混合检索(Hybrid Search)作为AI应用中的常用技术,需要融合多模数据和多种检索技术,从而实现整合不同检索策略,来提升检索的准确性、召回率和适应性。
基于一体化架构设计的OceanBase数据库,创新性地实现了结构化、半结构化和非结构化数据的统一存储和混合检索能力。本文将深入解析"标量+向量"这一典型的混合检索场景,详细阐述OceanBase混合检索的技术原理与优势,并延伸探讨"全文+向量"等更多的场景。
本文是【OceanBase向量技术解读系列】的第一篇文章,我们将持续带来更多深度技术解析,欢迎持续关注后续内容。
混合检索(Hybrid Search)的概念相信大家都不陌生。由于大量非结构化与半结构化数据的涌现,在许多 AI 应用场景中,数据库不仅需要具备对向量数据的检索能力,还需要针对多种数据模型,将不同的检索手段相结合,以达到更优的检索效果。
举一个典型的例子,在平台上请系统推荐“附近 500 米,评价 4.5 分以上、上菜快的火锅店”,就需要同时对地理空间数据(附近 500 米)、关系型数据(评价 4.5 分以上)、向量数据(上菜快的火锅店)进行融合查询和语义匹配。
2024 年,OceanBase 引入了向量检索能力。OceanBase 基于多模一体化架构,提供了面向多模数据的混合检索能力,能够在一套数据库系统里实现对多种数据的融合查询。
虽然混合检索听起来是一件再自然不过的场景,但对于数据库来说,在一套系统中实现混合检索却非易事。今天让我们从最简单的标量+向量融合查询场景说起,走进 OceanBase 的混合检索。
01 标量 + 向量融合查询:先查向量,还是先查标量?
随着 OceanBase 发布向量能力,许多开发者朋友和我们的技术团队展开了丰富又深入的交流。而在这些交流中,我们听到最多的、也是许多人第一个问到的问题就是,在标量+向量融合查询的场景中,OceanBase 到底是先查向量还是先查标量?
对于许多不太了解向量数据库的朋友来说,这似乎是个很无聊的问题——先查什么数据重要吗?反正只要能查出来就好了嘛!
问题恰恰出在这里:先查标量,还是先查向量,很大程度上将影响查询的召回率和性能!这还要从混合检索的底层技术说起。
刚才我们说到,随着半结构化和非结构化数据的涌现,向量检索被用于大量的语义匹配的场景。换句话来讲,通过将文档和查询表示为向量,然后通过计算两者之间的相似度来找到前 k 个相关度最高的文档,实现近似匹配。而对于标量数据来说,一般通过常规的查询手段(等值查询、范围查询、倒排索引等)进行检索,目的是找到精确匹配用户需求的数据。在标量+向量的融合查询场景中,两个过程往往存在先后顺序。先查标量,可能由于过滤条件太过复杂,或者过滤条件的过滤性不好,导致产生大量的读表和条件表达式计算,影响查询性能;先查询向量,传统的做法可能会导致查询到的结果不满足标量过滤条件,导致结果数量少于预期。
现在让我们进一步了解这些技术,以及其在 OceanBase 中的实现方式。
📕(一)先查标量:前过滤(Pre-filtering)
当前,在许多数据库的技术方案里,先查标量(Pre-filtering)往往是唯一解,这个方案确实是有效的。它的原理是,每条向量在向量索引中对应一个唯一 ID,通过过滤标量条件,可以把符合条件的 ID 都搜索出来,并基于 ID 生成一个 Bitmap。向量索引在搜索过程中,每次查到一个候选结果,就去检查这个 Bitmap。如果在这个 Bitmap上,就说明这条结果是符合标量条件的,会暂存到结果集中,如果不在,就继续搜索,直到满足向量查询终止条件,最后在结果集中返回 Top k。
