最近项目用到了Doris,其实之前也用过Doris ,这次总结一下Doris基础。参考资料为官方文档:https://doris.apache.org/zh-CN/docs/3.0/gettingStarted/what-is-apache-doris,官方文档写的比较明了,而且是中文的。
1.简介
1.1历史
Apache Doris 最初是百度广告报表业务的 Palo 项目。2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化。在 Apache 导师的指导下,由孵化器项目管理委员会成员进行孵化和运营。2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。目前,Apache Doris 社区已经聚集了来自不同行业数百家企业的 600 余位贡献者,并且每月活跃贡献者人数超过 120 位。
1.2架构
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。MPP(Massively Parallel Processing)是一种通过多个处理器或节点并行处理数据的大规模并行处理架构。
1.3使用场景
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
2.整体架构
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各类客户端工具访问 Apache Doris,并支持与 BI 工具无缝集成。Doris 的整体架构由两类进程组成:Frontend (FE) 和 Backend (BE)。其中 FE 主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作;BE 主要负责数据存储、查询计划的执行。在部署 Apache Doris 时,可以根据硬件环境与业务需求选择存算一体架构或存算分离架构。
2.1存算一体架构
FE 和 BE 进程都可以横向扩展。单个集群可以支持数百台机器和数十 PB 的存储容量。FE 和 BE 进程通过一致性协议来保证服务的高可用性和数据的高可靠性。存算一体架构高度集成,大幅降低了分布式系统的运维成本。

优点
- 部署简易:Apache Doris 不需要依赖类似外部共享文件系统或者对象存储,仅依赖物理服务器部署 FE 和 BE 两个进程即可完成集群的搭建,可以从一个节点扩展到数百个节点,同时也增强了系统的稳定性。
- 性能优异:Apache Doris 执行计算时,计算节点可直接访问本地存储数据,充分利用机器的 IO、减少不必要的网络开销、获得更极致的查询性能。
使用场景
- 简单使用/快速试用 Doris,或在开发和测试环境中使用;
- 不具备可靠的共享存储,如 HDFS、Ceph、对象存储等;
- 业务线独立维护 Apache Doris,无专职 DBA 来维护 Doris 集群;
- 不需极致弹性扩缩容,不需 K8s 容器化,不需运行在公有云或者私有云上。
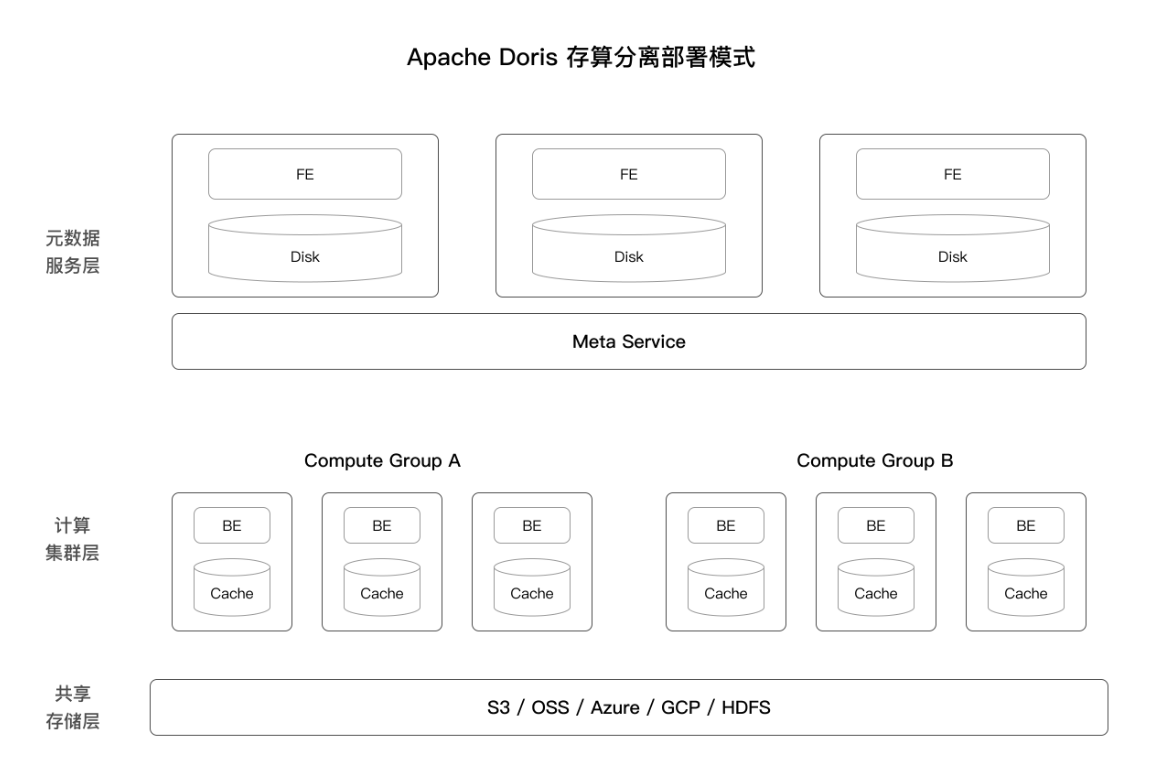
2.2存算分离架构
从 3.0 版本开始,可以选择存算分离部署架构。Apache Doris 存算分离版使用统一的共享存储层作为数据存储空间。存储和计算分离后,用户可以独立扩展存储容量和计算资源,从而实现最佳性能和成本效益。存算分离架构分为以下三层:
元数据层: 负责请求规划、查询解析以及元数据的存储和管理。
计算层: 由多个计算组组成。每个计算组可以作为一个独立的租户承担业务计算。每个计算组包含多个无状态的 BE 节点,可以随时弹性伸缩 BE 节点。
存储层: 可以使用 S3、HDFS、OSS、COS、OBS、Minio、Ceph 等共享存储来存放 Doris 的数据文件,包括 Segment 文件和反向索引文件等。
优点
- 弹性的计算资源:不同时间点使用不同规模的计算资源服务业务请求,按需使用计算资源,节约成本。
- 负载(完全)隔离:不同业务之间可在共享数据的基础上隔离计算资源,兼具稳定性和高效率。
- 低存储成本:可以使用更低成本的对象存储,HDFS 等低成本存储。
适用场景
- 已在使用公有云服务
- 具备可靠的高性能共享存储系统,比如 HDFS、Ceph、对象存储等
- 多个业务使用共享同一份数据, 并且有隔离计算的需求
- 需要极致的弹性扩缩容,需要 K8S 容器化,需要运行在私有云上
- 有专职团队维护整个公司的数据仓库平台
如果共享存储的吞吐或者延迟等性能比较差,对于存算分离架构Doris有比较大的性能影响。
3.数据表设计——数据模型
Doris支持3种数据模型。主键模型(Unique Key Model)、明细模型(Duplicate Key Model)、
聚合模型(Aggregate Key Model)。因为数据模型在建表时就需要确定,且无法修改。针对业务场景,所以选择一个合适的数据模型非常重要。
3.1主键模型
特点
