一、人工智能与机器学习基础
1.1 AI、ML与DL的层次关系
概念定位与核心思想:
人工智能(AI) 是让机器模拟人类智能行为的宏观领域,目标是构建能推理、决策和感知的系统。AI就像整个教育体系的总目标,旨在培养具有各种能力的"聪明"学生,涵盖从基本常识到高级技能的所有方法。
机器学习(ML) 是实现AI的核心路径,通过数据训练模型来自动优化性能(无需显式编程)。ML相当于系统化的课程学习,通过习题和考试让学生逐步掌握知识,教会系统从数据中总结经验。
深度学习(DL) 是ML的一个特殊子领域,基于多层神经网络从原始数据中自动学习多层次特征表示。DL则像专注于某个学科的密集培训班(如科学实验营),通过深层神经网络掌握复杂技能。
。三者的关系可表示为:AI ⊃ ML ⊃ DL,如同大小不一的俄罗斯套娃。
技术范式对比:
| 维度 | 机器学习(ML) | 深度学习(DL) |
|---|---|---|
| 数据依赖 | 中小规模数据(千~百万级) | 海量数据(百万~十亿级) |
| 特征处理 | 依赖人工特征工程 | 自动学习特征 |
| 计算需求 | CPU即可训练 | 需GPU/TPU等异构计算 |
| 适用任务 | 结构化数据(表格、日志) | 非结构化数据(图像、语音、文本) |
| 可解释性 | 决策树等模型可解释性高 | 黑盒特性(需XAI技术辅助解释) |
应用场景示例:银行信用评分等结构化数据任务优先选择ML(如XGBoost),而图像识别和自然语言处理等非结构化数据任务优先选择DL(如CNN/Transformer)。
1.2 机器学习核心要素
样本/特征/标签定义:
- 样本(Sample):数据集中的一行数据(一条记录),如一张猫狗图片的像素数据。
- 特征(Feature):描述样本的属性或指标(如图片的像素值、文本的TF-IDF向量),一列数据代表一个特征。
- 标签(Label/Target):模型要预测的目标值(如"猫"或"狗"的分类标签),在监督学习中与样本对应。
数据集划分标准:
from sklearn.model_selection import train_test_split
# 典型划分比例:训练集70-80%,测试集20-30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)实践建议:当数据存在时间序列特性时,应采用时间顺序划分而非随机划分,避免未来信息泄露。
二、机器学习框架与数据处理
2.1 算法分类体系
监督学习典型场景:
- 分类任务:电子邮件垃圾识别(输入邮件内容,输出"垃圾"或"正常")
- 回归任务:房价预测(输入房屋特征,输出连续型价格)
- 核心特点:训练数据包含特征和对应的标签,像老师教学生提供"题目+答案"
无监督学习典型场景:
- 聚类分析:客户分群(根据消费行为将用户分成不同组别)
- 降维处理:PCA将高维基因数据压缩到二维可视化
- 核心特点:没有标准答案,让机器自己发现数据中的隐藏结构
强化学习典型场景:
- 游戏AI:AlphaGo通过奖励(赢棋)和惩罚(输棋)学习最佳策略
- 机器人控制:机械臂通过试错学习抓取物体的最优动作序列
- 核心机制:智能体(Agent)在环境(Environment)中执行动作(Action)获得奖励(Reward)
2.2 特征工程核心作用
特征处理技术:
# 特征选择示例:基于卡方检验选择最佳特征
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=10)
X_new = selector.fit_transform(X, y)
# 特征提取示例:PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=0.95) # 保留95%方差
X_pca = pca.fit_transform(X)业务理解与特征稳定性:
- 领域知识融合:在医疗诊断中,结合医学知识构造"症状组合特征"比单独使用原始体征更有效。
- 稳定性验证:金融风控模型中,特征在不同时间段的表现应保持一致(如季度波动<5%)。
2.3 数据归一化与标准化
数学表达与实现:
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Min-Max归一化(压缩到[0,1]区间)
minmax_scaler = MinMaxScaler()
X_normalized = minmax_scaler.fit_transform(X)
# Z-score标准化(均值为0,标准差为1)
std_scaler = StandardScaler()
X_standardized = std_scaler.fit_transform(X)应用场景对比:
| 场景 | 推荐方法 | 实例 | 原因说明 |
|---|---|---|---|
| 图像处理 | 归一化 | 将像素值从[0,255]映射到[0,1] | 神经网络激活函数需要固定输入范围 |
| 金融风控模型 | 标准化 | 将收入(万元级)和年龄(十岁级)统一 | 消除量纲差异对距离计算的影响 |
| 包含异常值的数据集 | 标准化 | 房屋价格中存在少量豪宅记录 | 标准化对异常值不敏感 |
| 需要概率输出的模型 | 归一化 | 朴素贝叶斯分类器 | 符合概率分布特性 |
关键认知:标准化不改变数据分布形态,而归一化将数据压缩到固定区间。当特征存在明显异常值时,标准化通常表现更好。
三、核心算法原理与应用
3.1 距离度量与KNN算法
距离计算数学表达:
欧氏距离:多维空间直线距离

