源自论文:Vision Language Action Models in Robotic Manipulation: A Systematic Review
VLA模型的定义
Vision Language Action(VLA)模型是一种在机器人操控领域具有变革性的学习框架,其核心定义可从目标、架构、能力三个维度详细描述:
一、核心目标
VLA模型旨在统一视觉感知、自然语言理解与具象化控制,打破传统机器人系统中“感知-决策-执行”模块分离的局限,使机器人能在动态、非结构化环境中,通过单一框架实现“理解指令→感知环境→执行动作”的端到端闭环。
传统机器人依赖任务特定编程,难以适应环境变化;而VLA模型借助大规模基础模型的泛化能力,让机器人具备处理复杂、开放任务的自主性(例如根据自然语言指令“把苹果和香蕉放在盘子里”,自主完成视觉识别、路径规划和抓取动作)。
二、核心架构与技术基础
VLA模型以Transformer架构为核心骨架,融合视觉、语言、动作三大模态的处理能力,其架构本质是“跨模态融合+动作生成”的结合体,具体依赖四类基础组件:
视觉编码器
将图像/视频(如RGB、深度图)转换为特征向量,常用模型包括ViT(视觉Transformer)、CLIP、DINOv2等。例如,通过ViT将图像分割为补丁(Patches),提取空间语义特征(如物体位置、形状)。语言编码器
将自然语言指令(如“拿起红色杯子”)转换为语义向量,常用模型包括LLaMA、T5、CLIP文本编码器等。需支持理解抽象指令(如“整理桌面”)和细粒度指令(如“将杯子放在盘子左侧”)。状态编码器
处理机器人自身状态(如关节角度、末端执行器位置、 gripper 状态),通过MLP或小型Transformer生成特征,确保动作符合机器人运动学约束(如避免碰撞、判断可达性)。动作解码器
融合上述三类特征,生成具体控制指令(如关节轨迹、末端执行器速度)。主流方案包括:- 扩散Transformer(如Octo):通过迭代去噪生成平滑轨迹;
- 自回归Transformer(如RT-1):逐步预测离散动作;
- MLP/Token预测器(如OpenVLA):输出离散动作令牌或连续控制信号。
三、核心能力
VLA模型需具备三大核心能力,以区别于传统视觉语言模型(VLM)或单一操控模型:
跨模态对齐能力
实现视觉(“看到什么”)、语言(“指令是什么”)、动作(“该做什么”)的语义绑定。例如,将语言指令“递给我勺子”与视觉中的“勺子”物体、动作“抓取-递送”关联。泛化能力
- 跨任务泛化:从已知任务(如“开门”)迁移到未知任务(如“开抽屉”);
- 跨机器人泛化:在不同形态机器人(如机械臂、双足机器人)上复用模型;
- 零样本适应:无需重新训练即可处理新环境(如不同光照、新物体)。
具象化执行能力
不仅能理解指令和感知环境,还能生成符合物理约束的实际动作。例如,根据“轻轻放置鸡蛋”的指令,自动调整抓取力度和放置速度,避免物体损坏。
四、典型特征
- 端到端学习:直接从“视觉+语言输入”映射到“动作输出”,减少人工设计的中间模块(如传统的“目标检测→路径规划→控制”分步骤流程)。
- 依赖大规模数据:需通过真实世界演示或仿真数据(如Open X-Embodiment、DROID数据集)学习多样任务模式。
- 模块化与可扩展性:支持替换核心组件(如用更强的ViT替换视觉编码器),或通过微调适配新场景(如LoRA技术在OpenVLA中的应用)。
总结
VLA模型是机器人领域的“感知-理解-执行”一体化框架,通过Transformer架构融合视觉、语言、动作模态,核心目标是让机器人在自然语言驱动下,自主完成复杂操控任务。其定义的核心在于“跨模态统一”与“具象化行动”——不仅能“看懂”“听懂”,更能“做出正确的动作”,是实现通用机器人智能的关键方向。
VLA模型的支撑技术
根据论文内容,VLA(Vision Language Action)的支撑技术主要包含四类关键组件:Transformer架构、视觉Transformer(ViT)、大型语言模型(LLMs)、视觉-语言模型(VLMs)。这些概念为VLA提供了“跨模态感知”与“序列建模”能力,是VLA实现“视觉-语言-动作”融合的基础。
一、Transformer架构(核心骨架)
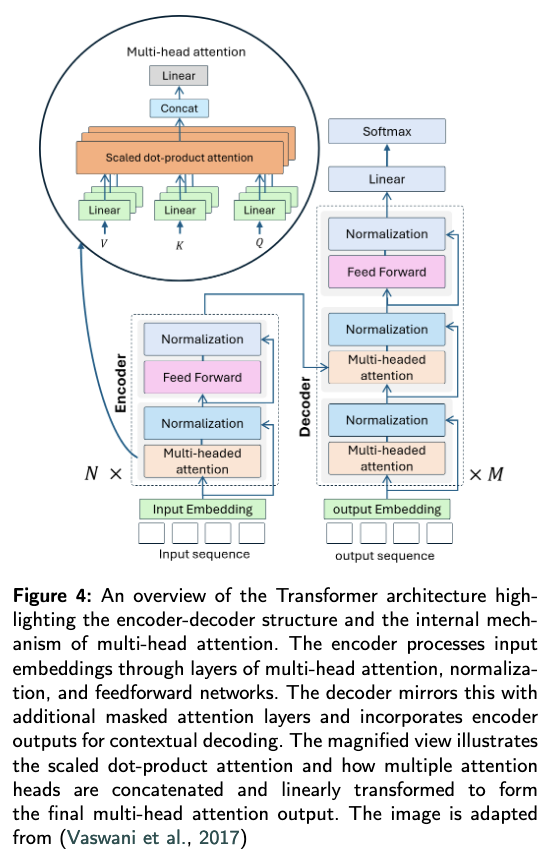
Transformer是VLA架构的“通用骨架”,其自注意力机制和编码器-解码器结构为跨模态融合提供了基础能力。
核心原理
基于“自注意力机制”实现序列数据的并行处理,能捕捉输入中不同元素(如文本单词、图像补丁)之间的长距离依赖关系,解决了传统RNN在长序列处理中的效率与依赖捕捉短板。关键组件
- 嵌入层(Embedding Layer):将离散输入(如文本令牌、图像补丁)转换为连续向量(嵌入向量),并添加“位置编码”(Positional Encoding)以保留序列顺序(如文本的词序、图像的空间位置)。