OceanBase 针对这种方案进行了一些改进,即支持用户在标量条件上建索引,且 OceanBase 的优化器能够自动选择性能最优的索引进行查询。

Pre-filtering
Pre-filtering 的问题在于,如果标量过滤条件的过滤率低(即过滤后剩下的数据量依然很大),或者条件太复杂(比如条件涉及多列),进行标量过滤的代价甚至会大于向量索引近似最近邻查询的代价。比如有 100 万条数据,经过过滤后留下了 10 万条,而且过滤条件涉及多列,那么即使选中了合适的索引,也需要进行 10 万次回表计算,耗时可想而知。
因此,这种方案往往会被应用于部分过滤率(filter rate)非常高、且过滤条件不包含多个字段/复杂条件的场景,否则就会因为标量过滤代价过大,导致性能显著下降。
📕(二)在查询中过滤:In-filtering
于是,另一种思路出现了,即直接在向量查询中进行过滤(In-filtering),跳过扫描索引表和构造 Bitmap 的环节,系统直接进行向量索引的查询,在找到符合要求的向量之后,再进行过滤条件的检查和计算。
在这个过程中,为了进一步提高性能,OceanBase 还提供了一个叫作 extra info 的特性。在过滤条件比较固定的情况下,用户可以通过配置 extra info 保存常用字段,把这条标量直接存储到内存向量索引当中,从而完全避免回表和扫表的代价,系统执行就会更快。
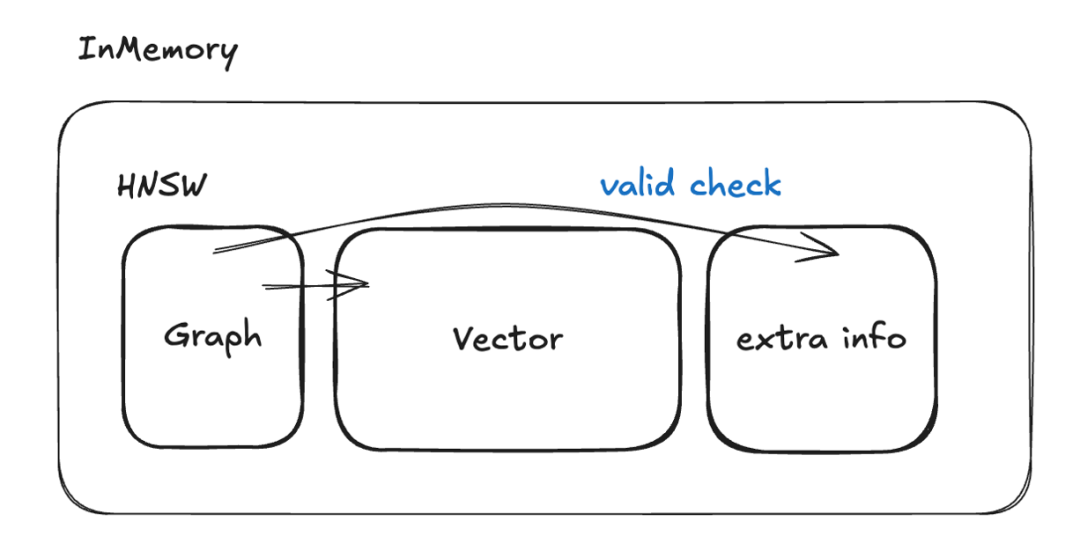
In-filtering with extra info
这种方案往往会被用于一些过滤率(filter rate)中高的场景,在这些场景下 In-filtering 会比 Pre-filtering 的效果更好,而它的缺点在于需要占用额外的内存。如果要过滤的标量字段是一个特别大的 JSON,或者说是一些更复杂的数据类型,就会带来非常大的代价。另外如果条件太复杂、过滤性非常差,这种方案仍然是不适用的。
📕(三)迭代式过滤:Iterative-Ann
于是,我们来到了最后一种方案,它的全称叫迭代式近似最近邻查询(Iterative-Ann),或者简单地称之为迭代式过滤。在这种方案里,我们先进行向量索引的查询,但是在查询的过程中,会把查询的上下文保存下来,在每一轮向量索引查询后再进行过滤,如果发现有一部分数据是不满足要求的,则会恢复上下文,从上一次迭代的位置开始,继续搜索近似最近邻。
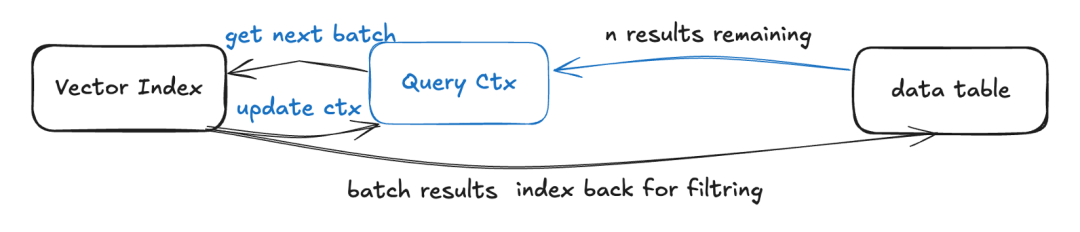
Iterative-Ann
在这种情况下,如果标量的过滤率比较低,则意味着大部分数据都会保留下来,因此可能只需要几次迭代就能获得想要的结果。举个例子,在需要搜 100 条结果、标量过滤率是 50% 的情况下,在第一次迭代中向量索引查询出 100 条结果,经过过滤后留下 50 条,那么接下来再经过一两轮迭代,就很可能填满 100 条结果的要求,而这个过程中过滤条件的执行次数只有两三百次。也就是说,在过滤率(filter rate)中低场景,且过滤条件复杂的情况下,迭代式过滤反而计算量少,性能明显优于前述两种方案。
讲了这么多,OceanBase 采用的究竟是哪种方案呢?
