文章目录
问题:什么是生成式人工智能
Generative Al
目标:机器生成复杂有结构的物件
- 有结构:如文章(文字组成)、影像(像素组成)和语音(取样点组成)
- 复杂:没有办法穷举
比如让写一篇100字的中文文章,假设中文常用字为1000(实际更多),用中文组成100字的文章有1000100 =1030 种可能性。
不是生成式AI的例子:
- 分类(Classification):从有限的选项种做选择
生成式AIGenerative Al与机器学习Machine Learning的关系
机器学习:机器自动从资料(训练资料)找一个函数 => 学习(训练)指的是通过训练资料找出函数中的参数 => 给找到参数的函数一个新的图片,观察函数的输出,这个过程被称为测试(推论)

深度学习Deep Learning:将上万个参数的函数表示为类神经网络并求解的技术

总结

问题:深度学习怎么解生成式人工智能的问题?
可以将ChatGPT想象成一个非常复杂的函数,输入是一段文字,输出是ChatGPT的回复。
这个上亿参数的类神经网络,被称为Transformer。
输入一大堆的训练资料,利用深度学习技术将上亿个参数找出来。

生成式AI的挑战
**挑战:**机器需要能够产生在训练时从来没有看过(训练中没有)的东西
问题: chatGPT中如何产生训练时从来没有看过的东西?
核心:文字接龙,可以做文字接龙的模型被称为语言模型
在chatGPT中,生成一个答案被拆解成一连串文字接龙。

**将生成完整答案改成一系列文字接龙的好处: **生成式AI的难点是可能的答案无穷无尽,而文字接龙的答案是有限的(只需要猜下一个字是什么) => 将生成式AI问题转换为一系列的分类问题

语言模型是生成式AI的其中一个技术

其他生成策略
Autoregressive Generation自回归生成策略:将复杂物件拆解成较小的单位,按照某种固定的顺序依序生成(chatGPT采用)

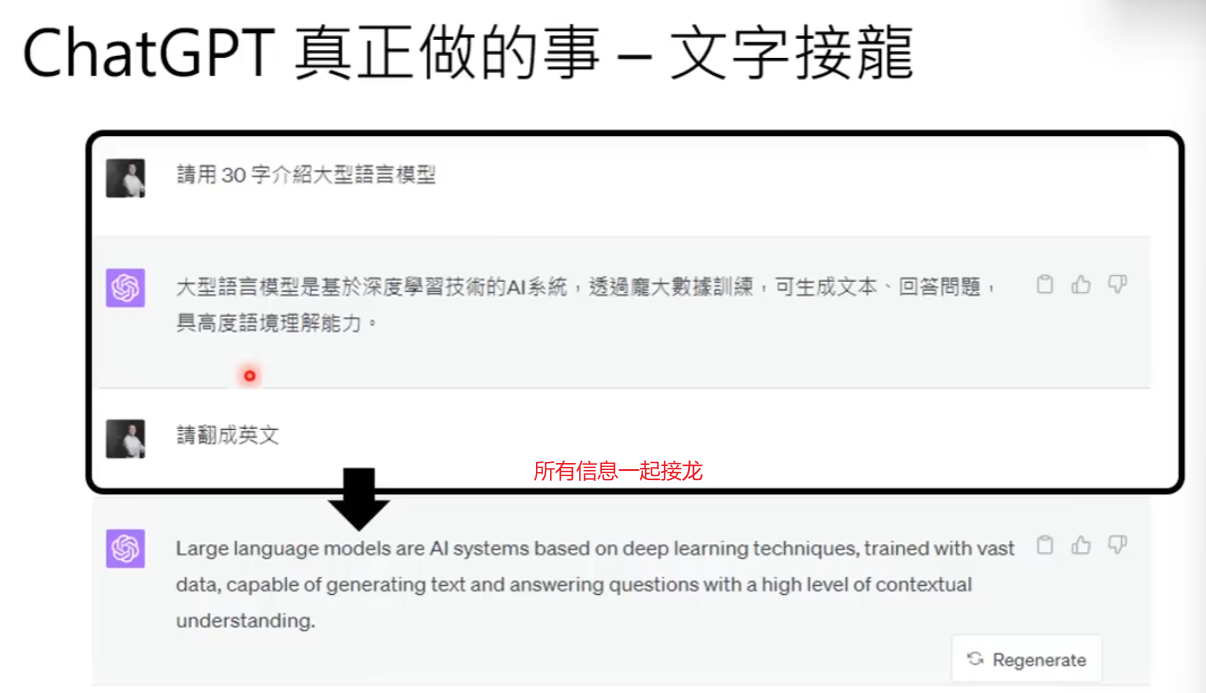
ChatGPT真正做的事:文字接龙
chatGPT
G: Generative 生成
P: Pre-trained 预训练
T: Transformer
chatGPT真正做的事:文字接龙
在chatGPT中,生成一个答案被拆解成一连串文字接龙
**将生成完整答案改成一系列文字接龙的好处: **生成式AI的难点是可能的答案无穷无尽,而文字接龙的答案是有限的(只需要猜下一个字是什么) => 将生成式AI问题转换为一系列的分类问题

