
本文整理自瓴羊的王璟尧老师与镜舟科技石强老师的联合分享,围绕 Quick BI 在智能 BI 场景中的落地实践,深入探讨了 StarRocks 如何凭借 MPP 架构、实时分析能力与 AI 原生支持,成为智能分析的理想 Lakehouse 引擎底座,助力 BI 从“被动查询”迈向“主动决策”,开启数据“会说话”的新体验。
一、BI 的演进与智能 BI 的崛起
从近十余年 Gartner 魔力象限的变化中,可以清晰观察到商业智能(BI)与数据分析行业的演进趋势。从 2010 年到 2016 年,再到 2024 年,整个 BI 领域大致经历了三个阶段:传统 BI、敏捷 BI,以及智能 BI。
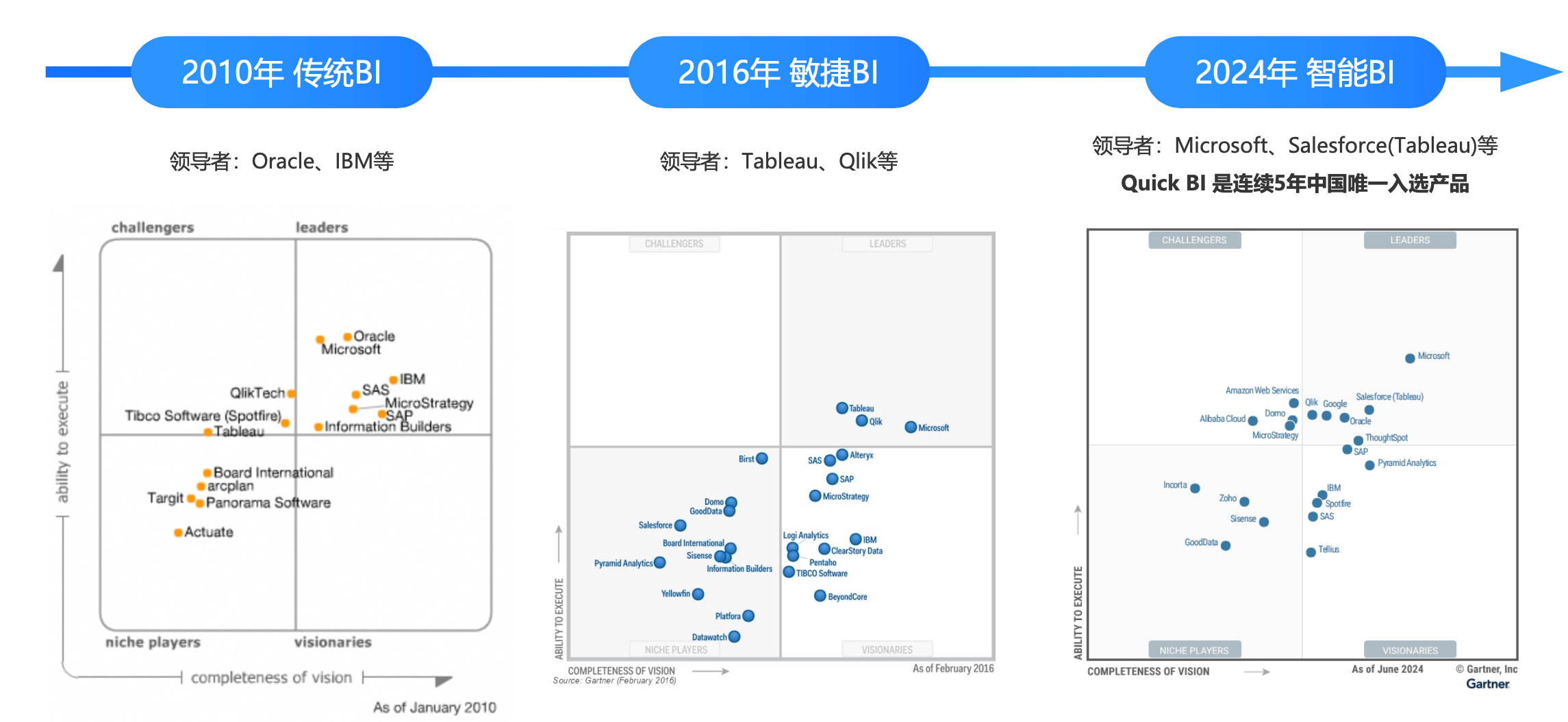
传统 BI 面临的核心问题
传统 BI 多依赖集中式分析,虽然具备数据整合和加工能力,但在满足更高阶的业务需求时存在明显局限。其典型问题包括:
数据孤岛:跨部门、跨系统数据难以打通,缺乏统一接入能力;
口径不一致:数据存储在不同位置且未打通时,同一指标在不同系统中可能出现多种口径,导致分析结果存在偏差。
性能瓶颈:难以支撑大规模计算或高并发查询的需求。
分析流程耗时:报表生成需经历多个步骤(数据位置与口径的确认->数据获取与预处理->SQL 分析过程->可视化输出->洞察生成与判断支持),通常耗时数十分钟;
缺乏业务洞察能力:仅输出静态报表,缺少对业务问题的智能解读与建议。
敏捷 BI 的转变
以 Tableau 等为代表的敏捷 BI 工具引入可视化和自助式分析,通过拖拽操作降低了使用门槛,提升了交互性。尽管部分工具开始引入智能化特性,但整体仍以规则驱动为主,智能水平有限。
智能 BI 的崛起
在传统的数据分析流程中,业务方提出需求后,数据团队往往只是“执行者”,负责生成报表,流程单一、响应周期长,常成为业务推进的瓶颈。即便敏捷 BI 工具提升了可视化和交互体验,仍未真正打通数据团队与业务团队之间的协作壁垒,分析流程依然割裂,难以形成端到端的闭环。
这一局限正在被大模型与分析引擎的技术突破所打破。QuickBI 借助大模型强大的语言理解与生成能力,BI 工具正从“报表工具”演进为“数字化助手”。用户只需用自然语言描述分析意图,系统即可理解上下文、自动拆解任务并高效返回结果,真正实现“人人皆可分析”。
智能 BI 相较于传统 BI,具备三大核心优势:
自动分析能力:基于内置模型,主动识别数据趋势与关键变化;