每一行的 Key 值唯一。Doris存储层对每个 key 只保留最新写入的数据,插入或更新数据时,新数据会覆盖具有相同 Key 的旧数据,确保数据记录为最新。与其他数据模型相比,主键模型适用于数据的更新场景,在插入过程中进行主键级别的更新覆盖。
使用场景
适合高频更新且有唯一键约束的场景。
- 高频数据更新:适用于上游 OLTP 数据库中的维度表,实时同步更新记录,并高效执行 UPSERT 操作;
- 数据高效去重:如广告投放和客户关系管理系统中,使用主键模型可以基于用户 ID 高效去重;
- 需要部分列更新:如画像标签场景需要变更频繁改动的动态标签,消费订单场景需要改变交易的状态。通过主键模型部分列更新能力可以完成某几列的变更操作。
实现方式
主键模型有两种实现方式。
- 写时合并(merge-on-write):自 1.2 版本起,Doris 默认使用写时合并模式,数据在写入时立即合并相同 Key 的记录,确保存储的始终是最新数据。写时合并兼顾查询和写入性能,避免多个版本的数据合并,并支持谓词下推到存储层。大多数场景推荐使用此模式;自 Doris 2.1 版本以后,默认开启写时合并:
- 读时合并(merge-on-read):在 1.2 版本前,Doris 中的主键模型默认使用读时合并模式,数据在写入时并不进行合并,以增量的方式被追加存储,在 Doris 内保留多个版本。查询或 Compaction 时,会对数据进行相同 Key 的版本合并,确保结果正确。读时合并适合写多读少的场景,在查询是需要进行多个版本合并,谓词无法下推,可能会影响到查询速度。
主键模型更新有两种语义。
- 整行更新:Unique Key 模型默认的更新语义为整行UPSERT,即 UPDATE OR INSERT,该行数据的 Key 如果存在,则进行更新,如果不存在,则进行新数据插入。在整行 UPSERT 语义下,即使用户使用 Insert Into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充。
- 部分列更新:如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。请查阅文档部分列更新。
数据插入与存储
建表,插入4条数据,再插入2条数据,相同的Key会覆盖。
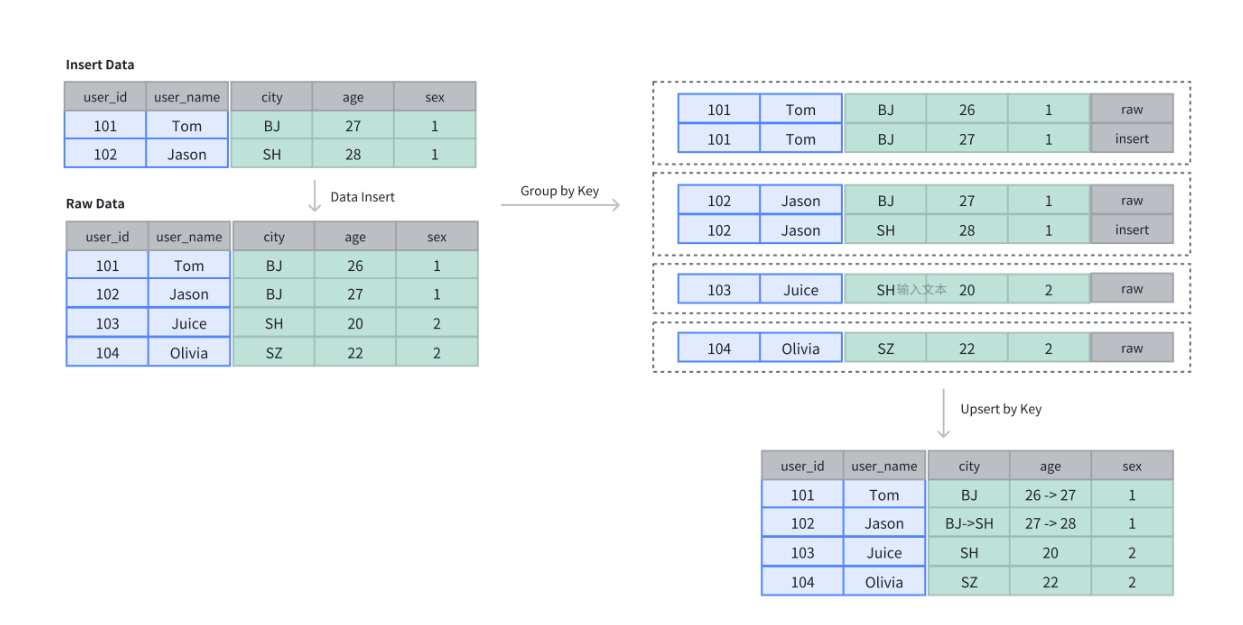
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
username VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "false"
);
-- insert into raw data
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);
-- insert into data to update by key
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 27, 1),
(102, 'Jason', 'SH', 28, 1);
-- check updated data
SELECT * FROM example_tbl_unique;
+---------+----------+------+------+------+
| user_id | username | city | age | sex |
+---------+----------+------+------+------+
| 101 | Tom | BJ | 27 | 1 |
| 102 | Jason | SH | 28 | 1 |
| 104 | Olivia | SZ | 22 | 2 |
| 103 | Juice | SH | 20 | 2 |
+---------+----------+------+------+------+
注意事项
- Unique 表的实现方式只能在建表时确定,无法通过 schema change 进行修改。不只是Unique ,其他两种也是。
- 在整行 UPSERT 语义下,即使用户使用 insert into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充;
- 部分列更新。如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。请查阅文档部分列更新获取相关使用建议;
- 使用 Unique 表时,为了保证数据的唯一性,分区键必须包含在 Key 列内。
最后这条我解释一下:如果分区键不包含在Key中,那么相同的Key可能会被分到不同的分区中,这样只能保证一个分区内Key唯一,不能保证Key的全局唯一,会出现不同分区有相同Key的情况;如果分区键包含在Key中,那么相同的Key肯定会被分到同一个分区中,这样能保证一个分区内Key唯一,不同分区的Key肯定不同,这样就保证了Key的全局唯一。
3.2明细模型
允许指定的 Key 列重复,Doirs 存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况。