chatGPT中生成多少Token花多少钱,这里的Token指的就是可以选择的符号 ,每一个语言模型定义的Token是不一样,Token是预先设定好的。

问题:为什么英文Token不是单词
解答:因为英文单词无法穷举 => Token需要被穷举,chatGPT才可以给出每一个Token对应的概率
补充:在chatGPT中一个中文方块字往往是好几个Token
**问题:**为什么要掷色子决定输出,而不是选择几率最高的Token作为输出?
由于最后输出是通过掷色子决定,所以对于同样的问题chatGPT每次的答案都不相同。
答案:每次都选择几率最大的符号不一定得到最好的结果

问题:chatGPT本质并没有理解问题的概念,只是用概率生成一段文字。那么chatGPT怎么知道过去的聊天记录?
答案:同一个聊天记录里,过去的问题和GPT的回答都会作为文字接龙的一部分。
语言模型怎么学习文字接龙?
任何文句都可以是训练资料,通过资料调整输出的选项概率

语言模型的背后是一个类神经网络,一般语言模型采用的类神经网络为Transformer

深度学习
Deep Learning:将上万个参数的函数表示为类神经网络并求解的技术 => 类神经网络本质就是一个函数,只是函数的表示方法像一个网络。
下一个阶段:GPT->ChatGPT
预训练与监督学习


GPT3以前从网络资料中学习做文字接龙,所有资料都学习并不清楚人类想要什么(自监督学习) => ChatGPT让人类告诉GPT人类想要的答案是什么(监督学习)
如果跟老师学习看成真正的训练,在网络上自己教自己可以看成预训练

预训练的重要性:有预训练后,监督学习不用大量资料(人类不需要教太多)
在多种语言上做预训练后,只需要教某一个语言的某一个任务,模型就可以自动学会其他语言的同样任务。

强化学习Reinforcement Learning
人类老师不提供正确答案,而是提供回馈告诉语言模型答案的好坏。
相比于监督学习,强化学习更人力。

**强化学习基本概念:**通过人类反馈的好坏,模型会想办法提高好答案的几率降低差答案的几率
注意:模型需要有一定程度的能力才能进入强化学习(需要先有输出的答案,才能进一步学习哪一个答案更好)
ChatGPT背后的强化学习分为两个步骤
① 模仿人类老师的喜好 => 学习人类老师的偏好
得到人类答案之后,ChatGPT又训练了一个Reward Model,输入人类的答案输出一个分数

②利用训练到的Reward Model(充当人类老师)去教语言模型
将答案输入给Reward Model如果得到低分,则降低这个答案的几率。如果得到高分,则升高这个答案的几率。

Alignment对齐(对其人类的的需求)=监督式学习+强化学习

语言模型的使用
- 讲清楚需求
- 提供资讯给
ChatGPT,因为ChatGPT是做文字接龙,所以前提资讯很重要

- 提供范例给
ChatGPT

- 鼓励
ChatGPT想想了,会提高准确率

- 如何找出神奇咒语

ChatGPT可以使用其他工具
没有使用其他工具时,通过文字接龙的方式回答,答案有对有错。


并不是说ChatGPT使用其他工具就可以得到完全正确的答案。比如ChatGPT使用搜索引擎回答以下问题时,以为全台最大的缩写就是台大。
语言模型做的事就是根据搜索引擎的结果继续**文字接龙,**并不保证一定不会犯错。

- 当问题很难时,可以选择拆解任务喂给
ChatGPT ChatGPT是会反省的 => 请检查上述咨询是否正确等话术- 让语言模型和真实环境互动