智能决策建议:结合业务逻辑与上下文,生成可参考的分析结论;
自然语言交互:以 ChatBI 为代表,实现类对话式分析体验。
智能 BI 带来的价值实现
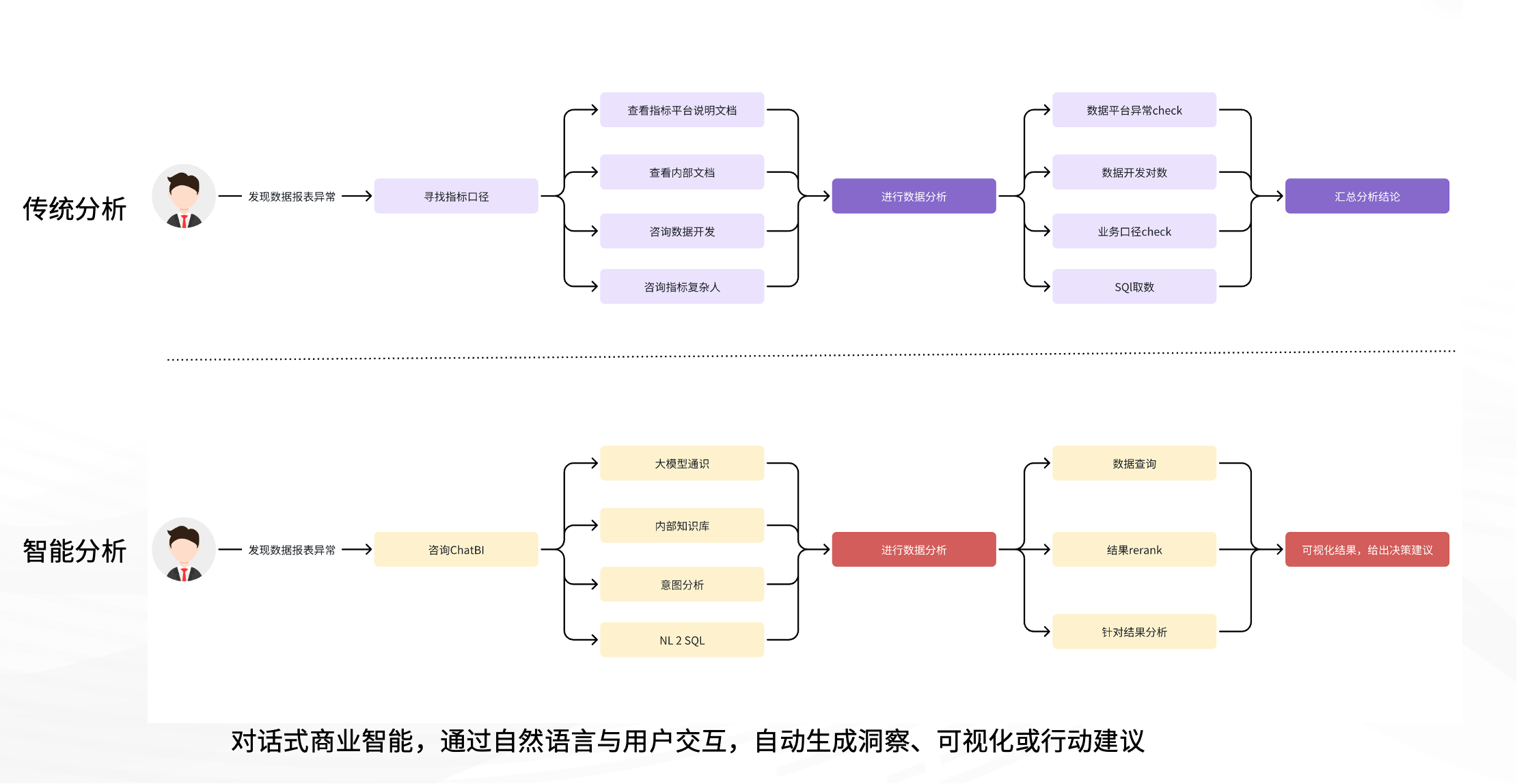
智能 BI 最直观的价值在于简化数据分析流程、降低使用门槛、提升响应效率,并推动分析真正走向洞察与行动。
在传统流程中,分析人员在发现数据异常后,需逐层确认指标定义、数据来源,甚至联系开发人员,排查是否是平台异常、服务中断或口径差异。这一过程依赖大量人工沟通,耗时且易出错。
而在智能 BI 支持下,流程被彻底重构:
业务人员可直接通过自然语言向 ChatBI 提问;
系统自动识别意图,结合知识库判断相关数据表、字段与指标;
利用 NL2SQL 自动生成查询并执行;
返回可视化结果,解释异常原因,提供业务建议,甚至生成可执行方案。
这标志着数据分析从“事实呈现”跃迁至“洞察生成”与“行动建议”。在接入业务 Agent 的场景下,系统还能触发自动操作。
对话式 BI 的核心价值在于:通过自然语言交互,自动完成分析、洞察与建议输出。同时,智能 BI 的落地也对底层系统提出更高要求:必须具备高并发处理能力、实时响应性能,以及对 AI 模型的深度融合能力,如语义理解、逻辑推理和模型对接等 —— 而这正是 StarRocks 所擅长的。
二、智能 BI 的技术实现
大模型重塑 BI 分析流程
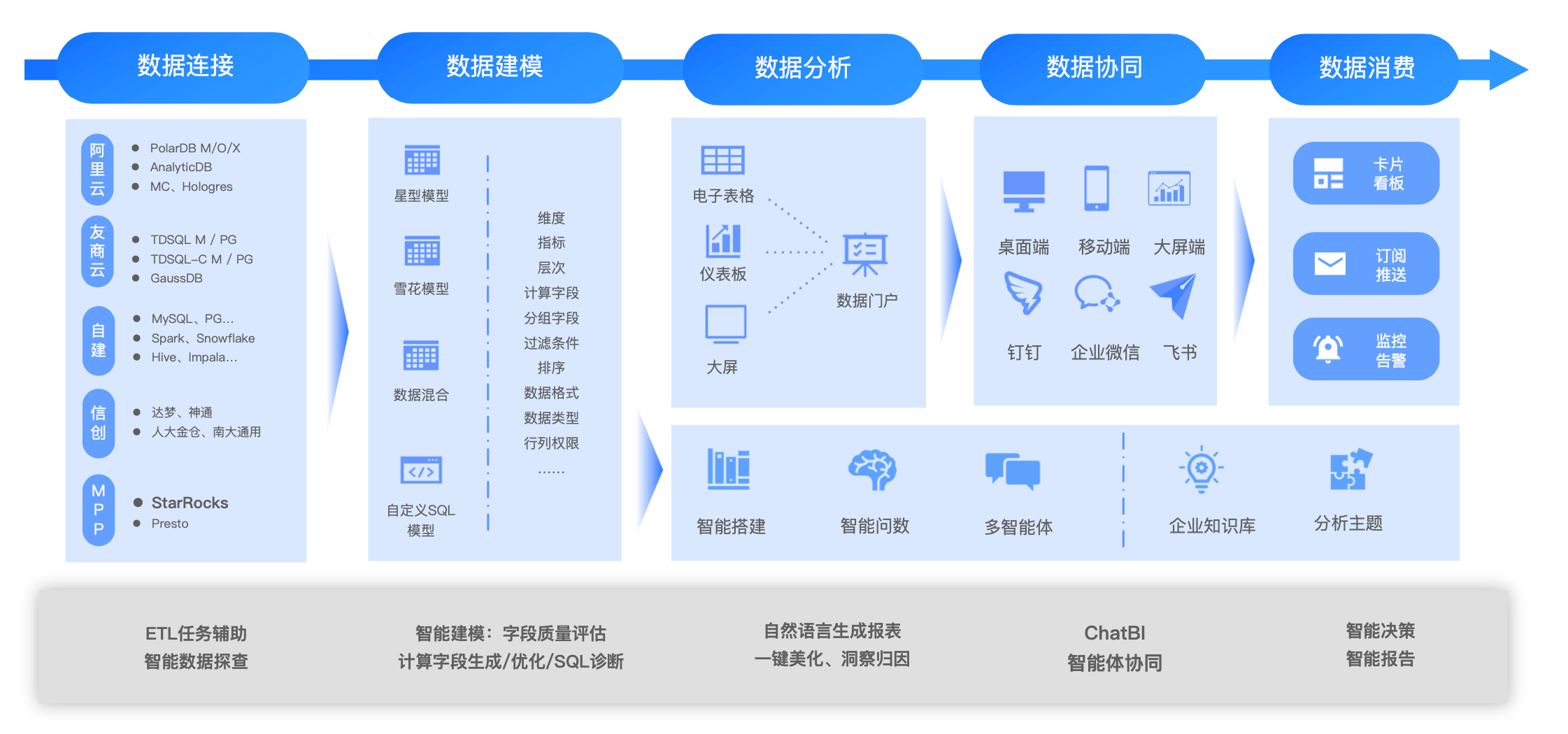
“所有产品都值得用大模型技术重新做一遍”这句话同样适用于 BI。大模型正重塑 QuickBI 的分析流程,为传统的“数据连接—建模—分析—可视化—消费协同”链路注入智能化能力:
数据连接与准备:大模型可辅助完成数据洞察与质量校验。例如,用户可使用 StarRocks 作为数据源,快速识别数据分布与异常,为后续分析提供高效稳定的支持。
数据建模:AI 可自动理解数据语义、构建数据集,显著减少人工配置。
数据分析:借助自然语言交互,实现智能搭建、洞察发现、一键美化与结果生成。
数据消费与协同:通过 ChatBI,用户可对话式完成分析任务,提升数据消费的自然性与流畅性。
BI Copilot 智能搭建(以 Quick BI 为例)
在智能搭建方面,Quick BI 的探索始于以自然语言替代传统拖拽操作,优化分析师的建模与报表流程,聚焦于高频、复杂、依赖经验的典型场景。例如:
“将报表中金额大于某值的项目标红”对应条件格式配置;
“帮我美化一下报表”则结合设计经验,自动完成配色与排版。
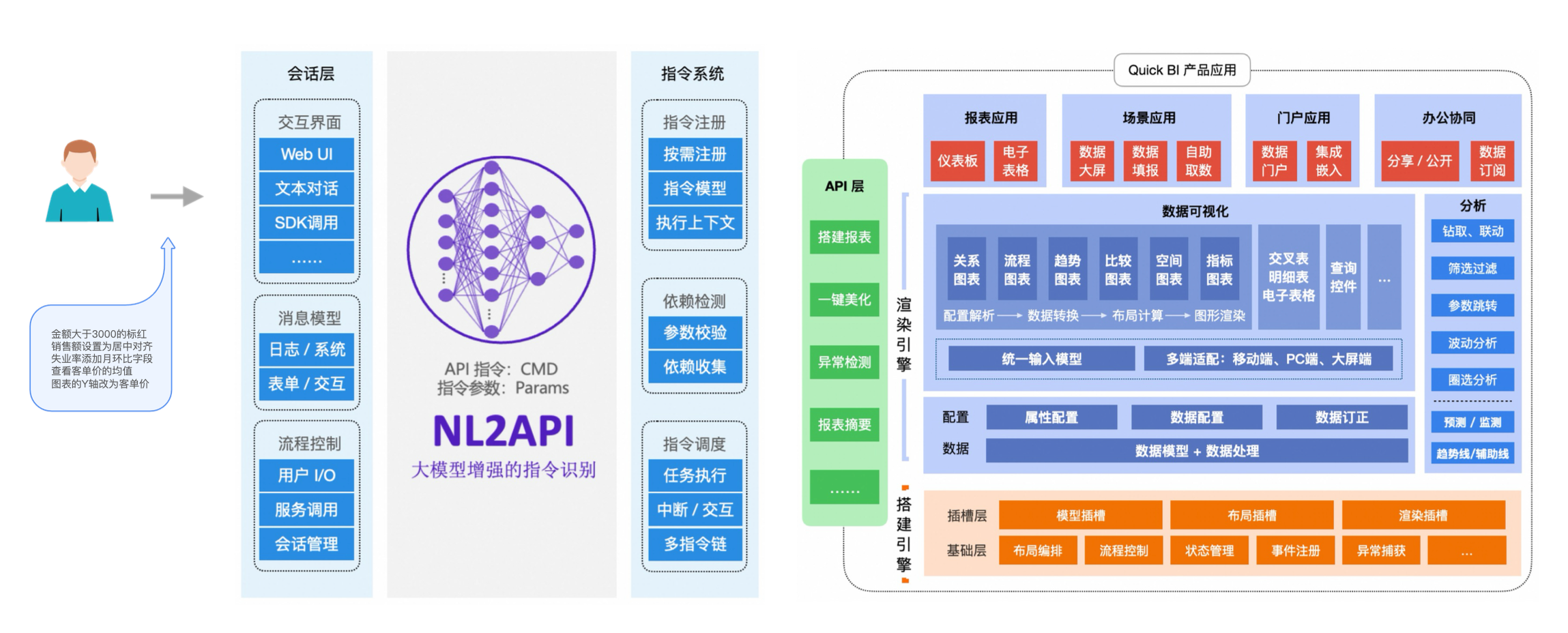
在技术架构上,Quick BI 解耦底层搭建引擎、渲染引擎与会话系统,构建了指令系统与前端 API 层。大模型作为中介,将用户自然语言转化为产品指令,驱动搭建流程。
BI Copilot 数据洞察

户在数据洞察中的核心诉求可分为五个阶段:看懂图表、补充信息、分析解释、定位问题、支持决策。要支撑这一链路,算法、数据与引擎需协同配合——算法需具备精度与泛化能力,数据源需丰富可靠,底层引擎则必须支持高频、多维的实时查询。
当前,Quick BI 的洞察能力聚焦于三方面:
内置洞察算法:结合统计算法与 Agent 技术,基于历史数据、行业经验等识别显著数据与关键波动因子;
大模型驱动的解读:整合报表、数据集与元数据,利用语义理解能力进行深度解读,基于 Prompt 工程和多 Agent 协同机制完成;
第三方 Agent 接入:支持用户根据自身业务逻辑,接入外部 Agent 平台,实现定制化的洞察与响应策略。
这类高频、复杂、多维的分析任务,对底层引擎能力提出极高要求。Quick BI 正是依托 StarRocks 等高性能 MPP 架构查询引擎,才能在数据洞察体验上保持稳定与高效。
三、StarRocks 驱动 BI 分析引擎进化
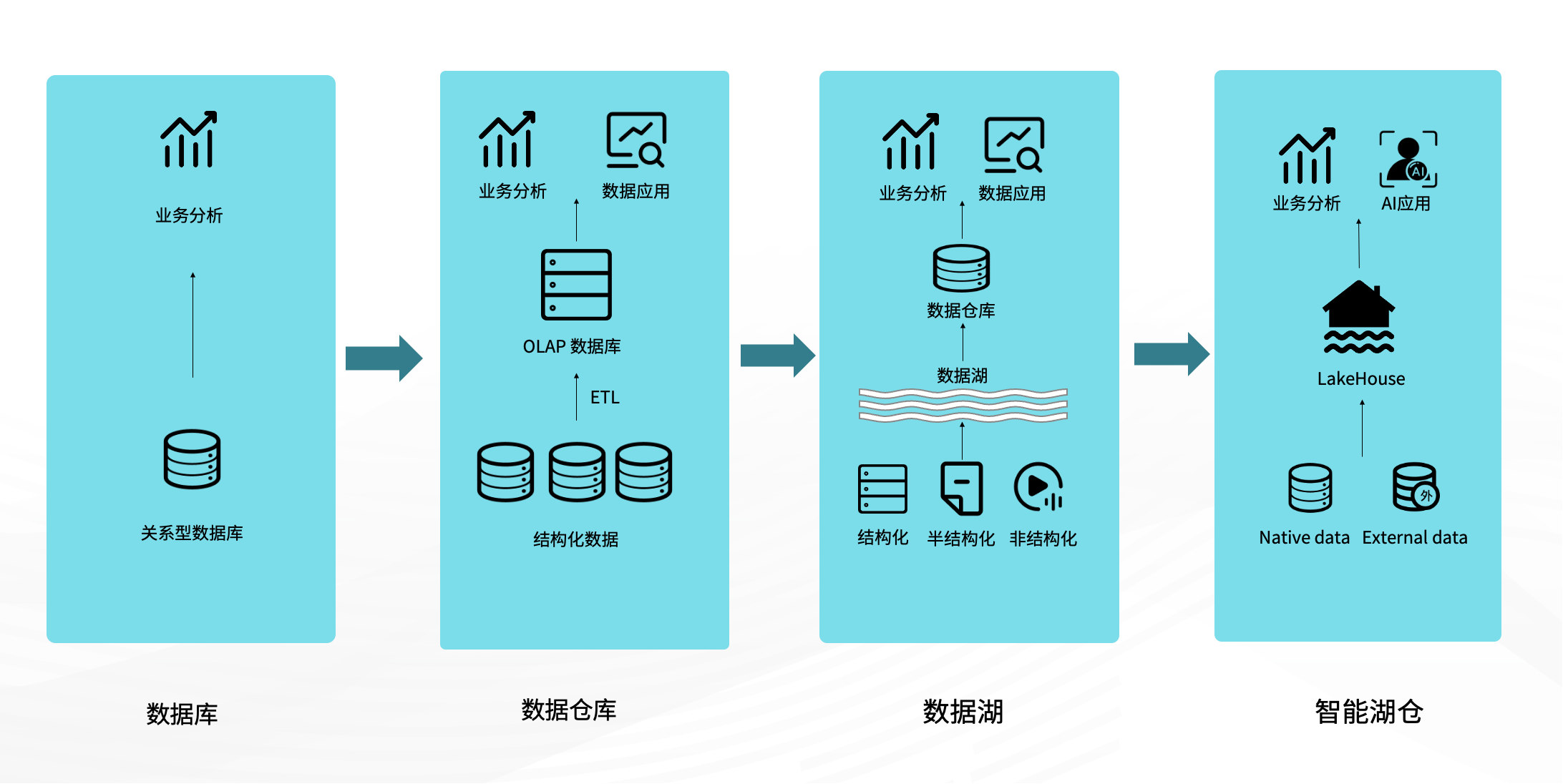
面对大模型时代对实时性、灵活性和智能化的需求,分析引擎经历了四个阶段的演进:
数据库阶段:对应传统 BI 架构,聚焦结构化数据的存储与查询,但扩展性差,难以支撑大规模处理和复杂指标。
数据仓库阶段:增强了建模与分析能力,支持部分自助分析,但多源数据分散、口径不统一等问题依旧突出。
数据湖阶段:自 2018 年起兴起,强调统一存储,实现“Single Source of Truth”。但面对复杂业务需求,仍需借助数据仓库补充建模与查询,形成“湖仓割裂”。
湖仓一体阶段:统一数据架构、降低运维成本,打通数据存储与分析链路,提升数据一致性、时效性和开发效率。
随着 AI 应用的普及,湖仓一体正进一步演化为智能湖仓,在原有统一架构的基础上,原生支持 AI 应用接入,具备更强的实时性、语义理解能力和向量检索能力,成为智能分析的新基石。
为什么 Lakehouse 正在成为智能分析的关键基石?
