本文翻译自《SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics》,旨在促进相关技术在国内学术界的传播和发展。
摘要
视觉-语言模型(VLMs)通过在大规模多模态数据集上的预训练,蕴含了丰富的视觉和语言知识,是机器人领域的重要基石。与其从零开始训练机器人策略,近年来的研究更倾向于将 VLM 适配为视觉-语言-动作(VLA)模型,以实现基于自然语言的感知与控制。然而,现有 VLA 模型通常规模庞大——动辄数十亿参数——导致训练成本高昂,难以在真实场景中部署;同时,它们多依赖学术或工业级数据集,忽视了来自廉价机器人平台的社区采集数据的日益丰富性。
本研究提出SmolVLA——一个小巧、高效且由社区驱动的VLA模型。该模型在大幅降低训练和推理成本的同时,仍能保持出色的性能表现。SmolVLA 可在单卡 GPU 上完成训练,并能部署于消费级 GPU,甚至 CPU 上。为进一步提升响应速度,我们引入了异步推理架构,将感知和动作预测与动作执行解耦,实现分块动作生成下的更高控制频率。尽管模型规模紧凑,SmolVLA 仍能达到与大型 VLA(参数量是其 10 倍)相媲美的效果。我们在多种仿真与真实机器人基准上对 SmolVLA 进行了评估,并开源了全部代码、预训练模型和训练数据。
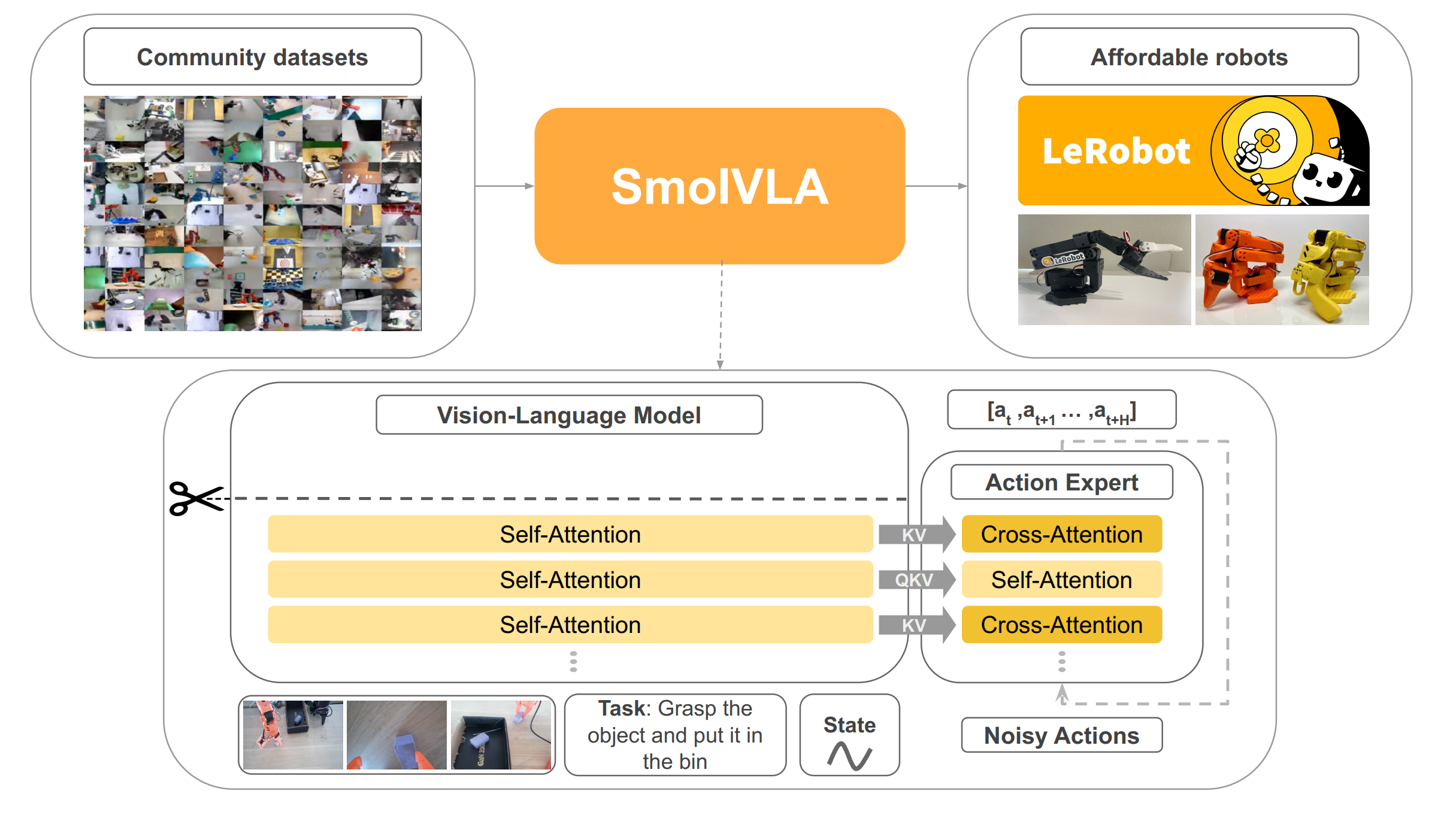
图1 | SmolVLA架构图。SmolVLA基于紧凑的预训练视觉-语言模型构建,通过剪除最后L−N层来减小模型规模(剪刀图标)。保留的层负责处理三类输入:(i) 语言指令,(ii) RGB图像,(iii) 机器人感知和运动状态。这些输入经过token化后,输入到由交叉注意力(金色)和自注意力(浅黄色)交替组成的动作专家模块中。该模块采用flow matching方法训练,输出包含n个低级动作的序列 a t , . . . , a t + n a_t,...,a_{t+n} at,...,at+n。SmolVLA在公开社区数据集上完成预训练,并在低成本机器人上进行评估。
1 引言
近年来,人工智能领域正朝着基础模型(foundation models)的方向发展,这类模型具备处理多种任务的通用能力。大型语言模型(LLMs)就是这一趋势的典型代表,它们在自然语言理解与生成、复杂推理以及知识运用等方面已达到接近人类的水平(Brown等,2020;Achiam等,2023;Dubey等,2024;Team等,2023;Jiang等,2023)。文本模型的成功进一步推动了其他模态的发展,催生了多模态视觉-语言模型(VLMs)(Alayrac等,2022;Chen等,2023;Huang等,2023;Liu等,2023b;Chen等,2024;Shukor等,2023b)和音频-语言模型(ALMs)(Défossez等,2024;Das等,2024;Borsos等,2023)等研究热点。这些多模态基础模型的发展主要得益于两个关键因素:一是采用了Transformer等可扩展架构(Vaswani,2017),二是利用了互联网规模的训练数据集。
尽管基础模型在数字世界取得了令人瞩目的成就,但在现实世界的应用——尤其是机器人领域——仍然面临诸多限制。具体而言,现有机器人策略(Zhao等,2023;Chi等,2024;Lee等,2024;Hansen等,2022)在面对不同物体类型、位置变化、环境差异和任务变换时,泛化能力仍显不足(Xie等,2024;Ebert等,2021)。理想的机器人应当能够适应新环境和新物体,这需要机器人对世界有常识理解能力,其技能具备鲁棒性。然而,这一目标的实现往往受限于高质量多样化数据的稀缺性。
为解决这一瓶颈,越来越多的研究开始探索机器人基础模型,其中视觉-语言-动作(VLA)模型备受关注(Team等,2024;O’Neill等,2024;Brohan等,2023;Kim等,2024;Black等,2024;Bjorck等,2025;Li等,2024;Huang等,2024)。VLA模型旨在整合预训练大型语言和视觉-语言模型中蕴含的抽象推理、世界知识和决策能力。这类模型能够接收多模态输入——包括视觉观测和自然语言指令——并输出相应的机器人动作。初步研究结果显示,VLA模型在泛化能力方面展现出良好前景(Black等,2024;Brohan等,2023)。
然而,VLA模型目前仍处于发展初期,远未达到LLMs和VLMs的成熟度和普及程度。许多具有影响力的VLA研究成果仍属专有技术,研究者往往只公开模型权重,对完整的训练细节和关键方法组件保密。虽然这些模型在学术基准测试中表现出色,但我们认为,要在机器人技术中实现人类水平的能力,必须加强开源合作。具体来说,透明、可重现的开源模型和训练方案对于加速研究进展、促进机器人研究社区的广泛参与至关重要。我们倡导开发更多普通研究者能够使用的经济实用、高效的模型。尽管OpenVLA(Kim等,2024)和RT-2-X(O’Neill等,2024)等项目证明了开源VLA系统的可行性,但这些模型仍然体积庞大、资源消耗巨大,且依赖昂贵的机器人平台,限制了其普及应用。
基于上述考虑,我们推出了SmolVLA——一个开源项目,包含紧凑而强大的VLA模型,以及可重现的高效训练和推理方案。我们的主要贡献包括:
• 轻量级架构设计:SmolVLA是一个紧凑高效的视觉-语言智能体,专门针对消费级GPU训练和CPU部署进行优化。关键设计包括:跳过VLM中的部分层、最小化视觉token数量、采用小型预训练VLMs、以及交替使用自注意力和轻量交叉注意力层。
• 社区数据驱动的预训练:SmolVLA仅使用不到3万个episode进行端到端训练,这些数据完全来自公开的社区贡献数据集。相比现有技术,我们的数据用量减少了一个数量级,却仍能表现出优秀的性能。
• 异步推理机制:我们开发了优化的异步推理架构,将动作执行与观测处理和动作预测解耦,有效降低延迟,实现快速且资源友好的推理过程。
我们在多个仿真环境和真实场景中对SmolVLA进行了全面评估。令人惊喜的是,尽管模型规模显著更小,SmolVLA的性能却能够匹敌甚至超越更大规模的VLA模型。
2 相关工作
视觉-语言模型(VLMs)
VLMs专门用于处理视觉和文本两种模态,通常同时接收图像和文本输入,并在视觉上下文的指导下生成文本输出。VLMs的快速发展很大程度上受益于LLMs的成功经验,许多方法都建立在预训练LLMs的基础上,并采用类似的训练策略。
