本文介绍了一篇发表于数据挖掘顶刊IEEE Transactions on Knowledge and Data Engineering(TKDE)的论文《ST-LLM+: Graph Enhanced Spatio-Temporal Large Language Models for Traffic Prediction》。现有交通预测模型泛化能力有限,而大语言模型在参数扩展和预训练方面具备优势,因此,本文将图结构信息整合到大语言模型中以提升交通预测性能,从而提出了面向交通预测的图增强时空大语言模型ST-LLM+。该模型的核心组件包括时空嵌入与融合层、部分冻结图注意力(PFGA)模块、LoRA 增强训练策略。该模型在 NYCTaxi 和 CHBike 等真实交通数据集上验证了其性能。实验结果显示,ST-LLM+的性能优于文中的对比模型,且在少样本和零样本预测中表现稳健,从而验证了其有效性和泛化能力。此外,文中还对比了其与前期工作 ST-LLM 的改进,并分析了模型的复杂度和效率优势。
论文链接:https://ieeexplore.ieee.org/document/11005661
本推文由韩煦撰写,审核为邓镝。
一、期刊介绍

IEEE Transactions on Knowledge and Data Engineering(简称TKDE)是由IEEE Computer Society出版的一份专注于知识与数据工程领域的学术期刊,每年共出版12期,被归为中科院一区期刊,目前的影响因子为10.4。
期刊官网:https://ieeexplore.ieee.org/xpl/RecentIssue.jsp?punumber=69
二、研究背景
在智能交通系统中,交通预测面临着时空相关性建模不足、任务适配性差不足和计算效率瓶颈等多重挑战,具体表现在如下几方面:
1) 时空相关性建模不足:传统模型如 GNN 和注意力机制虽能捕捉局部时空模式,但难以应对动态变化的交通网络拓扑(如相邻站点的实时影响)和长距离依赖关系(如跨区域交通流的关联);
2) 任务适配性差:大语言模型通过参数扩展和大规模预训练在计算机视觉、自然语言处理等领域表现优异,其处理序列数据的能力使其在时间序列和时空分析中具有潜力,但现有基于 LLM 的交通预测方法多聚焦时间维度,忽视了交通网络中固有的空间依赖;
3) 计算效率瓶颈:全参数微调LLM(如GPT-2)在交通预测中参数量巨大(百万级),训练成本高且易过拟合。
4) 模型泛化能力不足:大部分现有方法在有限的时间序列数据上训练,对于few-shot和zero-shot场景下的预测表现平平,不能充分应对突发事件及外部干扰。
论文的主要贡献如下:
1. 图增强时空大语言模型架构。提出将交通网络的邻近性邻接矩阵作为注意力掩码融入 LLM,突破传统 LLM 仅依赖序列顺序的局限性,显式建模站点间空间依赖。
2. 部分冻结图注意力(PFGA)模块。改进前期 ST-LLM 的部分冻结策略,提出分层冻结 + 图注意力的混合架构:前 F 层冻结以保留语言模型的时序推理能力,最后 U 层解冻并注入图结构,在保持预训练知识的同时适配交通领域特性。
3. LoRA 轻量微调策略。对注意力层引入低秩矩阵分解(LoRA),仅训练少量参数(如3.76%),大幅降低计算开销。
三、研究方法
3.1 方法概述
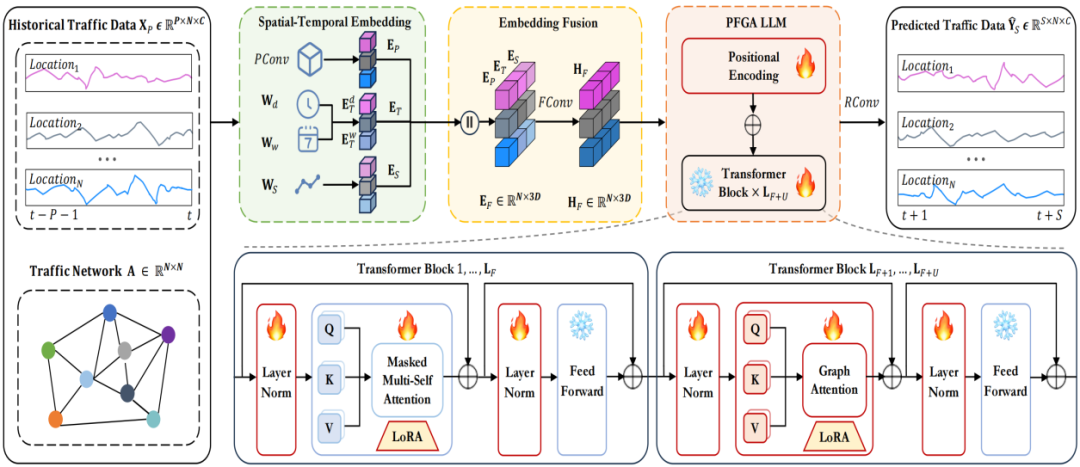
图1 ST-LLM + 框架
图1为ST-LLM + 框架。ST-LLM + 通过时空嵌入对交通数据进行建模。这些嵌入通过嵌入融合层被统一整合。LoRA 增强的部分冻结图注意力(PFGA)大语言模型由 F+U 层组成:前 F 层采用原始的多头注意力机制,而后 U 层则融入基于图的注意力,使用邻接矩阵作为注意力掩码。前 F 层中的多头注意力层和前馈层是冻结的,而后 U 层中的多头注意力层则是解冻的,并通过 LoRA 进行增强。最后,PFGA 大语言模型的输出通过回归层,生成交通预测结果。图2展示了ST-LLM +框架的训练流程。