特点
- 保留原始数据:明细模型保留了全量的原始数据,适合于存储与查询原始数据。对于需要进行详细数据分析的应用场景,建议使用明细模型,以避免数据丢失的风险;
- 不去重也不聚合:不管key是不是相同,都是插入新数据,不会覆盖和聚合。
- 灵活的数据查询:明细模型保留了全量的原始数据,可以从完整数据中提取细节,基于全量数据做任意维度的聚合操作,从而进行元数数据的审计及细粒度的分析。
使用场景
适合一些全量原始数据,只会追加而不会发生变更的场景。
- 日志存储:用于存储各类的程序操作日志,如访问日志、错误日志等。每一条数据都需要被详细记录,方便后续的审计与分析;
- 用户行为数据:在分析用户行为时,如点击数据、用户访问轨迹等,需要保留用户的详细行为,方便后续构建用户画像及对行为路径进行详细分析;
- 交易数据:在某些存储交易行为或订单数据时,交易结束时一般不会发生数据变更。明细模型适合保留这一类交易信息,不遗漏任意一笔记录,方便对交易进行精确的对账。
数据插入和存储
明细模型中 Key 列指做为排序。
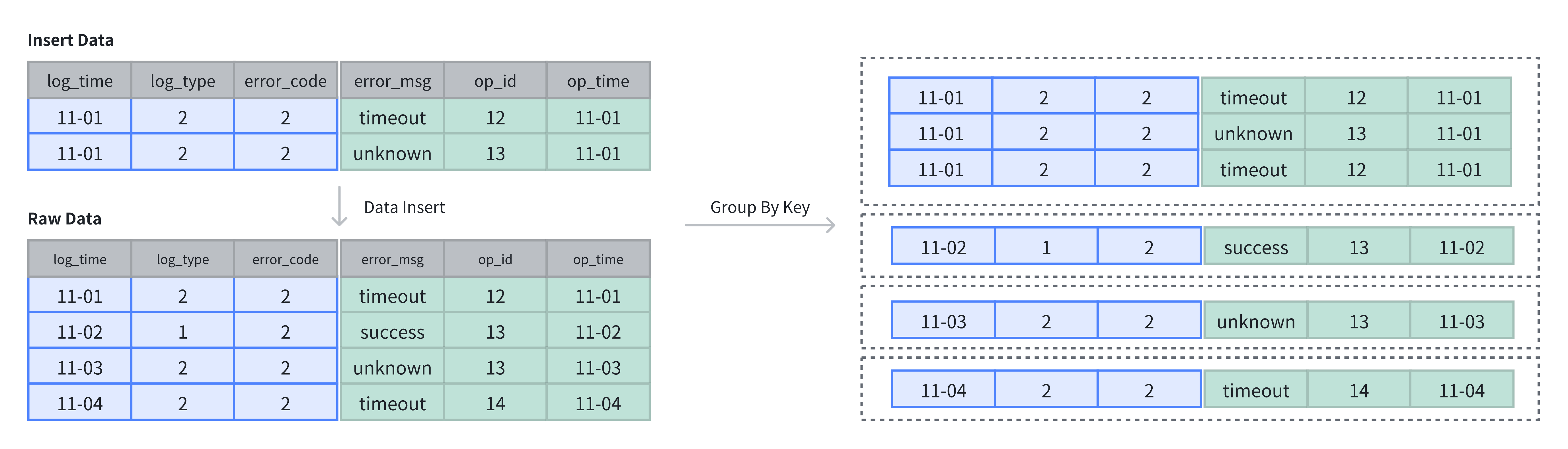
-- 4 rows raw data
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-02 00:00:00', 1, 2, 'success', 13, '2024-11-02 01:00:00'),
('2024-11-03 00:00:00', 2, 2, 'unknown', 13, '2024-11-03 01:00:00'),
('2024-11-04 00:00:00', 2, 2, 'unknown', 12, '2024-11-04 01:00:00');
-- insert into 2 rows
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-01 00:00:00', 2, 2, 'unknown', 13, '2024-11-01 01:00:00');
-- check the rows of table
SELECT * FROM example_tbl_duplicate;
+---------------------+----------+------------+-----------+-------+---------------------+
| log_time | log_type | error_code | error_msg | op_id | op_time |
+---------------------+----------+------------+-----------+-------+---------------------+
| 2024-11-02 00:00:00 | 1 | 2 | success | 13 | 2024-11-02 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
| 2024-11-03 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-03 01:00:00 |
| 2024-11-04 00:00:00 | 2 | 2 | unknown | 12 | 2024-11-04 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-01 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
+---------------------+----------+------------+-----------+-------+---------------------+
3.3聚合模型
Key值唯一,可根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。聚合模型只存储聚合后的数据,节省存储空间并加速查询。比如插入了3个子订单,插入后可根据订单号聚合为1条,汇总订单金额。
使用场景
适合不需要查询原始明细数据,只需要明细数据汇总后的信息。
明细数据进行汇总:用于电商平台的月销售业绩、金融风控的客户交易总额、广告投放的点击量等业务场景中,进行多维度汇总;
不需要查询原始明细数据:如驾驶舱报表、用户交易行为分析等,原始数据存储在数据湖中,仅需存储汇总后的数据。
原理
每一次数据导入会在聚合模型内形成一个版本,在 Compaction 阶段进行版本合并,在查询时会按照主键进行数据聚合:
- 数据导入阶段:数据按批次导入,每批次生成一个版本,并对相同聚合键的数据进行初步聚合(如求和、计数);
- 后台文件合并阶段(Compaction):多个版本文件会定期合并,减少冗余并优化存储;
- 查询阶段:查询时,系统会聚合同一聚合键的数据,确保查询结果准确。
数据插入和存储
