原创 化心为海
3.2 线性回归
本章节首先介绍了正规方程和梯度下降的基本原理,其次介绍了模型评估方法和指标,最后通过线性回归模型预测房价。
🚜 什么是线性回归
线性回归是一种线性方法,用于对因变量y和一个或多个自变量之间的关系进行建模。如果自变量个数为1则称为一元回归分析,当有两个或两个以上自变量时,称为多元回归分析。线性回归主要解决回归问题,即对连续型变量进行预测,如房价,销售量等。
线性回归是一种解决回归问题的常用方法。在线性回归中,求解最优参数的方法是最小化其损失函数。最小化损失函数有两种方法:正规方程和梯度下降法。正规方程通过矩阵求得最优参数,梯度下降法是沿负梯度的方向一步步最小化损失函数,求解最优参数。
线性回归的目标是,对于输入向量x,预测其目标值y。例如,预测房屋价格,以y表示要预测的房屋价格,以向量x中的元素xⱼ表示房屋的特征(如房屋面积、卧室数量等)。已知很多房屋数据中,用xᵢ表示第i个房屋的特征,用yᵢ表示其房屋价格。
下面通过公式推导,演示如何使用线性回归解决连续型数据预测的问题。
因为是连续型数据的预测,我们希望找到一个函数,yᵢ = h(x),则可以通过h(x)对未知价格的房屋进行房价预测。我们采用线性函数表示h(x),即h(x)=ωᵀx。现在的问题是如何从已知的数据中找到最优的w参数,满足任意的yᵢ = ωᵀxᵢ。即通过h(x)得到的预测值和真实值是一样的,他们之间的差值为0。在有限的数据集中并不能找到一个理想的ω,不过可以基于现有的数据集找到接近于理想值的ω。同时,采用平方误差来评估ω是否最接近理想值,公式如下:
![]()
该函数可以作为线性回归的损失函数,损失函数值越小,则ω越接近理想值。
🚜 正规方程(Normal Equation)
正规方程是线性回归中用于直接求解最优参数ω的解析方法,其核心是通过最小化平方误差损失函数推导出闭式解。以下是详细的求导过程(来源:deepseek):
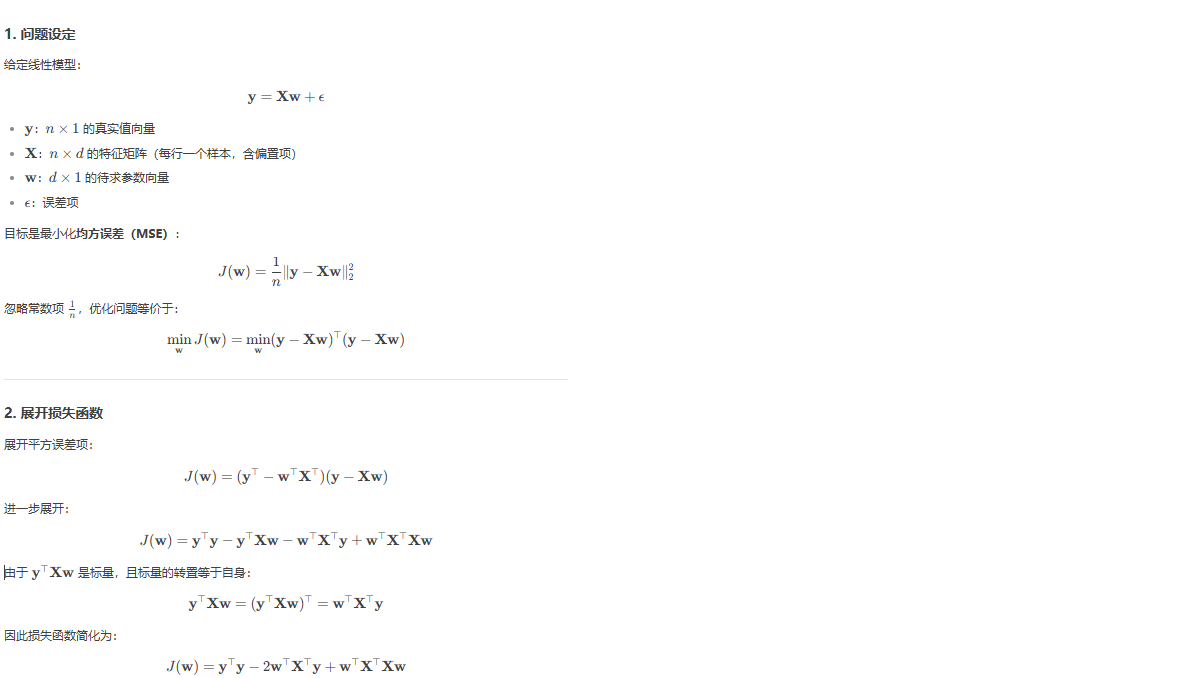