图2 ST-LLM + 模型的训练流程
3.2 部分冻结的图注意力模块(PFGA)
该部分的核心创新在于引入图结构、图注意力机制、部分冻结策略。LoRA 增强的部分冻结图注意力(PFGA)大语言模型(LLMs)由 F+U 层组成:前 F 层采用原始多头注意力机制,后 U 层融入基于图的注意力并使用邻接矩阵作为注意力掩码。前F层冻结多头注意力和前馈层,以保留 LLMs 在预训练中习得的全局时序依赖捕捉能力,其计算遵循标准的多头注意力机制;后U层则解冻多头注意力,并将交通网络的邻近性邻接矩阵A作为注意力掩码整合到注意力机制中,使模型能聚焦于空间上邻近的节点,专门捕捉局部空间依赖。
3.3 LoRA增强训练策略
图3为LoRA 增强的部分冻结图注意力的处理流程。通过区分前F层(冻结,保留预训练知识)和后U层(解冻,结合 LoRA 微调与图注意力),实现 “全局依赖保留 + 局部空间依赖捕捉” 的双重目标。LoRA 的低秩分解策略在减少计算开销的同时,确保模型能灵活适配交通数据的时空特性,而邻接矩阵的引入则显式建模了站点间的空间关联。

图3 LoRA 增强的部分冻结图注意力的处理流程
四、实验结果
4.1 实验设置
数据集:实验使用了两类数据集,均与交通相关,且每个数据集分别包含“Pick-up”(拾取 / 上车)和 “Drop-off”(放下 / 下车)两种场景的记录。
基线对比
(1)GNN-based 模型
DCRNN:将交通数据建模为有向图,结合扩散卷积与门控循环单元捕捉时空依赖;
STGCN:结合图卷积网络与 1D 卷积处理交通时间序列预测;
GWN:采用带自适应邻接矩阵的图卷积网络;
AGCRN:自适应图卷积循环网络,融合节点学习与交通序列依赖推理;
STSGCN:改进的图卷积网络,通过同步建模和模块化组件捕捉局部时空依赖与异质性;
STG-NCDE:基于图神经控制微分方程的交通预测模型;
DGCRN:动态图卷积循环网络的交通预测框架。
(2)Attention-based 模型
ASTGCN:基于注意力的时空图卷积网络,用于交通预测;
GMAN:采用编码器 - 解码器架构的注意力预测模型;
ASTGNN:基于注意力的模型,学习交通数据的动态性和异质性。
(3)LLM-based 模型
OFA:修改 GPT-2,冻结残差块中的自注意力和前馈网络,对交通数据采用反向视图;
GATGPT:在 GPT-2 骨干网络前(或后)融入图注意力网络;
GPTGAT:将图注意力置于 LLM 骨干网络之后;
GCNGPT:结合图卷积网络与冻结的预训练 Transformer;
LLaMA-2:预训练和微调大语言模型,采用冻结的预训练 Transformer 适配任务;
ST-LLM:作者前期工作,引入时空大语言模型与部分冻结注意力机制。
4.2 与最先进方法的比较
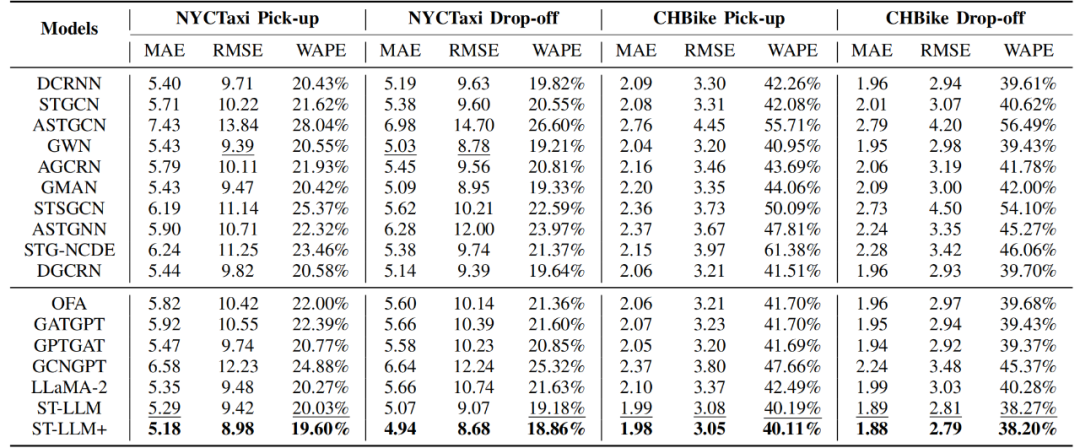
在NYCTaxi 和 CHBike 两个真实交通数据集上,与 GNN-based、Attention-based、LLM-based 三大类基线模型对比预测性能。ST-LLM+在所有评价指标(MAE、RMSE、WAPE)上均取得最佳成绩,验证其有效性。
表1 交通数据集上的模型性能对比
4.3 消融实验
消融实验1:
该实验针对ST-LLM + 的关键组件,通过创建 “w/o ST”(无时空嵌入层)、“w/o Fusion”(无融合卷积层)、“w/o LLMs”(无 LLMs 组件)等变体进行评估。结果显示,移除 LLMs 组件会显著增加误差,表明 LLMs 对学习交通数据的复杂依赖至关重要;移除时空嵌入层也会导致明显性能下降,凸显其在建模时空依赖中的作用;移除融合层影响较小,而完整模型表现最优。具体实验结果见图4。
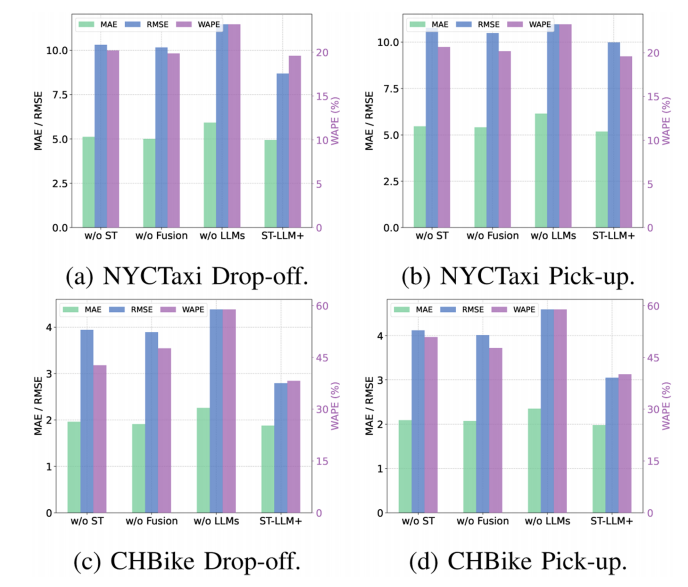
图4 ST-LLM + 关键组件的消融实验
消融实验2:
该实验聚焦于PFGA LLMs,通过 “Full Tuning”(全微调,无冻结层)、“Full Graph-based Attention”(全图注意力,所有层用邻接矩阵)、“Partially Frozen Attention”(部分冻结注意力,无图注意力)等变体评估。实验结果如表2所示,结果表明PFGA 表现最优,全图注意力可能稀释全局依赖,全微调难以充分利用预训练知识,部分冻结注意力虽有竞争力但 PFGA 更优。
表2 部分冻结图注意力大语言模型的消融实验

