
1.摘要
粒子群算法(PSO)是一种简单且高效的元启发式算法,但在解决复杂多峰问题时,可能会遇到局部最优解和过早收敛等问题。为了增强PSO的全局搜索能力,本文提出了一种潜力驱动多学习粒子群算法(PDML-PSO),该算法通过根据粒子适应度将其划分为精英粒子、潜力粒子和普通粒子三类,并采用多学习策略为不同类别的粒子分配不同的搜索优先级。PDML-PSO使用了一种基于连续梯度步数与适应度相关的非传统选择标准来分类潜力粒子,从而保留了梯度下降加速搜索的优点,同时避免了其陷入局部最优解的缺点。
2.粒子群算法PSO原理
3.潜力驱动多学习粒子群算法PDML-PSO
多层结构
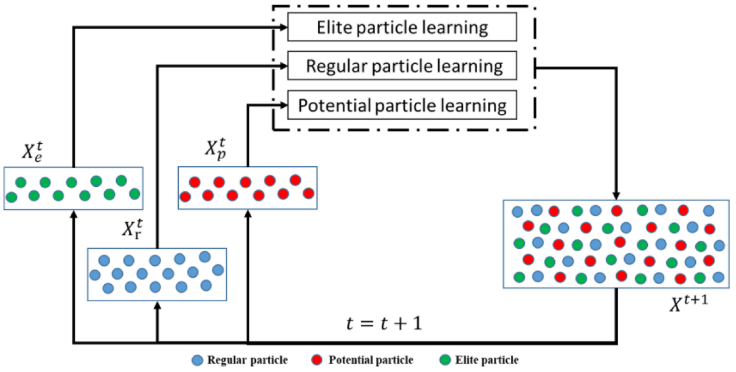
PDML-PSO根据粒子群中粒子的适应度值或适应度值变化,将所有粒子分为三个层次:精英粒子层、潜力粒子层和普通粒子层。每个层次采用不同的学习方法进行更新和迭代。
- 精英粒子层:适应度值较小的粒子,靠近局部最优解,引导粒子群朝最优解收敛,从而增强收敛性,选择前20%的粒子作为精英粒子层。
- 潜力粒子层:根据适应度值连续下降的次数对粒子进行排名,按降序排列,选择前20%的粒子作为潜力粒子层。
- 普通粒子层:剩余的粒子组成普通粒子层。
潜力引导
传统PSO算法及其变种通常侧重于基于历史信息进行学习优化,但往往忽视了历史信息与未来趋势之间的关系。梯度可以有效地利用历史数据来预测未来的发展趋势,利用连续的梯度适应度计数来更准确地估计未知潜力:
∇ P f i t i ( t ) = P f i t i ( t ) − P f i t i ( t − 1 ) \nabla Pfit_i(t)=Pfit_i(t)-Pfit_i(t-1) ∇Pfiti(t)=Pfiti(t)−Pfiti(t−1)
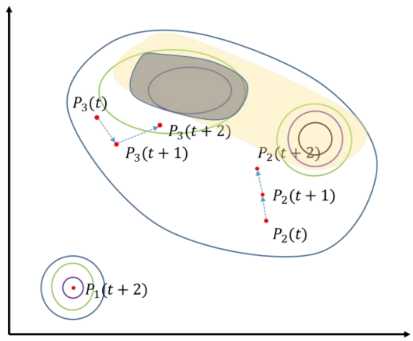
如图所示,粒子 P 1 P_1 P1、 P 2 P_2 P2和 P 3 P_3 P3位于不同位置,且在时刻 t + 2 t + 2 t+2时,具有不同的适应度值,按降序排列为 P 1 ( t + 2 ) P_1(t + 2) P1(t+2)、 P 3 ( t + 2 ) P_3(t + 2) P3(t+2)、 P 2 ( t + 2 ) P_2(t + 2) P2(t+2)。尽管 P 3 P_3 P3的适应度梯度不连续,但其具有最大的总体适应度梯度,传统的潜力粒子选择方法倾向于选择 P 3 P_3 P3。短期内, P 3 P_3 P3能够引导粒子群朝着更优解发展(灰色区域),但这也增加了陷入局部最优解的风险。
