Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
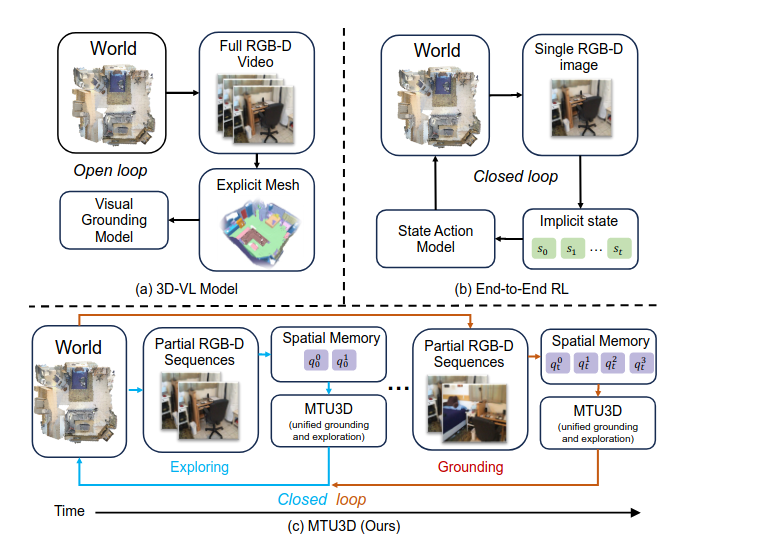
MTU3D(Move to Understand)是一个开创性的统一具身导航框架,其核心目标是结合视觉定位(visual grounding)和探索(exploration)能力,使具身智能体能够有效地探索并理解其所处的3D环境。它旨在克服现有3D视觉-语言(3D-VL)模型在处理静态3D重建(如网格和点云)中的物体定位时,缺乏主动感知和探索环境能力的局限性。MTU3D通过在线场景理解与探索的动态空间记忆更新,将在线探索与终身定位(lifelong grounding)有效地结合起来。
MTU3D的关键创新点包括:
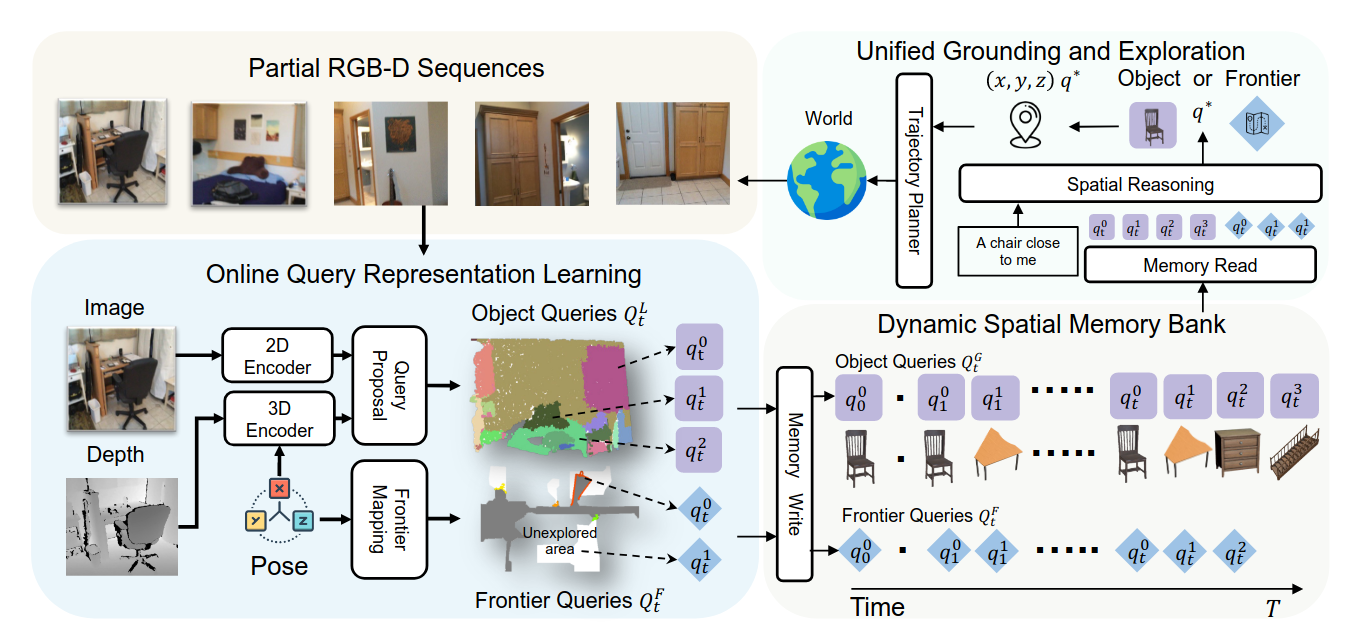
在线查询表示学习(Online Query-based Representation Learning):
- MTU3D能够直接从RGB-D帧构建空间记忆库,从而无需显式地进行3D重建。
- 它利用2D基础模型(如DINO和SAM)的特征提取和分割先验,提取丰富的语义信息和精确的3D空间信息,以生成查询表示。
- 系统会生成“局部查询(Local Query Proposal)”,这些查询通过多层感知机(MLP)结合2D和3D特征生成,并经由受PQ3D启发的解码器层进行精炼。每个精炼后的局部查询包含3D边界框、实例分割的段级掩码预测、开放词汇特征嵌入、来自查询解码器的输出特征以及检测置信度得分。
- 这些局部查询会被聚合成“全局查询(Global Queries)”并存储在一个**动态空间记忆库(Dynamic Spatial Memory Bank)**中,从而实现了跨时间步长的查询管理和更新。在记忆库中,边界框信息通过平均值进行融合,而实例分割掩码则通过并集操作进行融合,以实现信息的高效管理。
统一的定位与探索目标(Unified Exploration-Grounding Objective):
- MTU3D引入了一个联合优化框架,将未探索区域表示为“前沿查询(frontier queries)”。这些前沿是已探索(已知)和未探索(未知)区域之间的边界,用3D空间坐标表示,作为潜在的探索目标。