综上,正规方程中有一项 (XᵀX)⁻¹,因此,XᵀX必须可逆。当样本数小于特征数时,XᵀX的逆是不可以直接计算的。如果XᵀX不可逆,比如一些特征存在线性依赖时,一般可以考虑删除冗余特征;如果样本数小于特征数,则要删除一些特征。
#python代码实现正规方程求解示例
#python代码实现正规方程求解示例
import numpy as np
# 生成数据
X = np.array([[1, 1], [1, 2], [1, 3]]) # 含偏置项
y = np.array([2, 3, 4])
# 正规方程求解
w = np.linalg.inv(X.T @ X) @ X.T @ y
print(w) # 输出: [1. 1.](即 w0=1, w1=1)代码解释:

3.2.1 🚜 梯度下降法
除了正规方程意外,在求解机器学习算法的模型参数时,另一种常见的方法是梯度下降法。
1.什么是梯度?
多元函数对每个参数求偏导,然后将各个参数的偏导数组合成一个向量,该向量称为梯度。它的几何意义是函数增加最快的方向。例如,f(x,y),对参数x求偏导为∂f/∂x,对参数y求偏导为∂f/∂y,组成梯度向量(∂f/∂x, ∂f/∂y)ᵀ,简称为∇f(x,y)。函数f(x,y)在点(x0,y0)处沿着∇f(x,y)移动,其函数值增加的最快,换一句话说,如果沿着梯度的反方向,则函数值下降的最快,更容易找到最小值。
In [11]:
#梯度下降代码示意图
#梯度下降代码示意图
import numpy as np
import matplotlib.pyplot as plt
# 定义目标函数和梯度
def f(x): return x**2 - 4*x + 1
def df(x): return 2*x - 4
# 梯度下降迭代
x = 50 # 初始值
alpha = 0.1
path = []
for _ in range(100):
path.append(x)
x = x - alpha * df(x)
# 绘制函数和路径
x_vals = np.linspace(-10, 50, 100)
plt.plot(x_vals, f(x_vals), 'b-')
plt.plot(path, [f(p) for p in path], 'ro--')
plt.xlabel('x'), plt.ylabel('f(x)')
plt.show()
2.什么是梯度下降?
优化模型的目标是最小化损失函数。我们可以通过梯度下降的方法解决损失函数的问题,即沿着负梯度方向一步一步接近最小值。从一个更直观的角度理解梯度下降,加入站在山上某一处,梯度下降方向即最陡峭的下坡方向,我们沿着最陡峭的下坡方向下山, 可以最快速地到达山脚下。
运用梯度下降法能否一定可以找到全局最优解吗?并不一定,梯度下降法可能只会得到局部最优解,就像最陡峭的下坡方向不一定能直接通向山脚,可能只达到山峰的低处。

图片来源:《深入理解XGBoost:高效机器学习算法与进阶》,侵权删除
3.梯度下降算法过程
首先,确定损失函数的梯度,对于当前位置ωⱼ,梯度如下:

然后,用步长α乘以梯度,得到当前梯度下降的距离

检查梯度下降的距离是否小于阈值ε,若小于则算法停止,否则更新ω,对于ωⱼ,有

更新ω后再次检查下降距离和阈值ε的关系,重复上述步骤直至算法停止。可以看到,在计算梯度距离时会乘一个步长系数α,梯度向量决定了梯度下降的方向,而步长则决定了梯度下降的距离,还是以下山为例,步长就是沿最陡峭的方向向前走一步的距离。
4.梯度下降的方式
梯度下降法有多种方式,如批量梯度下降法、随机梯度下降法、mini-batch梯度下降法等。
🚜批量梯度下降法是每次使用所有样本来更新参数,前面介绍的方法用的就是批量梯度下降法。
🚜随机梯度下降法是每次只使用一个样本来更新参数。
这两种方法的优缺点都非常明显。批量梯度下降计算量比较大,训练速度慢,而随机梯度下降因为只需要一个样本,因此训练速度大大加快了。但随机梯度下降法仅用一个样本决定梯度的方向,导致其可能并不是最优的方向,迭代方向变化较大,函数收敛较慢。
🚜mini-batch梯度下降法是以上两种方法的折中算法,每次选取一个样本集的子集(mini-batch)进行参数更新,从而平衡了前两种方法的优缺点。
小贴士:批量梯度过程说明以及示例:(源自:deepseek)

示例如下:


