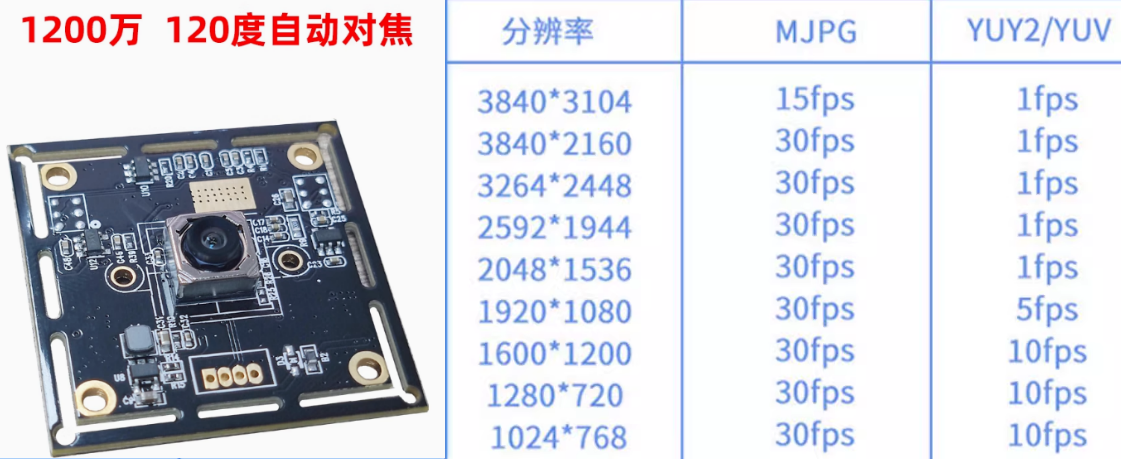
业余时间一直在基于RDK X5搞一些小研究,需要基于高分辨率图像检测目标。实际落地时,在图像采集上遇到了个大坑。首先,考虑到可行性,我挑选了一个性价比最高的百元内摄像头,已确定可以在X5上使用,接下来就开始一系列的痛苦适配流程😭。
检测算法能够应用的前提是摄像头采集与实际时间不能相差过多,如果使用下面这种通用的采集方式的话,延迟在3-7s,且每秒最多显示1帧。
import cv2
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 3264)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 2448)
cv2.namedWindow('frame', cv2.WINDOW_NORMAL)
while True:
ret, img = self.cap.read()
if not ret:
print("Failed to capture image from camera")
return
img = cv2.resize(img , (3264 // 4, 2448 //4))
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
如果是这样的话,那就别想着算法落地了,完全没法用。利用了我5个月的闲暇时间(唉,工作巨忙,抽出时间真的太难了),终于把问题和对应解决方案都给摸了,最终结论如下:800M分辨率下,延迟200ms,FPS在20-30之间,已经达到可用的标准。
本文将带给各位如下内容:
- 编解码问题剖析
- 官方PyAPI的编解码示例
- OpenWanderary编解码示例(个人维护库)
一 采集问题剖析
- 为什么每秒只能采集1帧?