02 OceanBase: 自适应混合检索更快、更准、更易用
OceanBase 到底是先查向量还是先查标量?我们的答案是,依情况而定,具体问题具体分析。
下图是我们使用 VectorDBBench 向量数据库性能测试工具对比 OceanBase 4.3.5 BP2 版本和某主流开源向量数据库在同一环境下,采用 768D1M 数据集,查询 Top100,召回率 98%,进行向量+标量混合检索性能测试得到的结果。
根据结果可以发现,在不同过滤率的条件下,OceanBase 的性能基本是全面占优的,特别是对于极高过滤率(99%)的场景,OceanBase 的性能具有显著的优势。
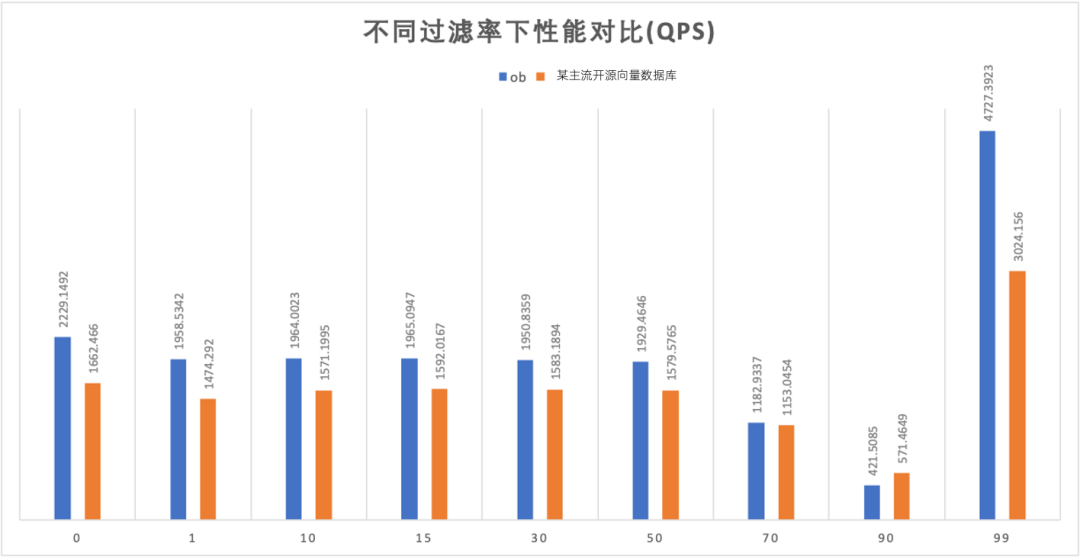
Vectordbbench: OceanBase V4.3.5 BP2 vs 某主流开源向量数据库
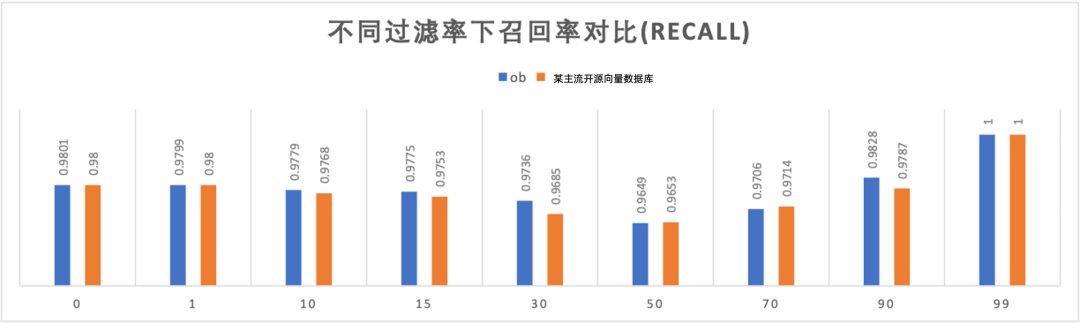
Vectordbbench: OceanBase V4.3.5 BP2 vs 某主流开源向量数据库
OceanBase 在混合检索场景下的优秀表现得益于其自适应的混合检索策略,根据实际代价,系统会选择不同的执行路径完成检索任务。
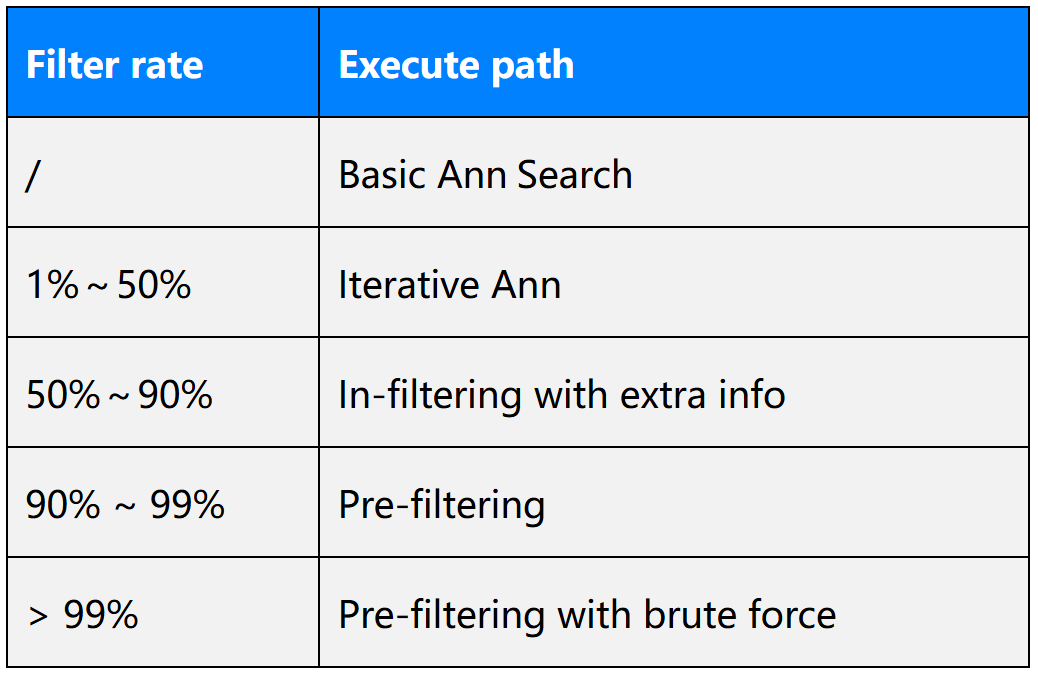