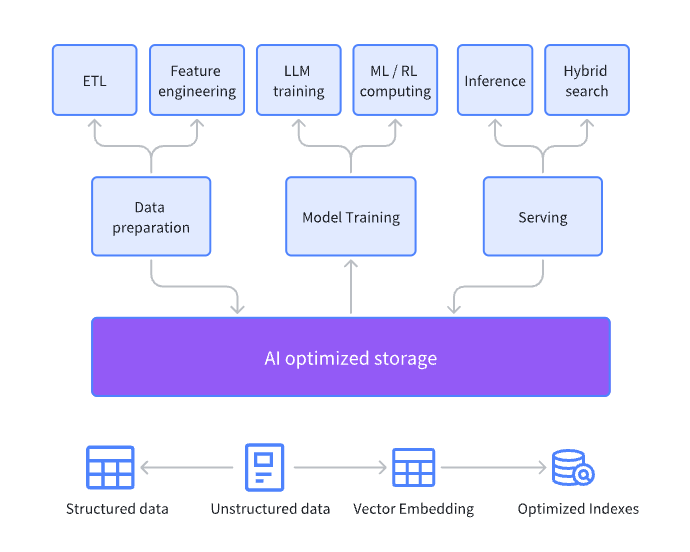
Lakehouse 之所以成为智能分析的核心基座,关键在于其兼具统一存储、高性能查询与 AI 原生支持三大能力,真正打通了从数据准备到模型训练、推理的全流程。
在智能分析场景中,数据通常经历 ETL 与特征工程 → 模型训练(training)→ 推理(inference)→ 服务(serving)等环节,整个链路的读取与存储均依赖 Lakehouse 架构中具备 AI 优化能力的存储层(AI-Optimized Storage)。
其核心价值体现在以下三方面:
统一数据来源(Single Source of Truth):所有数据集中存储,确保训练与推理阶段使用的数据一致,提升模型输出准确性。
多类型数据融合:支持结构化与半结构化数据共存,可生成并存储 embedding,为语义搜索与 RAG 场景提供底层支持。
高性能向量检索:构建 embedding 索引,显著提升语义匹配与相关性检索效率,使知识库调用更及时、精准。
StarRocks,面向智能 BI 的湖仓分析引擎
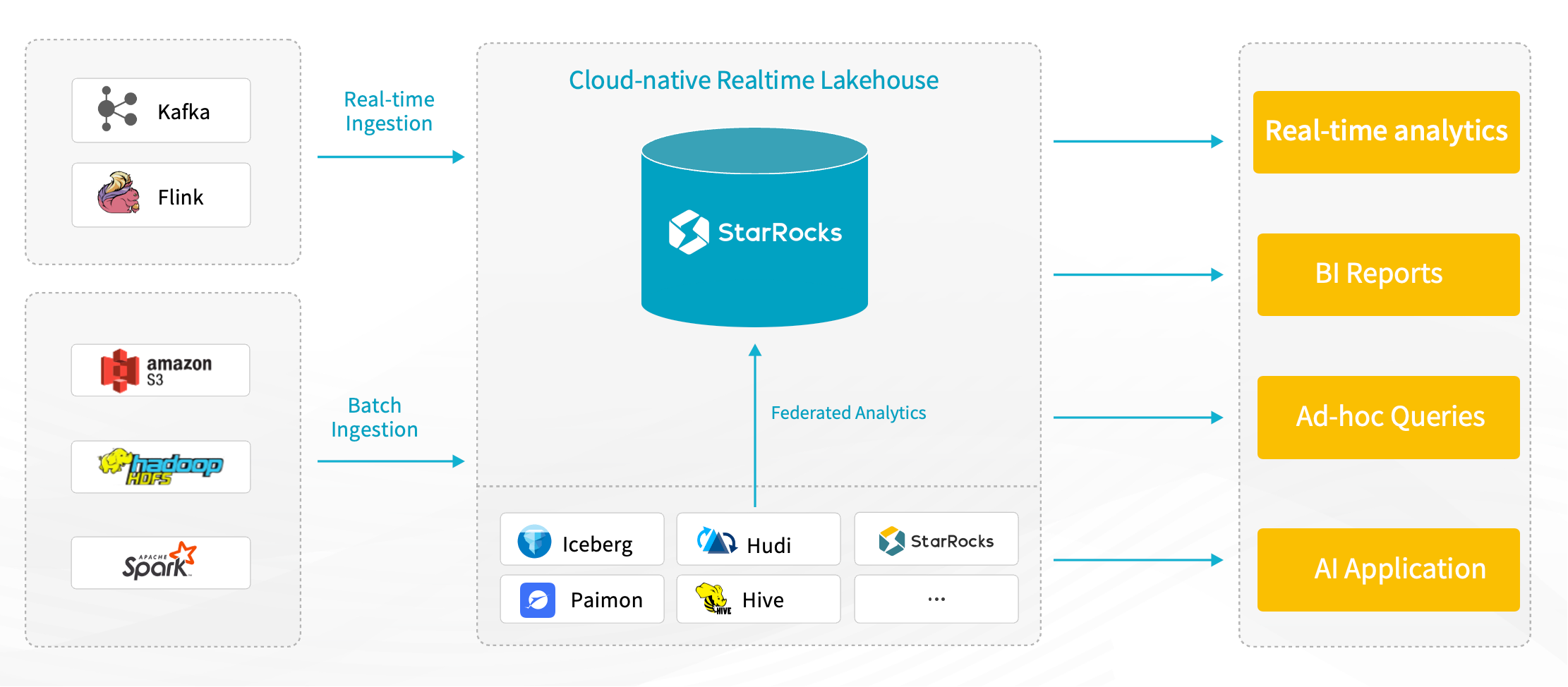
StarRocks 定位为面向智能 BI 场景的 Lakehouse 分析引擎,具备高并发、低延迟、灵活访问与智能协同等能力,适配实时、批量与多湖数据的统一分析需求。
其核心能力包括:
多模式数据接入:支持通过 Flink、Kafka 等导入实时流式数据,也支持批量写入;兼容现有数据湖架构,可通过 Catalog 无缝访问 Iceberg、Paimon 等外部湖表数据,无需迁移。
联邦分析:支持为不同数据湖创建独立 Catalog,自动实现跨 Catalog 表关联分析,无需额外数据同步开发,并支持将分析结果写回原始数据湖。
提供 JDBC 等标准接口,便于接入 BI 系统和 AI 应用,支撑灵活的数据消费模式。
作为 MPP 架构的 OLAP 引擎,支持即席查询、多维分析、存算分离与弹性扩展,简化部署与运维。
总体来看,StarRocks 能在不改变现有数据架构的前提下,打通实时、离线与跨湖分析路径,天然契合智能 BI 对多源融合、分析灵活性与高性能的需求。
