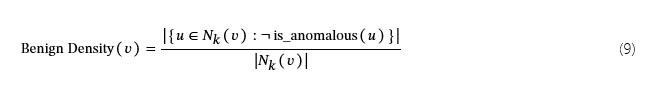
如果良性密度(v)超过一个阈值(在我们的实现中为 80%),表明它的大部分相邻顶点是良性的,我们认为v缺少攻击局部并将其更正为良性,从而进一步减少误报。
四评估。
我们通过回答以下研究问题来评估 FEAD:
∙ RQ1:(监控覆盖率)从实际攻击中捕获了哪些安全关键型监控项目,现有工具是否遗漏了其中任何一个?
∙ RQ2:(效果)FEAD 在资源受限的环境中检测攻击事件和异常的有效性如何?
∙ RQ3:(消融研究)FEAD 的组件和设计选择如何影响其在攻击检测和异常识别方面的有效性?
∙ RQ4:(部署成本)FEAD 的开发成本是多少,对于实际部署是否可行?
图 5:来自实际攻击的以安全为中心的监控项目。
评估数据集我们使用 DARPA TC 评估我们的方法[78]和 CSE-CIC-IDS2018[79]数据集,与之前的工作一样[18,17,13,80].DARPA TC 数据集由四个场景组成 — THEIA、Trace、CADETS 和 Fivedirections,涵盖各种攻击步骤和环境。CSE-CIC-IDS2018 数据集来自加拿大网络安全研究所 (CIC),包括有关各种攻击的数据,例如 Brute Force、Heartbleed 等。表 IV 总结了这些数据集。
表 IV:评估数据集概述
| 数据 | 场景 | 良性顶点 | 异常顶点 | 边缘 |
| DARPA TC | 忒伊亚 | 3,505,326 | 25,362 | 102,929,710 |
| 跟踪 | 2,416,007 | 67,383 | 6,978,024 | |
| 学员 | 706,966 | 12,852 | 8,663,569 | |
| 五大方向 | 569,848 | 425 | 9,852,465 | |
| CSE-CIC-IDS2018 | - | 212,628 | 89,228 | 501,856 |
由于现有数据集没有包含我们构建的监控系统,因此我们创建自定义数据集来评估 FEAD 的监控设计和异常检测能力。我们与两位行业专家合作,重现常见的漏洞利用,例如 Log4j 漏洞 (CVE-2021-44228)[81,82,83]以及 OpenSMTPD 漏洞 (CVE-2020-7247)[84,85,86],以及基于实际应用场景的相关攻击活动。 数据集包括:(1) Log4j+ENV 攻击数据集:该数据集模拟了与 Log4j 漏洞相关的攻击,涵盖了对目标的初始访问、通过环境变量进行提权以及建立反向 shell 连接等场景。(2) OpenSMTPD+恶意执行:该数据集展示了一个利用 OpenSMTPD 漏洞的攻击链,包括未经授权的命令执行、下载恶意脚本和执行其他恶意软件。
部署环境。 (1) 对于攻击报告分析和安全监控项提取,我们使用 Microsoft 的 Azure OpenAI API[87]使用 GPT-3.5-16K 模型 并将温度参数设置为 0.4 以平衡创造力和准确性。(2) 对于我们的 GAT 实现,我们使用了具有 8 个注意力头和一个 128 个单元的隐藏层的两层 GAT 架构。我们将 batch size 设置为 500,学习率为 0.01,权重衰减为 5e-4,dropout 率为 0.5,以防止过拟合。(3) 对于 FEAD 部署和异常检测实验,我们使用 Debian 10.8 (Linux 5.10) 和 Intel(R) Core(TM) i5-12500 处理器和 48GB RAM,托管所有信息收集工具和攻击检测系统。(4) 对于我们的成本函数实现,我们通过专家评估确定了参数。四位具有 2-3 年攻击检测研究经验的合著者,以及两位具有 7-8 年网络安全经验的行业专家,使用多数投票共同建立了参数值,以解决分歧。我们设置α=0.2对于现有的 monitor weights,反映重用组件时的最小开销。对于新的实现,我们分配了βuser=0.7,βkernel=0.5和βhw=0.3,捕获了我们的观察结果,即用户空间实现通常比内核空间引入更高的运行时开销,而硬件加速监视器显示的影响最小。开发成本参数化为γuser=10,γkernel=25和γhw=50,表示基于以前项目的相对实现工作量(以人天为单位),硬件实现需要更专业的专业知识和时间。这种方法确保了我们的成本函数在理论合理性与实际考虑之间取得平衡,产生了任务分解,最大限度地提高了现有显示器的利用率,同时最大限度地减少了开发开销。