本文提出的方法通过基于适应度的连续梯度下降计数来选择潜力引导粒子,倾向于选择 P 2 P_2 P2作为潜力粒子。尽管 P 2 P_2 P2的适应度梯度较 P 3 P_3 P3弱,但其适应度持续下降,表明P2的搜索方向更有可能在长期内找到更优解(黄色区域)。虽然 P 2 P_2 P2在短期内的效果不如 P 3 P_3 P3,但它更有可能最终找到最优解,从而提高粒子群的整体搜索能力。
P o t e n t i a l i = { P o t e n t i a l i + 1 , ∇ P f i t i < 0 0 , ∇ P f i t i ≥ 0 Potential_i=\left\{ \begin{array} {c}Potential_i+1,\nabla Pfit_i<0 \\ 0,\nabla Pfit_i\geq0 \end{array}\right. Potentiali={Potentiali+1,∇Pfiti<00,∇Pfiti≥0
P i p = P o t e n t i a l i ∑ i T P o t e n t i a l i P_i^p=\frac{Potential_i}{\sum_i^TPotential_i} Pip=∑iTPotentialiPotentiali

多元学习
PDML-PSO每个层级的粒子都有不同的学习方法,用以理解粒子在不同层级的特征。
普通粒子层:普通粒子根据粒子群的潜力状态选择学习方法。
V i r ( t + 1 ) = ω ( t ) ∗ V i r ( t ) + c 1 ∗ r 1 ∗ ( X e ( t ) − X i r ( t ) ) + c 2 ∗ r 2 ∗ ( X p ( t ) − X i r ( t ) ) \begin{aligned} V_{i}^{r}(t+1) & =\omega(t)*V_{i}^{r}(t)+c_{1}*r_{1}*\left(X_{e}(t)-X_{i}^{r}(t)\right)+c_{2}*r_{2} \\ & *\left(X_{p}(t)-X_{i}^{r}(t)\right) \end{aligned} Vir(t+1)=ω(t)∗Vir(t)+c1∗r1∗(Xe(t)−Xir(t))+c2∗r2∗(Xp(t)−Xir(t))
精英粒子速度更新:
V i r ( t + 1 ) = ω ( t ) ∗ V i r ( t ) + c 1 ∗ r 1 ∗ ( X e ′ ( t ) − X i r ( t ) ) + c 2 ∗ r 2 ∗ ( X r ′ ( t ) − X i r ( t ) ) \begin{aligned} V_{i}^{r}(t+1) & =\omega(t)*V_{i}^{r}(t)+c_{1}*r_{1}*\left(X_{e}^{^{\prime}}(t)-X_{i}^{r}(t)\right)+c_{2}*r_{2} \\ & *\left(X_{r}^{^{\prime}}(t)-X_{i}^{r}(t)\right) \end{aligned} Vir(t+1)=ω(t)∗Vir(t)+c1∗r1∗(Xe′(t)−Xir(t))+c2∗r2∗(Xr′(t)−Xir(t))
潜力粒子层:潜力粒子层的粒子具有一定的探索更好解的能力。在迭代更新过程中,保持其探索能力对于提高搜索效果非常重要。
X i D E t = X i ( t ) − X i ( t − 1 ) X_i^{DE}t=X_i(t)-X_i(t-1) XiDEt=Xi(t)−Xi(t−1)
P f i t i D E t = P f i t i ( t ) − P f i t i ( t − 1 ) Pfit_i^{DE}t=Pfit_i(t)-Pfit_i(t-1) PfitiDEt=Pfiti(t)−Pfiti(t−1)
V i p ( t + 1 ) = V i p ( t ) + P f i t D E , i ( t ) / X i D E t V_i^p(t+1)=V_i^p(t)+Pfit_{DE,i}(t)/X_i^{DE}t Vip(t+1)=Vip(t)+PfitDE,i(t)/XiDEt

4.结果展示
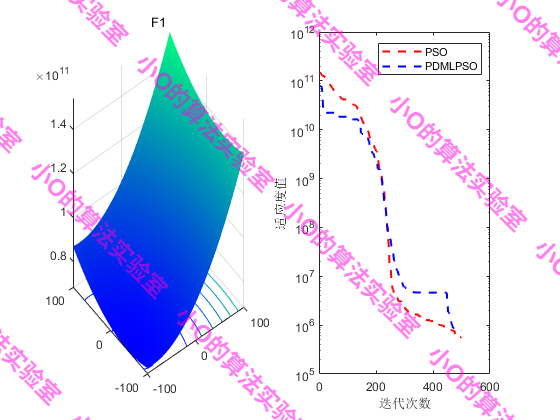
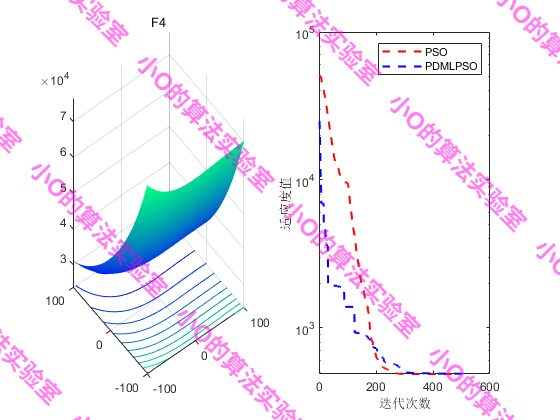
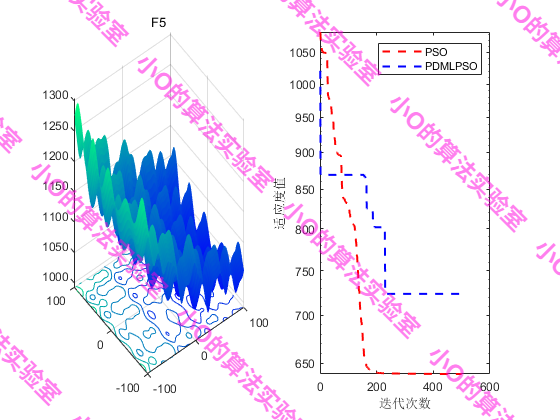
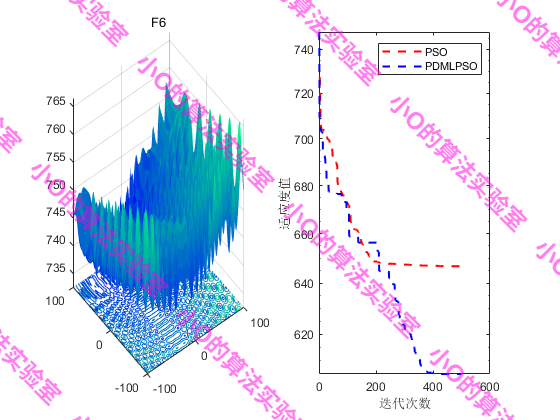
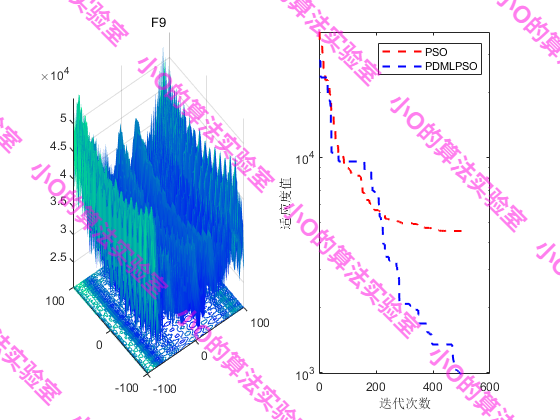
PS:CEC2017上测试效果不太理想🤣
5.参考文献
[1] Zhao W, Azizul Z H, Woo C S, et al. Potential-driven multi-learning particle swarm optimisation[J]. Swarm and Evolutionary Computation, 2025, 96: 101993.
6.代码获取
xx