具体而言,在过滤率介于 1% 到 50%时,OceanBase 会选择迭代式过滤;在过滤率介于 50% 到 90% 的情况下,选择 In-filtering 路径;在大于 90% 的场景下会选择前过滤,也就是业界最常用的方案。此处还有一个特殊场景,也就是过滤率大于 99% 的条件。这种情况下经过过滤的数据量通常已经比较小了,所以很可能直接暴力计算比走索引更快,此时系统会在前过滤和暴力计算的方案中进行选择。
03 下一步:向量+全文多索引融合排序
在标量之上,混合检索还会遇到向量检索与全文检索融合查询的场景。
举个例子,我们希望查询“广州周边适合一日游、适合拍照打卡且人少的旅游目的地”。一般情况下,我们会认为向量检索天然适合这种需要语义搜索的场景,例如“适合拍照打卡且人少”,可能匹配到“无商业开发”、“原生态风貌”等信息,从而完成较为准确的推荐。
然而,向量检索可能并不能理解并精确查询出符合“一日游”条件的内容。这是因为向量检索可能会将“一日游”的概念与“距离近”、“交通方便”等内容匹配,而不能实现对一日游能够当天来回的条件的精准检索。在这一基础上,引入全文检索就能够很好地解决这个问题。全文检索是基于词频和分词的搜索模式,能够实现对词语的精确匹配,其缺点在于不能理解语义,从而无法实现语义上的近似查询。
因此,在此类场景中,单独使用向量检索或全文检索都无法达到用户所需的最优结果,我们需要向量索引+全文索引的混合检索,并将搜索结果融合起来进行综合排序。
在进行排序时,最大的问题在于全文索引的值域范围是非常广的,从十几到上百都有可能,然而向量索引,以典型的 Cosine 距离为例,它的值域范围就是 [0,2],这两者之间往往是没法比较的。我们怎么去做综合排序呢?
