Python基础编程
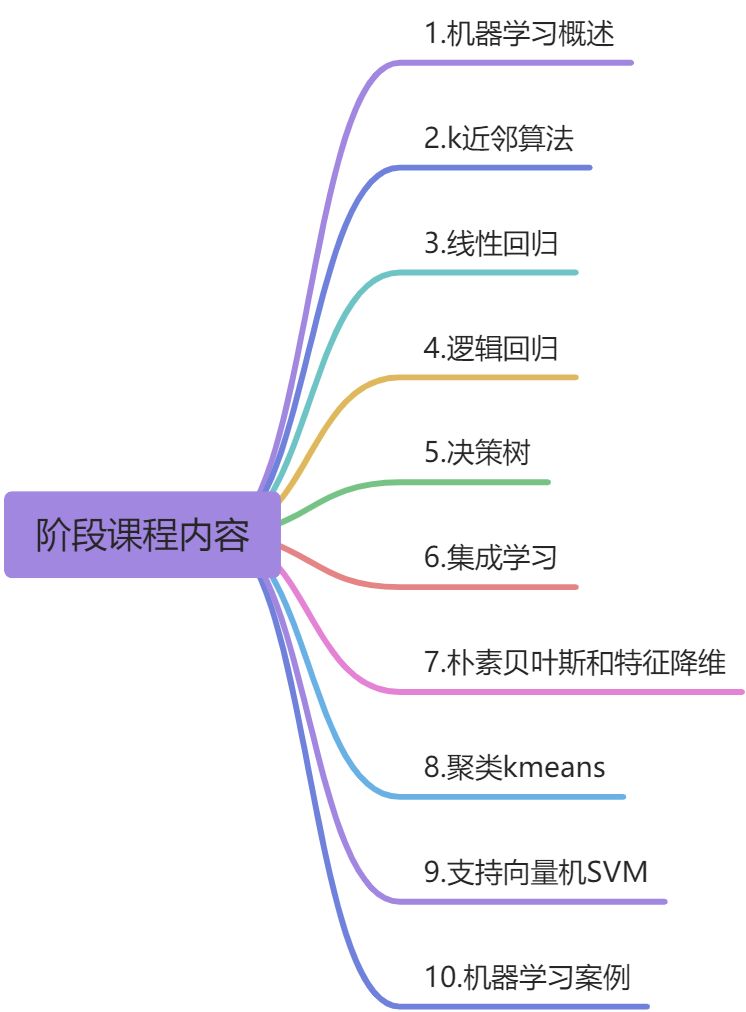
阶段课程内容
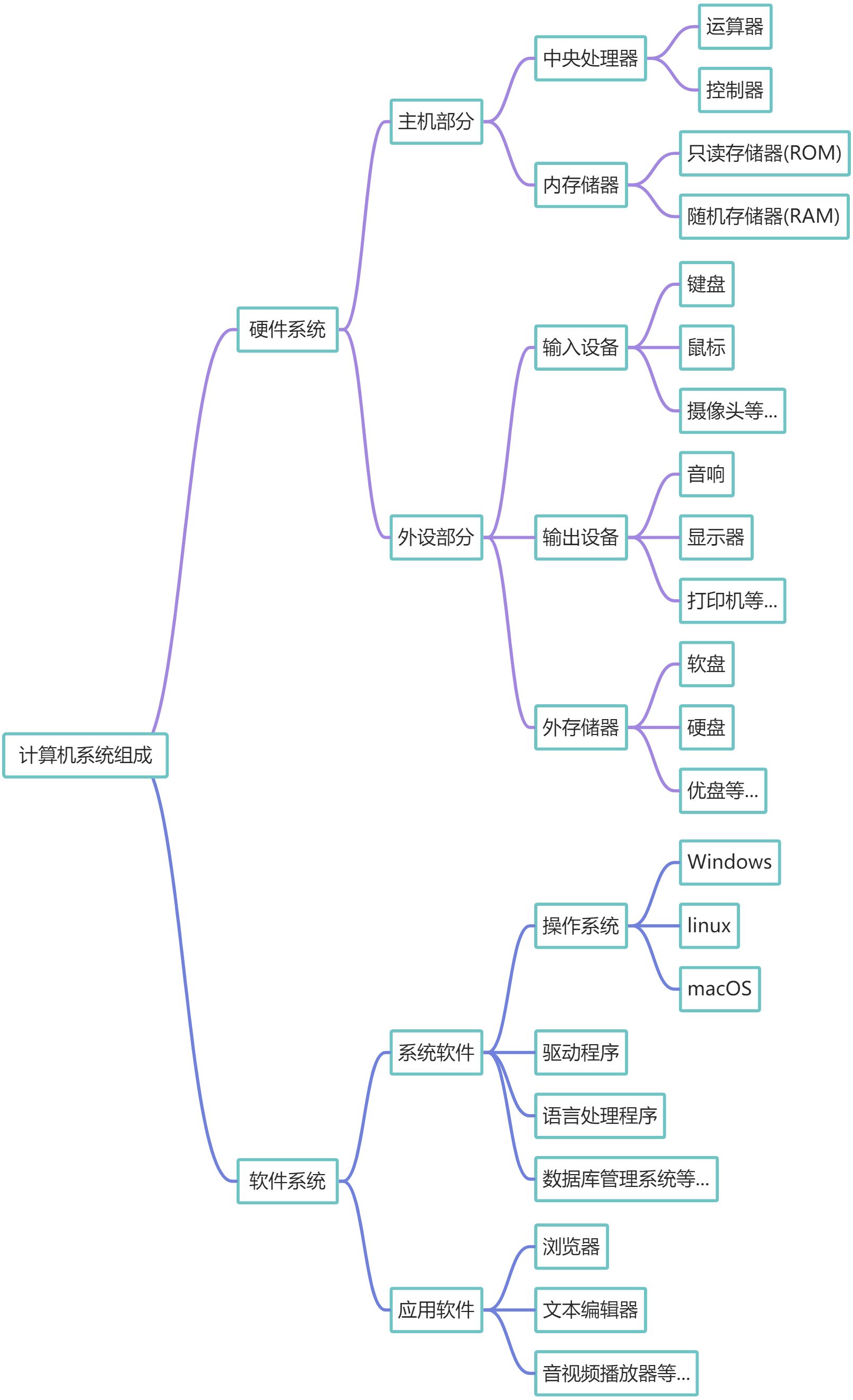
计算机系统组成
Python核心信息
创始人
吉多范罗苏姆,也被尊称为龟叔
第一个版本发布时间---------1991
开发中常使用的是 3.7 3.8 3.9
程序
Python解释器
将Python语法解释为计算机能够看得懂的机器语言进行执行,解释一行,执行一行.