在聚合表中,数据基于聚合键进行聚合操作。数据插入后及完成聚合操作。
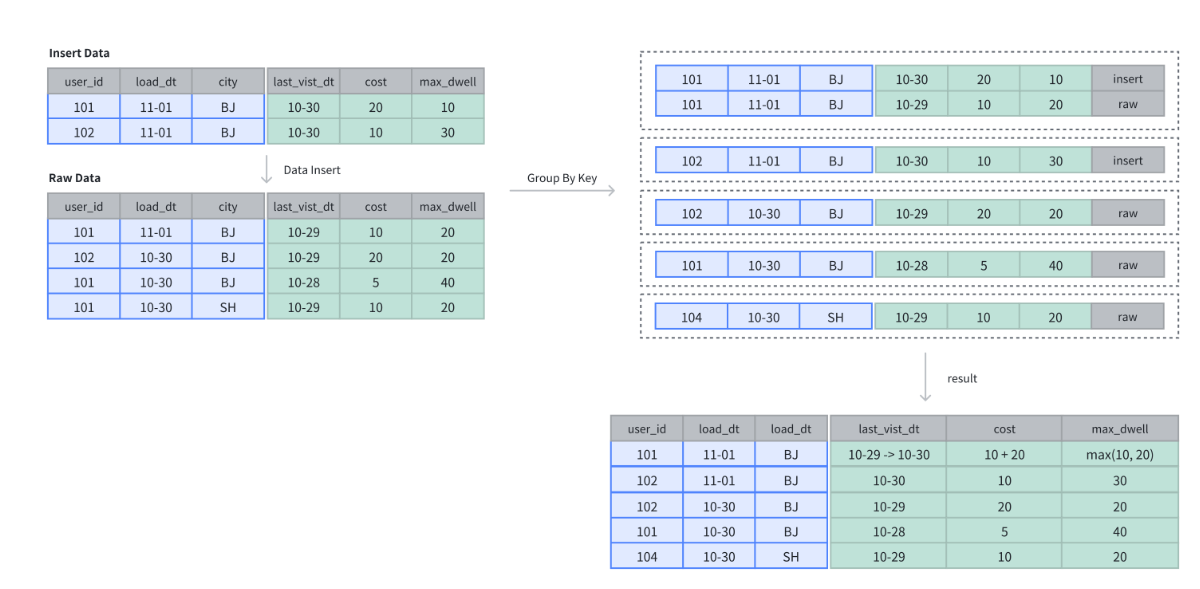
聚合方式
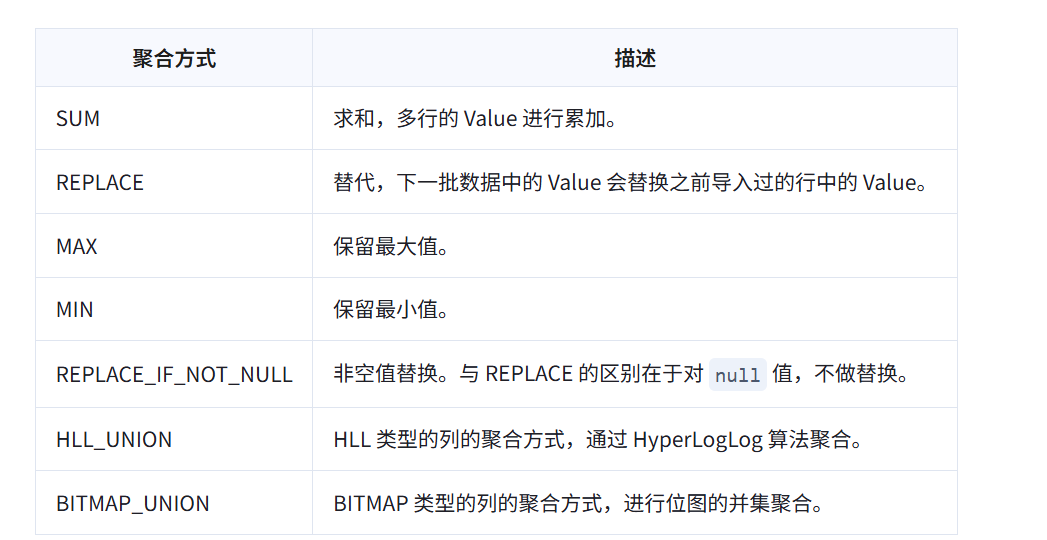
-- 建表
CREATE TABLE IF NOT EXISTS example_tbl_agg
(
user_id LARGEINT NOT NULL,
load_dt DATE NOT NULL,
city VARCHAR(20),
last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
cost BIGINT SUM DEFAULT "0",
max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_dt, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
-- 4 rows raw data
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);
-- insert into 2 rows
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);
-- check the rows of table
SELECT * FROM example_tbl_agg;
+---------+------------+------+---------------------+------+----------------+
| user_id | load_date | city | last_visit_date | cost | max_dwell_time |
+---------+------------+------+---------------------+------+----------------+
| 102 | 2024-10-30 | BJ | 2024-10-29 00:00:00 | 20 | 20 |
| 102 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 10 | 30 |
| 101 | 2024-10-30 | BJ | 2024-10-28 00:00:00 | 5 | 40 |
| 101 | 2024-10-30 | SH | 2024-10-29 00:00:00 | 10 | 20 |
| 101 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 30 | 20 |
+---------+------------+------+---------------------+------+----------------+
3.4排序键
在 Doris 中,数据以列的形式存储,一张表可以分为 key 列与 value 列。其中,key 列用于分组与排序,value 列用于参与聚合。Key 列可以是一个或多个字段,在建表时,按照各种表模型中,Aggregate Key、Unique Key 和 Duplicate Key 的列进行数据排序存储。
不同的表模型都需要在建表时指定 Key 列,分别有不同的意义。明细模型排序键作用是排序,而主键模型和聚合模型排序键的作用是排序+唯一键约束。
合理使用排序键收益
- 加速查询性能:排序键有助于减少数据扫描量。对于范围查询或过滤查询,可以利用排序键直接定位数据的位置。对于需要进行排序的查询,也可以利用排序键进行排序加速;
- 数据压缩优化:数据按排序键有序存储会提高压缩的效率,相似的数据会聚集在一起,压缩率会大幅度提高,从而减小数据的存储空间。
- 减少去重成本:当使用 Unique Key 表时,通过排序键,Doris 能更有效地进行去重操作,保证数据唯一性。
选择排序键时,可以遵循以下建议
- Key 列必须在所有 Value 列之前。
- 尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于 VARCHAR 和 STRING 类型的长度,遵循够用即可原则。
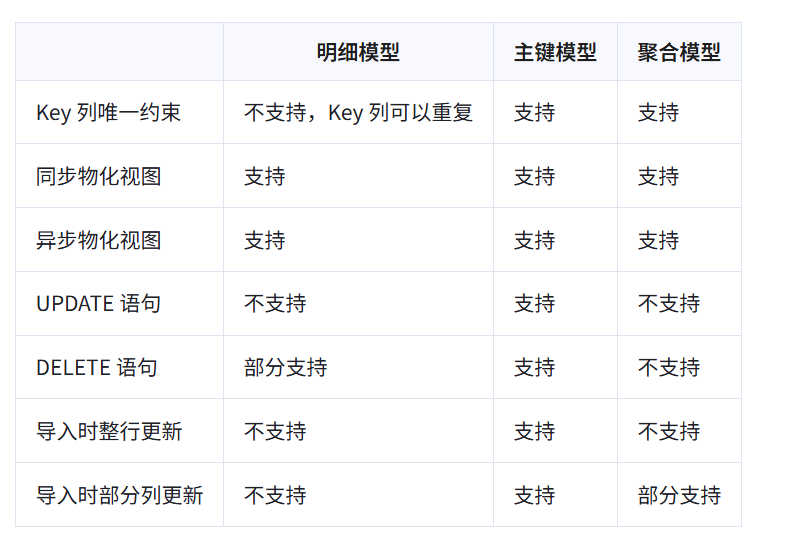
3.5模型能力对比
4. 数据表设计——数据划分
4.1 数据分布
概念
数据分布通过合理的分区和分桶策略,将数据高效地映射到各个数据分片(Tablet)上,从而充分利用多节点的存储和计算能力,支持大规模数据的高效存储和查询。
数据分片
BE 节点的存储数据分片的数据,每个分片是 Doris 中数据管理的最小单元,也是数据移动和复制的基本单位。
节点与存储架构
Doris 集群由以下两种节点组成:FE 节点(Frontend)和 BE 节点(Backend)。
- FE 节点(Frontend):管理集群元数据(如表、分片),负责 SQL 的解析与执行规划。
- BE 节点(Backend):存储数据,负责计算任务的执行。BE 的结果汇总后返回至 FE,再返回给用户。