- 该框架联合优化目标定位(即寻找特定物体)和前沿选择(即决定下一步探索方向),实现探索与定位的无缝集成。
- 通过一个空间推理转换器(Spatial Reasoning Transformer),系统整合语言指令、对象表示和前沿信息,生成一个统一的得分来决定是定位物体还是选择前沿进行探索。对于语言目标,它使用CLIP文本编码器;对于基于图像的目标,则使用CLIP图像编码器。最终,系统会选择得分最高的查询作为下一步行动的目标。
端到端视觉-语言-探索(VLE)预训练(End-to-End Vision-Language-Exploration (VLE) Pre-training):
- MTU3D通过大规模训练,整合了超过一百万条来自模拟和真实世界的RGB-D轨迹。
- 它开发了一种自动轨迹混合策略,融合了专家数据和噪声导航数据以增强训练多样性。
- 预训练过程分为三个阶段:
- 低级感知训练:利用ScanNet和HM3D的RGB-D轨迹训练查询表示,并结合3D框IoU损失、二元交叉熵损失(用于掩码和置信度得分)以及余弦相似度损失(用于词汇嵌入)。
- 视觉-语言-探索预训练:在此阶段,MTU3D利用第一阶段的输出查询,对探索和定位进行联合训练。统一的决策得分通过二元交叉熵损失进行优化。
- 任务专用导航微调:最后,MTU3D会根据特定导航轨迹进行微调,以优化在目标部署场景中的性能。
MTU3D的架构和工作流程概览:
- 输入接收:MTU3D接收部分RGB-D序列作为输入,包括RGB图像、深度图像和相机姿态。
- 2D和3D编码:
- 2D特征提取:采用FastSAM对图像进行分割以生成区域ID,并通过DINO骨干网络提取像素级特征,然后根据区域ID池化为段级表示。这部分借鉴了EmbodiedSAM的方法。
- 3D特征提取:将深度图像投影为点云并进行下采样,然后通过稀疏卷积U-Net处理,生成3D特征,并同样进行段级池化。
- 局部查询生成:通过结合2D和3D段级特征,生成初始对象查询,并通过类似PQ3D的解码器层进行精炼,产生带有3D边界框、实例掩码、开放词汇特征等信息的局部查询。
- 动态空间记忆库:将这些局部查询聚合成全局查询,并存储在记忆库中。记忆库中的信息(如边界框)通过几何相似性进行匹配和融合,而掩码则通过并集操作融合。