4.4 零样本与少样本实验
该实验仅用 NYCTaxi 数据训练,直接在 CHBike 数据上测试。零样本实验结果如表3所示。ST-LLM+在未见过的数据集上仍优于其他模型,展示出色的跨域泛化能力。
表3 零样本迁移实验
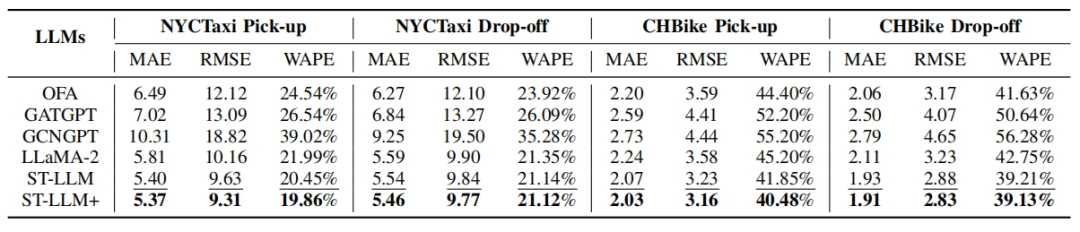
零样本实验仅使用 10% 训练数据进行微调,实验结果如表4所示。ST-LLM+在数据稀缺场景下依然保持高精度,验证其稳健性。
表4 少样本学习实验

五、总结
ST-LLM + 通过时空嵌入和部分冻结图注意力(PFGA)在校准用于交通预测的大型语言模型方面取得了进展。PFGA 使 ST-LLM + 能够有效捕捉复杂的时空依赖关系,从而增强预测效果和适应性。基于 LLM 注意力设计的 LoRA 增强训练策略可实现高效预测。实证研究表明,ST-LLM + 始终优于最先进的交通预测模型和其他基于 LLM 的方法,同时也证明了其在少样本和零样本场景中的鲁棒性。未来,ST-LLM + 可扩展至更多任务,如交通数据插补、生成和异常检测,以构建多功能的交通分析框架。