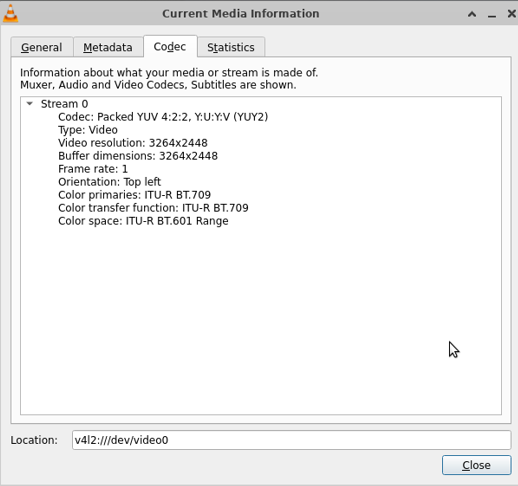
cap = cv2.VideoCapture(0)的默认采集模式为CAP_ANY,用VLC工具(sudo apt-get install vlc)打开摄像头查看默认配置。发现默认是YUV模式,根据摄像头文档,YUV模式就是每秒只能播一帧。
- 如果只是采集1帧的话,为什么采集延迟在3-7s? 参考下面代码获取
CAP_PROP_BUFFERSIZE的参数,返回值为4。这个参数表示会自动存储最新的4帧图像,如果我们无法及时在1s内处理完数据,很容易读取到缓存图像,即4s前的数据。

参考上述分析出的问题,我们可以将采集代码改为如下形式,这样我们就可以获得稍微快速的效果
import cv2
# 切换为V4L2模式,该模式下将利用linux的v4l2工具完成图像采集
cap = cv2.VideoCapture(0, cv2.CAP_V4L2)
# 切换为MJPG模式采集图像,该模式下摄像头FPS为30FPS。
cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'))
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 3264)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 2448)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1) # 保留1帧缓存,不需要读取旧图像
# 后面采集方式跟之前一样
cv2.namedWindow('frame', cv2.WINDOW_NORMAL)
while True:
ret, img = self.cap.read()