- 编码器(Encoder):由N个相同层组成,每层包含“多头自注意力”(Multi-Head Self-Attention)和“前馈网络”(Feed-Forward Network),通过残差连接和层归一化增强训练稳定性。编码器能生成输入序列的“上下文感知特征”(如文本的语义、图像的全局特征)。
- 解码器(Decoder):由M个相同层组成,除编码器的组件外,额外包含“编码器-解码器注意力”(Encoder-Decoder Attention),用于关注编码器输出的关键信息;同时通过“掩码自注意力”(Masked Self-Attention)确保 autoregressive 生成(如生成动作时仅依赖历史序列)。
在VLA中的作用
Transformer的“序列建模能力”是VLA的核心——它将视觉(图像补丁序列)、语言(文本令牌序列)、动作(控制信号序列)统一为“序列数据”处理,通过自注意力实现跨模态元素的关联(如“苹果”的视觉特征与“抓取”的动作指令绑定)。
二、视觉Transformer(Vision Transformer, ViT)
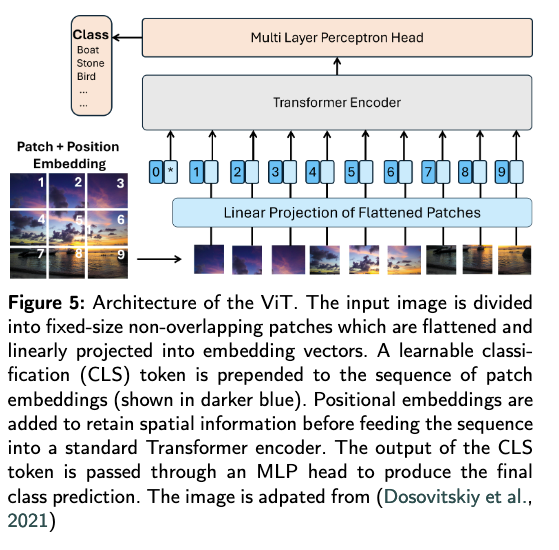
ViT是VLA视觉感知的核心,将Transformer的序列建模能力迁移到视觉领域,解决了传统CNN在全局视觉关系捕捉上的不足。
核心原理
将图像视为“视觉序列”——将图像分割为非重叠的固定大小补丁(如16×16像素),每个补丁被线性投影为嵌入向量(类似文本令牌),再通过Transformer编码器提取全局视觉特征。关键组件
- 图像补丁化(Image Patching):将输入图像(如224×224)分割为N个补丁(如14×14个16×16补丁),每个补丁展平为一维向量。
- 线性投影(Linear Projection):将补丁向量转换为固定维度的嵌入向量(如768维),作为Transformer的输入。
- 分类令牌(Classification Token, [CLS]):在补丁序列前添加一个可学习的令牌,其最终输出用于视觉任务(如物体分类、场景理解),在VLA中则用于提取图像的全局语义(如“厨房场景”“苹果在盘子里”)。
- 位置编码(Positional Embedding):添加到补丁嵌入中,保留图像的空间位置信息(如“苹果在左上角”)。
在VLA中的作用
ViT为VLA提供“全局视觉感知”能力——它不仅能识别单个物体(如“苹果”),还能捕捉物体间关系(如“苹果在盘子上”)和场景布局(如“厨房台面”),为动作生成提供视觉依据(如“抓取盘子上的苹果”)。
三、大型语言模型(Large Language Models, LLMs)
LLMs是VLA语言理解的核心,通过大规模文本预训练获得自然语言指令解析、逻辑推理能力,支撑VLA对“人类指令”的理解。
核心原理
基于Transformer解码器(或编码器-解码器)架构,在海量文本数据(如书籍、网页)上通过“预测下一个令牌”任务预训练,实现对语言语义、语法、逻辑的理解。主要类型及特点
- 编码器仅模型(Encoder-Only):如BERT、RoBERTa,通过双向自注意力理解文本上下文,擅长文本分类、语义相似性判断(如判断“拿苹果”与“抓取苹果”语义一致)。
- 解码器仅模型(Decoder-Only):如GPT系列、LLaMA,通过单向自注意力(仅关注前文)实现 autoregressive 文本生成,擅长指令理解、逻辑推理(如将“整理桌面”拆解为“拿起文件→放入文件夹”)。
- 编码器-解码器模型(Encoder-Decoder):如T5、BART,编码器处理输入文本,解码器生成输出文本,擅长序列转换任务(如机器翻译、指令到子任务的拆解)。
在VLA中的作用
LLMs为VLA提供“语言理解与规划能力”——它将人类指令(如“把苹果放在红色盘子里”)转换为机器可理解的语义表示,甚至拆解为子任务序列(如“识别苹果→识别红色盘子→规划抓取轨迹”),指导VLA的动作生成方向。
四、视觉-语言模型(Vision-Language Models, VLMs)
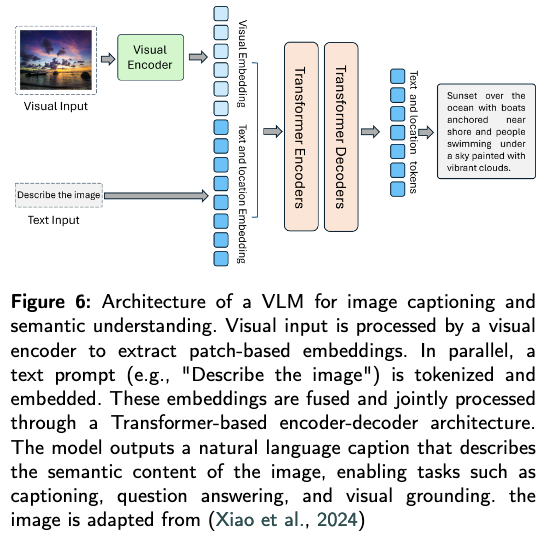
VLMs是VLA跨模态对齐的核心,它融合视觉与语言的感知能力,实现“图像与文本的语义绑定”,为VLA的“视觉-语言-动作”融合奠定基础。
核心原理
通过联合训练视觉编码器(如ViT)和语言编码器(如LLM),将视觉特征与语言特征映射到共享 latent 空间,使“图像内容”与“文本描述”在语义上对齐(如“苹果图像”与“红色圆形水果”文本距离相近)。典型架构与训练目标
- 双编码器架构(如CLIP):视觉编码器(ViT)处理图像,语言编码器(Transformer)处理文本,通过“对比学习”(Contrastive Learning)训练——使匹配的图像-文本对在共享空间中距离更近,非匹配对距离更远。