表 V:自定义数据集信息
| 场景 | 良性顶点 | 异常顶点 | 边缘 |
| Log4j+ENV | 812 | 37 | 1,975 |
| OpenSMTPD+恶意执行 | 3,384 | 34 | 7,989 |
表 VI:检测效果比较
| 数据 | 我们的方法 | ThreaTrace 跟踪 | ||||||
| 精度 | 召回 | FPR | F1 分数 | 精度 | 召回 | FPR | F1 分数 | |
| 学员 | 97.92% | 99.88% | 0.08% | 98.89% | 93.84% | 99.96% | 0.24% | 96.81% |
| 五大方向 | 72.53% | 95.06% | 0.04% | 82.28% | 75.21% | 84.94% | 0.032% | 79.78% |
| 忒伊亚 | 99.81% | 99.91% | 0.02% | 99.86% | 95.49% | 99.90% | 0.37% | 97.65% |
| 跟踪 | 98.24% | 99.996% | 0.02% | 99.11% | 81.59% | 99.99% | 1.33% | 89.86% |
| CSE-CIC | 98.99% | 93.55% | 0.04% | 96.19% | 92.58% | 95.12% | 7.58% | 93.44% |
| Log4j+ENV | 99.46% | 100% | 0.02% | 99.73% | 76.09% | 99.99% | 1.36% | 86.42% |
| OpenSMTPD | 94.97% | 100% | 0.05% | 97.42% | 77.50% | 91.18% | 0.27% | 83.78% |
| 平均 | 94.41% | 98.91% | 0.03% | 96.76% | 84.61% | 95.87% | 1.57% | 88.53% |
IV-A 型RQ1:监控项和监控覆盖率评估
无花果。5 介绍了我们的方法从真实攻击报告和 ATT&CK 案例中提取的 85 个与安全相关的监控项目。而传统的监控工具主要关注基本的系统元素(进程 PID、名称、参数、文件路径/名称以及网络 IP 和端口)。 相比之下,我们的方法系统性地拓宽了监控范围。除了这些基本元素之外,我们的框架还包含对系统安全配置(例如,防火墙规则更改、安全设置修改和服务状态更新)、用户身份验证模式(例如,登录记录、权限提升事件和会话跟踪)、进程行为(例如,DLL 加载、资源使用和网络活动)和文件完整性指标(例如,哈希值、加密状态和访问控制列表的更改)的详细监控, 这些经常被传统的监测工具所忽视。
如表 VII 所示,虽然 Auditd 和 Camflow 被广泛用于为来源图生成系统日志,但它们最初并不是为安全而设计的,导致对来自真实世界攻击的监控要求的覆盖率较低(分别为 49.40% 和 40.00%)。Auditbeat 是 Elastic 的 Auditd 安全增强版本,它展示了专业知识如何缩小这些差距,实现 75.30% 的覆盖率。 最近,eBPF 因其在 Linux 环境中的低开销和实时功能而受到关注。我们评估了 eAudit,这是使用 eBPF 的 Auditd 的学术扩展,它将覆盖率提高到 56.47%,但仍有进一步改进的空间。 我们的方法侧重于 Linux(不包括 ETW 等特定于 Windows 的工具),应用了第 III-B 节中的方法(第 III-E 节中有案例研究)。通过分解复杂的监控任务、利用现有监控器并整合收集的数据,我们将覆盖率扩展到 83.50%。我们通过 RQ3 中的消融实验进一步验证了我们监测框架的有效性和实用性。
表 VII:不同监控工具的覆盖率分析
| 指标 | 审计 | 审计节拍 | 电子审计 | Camflow 公司 | 我们的方法 |
| 覆盖数量 | 42 | 64 | 48 | 34 | 71 |
| 覆盖率 (%) | 49.40% | 75.30% | 56.47% | 40.00% | 83.50% |
IV-B 型RQ2: FEAD 的有效性
表 VIII:消融研究:监测框架和攻击位置
| 数据源 | 使用我们的监控框架 | 没有我们的监控框架 | ||||||
| 精度 | 召回 | FPR | F1 分数 | 精度 | 召回 | FPR | F1 分数 | |