数据写入和查询执行
- 数据写入时,Doris 首先根据表的分区策略将数据行分配到对应的分区。接着,根据分桶策略将数据行进一步映射到分区内的具体分片,从而确定了数据行的存储位置。
- 查询运行时,Doris 的优化器会根据分区和分桶策略裁剪数据,最大化减少扫描范围。在涉及 JOIN 或聚合查询时,可能会发生跨节点的数据传输(Shuffle)。合理的分区和分桶设计可以减少 Shuffle 并充分利用 Colocate Join 优化查询性能。
分区策略
分区是数据组织的第一层逻辑划分,用于将表中的数据划分为更小的子集。Doris 提供以下两种分区类型和三种分区模式:
分区类型
- Range 分区:根据分区列的值范围将数据行分配到对应分区。
- List 分区:根据分区列的具体值将数据行分配到对应分区。
分区模型
- 手动分区:用户手动创建分区(如建表时指定或通过 ALTER 语句增加)。
- 动态分区:系统根据时间调度规则自动创建分区,但写入数据时不会按需创建分区。
- 自动分区:数据写入时,系统根据需要自动创建相应的分区,使用时注意脏数据生成过多的分区。
分桶策略
分桶是数据组织的第二层逻辑划分,用于在分区内将数据行进一步划分到更小的单元。Doris 支持以下两种分桶方式:
Hash 分桶
通过计算分桶列值的 crc32 哈希值,并对分桶数取模,将数据行均匀分布到分片中。
Random 分桶
随机分配数据行到分片中。使用 Random 分桶时,可以使用 load_to_single_tablet 优化小规模数据的快速写入。写入时,系统根据需要自动创建相应的分区,使用时注意脏数据生成过多的分区。
数据分布优化
- Colocate Join:对于需要频繁进行 JOIN 或聚合查询的大表,可以启用 Colocate 策略,将相同分桶列值的数据放置在同一物理节点上,减少跨节点的数据传输,从而显著提升查询性能。
- 分区裁剪:查询时,Doris 可以通过过滤条件裁剪掉不相关的分区,从而减少数据扫描范围,降低 I/O 开销。
- 分桶并行:查询时,合理的分桶数可以充分利用机器的计算资源和 I/O 资源。
数据分布目标
- 均匀数据分布: 确保数据均匀分布在各 BE 节点上,避免数据倾斜导致部分节点过载,从而提高系统整体性能。
- 优化查询性能: 合理的分区裁剪可以大幅减少扫描的数据量,合理的分桶数可以提升计算并行度,合理利用 Colocate 可以降低 Shuffle 成本,提升 JOIN 和聚合查询效率。
- 灵活数据管理:
按时间分区保存冷数据(HDD)与热数据(SSD)。
定期删除历史分区释放存储空间。 - 控制元数据规模: 每个分片的元数据存储在 FE 和 BE 中,因此需要合理控制分片数量。经验值建议:
每 1000 万分片,FE 至少需 100G 内存。平均一下,1个分片0.01M。
单个 BE 承载的分片数应小于2万。 - 优化写入吞吐:
分桶数应合理控制(建议 < 128),以避免写入性能下降。
每次写入的分区数量应适量(建议每次写入少量分区)
通过精心设计和管理分区与分桶策略,Doris 能够高效地支持大规模数据的存储与查询处理,满足各种复杂业务需求。
4.2手动分区
分区列
- 分区列可以指定一列或多列,分区列必须为 KEY 列。其他类型的分区也一样
- 不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。但默认限制每张表 4096 个分区,如果想突破这个限制,可以修改 FE 配置max_multi_partition_num和max_dynamic_partition_num 。
- 当不使用分区建表时,系统会自动生成一个和表名同名的,全值范围的分区。该分区对用户不可见,并且不可删改。
- 创建分区时不可添加范围重叠的分区。
Range 分区
Range 分区支持的列类型 DATE, DATETIME, TINYINT, SMALLINT, INT, BIGINT, LARGEINT。分区列通常为时间列,以方便的管理新旧数据
FIXED RANGE:定义分区的左闭右开区间。
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)),
PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, ))
)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES [("2017-01-01"), ("2017-02-01")),
PARTITION `p201702` VALUES [("2017-02-01"), ("2017-03-01")),
PARTITION `p201703` VALUES [("2017-03-01"), ("2017-04-01"))
)
LESS THAN:仅定义分区上界。下界由上一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...)