为了解决这个问题,OceanBase 考虑了三种方法。
第一种方法叫做加权求和(Weighted Sum),将不同索引查询结果分别归一化,再进行加权计算。这里的权重来源于一些经验值,并根据具体的场景进行微调。例如可以把全文权重设置为 0.3,向量权重设置为 0.7。因此在有先验数据的情况下,这是一种较好的方法。
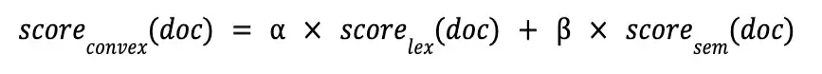
加权求和(Weighted Sum)
另一种方法叫做倒数排序融合(Reciprocal rank fusion),不需归一化,只根据结果集中的排名对其进行评分,比如向量查出十条结果,第一名的 rank 值是 1,第十名 rank 就是 10,以此类推。在没有先验知识的情况下,使用这种排序方法通常就能够取得比较好的效果了。

倒数排序融合(Reciprocal rank fusion)
还有一种方法就是直接使用预训练的 rerank 模型进行重排,这种方法得到的结果最精确,但代价也最高,当前市面上已经有一些可以使用的模型了。如果我们需要的结果集数量较小,例如 Top10、Top20,rerank 模型无疑是非常好的方案,但如果查询的结果数量较多,就需要综合考虑成本。
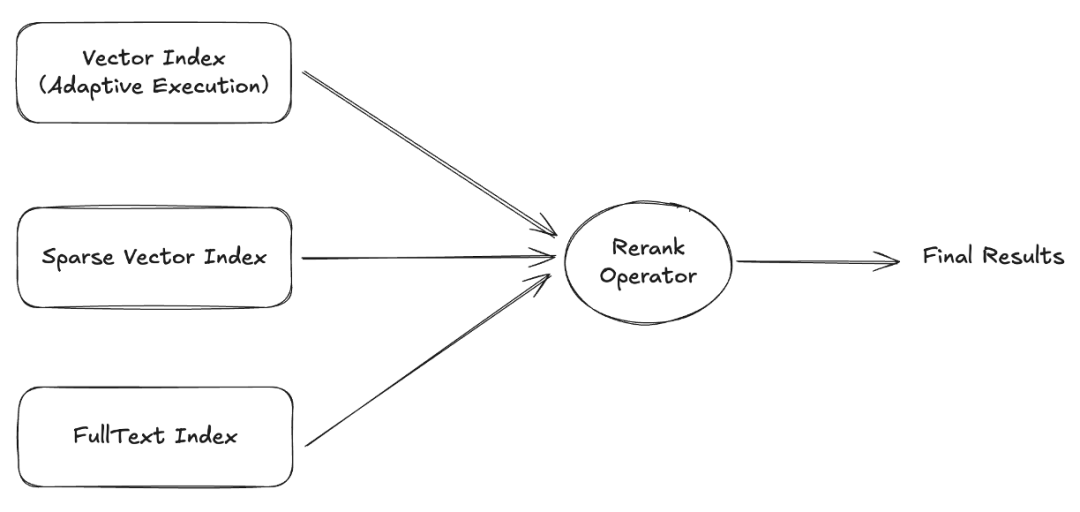
当前,OceanBase 已支持全文索引与向量索引,用户可以在应用端分别查询,并在应用端做融合排序,未来计划支持在内核实现用一个语句即可完成融合查询。
OceanBase 为用户提供更快、更准、更易用的混合检索体验,配置丰富的执行策略,并采用基于代价的自适应的方法,选择性能与召回率最优的计划。
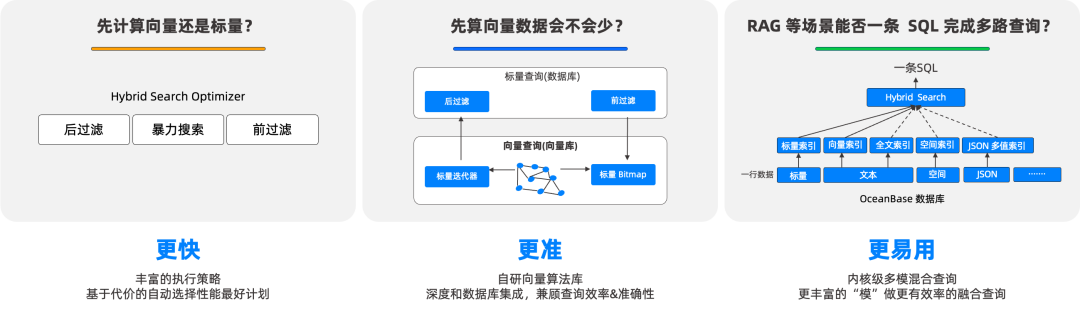
未来,OceanBase 将持续完善稀疏向量的自适应执行策略,并引入多索引的融合排序,同时继续提升向量能力,增强在混合检索等场景的全面支持,为用户带来更好的 AI 体验。