| opensmtpd | 94.97% | 100% | 0.05% | 97.42% | 78.57% | 97.06% | 0.27% | 86.84% |
| log4jEnv | 99.46% | 100% | 0.02% | 99.73% | 74.00% | 100% | 1.6% | 85.06% |
| 平均 | 97.22% | 100% | 0.035% | 98.58% | 76.29% | 98.53% | 0.94% | 85.95% |
| 场景 | 使用 Attack Locality | 无攻击位置 | ||||||
| 精度 | 召回 | FPR | F1 分数 | 精度 | 召回 | FPR | F1 分数 | |
| 学员 | 97.92% | 99.88% | 0.08% | 98.89% | 84.14% | 99.89% | 0.70% | 91.34% |
| 五大方向 | 72.53% | 95.06% | 0.04% | 82.28% | 44.30% | 95.06% | 0.14% | 60.43% |
| 忒伊亚 | 99.81% | 99.91% | 0.02% | 99.86% | 92.11% | 99.91% | 0.68% | 95.85% |
| 跟踪 | 98.24% | 99.996% | 0.02% | 99.11% | 89.47% | 99.995% | 0.11% | 94.44% |
| 平均 | 92.13% | 98.71% | 0.04% | 95.04% | 77.51% | 98.71% | 0.41% | 85.52% |
为了评估我们提出的方法的有效性,我们对多个数据集进行了全面实验,并将我们的方法与 ThreaTrace 进行了比较[18],这是一种最先进的基于 GraphSAGE 的检测方法,用于来源图异常检测,已获得大量引用并提供完整的开源实施。
表 VI 显示,与 ThreaTrace 相比,我们的方法表现出卓越的检测性能(F1 分数平均高 8.23%)。对各个数据集的性能进行详细分析后,可以发现以下改进:
DARPA 数据集性能分析:我们的方法在四个 DARPA 数据集中表现出显着的一致性,在 Theia 数据集上取得了显着的改进,F1 分数提高了 9.25%,假阳性率 (FPR) 降低了 1.31%。这意味着精度提高了 16.65%,突出了我们的局部感知异常检测方法在已建立的复杂系统环境中的有效性。 在 Trace 数据集上同样令人印象深刻的结果表明,与 ThreaTrace 的 89.86% 相比,我们的方法取得了出色的 99.11% F1 分数,这主要是由于我们要高得多的准确率(98.24% 对 81.59%),同时保持了可比的召回率。这些改进展示了我们基于攻击位置的顶点加权机制如何有效区分各种系统行为中的良性活动和恶意活动。
CSE-CIC 数据集性能分析:在这个数据集上,我们的方法取得了 96.19% 的 F1 分数,超过了 ThreaTrace 的 93.44%。最值得注意的是,我们的方法将 FPR 大幅降低到仅 0.04%,而 ThreaTrace 为 7.58%,提高了 189 倍,将显著减少安全分析师必须调查的误报数量。这种巨大的性能差距进一步验证了我们的本地感知异常检测机制有效地利用了恶意活动的集群特征,从而更精确地区分了正常网络流量和真正的攻击。
自定义攻击数据集性能分析:为了验证我们的安全监控框架的有效性,我们使用我们提议的监控系统从真实世界的攻击中收集了数据。在这里,我们的方法显示出显着的改进,Log4j+ENV 数据集显示,与 ThreaTrace 相比,F1 分数高出 13.31%。我们的方法实现了近乎完美的 99.73% F1 分数,而 ThreaTrace 的 F1 分数为 86.42%,这表明了对这种复杂攻击媒介的卓越检测能力。对于 OpenSMTPD 数据集,我们观察到同样令人印象深刻的结果,达到 97.42% 的 F1 分数,同时保持非常低的 0.05% FPR。 这些针对现代攻击场景的结果清楚地表明,我们的组合方法(同时使用面向安全的监控框架和位置感知分析)如何成功捕获重要的攻击特征,同时正确区分良性节点和来源图。
这些结果证实,我们的方法有效地将增强型安全监控与位置感知异常检测相结合,显著提高检测准确性,同时减少不同环境中的误报。
表 IX:部署成本分析
| 指标 | 基线 | FEAD(成本) | 非 FEAD(成本) |