典型的VLMs构建方式是将预训练的视觉编码器(Radford等,2021;Zhai等,2023;Fini等,2024)与预训练的LLM(AI@Meta,2024;Jiang等,2023;Wang等,2024)相结合(Alayrac等,2022;Laurençon等,2024;Lin等,2023a)。训练过程通常分为多个多模态阶段:首先在图像-文本配对数据集(Schuhmann等,2022;Byeon等,2022)和交错的视觉-语言语料库(Laurençon等,2023;Zhu等,2023)上进行大规模预训练,随后在指令调优数据集上进行监督微调(Liu等,2023b;Tong等,2024;Laurençon等,2024)。
也有研究探索了不依赖预训练视觉编码器的方法(Bavishi等,2023;Shukor等,2025;Diao等,2025,2024),以及开发更统一架构的尝试,这些架构将图像和文本都表示为离散token,使单一模型能够处理多模态token序列(Wang等,2022;Shukor等,2023b;Team,2024;Lin等,2024)。
效率问题已成为VLM研究的核心关注点。相关工作主要通过以下方式降低训练成本:使用更小但更多样化的数据集(Liu等,2023b;Dai等,2023;Bai等,2025;Zhu等,2024;Tong等,2024)、训练更小规模的模型(Marafioti等,2025;Korrapati,2024;Yao等,2024),或者通过参数高效微调方法来适配预训练的单模态模型(Shukor等,2023a;Vallaeys等,2024;Mañas等,2023;Koh等,2023;Tsimpoukellis等,2021;Li等,2023)。虽然大部分VLM研究集中在图像和文本模态,但最近的工作表明,类似技术可以扩展到视频和音频等其他模态(Wang等,2025;Liu等,2024;Zhang等,2025;Kong等,2024)。
视觉-语言-动作模型(VLAs)
机器人研究领域正在兴起一个重要方向:开发通用策略模型。这类模型能够执行广泛的任务,并在不同环境和机器人平台间实现良好泛化。VLAs正是这一方向的重要代表,它们能够处理三类输入:自然语言任务指令、视觉观测(如摄像头图像流)以及本体状态信息,并输出相应的控制动作。
早期研究如Octo(Team等,2024)和RT-1(O’Neill等,2024)采用从零开始的方式,在大规模机器人演示数据集上训练基于Transformer的模型。为了提升性能和泛化能力,RT-2(Brohan等,2023)开始利用预训练的视觉-语言模型,并在机器人特定数据上进行进一步训练。
为促进开放性和可重现性,OpenVLA(Kim等,2024)发布了一个7B参数的VLA模型,该模型在公开数据上训练,用于生成离散动作token。然而,动作token化方法在连续控制任务中存在局限性,因此π₀(Black等,2024)和DexVLA(Wen等,2025)提出使用基于扩散的解码器来生成连续动作。这两项工作都采用了适配预训练VLM(RDT-1B)的方法,引入了大型扩散组件——即"动作专家"——直接在机器人演示数据上进行训练。
最近,Pertsch等(2025)提出了一种完全自回归的方法,使用新颖的动作token化器,虽然改进了传统的分箱方法,但仍受到自回归推理速度慢的限制。为提高VLAs的效率,TinyVLA(Wen等,2024)从零开始训练了一个轻量级的sub-1B模型,先在多模态数据上预训练,再在机器人数据集上微调。不过,由于缺乏大规模机器人数据预训练,其泛化能力受到一定限制。
SmolVLA与上述大多数工作目标相似,都致力于开发和发布在训练和推理方面既高性能又高效的开源模型。
3 SmolVLA:小型、高效且功能强大的VLA
整体设计思路
SmolVLA是一个轻量级的VLA(Vision-Language-Action model),由一个紧凑的预训练VLM(Vision-Language Model)和一个通过Flow Matching训练的动作专家组成。给定多张图像和描述任务的语言指令,该模型会输出一系列动作。它首先通过模仿学习在社区收集的数据集上进行预训练,然后在真实世界和模拟环境中进行评估。预训练数据旨在覆盖多样化的任务和行为,使模型能够学习可泛化的物理技能,这些技能可以在不同场景中进行迁移。在推理阶段,我们引入了异步执行架构,将动作执行与感知预测解耦,从而实现更快、响应更灵敏的控制。
3.1 模型架构
SmolVLA由两个主要组件构成:(i) 负责感知的预训练VLM,以及 (ii) 经过训练用于执行动作的动作专家。两个组件紧密协作:VLM处理状态输入并生成特征来指导动作专家,而动作专家生成的动作又会改变输入给VLM的状态信息。具体来说,VLM负责处理感知和运动状态,包括来自多个RGB摄像头的图像和描述任务的语言指令。VLM输出的特征直接输入到动作专家,由后者生成最终的连续动作序列。
视觉-语言模型(VLM)
我们利用一个预训练的VLM作为感知机器人周围环境的骨干网络。在多样化多模态数据上预训练的VLMs蕴含着丰富的世界知识。为确保效率和可用性,我们采用了SmolVLM-2(Marafioti等,2025),这是一个专门针对多图像和视频输入优化的高效模型。SmolVLM-2使用SigLIP(Zhai等,2023)来为SmolLM2语言解码器(Allal等,2025)编码视觉特征。
在SmolVLA中,VLM组件通过视觉编码器处理图像序列,并采用token-shuffling技术来减少token数量,提升效率。语言指令被转换为文本token,感知和运动状态通过线性层投影为单个token,以匹配语言模型的token维度。最后,视觉、语言和状态token被拼接后输入语言解码器。解码器输出的特征随后用于指导动作专家的工作。
状态、动作和特征投影器
我们在SmolVLA的多个位置使用线性投影层。特别是,我们使用线性投影层来 (i) 投影状态以匹配VLM维度,(ii) 投影动作以匹配动作专家维度,以及 (iii) 调整VLM特征以与动作专家的维度对齐。
视觉token优化
虽然高分辨率图像对VLM性能至关重要,但也会增加推理成本。为了保证效率,SmolVLM-2在训练时使用了图像平铺(image tiling)(Lin等,2023b),这是一种流行的技术,除了全局图像外,还涉及处理同一图像的多个裁剪。然而,为了获得更快的推理时间,SmolVLA不使用平铺。只使用全局图像,并结合像素混洗操作(pixel shuffle operation),将每个帧的视觉token限制为64个。
通过层跳过加速推理
为了提升推理速度,我们在VLM中跳过部分计算。先前研究(Shukor和Cord,2024;Tang等,2023)已经证明,在预训练模型中跳过某些层不会导致显著的性能下降。最近的工作(El-Nouby等,2024;Bolya等,2025;Rajasegaran等,2025)进一步表明,下游任务的最佳特征不一定从VLM的最后一层获得。因此,我们的动作专家可以访问指定层N的所有特征,而不是使用最后一层特征。实际上,我们发现将 N N N设置为总层数的一半( N = L / 2 N = L/2 N=L/2)可以在速度和性能之间提供良好的权衡,有效地将LLM和动作专家的计算成本减半。