)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),
PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01")),
PARTITION `other` VALUES LESS THAN (MAXVALUE)
)
BATCH RANGE:批量创建数字类型和时间类型的 RANGE 分区,定义分区的左闭右开区间,设定步长。
这个挺有用,比如一些范围可控的数据,可以用这个分区,比如人的年龄、省份的ID等。
PARTITION BY RANGE(int_col)
(
FROM (start_num) TO (end_num) INTERVAL interval_value
)
PARTITION BY RANGE(date_col)
(
FROM ("start_date") TO ("end_date") INTERVAL num YEAR | num MONTH | num WEEK | num DAY | 1 HOUR
)
PARTITION BY RANGE(age)
(
FROM (1) TO (100) INTERVAL 10
)
PARTITION BY RANGE(`date`)
(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 2 YEAR
)
MULTI RANGE:批量创建 RANGE 分区,定义分区的左闭右开区间。示例如下:
PARTITION BY RANGE(col)
(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
)
List分区
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
Partition 支持通过 VALUES IN (…) 来指定每个分区包含的枚举值
PARTITION BY LIST(city)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
List 分区也支持多列分区,示例如下:
PARTITION BY LIST(id, city)
(
PARTITION p1_city VALUES IN (("1", "Beijing"), ("1", "Shanghai")),
PARTITION p2_city VALUES IN (("2", "Beijing"), ("2", "Shanghai")),
PARTITION p3_city VALUES IN (("3", "Beijing"), ("3", "Shanghai"))
)
NULL 分区
PARTITION 列默认必须为 NOT NULL 列,如果需要使用 NULL 列,应设置 session variable allow_partition_column_nullable = true。对于 LIST PARTITION,我们支持真正的 NULL 分区。对于 RANGE PARTITION,NULL 值会被划归最小的 LESS THAN 分区。分列如下:
LIST 分区
mysql> create table null_list(
-> k0 varchar null
-> )
-> partition by list (k0)
-> (
-> PARTITION pX values in ((NULL))
-> )
-> DISTRIBUTED BY HASH(`k0`) BUCKETS 1
-> properties("replication_num" = "1");
Query OK, 0 rows affected (0.11 sec)
mysql> insert into null_list values (null);
Query OK, 1 row affected (0.19 sec)
mysql> select * from null_list;
+------+
| k0 |
+------+
| NULL |
+------+
1 row in set (0.18 sec)
RANGE 分区 —— 归属最小的 LESS THAN 分区
mysql> create table null_range(
-> k0 int null
-> )
-> partition by range (k0)
-> (
-> PARTITION p10 values less than (10),
-> PARTITION p100 values less than (100),
-> PARTITION pMAX values less than (maxvalue)
-> )
-> DISTRIBUTED BY HASH(`k0`) BUCKETS 1
-> properties("replication_num" = "1");
Query OK, 0 rows affected (0.12 sec)
mysql> insert into null_range values (null);
Query OK, 1 row affected (0.19 sec)
mysql> select * from null_range partition(p10);
+------+
| k0 |
+------+
| NULL |
+------+
1 row in set (0.18 sec)
RANGE 分区 —— 没有 LESS THAN 分区时,无法插入
mysql> create table null_range2(
-> k0 int null
-> )
-> partition by range (k0)
-> (
-> PARTITION p200 values [("100"), ("200"))
-> )
-> DISTRIBUTED BY HASH(`k0`) BUCKETS 1
-> properties("replication_num" = "1");
Query OK, 0 rows affected (0.13 sec)
mysql> insert into null_range2 values (null);
ERROR 5025 (HY000): Insert has filtered data in strict mode, tracking_url=......
4.3动态分区
动态分区会按照设定的规则,滚动添加、删除分区,从而实现对表分区的生命周期管理(TTL),减少数据存储压力。在日志管理,时序数据管理等场景,通常可以使用动态分区能力滚动删除过期的数据。
下图中展示了使用动态分区进行生命周期管理,其中指定了以下规则:
- 动态分区调度单位 dynamic_partition.time_unit 为 DAY,按天组织分区;
- 动态分区起始偏移量 dynamic_partition.start 设置为 -1,保留一天前分区;
- 动态分区结束偏移量 dynamic_partition.end 设置为 2,保留未来两天分区
依据以上规则,随着时间推移,总会保留 4 个分区,即过去一天分区,当天分区与未来两天分区:
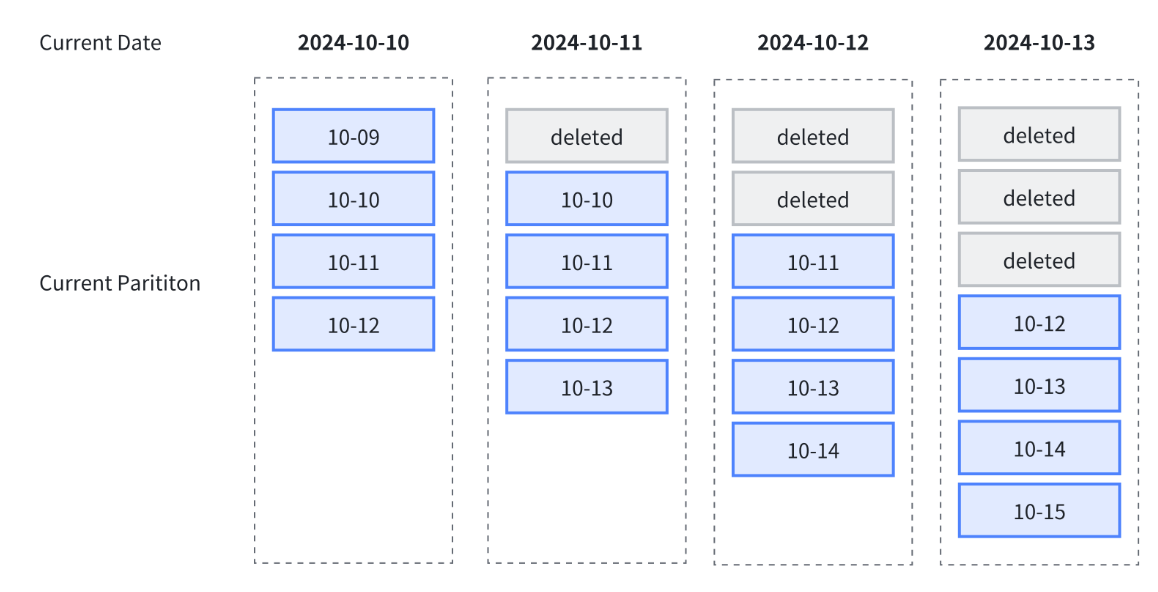
使用限制
动态分区只支持range分区,且分区键必须是date/datetime类型的单列。
创建动态分区
CREATE TABLE test_dynamic_partition(
order_id BIGINT,
create_dt DATE,
username VARCHAR(20)
)
DUPLICATE KEY(order_id)
PARTITION BY RANGE(create_dt) ()
DISTRIBUTED BY HASH(order_id) BUCKETS 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.create_history_partition" = "true"
);
动态分区参数
| 参数 | 必选 | 说明 |
|---|---|---|
