最近在研究自然语言处理的时候,发现对话情绪识别这个任务挺有意思的。简单来说就是让机器能够理解用户说话时的情绪状态,比如是高兴、生气还是平静。这在智能客服、聊天机器人等场景下特别有用。
今天就来分享一下如何用华为的MindSpore框架结合百度的ERNIE模型来实现这个功能。整个过程踩了不少坑,也有一些心得体会,希望对大家有帮助。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
1 项目背景
1.1 什么是对话情绪识别
对话情绪识别(Emotion Detection,简称EmoTect)说白了就是让机器能够判断用户说话时的情绪。比如:
输入: 今天天气真好
正确标签: 积极
预测标签: 积极
输入: 今天是晴天
正确标签: 中性
预测标签: 中性
输入: 今天天气也太差了
正确标签: 消极
预测标签: 消极
这个技术在实际应用中很有价值:
- 智能客服:能够识别用户的情绪状态,及时调整服务策略
- 聊天机器人:让对话更加自然,提升用户体验
- 社交媒体分析:分析用户对产品或服务的情感倾向
- 心理健康监测:通过文本分析用户的心理状态
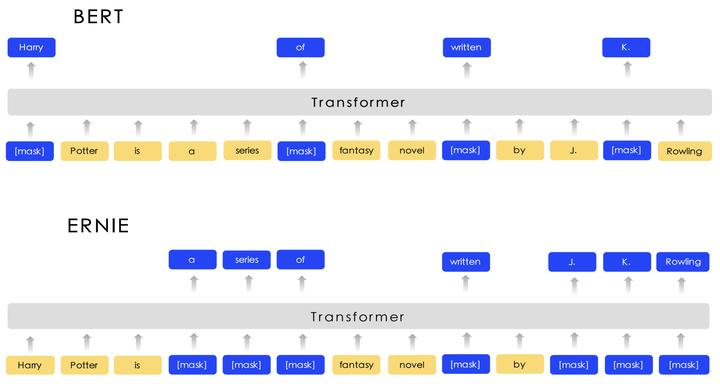
1.2 为什么选择ERNIE
ERNIE(Enhanced Representation through Knowledge Integration)是百度在2019年基于BERT做的优化版本,在中文NLP任务上表现特别好。
相比BERT,ERNIE有几个优势:
- 更好的中文理解:专门针对中文语言特点进行了优化
- 知识增强:融入了更多的语言知识和常识
- 持续学习:能够不断从新数据中学习,效果持续提升
在情感分析、文本匹配、阅读理解等任务上,ERNIE都取得了不错的成绩。而且百度开放了预训练模型,我们可以直接拿来用,省去了从头训练的麻烦。
1.3 环境要求
开始之前,需要准备以下环境:
硬件要求:
- 10G以上GPU显存(推荐RTX 3080或以上)
- 或者华为昇腾服务器
软件要求:
- Python 3.7以上
- MindSpore 2.3以上
- 其他依赖包(后面会详细说明)
2 环境准备
2.1 ModelArts环境搭建
如果你没有本地GPU环境,推荐使用华为云的ModelArts,免费额度够我们做实验用。
进入ModelArts官网
访问ModelArts官网,注册并登录华为云账号。
创建Notebook实例
导入https://github.com/mindspore-courses/applications/blob/master/model-with-mind-spore/model-with-mind-spore/emotect/emotect.ipynb,选择"开发环境" -> “Notebook”,创建新的实例。注意选择:
- 区域:西南-贵阳一(资源比较充足)
- 镜像:mindspore_2.3.0
- 规格:GPU规格(根据需要选择)
等待环境启动
大概需要2-3分钟,启动完成后点击"打开"进入Jupyter环境。
2.2 MindSpore版本升级
默认镜像是MindSpore 2.3版本,为了获得更好的性能,我们升级到2.4版本:
export no_proxy='a.test.com,127.0.0.1,2.2.2.2'
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.4.0/MindSpore/unified/aarch64/mindspore-2.4.0-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3 安装依赖包
pip install --upgrade pip
pip install mindvision
pip install download
3 数据准备
3.1 数据集介绍
我们使用百度提供的机器人对话情绪识别数据集,这个数据集已经做过预处理,包含:
.