Flow Matching动作专家
动作专家 v θ v_\theta vθ负责从VLM特征预测动作序列 A t = ( a t , . . . , a t + n ) A_t = (a_t, ..., a_{t+n}) At=(at,...,at+n)。与之前的工作保持一致,我们的 v θ v_\theta vθ实现基于Transformer架构(Vaswani,2017)。与以往的VLA架构不同,我们交错使用交叉注意力和自注意力层,使用条件Flow Matching Transformer(Esser等,2024;Liu,2022;Lipman等,2022)作为 v θ v_\theta vθ。
动作专家的训练目标定义为:
L τ ( θ ) = E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) [ ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 ] \mathcal{L^\tau}(\theta) = \mathbb{E}_{p(A_t|o_t),q(A_t^\tau|A_t)} \left[\|v_\theta(A_t^\tau, o_t) - u(A_t^\tau|A_t)\|^2\right] Lτ(θ)=Ep(At∣ot),q(Atτ∣At)[∥vθ(Atτ,ot)−u(Atτ∣At)∥2]
其中 o t o_t ot表示从VLM第 N N N层提取的观察特征, A t τ = τ A t + ( 1 − τ ) ϵ A_t^\tau = \tau A_t + (1-\tau)\epsilon Atτ=τAt+(1−τ)ϵ, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)。具体来说, v θ v_\theta vθ被训练为从VLM特征和噪声动作 A t τ A_t^\tau Atτ输出向量场 u ( A t τ ∣ A t ) = ϵ − A t u(A_t^\tau|A_t) = \epsilon - A_t u(Atτ∣At)=ϵ−At。与Black等(2024)的做法一致,我们从Beta分布中采样 τ \tau τ。为提高推理效率,我们将 v θ v_\theta vθ的隐藏维度设置为 0.75 × d 0.75 \times d 0.75×d,其中 d d d是VLM的隐藏维度。
初学者在这个地方可能会感到困扰,后续计划开个单章深度解释Flow Matching动作专家部分。
交错的交叉注意力和因果自注意力层
动作专家 v θ v_θ vθ生成以VLM特征为条件的动作块,SmolVLA中VLM和动作专家之间的交互通过注意力机制实现。与之前仅使用自注意力(SA)(Black等,2024)或交叉注意力(CA)(Bjorck等,2025)的工作不同,我们采用了一种交错方法,其中每个块包含一个CA或一个SA层。这种设计选择也不同于标准VLM架构,其中每个解码器块同时包含SA和CA层(Laurençon等,2023;Alayrac等,2022;Chen等,2022)。
在动作专家的前向传播中,动作和VLM特征通过注意力机制交互,将token投影为查询、键和值(Vaswani,2017)。在我们的设置中,CA层对VLM的键和值进行交叉注意力计算,而SA层允许 v θ v_θ vθ中的动作token相互关注。我们为SA层使用因果注意力掩码,确保每个动作token只能关注序列中的历史token,避免未来信息泄露。实验表明,交替使用CA和SA层能够提供更高的成功率和更快的推理速度。特别是,我们发现自注意力有助于生成更平滑的动作序列 A A A,这在真实机器人评估中表现得尤为明显。
3.2 社区驱动的预训练数据
机器人领域可用于大规模预训练的数据量仍远小于推动视觉和语言领域突破的数据规模。例如,自然语言基础模型能够充分利用独特的基于文本的接口和海量互联网数据,而机器人数据集的整合和扩展却面临重重挑战,主要原因包括:数据集间的差异性以及对人类专家遥操作数据收集的依赖。此外,机器人形态、传感器、驱动方式、控制频率和数据格式的高度异构性造成了"数据孤岛"现象(Bjorck等,2025)——各个机器人数据集相互分离,整合具有挑战性。
在这种背景下,低成本机器人平台和标准化机器人库的出现为缓解数据异构性问题提供了独特机遇,为从业者进入机器人领域降低了门槛。更重要的是,个人从业者贡献的开源数据为整个机器人社区提供了宝贵的社区数据集。这些数据集在多样化的真实环境中收集——从学术实验室到家庭场景——是通过开源方式实现机器人学习去中心化和规模化的重要组成部分。
与遵循标准化协议的学术数据集不同,社区数据集天然具有多样性,涵盖了不同的机器人平台、控制方案、摄像头视角和任务类型。此外,社区数据集通过包含噪声演示、异构环境和多样化物体交互,真实反映了现实世界的复杂性,为预训练提供了宝贵资源。
在本研究中,我们从Hugging Face获取了481个社区数据集的子集,并根据机器人平台类型、episode数量、整体数据质量和帧覆盖率进行了筛选(表1)。
| 数据集数量 | episode数量 | frames数量 |
|---|---|---|
| 481 | 22.9K | 10.6M |
表1 | 社区数据集统计信息。我们的预训练集约包含1000万帧,比其他最先进方法至少小一个数量级。完整的社区数据集列表见附录A.1。
基于VLM的任务标注
使用社区贡献数据集面临的一个挑战是标准化问题。我们发现任务标注中存在大量噪声——即对给定数据集中机器人预期行为的自然语言描述质量参差不齐。许多数据集包含模糊的占位符(如"task desc")、过于模糊的命令(如"Hold"或"Up"),或者完全缺乏指令说明。
为了提升标注质量,我们使用现成的VLM(Qwen2.5-VL-3B-Instruct)自动生成简洁的任务描述。对于每个数据集,我们采样了具有代表性的帧,并将其与原始指令一起提供给模型。模型被要求生成简短、面向动作的句子来概括行为模式。完整的提示内容见附录A.1。
摄像头视角标准化
使用社区数据集的另一个挑战是摄像头命名约定的高度可变性。例如,不同数据集中的"images.laptop"可能指代顶视图、侧视图或腕部安装视图。我们发现这种不一致性对预训练有害,而统一的摄像头排序对这种数据规模下的训练相当有益。