PyCharm
ide工具---集成化开发环境
有着代码提示,代码高亮,错误检查,工程管理....
Python基础
注释
单行注释#
多行注释
有两种格式: ''' ''' 或""" """,这两种写法都可以,但是要记住都是三对符号
变量及其类型
变量就是存储数据的容器.当我们使用变量时,实际获取的是变量里面的数据信息
类型
int,float,bool,list,tuple,str,set,dict.
标识符与关键字
标识符
程序员自己定义的,有特殊功能的字符组合,程序员定义的标识符不能使用关键字
命名规则
1.只能由字母,数字和下划线组成
2.不能使用关键字
3.不能以数字开头
4.严格区分大小写
命名规范
1.大驼峰命名法:每个单词首字母大写,如:StudentNum
Python中的类名使用大驼峰命名法
2.小驼峰命名法:除了首字母外,其余单词首字母大写,如:studentNum
3.下划线命名法:单词中间用下划线分隔开
Python中的变量名、函数名、方法名、文件名等,使用下划线分割法
如:student_num
4.标识符要做到见名知意,增强代码的可读性
关键字
系统或者Python定义的,有特殊功能的字符组合
在学习过程中,文件名没有遵循标识符命名规则,是为了按序号编写文件方便查找复习
但是,在开发中,所有的Python文件名称必须遵循标识符的命名规则,且不能含有中文信息
输出函数
输出就是计算机在控制台中,向用户展示数据内容
使用的函数: print(输出的内容)
输出普通数据
print("圆梦大厂") #输出字符串数据
print(123) #输出数字型数据
print(True) #输出bool型数据格式化后的数据内容
格式化:在特定位置更换输出内容
如: '要输出的内容 占位符1,占位符2...' %(数据1,数据2......)
注意:数据的个数要和占位符保持一致
输出的内容会随变量的变化而变化
占位符
使用该符号进行占位,运行时使用变量将其替换掉,常见的占位符有:%d,%f,%s
name='松松'
print('我的名字是%s' %name)可以添加多个占位符
由于我们进行格式化拼接时,只能获取一个元素,所以需要将多个变量使用括号包裹起来.
print('我的名字是%s,我的年龄是%d,我的性别是%s' %(name,age,gender))
多占位符格式化字符串时,要注意:
1.占位符和变量的数量一致,类型一致
2.占位符与变量赋值时顺序要一一对应,不能交叉赋值,也不能跳跃赋值
3.在格式化时,%只能识别一个数据,所以如果有多个变量时,要用()括起来
可以完成精度处理
%.nf :浮点型保留n位小数
%nd :可以占n位,不足位用空格或0补齐,超出n位,则原样显示
例如:%0nd,当不足时用,0补齐
name="张三"
age=18
sex='男'
print("我的名字是%s,年龄是%d,性别是%s" %(name,age,sex) )分隔符和结束符
在print函数中,sep和end有默认值
def print(self, *args, sep=' ', end='\n', file=None):
pass在打印时,对默认值进行修改,可以改变输出方式
输入函数
输入:人类向计算机输入指令
使用的函数:input
格式
变量名=input('提示语句')
注意
1.提示语句是输出到控制台上的,并不会被变量所接受
2.我们通过控制台输入的数据会被变量接受
3.我们输入的一切数据都会被当做字符串数据使用
username=input('请输入您的用户名:')
print('您的用户名是%s' %username)
password=input('请输入您的密码:')
print('您的密码是%s' %password)
print(type(username)) #<class 'str'>
print(type(password)) #<class 'str'>name=input("请输入姓名:")
age=input("请输入年龄:")
height=input("请输入身高:")
number=input("请输入学号:")