- 编码器-解码器架构(如BLIP、Flamingo):视觉编码器提取图像特征,与文本令牌一起输入解码器,通过“生成式任务”(如图像 captioning、视觉问答VQA)训练,实现更紧密的跨模态融合。
在VLA中的作用
VLMs解决了VLA的“跨模态语义对齐”问题——它确保VLA能将“视觉看到的物体”(如苹果)与“语言指令中的物体”(如“苹果”)关联,避免“看到苹果却执行‘拿香蕉’动作”的错位,是VLA从“独立感知”到“统一理解”的关键。
总结:基础架构的协同作用
VLA的Background Concepts是一个“层级支撑”体系:
- Transformer 提供通用序列建模骨架,让视觉、语言、动作能以“序列”形式统一处理;
- ViT 将视觉输入转换为序列特征,提供“看”的能力;
- LLMs 将语言输入转换为序列特征,提供“理解”的能力;
- VLMs 实现视觉与语言的语义对齐,解决“看”与“理解”的关联问题。
这一基础架构使VLA能够进一步整合“动作生成模块”,最终实现“看到场景→理解指令→执行对应动作”的闭环——它是VLA从“理论概念”走向“实际功能”的技术基石。
VLA的模型结构
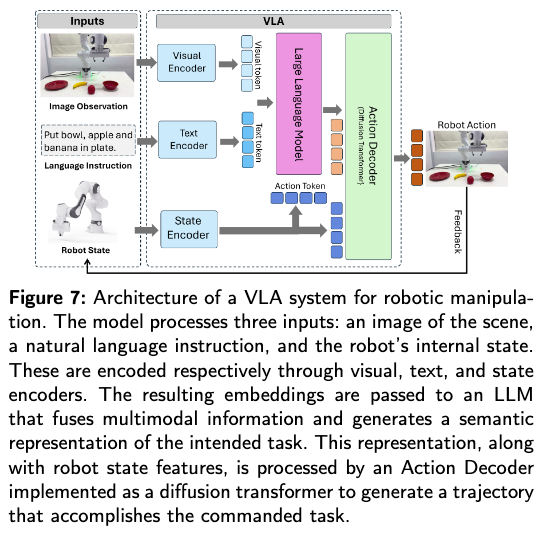
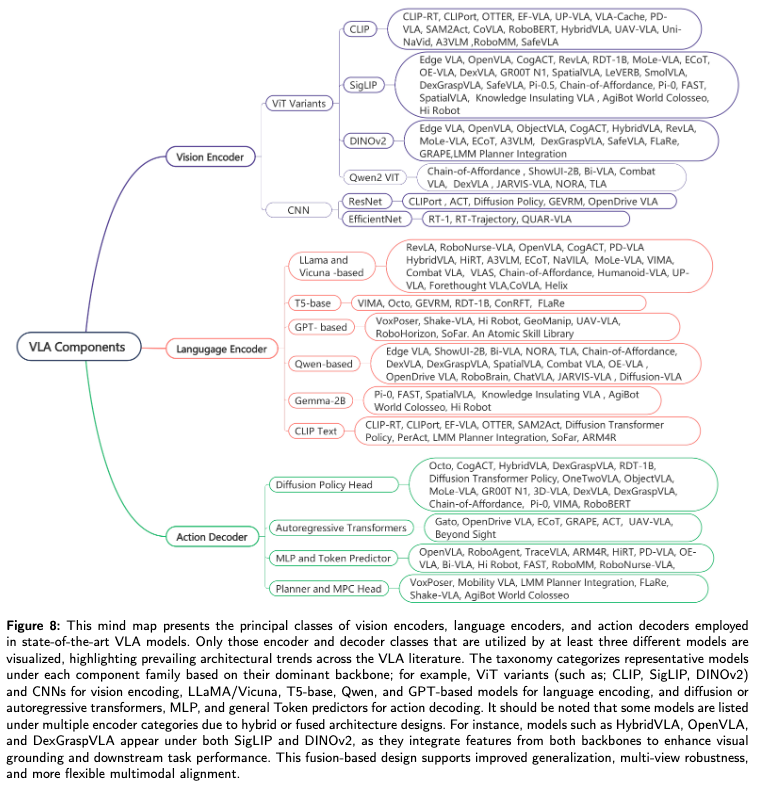
一、VLA模型整体架构
VLA(Vision Language Action)模型的核心目标是统一视觉感知、自然语言理解和具象化控制,其架构以Transformer为基础骨架,通过跨模态融合实现“输入(视觉+语言)→输出(动作)”的端到端映射。整体架构包含四大核心模块,各模块通过共享特征空间实现协同工作。
| 核心模块 | 功能描述 | 技术基础 |
|---|---|---|
| 视觉编码器 | 将RGB图像、深度图等视觉输入转换为特征向量,捕捉物体位置、场景布局等信息。 | 基于ViT(Vision Transformer)、CLIP视觉模型或CNN(如ResNet)。 |
| 语言编码器 | 将自然语言指令(如“把苹果放在盘子里”)转换为语义特征,支持指令解析。 | 基于LLM(如LLaMA、GPT)或视觉-语言模型(如CLIP文本编码器、T5)。 |
| 状态编码器 | 编码机器人自身状态(如关节角度、末端执行器位置),确保动作符合运动学约束。 | 基于MLP或小型Transformer,处理连续状态数据。 |
| 动作解码器 | 融合多模态特征,生成连续动作指令(如轨迹、关节控制信号)。 | 基于扩散Transformer、自回归Transformer或MLP,支持平滑动作生成。 |
工作流程:
- 视觉、语言、状态数据分别通过对应编码器转换为特征;
- 特征在共享 latent 空间对齐(通过交叉注意力或对比学习);
- 动作解码器生成具体控制指令,部分模型支持闭环反馈(如根据执行结果修正动作)。
二、VLA模型架构分类
根据“视觉-语言-动作”的融合方式和功能侧重,VLA架构可分为三类主流范式,适配不同任务场景:
1. 端到端统一架构(End-to-End Unified)
- 特点:视觉、语言、动作通过单一Transformer框架处理,无人工设计的中间模块,直接实现“输入→动作”映射。
- 优势:减少模块间信息损失,适合大规模数据训练下的泛化。
- 典型技术:采用扩散Transformer或自回归Transformer作为主干,支持连续动作生成。
- 代表模型:RT-1、Octo、RT-2。
2. 模块化融合架构(Modular Fusion)
- 特点:视觉、语言、动作模块解耦,通过适配器(Adapter)或接口层连接,可灵活替换子模块。
- 优势:兼容性强,可按需升级单一组件(如替换更强的视觉编码器)。
- 典型技术:通过LoRA(低秩适配)微调适配器,降低跨任务适配成本。
- 代表模型:OpenVLA、DexVLA。
3. 分层规划架构(Hierarchical Planning)
- 特点:分为“高层规划”和“底层控制”两层:高层通过LLM将语言指令拆解为子任务,底层生成具体动作。
- 优势:支持长流程任务(如“做饭→切菜→炒菜”),提升推理可解释性。
- 典型技术:结合LLM规划(如GPT-4)与技能库(如预训练抓取动作)。
- 代表模型:VoxPoser、SayCan。
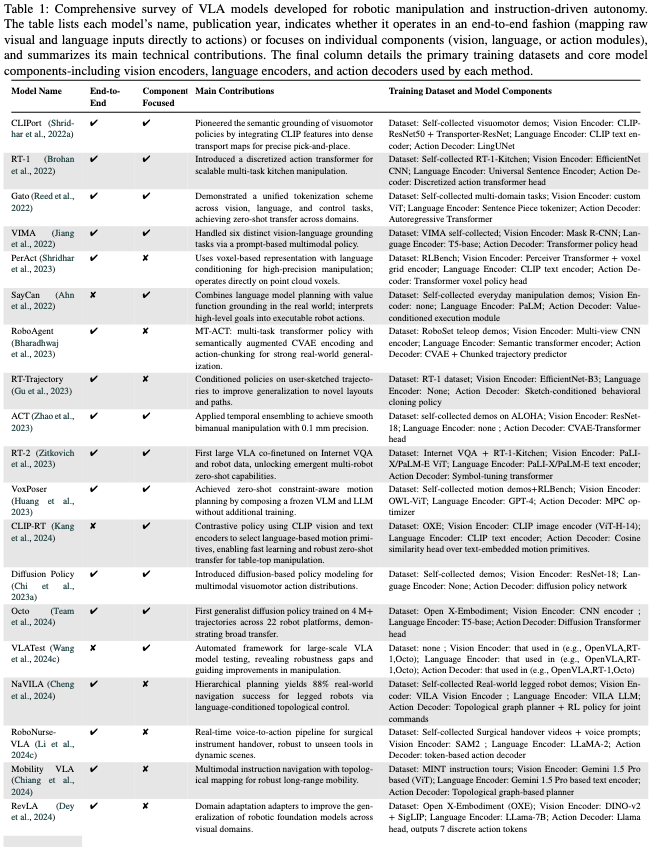
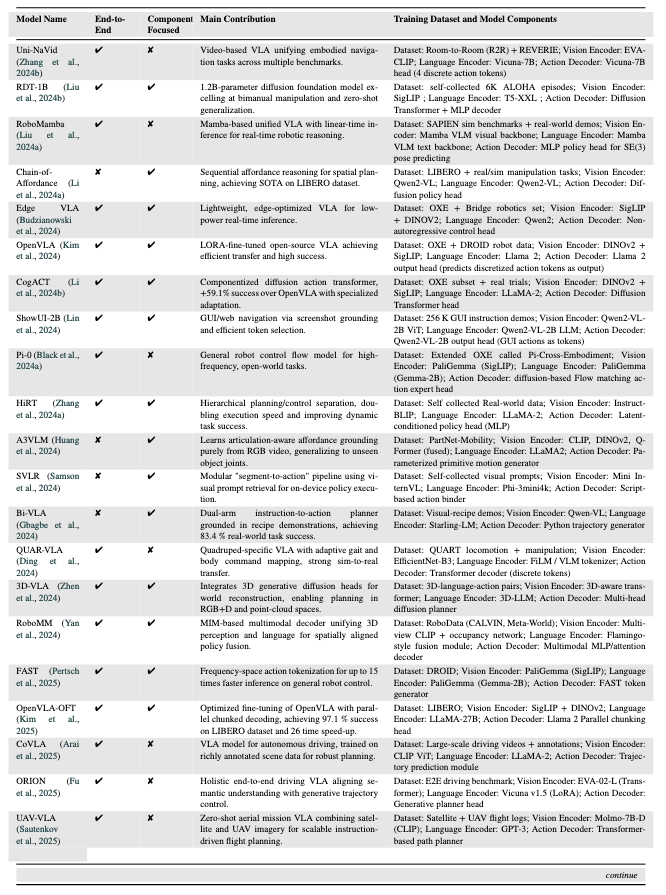
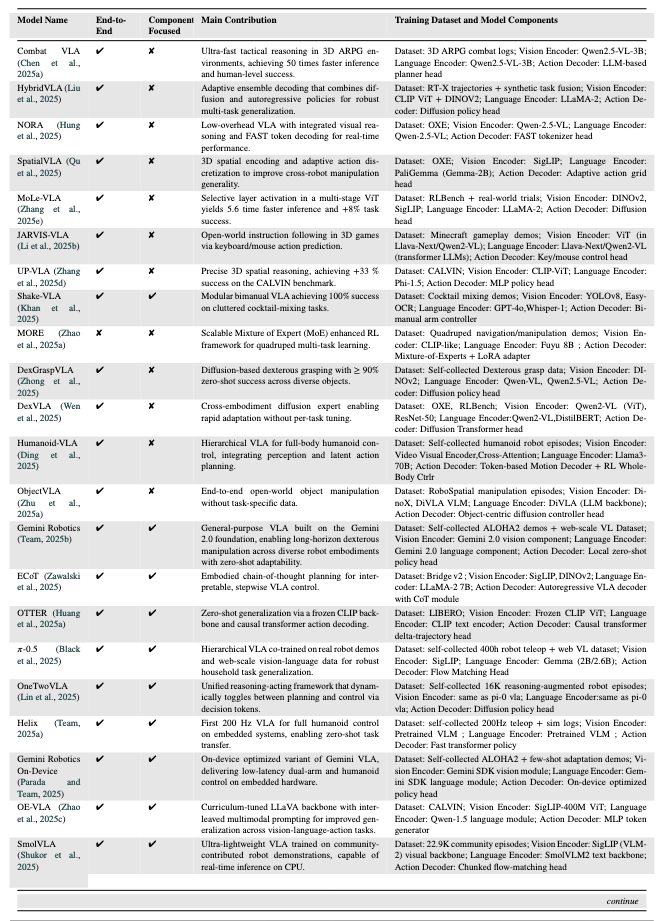
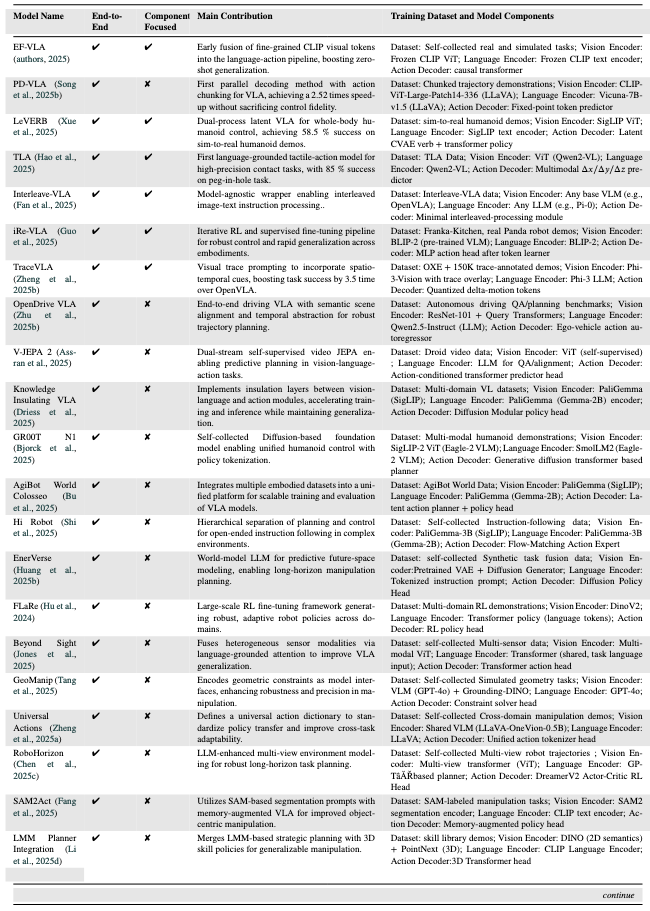
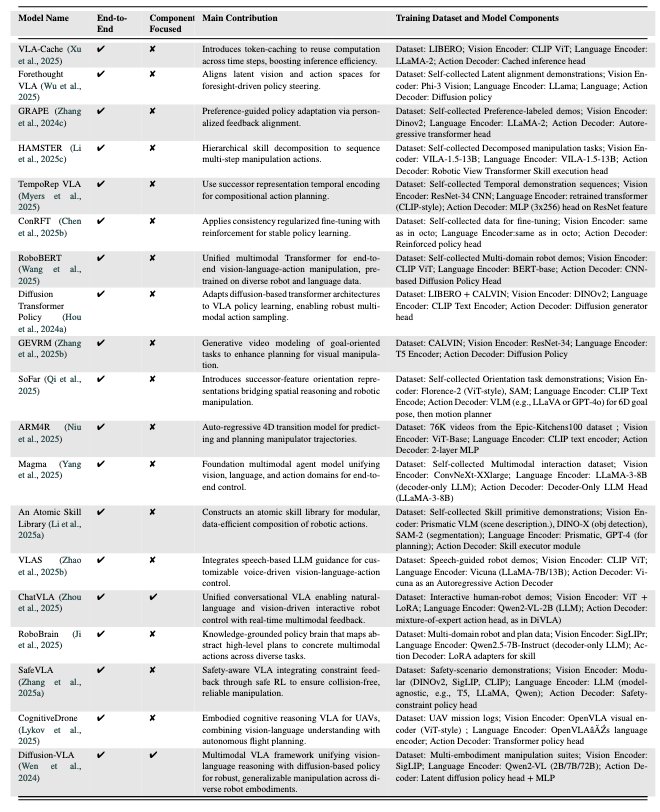
三、关键VLA模型及技术特点