为解决这一标准化挑战,我们手动将每个摄像头映射到标准化视图类型——优先考虑顶视图、腕部视图和侧视图——并将其重命名为OBS_IMAGE_1、OBS_IMAGE_2和OBS_IMAGE_3。对于具有额外视图的数据集,保留了顺序,但在训练期间丢弃了未使用的视图。未来的工作可能会使用VLM自动化此过程,或提出/采用标准化的数据收集指南。
3.3 异步推理机制
现代视觉运动策略(Zhao等,2023;Chi等,2023;Black等,2024)通常输出动作块——即序列 π ( o t ) = A t \pi(o_t) = A_t π(ot)=At,其中 A t = ( a t , a t + 1 , . . . , a t + n ) A_t = (a_t, a_{t+1}, ..., a_{t+n}) At=(at,at+1,...,at+n)是包含 n n n个( n n n远大于1)低级命令的序列,这些命令从环境观察 o t o_t ot开始排队到动作队列中。通常情况下,机器人会执行完整个动作块 A t A_t At,然后将新观察 o t + n o_{t+n} ot+n传递给策略 π \pi π来预测下一个块。这导致在每 n n n个时间步捕获的观察之间出现开环推理。
一些工作(Zhao等,2023;Chi等,2023)采用了不同的策略,机器人控制器交替进行块预测 A t ← π ( o t ) A_t \leftarrow \pi(o_t) At←π(ot)和块消费 a t ← PopFront ( A t ) a_t \leftarrow \text{PopFront}(A_t) at←PopFront(At),在每个时间步 t t t计算新的动作块,并在重叠部分聚合预测的块。虽然这种方法具有自适应性——每个时间步的观察 o t o_t ot都会被处理——但它依赖于连续运行推理,在资源受限的场景(如边缘部署)中可能成本过高。
一种资源消耗较少的方法是在预测新动作块之前完全消耗当前块 A A A,我们称之为同步(sync)推理。同步推理能够在每 n n n个时间步有效分配计算资源,降低控制时的平均计算负担。然而,这种方法限制了机器人系统的响应性,因为机器人在计算 A A A时会出现空闲等待,产生盲目延迟。
针对开环动作导致的机器人系统适应性不足,以及运行时延迟存在的问题,我们通过将动作块预测 A A A与动作执行 a t ← PopFront ( A t ) a_t \leftarrow \text{PopFront}(A_t) at←PopFront(At)解耦,开发了异步(async)推理架构(算法1)。在这个架构中,RobotClient向PolicyServer发送观察 o t o_t ot,推理完成后接收动作块 A t A_t At(图2)。我们通过在控制循环仍在消费先前可用队列时触发新一轮预测,并在新队列可用时将其与现有队列聚合,从而避免执行滞后。反过来,异步推理通过提高观测处理频率,缩短了动作预测与执行之间的闭环。最关键的是,将动作预测与执行解耦后,可将更多计算资源分配到远程策略服务器,再通过网络向机器人客户端下发指令,这在低功耗机器人等资源受限场景中尤为高效。
算法1 异步推理控制循环
1: Input: 时间范围T,块大小n,阈值g ∈ [0, 1]
2: Init: 捕获o₀;向PolicyServer发送o₀;接收A₀ ← π(o₀)
3: for t to T do
4: aₜ ← PopFront(Aₜ)
5: Execute(aₜ) ▷ 在时间步t执行动作
6:
7: if |Aₜ|/n < g then ▷ 队列低于阈值
8: 捕获新观察oₜ₊₁
9: if NeedsProcessing(oₜ₊₁) then ▷ 相似性过滤或触发直接处理
10: async_handle ← AsyncInfer(oₜ₊₁) ▷ 触发新块预测(非阻塞)
11: Ãₜ₊₁ ← π(oₜ₊₁) ▷ 用策略预测新队列
12: Aₜ₊₁ ← f(Aₜ, Ãₜ₊₁) ▷ 聚合重叠部分(如有)
13: end if
14: end if
15: if NotCompleted(async_handle) then
16: Aₜ₊₁ ← Aₜ ▷ 队列无更新(推理尚未完成)
17: end if
18: end for
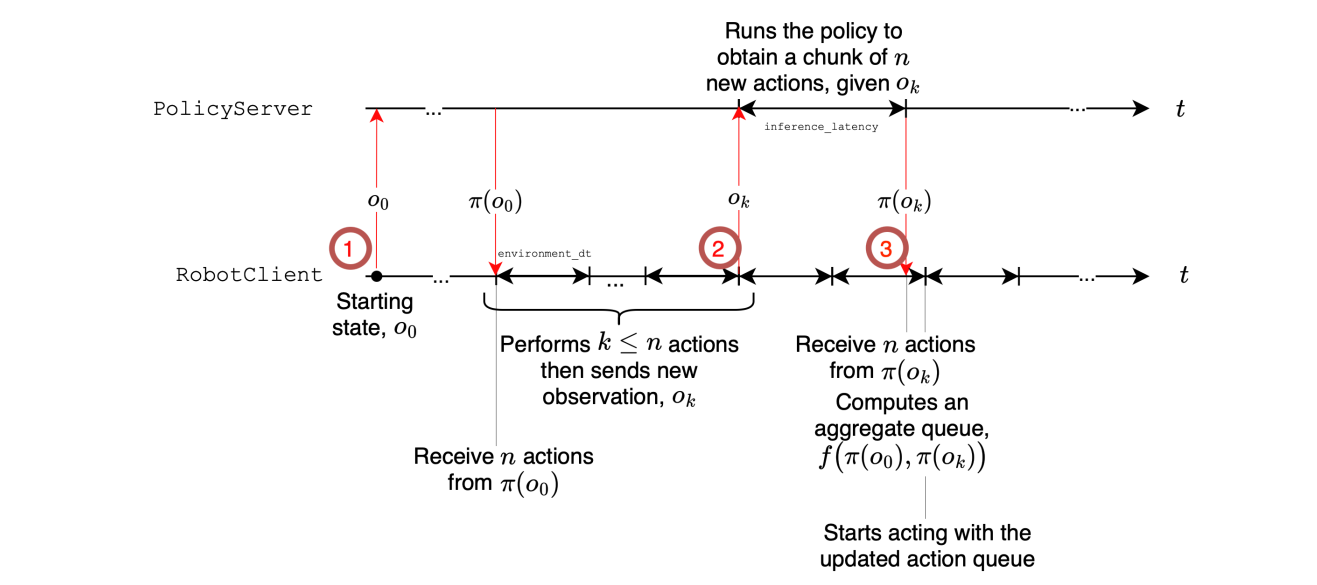
图2 | 异步推理架构图。该图展示了异步推理架构的工作流程。注意策略可以在远程服务器上运行,并可使用GPU加速运行。
实现细节
异步推理通过两种方式提升系统性能:
- (i) 通过更频繁地获取观测来收紧控制闭环,直接消除运行时的空闲间隙;
- (ii) 可以将推理部署到比自主机器人平台上通常可用的计算资源更强大的设备上运行。
从算法角度来看,我们在 RobotClient 端通过以下方式实现 (i):持续从已就绪队列中消费动作,直到队列中剩余动作数量满足阈值条件( ∣ A t ∣ / n < g |A_t|/n < g ∣At∣/n<g)。一旦触发该条件,即刻捕获新的环境观测并将其发送至(可能位于远端的)PolicyServer。为避免多余的服务器调用和运行时的不稳定行为,我们首先在关节空间比较观测,若两次观测在关节空间距离小于预定阈值 ϵ ∈ R + \epsilon \in \mathbb{R}^+ ϵ∈R+,则视为近似重复并予以丢弃。但当 RobotClient 可用队列被耗尽时,无论相似度如何,都必须处理最新的观测。
异步推理的行为可以通过分析来研究。首先,令 ℓ \ell ℓ为发送观测 o o o后接收动作块 A A A所需的随机延迟,其可分解为:
- 从RobotClient到PolicyServer发送观测 o o o的时间 t C → S t_{C \rightarrow S} tC→S
- PolicyServer上的推理延迟 ℓ S \ell_S ℓS
- 从PolicyServer返回动作 A A A至RobotClient的时间 t S → C t_{S \rightarrow C} tS→C
在假设三者相互独立的情况下,有
E [ ℓ ] = E [ t C → S ] + E [ ℓ S ] + E [ t S → C ] \mathbb{E}[\ell] = \mathbb{E}[t_{C \rightarrow S}] + \mathbb{E}[\ell_S] + \mathbb{E}[t_{S \rightarrow C}] E[ℓ]=E[tC→S]+E[ℓS]+E[tS→C]
若进一步假设通信时延双向相同且相较于推理延迟可忽略,则可近似得出
E [ ℓ ] ≃ E [ ℓ S ] \mathbb{E}[\ell] \simeq \mathbb{E}[\ell_S] E[ℓ]≃E[ℓS]
其次,令环境控制周期为 Δ t \Delta t Δt,在 30 FPS 的真实帧率下, Δ t = 33 ms \Delta t = 33\text{ms} Δt=33ms。因此,只要