print("姓名:%s,年龄:%s,身高:%s,学号:%s" %(name,age,height,number))print里面的占位符一定要是%s,否则就会报错
快速格式化代码的快捷键:Ctrl+alt+L
注意:input接收的所有数据都是字符串类型,需要使用%s进行接收
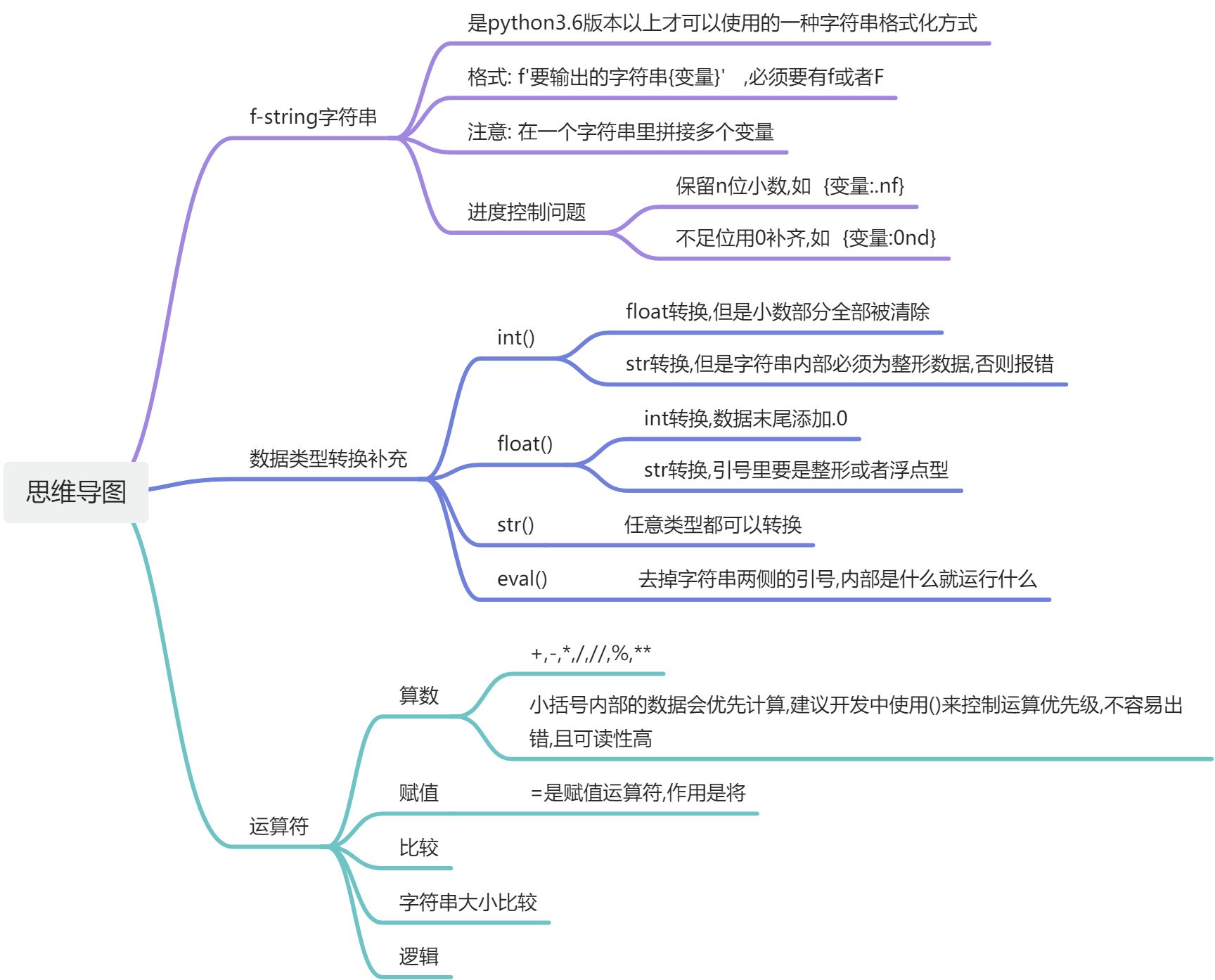
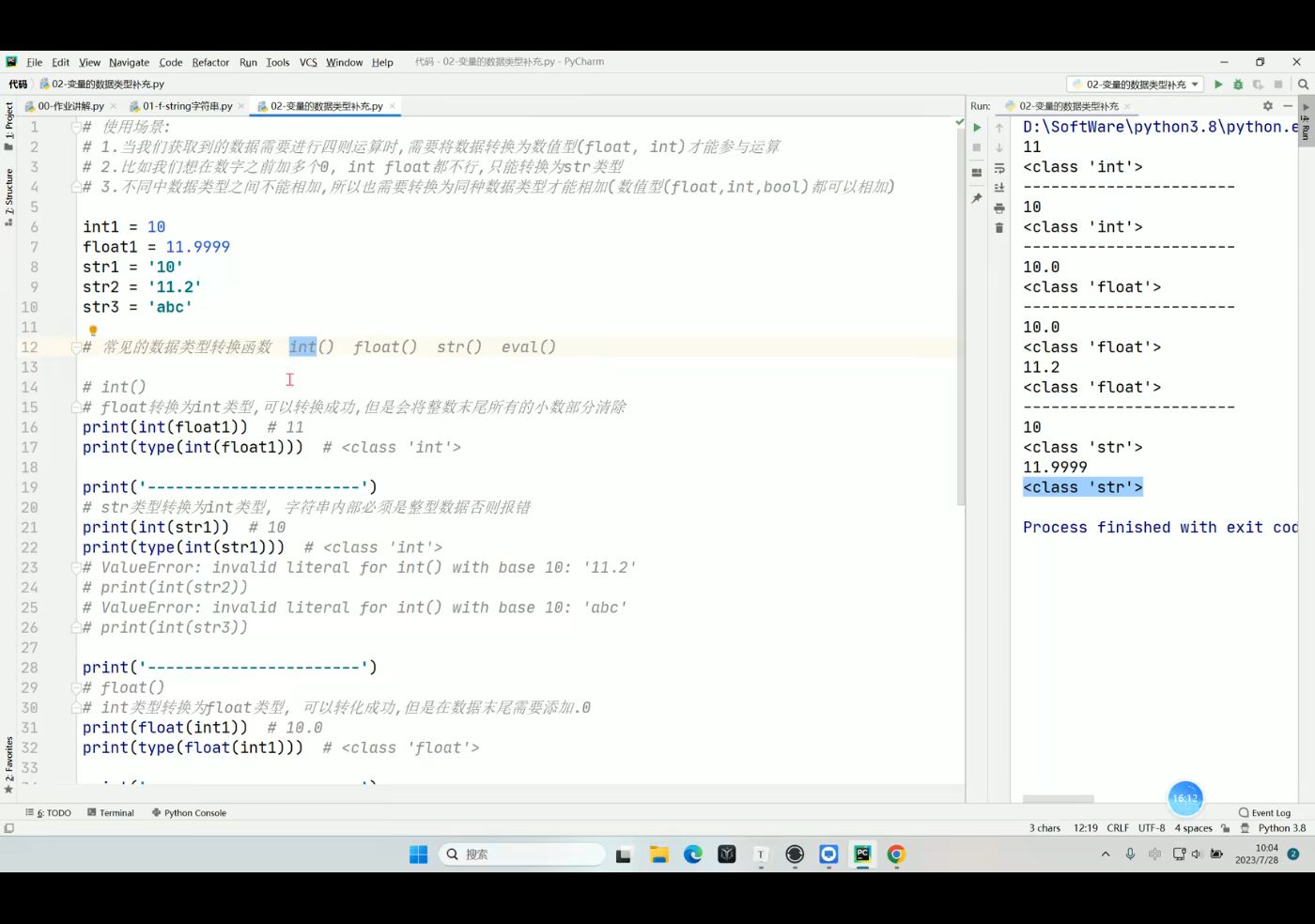
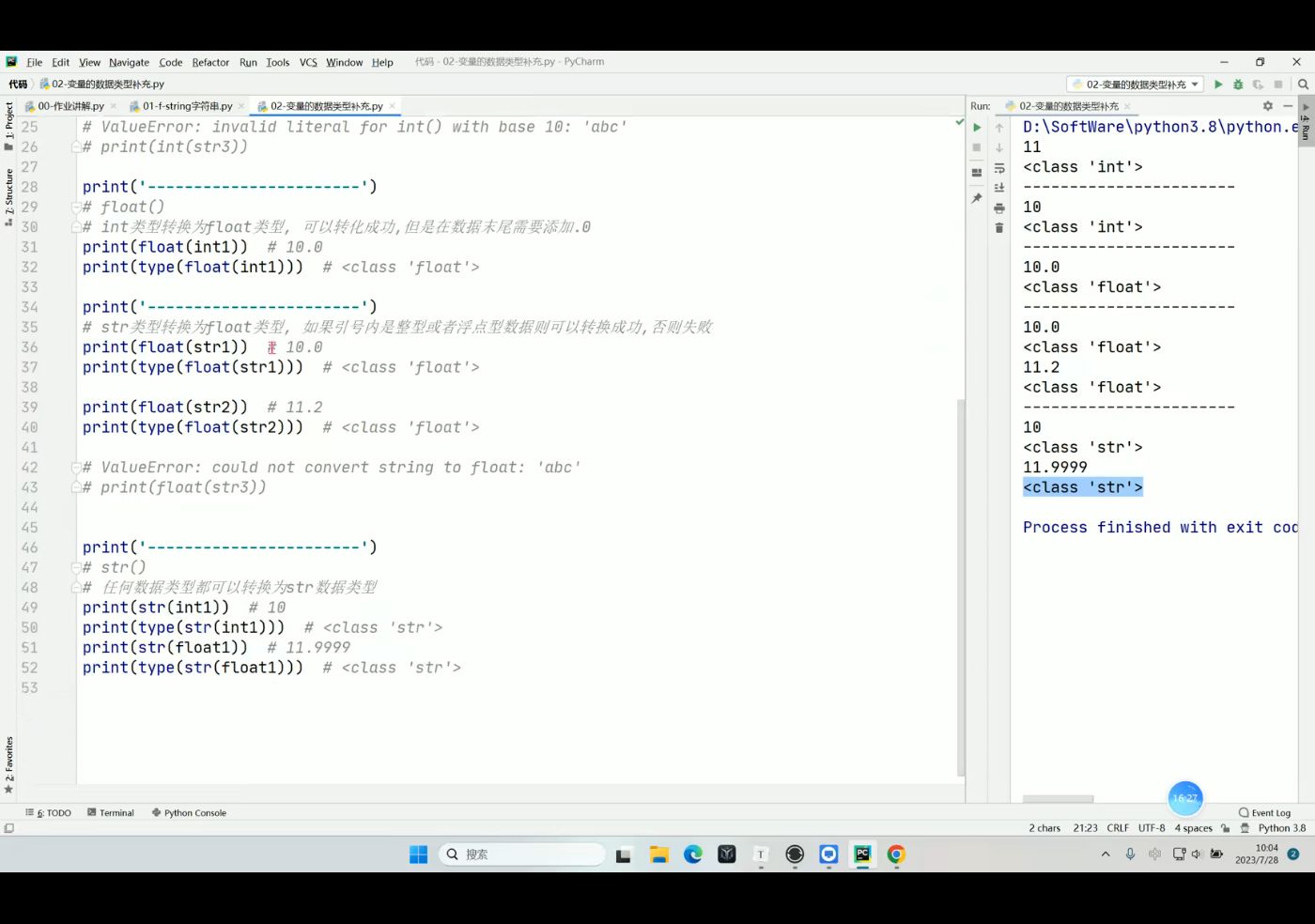
数据类型转换
转换的原因
1.不同数据类型有不同的功能,比如字符串类型没有办法进行数学运算 减法除法等
2.不同类型的数据没有办法进行数学运算,比如字符串类型没有办法+1
方式
就是给数据穿一层衣服
变为int类型: int(值或变量)
变为float类型: float(值或变量)
变为str类型: str(值或变量)
注意
被转换的数据一定是可以被转换的,否则就会报错
str1='11'
int1=int(str1)
print(type(int1) ) <class 'int'>
print(type(str1) ) <class 'str'>
print(int1) 11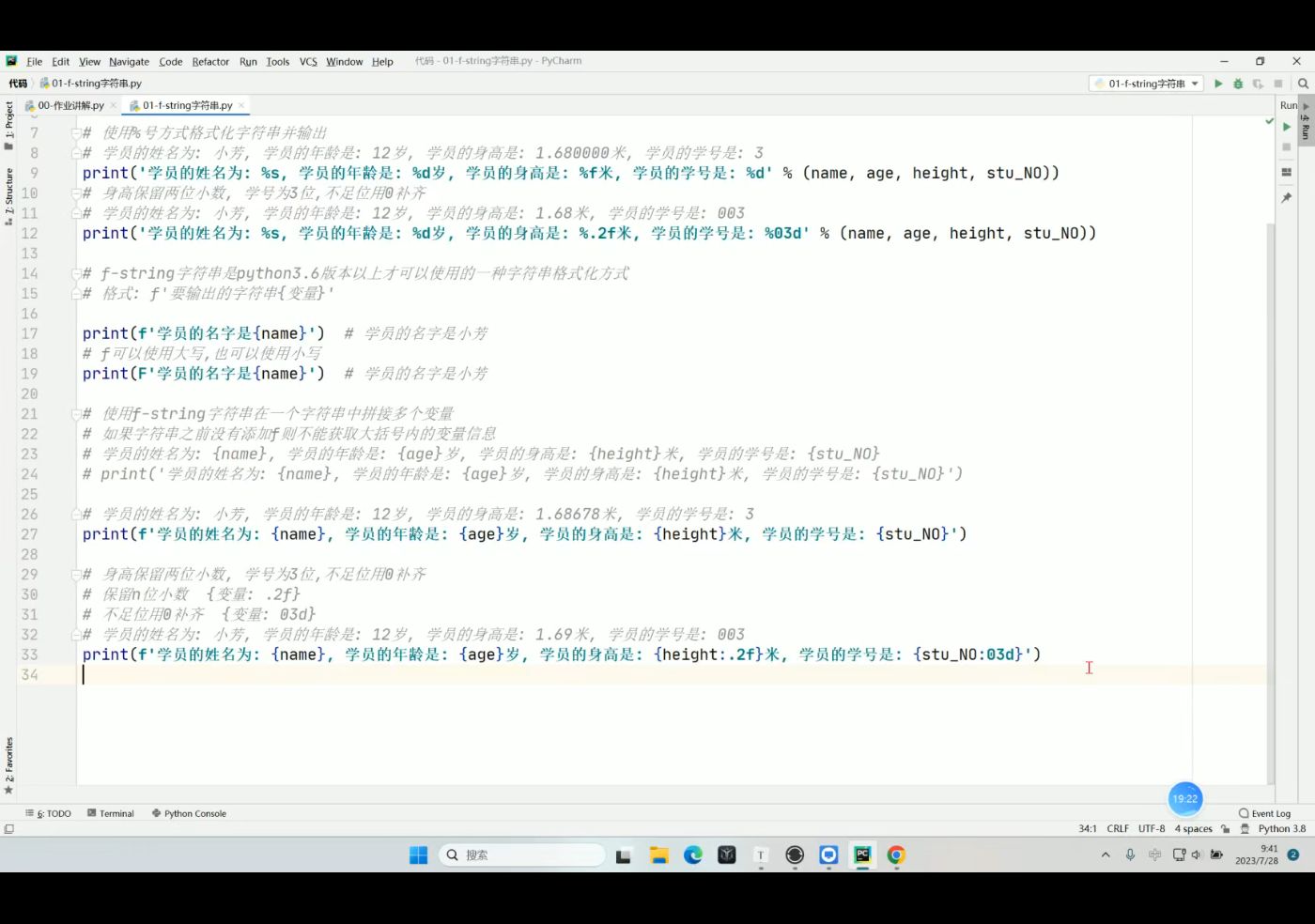
eval()
去除字符串左右两侧的引号,内部是什么就运行什么
str1 = '12'
print(eval(str1)) 12
print(type(eval(str1))) <class 'int'>
str2 = '12.6'
print(eval(str2)) 12.6
print(type(eval(str2))) <class 'float'>
str3 = 'False'
print(eval(str3)) False
print(type(eval(str3))) <class 'bool'>