论文分析了102个VLA模型,以下为具有里程碑意义的关键模型,覆盖不同架构类型和应用场景:
| 模型名称 | 发布时间 | 核心架构类型 | 关键技术与贡献 | 训练数据与组件 |
|---|---|---|---|---|
| RT-1 | 2022 | 端到端统一架构 | 首个离散动作Transformer,通过离散化动作令牌实现多任务厨房操控,支持100+日常任务。 | 数据集:RT-1-Kitchen(自收集厨房演示); 组件:EfficientNet(视觉)、Universal Sentence Encoder(语言)、离散动作Transformer(解码器)。 |
| VIMA | 2022 | 端到端统一架构 | 提出“提示驱动”(Prompt-based)控制,单一模型支持6类视觉-语言任务(如按颜色分类)。 | 数据集:VIMA(自收集多任务数据); 组件:Mask R-CNN(视觉)、T5-base(语言)、Transformer政策头(解码器)。 |
| SayCan | 2022 | 分层规划架构 | 结合LLM(PaLM)与价值函数,将语言指令映射为可执行动作(如“拿水”→“开冰箱”)。 | 数据集:日常操控演示; 组件:无专用视觉编码器(依赖预定义物体检测)、PaLM(语言)、价值条件执行模块(解码器)。 |
| RT-2 | 2023 | 端到端统一架构 | 首次在互联网视觉-语言数据(如VQA)与机器人数据上联合微调,解锁跨机器人零样本能力。 | 数据集:互联网VQA数据+RT-1-Kitchen; 组件:PaLI-X ViT(视觉)、PaLI-X文本编码器(语言)、符号微调Transformer(解码器)。 |
| Octo | 2024 | 端到端统一架构 | 首个基于扩散策略的通用模型,训练于400万+轨迹,支持22种机器人平台,泛化能力突出。 | 数据集:Open X-Embodiment(多机器人数据); 组件:CNN(视觉)、T5-base(语言)、扩散Transformer(解码器)。 |
| OpenVLA | 2024 | 模块化融合架构 | 开源模型,通过LoRA微调实现高效迁移,在LIBERO数据集上达到97.1%成功率。 | 数据集:Open X-Embodiment + DROID; 组件:DINOv2+SigLIP(视觉)、LLaMA 2(语言)、LLaMA输出头(解码器)。 |
| DexVLA | 2025 | 模块化融合架构 | 提出“插件式扩散专家”,无需任务微调即可适配不同机器人形态(如单臂、双臂)。 | 数据集:RT-X + RLBench; 组件:Qwen2-VL(视觉)、Qwen2-VL(语言)、扩散Transformer(解码器)。 |
| TLA | 2025 | 端到端统一架构 | 首个融合触觉信号的VLA模型,在接触密集任务(如 peg-in-hole 装配)中成功率达85%+。 | 数据集:TLA(3万+触觉-语言-动作数据); 组件:Qwen2-VL(视觉)、Qwen2-VL(语言)、多模态位置预测器(解码器)。 |
四、架构发展趋势
从关键模型的演进来看,VLA架构呈现三大趋势:
- 扩散策略主导动作生成:扩散Transformer(如Octo、DexVLA)逐步替代传统自回归模型,因其能生成更平滑、抗噪声的动作轨迹。
- 模块化与可扩展性增强:通过LoRA(OpenVLA)或插件式设计(DexVLA),支持快速适配新机器人或任务,降低部署成本。
- 多模态融合深化:从视觉-语言扩展到触觉(TLA)、力控信号,提升接触密集任务(如装配、抓取)的精度。
总结
VLA模型架构以Transformer为核心,通过视觉、语言、状态编码器提取特征,经动作解码器生成控制指令,按融合方式可分为端到端统一、模块化融合、分层规划三类。关键模型如RT-1(开创端到端范式)、Octo(扩散策略规模化)、OpenVLA(开源与可扩展性)推动了领域发展,未来将进一步向“多模态融合”“泛化能力”和“部署效率”方向演进。
一、VLA模型整体架构
VLA(Vision Language Action)模型的核心目标是统一视觉感知、自然语言理解和具象化控制,其架构以Transformer为基础骨架,通过跨模态融合实现“输入(视觉+语言)→输出(动作)”的端到端映射。整体架构包含四大核心模块,各模块通过共享特征空间实现协同工作。
| 核心模块 | 功能描述 | 技术基础 |
|---|---|---|
| 视觉编码器 | 将RGB图像、深度图等视觉输入转换为特征向量,捕捉物体位置、场景布局等信息。 | 基于ViT(Vision Transformer)、CLIP视觉模型或CNN(如ResNet)。 |
| 语言编码器 | 将自然语言指令(如“把苹果放在盘子里”)转换为语义特征,支持指令解析。 | 基于LLM(如LLaMA、GPT)或视觉-语言模型(如CLIP文本编码器、T5)。 |
