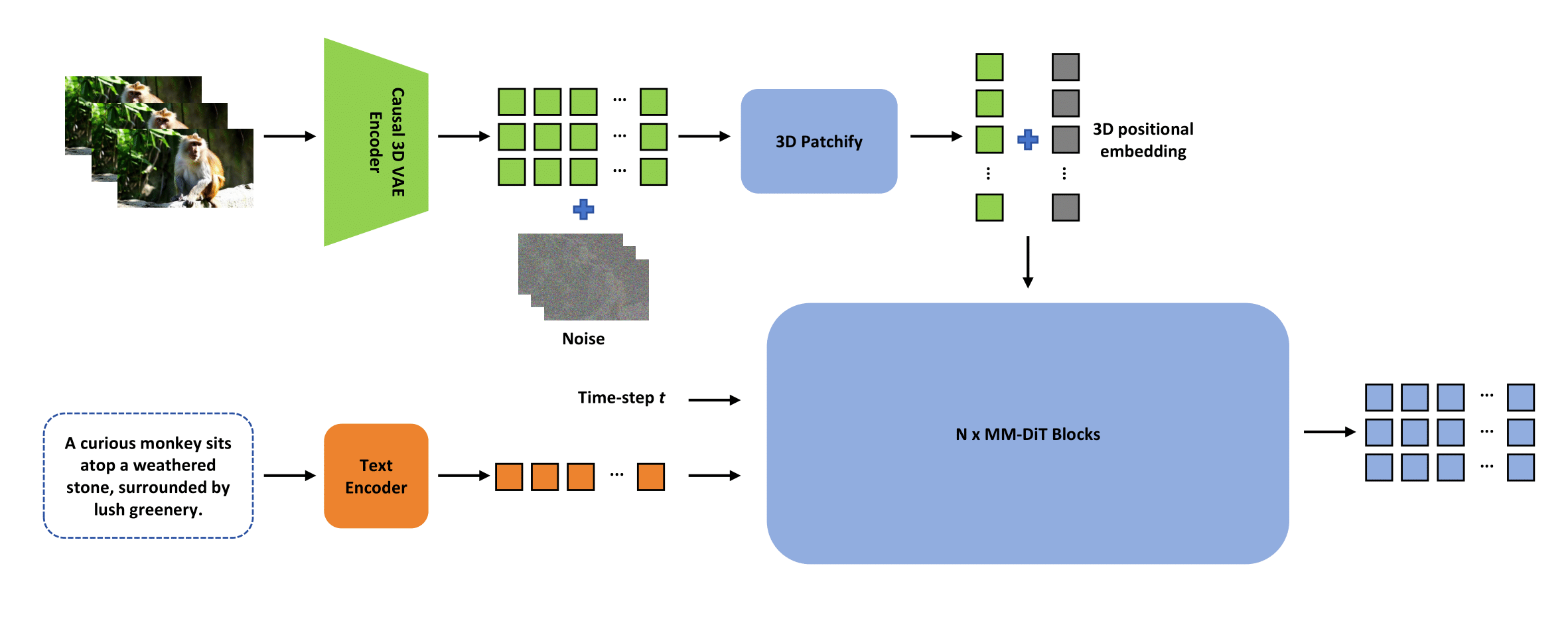
本项目提出了ContentV框架,通过三项关键创新高效加速基于DiT的视频生成模型训练:
- 极简架构设计,最大化复用预训练图像生成模型进行视频合成
- 系统化的多阶段训练策略,利用流匹配技术提升效率
- 经济高效的人类反馈强化学习框架,无需额外人工标注即可提升生成质量
我们开源的80亿参数模型(基于Stable Diffusion 3.5 Large和Wan-VAE)仅用4周时间在256×64GB NPU上训练,就取得了VBench评测85.14分的业界最佳成绩。

⚡ 快速开始
推荐PyTorch版本
- GPU版本:torch >= 2.3.1 (CUDA >= 12.2)
- NPU版本:torch和torch-npu >= 2.1.0 (CANN >= 8.0.RC2)。请参考昇腾PyTorch扩展安装torch-npu。
安装步骤
git clone https://github.com/bytedance/ContentV.git
cd ContentV
pip3 install -r requirements.txt
文生视频
## For GPU
python3 demo.py
## For NPU
USE_ASCEND_NPU=1 python3 demo.py
24GB消费级显卡可以使用,建议开启model offload。
📊 VBench
| Model | Total Score | Quality Score | Semantic Score | Human Action | Scene | Dynamic Degree | Multiple Objects | Appear. Style |
|---|---|---|---|---|---|---|---|---|
| Wan2.1-14B | 86.22 | 86.67 | 84.44 | 99.20 | 61.24 | 94.26 | 86.59 | 21.59 |
| ContentV (Long) | 85.14 | 86.64 | 79.12 | 96.80 | 57.38 | 83.05 | 71.41 | 23.02 |
| Goku† | 84.85 | 85.60 | 81.87 | 97.60 | 57.08 | 76.11 | 79.48 | 23.08 |
| Open-Sora 2.0 | 84.34 | 85.40 | 80.12 | 95.40 | 52.71 | 71.39 | 77.72 | 22.98 |
| Sora† | 84.28 | 85.51 | 79.35 | 98.20 | 56.95 | 79.91 | 70.85 | 24.76 |
| ContentV (Short) | 84.11 | 86.23 | 75.61 | 89.60 | 44.02 | 79.26 | 74.58 | 21.21 |
| EasyAnimate 5.1 | 83.42 | 85.03 | 77.01 | 95.60 | 54.31 | 57.15 | 66.85 | 23.06 |
| Kling 1.6† | 83.40 | 85.00 | 76.99 | 96.20 | 55.57 | 62.22 | 63.99 | 20.75 |
| HunyuanVideo | 83.24 | 85.09 | 75.82 | 94.40 | 53.88 | 70.83 | 68.55 | 19.80 |
| CogVideoX-5B | 81.61 | 82.75 | 77.04 | 99.40 | 53.20 | 70.97 | 62.11 | 24.91 |
| Pika-1.0† | 80.69 | 82.92 | 71.77 | 86.20 | 49.83 | 47.50 | 43.08 | 22.26 |
| VideoCrafter-2.0 | 80.44 | 82.20 | 73.42 | 95.00 | 55.29 | 42.50 | 40.66 | 25.13 |
| AnimateDiff-V2 | 80.27 | 82.90 | 69.75 | 92.60 | 50.19 | 40.83 | 36.88 | 22.42 |
| OpenSora 1.2 | 79.23 | 80.71 | 73.30 | 85.80 | 42.47 | 47.22 | 58.41 | 23.89 |