g ≥ E [ ℓ S ] / ( n ⋅ Δ t ) g \geq \mathbb{E}[\ell_S]/(n \cdot \Delta t) g≥E[ℓS]/(n⋅Δt)
即可避免运行时因队列耗尽而等待新分段的空闲状态。在此,阈值 g g g对 RobotClient 可用动作的保障起着关键作用。
图 3(A) 展示了在三个典型 g g g 值下,动作分段大小 ∣ A t ∣ \lvert A_t\rvert ∣At∣ 随时间的演变,突出以下几种主要情形:
- 顺序极限( g = 0 g=0 g=0):客户端必须消费完上一分段后,才发送新观测。此时在往返推理延迟期间队列会被清空,机器人处于“无动作”状态,平均空闲时长为 E [ ℓ S ] E[\ell_S] E[ℓS]。
- 异步推理( g = 0.7 g=0.7 g=0.7):客户端在队列消耗到约 1 − g = 0.3 1-g=0.3 1−g=0.3 时即触发新一轮推理,利用队列的重叠部分(将上一分段与新分段在重叠时刻的动作合并)来掩盖建模误差,同时避免队列耗尽。
- 计算密集极限( g = 1 g=1 g=1):每个控制周期都发送一次观测,队列几乎始终保持满载,仅因 Δ t / E [ ℓ S ] < 1 \Delta t/E[\ell_S]<1 Δt/E[ℓS]<1 出现轻微锯齿波动。虽然此时响应最快,但在硬件受限场景下,每个周期一次前馈推理的开销可能过高。
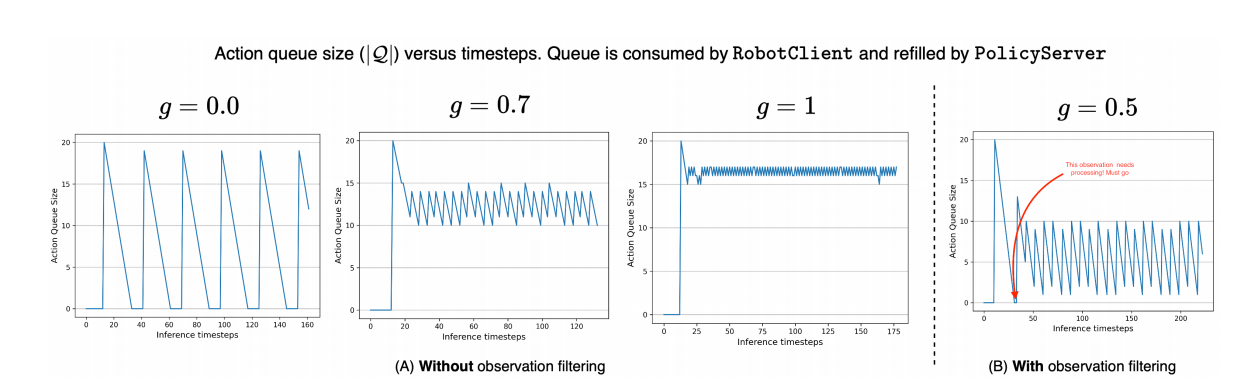
图3 ∣ 在以下两种情况下,不同 g g g 值下运行时动作队列大小的演变:(A)未基于关节空间相似性过滤观测;(B)过滤掉关节空间近重复观测。
如图 3(A) 所示, g g g 决定了空闲期与计算开销之间的权衡。实践中,选取 g ∈ ( 0 , 1 ) g\in(0,1) g∈(0,1) 可在响应速度和资源预算间达到平衡。如果没有相似度过滤器,RobotClient 将以 ( 1 − g ) n ⋅ Δ t (1-g)n\cdot\Delta t (1−g)n⋅Δt 的周期发送观测,并在平均 ( 1 − g ) n ⋅ Δ t + E [ ℓ S ] (1-g)n\cdot\Delta t + E[\ell_S] (1−g)n⋅Δt+E[ℓS] 后接收新分段;而过滤器的引入会拉长该处理周期,避免机器人因队列不断被几乎相同的分段刷新而停滞。图 3(B) 中,除非观测被判定为近似重复,否则新分段会持续填满队列;红色箭头所示时刻即为过滤器被绕过,因队列耗尽而强制处理近似重复观测的情况。
4 实验
4.1 实验设置
我们在仿真和真实世界的机器人操纵任务上对模型进行了评估。
仿真评估
- 在 MetaWorld(Yu 等, 2020)中,我们为 50 个任务各收集 50 条示例演示,构建了新的数据集。
- 在真实世界评估中,我们分别使用 SO‑100 机械臂(Knight 等人)和 SO‑101 机械臂收集了四个数据集,每个数据集对应一个不同的操纵任务。每个数据集包含 5 个不同起始位置下的 10 条演示轨迹,总计 50 条示例。
- 除非另有说明,SmolVLA 均在多任务设置下进行训练。
评估指标
成功率(SR):作为所有基准的主要指标。
- 对于仿真评估,若任务完成则 SR=1,否则 SR=0。
- 对于真实世界评估,我们将每个任务拆分为若干子任务,按精细化评分。例如在“抓取并放置”任务中,成功抓起方块得 0.5 分,正确将其放入目标容器再得 0.5 分。
仿真环境
- LIBERO(Liu 等, 2023a):涵盖空间(Spatial)、物体(Object)、目标(Goal)和长时序(Long)四大类共 40 项任务。我们使用 Kim 等(2024)和 Pertsch 等(2025)提供的包含 1,693 条覆盖所有任务的样本,共 10 次试验,按照二元完成标准计算平均成功率。
- Meta‑World(Yu 等, 2020):包含 50 项难度从易到“非常难”不等的任务(Seo 等, 2023)。我们使用 2,500 条示例(每项任务 50 条),评估协议同 LIBERO:每项任务 10 次试验,仅在完全完成时计作成功。
真实世界任务
- 我们在 Hugging Face 上开源了针对 SO‑100 和 SO‑101 平台的四个真实世界数据集(见图 4),分别用于抓取放置、堆叠和分类任务。
- 其中 SO‑100 上的抓取放置、堆叠与分类能力,以及 SO‑101 上的抓取放置能力均纳入基准测试。重要的是,SmolVLA 并未在任何 SO‑101 数据集上进行预训练。
真实世界任务详情
抓取并放置(Pick-and-Place)
- 目标:将方块抓起并放入固定位置的小箱子。
- 初始条件:方块起始位姿在五种不同条件下变化,箱子位置固定。
- 评分:抓取成功得 0.5 分,放置成功再得 0.5 分。
堆叠(Stacking)
- 目标:将红色方块抓起并堆放到蓝色方块之上。
- 初始条件:两块方块的起始位置在不同试验中变化。
- 评分:抓取上方方块得 0.5 分,正确放置得 0.5 分。
分类(Sorting)
- 目标:根据指令将方块按颜色分类——将红色方块放入右侧箱子,蓝色方块放入左侧箱子。
- 初始条件:方块在五个不同位置间变化;为增加多样性,在颜色配置翻转情况下对每种配置各采集 5 条示例,共 10 条示例/位置。箱子位置保持固定。
- 评分:抓取任一方块得 0.25 分,每完成一次“方块—箱子”匹配再得 0.25 分;四次匹配完成则总得分为 1.0 分。
泛化任务(Generalization)
- 目标:在另一种机器人平台及任务上测试 SmolVLA 的泛化能力。该任务类似“抓取并放置”,但使用更小的乐高砖块代替立方体——指令要求将粉色乐高砖块放入透明盒中。
- 挑战点:小尺寸物体的高精度抓取;透明容器的视觉识别。
- 评分:同“抓取并放置”任务,抓取成功 0.5 分,放置成功 0.5 分。
至此,我们完整描述了仿真与真实世界四类操纵任务的设置与评估指标。

图 4 ∣ 我们用于评估 SmolVLA 的四个真实世界任务示意图,展示了所考虑数据集中每个任务的起始帧与终止帧,分别对应 SO‑100 机型(A)和 SO‑101 机型(B)。对于 SO‑100,我们使用顶视与腕部摄像头;对于 SO‑101,则如图所示采用顶视与侧视摄像头。
4.2 机器人平台
在仿真与真实世界环境中,我们使用了多种机器人平台:
SO‑100 与 SO‑101(Cadene 等,2024)