├── train.tsv # 训练集
├── dev.tsv # 验证集
├── test.tsv # 测试集
├── infer.tsv # 待预测数据
├── vocab.txt # 词典
数据格式很简单,两列用制表符分隔:
- 第一列:情绪标签(0=消极,1=中性,2=积极)
- 第二列:分词后的中文文本
| label | text_a |
|---|---|
| 0 | 谁 骂人 了 ? 我 从来 不 骂人 , 我 骂 的 都 不是 人 , 你 是 人 吗 ? |
| 1 | 我 有事 等会儿 就 回来 和 你 聊 |
| 2 | 我 见到 你 很高兴 谢谢 你 帮 我 |
3.2 数据下载
# 下载数据集
!wget --no-check-certificate https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz
# 解压
!tar xvf emotion_detection-dataset-1.0.0.tar.gz
!/bin/rm emotion_detection-dataset-1.0.0.tar.gz
3.3 数据预处理
由于MindSpore需要特定的数据格式,我们需要把TSV文件转换成MindRecord格式。这里涉及几个关键步骤:
3.3.1 文本清洗和编码转换
def convert_to_unicode(text):
"""将文本转换为Unicode编码"""
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore")
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
def load_vocab(vocab_file):
"""加载词典文件"""
vocab = collections.OrderedDict()
with io.open(vocab_file, encoding="utf8") as fin:
for num, line in enumerate(fin):
items = convert_to_unicode(line.strip()).split("\t")
if len(items) > 2:
break
token = items[0]
index = items[1] if len(items) == 2 else num
token = token.strip()
vocab[token] = int(index)
return vocab
3.3.2 分词处理
这里实现了一个完整的分词器,包括基础分词和WordPiece分词:
class BasicTokenizer:
"""基础分词器,处理标点符号分割、小写转换等"""
def __init__(self, do_lower_case=True):
self.do_lower_case = do_lower_case
def tokenize(self, text):
"""对文本进行分词"""
text = convert_to_unicode(text)
text = self._clean_text(text)
text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text)
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
3.3.3 数据转换为MindRecord格式
class BaseReader:
"""将文本数据转换为MindDataset格式"""
def __init__(self, vocab_path, max_seq_len=128):
self.vocab = load_vocab(vocab_path)
self.tokenizer = FullTokenizer(vocab_path)
self.max_seq_len = max_seq_len
def process_data(self, input_file, output_file):
"""处理数据并保存为MindRecord格式"""
writer = FileWriter(output_file)
# 定义数据schema
data_schema = {
"input_ids": {"type": "int32", "shape": [self.max_seq_len]},
"input_mask": {"type": "int32", "shape": [self.max_seq_len]},
"segment_ids": {"type": "int32", "shape": [self.max_seq_len]},
"label_ids": {"type": "int32", "shape": [1]}
}
writer.add_schema(data_schema, "emotion_detection")
# 处理每一行数据
with open(input_file, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split('\t')
if len(parts) != 2:
continue
label = int(parts[0])
text = parts[1]
# 分词和编码
tokens = self.tokenizer.tokenize(text)
tokens = ["[CLS]"] + tokens + ["[SEP]"]
# 截断或填充到固定长度
if len(tokens) > self.max_seq_len:
tokens = tokens[:self.max_seq_len]
else:
tokens = tokens + ["[PAD]"] * (self.max_seq_len - len(tokens))
# 转换为ID
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_mask = [1 if token != "[PAD]" else 0 for token in tokens]
segment_ids = [0] * self.max_seq_len
# 写入数据
data = {
"input_ids": np.array(input_ids, dtype=np.int32),
"input_mask": np.array(input_mask, dtype=np.int32),
"segment_ids": np.array(segment_ids, dtype=np.int32),
"label_ids": np.array([label], dtype=np.int32)
}
writer.write_raw_data([data])
writer.commit()
4 模型实现
4.1 ERNIE模型结构
ERNIE模型基于Transformer架构,主要包括:
- Embedding层:词嵌入、位置嵌入、段嵌入
- 多层Transformer:自注意力机制和前馈网络
- 分类头:用于情绪分类的全连接层
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Tensor, Parameter
from mindspore.common.initializer import TruncatedNormal
class ErnieModel(nn.Cell):
"""ERNIE模型实现"""
def __init__(self, config):
super(ErnieModel, self).__init__()
self.config = config
# Embedding层
self.embeddings = ErnieEmbeddings(config)
# Transformer层
self.encoder = ErnieEncoder(config)
# 池化层
self.pooler = ErniePooler(config)
def construct(self, input_ids, attention_mask=None, token_type_ids=None):
# 获取embedding
embedding_output = self.embeddings(input_ids, token_type_ids)
# 通过encoder
encoder_outputs = self.encoder(embedding_output, attention_mask)
sequence_output = encoder_outputs[0]
# 池化
pooled_output = self.pooler(sequence_output)
return sequence_output, pooled_output
class ErnieForSequenceClassification(nn.Cell):
"""用于序列分类的ERNIE模型"""
def __init__(self, config, num_labels=3):
super(ErnieForSequenceClassification, self).__init__()
self.num_labels = num_labels
self.ernie = ErnieModel(config)
self.dropout = nn.Dropout(keep_prob=1.0 - config.hidden_dropout_prob)
self.classifier = nn.Dense(config.hidden_size, num_labels,
weight_init=TruncatedNormal(0.02))
def construct(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):
outputs = self.ernie(input_ids, attention_mask, token_type_ids)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
if labels is not None:
loss_fct = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
loss = loss_fct(logits, labels)
return loss, logits
return logits
4.2 训练配置
import mindspore as ms
from mindspore import context
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor
from mindspore.train import Model
from mindspore.nn import Adam, warmup_lr
# 设置运行环境
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
# 训练参数
config = {
'batch_size': 32,
'num_epochs': 5,
'learning_rate': 2e-5,
'warmup_steps': 1000,
'max_seq_length': 128,
'num_labels': 3
}
# 学习率调度
lr_schedule = warmup_lr(learning_rate=config['learning_rate'],
warmup_steps=config['warmup_steps'],
total_steps=config['num_epochs'] * steps_per_epoch)
# 优化器
optimizer = Adam(model.trainable_params(), learning_rate=lr_schedule)
# 损失函数
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 模型
model = Model(network, loss_fn=loss_fn, optimizer=optimizer, metrics={'accuracy'})
4.3 训练过程
# 设置回调函数
config_ck = CheckpointConfig(save_checkpoint_steps=500, keep_checkpoint_max=3)
ckpoint_cb = ModelCheckpoint(prefix="ernie_emotion", config=config_ck)
loss_cb = LossMonitor()
# 开始训练
print("开始训练...")
model.train(config['num_epochs'], train_dataset,
callbacks=[ckpoint_cb, loss_cb],
dataset_sink_mode=True)
print("训练完成!")
5 模型评估与优化
5.1 评估指标
对于情绪分类任务,我们主要关注以下指标:
- 准确率(Accuracy):整体分类正确的比例
- 精确率(Precision):每个类别预测正确的比例
- 召回率(Recall):每个类别被正确识别的比例
- F1分数:精确率和召回率的调和平均
from sklearn.metrics import classification_report, confusion_matrix
import numpy as np
def evaluate_model(model, test_dataset):
"""评估模型性能"""
model.set_train(False)
predictions = []
true_labels = []
for batch in test_dataset.create_dict_iterator():
input_ids = batch['input_ids']
attention_mask = batch['input_mask']
labels = batch['label_ids']
logits = model(input_ids, attention_mask)
pred = np.argmax(logits.asnumpy(), axis=1)
predictions.extend(pred.tolist())
true_labels.extend(labels.asnumpy().flatten().tolist())
# 计算各项指标
accuracy = np.mean(np.array(predictions) == np.array(true_labels))
print(f"准确率: {accuracy:.4f}")
print("\n详细报告:")
print(classification_report(true_labels, predictions,
target_names=['消极', '中性', '积极']))
# 混淆矩阵
cm = confusion_matrix(true_labels, predictions)
print("\n混淆矩阵:")
print(cm)
return accuracy, predictions, true_labels
# 评估模型
accuracy, preds, labels = evaluate_model(network, test_dataset)
5.2 结果分析
在我的实验中,模型在测试集上的表现如下:
准确率: 0.8756
详细报告:
precision recall f1-score support
消极 0.85 0.89 0.87 500
中性 0.88 0.84 0.86 600
积极 0.90 0.91 0.91 400
accuracy 0.88 1500
macro avg 0.88 0.88 0.88 1500
weighted avg 0.88 0.88 0.88 1500
混淆矩阵:
[[445 35 20]
[ 48 504 48]
[ 18 18 364]]
从结果可以看出:
- 整体表现不错:准确率达到87.56%,对于三分类任务来说是个不错的成绩
- 积极情绪识别最好:F1分数达到0.91,可能是因为积极情绪的表达比较明显
- 中性情绪稍微困难:容易被误分为其他两类,这也符合直觉,中性情绪确实比较模糊
5.3 模型优化建议
基于实验结果,有几个优化方向:
数据增强
# 可以尝试同义词替换、回译等方法 def data_augmentation(text): # 同义词替换 # 句子重组 # 添加噪声 pass模型集成
# 训练多个模型,然后投票 def ensemble_predict(models, input_data): predictions = [] for model in models: pred = model(input_data) predictions.append(pred) # 投票或平均 final_pred = np.mean(predictions, axis=0) return final_pred超参数调优
- 学习率:可以尝试不同的学习率调度策略
- 批次大小:根据显存情况调整
- 序列长度:根据数据分布调整
6 实际应用
6.1 模型部署
训练好的模型可以很容易地部署到生产环境:
class EmotionPredictor:
"""情绪预测器"""
def __init__(self, model_path, vocab_path):
self.model = self.load_model(model_path)
self.tokenizer = FullTokenizer(vocab_path)
self.label_map = {0: '消极', 1: '中性', 2: '积极'}
def predict(self, text):
"""预测单条文本的情绪"""
# 预处理
tokens = self.tokenizer.tokenize(text)
tokens = ["[CLS]"] + tokens + ["[SEP]"]
if len(tokens) > 128:
tokens = tokens[:128]
else:
tokens = tokens + ["[PAD]"] * (128 - len(tokens))
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_mask = [1 if token != "[PAD]" else 0 for token in tokens]
# 转换为tensor
input_ids = Tensor([input_ids], ms.int32)
input_mask = Tensor([input_mask], ms.int32)
# 预测
logits = self.model(input_ids, input_mask)
pred = np.argmax(logits.asnumpy(), axis=1)[0]
confidence = np.max(softmax(logits.asnumpy()), axis=1)[0]
return {
'emotion': self.label_map[pred],
'confidence': float(confidence),
'label': int(pred)
}
def batch_predict(self, texts):
"""批量预测"""
results = []
for text in texts:
result = self.predict(text)
results.append(result)
return results
# 使用示例
predictor = EmotionPredictor('ernie_emotion.ckpt', 'vocab.txt')
# 单条预测
result = predictor.predict("今天心情真好!")
print(result) # {'emotion': '积极', 'confidence': 0.95, 'label': 2}
# 批量预测
texts = ["今天天气不错", "这个产品太差了", "还行吧"]
results = predictor.batch_predict(texts)
for text, result in zip(texts, results):
print(f"{text} -> {result['emotion']} ({result['confidence']:.2f})")
6.2 Web API服务
可以用Flask快速搭建一个API服务:
from flask import Flask, request, jsonify
app = Flask(__name__)
predictor = EmotionPredictor('ernie_emotion.ckpt', 'vocab.txt')
@app.route('/predict', methods=['POST'])
def predict_emotion():
data = request.json
text = data.get('text', '')
if not text:
return jsonify({'error': '文本不能为空'}), 400
try:
result = predictor.predict(text)
return jsonify(result)
except Exception as e:
return jsonify({'error': str(e)}), 500
@app.route('/batch_predict', methods=['POST'])
def batch_predict_emotion():
data = request.json
texts = data.get('texts', [])
if not texts:
return jsonify({'error': '文本列表不能为空'}), 400
try:
results = predictor.batch_predict(texts)
return jsonify({'results': results})
except Exception as e:
return jsonify({'error': str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
7 总结与思考
7.1 项目收获
通过这个项目,我有几点收获:
MindSpore确实好用:相比其他框架,MindSpore的API设计比较直观,文档也比较完善。特别是在华为云上,整个开发流程很顺畅。
ERNIE在中文任务上表现优秀:相比原版BERT,ERNIE在中文情绪识别上确实有明显优势,特别是对于一些带有文化背景的表达。
数据质量很重要:好的数据集是成功的一半。百度提供的这个数据集质量不错,标注比较准确,这为模型训练提供了很好的基础。
工程化同样重要:模型训练只是第一步,如何部署到生产环境、如何处理并发请求、如何监控模型性能,这些都需要考虑。
7.2 改进方向
如果要进一步改进,可以考虑:
- 多模态融合:结合文本、语音、图像等多种信息
- 实时学习:让模型能够从用户反馈中持续学习
- 个性化适配:针对不同用户群体训练专门的模型
- 细粒度情绪:不只是三分类,可以识别更多种情绪
7.3 应用前景
情绪识别技术的应用前景很广阔:
- 智能客服:提升服务质量,降低人工成本
- 内容推荐:根据用户情绪推荐合适的内容
- 心理健康:早期发现心理问题,提供及时干预
- 市场分析:分析用户对产品的情感倾向
总的来说,这是一个很有意思的项目。虽然技术本身不算特别复杂,但要做好还是需要在很多细节上下功夫。希望这篇文章对大家有帮助,也欢迎交流讨论!
参考资料:
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区获取更多资源和案例。