所有内容都是来源于这个
我们所说的cs模式就是custom和sever模式
爬虫Server,负责管理所有URL(即,爬虫客户端的下载任务)的状态,通过我们前面介绍的UrlPool(网址池)进行管理。还不知道UrlPool的同学可以搜索我们前面的文章,或者到《猿人学网站》上去看“Python爬虫教程”找到UrlPool的讲解。Server提供接口给Clients,以便它们获取URL和提交URL。
爬虫Client,负责URL的下载、网页的解析以及存储等各种。Client通过接口向Server请求需要被下载的URL,下载完成后向Server报告URL是否下载成功,同时把从网页中提取到的URLs提交给Server,Server把它们放入URLPool。
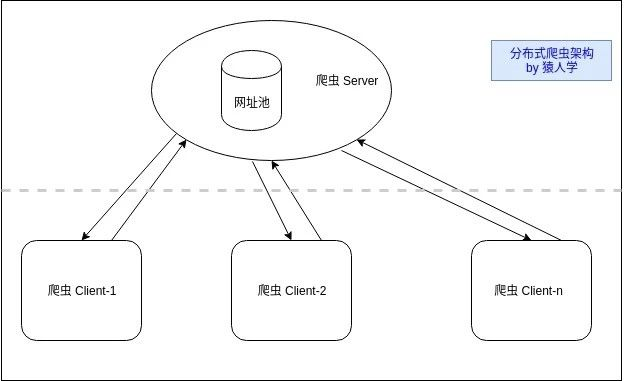
我们把这个分布式爬虫叫做“bee”(小蜜蜂),寓意一群蜜蜂去采蜜。分别创建Server和Client的文件:
bee_server.py
bee_client.py
#!/usr/bin/env python3
# 指定 Python3 解释器来执行脚本,让系统找到对应的 Python3 环境运行代码
# encoding: utf8
# 设置脚本文件的编码格式为 utf8,确保能正确处理中文字符等非 ASCII 字符
# author: veeltion
# 作者标识,表明代码由 veeltion 编写
# 从 sanic 框架中导入 Sanic 类,用于创建 Sanic 应用实例
from sanic import Sanic
# 从 sanic 框架中导入 response 相关功能,用于构造响应返回给客户端
from sanic import response
# 从自定义的 urlpool 模块(需确保存在该模块)中导入 UrlPool 类,用于管理 URL 相关操作
from urlpool import UrlPool
# 创建 UrlPool 实例,传入当前脚本文件的 __file__ 参数(可能用于一些路径相关初始化,具体看 UrlPool 类实现)
urlpool = UrlPool(__file__)
# 向 urlpool 中添加一个初始的 URL,这里添加的是新浪新闻的网址,可根据实际需求修改添加的 URL
urlpool.add('https://news.sina.com.cn/')
# 创建 Sanic 应用实例,__name__ 是 Python 中内置的变量,一般为模块名,Sanic 用它来标识应用等
app = Sanic(__name__)
# 定义一个监听器,当服务器停止后(after_server_stop 阶段)执行对应的函数
@app.listener('after_server_stop')
async def cache_urlpool(app, loop):
global urlpool # 声明使用全局作用域的 urlpool 变量
print('caching urlpool after_server_stop') # 打印提示信息,表明进入服务器停止后的缓存操作阶段
del urlpool # 删除 urlpool 实例,可能是做一些资源清理等操作
print('bye!') # 打印结束提示信息
# 定义一个路由,路径为 /task,请求方法默认是 GET(不写 methods 参数时,Sanic 默认为 GET 方法)
@app.route('/task')
async def task_get(request):
# 从请求的查询参数中获取 'count' 的值,如果没有则默认值为 10
count = request.args.get('count', 10)
try:
count = int(count) # 尝试将获取到的 count 值转为整数类型
except:
count = 10 # 如果转换失败(比如参数不是数字形式),就将 count 设为 10
urls = urlpool.pop(count) # 从 urlpool 中取出指定数量(count 个)的 URL
return response.json(urls) # 将取出的 URLs 以 JSON 格式响应返回给客户端
# 定义一个路由,路径为 /task,请求方法指定为 POST
@app.route('/task', methods=['POST', ])
async def task_post(request):
result = request.json # 获取请求中的 JSON 数据并赋值给 result
# 根据获取到的 JSON 数据中的 'url' 和'status',设置对应 URL 在 urlpool 中的状态
urlpool.set_status(result['url'], result['status'])
# 如果 JSON 数据中的 'url_real' 和 'url' 不相等
if result['url_real'] != result['url']:
# 为 'url_real' 对应的 URL 也设置相同的状态
urlpool.set_status(result['url_real'], result['status'])