# 解释: 将下方字符串左右两侧的引号去掉,就是打印hello world的代码,所以使用eval可以打印hello world
eval("print('hello world')") hello world
# NameError: name 'aaa' is not defined
# 将str4两侧的引号去掉,aaa就是一个变量名,但是变量名没有被定义,所以会报错
# 注意:变量必须先定义,再调用
'''
str4 = 'aaa'
print(eval(str4))
print(type(eval(str4)))
'''运算符
算数运算符
/:求商,0不能作为分母存在
//:整除 %:取余
**:幂次运算
先乘除,后加减,如果算数运算符优先级相同,从左至右依次运算
整除和取余运算优先级和乘除相同
幂次运算优先级最高
()改变运算符的优先级
赋值运算符=
将右侧的数据赋值给左侧的变量
# 可以一次给多个变量赋相同的值
a = b = c = 1
print(a, b, c)
# 可以使用逗号分隔,一次性给多个变量赋值,但等号两侧的数量要保持一致
num1, num2 = 1, 2
print(num1, num2)
#变量必须先定义后调用,否则报NameError的错误复合赋值运算符
相当于将算术运算符和赋值运算符进行结合,先运算后赋值
等号左侧必须是已经被定义的变量,右侧是已经被定义的变量或值
比较运算符
比较运算的结果是bool类型
注意
判断大于小于时,需要符号左右两侧的数据类型相同(数值型之间可以随意比较,如int float bool )
# 判断相等或不等时,可以与其他数据类型进行比较
# 但是数据类型不相同,一般值也不相同
print(1 == '1') #False
print(1 == True) #True
print(1 == 1.0) #True字符串数据之间可以进行比较运算符的计算
一般不会使用字符串进行数字逻辑的比较,而一般比较字符串是为了排序
字符串之间比较大小的规则
1.是按照字符的编码序号进行比较的
ascii码:美国信息交换标准码 一共128位,代表128个常用字符,可以满足美国当时正常通讯要求