StarRocks 的 lakehouse 架构赋能实时智能分析
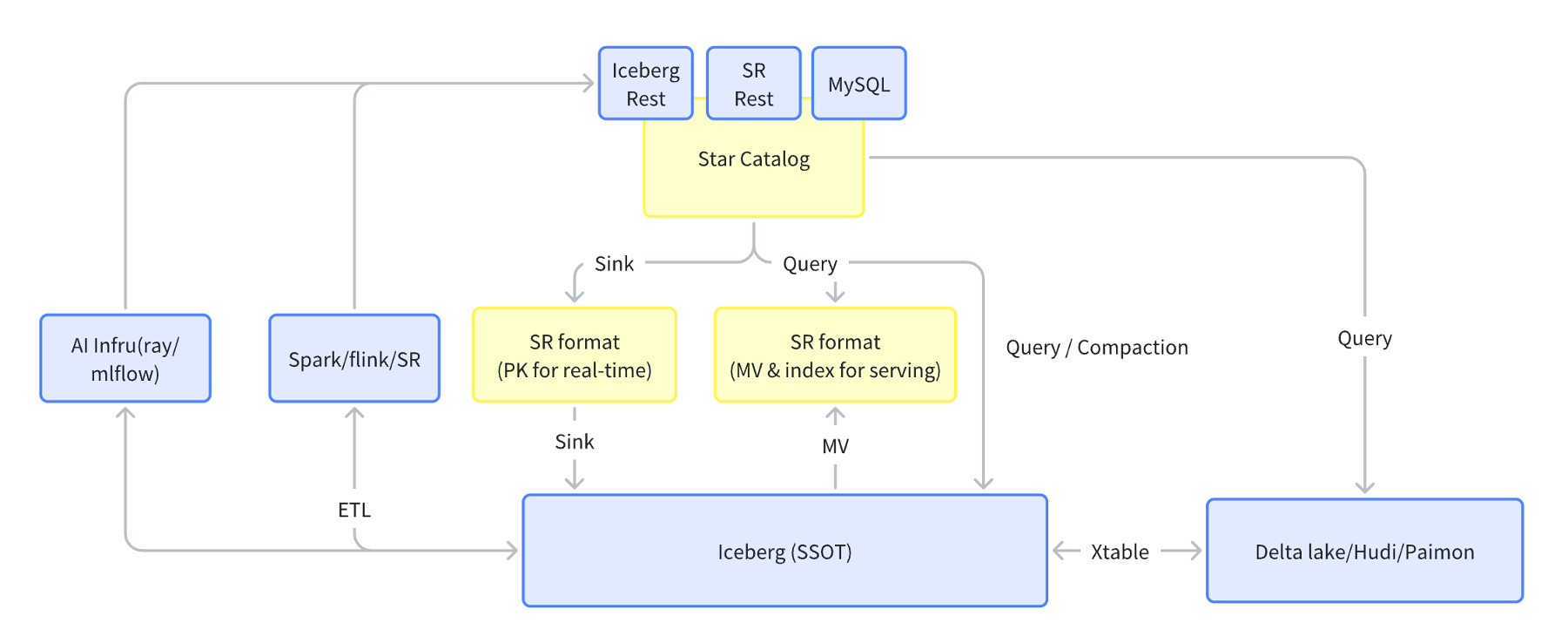
StarRocks 构建了统一的 Lakehouse 架构,有效支撑从数据接入、处理、分析到 AI 推理的全链路能力,正成为智能分析的关键底座。在数据接入层,StarRocks 支持对接主流 AI 基础设施,如 Ray 与 MLflow。其中,Ray 可通过 BC 接口直接访问 StarRocks,将生成的 embedding 数据写入,引导下游分析智能演进。
1. 实时洞察:秒级数据新鲜度,驱动动态决策
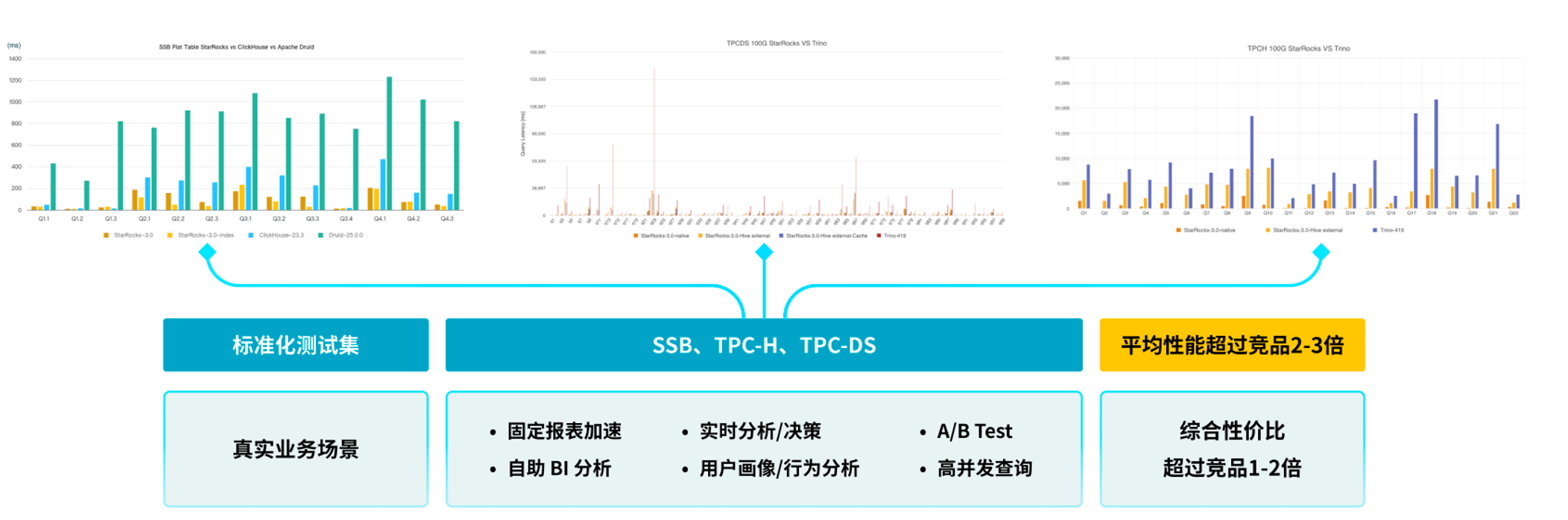
得益于 MPP 架构、Runtime Filter、CPU 优化器等核心能力,StarRocks 支持毫秒级复杂查询响应;系统支持上千并发连接,甚至在部分客户场景中稳定支持超 5000 并发。
在标准测试集(如 SSB、TPC-DS、TPC-H)中,查询性能普遍领先竞品 2–3 倍;多个实际迁移案例也实现 1–2 倍性能提升。
2. 简化架构:不搬数、减架构、省成本,提升分析效率
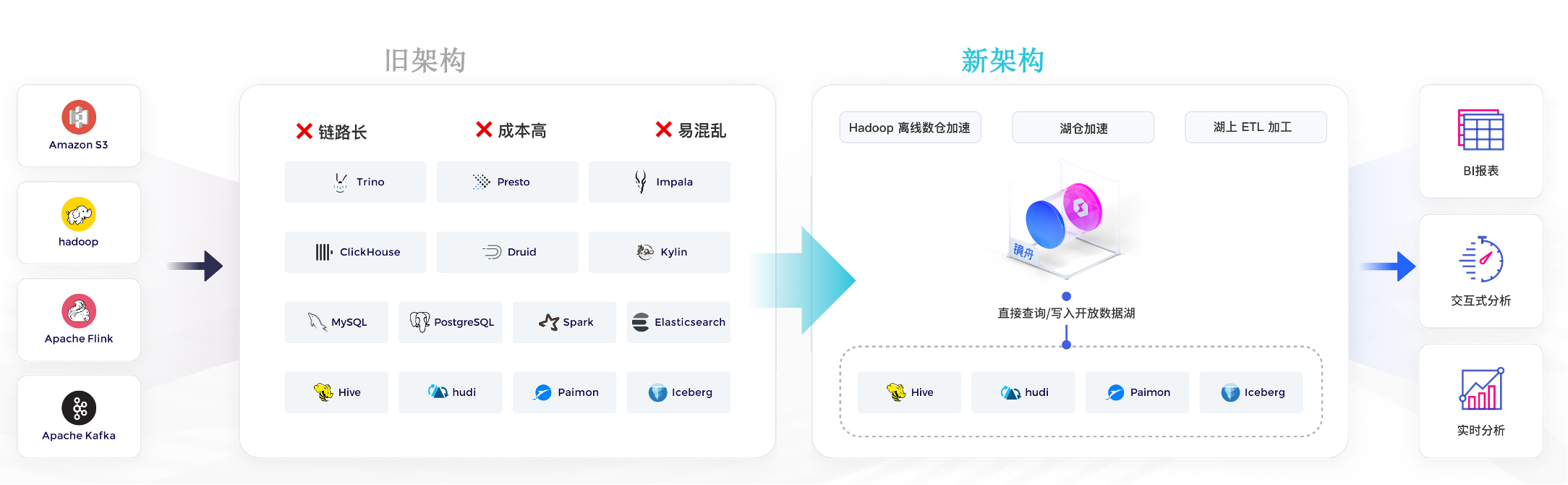
StarRocks 打破传统 BI 的多系统、多链路架构,支持 Flink、Spark 等导入方式,实现流批一体的数据接入。
通过 StarCatalog,可直接查询 Iceberg 等湖表,实现数据“零迁移”。分析结果也可写回原始湖表。
配合 AutoMV 自动生成物化视图,加速查询、简化建模,进一步提升分析效率。
3. 业务赋能:直面分析,业务人员按需加载
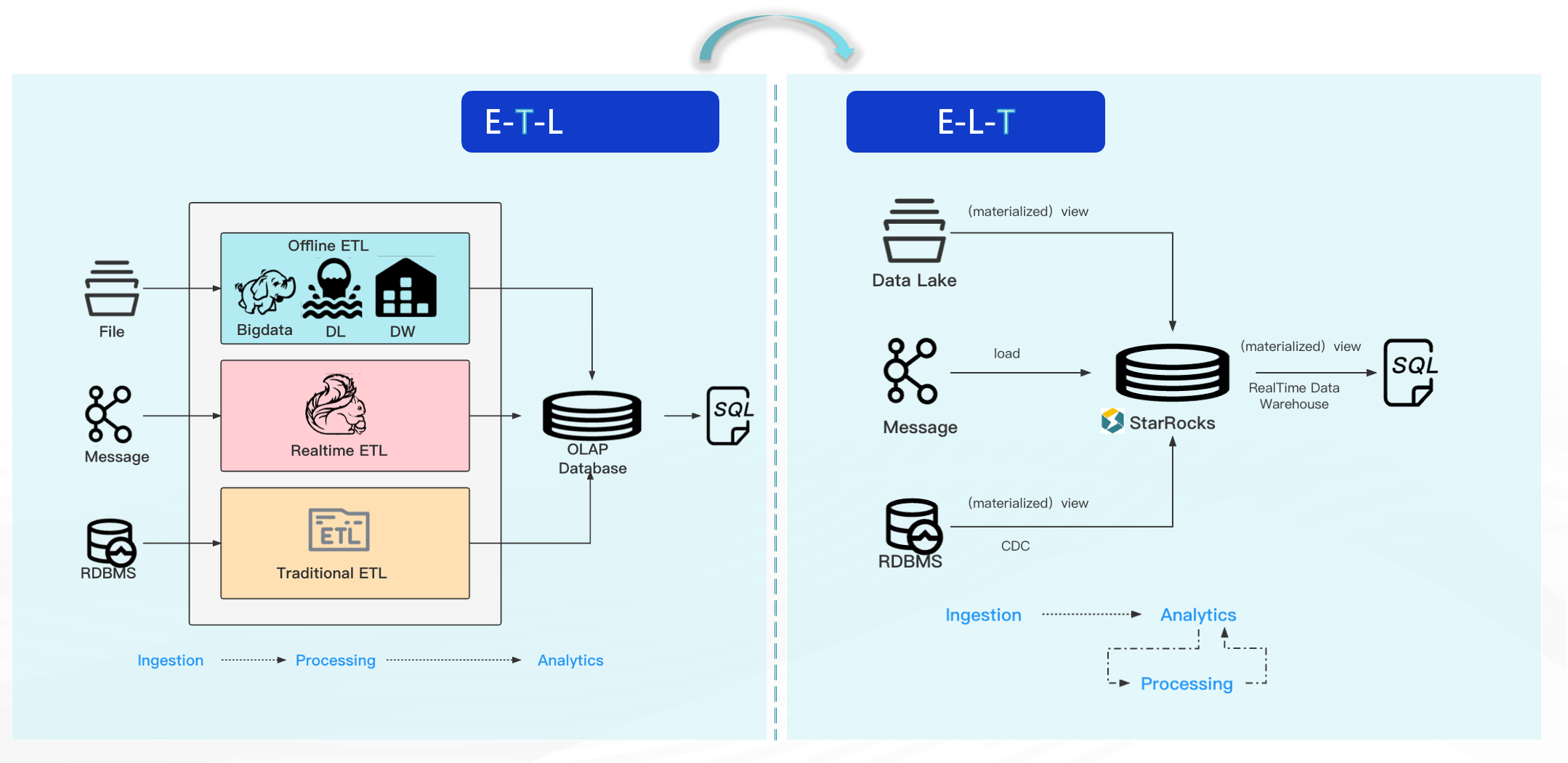
在 ELT 架构下,研发专注数据导入湖仓,业务人员可通过元数据平台按需获取数据,自主完成报表构建与分析探索,显著降低跨团队沟通与交付成本。
4. AI 集成:StarRocks 良好的 AI 特性支持
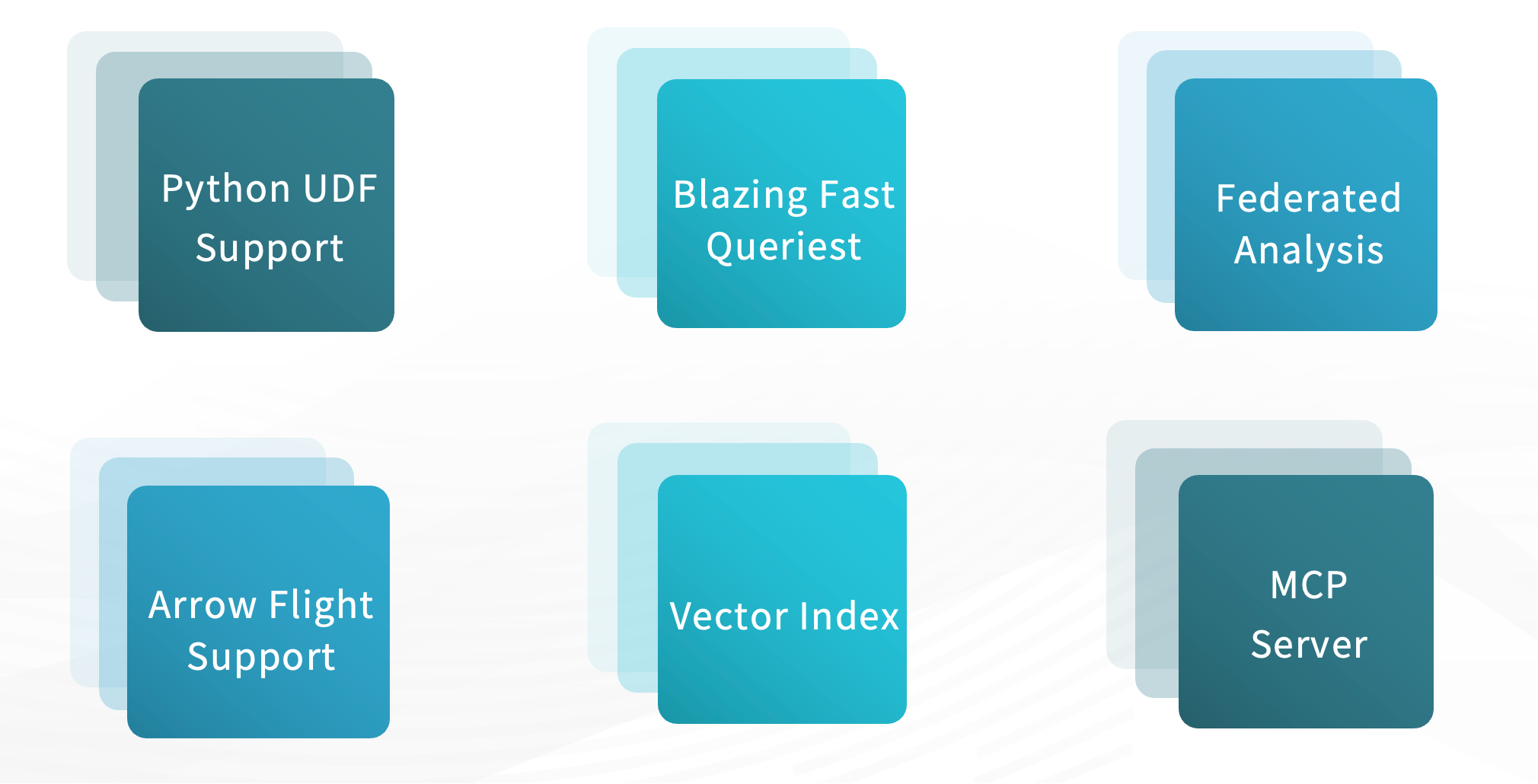