| dynamic_partition.enable | 否 | 是否开启动态分区特性。可以指定为 TRUE 或 FALSE。如果指定了动态分区其他必填参数,默认为 TRUE。 |
| dynamic_partition.time_unit | 是 | 动态分区调度的单位。可指定为 HOUR、DAY、WEEK、MONTH、YEAR。分别表示按小时、按天、按星期、按月、按年进行分区创建或删除。 |
| dynamic_partition.start | 否 | 动态分区的起始偏移,为负数。默认值为 -2147483648,即不删除历史分区。根据 time_unit 属性的不同,以当天(星期/月)为基准,分区范围在此偏移之前的分区将会被删除。此偏移之后至当前时间的历史分区如不存在,是否创建取决于 dynamic_partition.create_history_partition。 |
| dynamic_partition.end | 是 | 动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当天(星期/月)为基准,提前创建对应范围的分区。 |
| dynamic_partition.prefix | 是 | 动态创建的分区名前缀。 |
| dynamic_partition.buckets | 否 | 动态创建的分区所对应的分桶数。设置该参数后会覆盖 DISTRIBUTED 中指定的分桶数。 |
| dynamic_partition.replication_num | 否 | 动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量。 |
| dynamic_partition.create_history_partition | 否 | 默认为 false。当置为 true 时,Doris 会自动创建所有分区,具体创建规则见下文。同时,FE 的参数 max_dynamic_partition_num 会限制总分区数量,以避免一次性创建过多分区。当期望创建的分区个数大于 max_dynamic_partition_num 值时,操作将被禁止。当不指定 start 属性时,该参数不生效。 |
| dynamic_partition.history_partition_num | 否 | 当 create_history_partition 为 true 时,该参数用于指定创建历史分区数量。默认值为 -1,即未设置。该变量与 dynamic_partition.start 作用相同,建议同时只设置一个。 |
| dynamic_partition.start_day_of_week | 否 | 当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点。 |
| dynamic_partition.start_day_of_month | 否 | 当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月 1 号,28 表示每月 28 号。默认为 1,即表示每月以 1 号为起始点。暂不支持以 29、30、31 号为起始日,以避免因闰年或闰月带来的歧义。 |
| dynamic_partition.reserved_history_periods | 否 | 需要保留的历史分区的时间范围。当 dynamic_partition.time_unit 设置为 “DAY/WEEK/MONTH/YEAR” 时,需要以 [yyyy-MM-dd,yyyy-MM-dd],[…,…] 格式进行设置。当 dynamic_partition.time_unit 设置为 “HOUR” 时,需要以 [yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[…,…] 的格式来进行设置。如果不设置,默认为 “NULL”。 |
| dynamic_partition.time_zone | 否 | 动态分区时区,默认为当前服务器的系统时区,如 Asia/Shanghai。更多时区设置可以参考时区管理。 |
这里我解释下dynamic_partition.start_day_of_week,可能不太好理解。比如:dynamic_partition.start = x,dynamic_partition.end = y,dynamic_partition.start_day_of_week = w。那么它创建得分区就是从前x周的周w到后x周的周w。 比如今天是2025-07-16,周3。指定 dynamic_partition.start = -1,dynamic_partition.end=2,dynamic_partition.start_day_of_week = 6。
CREATE TABLE aims.example_table6 (
dt DATE,
id INT,
name STRING
)
DUPLICATE KEY(dt, id)
PARTITION BY RANGE(dt) (
)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "WEEK",
"dynamic_partition.start" = "-1",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "8",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.start_day_of_week" = "6",
"dynamic_partition.create_history_partition" = "true"
);
那么它的分区是:
(PARTITION p2025_28 VALUES [('2025-07-12'), ('2025-07-19')),
PARTITION p2025_29 VALUES [('2025-07-19'), ('2025-07-26')),
PARTITION p2025_30 VALUES [('2025-07-26'), ('2025-08-02')),
PARTITION p2025_31 VALUES [('2025-08-02'), ('2025-08-09')))
如果dynamic_partition.start不指定,dynamic_partition.end=2,dynamic_partition.start_day_of_week = 6,那么它的分区是:
(PARTITION p2025_29 VALUES [('2025-07-18'), ('2025-07-25')),
PARTITION p2025_30 VALUES [('2025-07-25'), ('2025-08-01')),
PARTITION p2025_31 VALUES [('2025-08-01'), ('2025-08-08')))
DISTRIBUTED BY HASH(`id`) BUCKETS 8
4.4 自动分区
使用场景
自动分区功能主要解决了用户预期基于某列对表进行分区操作,但该列的数据分布比较零散或者难以预测,在建表或调整表结构时难以准确创建所需分区,或者分区数量过多以至于手动创建过于繁琐的问题。以时间类型分区列为例,在动态分区功能中,我们支持了按特定时间周期自动创建新分区以容纳实时数据。对于实时的用户行为日志等场景该功能基本能够满足需求。但在一些更复杂的场景下,例如处理非实时数据时,分区列与当前系统时间无关,且包含大量离散值。此时为提高效率我们希望依据此列对数据进行分区,但数据实际可能涉及的分区无法预先掌握,或者预期所需分区数量过大。这种情况下动态分区或者手动创建分区无法满足我们的需求,自动分区功能很好地覆盖了此类需求。
举个例子就是比如我要接入多个商家的数据,每个商家一个分区,可以按商家企业信用码来分,但后续接入还无法预测,就可以用到自动分区。这种我没用过,自己看文档吧
4.5 数据分桶
一个分区可以根据业务需求进一步划分为多个数据分桶(bucket)。每个分桶都作为一个物理数据分片(tablet)存储。合理的分桶策略可以有效降低查询时的数据扫描量,提升查询性能并增加并发处理能力。
分桶方式