GBK:国际拓展码 内部包含所有的汉字,可以将二进制转码为中文字符,兼容ascii码
unicode:万国码,包含了全世界大部分国家的语言、符号、表情等,包含unicode8 16 32等,数字越大,包含的字符数量越多,兼容ascii
# 数字<大写字母<小写字母<汉字
print('A' < 'a') # True
print('a' < '静') # True
# 含有多个字符的字符串,则从左到右依次对比,直到比出结果为止,有值的大于没值的
print('19' > '5') # False
print('51' < '53') # True
print('998' < '99a') # True
print('123' > ' 12') # True逻辑运算符
and:两边都为真,结果才是真
or:两边都为假,结果才是假
not:真变假,假变真;真假互换
Python中的三大流程语句
顺序语句
Python代码默认都是顺序执行的,代码永远都是从上到下依次执行的
分支语句
使用if进行构造,在同一条件下,只能有一个分支中的代码被执行
# Python中没有大括号控制分支范围,那么if控制的范围要使用缩进来进行标明
# 在if后的条件末尾务必加上 : ,下一行内容务必缩进(建议缩进一个tab键的位置或者四个空格)
# if控制的所有代码务必对齐
# 取消缩进后,就不在if控制的范围之内了
"""
分支语句格式:
if 条件1:
条件1成立时执行的代码块
elif 条件2:
条件2成立时执行的代码
elif 条件3:
条件3成立时执行的代码
else:
#else是否添加取决于我们上述条件是否将所有的情况覆盖完全,else是可选的
条件不成立时执行的代码块
首先判断条件是否成立,如果成立则执行if控制的代码块,如果不成立则执行else控制的代码块
条件判断语句就是一个结果是bool类型,或者是可以转换为bool类型的数据
"""
age = int(input("请输入小明的年龄:"))
if age >= 22:
print("满足转正的部分条件啦!!!")
else:
print("再沉淀沉淀吧")
print("不敢怎样,明天都要继续")
print('每天都要开心哈')
debug调试
也叫做调试模式或者纠错模式
在debug模式下,代码会暂停到断点行执行之前的状态
在此状态下,我们可以查看代码的执行流程和变量值
分支语句的嵌套
只有外层条件成立时,才能执行内层的分支语句,所以内层分支语句是否执行由外层条件决定
循环语句
使用for或者while构造,条件满足时可以重复执行相同或相似的代码,条件不成立时跳出循环,继续向下执行
import random
#randint函数是一个左闭右闭的区间,下方随机整数范围为1,2,3
print(random.randint(1,3))while循环格式
"""
while 判断条件:
条件成立时,执行的代码1
条件成立时,执行的代码2
注意:不在while控制的缩进范围内的代码不参与循环
"""
i = 0
while i < 100:
print("菜就多练")
i += 1
print("估计练的差不多得了")
# 循环可以提高开发效率,但是不一定会提高执行效率
循环不一定需要循环变量,必要条件:while关键字,循环条件,循环体
循环变量没有时,循环条件一直成立,循环正常执行。这种循环条件恒成立的情况,叫做死循环,也叫做无限循环。
#死循环是程序的一种正常执行状态,不一定是bug
while True:
print("666")可以使用一些非循环变量作为结束条件,比如:时间
print():表示打印一个换行符
print("\n"):实际上打印了两个,print函数本来就有end='\n'
for循环格式
for循环也是循环结构中的一种,一般和容器类型搭配使用
规则:从容器中依次获取每一个元素赋值给临时变量,当数据取完则循环终止
"""
for 临时变量 in 容器类型数据:
循环体
优势:
1.语法简洁,且不易出错(因为不需要循环变量来控制循环跳出条件)
2.从容器中遍历数据不需要构造数据,可以直接取用
"""
str1 = "itheima"
for i in str1:
print(i, end='')
# 容器内有多少个元素,for循环就遍历多少次
for循环搭配range函数使用
range函数就是一个范围函数,内部是根据特定规则生成的整数序列
使用格式:range(起始位置,终止位置,步长),这个函数是左[ ,右) 的
步长可以省略,省略后默认步长为1
起始位置是可以省略的,例如range(10)默认从0开始
步长可以是任意整数,所有参数只能使用整形数据
break:用于终止循环,即执行了break之后,循环就不再继续执行,直接执行下一句代码
break和continue只能控制当前所在循环的循环方式,只能使用在循环体中,否则报错
如果使用循环变量来控制循环跳出,则在执行continue之前,必须进行改变
break和continue只能控制当前所在循环体的循环方式
逻辑
while循环根据循环条件判断循环是否结束,一般用循环变量来控制循环结束条件
for循环是根据容器内的元素个数决定循环是否结束,不需要循环变量
场景
while循环一般构造有特定结束条件的循环或者死循环
for循环一般只对于容器类型遍历使用
在开发中一般情况下for和while可以相互转换,但是for循环使用场景比while要广一些
循环结构中的else
"""
for 临时变量 in 容器类型:
循环体
else:
代码块
当容器类型中的元素遍历完后,执行else中的代码
""""""
while 条件:
循环体
else:
代码块
当循环条件不满足时,执行else中的代码
"""总结
当循环正常结束后,就要执行else中的代码
注意
当循环异常终止时,else中的代码将不会执行
while循环不是因为条件不成立而终止的循环就是异常终止,比如:break
for循环不是因为容器中的元素遍历完而终止的循环就是异常终止,比如:break
break会导致程序异常终止,而continue不会
容器
容器类型就是可以保存多个数据或变量的数据类型
作用
1.减少变量的定义,例如我们保存所有学员的名称,使用容器类型只需要一个变量即可
2.容器类型中的元素可以使用for循环一次遍历获取
3.容器类型有自己的增删改查方法,便于使用
4.容器类型可以提高开发和存储(内存)效率
字符串
定义
在Python中单双引号效力相同,但是要成对出现不能混用
# 定义字符串,可以使用
# 一对单引号
str1 = '字节跳动'
# 一对双引号
str2 = "腾讯"
# 三对单引号
str3 = '''阿里巴巴'''
# 三对双引号
str4 = """美团"""
# 一对引号和三对引号有什么区别?
# 一对引号内部没有换行格式,三对引号内部有换行格式
str5 = '庆历四年春,' \
'滕子京谪守巴陵郡' # \:未完待续符, 代表下一行数据与这一行是同一行内容
print(str5) # 庆历四年春,滕子京谪守巴陵郡. 本质上str5没有进行换行,只是分行显示
str6 = '''吴丝蜀桐张高秋,
空山凝云颓不流.''' # 吴丝蜀桐张高秋,
print(str6) # 空山凝云颓不流.