适用于空间坐标等连续变量曼哈顿距离:网格路径绝对距离和

适用于城市街区路径、高维稀疏数据。
KNN分类实战示例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
# 加载乳腺癌数据集
data = load_breast_cancer()
X, y = data.data, data.target
# 数据标准化(KNN对尺度敏感)
X = StandardScaler().fit_transform(X)
# 创建KNN模型(k=5,距离加权)
knn = KNeighborsClassifier(n_neighbors=5, weights='distance')
knn.fit(X_train, y_train)
# 评估准确率
print("测试集准确率:", knn.score(X_test, y_test))调参建议:通过交叉验证选择最佳K值,避免过小K值(噪声敏感)或过大K值(忽略局部特征)。
3.2 线性回归与优化
损失函数与优化目标:
- 均方误差(MSE):

对异常值敏感,回归任务首选 - 平均绝对误差(MAE):

鲁棒性强,不易受异常值影响
正规方程求解过程:
import numpy as np
# 添加偏置项
X_b = np.c_[np.ones((len(X), 1)), X]
# 正规方程:θ = (XᵀX)⁻¹Xᵀy
theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
# 预测新样本
X_new = np.array([[1], [2]]) # 新数据
X_new_b = np.c_[np.ones((2, 1)), X_new]
y_pred = X_new_b.dot(theta)梯度下降动态演示:
# 批量梯度下降实现
def gradient_descent(X, y, learning_rate=0.01, epochs=1000):
m = len(X)
theta = np.random.randn(X.shape[1], 1) # 随机初始化参数
loss_history = []
for epoch in range(epochs):
gradients = 2/m * X.T.dot(X.dot(theta) - y)
theta -= learning_rate * gradients
loss = np.mean((X.dot(theta) - y)**2)
loss_history.append(loss)
# 学习率衰减
if epoch % 100 == 0:
learning_rate *= 0.9
return theta, loss_history学习率选择技巧:从0.001开始尝试,观察损失曲线。理想情况下损失应平稳下降,震荡说明学习率过大,下降过慢则需调大。
3.3 逻辑回归与评估指标
Sigmoid函数与决策边界:
import matplotlib.pyplot as plt
# Sigmoid函数定义
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 可视化Sigmoid曲线
z = np.linspace(-10, 10, 100)
s = sigmoid(z)
plt.plot(z, s)
plt.axhline(y=0.5, color='r', linestyle='--')
plt.title("Sigmoid函数与决策阈值(0.5)")精确率-召回率权衡:
- 精确率(Precision):

关注预测为正的样本中有多少真实为正(查准率) - 召回率(Recall):

关注真实为正的样本中有多少被正确召回(查全率)
ROC-AUC曲线绘制:
from sklearn.metrics import roc_curve, auc
# 计算ROC数据
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)
# 绘制曲线
plt.plot(fpr, tpr, color='darkorange', label=f'ROC (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--') # 随机猜测线
plt.xlabel('假正率(FPR)')
plt.ylabel('真正率(TPR)')
plt.title('ROC曲线')
plt.legend()场景选择:
- 金融反欺诈:高精确率优先(减少误伤正常交易)
- 疾病筛查:高召回率优先(减少漏诊)
四、模型泛化与集成学习
4.1 过拟合与正则化
过拟合/欠拟合表现形式:

L1/L2正则化对比:
- L1正则化(Lasso):损失函数 +

产生稀疏权重向量,天然特征选择 - L2正则化(Ridge):损失函数 +

权重平滑衰减,防止极端权重值
工程实践:深度学习中使用Dropout(随机失活)作为隐式正则化,训练时随机丢弃神经元防止过拟合。
4.2 决策树与集成方法
决策树核心算法对比:
| 算法 | 特征选择准则 | 树结构 | 处理特征类型 | 剪枝支持 |
|---|---|---|---|---|
| ID3 | 信息增益 | 多叉树 | 仅离散特征 | 不支持 |
| C4.5 | 信息增益比 | 多叉树 | 离散+连续 | 后剪枝 |
| CART | 基尼指数/均方误差 | 二叉树 | 离散+连续 | 预剪枝+后剪枝 |
随机森林双重随机性:
- 数据随机:Bootstrap采样构建子集
- 特征随机:节点分裂时随机选择特征子集
from sklearn.ensemble import RandomForestClassifier
# 创建包含100棵树的随机森林
rf = RandomForestClassifier(n_estimators=100,
max_features='sqrt',
oob_score=True)
rf.fit(X_train, y_train)
# 获取袋外分数(OOB)
print("OOB准确率:", rf.oob_score_)4.3 高级集成算法
GBDT残差拟合过程:
from sklearn.ensemble import GradientBoostingRegressor
# 梯度提升树回归
gbdt = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,
max_depth=3)
gbdt.fit(X_train, y_train)
# 可视化训练过程
plt.plot(gbdt.train_score_)
plt.title("GBDT每轮迭代损失")XGBoost优化创新:
- 二阶泰勒展开:使用损失函数的一阶和二阶导数
- 正则化目标函数:

- 特征并行与分位点加速:支持特征预排序和加权分位数策略
- 缺失值自动处理:学习默认分裂方向
import xgboost as xgb
# 创建DMatrix数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
# 参数设置
params = {'max_depth': 3,
'objective': 'binary:logistic',
'subsample': 0.8}
# 训练模型
model = xgb.train(params, dtrain, num_boost_round=100)算法选择指南:中小数据集选XGBoost(精度高),大数据集选LightGBM(速度快),需要可解释性选随机森林。
五、无监督学习与降维
5.1 K-means聚类
算法流程可视化:

肘部法则确定K值:
from sklearn.cluster import KMeans
inertias = []
K_range = range(1, 10)
for k in K_range:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
inertias.append(kmeans.inertia_) # 簇内平方和
# 绘制肘部曲线
plt.plot(K_range, inertias, 'bo-')
plt.xlabel('K值')
plt.ylabel('簇内平方和')数据预处理要点:K-means对特征尺度和异常值敏感,应用前必须标准化并清洗数据。
5.2 特征降维技术
PCA最大方差理论:
- 数据中心化:

- 计算协方差矩阵:
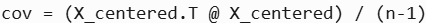
- 特征值分解:

- 选择主成分:按特征值降序取前k个特征向量
- 数据投影:

相关系数应用场景:
- 皮尔逊相关系数:线性关系强度(如广告投入与销售额)
- 斯皮尔曼秩相关:单调关系评估(如用户满意度排名)
- 肯德尔τ系数:有序分类变量一致性(如评委打分一致性)
六、工程实践与API调用
6.1 Scikit-learn应用示例
随机森林分类实战:
# 泰坦尼克生存预测
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 特征工程
df['FamilySize'] = df['SibSp'] + df['Parch']
df['Title'] = df['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
# 训练模型
rf = RandomForestClassifier(n_estimators=200,
max_depth=5,
class_weight='balanced')
scores = cross_val_score(rf, X, y, cv=5, scoring='f1')
# 输出交叉验证结果
print(f"F1均值: {scores.mean():.3f} (±{scores.std():.3f})")朴素贝叶斯文本分类:
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
# 文本向量化
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
# 训练朴素贝叶斯
nb = MultinomialNB(alpha=0.1) # 平滑参数
nb.fit(X_train_tfidf, y_train)
# 预测新样本
X_new = ["优惠促销!限时折扣"]
X_new_tfidf = tfidf.transform(X_new)
print("预测类别:", nb.predict(X_new_tfidf))6.2 模型部署优化
PCA降维加速推理:
from sklearn.decomposition import PCA
# 保留95%的方差
pca = PCA(n_components=0.95)
X_train_pca = pca.fit_transform(X_train)
# 在降维数据上训练模型
model.fit(X_train_pca, y_train)
# 部署时相同变换
X_test_pca = pca.transform(X_test)
predictions = model.predict(X_test_pca)模型压缩技术:
- 权重剪枝:移除接近零的权重
- 量化:将32位浮点转为8位整数
- 知识蒸馏:用小模型学习大模型输出
边缘部署建议:移动端优先选择树模型或轻量神经网络,避免大型深度学习模型的高计算开销。
总结与展望
本文系统性地介绍了机器学习的核心概念、经典算法和工程实践。从基础的AI/ML/DL区分,到监督学习、无监督学习和强化学习的分类体系;从特征工程的重要性,到各类算法的数学原理和实现细节;最后延伸到模型评估、集成学习和部署优化等实战内容。
关键认知要点:
- 没有免费午餐定理:不存在适用于所有问题的最佳算法,需根据数据特性和业务目标选择
- 偏差-方差权衡:简单模型高偏差(欠拟合),复杂模型高方差(过拟合)
- 可解释性与精度权衡:金融风控等场景需牺牲部分精度换取可解释性
未来学习方向:
- 自动化机器学习(AutoML):自动特征工程、超参数调优
- 可解释AI(XAI):LIME、SHAP等模型解释技术
- 联邦学习:在数据隐私保护下的分布式模型训练