NSDI 2026 Paper 分布式元数据论文阅读笔记整理
背景
分布式文件系统(DFS)是现代数据中心的重要组成部分。通过在统一的分层目录结构中提供符合POSIX标准的文件接口,DFS实现了对底层存储资源的通用访问,从而简化了存储管理,促进了不同应用程序之间的数据共享[2,35]。
但POSIX接口和DFS的树结构目录组织是一把双刃剑。一方面,POSIX接口因其通用性和便利性,有助于与现有应用程序和框架的集成。另一方面,POSIX接口和分层目录组织不适合分布式环境,导致许多关键用例效率低下。具体来说,树形结构组织需要DFS中的频繁路径解析。在执行任何文件操作之前,DFS客户端必须解析完整路径以定位目标文件的inode,这包括验证路径上每个目录的存在和权限。由于现代DFS通常在多个元数据服务器上分发目录元数据以实现可扩展性,因此路径解析需要在客户端和元数据服务器之间进行多次往返。
客户端元数据缓存一直是DFS中元数据操作的有效方法。客户端维护目录/文件元数据的本地缓存,以避免频繁的远程查找。本文将具有客户端缓存的客户端称为有状态客户端,因为它们在本地维护元数据状态。通过缓存已解析的路径,有状态客户端减少了网络往返次数,以及通过本地缓存的文件操作提高了性能。
问题
路径查询开销
深度学习训练任务中的大型工作集在请求放大导致的性能下降和缓存目录元数据所需的过度客户端内存消耗之间造成了两难境地。
本文发现客户端状态(例如缓存)不仅无效,而且会消耗深度学习管道中宝贵的内存资源。因为DL训练工作负载表现为大规模目录树的多次遍历,其中包含生产环境中的数十亿个目录和数千亿个文件,且随机顺序访问的。
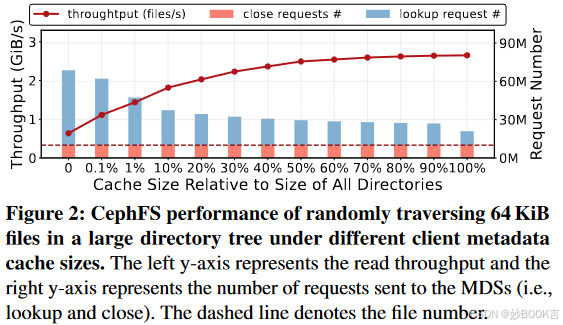
在访问庞大的目录结构时,有状态的客户端架构面临着一个权衡:要么消耗大量的客户端内存来缓存大型目录树,要么由于请求放大而导致性能严重下降。本文评估了元数据缓存大小如何影响大型目录树中随机文件遍历的性能,如图2所示。与存储所有目录的缓存相比,10%的缓存会导致32.5%的吞吐量降低,主要是因为查找请求增加了1.50倍。考虑到大规模目录树和客户端数量,即使缓存10%的目录在生产中也非常昂贵。而且,即使缓存了90%的目录,完成一个打开的文件也需要平均1.70个网络跃点。
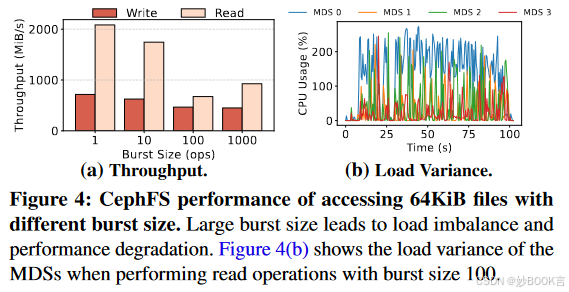
突发IO
对同一目录中的文件进行并发操作会受到MDS拥塞的影响,从而阻碍了性能的可扩展性。
本文工作
主要解决两个关键问题:(1)为了实现对大多数文件操作的单跳访问,客户端需要一种方法来找到存储目标文件索引节点的正确元数据服务器。(2)由于路径解析在服务器端,因此每个元数据服务器都应该能够在本地解析路径,在处理客户端的文件操作请求时不需要额外的网络跳转。