# 在三对引号内部的数据可以随意换行,打印时换行效果保留
# 三对引号中存放的数据,无需使用\n进行换行,可以直接使用回车,换行效果可以打印出来设计多种字符串定义格式的原因
可以方便字符串的处理以及数据的存储
索引
注意
正数索引从0开始,从左到右依次递增,连续不可跳跃,每个元素对于唯一索引
使用的索引在字符串中不存在会报错
负数下标从-1开始,从右到左依次递减
在字符串中左侧数据的索引一定小于右侧数据的索引
一般使用正数索引,当想要获取末尾数据时,使用负数索引
切片和查找
切片:按照规则获取字符串中一部分元素的方法
切片格式
[起始位置: 结束位置: 步长] 左闭右开
步长:获取数据的间隔(后一个索引减去前一个索引)
"""
字符串下标:
所谓的下标就是指字符串元素的索引(编号),每一个索引(编号)对于唯一的一个元素
所有的下标均为整数且连续,不可跳跃
格式:
字符串变量[索引],根据索引获取字符串中指定位置的元素
"""
#如果负数索引切到末尾,不能使用0;使用也不会报错,就是返回空字符串没有意义
str1='每天都要开心哈'
print(str1[-5:0])
#负数步长最常用的应用场景,将容器进行逆转
str2=str1[::-1]
#最后一个:不能省略,这种写法相当于复制了一个字符串
print(str1[:])
#当步长为负的时候(不能省略步长)切片范围超出索引范围
不会报错
如果切片范围超出,则只保留能够获取的数据
如果切片范围不存在任何数据,则返回空字符串
切片会产生新的字符串,原字符串不会发生改变
查找
find由于不会报错,所以在使用时比index更加安全,但是要注意-1索引也是有值的,要进行判断
# find(self,sub,__start,__end)
# self:先不用理会,不需要我们传值
# sub:要查找的字符或字符串
# __start:查找的起始位置索引
# __end:查找的结束位置索引
# 在字符串中查找元素出现的索引位置并通过索引值获取元素
# 如果查找的是字符串,则返回该字符串首字母在目标字符串中的索引值
str1 = "来不及看故事多跌宕"
#起始位置和终止位置可以省略,省略后默认获取从整个字符串中查找
index1 = str1.find('666') # 此处没有获取到元素,所以返回-1
print(str1[index1]) # 下标-1对应的数据为宕
# 一般开发中要判断获取的索引是否为-1
index2 = str1.find('666')
if index2 != -1:
print(str1[index2])# index(self,sub,__start,__end)
# self:先不用理会,不需要我们传值
# sub:要查找的字符或字符串
# __start:查找的起始位置索引
# __end:查找的结束位置索引
# 在字符串中查找元素出现的索引位置并通过索引值获取元素
# 如果查找的是字符串,则返回该字符串首字母在目标字符串中的索引值
str1 = "来不及看故事多跌宕"
#起始位置和终止位置可以省略,省略后默认获取从整个字符串中查找
#如果使用index,字符串在目标字符串中未出现,则报错
#ValueError: substring not found
index1 = str1.index('666')
print(str1[index1]) 总结
1.find和index都是进行子字符串在目标字符串中从左到右,第一次出现位置的索引查询
2.都可以指定查找的范围,依旧是左闭右开区间
3.find中,如果被查找的字符串不存在,则返回-1
4.index中,如果被查找的字符串不存在,则报错
5.当我们查找的是多个字符的子字符串时,只返回第一个字母的索引
str1 = 'hello Python and Bigdata'
# 任务:查询str1中所有a的出现位置并打印
start_index = 0
while True:
# 指定查询范围
find_index = str1.find('a', start_index)
if find_index != -1:
print(find_index)
# 查到数据之后,将起始位置设置为当前查询位置的下一位,便于查询向后继续查询
start_index = find_index + 1
else:
print('查询任务结束,收工')
break其他函数
replace()
将字符串中指定的子字符串替换为新的内容
# replace(self,__old,__new,__count)
# self:暂时不用理会,不需要我们传值
# __old:旧值
# __new:新值
# __count:替换次数
# 将字符串中的子字符串替换为新字符内容的方法,原始数据不会发生变化,生成新的字符串
str1 = 'hello python and chuanzhi and world'
# 如果没有给count传值,则全部替换
str2 = str1.replace('and', '&&')
print(str2)
# 如果count大于其拥有的最大子字符串数量,则全部替换
str3 = str1.replace('and', '&&', 100)
print(str3)
# 当要替换的字符串在原字符串中不存在时,不会报错,但是也不会发生替换
str4 = str1.replace('zijie', 'tengxun')
print(str4)
# 原字符串始终未发生改变
print(str1)
split()
字符串拆分
# split(self,sep,maxsplit)
# self:不予理会,不需要我们传值
# sep:拆分字符串时依据的分隔符
# maxsplit:最大拆分次数(拆分后,最多将字符串拆分为maxsplit+1份):相当于打算砍几刀
# __count:替换次数
# 根据指定的字符,将字符串拆分为多个子字符串,放置在一个列表中,进行返回
str1 = 'hello world and python'
str_list1 = str1.split(' ')
print(str_list1) # ['hello', 'world', 'and', 'python']
print(type(str_list1)) # <class 'list'>
str2 = 'hello world\tand\npython'
str_list2 = str2.split()
# 当split中什么都没有写时,就是按照空白进行拆分,空白包括(空格,制表符,换行符)
print(str_list2) # ['hello', 'world', 'and', 'python']
str3 = 'apple and banana'
# 按照哪一个字符或字符串进行拆分,则该字符或字符串将会消失
print(str3.split('a')) # ['', 'pple ', 'nd b', 'n', 'n', '']
# 前后都有空字符串
# 设置最大拆分次数为2,此时拆分为3份,并且是从左至右依次筛分
str4 = 'hello world and python'
str_list4 = str4.split(' ', 2)
print(str_list4)
endswith()
判断字符串是否以某个子字符串结尾的方法,返回值是bool类型数据,可以作为判断条件使用
#根据文件拓展名判断该文件是否为txt格式
file_name=input('请输入要查询的文件名称:')
if file_name.endswith('.txt'):
print('该文件为txt格式')
else:
print('格式错误')