StarRocks 提供良好的 AI 集成能力:
支持 Python UDF,提升智能推理的灵活性;
借助 Arrow Flight 实现大规模数据高速导入;
可作为 Vector DB 使用,生成并存储 embedding 向量,支持向量检索,服务 RAG、智能问答、知识库增强等场景;
支持多模型共享知识,将 embedding 数据集中存储供不同 Agent 或大模型加载使用;
内置 MCP Server,兼容 MCP 协议,支持模型与 StarRocks 的高效通信。
StarRocks 赋能智能 BI
ChatBI 的建设流程
ChatBI(如 QuickBI 智能问数)的核心在于将用户自然语言输入转化为结构化查询与语义解释,生成可视化结果与洞察建议。其背后依托大模型、向量检索与 StarRocks 查询引擎协同工作,整体流程包括以下几个环节:
整个流程大致如下:
前端输入与意图识别:用户在报表系统或对话窗口中输入自然语言问题,系统先进行文本处理(如语音转写、关键词提取、实体识别等),随后由大模型识别意图并分类判断:是查指标、看趋势,还是诊断异常。
任务规划与 NL2SQL 转换:明确意图后,系统进入任务规划和 SQL 生成阶段。此时,大模型需结合上下文与业务知识构建执行逻辑。但由于通用大模型缺乏业务上下文,系统会借助企业知识库,通过 StarRocks 的 Vector Index 进行语义检索,获取表名、字段、维度等元信息,增强大模型生成能力。
查询执行与结果优化:生成 SQL 后,通过 MCP Client 将查询请求下发至 StarRocks,由其完成优化、执行与初步检索。系统随后对结果进行特征提取、排序与重打分,确保返回内容更贴近用户意图。
结果润色与呈现:最终结果会被转化为自然语言回答,并按需生成图表或报表,提升表达清晰度与决策参考价值。
关于 StarRocks 在 RAG 企业知识库场景中的应用,以及 MCP 协议如何实现大模型与 StarRocks 的高效交互,已有详尽阐述,详见以下文章:
基于 StarRocks 构建 ChatBI 架构设计