本文提出了FalconFS,具有无状态客户端架构,实现了DL工作负载中大多数文件操作的单跳访问,同时不需要客户端缓存。
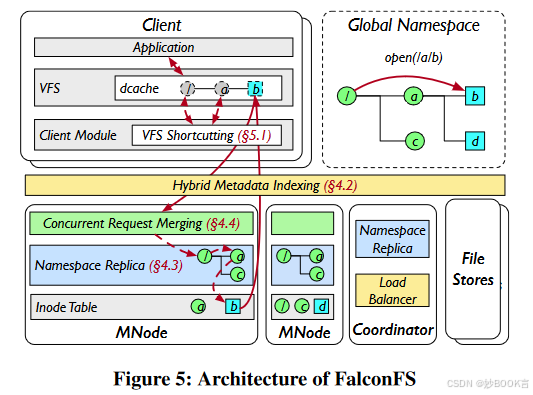
使用混合元数据索引,利用文件名哈希将文件索引节点放置到元数据服务器,同时通过选择性重定向实现负载平衡。
提出了惰性命名空间复制,将文件系统的整个命名空间(即目录树)复制到所有元数据服务器。为了减少维护开销,对命名空间的修改是延迟同步的,并采用基于无效的机制进行并发控制。
通过并发请求合并提高了服务器并发性,并通过VFS快捷方式来保持无状态客户端架构的一致性。
基于CephFS和Lustre的评估表明,FalconFS在小文件读/写方面实现了高达5.72倍的吞吐量,在深度学习模型训练方面实现了12.81倍的吞吐量。FalconFS已在华为拥有10000个NPU的自动驾驶系统的生产环境中运行了一年。
混合元数据索引
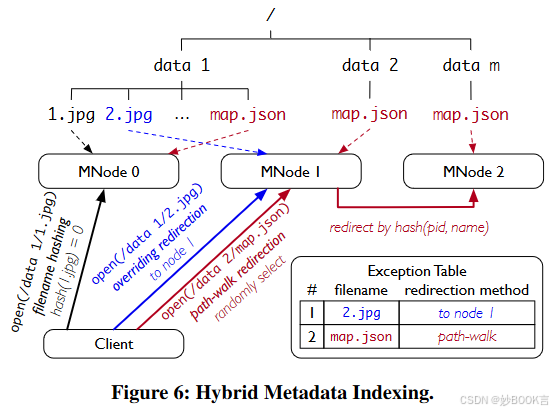
常见情况:文件名哈希。这种索引方法简单高效,不需要客户端状态,并支持高效的重命名。同时由于DL下目录大小较大,整个名称空间在统计上均匀分布,这构成了使用文件名哈希作为DL工作负载中常见情况的索引方法的基础。
在某些情况下,文件名哈希可能会导致文件分布不均。(1)热文件名:某些文件名比其他文件名更频繁。(2)哈希方差:唯一文件名的数量不远超过MNode的数量,这可能会导致分布不平衡。
少部分情况:选择重定向。FalconFS维护了一个共享数据结构——异常表,该表指定了应该重定向哪些文件名以及如何重定向。重定向分别针对热文件名和哈希方差。
路径遍历重定向。为了放置具有热文件名的文件,FalconFS通过文件名和其父目录ID计算哈希值。因此,即使热文件名存在于许多目录中,相应的文件也会放置在不同的MNode上。当客户端在异常表中识别出标记为路径遍历重定向的文件时,它们会向随机的MNode发送请求。接收节点利用其本地命名空间副本来遍历并获取父目录ID,并将请求转发给通过哈希文件名和父目录ID确定的目标节点。
覆盖重定向。当哈希方差导致节点间文件名分布不均时,FalconFS将选定的文件名重新分配给指定节点,将负载从过载节点转移到未充分利用的节点。这些位置覆盖在异常表中维护,在异常表中遇到标记为此类重定向的文件的客户端直接向其指定的MNode发送请求。
负载均衡
每个MNode定期报告其本地inode计数和最常见的O(nlogn)本地文件名及其出现计数,其中n是MNode的数量。