if not ret:
print("Failed to capture image from camera")
return
img = cv2.resize(img , (3264 // 4, 2448 //4))
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
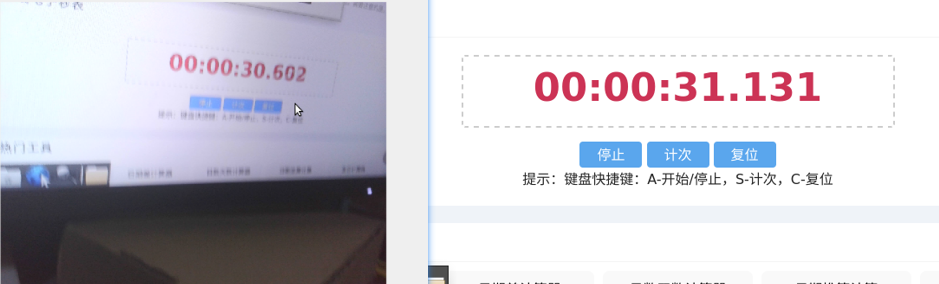
优化之后,每秒大概可处理3-5帧左右图像,延迟在0.5-1s之间。
二 利用官方Py接口实现硬件编解码
硬件编解码指利用X5的专用编解码芯片来处理图像的编解码操作。相比纯软件实现,硬件编解码能显著提高处理速度。为了搞通编解码,我还定位出官方Py包的一个Bug(快说谢谢小玺玺😋)。
2.1 解码MJPG图像
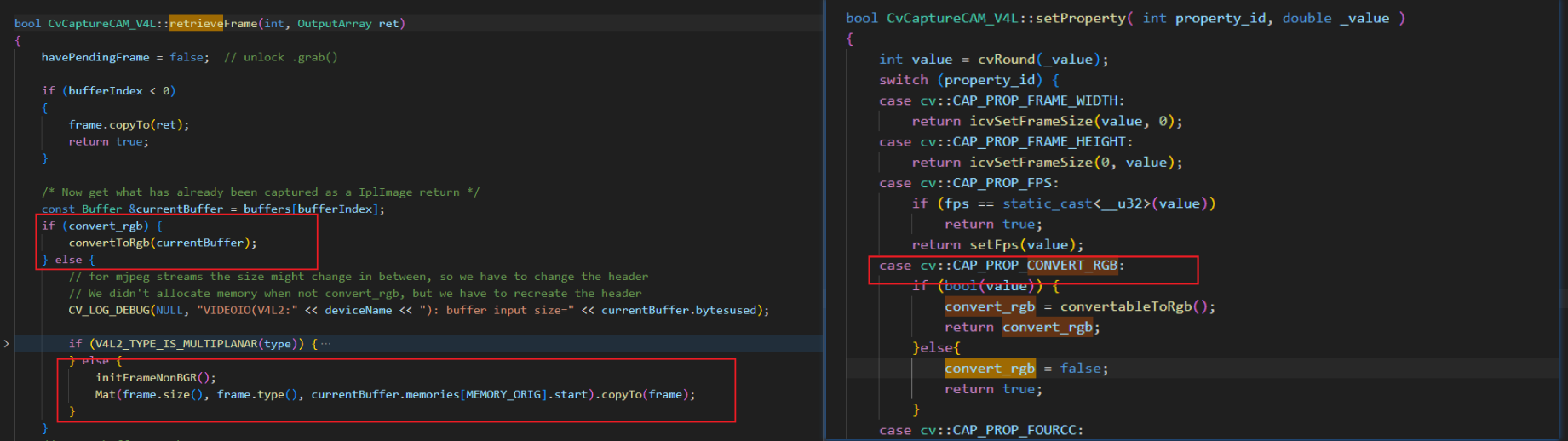
如果需要使用硬件编解码,就必须得想办法暴露出原始的MJPG流,通过翻OpenCV源码,只有将convert_rgb这个变量置为false,才能返回mjpg数据,那么问题简单了,调用cap.set(cv2.CAP_PROP_CONVERT_RGB, 0)即可完成设置。
官方的解码库导入方式为from hobot_vio.libsrcampy import Decoder,具体用法如下:
- 初始化编码类:
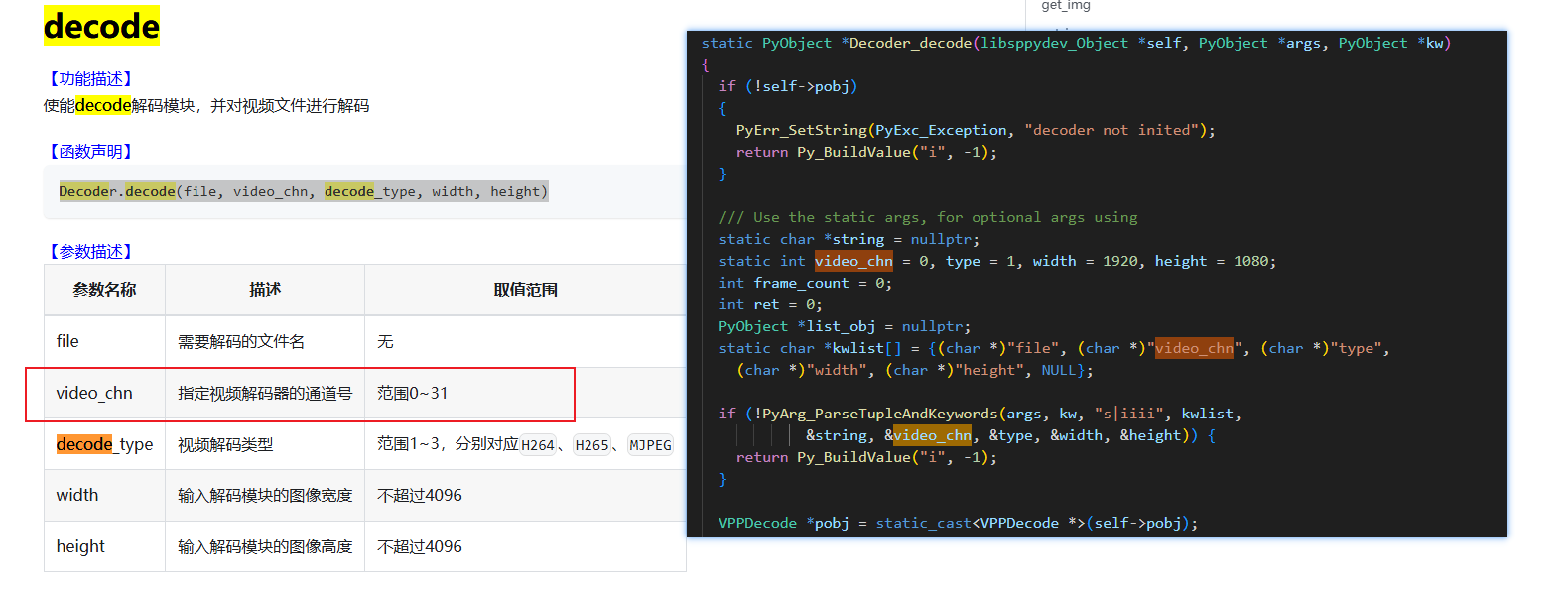
dec = Decoder() - 定义解码器参数:
ret = dec.decode("", 0, 3, imgw, imgh)。- 第一个参数为
file:表示解码数据来源,这里是通过视频流传入解码数据,因此这里指定为""即可。 - 第二个参数为