Standard Open SO‑100 是一款面向机器人及机器人学习研究、低成本且可3D 打印的机械臂。SO‑100 及其升级版 SO‑101 均为开源平台,适用于基础操纵任务。两者均具备六个自由度,采用位置控制的低成本舵机。SO‑101 在臂架设计与电机配置上进行了优化,装配更快捷,运动更平滑,特别适合对精度要求更高的任务。Panda(Haddadin 等,2022)
Franka Emika Panda 是一款七自由度、扭矩控制的机械臂,专为安全、精确的操纵任务而设计。其高分辨率关节传感与柔顺控制使其在仿真与真实世界的学习型操纵任务中表现优异。本研究在 LIBERO 仿真器中采用该机器人。Swayer(Yu 等,2020)
Swayer 为一款四自由度的机械臂,同样面向操纵任务。该平台在 Meta‑World 仿真器中使用,其策略模块直接控制机械臂末端执行器(gripper)的位姿与状态。
4.3 实现细节
我们使用基于 PyTorch 的机器人框架 LeRobot(Cadene 等,2024)进行实验。
预训练阶段
- 迭代 200,000 步,全局批量大小(global batch size)为 256,使用所有公开社区数据集。
- 采用 100 步的 warmup 后,使用余弦学习率调度(cosine schedule),初始学习率为 1 × 1 0 − 4 1\times10^{-4} 1×10−4,衰减至最小值 2.5 × 1 0 − 6 2.5\times10^{-6} 2.5×10−6。
- 优化器选用 AdamW,参数为 β 1 = 0.9 \beta_1=0.9 β1=0.9、 β 2 = 0.95 \beta_2=0.95 β2=0.95。
- 输入图像统一缩放至 512×512,与 VLM 的输入尺寸保持一致。
模型结构
- 视觉语言模型(VLM)骨干使用 SmolVLM‑2(Marafioti 等,2025),保留其中前 16 层大语言模型(LLM),并将其冻结,仅训练动作专家模块。
- 动作专家采用 Flow Matching,输出动作分段长度 n = 50 n=50 n=50。
- 主模型参数总量约 4.5 亿,其中动作专家约占 1 亿。
推理方式
- 真实世界评估:同步推理——仅在执行完整动作分段后才采样新观测。
- 仿真环境:在每次动作执行后即刻采样新观测并预测新动作。推理阶段 Flow Matching 固定为 10 步。
微调阶段
- 仿真基准:微调 100,000 步,批量大小 64。
- 真实世界任务:微调 200,000 步。
- 实践中可显著减少训练步数而不影响性能。
训练优化
- 使用 bfloat16 精度与 PyTorch 的 torch.compile()(Paszke,2019)进行 JIT 编译,加速并生成优化内核。
- 保持固定序列长度与批量大小,超出完整批次的多余帧将被丢弃。
- 多 GPU/多节点训练时,借助 Hugging Face accelerate(Gugger 等,2022)实现混合精度和可扩展、高效的训练流程。
- 虽然预训练时使用 4 块 GPU 以适应大batch size,但由于模型精简,也可以在单 GPU 上完成。
- 整个项目耗费约 3 万 GPU 小时。
4.4 基线方法
我们将 SmolVLA 与 LeRobot 库(Cadene 等,2024)中两种流行且性能强劲的基线模型进行对比:
π₀(Black 等,2024)
π₀ 是一种 VLA,将视觉–语言模型(VLM)与 Flow Matching 结合,用于动作块预测。模型共有 33 亿参数,预训练使用了 10,000 小时的跨平台机器人数据。其架构基于 Paligemma(Beyer 等,2024),输入包括三幅 RGB 图像、传感运动状态和语言指令。ACT(Zhao 等,2023)
ACT 是一种条件变分自编码器(CVAE)策略模型(Sohn 等,2015),采用编码器–解码器 Transformer 架构,参数量约 8,000 万。ACT 使用在 ImageNet 上预训练的 ResNet 视觉编码器,而 CVAE 模块则从头训练。模型输入为 RGB 图像序列和传感运动状态,通过回归目标直接预测连续动作块。
4.5 主要结果
在真实世界与仿真环境中,我们分别评估了 SmolVLA 的表现。真实世界评估中,SmolVLA 在社区数据集上进行预训练,π₀ 在目标数据集上微调,ACT 则从零开始训练。
仿真评估
如表 2 所示,在 LIBERO 与 Meta‑World 两大多任务仿真基准上,SmolVLA 优于其他基于 VLA 的方法(如 Octo Team 等,2024;OpenVLA Kim 等,2024)以及扩散策略基线。我们还与两种 π₀ 变体对比:一种基于视觉–语言模型(Paligemma‑3B)初始化,另一种在机器人数据集上进一步预训练(使用作者发布的权重)。尽管未在机器人数据上预训练,SmolVLA 仍稳定超越 VLM 初始化的 π₀,并与机器人数据预训练的变体表现相当。此外,SmolVLA 训练速度比 π₀ 快约 40%,内存消耗减少约 6 倍。
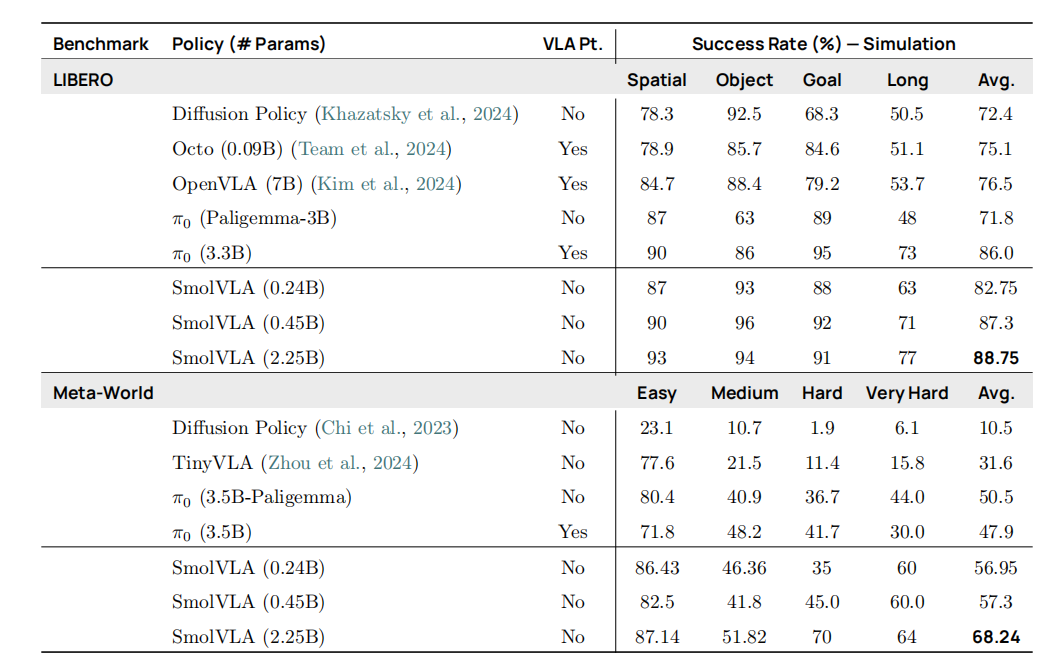 表 2 | 模拟基准测试(LIBERO 与 Meta‑World) 各策略的成功率(%)。LIBERO 任务对应不同设置(如空间、物体、目标、长时序);Meta‑World 任务则反映不同难度等级。 “VLA Pt” 表示在机器人数据上进行预训练;“SmolVLA” 则仅从视觉语言模型(VLM)初始化。基线结果引用自 Kim et al.(2024)和 Wen et al.(2024)。
表 2 | 模拟基准测试(LIBERO 与 Meta‑World) 各策略的成功率(%)。LIBERO 任务对应不同设置(如空间、物体、目标、长时序);Meta‑World 任务则反映不同难度等级。 “VLA Pt” 表示在机器人数据上进行预训练;“SmolVLA” 则仅从视觉语言模型(VLM)初始化。基线结果引用自 Kim et al.(2024)和 Wen et al.(2024)。真实世界评估
在表 3 中,我们评估了 SmolVLA 在四个真实世界任务上的表现。针对 SO‑100 基准,模型在三个数据集的组合上进行训练,并报告了各任务及平均成功率。SmolVLA 的表现超越了分别在各任务上单独训练的 ACT(Zhao 等,2023)和参数量大约为其 7 倍的 π₀。
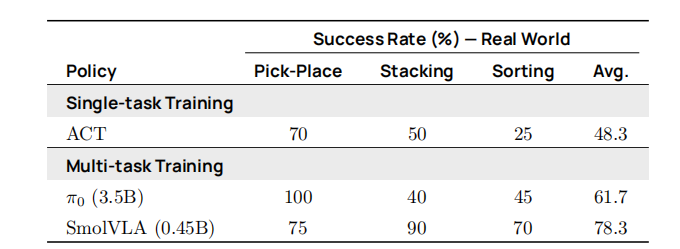
表 3 | 真实场景基准测试(SO100) 在多任务和单任务设置下,所训练策略在三项任务中的成功率(%)。
在 SO‑101 基准(见表 4)中,无论是在同分布(in-distribution)还是分布外(OOD)设置下,SmolVLA 均优于 ACT。对于 OOD 评估,我们将乐高积木放置于训练集中未出现过的新位置。