根据统计信息进行负载均衡,若不均衡,则采用两种方法进行重定向。
协调器会定期尝试缩小异常表以减少重定向开销。随机迭代所有路径遍历重定向条目和覆盖重定向条目,如果删除该条目不会导致负载不平衡,则将其删除。
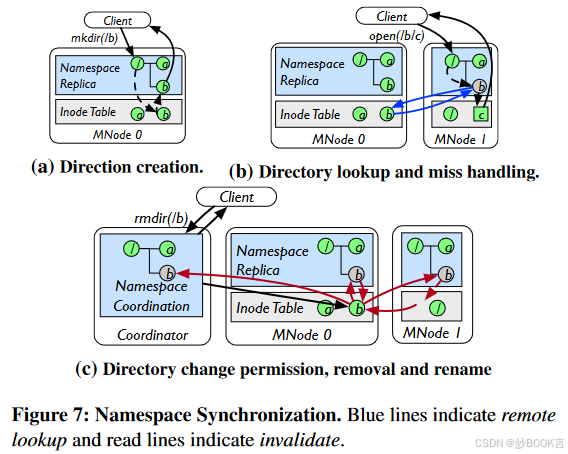
惰性命名空间复制
在每个MNode和协调器上维护一致但不一定完整的命名空间副本,从而实现本地路径解析。为了减少副本之间保持一致性的开销,对命名空间的修改是延迟同步的,并采用了基于无效的机制,设计遵循两个原则:
将同步延迟到访问。目录创建对于DL数据集初始化至关重要,因此性能很重要。在所有MNode上急切地复制目录创建将需要昂贵且不可扩展的两阶段提交(2PC)。因此,FalconFS将同步推迟到访问来分摊开销。
使用失效作为轻量级锁。当操作修改目录结构或权限时,必须阻止修改目录下子树中的并发操作以保持一致性。为此,使所有节点上的相应副本条目无效,而不是使用传统的两阶段锁定,从而节省了一轮请求广播。
并发请求合并
采用并发请求合并来扩大每MNode的吞吐量,以获得更高的元数据性能。每个MNode初始化固定数量的数据库工作线程,作为元数据存储的后端,并准备一个连接池。连接池接受传入的请求,并根据请求类型放入请求队列中。空闲的工作线程检索队列,并在单个数据库事务中执行队列中的所有请求。
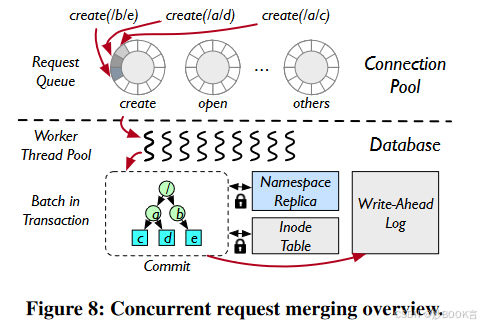
FalconFS通过锁合并来缓解锁开销,以每批粒度组合获取和释放锁以减少开销。由于文件系统命名空间的树形结构,请求可以共享公共的近根路径前缀。随着请求队列累积多个操作,工作器会合并共享路径前缀并消除冗余的锁获取。在图8中,三个创建操作分别遍历两个目录和一个文件。不再单独获取九个锁,而是消除了冗余的锁获取,只获取了六个锁。
实验
实验环境:

对比方法:
CephFS 12.2.13,JuiceFS 1.2.1,Lustre 2.15.6
数据集:
基准测试
对比角度:
元数据吞吐量和可扩展性,元数据延迟,数据IO吞吐量,缓存大小影响,突发IO影响,负载均衡度,消融实验,端到端性能。
总结
针对有状态客户端的问题,内存消耗大、缓存命中率低等问题。本文提出FalconFS,采用无状态客户端架构,包括3个创新点:(1)混合元数据索引,利用文件名哈希定位文件inode,同时结合路径遍历重定向和覆盖重定向实现负载平衡。(2)惰性命名空间复制,将整个目录树复制到所有元数据服务器,并采用基于失效的机制进行更新。(3)并发请求合并,批处理相似元数据请求,减少日志和锁开销,提升并发性。