- 前沿映射:系统维护一个占用地图,将空间段分类为已占用、未占用或未知。前沿代表已知和未知区域之间的边界,以3D空间坐标表示,作为潜在的探索目标。这些前沿路点会在到达每个目标位置时定期重新计算。
- 空间推理:接收语言指令、对象查询和前沿查询作为输入。它通过多层跨注意力机制(queries attend to input features, then to language goal)和空间自注意力机制,对这些信息进行整合,最终生成一个统一的得分,用于决定是定位物体还是选择前沿进行探索。
- 轨迹规划器:一旦决策确定(定位物体或探索前沿),MTU3D会利用Habitat-Sim的最短路径规划器生成局部轨迹,从而形成连续的感知-行动循环。
MTU3D的性能和优势:
- 卓越的性能:在多项具身导航和问答基准测试中,MTU3D的表现显著优于现有的强化学习和模块化导航方法。例如:
- 在HM3D-OVON上,成功率(SR)提升了13.7%,路径长度加权成功率(SPL)提升了2.4%。
- 在GOAT-Bench上,SR提升了23.0%,SPL提升了13.0%。
- 在SG3D上,SR提升了9.1%,SPL提升了6.3%。
- 在A-EQA的LLM-SR(大语言模型匹配成功率)上,提升了2.4%,LLM-SPL提升了29.5%。
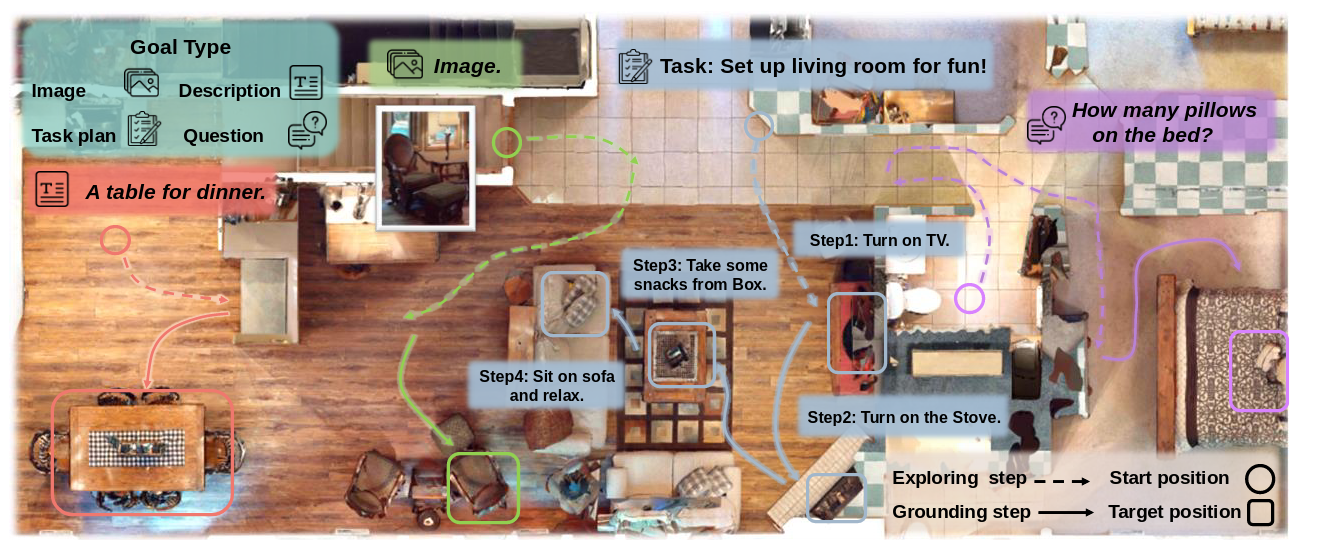
- 多模态输入支持:MTU3D支持多种输入模态,包括类别、语言描述、参考图像、任务计划序列和问题,极大地提高了导航的通用性。
- 高效探索:在探索步骤增加时,MTU3D在SR和SPL方面均超越了盲目的前沿探索(frontier exploration),因为它利用语义指导进行更高效、目标导向的探索。
- 终身导航能力:空间记忆库显著增强了终身导航能力,在GOAT-Bench中,对于对象、描述和图像目标,SR均有大幅提升,表明记忆库有助于保留有用的空间信息并利用过去的经验。
- 实时运行能力:MTU3D能够实时运行,查询生成平均192毫秒,空间推理平均31毫秒,整体帧率(FPS)达到3.4,参数量为266M。这表明模型在速度和性能之间达到了最佳平衡,适用于实时应用。
- 真实世界部署:MTU3D已在真实机器人上进行了部署和测试,能够有效处理真实世界的RGB-D数据和复杂环境,克服了模拟到真实(Sim-to-Real)的迁移挑战。
局限性:
- 尽管MTU3D在开放词汇导航方面表现出色,但在处理HM3D-OVON数据集中相对较短的轨迹时,其SPL可能低于基于视频的模型,因为后者能够更快地识别目标并直接导航。
总而言之,MTU3D通过其独特的在线查询表示学习、统一的定位与探索目标以及大规模VLE预训练,为具身智能领域中3D场景理解和导航提供了一个高效、通用且可泛化的框架,为具身智能体在复杂3D世界中进行自主探索和理解迈出了重要一步。
Unifying 3D Vision-Language Understanding via Promptable Queries
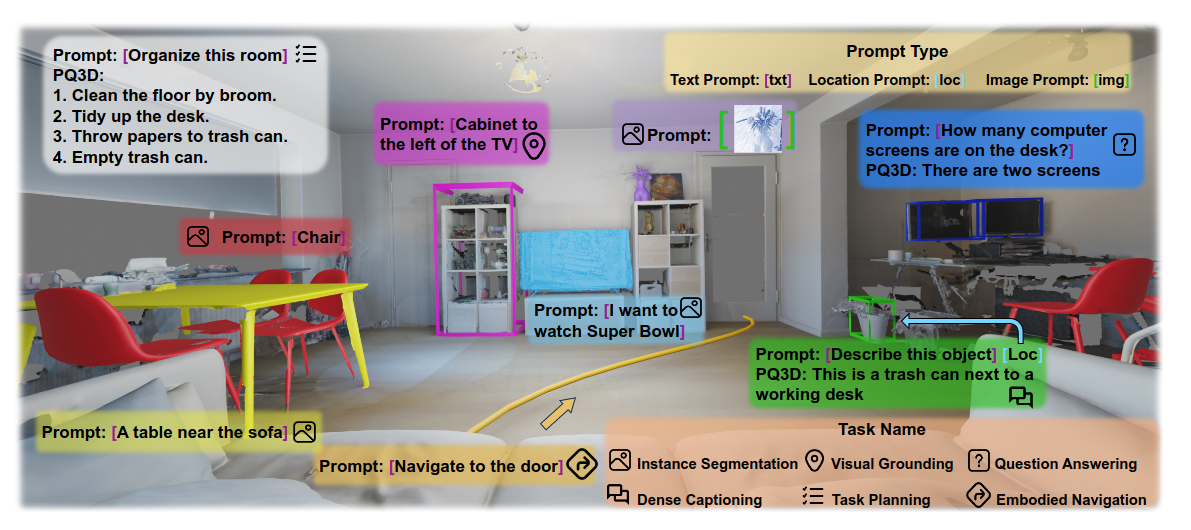
PQ3D(Promptable Queries for 3D Vision-Language Understanding)是一个统一的3D视觉-语言(3D-VL)理解模型,旨在弥合现有方法在处理3D场景表示、多任务训练以及低级到高级推理之间存在的显著差距。它通过引入**可提示查询(Promptable Queries)**这一核心概念,使模型能够处理各种3D场景表示,并执行从低级实例分割到高级推理和规划的广泛任务。
PQ3D旨在解决的关键挑战包括:
- 多样化的场景表示:现有的最先进方法通常针对特定任务使用特定的场景表示(例如,体素用于实例分割,点云用于视觉定位,多视图图像用于开放词汇理解),这限制了统一模型的潜力。
- 缺乏主动感知和探索能力:许多3D-VL模型主要侧重于从静态3D重建(如网格和点云)中定位物体,缺乏主动感知和探索环境的能力。
- 多任务训练的不足:尽管一些工作探索了多任务训练和预训练以寻求相关任务之间的互利,但它们通常仍需要现成的3D掩码提议模块。
- 动态环境适应性:现有模型缺乏增量更新机制,难以在动态环境中修订或废弃过时场景信息,这对于实时推理和长期记忆至关重要。
PQ3D的三大核心创新点:
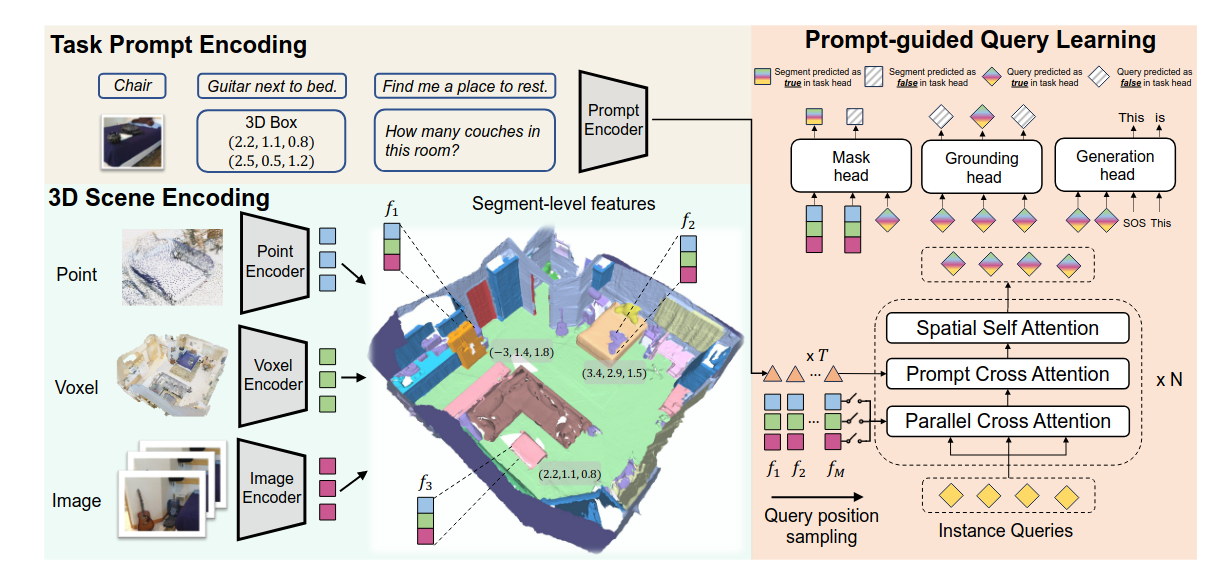
统一各种3D场景表示
- PQ3D能够将稠密点云特征、多尺度体素特征和多视图图像特征统一到共享的3D坐标空间中。
- 这一过程通过无监督的基于图的分割将3D点分组为更大的片段(segments),并将特征池化到片段级别,从而显著减少了点数量,便于训练。
- 点云处理:将完整点云分割成预生成的片段。每个片段采样1024个点,归一化坐标后输入预训练的PointNet++骨干网络,提取点特征。