video_chn:官方说指定解码器的通道号,但从源码来看,这个参数完全没用到,填什么都可以。 - 第三个参数为
decode_type:1表示H264,2表示H265,3表示MJPEG,这里摄像头是MJPG流,因此这里填3 - 第四/五个参数就是图像的Size。
- 第一个参数为
- 向编码器中传入编码数据:
dec.set_img(byte_data) - 获取解码数据:
decode_img_x5 = dec.get_img()
更详细的代码用法如下
import cv2
from hobot_vio import libsrcampy
import numpy as np
cap = cv2.VideoCapture(0, cv2.CAP_V4L2)
cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'))
imgh, imgw = 2448, 3264
cap.set(cv2.CAP_PROP_FRAME_WIDTH, imgw)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, imgh)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
# 返回MJPG数据
cap.set(cv2.CAP_PROP_CONVERT_RGB, 0)
# 设置RDKX5的解码器
dec = libsrcampy.Decoder()
ret = dec.decode("", 0, 3, imgw, imgh)
cv2.namedWindow('frame', cv2.WINDOW_NORMAL)
while True:
data = cap.grab()
if not data:
continue
# 这里frame返回的是MJPG数据
ret, frame = cap.retrieve()
if not ret:
continue
# 将编码数据传入解码器
byte_data = frame.tobytes()
dec.set_img(byte_data)
decode_img_x5 = dec.get_img()
decode_img_x5 = cv2.cvtColor(
np.frombuffer(decode_img_x5, dtype=np.uint8).reshape(imgh * 3 // 2, imgw),
cv2.COLOR_YUV2BGR_NV12)
decode_img = cv2.resize(decode_img_x5, (imgw// 4, imgh//4))
cv2.imshow('frame', decode_img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
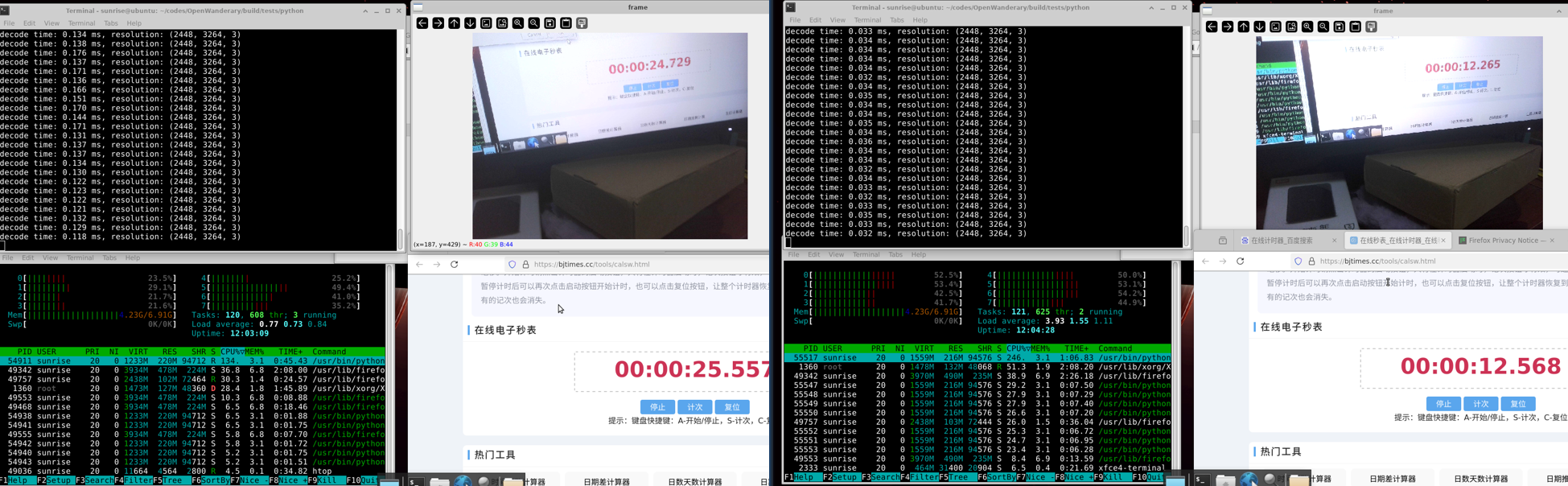
软硬编解码测试结果如下,硬解码CPU占用多了1倍,但效率优化了4倍左右。
- OpenCV软解码:平均解码耗时在140ms左右,CPU占用为134%。
- RDKX3硬解码:平均解码耗时在34ms左右,CPU占用为246%。
2.2 编码图像为MJPG数据
这里介绍下有编码需求的场景,摄像头采集完图像,利用BPU推理之后,一般会将检测结果绘制到图像上,部分开发这需要利用Flask(Python 编写的轻量级 Web 应用框架)将图像传到网页端进行查看,这时候对原图进行编码传输会提高传输效率,提高可视化的丝滑度。
这里直接给出对应的编码示例,软解码调用data = cv2.imencode(".jpg", img),测试图像分辨率为1280x720。具体测试结论如下:
- 软编码:耗时
18ms,编码后字节数123662。 - 硬编码:耗时
3ms,编码后字节数53496。
imgpath = "zidane.jpg"
img = cv2.imread(imgpath)
imgh, imgw, chl = img.shape
# 设置编码,参数意义同Decoder
enc = libsrcampy.Encoder()
ret = enc.encode(0, 3, imgw, imgh)
nv12 = bgr2nv12_opencv(img) # 编码输入要求为nv12格式
enc.encode_file(nv12.tobytes()) # 传入需编码的数据
enc_data = enc.get_img() # 返回编码后的字节
buf = np.frombuffer(enc_data, dtype=np.uint8)
dec_img = cv2.imdecode(buf, cv2.IMREAD_COLOR)
print(dec_img.shape)
enc.close()
三 利用OpenWanderary实现Py和C++的编解码
OpenWanderary在23年就已经开始启动了,最开始是在[BPU部署教程] 万字长文!通透解读模型部署端到端大流程中初步介绍了一些功能。主要是针对X3/X5的一些功能进行二次封装,并补充一些轮子库(工作真的是越来越忙,能抽出时间搞这种东西真的就是纯热爱了 💞 )。仓库地址:https://github.com/Li-Zhaoxi/OpenWanderary
为什么我要重新封装,从官方开源的代码和文档里来看,不同的开发板对应的文档是不同的。甚至代码都是完全复制一份来适配的,那么后续有更新,或者有bug修复,真的很不适合持续的发版与迭代。自己开发时候遇到很多问题,比如这个摄像头问题,定位了好久。我个人不喜欢走回头路,比如一个编解码问题只是个接口,内部应该适配多个开发板。不需要用户去区分这些。