| 状态编码器 | 编码机器人自身状态(如关节角度、末端执行器位置),确保动作符合运动学约束。 | 基于MLP或小型Transformer,处理连续状态数据。 |
| 动作解码器 | 融合多模态特征,生成连续动作指令(如轨迹、关节控制信号)。 | 基于扩散Transformer、自回归Transformer或MLP,支持平滑动作生成。 |
工作流程:
- 视觉、语言、状态数据分别通过对应编码器转换为特征;
- 特征在共享 latent 空间对齐(通过交叉注意力或对比学习);
- 动作解码器生成具体控制指令,部分模型支持闭环反馈(如根据执行结果修正动作)。
二、VLA模型架构分类
根据“视觉-语言-动作”的融合方式和功能侧重,VLA架构可分为三类主流范式,适配不同任务场景:
1. 端到端统一架构(End-to-End Unified)
- 特点:视觉、语言、动作通过单一Transformer框架处理,无人工设计的中间模块,直接实现“输入→动作”映射。
- 优势:减少模块间信息损失,适合大规模数据训练下的泛化。
- 典型技术:采用扩散Transformer或自回归Transformer作为主干,支持连续动作生成。
- 代表模型:RT-1、Octo、RT-2。
2. 模块化融合架构(Modular Fusion)
- 特点:视觉、语言、动作模块解耦,通过适配器(Adapter)或接口层连接,可灵活替换子模块。
- 优势:兼容性强,可按需升级单一组件(如替换更强的视觉编码器)。
- 典型技术:通过LoRA(低秩适配)微调适配器,降低跨任务适配成本。
- 代表模型:OpenVLA、DexVLA。
3. 分层规划架构(Hierarchical Planning)
- 特点:分为“高层规划”和“底层控制”两层:高层通过LLM将语言指令拆解为子任务,底层生成具体动作。
- 优势:支持长流程任务(如“做饭→切菜→炒菜”),提升推理可解释性。
- 典型技术:结合LLM规划(如GPT-4)与技能库(如预训练抓取动作)。
- 代表模型:VoxPoser、SayCan。
三、关键VLA模型及技术特点
论文分析了102个VLA模型,以下为具有里程碑意义的关键模型,覆盖不同架构类型和应用场景:
| 模型名称 | 发布时间 | 核心架构类型 | 关键技术与贡献 | 训练数据与组件 |
|---|---|---|---|---|
| RT-1 | 2022 | 端到端统一架构 | 首个离散动作Transformer,通过离散化动作令牌实现多任务厨房操控,支持100+日常任务。 | 数据集:RT-1-Kitchen(自收集厨房演示); 组件:EfficientNet(视觉)、Universal Sentence Encoder(语言)、离散动作Transformer(解码器)。 |
| VIMA | 2022 | 端到端统一架构 | 提出“提示驱动”(Prompt-based)控制,单一模型支持6类视觉-语言任务(如按颜色分类)。 | 数据集:VIMA(自收集多任务数据); 组件:Mask R-CNN(视觉)、T5-base(语言)、Transformer政策头(解码器)。 |
| SayCan | 2022 | 分层规划架构 | 结合LLM(PaLM)与价值函数,将语言指令映射为可执行动作(如“拿水”→“开冰箱”)。 | 数据集:日常操控演示; 组件:无专用视觉编码器(依赖预定义物体检测)、PaLM(语言)、价值条件执行模块(解码器)。 |
| RT-2 | 2023 | 端到端统一架构 | 首次在互联网视觉-语言数据(如VQA)与机器人数据上联合微调,解锁跨机器人零样本能力。 | 数据集:互联网VQA数据+RT-1-Kitchen; 组件:PaLI-X ViT(视觉)、PaLI-X文本编码器(语言)、符号微调Transformer(解码器)。 |
| Octo | 2024 | 端到端统一架构 | 首个基于扩散策略的通用模型,训练于400万+轨迹,支持22种机器人平台,泛化能力突出。 | 数据集:Open X-Embodiment(多机器人数据); 组件:CNN(视觉)、T5-base(语言)、扩散Transformer(解码器)。 |
| OpenVLA | 2024 | 模块化融合架构 | 开源模型,通过LoRA微调实现高效迁移,在LIBERO数据集上达到97.1%成功率。 | 数据集:Open X-Embodiment + DROID; 组件:DINOv2+SigLIP(视觉)、LLaMA 2(语言)、LLaMA输出头(解码器)。 |
| DexVLA | 2025 | 模块化融合架构 | 提出“插件式扩散专家”,无需任务微调即可适配不同机器人形态(如单臂、双臂)。 | 数据集:RT-X + RLBench; 组件:Qwen2-VL(视觉)、Qwen2-VL(语言)、扩散Transformer(解码器)。 |