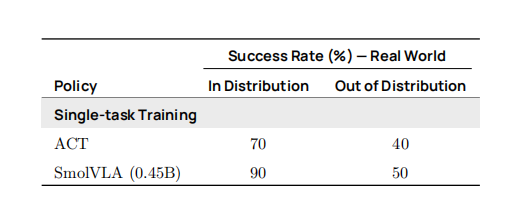 表 4 | 真实场景基准测试(SO101) 使用单任务设置训练的策略在 Pick‑Place‑Lego 任务中的成功率(%)。
表 4 | 真实场景基准测试(SO101) 使用单任务设置训练的策略在 Pick‑Place‑Lego 任务中的成功率(%)。
- 预训练与多任务学习的影响
在表 5 中,我们进一步考察了在社区数据集上预训练对SmolVLA 在真实世界任务中性能的影响,以及多任务微调是否能带来额外收益。结果表明,在社区数据集上预训练使性能显著提升——成功率从 51.7% 提高到78.3%。此外,多任务微调还能带来额外增益,凸显了跨任务知识迁移的重要性。
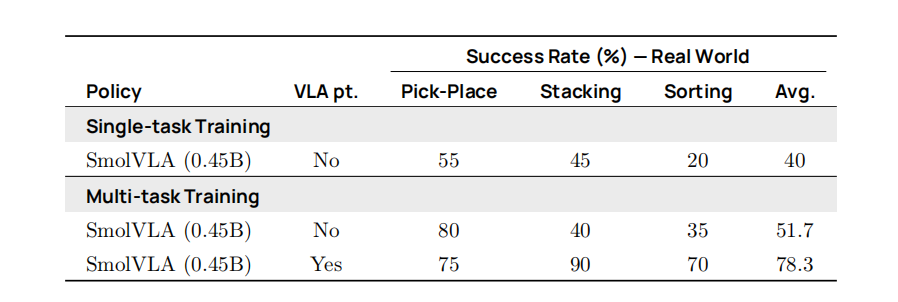
表 5 | 预训练与多任务学习的影响 在 SO100 机器人上,使用 SmolVLA 在多任务与单任务设置下训练的策略在三项任务中的成功率(%)。
4.6 异步推理评估
我们在两种推理模式下评估了 SmolVLA:同步(sync)和异步(async)。同步模式是机器人学中常见的评估设置,即策略预测一段完整的动作序列,待该序列全部执行完毕后才开始下一轮预测。与之相反,异步模式将动作执行与策略推理解耦,使预测与控制能够并行进行。
结果
对于两种推理模式,我们报告了成功率和策略执行速度(见图 5)。为了评估速度,我们设计了两项以 Pick‑Place 任务为载体的实验。第一项实验中,我们在 10 次试验和 5 个不同方块位置下,测量完成任务所需时间;第二项实验中,设定固定时限(例如 60 秒),统计机器人在不同位置成功将方块搬入箱内的次数。计时从机器人开始移动时启动。
如图 5a 所示,两个模式在三项真实场景任务上的成功率相当。但在速度上,异步推理表现出显著优势(图 5b)。平均而言,异步模式完成任务所需时间为 9.7 秒,而同步模式为 13.75 秒,提速约 30%。此外,在固定时限评估下,异步模式可完成 19 个成功的取放循环,同步模式仅完成 9 个(图 5c)。
定性观察
我们发现异步推理能够更迅速地响应并更好地适应环境变化。机器人对目标位置偏移和外界扰动表现出更高的鲁棒性,并且由于避免了预测延迟,总体上能够在相同时间内更多次地成功完成任务(见图 5)。
 图 5 | 同步(Sync)与异步(Async)推理对比。 我们在三项真实场景任务中,分别以两种推理模式评估 SmolVLA。异步推理在固定时间设置下,不仅取得了相近的成功率(左图),而且速度显著更快(中图),并且完成的任务数量更多(右图)。所有超参数已针对 Pick‑Place 任务优化,并在各任务间复用。
图 5 | 同步(Sync)与异步(Async)推理对比。 我们在三项真实场景任务中,分别以两种推理模式评估 SmolVLA。异步推理在固定时间设置下,不仅取得了相近的成功率(左图),而且速度显著更快(中图),并且完成的任务数量更多(右图)。所有超参数已针对 Pick‑Place 任务优化,并在各任务间复用。
4.7 消融研究
我们在 LIBERO 基准上进行了全面的消融实验,以评估最终 SmolVLA 模型的关键设计选择。除非另有说明,所有模型均从头训练,未在机器人数据上进行预训练。VLM 骨干保持冻结,仅对动作专家 v θ v_θ vθ进行训练。
VLM和 v θ v_θ vθ间的注意力机制:交叉注意力(CA)vs自注意力(SA)
我们比较了三种交互方式:仅因果自注意力(SA)、仅交叉注意力(CA)和我们提出的交替 SA+CA。在SA设置中,动作token使用因果掩码相互关注;在CA设置中,VLM特征作为 v θ v_θ vθ中注意力的键和值。如表 6 所示,交叉注意力大幅优于自注意力,而交替使用两者产生最佳结果,凸显其互补优势。
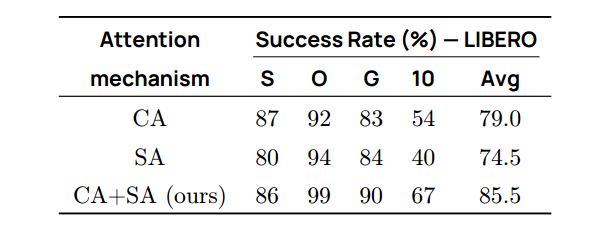
表 6 | 交叉注意力(CA)与自注意力(SA)对比。交错使用 CA 与 SA 可获得最佳效果。
动作专家 v θ v_θ vθ内部动作token的注意力方式:因果vs双向注意力
接下来,我们研究动作专家 v θ v_θ vθ内动作token应如何相互关注。我们比较了:(i) 动作token间无交互(纯CA),(ii) 因果自注意力,(iii) 双向自注意力。表 7 表明,因果自注意力性能最佳,双向自注意力反而降低效果,且纯 CA 设置也表现不俗,说明仅依赖 VLM 特征已具备很强能力。
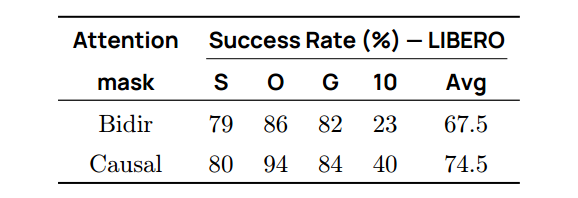
表 7 | 双向注意力与因果注意力对比。 阻止未来动作信息泄露可提升性能。
在VLM中使用早期LLM层
VLM骨干由视觉编码器和LLM组成。为提高SmolVLA效率,我们研究了仅使用前N (N< L)层特征而非所有L个LLM层的可用特征(Black等,2024)。训练开始前,我们丢弃VLM的顶部L − N层。如表8所示,仅用一半 LLM 层在性能与计算成本间取得良好平衡。我们还测试了每隔一层采样的变体(Skip % 2,(Shukor和Cord,2024))——将深度减半同时保留完整模型容量。表8表明每隔一层采样虽优于缩小 VLM,但不及直接截取前 N 层。
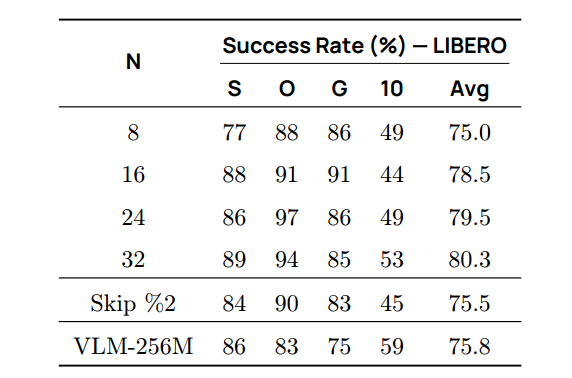
**表 8 | VLM 层跳跃。**从大型 VLM(约 5 亿参数)中跳跃丢弃层比直接缩小 VLM 更有效,每隔一层跳跃是一种有竞争力的基线。
动作专家容量
基于效率考量,我们研究了调整动作专家模型隐藏层维度对模型容量和性能的影响。给定VLM维度 d d d,表9显示将专家模型隐藏层大小减少到 0.75 × d 0.75 × d 0.75×d,能在性能与效率间取得良好平衡。
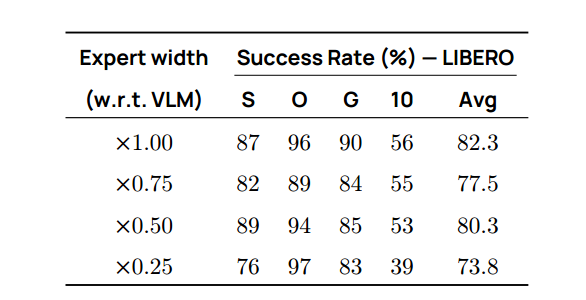
**表 9 | 动作专家容量。**调整专家隐藏层维度会影响性能,更大容量通常带来更高成功率。
训练目标:回归 vs. Flow Matching
我们比较了训练动作专家 v θ v_θ vθ的两种目标函数:flow matching(默认选择)和预测动作块与真实动作块间的标准L1回归损失。表 10 表明,Flow Matching 显著优于回归,说明它对建模复杂多模态动作分布具有更佳归纳偏置,与Black等(2024)、Chi等(2024)的结果一致。
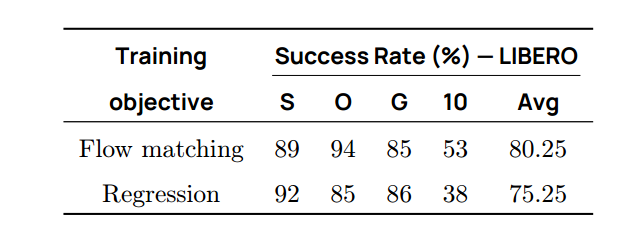
**表 10 | 训练目标对比。**将 Flow Matching 与 L1 回归损失进行比较,Flow Matching 显著优于回归。
状态输入到VLM还是动作专家?
我们对比了将感知-运动状态投影到 VLM 中与直接传递给动作专家两种方案。表 11 显示,将状态信息包含在 VLM 中,无论 CA 还是 SA,均能显著提升性能。
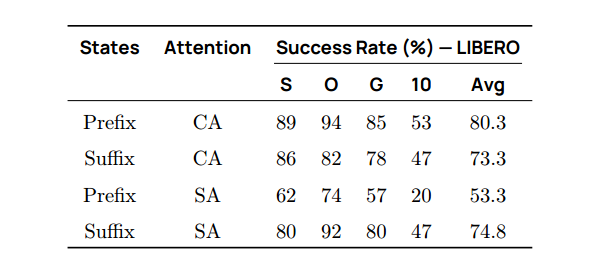
**表 11 | 状态信息作为前缀 vs. 后缀。**将状态信息馈入 VLM(前缀)比馈入专家(后缀)表现更佳。
动作块大小n
我们的模型预测动作块,每个块包含n个时间步。我们研究了改变n对整体性能的影响。更大的n允许机器人在推理时执行更多动作,然后才需要处理新观察并预测下一个块。表 12 表明,过小或过大都会削弱性能;n 在 10–50 之间时,可在机器人反应速度与效率间取得最佳平衡。
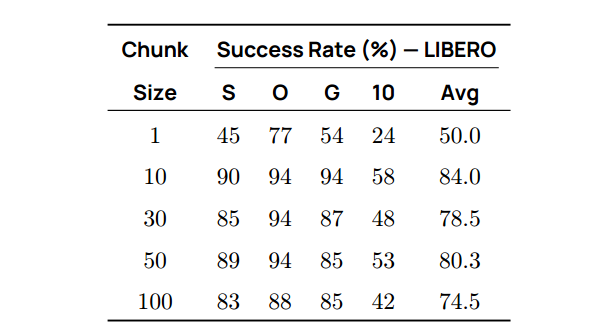
表 12 | 动作分段大小。 分段长度在 10 到 50 之间可在预测频率与性能之间取得良好平衡。
更新观测前执行的动作数量
为提高真实环境推理速度,机器人可在消耗完整个动作块前,执行多步后再获取新观测。虽然一次性执行整个动作块能加速推理,但也会降低机器人对环境变化的响应性。表13表明更频繁地更新观测能显著提高成功率,凸显了推理速度和控制精度间的权衡。
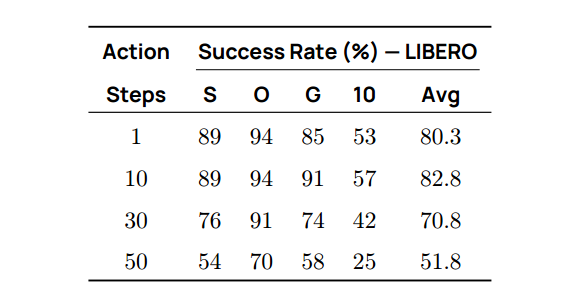
表 13 | 动作执行步数。 更频繁地采样新观测(如每 1 步或 10 步)可显著提升性能。
5 讨论
我们提出了一种紧凑、高效且轻量级的视觉-语言-动作模型——SmolVLA,可在消费级硬件上运行,控制低成本机器人,并与体积大得多的VLA模型相媲美。SmolVLA 的架构在不损失成功率的前提下,兼顾了训练与推理的效率。此外,我们创新性地设计了异步推理栈,提升了现实操作任务中的适应性与响应速度。该推理策略与模型结构无关,可集成于任何输出动作分段的策略中。
我们的研究通过全面的消融与架构分析,为实践者和研究人员提供了改进思路。最后,我们开源了模型、代码库、训练数据集与机器人硬件,并提供了详细的复现指导,以促进完全可重复的实验。
5.1 局限性
我们识别出以下仍需解决的挑战:
• 数据集多样性和跨平台训练:当前预训练仅使用单一机器人(SO100)采集的数据。尽管模型可微调用于不同机器人(表 4),并超越现有基线,但引入多种机器人形态的数据对提升新平台的泛化能力至关重要。
• 数据集规模和可扩展性:用于训练的数据集约含 2.3 万条轨迹,远小于典型 VLA 训练所用规模(如 OpenVLA 约 100 万条)。扩大数据规模可显著提升性能及广泛任务环境的适应性。
• 模型规模和硬件效率:SmolVLA 参数量低于 5 亿,可在消费级硬件上实现快速推理。尽管效率优势明显,如何在不牺牲速度与可及性的前提下进一步扩展架构,仍是未来研究方向。
• VLM骨干的选择:我们采用的 VLM骨干主要在文档阅读与 OCR 任务上预训练(Marafioti et al., 2025),其对真实机器人交互场景的适用性尚不明朗。未来可探索更专业化或替代的预训练策略,以更好地契合机器人环境需求。
• 多模态和机器人数据联合训练:将机器人专用数据与更广泛的多模态数据联合训练,或可提升模型的泛化与指令执行能力,使 VLA 更加健壮且可适应多样场景。
• 任务复杂度与长时序问题:SmolVLA 在相对简单、短时序任务中表现出色,但扩展至更长时序问题仍具挑战。引入分层策略或多级规划机制,或可缓解此类复杂性。
• 学习范式:模仿学习vs强化学习:当前方法主要依赖模仿学习。未来探索适用于 VLA 的强化学习技术(Chen et al., 2025),尤其是在处理复杂或长时序任务时,可能带来更优的性能与灵活性。
主要术语对照
| 英文术语 | 中文翻译 |
|---|---|
| Vision-Language-Action (VLA) | 视觉-语言-动作模型 |
| Flow Matching | Flow Matching(保留英文) |
| Action Expert | 动作专家 |
| Asynchronous inference | 异步推理 |
| Action chunk | 动作块 |
| Cross-attention | 交叉注意力 |
| Self-attention | 自注意力 |
| Embodiment | 机器人平台/实体 |
| Episode | Episode(保留英文) |
| Token | Token(保留英文) |