| SPEC2006 (执行时间) | 2,724.6 秒 | 2,871.85 秒 (5.40%)) | 3043.65 秒 (11.71%)) |
| STREAM(吞吐量) | 19,036.75 MB/秒 | 18,988.28 MB/秒 (0.26%)) | 18860.30 MB/秒 (0.94%)) |
| 应用程序 (执行时间) | 4,498 毫秒 | 4,514 毫秒 (0.36%)) | 5,814 毫秒 (29.26%)) |
| 代码行数 | - | 59,203 | 86,257 |
IV-C 型RQ3:FEAD 的消融研究
为了评估我们关键设计组件的有效性,我们进行了两个消融实验:(1) 利用我们面向安全的监控项框架是否增强了检测能力——在我们复现的 Log4j 和 OpenSMTPD 漏洞利用场景中测试 FEAD 的检测性能,无论有没有我们的数据/日志收集监控项,以及 (2) 考虑攻击局部性是否能提高检测性能- 评估 FEAD 对广泛使用的 DARPA 数据集的检测效果,考虑和不考虑攻击位置。
监控框架影响分析。如表 VIII 所示,我们的监控项目框架显著提高了检测能力,平均 F1 得分为 98.58%,而没有框架的 F1 评分为 85.95%,提高了 12.63%。使用我们的框架,FPR 下降了 0.91%,对应的精度提高了 20.93%。检查各个数据集后发现,最显着的改进发生在 Log4j+ENV 场景中,其中精度从 74.00% 提高到 99.46%(提高了 25.46%),同时保持了完美的召回率。同样,对于 OpenSMTPD,精度从 78.57% 提高到 94.97%(提高了 16.4%)。这些结果验证了我们从真实攻击中系统提取的监控项目对于准确检测攻击至关重要,从而提供对否则会错过的攻击行为的可见性。
攻击位置影响分析。 在考虑局部模式时,FEAD 的平均 F1 分数为 95.04%,而没有局部模式时为 85.52%。这表明 locality 在将检测精度提高 9.52% 的同时,保持了显著降低的假阳性率(0.04% 对 0.41%)的有效性。这种影响在 Fivedirections 数据集上最为明显,其中 F1 分数从 60.43% 提高到 82.28%(提高了 21.85%),主要是通过提高精度(从 44.30% 提高到 72.53%)。即使在我们的方法已经表现良好的数据集上,例如 Theia(F1 分数从 95.85% 提高到 99.86%),结合局部模式也可以进一步减少 0.66% 的假阳性。所有数据集的这种一致模式表明,攻击位置是有效区分真实攻击和孤立异常的基本特征。
这些结果证实,我们面向安全的监控框架和攻击位置考虑都大大提高了检测效率,同时最大限度地减少了误报。该框架可确保全面了解与安全相关的系统活动,而基于局部性的分析可以区分良性异常和实际攻击模式,从而在整体检测能力方面实现乘法改进,而不仅仅是加法改进。
IV-D 型RQ4:部署成本分析
为了评估我们方法的部署成本,我们测量了性能开销和开发复杂性。对于性能指标,我们使用广泛认可的 SPEC2006 基准测试来评估 CPU 性能[88,89]、使用 STREAM 基准测试的内存吞吐量[90,91]以及应用程序运行时开销。对于开发复杂性,我们以代码行为单位衡量了实现工作量。虽然我们的 FEAD 方法分解了复杂的监控任务并将其分配给现有的收集器,但非 FEAD 实施需要从头开始开发新的监控功能。
表 IX 显示 FEAD 产生的部署成本最低。它仅引入了 5.40% 的 CPU 性能开销 (SPEC2006),比传统方法提高了 6.31%。内存吞吐量影响更小,下降了 0.26%,维持在 18,988.28 MB/s。最值得注意的是,FEAD 仅引入了 0.36% 的应用程序运行开销,降低了 28.90%。在开发工作方面,FEAD 需要 59,203 行代码,将实现复杂性降低了 31.4%。 这些结果突出了 FEAD 的监控策略是一种有效的解决方案,可以最大限度地减少性能影响和开发工作,使其非常适合生产环境。
V结论
我们提出了 FEAD,这是一种在资源受限的系统中检测复杂网络威胁的新型框架。我们引入了一种攻击模型驱动的监控项识别方法,从攻击报告系统地提取安全关键项,提出了一种通过复杂任务分解机制的高效监控框架部署,并开发了一种利用恶意活动聚类特征的局部感知异常分析技术。我们对多个真实数据集和自定义攻击场景进行了广泛的评估。实验结果表明,FEAD 的性能优于现有解决方案,F1 分数高出 8.23%,而开销仅为 5.4%,验证了其高效、准确检测攻击的有效性。