| TLA | 2025 | 端到端统一架构 | 首个融合触觉信号的VLA模型,在接触密集任务(如 peg-in-hole 装配)中成功率达85%+。 | 数据集:TLA(3万+触觉-语言-动作数据); 组件:Qwen2-VL(视觉)、Qwen2-VL(语言)、多模态位置预测器(解码器)。 |
四、架构发展趋势
从关键模型的演进来看,VLA架构呈现三大趋势:
- 扩散策略主导动作生成:扩散Transformer(如Octo、DexVLA)逐步替代传统自回归模型,因其能生成更平滑、抗噪声的动作轨迹。
- 模块化与可扩展性增强:通过LoRA(OpenVLA)或插件式设计(DexVLA),支持快速适配新机器人或任务,降低部署成本。
- 多模态融合深化:从视觉-语言扩展到触觉(TLA)、力控信号,提升接触密集任务(如装配、抓取)的精度。
总结
VLA模型架构以Transformer为核心,通过视觉、语言、状态编码器提取特征,经动作解码器生成控制指令,按融合方式可分为端到端统一、模块化融合、分层规划三类。关键模型如RT-1(开创端到端范式)、Octo(扩散策略规模化)、OpenVLA(开源与可扩展性)推动了领域发展,未来将进一步向“多模态融合”“泛化能力”和“部署效率”方向演进。
VLA的数据集和仿真平台
根据论文内容,VLA(Vision Language Action)的训练与应用高度依赖大规模数据集和仿真平台——数据集提供训练样本,仿真平台解决真实世界数据收集的成本、安全性与多样性瓶颈。二者共同构成VLA模型从“理论架构”到“实际部署”的核心支撑。以下是详细描述:
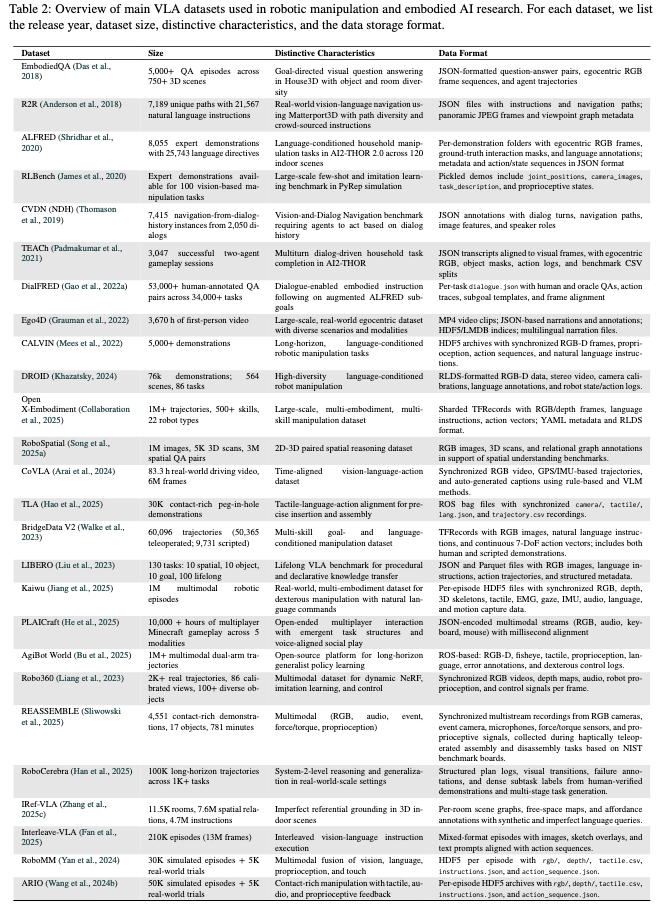
一、VLA的核心数据集(26个关键数据集)
论文对26个VLA核心数据集的特征、规模及适用场景进行了系统分析,按“任务复杂度”“模态丰富度”和“应用场景”可分为三类,核心作用是为VLA模型提供“视觉-语言-动作”关联的训练样本。
1. 核心特征与评估框架
论文提出二维评估框架,从“任务复杂度(CtaskC_{task}Ctask)”和“模态丰富度(CmodC_{mod}Cmod)”量化数据集能力:
- 任务复杂度(CtaskC_{task}Ctask):通过“单任务动作数(T)”“技能多样性(S)”“任务依赖性(D)”“语言复杂度(L)”计算,反映任务从“单步简单动作”到“长流程多技能”的难度(如“拿起苹果”vs“做饭”)。
- 模态丰富度(CmodC_{mod}Cmod):通过“模态数量(M)”“数据质量(Q)”“时序对齐度(A)”“推理辅助信息(R)”计算,反映数据集是否涵盖视觉(RGB/深度)、语言(指令)、状态(关节位置)、触觉等多模态信息。
2. 代表性数据集及特点
| 数据集名称 | 规模 | 核心特点 | 适用场景 |
|---|---|---|---|
| Open X-Embodiment | 100万+轨迹,22种机器人 | 统一22种机器人的动作空间,覆盖500+任务(如抓取、组装),支持跨机器人泛化训练。 | 训练通用VLA模型(如Octo),提升跨机器人适配能力。 |
| DROID | 7.6万演示,564个场景 | 结合互联网级视觉数据与机器人操控视频,含人类标注语言指令,覆盖复杂场景(如厨房、实验室)。 | 训练VLA的“视觉-语言-动作”关联能力,提升真实场景适应性。 |
| CALVIN | 5000+长流程演示 | 专注“语言条件下的长流程操控”(如“打开抽屉→取餐具→摆放”),含细粒度语言指令与动作轨迹。 | 训练VLA的长任务规划能力,解决“多步动作连贯性”问题。 |
| Kaiwu | 100万+多模态episode | 集成RGB、深度、触觉、EMG(肌电)、语言等7种模态,支持复杂环境下的精细动作训练。 | 训练接触密集型任务(如手术、装配),提升VLA对力、触觉信号的利用能力。 |
| BridgeData V2 | 6万+轨迹(5万人类操作,1万脚本) | 含“目标条件”和“语言条件”两种标注,覆盖多技能(如抓取、放置、推动),支持模仿学习。 | 训练VLA的“指令-动作”映射,适合家庭、办公等日常场景。 |
3. 数据集的核心价值
- 解决训练数据瓶颈:真实世界机器人数据收集成本高(如工业场景每小时数据成本超万元),数据集通过整合多来源数据(人类演示、仿真生成)降低训练门槛。
- 支撑泛化能力:大规模、多场景数据集(如Open X-Embodiment)让VLA模型学习“通用动作模式”(如“抓取”的共性轨迹),而非单一机器人的“专用动作”。
- 对齐多模态语义:数据集通过“视觉-语言-动作”的同步标注(如“拿起红色杯子”的指令对应视觉中红色杯子的位置和抓取动作),帮助VLA实现跨模态对齐。
二、VLA的仿真平台(12个核心平台)
仿真平台是VLA训练的“虚拟训练场”——它们生成物理逼真的虚拟环境,自动生成带标注的训练数据,解决真实世界训练的“成本高、风险大、场景有限”问题。