X5的开发板,底层是有个hbm的C语言接口,这个接口是稳定的。无论是官方SDK还是我维护的OpenWanderary,都是基于这个底层的API派生而来。
然后说说自己设计OpenWanderary的几个优点吧:
- 每个关键函数都有UnitTest测试,而且是数值一致性级别的。
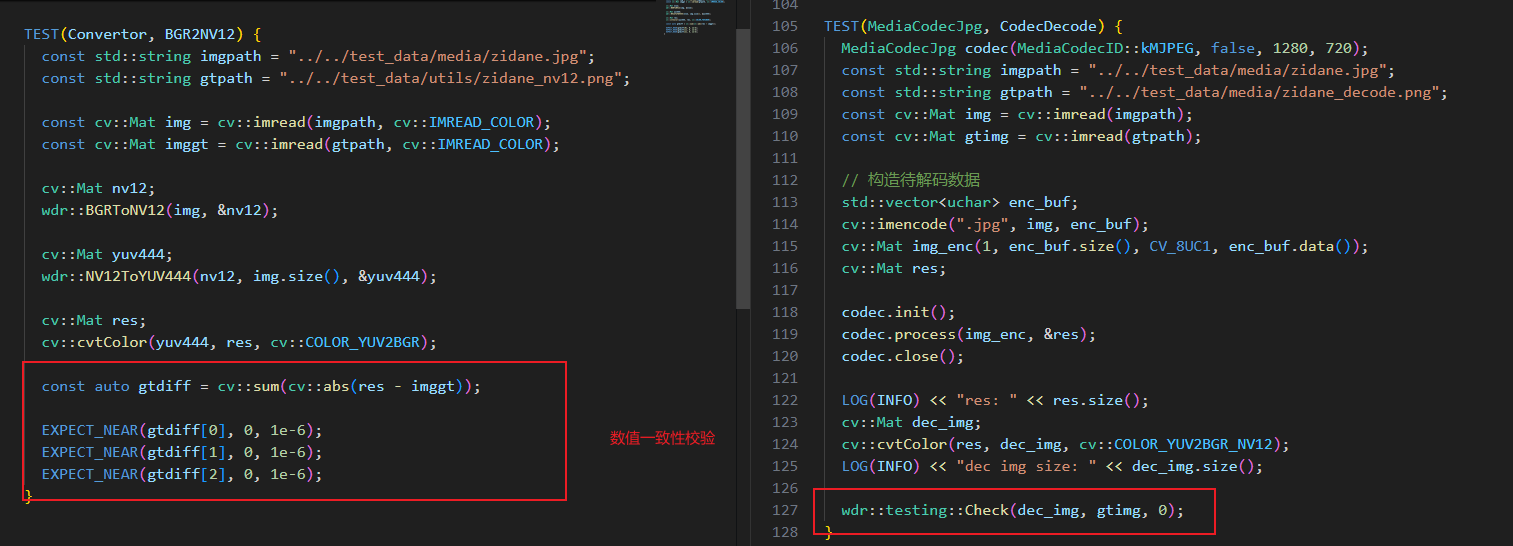
- 代码规范符合Google开发规范,并有pre-commit功能完成基本的规范性校验。
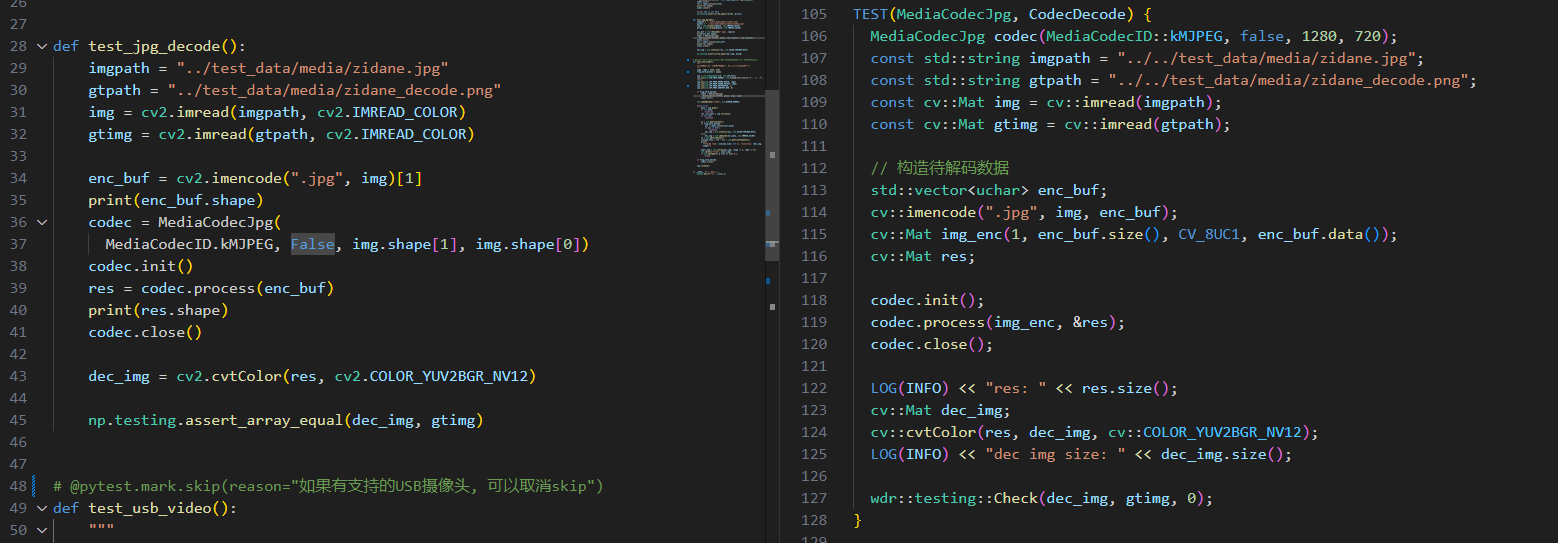
- Py接口利用PyBind对现有的C++进行封装,也同时有相关的UnitTest完成测试。
OpenWanderary目前处于持续开发中,迭代过程中部分函数接口会有一些变化,但会始终保持UnitTest的通过。
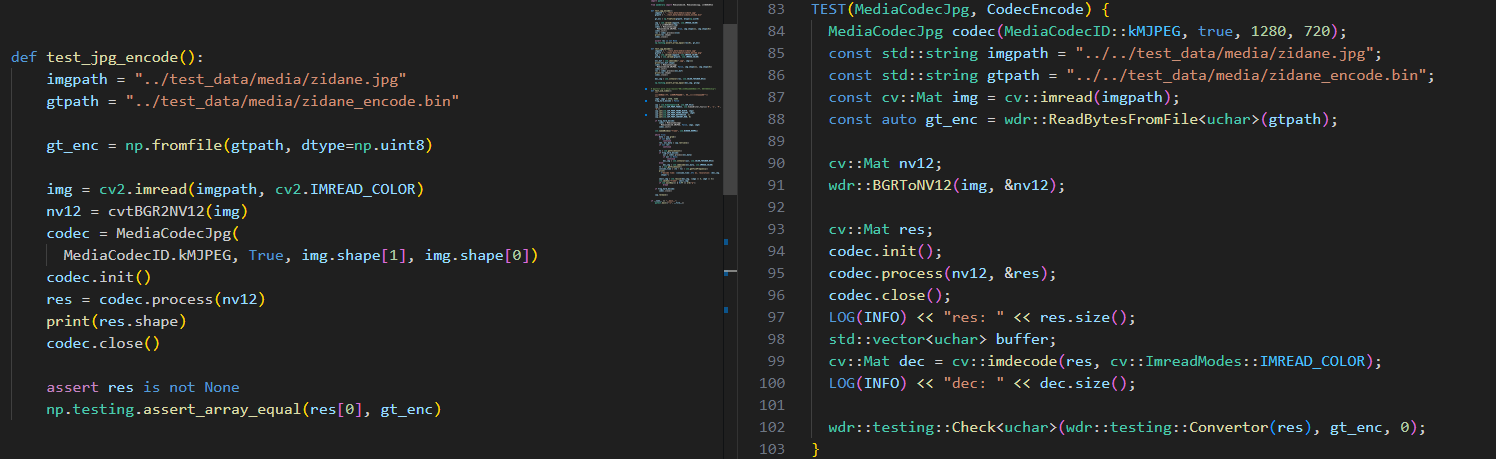
对应的编解码Py版本和C++版本的测试示例如下,MediaCodecJpg类负责MJPG的编解码;
- 构造阶段:可指定编码或解码
- 初始化以及释放都是
init()和close()函数,无序其他参数 - 无论是编码还是解码主函数都是process。编码时输入的是nv12数据,解码则是正常的1xN字节Mat。
四 小结
落地和出Demo完全是一个天一个地。出个Demo,去年就已经搞定了,但是如何将算法落地,达到丝滑的体验,需要更多的时间去打磨。OpenWanderary目前仍然处于初级阶段,我会慢慢将我的所有轮子都补充上去。
编解码问题我目前用着很稳定,各位可以放心食用。后面我也会慢慢完善BPU的接口适配,集成超神Cauchy_WuChao的顶级Yolo项目。