- 体素特征提取:遵循Mask3D的方法,将3D场景离散化为体素,并通过稀疏卷积U-net骨干网络处理,提取分层信息。提取的体素特征被映射到预生成片段并进行平均池化。
- 多视图图像特征:借鉴OpenScene,通过预训练的OpenSeg分割模型获取每张图像的像素级嵌入,然后将2D像素反投影到3D点,并聚合来自关联多视图像素的特征,最终通过平均池化获得片段级图像特征。
- 最终的3D场景表示由这些三种片段级特征以及通过MLP编码的**片段3D位置信息( positional encoding)**组成。
基于注意力的查询解码器
- PQ3D引入了一种新颖的基于Transformer的查询解码器,它在任务提示(task prompts)的指导下,逐步从对齐的场景特征中检索任务特定信息。
- 查询初始化:实例查询(instance queries)Q0被初始化为零值,其位置通过3D点上的最远点采样(Farthest Point Sampling)获取。
- 查询精炼:在每个解码器层中,实例查询Ql首先并行地关注场景特征(体素、图像、点),然后关注任务提示t。之后,进行空间自注意力(Spatial Self-Attention)。
- 掩码注意力机制(Masked Attention):在交叉注意力阶段,它通过限制注意力范围到查询中心周围的局部特征,加速收敛并提高性能。
- 灵活推理(Flexible Inference):为了支持仅部分场景表示可用时的灵活推理,在训练期间,模型会以0.6的概率随机丢弃一些场景特征。
通用输出头
- PQ3D为每个查询配备了三个通用输出头,以支持广泛的3D-VL任务:
- 掩码头(Mask Head):预测预生成片段上的二进制掩码,用于实例分割。
- 定位头(Grounding Head):预测实例查询是否与当前任务相关,提供任务相关性得分。
- 生成头(Generation Head):使用预训练的T5-small解码器作为生成头,根据所有实例查询作为编码输入,生成文本响应(例如,问答和稠密描述)。
- 在训练过程中,总损失由这三个头的损失加权求和组成。
- PQ3D为每个查询配备了三个通用输出头,以支持广泛的3D-VL任务:
任务提示编码(Task Prompt Encoding)
- PQ3D能够处理文本、视觉和数值三种不同格式的任务提示。