if result.get('newurls'): # 如果 JSON 数据中存在 'newurls' 字段(即有新的 URL 列表)
print('receive URLs:', len(result['newurls'])) # 打印接收到的新 URL 的数量
for url in result['newurls']: # 遍历新的 URL 列表
urlpool.add(url) # 将每个新 URL 添加到 urlpool 中
return response.text('ok') # 返回文本响应 'ok' 给客户端,表示处理完成实体信息
- 类名:
CrawlerClient,代表爬虫客户端类,用于封装爬虫相关的属性和方法。 - 依赖库:使用了
asyncio(用于异步操作)、aiohttp(用于异步 HTTP 请求)、chardet(用于检测网页编码 ,代码中chardet.detect调用处需确保该库已正确安装导入 )。
class CrawlerClient:
def __init__(self, ):
# 已创建的工作线程/任务数
self.workers = 0
# 最大工作线程/任务数限制
self.workers_max = 10
# 服务器主机地址,设为本地
self.server_host = 'localhost'
# 服务器端口
self.server_port = 8080
# 请求头,模拟特定浏览器(这里模拟较旧的 IE 浏览器 User - Agent)
self.headers = {'User - Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; '
'Windows NT 6.1; Win64; x64; Trident/5.0)')}
# 获取异步事件循环
self.loop = asyncio.get_event_loop()
# 创建异步队列,用于任务等管理,依赖上面的事件循环
self.queue = asyncio.Queue(loop=self.loop)
# 创建 aiohttp 的客户端会话,用于发起异步 HTTP 请求,依赖事件循环
self.session = aiohttp.ClientSession(loop=self.loop)
async def download(self, url, timeout=25):
# 初始化状态码,900 可视为自定义的初始错误码之类
status_code = 900
html = ''
url_now = url
try:
# 发起异步 GET 请求,携带请求头和超时时间,使用 async with 管理响应上下文
async with self.session.get(url_now, headers=self.headers, timeout=timeout) as response:
status_code = response.status # 获取响应状态码
html = await response.read() # 读取响应内容(异步等待读取完成)
# 检测网页内容编码,chardet.detect 返回包含编码信息的字典,取出编码
encoding = chardet.detect(html)['encoding']
# 按检测到的编码解码网页内容,忽略解码错误
html = html.decode(encoding, errors='ignore')
url_now = str(response.url) # 获取实际请求的 URL(可能有重定向等情况,和传入 url 不同)
except Exception as e: # 捕获所有异常
# 打印异常信息,包括异常对象、类型、描述
print('=== exception: ', e, type(e), str(e))
# 构造失败提示信息,包含 URL 和异常详情
msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(e)), str(e))
print(msg)
# 返回状态码、网页内容、实际请求的 URL
return status_code, html, url_now 代码主要实现了一个基础的异步爬虫客户端类,__init__ 方法初始化爬虫相关的配置(如工作线程数、服务器地址、请求头、异步循环、队列、会话等 ),download 方法用于异步下载指定 URL 的网页内容,处理请求、编码检测及异常捕获等逻辑 。不过代码中 chardet 若未提前导入会报错,实际使用需补充相关导入语句(如 import chardet ),且 aiohttp 等库也需确保已正确安装 。
我们把Client写成一个类,这个类一部分接口是与Server交互用的,也就是从Server那里获取要下载的URL,以及向Server提交新得到的URLs。另外一部分接口是与互联网交互的,即下载URLs。
通过异步IO,我们可以把Client的并发提高上去,达到更高的抓取速度。
先来看看这个类的初始
其中,self._workers 记录当前正在下载的协程(即,并发数);
sellf.workers_max 是限制最大并发数,根据自己的CPU性能和网络带宽调整其大小,从而达到最大效率利用硬件资源。
download()方法是对aiohttp的封装,方便异步下载。