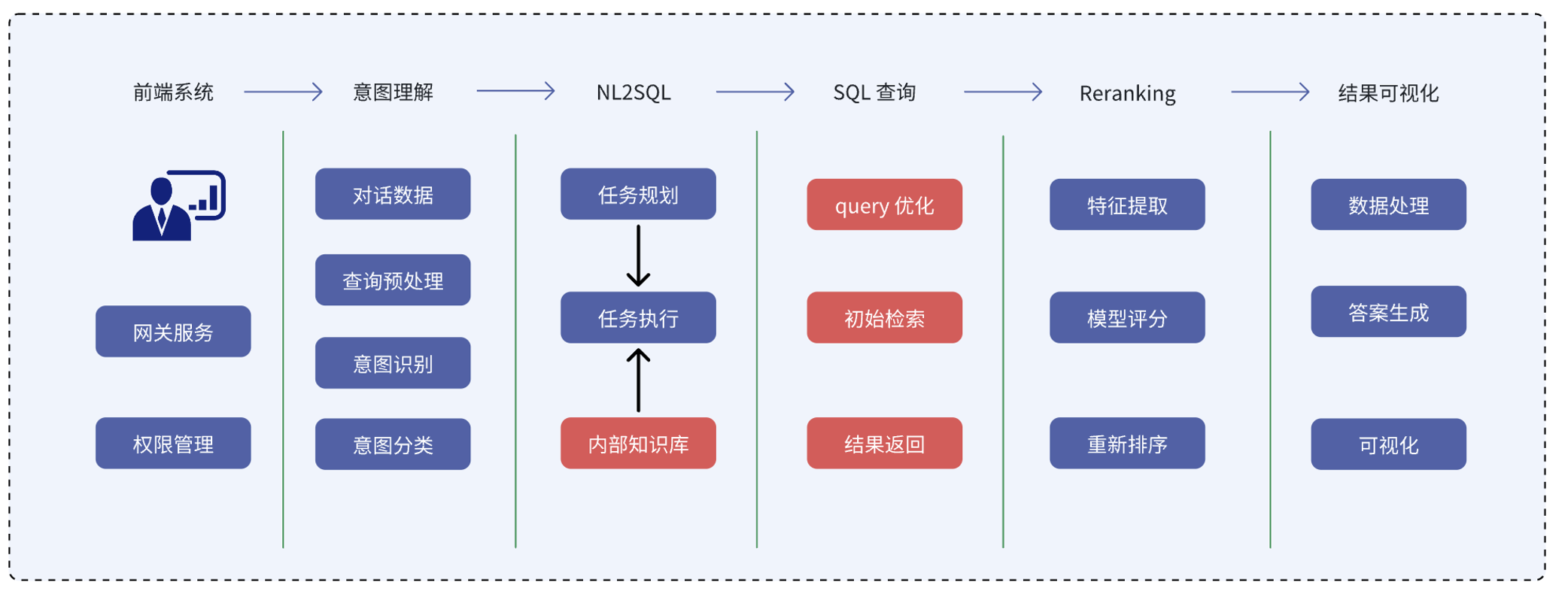
前文所述 ChatBI 流程,实质上可通过一张系统链路图完整呈现,从用户提问到查询执行、再到结果生成与可视化输出。
用户在前端输入自然语言问题,系统将其传递给大语言模型(LLM),结合上下文完成意图识别与补全(如添加提示词),再转化为结构化查询语句(SQL)。
SQL 随后提交至 StarRocks 查询引擎执行。StarRocks 会根据目标数据来源自动选择访问路径:
若数据位于 Iceberg 等数据湖中,可通过 StarCatalog 无缝访问湖表;
若来自 Kafka、Flink 等实时系统,则通过 routine load 或 Flink sink 实现导入;
若为 HDFS/S3 中的批量数据,则支持直接加载 ORC、Parquet 格式文件。
无论数据存储在哪里,用户只需自然语言提问,大模型与 StarRocks 即可完成统一调度与即时分析,省去传统架构中大量开发与同步成本。StarRocks 还具备 I/O 优化与预加载机制,确保查询响应高效稳定。
查询完成后,结果将返回至大模型,由其进行排序、重写与语言润色,生成清晰易懂的答复。如有需要,还会自动生成图表,并基于上下文提出进一步的分析建议,真正实现从数据展示到业务行动。
StarRocks 作为底层分析引擎的 ChatBI 优势
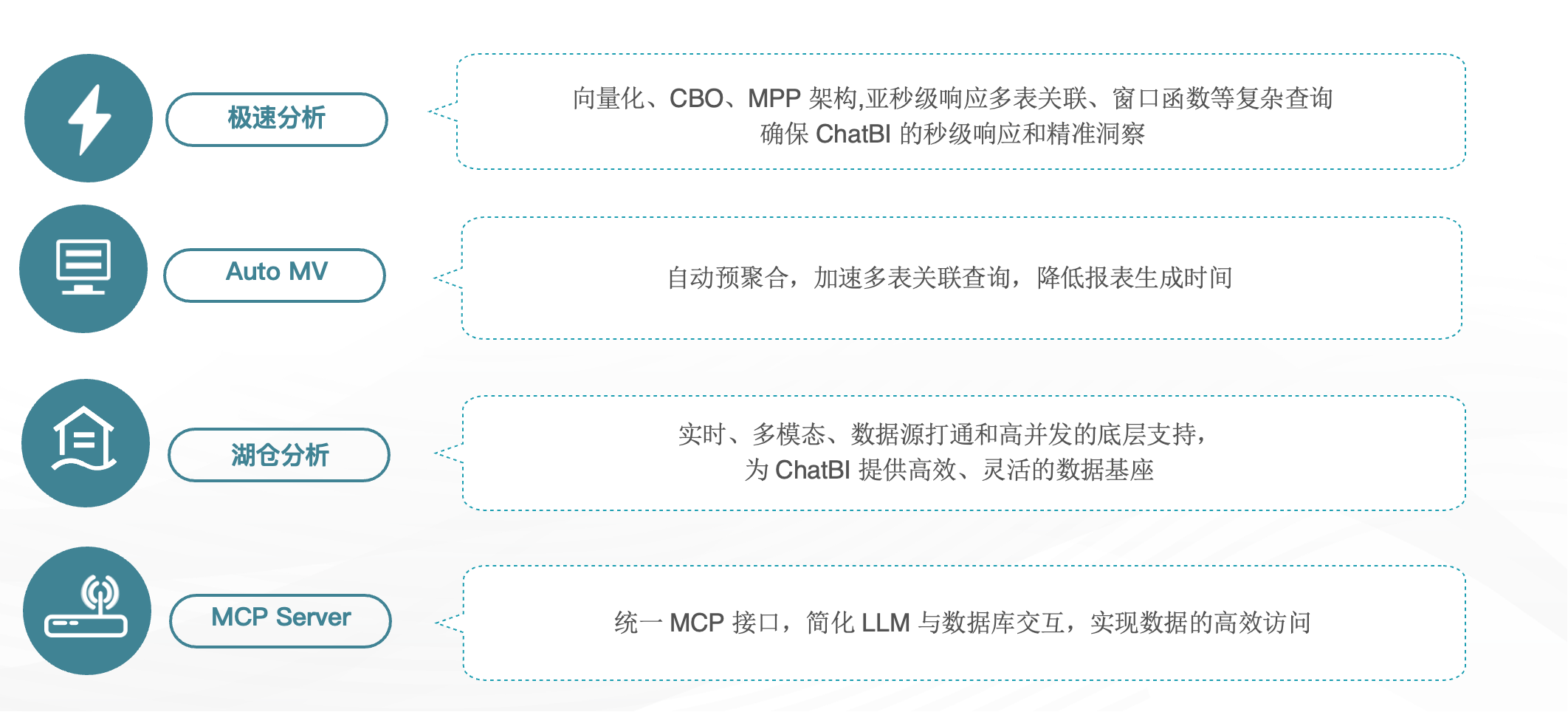
在 ChatBI 场景中,StarRocks 作为底层分析引擎具备以下核心优势:
极速分析性能:得益于底层核心优化,查询性能较同类产品提升 1–2 倍,支持高并发、低延迟的即时分析。
AutoMV 自动物化视图:可根据查询模式自动生成加速视图,复用历史结果。
湖仓分析能力:支持统一访问多源数据,构建简化架构与 Single Source of Truth,保障数据可达性与访问时效。
MCP Server 接入能力:提供统一 MCP 接口,便于模型或 Agent 访问 StarRocks 数据。
四、AI+BI 落地案例分享(以Quick BI 为例)
案例一:某饮品行业客户为例