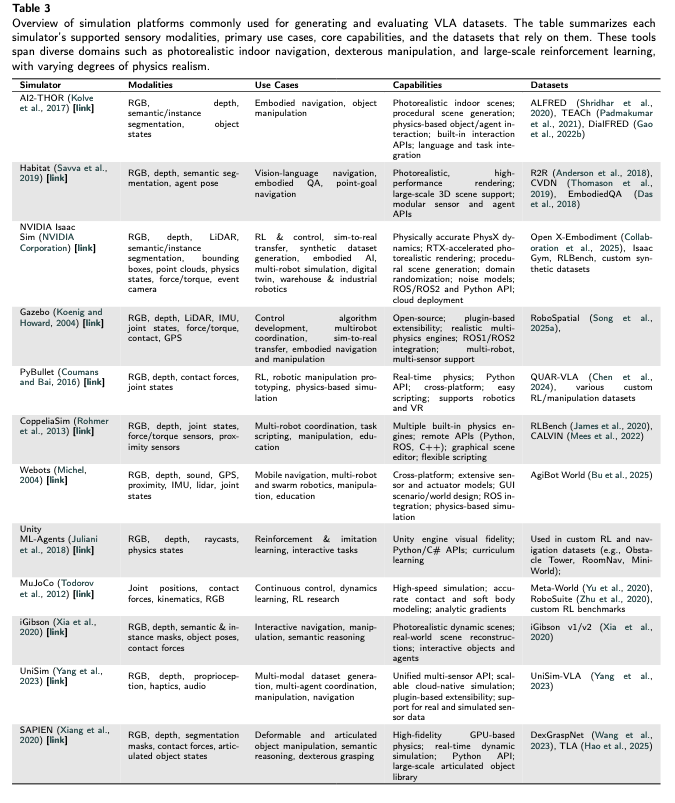
1. 核心功能
- 物理逼真模拟:模拟重力、摩擦力、碰撞等物理规律,确保虚拟动作可迁移到真实世界(如虚拟抓取轨迹在实机中仍有效)。
- 大规模数据生成:自动生成多样化场景(如不同光照、物体布局)和动作轨迹,支持批量训练。
- 安全与可控性:在虚拟环境中测试危险动作(如碰撞、高处操作),避免实机损坏或人员安全风险。
2. 代表性仿真平台及特点
| 平台名称 | 核心能力 | 典型应用 |
|---|---|---|
| NVIDIA Isaac Gym | 基于GPU加速,支持1000+并行环境,物理引擎精度高(如软物体形变、关节摩擦模拟)。 | 训练VLA的大规模动作样本(如Octo在400万+虚拟轨迹上预训练),提升训练效率。 |
| Habitat | 专注视觉导航与场景交互,提供 photorealistic 室内环境(如公寓、办公室),支持场景自定义。 | 训练VLA的视觉感知与环境交互能力(如识别家具位置、规划移动路径)。 |
| RoboSuite | 专注机器人操控,内置多种机器人模型(如Franka Panda)和物体库(如餐具、工具),支持动作轨迹自动标注。 | 训练抓取、装配等精细动作,生成带“物体位置-动作轨迹”标注的数据。 |
| AI2-THOR | 模拟人类-centric室内环境(如厨房、卧室),物体布局与真实世界高度一致,支持自然语言指令生成。 | 训练VLA的“语言指令→环境交互”能力(如“根据指令找到并移动特定物体”)。 |
| iGibson | 基于真实建筑扫描数据构建虚拟环境,支持物理交互(如开门、移动物体),视觉渲染接近真实。 | 解决“仿真-真实域偏移”问题,提升VLA模型的虚实迁移能力。 |
3. 仿真平台的核心价值
- 降低数据成本:生成1小时虚拟训练数据的成本仅为真实世界的1/100(如Isaac Gym可并行生成1000个环境的同步数据)。
- 扩展场景多样性:可模拟极端场景(如高温、狭窄空间)或危险任务(如化学品操作),填补真实世界数据空白。
- 提升训练效率:支持“领域随机化”(如随机改变物体颜色、光照),让VLA模型学习“不变特征”(如“抓取”的本质是“接触-施力”,与物体颜色无关),增强泛化能力。
三、数据集与仿真平台的协同作用
数据集与仿真平台并非孤立存在,而是形成“数据生成-标注-训练”的闭环:
- 仿真平台(如Isaac Gym)生成大规模虚拟数据(带自动标注的动作轨迹、物体位置);
- 数据集(如Open X-Embodiment)整合虚拟数据与真实数据,去除噪声并统一格式;
- VLA模型在融合数据上训练,兼顾“仿真数据的规模”与“真实数据的真实性”。
这种协同解决了VLA训练的核心瓶颈——没有足够多、足够多样的“视觉-语言-动作”关联数据,就无法训练出能适应真实世界的通用模型。
总结
VLA的数据集和仿真平台是其从“理论架构”走向“实际应用”的核心支撑:
- 数据集提供“视觉-语言-动作”的关联样本,决定VLA模型的“学习素材”;
- 仿真平台提供“低成本、高安全、多样化”的训练环境,解决数据生成与虚实迁移问题。
二者共同推动VLA模型从“小样本过拟合”向“大规模泛化”演进,为机器人领域的“通用智能体”目标奠定基础。
困难和挑战
根据论文内容,VLA(Vision Language Action)模型在发展过程中面临三大类核心困难与挑战,涵盖架构设计、数据集构建、仿真平台三大维度,这些挑战直接制约着VLA从“专用模型”向“通用智能体”的演进。以下是详细描述:
一、架构设计的核心挑战
VLA的核心目标是融合“视觉感知、语言理解、动作生成”,但跨模态特性导致其架构面临难以调和的技术矛盾:
1. 跨模态语义对齐难题
- 表现:视觉(图像像素)、语言(文本令牌)、动作(控制信号)的“语义粒度”和“表示形式”差异极大——例如“红色杯子”的视觉特征(颜色、形状)、语言描述(文字符号)、抓取动作(关节角度序列)难以在同一空间精确对齐。
- 后果:模型可能出现“视觉-语言错位”(如把“蓝色盘子”识别为“红色杯子”)或“语言-动作错位”(如指令“轻放”却生成“用力按压”动作)。
- 现有局限:虽有CLIP等模型实现视觉-语言对齐,但动作与前两者的对齐仍依赖人工设计的映射规则(如固定“抓取”对应特定关节角度),缺乏端到端的自动对齐机制。
2. 动作生成的物理约束适配
- 表现:机器人动作需符合运动学(如关节角度范围)和动力学(如避免碰撞、保持平衡)约束,而VLA的基础模型(如LLM)缺乏“物理常识”,生成的动作可能在虚拟环境中“可行”但在真实世界中“不可执行”(如规划的抓取轨迹穿过障碍物)。
- 后果:模型在仿真中表现优异,但实机部署时成功率骤降(“仿真-真实鸿沟”)。