Doris 支持两种分桶方式:Hash 分桶与 Random 分桶。
Hash分桶
在创建表或新增分区时,用户需选择一列或多列作为分桶列,并明确指定分桶的数量。在同一分区内,系统会根据分桶键和分桶数量进行哈希计算。哈希值相同的数据会被分配到同一个分桶中。例如,在下图中,p250102 分区根据 region 列被划分为 3 个分桶,哈希值相同的行被归入同一个分桶。

使用场景
- 业务需求频繁基于某个字段进行过滤时,可将该字段作为分桶键,利用 Hash 分桶提高查询效率。
- 当表中的数据分布较为均匀时,Hash 分桶同样是一种有效的选择。
示例
通过 DISTRIBUTED BY HASH(region) 指定了创建 Hash 分桶,并选择 region 列作为分桶键。同时,通过 BUCKETS 8 指定了创建 8 个分桶。
CREATE TABLE demo.hash_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY HASH(region) BUCKETS 8;
Random 分桶
在每个分区中,使用 Random 分桶会随机地将数据分散到各个分桶中,不依赖于某个字段的 Hash 值进行数据划分。Random 分桶能够确保数据均匀分散,从而避免由于分桶键选择不当而引发的数据倾斜问题。
在导入数据时,单次导入作业的每个批次会被随机写入到一个 tablet 中,以此保证数据的均匀分布。例如,在一次操作中,8 个批次的数据被随机分配到 p250102 分区下的 3 个分桶中。
在使用 Random 分桶时,可以启用单分片导入模式(通过设置 load_to_single_tablet 为 true)。这样,在大规模数据导入过程中,单个批次的数据仅写入一个数据分片,能够提高数据导入的并发度和吞吐量,减少因数据导入和压缩(Compaction)操作造成的写放大问题,从而确保集群稳定性。
使用场景
- 在任意维度分析的场景中,业务没有特别针对某一列频繁进行过滤或关联查询时,可以选择 Random 分桶;
- 当经常查询的列或组合列数据分布极其不均匀时,使用 Random 分桶可以避免数据倾斜。
- Random 分桶无法根据分桶键进行剪裁,会扫描命中分区的所有数据,不建议在点查场景下使用;
- 只有 DUPLICATE 表可以使用 Random 分桶,UNIQUE 与 AGGREGATE 表无法使用 Random 分桶;
示例
通过 DISTRIBUTED BY RANDOM 语句指定了使用 Random 分桶,创建 Random 分桶无需选择分桶键,通过 BUCKETS 8 语句指定创建 8 个分桶。
CREATE TABLE demo.random_bucket_tbl(
oid BIGINT,
dt DATE,
region VARCHAR(10),
amount INT
)
DUPLICATE KEY(oid)
PARTITION BY RANGE(dt) (
PARTITION p250101 VALUES LESS THAN("2025-01-01"),
PARTITION p250102 VALUES LESS THAN("2025-01-02")
)
DISTRIBUTED BY RANDOM BUCKETS 8;
选择分桶键
只有 Hash 分桶需要选择分桶键,Random 分桶不需要选择分桶键。
分桶键可以是一列或者多列。如果是 DUPLICATE 表,任何 Key 列与 Value 列都可以作为分桶键。如果是 AGGREGATE 或 UNIQUE 表,为了保证逐渐的聚合性,分桶列必须是 Key 列。
通常情况下,可以根据以下规则选择分桶键:
**利用查询过滤条件:**使用查询中的过滤条件进行 Hash 分桶,有助于数据的剪裁,减少数据扫描量;
利用高基数列:选择高基数(唯一值较多)的列进行 Hash 分桶,有助于数据均匀的分散在每一个分桶中;
**高并发点查场景:**建议选择单列或较少列进行分桶。点查可能仅触发一个分桶扫描,不同查询之间触发不同分桶扫描的概率较大,从而减小查询间的 IO 影响。
**大吞吐查询场景:**建议选择多列进行分桶,使数据更均匀分布。若查询条件不能包含所有分桶键的等值条件,将增加查询吞吐,降低单个查询延迟。
选择分桶数量
在 Doris 中,一个 bucket 会被存储为一个物理文件(tablet)。一个表的 Tablet 数量等于 partition_num(分区数)乘以 bucket_num(分桶数)。一旦指定 Partition 的数量,便不可更改。
在确定 bucket 数量时,需预先考虑机器扩容情况。自 2.0 版本起,Doris 支持根据机器资源和集群信息自动设置分区中的分桶数。
手动设置分桶数
-- Set hash bucket num to 8
DISTRIBUTED BY HASH(region) BUCKETS 8
-- Set random bucket num to 8
DISTRIBUTED BY RANDOM BUCKETS 8
在决定分桶数量时,通常遵循数量与大小两个原则,当发生冲突时,优先考虑大小原则:
- 大小原则:建议一个 tablet 的大小在 1-10G 范围内。过小的 tablet 可能导致聚合效果不佳,增加元数据管理压力;过大的 tablet 则不利于副本迁移、补齐,且会增加 Schema Change 操作的失败重试代价;
- 数量原则:在不考虑扩容的情况下,一个表的 tablet 数量建议略多于整个集群的磁盘数量。
例如,假设有 10 台 BE 机器,每个 BE 一块磁盘,可以按照以下建议进行数据分桶:
| 单表大小 | 建议分桶数量 |
|---|---|
| 500MB | 4-8 个分桶 |
| 5GB | 6-16 个分桶 |
| 50GB | 32 个分桶 |
| 500GB | 500GB 建议分区,每个分区 50GB,每个分区 16-32 个分桶 |
| 5TB | 每个分区 500GB,每个分桶 16-32 个分桶 |
自动设置分桶数
自动推算分桶数功能会根据过去一段时间的分区大小,自动预测未来的分区大小,并据此确定分桶数量。
-- Set hash bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
-- Set random bucket auto
DISTRIBUTED BY HASH(region) BUCKETS AUTO
properties("estimate_partition_size" = "20G")
在创建分桶时,可以通过 estimate_partition_size 属性来调整前期估算的分区大小。此参数为可选设置,若未给出,Doris 将默认取值为 10GB。请注意,该参数与后期系统通过历史分区数据推算出的未来分区大小无关。
维护分桶数
目前,Doris 仅支持修改新增分区的分桶数量,对于以下操作暂不支持:修改分桶类型、修改分桶键
不支持修改已创建的分区的分桶数量。
在建表时,已通过 DISTRIBUTED 语句统一指定了每个分区的数量。为了应对数据增长或减少的情况,在动态增加分区时,可以单独指定新分区的分桶数量。以下示例展示了如何通过 ALTER TABLE 命令来修改新增分区的分桶数:
-- Modify hash bucket table
ALTER TABLE demo.hash_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY HASH(region) BUCKETS 16;
-- Modify random bucket table
ALTER TABLE demo.random_bucket_tbl
ADD PARTITION p250103 VALUES LESS THAN("2025-01-03")
DISTRIBUTED BY RANDOM BUCKETS 16;
-- Modify dynamic partition table
ALTER TABLE demo.dynamic_partition_tbl
SET ("dynamic_partition.buckets"="16");
在修改分桶数量后,可以通过 SHOW PARTITION 命令查看修改后的分桶数量。