- 文本和视觉提示通过预训练的CLIP模型进行编码,这使得模型能够在训练时使用文本提示,并在推理时使用图像提示进行零样本迁移。
- 数值提示(如3D边界框和位置)通过全连接层投射到与CLIP相同的特征空间中。
- 这种统一设计使得模型能够在不同提示类型之间迁移知识。
训练和性能:
- 训练过程:分为两个阶段。第一阶段在ScanNet200数据集上单独训练实例分割,利用分类头预测实例查询。第二阶段,模型在完整训练集上继续训练,使用通用输出头的损失函数。
- 数据量:结合了八个数据集进行多任务训练,包含约662K个训练样本。
- 卓越性能:
- 在十个不同的3D-VL数据集上进行了广泛实验,包括ScanNet200、Replica(实例分割)、ScanRefer、ReferIt3D、Multi3DRefer(视觉定位)、ScanQA、SQA3D(问答)和Scan2Cap(稠密描述)。
- 在大多数基准测试中创造了新记录。例如,ScanNet200上AP25提高4.9%,ScanRefer上准确率提高5.4%,Multi3DRefer上F1@0.5提高11.7%,Scan2Cap上CIDEr@0.5提高13.4%。
- 在GOAT-Bench、HM3D-OVON、SG3D和A-EQA等具身导航和问答基准测试中表现出色。
- 零样本能力:支持使用新颖的提示类型,例如,可以使用图像草图来定位场景中相关对象。
- 灵活推理:可以支持单个或组合形式的3D表示进行灵活推理。
- 多任务联合训练的有效性:来自视觉定位任务的数据能提升问答和稠密描述任务的性能,稠密描述数据也能积极影响视觉定位和问答任务。
- 具身导航与任务规划:可以为具身智能体提供全局3D特征,显著提升导航成功率。例如,在ObjNav任务上,成功率提升了22.9%。它还能规划复杂的任务,如组织客厅。
局限性:
- PQ3D的规模和泛化能力与2D视觉语言基础模型相比仍存在差距。在SQA3D任务上,其性能略低于SOTA,这可能与CLIP文本编码器在理解长句方面的局限性有关。
- 当文本提示缺乏足够的清晰度或图像提示包含背景噪声时,模型可能会分割不相关的对象或产生混淆。
总的来说,PQ3D通过其统一的架构和创新的查询机制,为3D视觉-语言理解领域提供了一个高效、通用和可泛化的框架,并为具身智能体在复杂3D世界中的自主探索和理解奠定了重要基础。