- 现有局限:状态编码器虽能输入关节位置等物理信息,但难以实时感知动态约束(如物体突然滑动导致的力反馈变化),动作解码器生成的轨迹缺乏“物理合理性校验”模块。
3. 效率与性能的平衡
- 表现:VLA依赖大规模Transformer架构(如10亿参数以上)实现泛化,但机器人端(尤其是边缘设备)计算资源有限(如嵌入式CPU的算力仅为GPU的1/100),难以支撑实时推理。
- 后果:模型要么因“轻量化”牺牲精度(如Edge VLA压缩后零样本泛化率下降15%),要么因“高性能”无法部署(如GPT-4级模型推理延迟超1秒,无法满足实时控制需求)。
- 现有局限:现有轻量化方法(如模型剪枝、知识蒸馏)会丢失细粒度特征,而专用硬件(如机器人专用NPU)尚未普及,难以兼顾“精度”与“效率”。
二、数据集构建的核心挑战
VLA需要大规模、多样化、高质量的“视觉-语言-动作”关联数据,但数据生成与标注面临难以突破的瓶颈:
1. 真实世界数据的“规模-质量-多样性”矛盾
- 表现:
- 规模不足:真实机器人数据收集成本极高(如工业场景每小时数据标注成本超万元),单一场景(如厨房)的完整数据集(含1000+任务)需数月采集。
- 质量不均:人类演示数据存在动作噪声(如手部抖动),传感器数据(如深度图)存在误差,导致模型学习“错误动作模式”。
- 多样性有限:真实场景难以覆盖极端情况(如黑暗环境、物体堆叠)或危险任务(如高温物体抓取),导致模型泛化能力弱。
- 后果:模型在训练场景中表现优异,但面对未见过的物体、环境或任务时失效(如训练过“抓取杯子”却无法“抓取不规则石头”)。
2. 模态失衡与时序对齐问题
- 表现:
- 模态失衡:现有数据集多以“视觉+语言”为主,缺乏触觉(如抓取力度)、力控(如装配时的压力)等关键模态(仅Kaiwu、TLA等少数数据集包含触觉信号),导致VLA在接触密集任务(如精密装配)中精度不足。
- 时序错位:视觉帧、语言指令、动作信号的采样频率不同(如视觉30Hz、动作100Hz),人工对齐易出现“指令与动作不同步”(如“放下”指令对应“抓取”动作),影响模型学习因果关系。
- 后果:模型无法理解“动作力度”“接触反馈”等关键信息,在需要精细控制的场景(如拿起易碎品)中易失败。
3. 标注成本与自动化瓶颈
- 表现:高质量标注(如6D物体姿态、动作意图分类)依赖专家人工,难以自动化——例如标注“抓取动作是否成功”需人工判断,而“语言指令与动作的关联”(如“整理”对应“拿起→移动→放下”)需语义级标注,成本极高。
- 现有局限:自动标注工具(如基于VLM的标签生成器)在复杂场景中准确率不足(如遮挡物体的姿态预测误差超5cm),难以替代人工。
三、仿真平台的核心挑战
仿真平台是VLA训练的“数据工厂”,但“物理真实性”与“训练效率”的矛盾制约其作用:
1. 物理引擎的精度与效率矛盾
- 表现:
- 高精度物理引擎(如MuJoCo)能模拟软物体形变、摩擦力变化等细节,但计算耗时(单环境步长耗时10ms,1000并行环境需GPU显存32GB以上);
- 高效引擎(如Isaac Gym)支持10000+并行环境,但简化了物理模型(如忽略物体表面纹理对摩擦力的影响),导致“仿真-真实差异”(如虚拟中“抓取成功率90%”,实机中仅60%)。
- 后果:模型在仿真中学习的“动作模式”无法迁移到真实世界,需额外“实机微调”,抵消了仿真的成本优势。
2. 场景与物体的真实感不足
- 表现:仿真平台的虚拟场景(如AI2-THOR的厨房)虽能模拟布局,但物体材质(如金属反光、布料褶皱)、光照变化(如阴影、反光)的真实感不足,导致VLA的视觉模型在真实场景中“认不出”熟悉物体(如虚拟中“光滑杯子”与真实中“带花纹杯子”的特征差异)。
- 后果:视觉感知模块在仿真中精度超95%,但实机测试时骤降至70%,成为VLA虚实迁移的主要障碍。
3. 语言与动作的自动关联缺失
- 表现:仿真平台能自动生成视觉和动作数据,但难以生成“自然语言指令与动作的关联标注”——例如虚拟机器人完成“抓取苹果”动作后,需人工输入对应指令(如“把苹果拿起来”),无法自动生成多样化语言描述(如“抓取红色圆形物体”“拿起桌上的苹果”)。
- 后果:仿真数据缺乏“语言-动作”关联样本,需依赖真实世界的语言标注,无法充分发挥仿真的“规模化优势”。
总结:核心矛盾与本质挑战
VLA的所有困难可归结为一个核心矛盾:“通用智能”的泛化需求与“具象化动作”的物理约束之间的不匹配。具体表现为:
- 架构上,“跨模态对齐”与“物理可行性”难以兼顾;
- 数据上,“大规模需求”与“高质量、多样化供给”存在鸿沟;
- 仿真上,“训练效率”与“真实感迁移”无法平衡。
这些挑战的本质是:VLA试图将基础模型的“抽象智能”与机器人的“具象化动作”结合,但二者的“能力底座”(数据、硬件、理论)尚未完全适配。解决这些挑战需要跨领域协同——从架构(如模块化设计)、数据(如混合仿真-真实数据)、硬件(如专用NPU)多维度突破,推动VLA从“实验室原型”向“实用系统”演进。