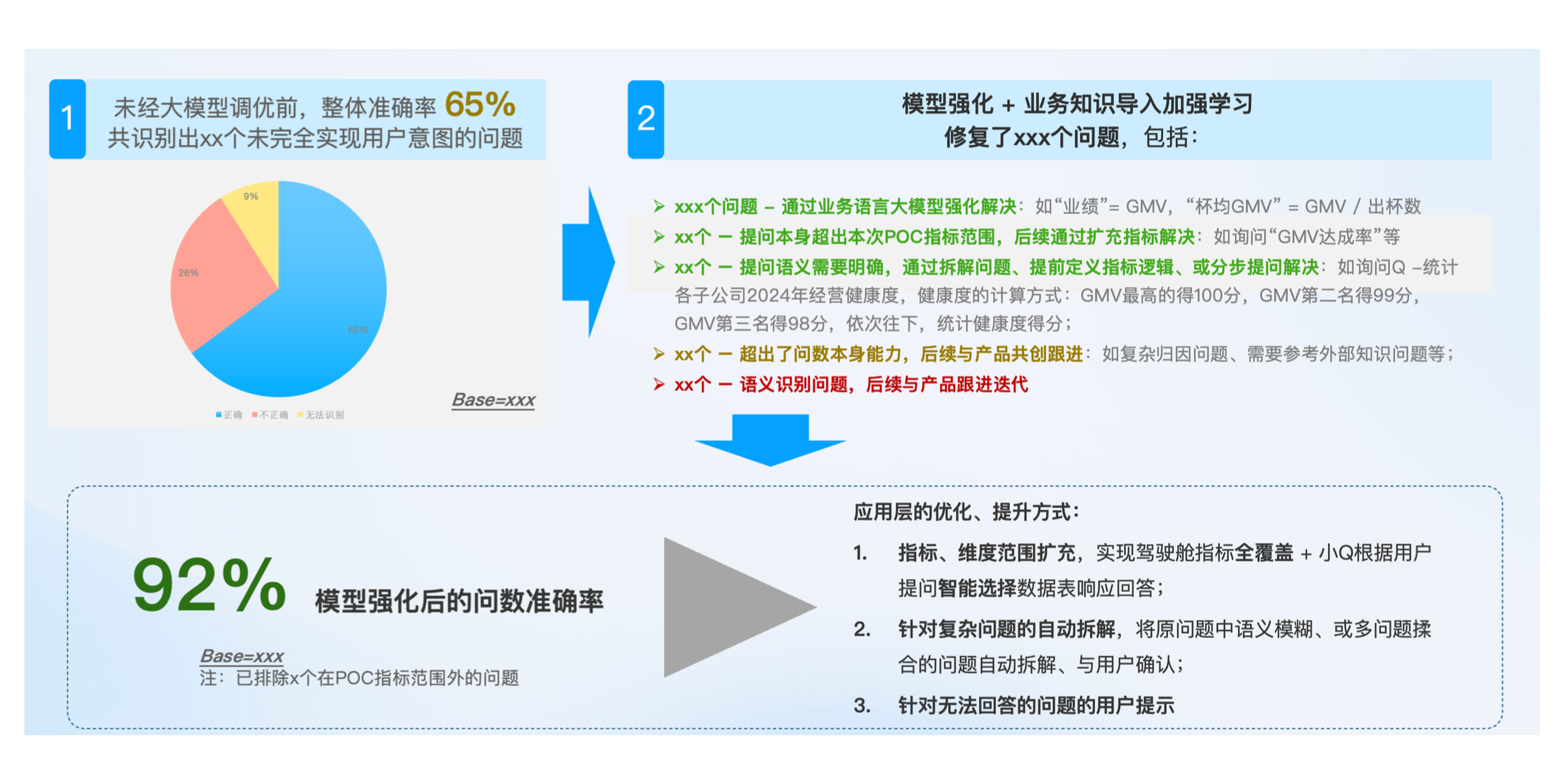
在某饮品品牌中,我们对 ChatBI 系统进行了针对性优化,验证了“好数据 + 清晰问题”对问数效果的决定性作用。
初期,由于提问模糊、缺乏上下文,系统问数准确率仅约 60%。在优化过程中,我们通过以下方式实现显著提升:
引入业务知识库,补充模型未覆盖的关键信息(如客户财年起始时间);
注入 Prompt 强化上下文识别能力;
指导用户优化提问方式;
最终,问数准确率从 65% 提升至 92%,获得客户高度认可。
案例二:数据解读 Agent
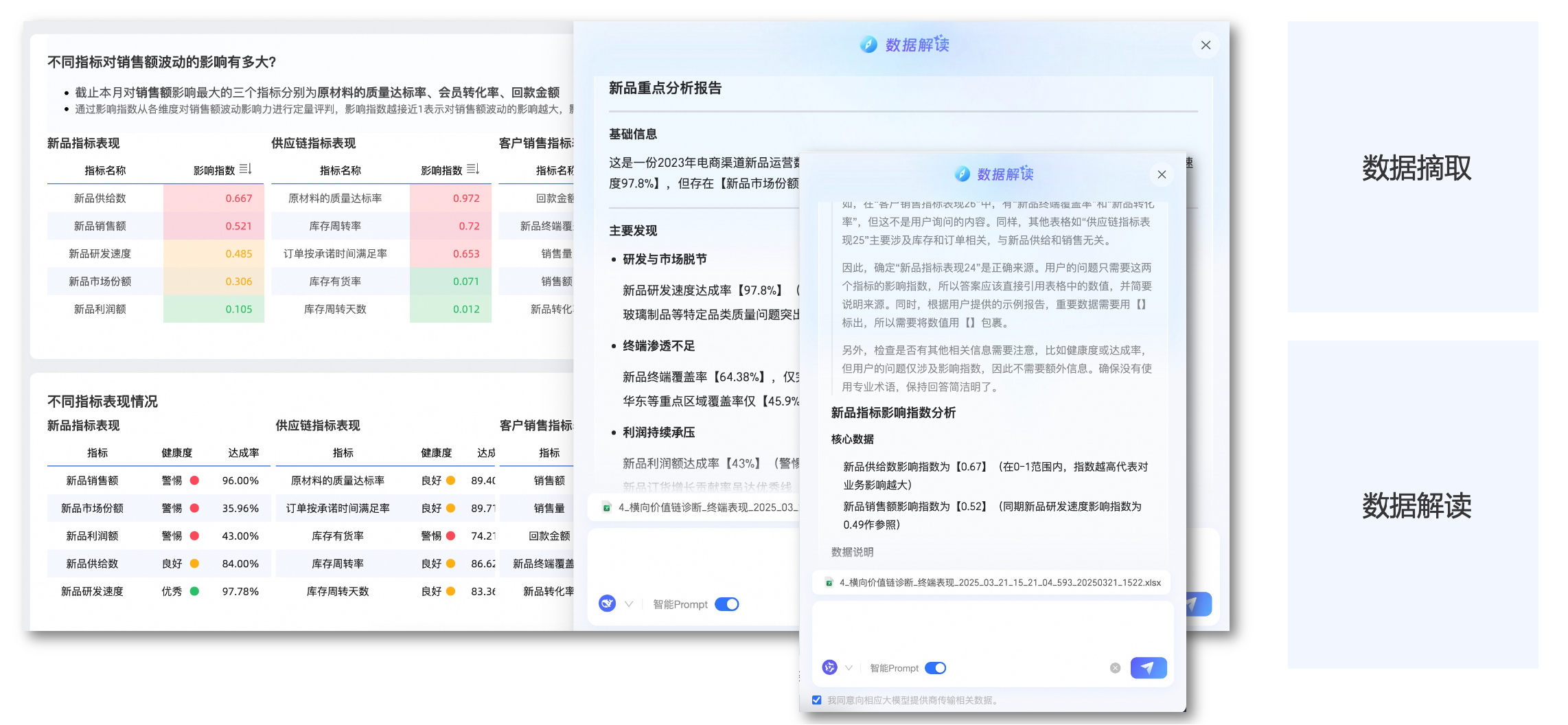
数据解读流程分为两步:数据摘取与洞察生成。
系统首先从报表或表格中提取结构化信息,转换为大模型可识别格式;再结合用户问题,进行归因分析与趋势判断,发现异常与潜在机会。
关键在于“选对数”——即识别与业务意图最相关的指标与维度。该过程由多个 Agent 协同完成,如搜索 Agent、分析 Agent、问数 Agent 等。
案例三:进阶能力:多智能体协同


在进阶应用中,Quick BI 已支持 Multi-Agent 协同机制,实现从现状诊断、归因分析,到建议生成的闭环式智能报告。
例如,在专题分析、日报/周报自动撰写中,系统通过分析 Agent、报告生成 Agent、调度 Agent 等多角色协同,自动生成图文并茂的分析结果,甚至可通过信息流方式主动推送。
五、未来展望
随着大模型技术持续演进,StarRocks 正在加速推动 AI 与 BI 的深度融合,未来将聚焦三个方向:
提升向量检索准确性,解决语义匹配偏差问题;
加强与 AutoML、深度学习等 AI 组件的原生集成,构建 AI-Native 分析引擎;
深化与云平台和模型生态的协同,打造更开放的数据智能平台。
从行业趋势来看,智能 BI 正从“任务执行者”向“智能决策主体”演进。大模型将具备动态推演、任务拆解、多模态感知与自我反思能力,实现非预设路径的智能决策,QuickBI 也正朝着这个方向演进。
StarRocks 的目标,是成为这一转变的关键基座,让数据真正“会说话”,让每个人都能成为自己的分析师。