什么是内存淘汰?
内存总是有限的,因此当 Redis 内存超出最大内存时,就需要根据一定的策略去主动的淘汰一些 Key,来腾出内存,这就是内存淘汰策略。我们可以在配置文件中通过 maxmemory-policy 配置指定策略。
与到期删除策略不同,内存淘汰策略主要目的则是为了防止运行时内存超过最大内存,所以尽管最终目的都是清理内存中的一些 Key,但是它们的应用场景和触发时机是不同的。
算上在 4.0 添加的两种基于 LFU 算法的策略, Redis 一共提供了八种策略供我们选择:
- noeviction,不淘汰任何 key,直接报错。它是默认策略。
- volatile-random:从所有设置了到期时间的 Key 中,随机淘汰一个 Key。
- volatile-lru: 从所有设置了到期时间的 Key 中,淘汰最近最少使用的 Key。
- volatile-lfu: 从所有设置了到期时间的 Key 中,淘汰最近最不常用使用的 Key(4.0 新增)。
- volatile-ttl: 从所有设置了到期时间的 Key 中,优先淘汰最早过期的 Key。
- allkeys-random:从所有 Key 中,随机淘汰一个键。
- allkeys-lru: 从所有 Key 中,淘汰最近最少使用的 Key。
- allkeys-lfu: 从所有 Key 中,淘汰最近最不常用使用的键(4.0 新增)。
从淘汰范围来说可以分为不淘汰任何数据、只从设置了到期时间的键中淘汰和从所有键中淘汰三类。而从淘汰算法来分,又主要分为 Random(随机),LRU(最近最少使用),以及 LFU(最近最不常使用)三种。
其中,关于 LRU 算法,它是一种非常常见的缓存淘汰算法。我们可以简单理解为 Redis 会在每次访问 Key 的时候记录访问时间,当淘汰时,优先淘汰最后一次访问距离现在最早的 Key。
而对于 LFU 算法,我们可以理解为 Redis 会在访问 Key 时,根据两次访问时间的间隔计算并累加访问频率指标,当淘汰时,优先淘汰访问频率指标最低的 key。相比 LRU 算法,它避免了低频率的大批量查询造成的缓存污染问题。
什么是缓存污染问题?
LRU 有个最大问题,就是它只认最近一次访问时间。而如果出现系统偶尔需要一次性读取大量数据的时候,会大规模更新 Key 的最近访问时间,从而导致真正需要被频繁访问的 Key 因为最近一次访问时间更早而被直接淘汰。这种情况被称为缓存污染。为此,我们需要使用 LFU 算法来解决。
淘汰策略对缓存击穿的影响?
举个例子,我们操作了缓存预热和设置 Redis 永不过期,如果说设置 Redis 内存淘汰策略是以下类型:
- allkeys-random:从所有 Key 中,随机淘汰一个键。
- allkeys-lru: 从所有 Key 中,淘汰最近最少使用的 Key。
- allkeys-lfu: 从所有 Key 中,淘汰最近最不常用使用的键(4.0 新增)。
因为是从所有键中去执行淘汰算法,是否有可能将咱们设置的热 Key 或者说访问较多的 Key 给淘汰掉?第一种绝对有可能,第二三种虽然概率比较小,但是也不是没可能。
所以,我们只能从这几个淘汰算法中进行选择:
noeviction,不淘汰任何 Key,直接报错。
volatile-random:从所有设置了到期时间的 Key 中,随机淘汰一个 Key。
volatile-lru: 从所有设置了到期时间的 Key 中,淘汰最近最少使用的 Key。
volatile-lfu: 从所有设置了到期时间的 Key 中,淘汰最近最不常用使用的 Key(4.0 新增)。
volatile-ttl: 从所有设置了到期时间的 Key 中,优先淘汰最早过期的 Key。
内存淘汰底层原理
1. 淘汰过程
Redis 内存淘汰执行流程如下:
1.每次当 Redis 执行命令时,若设置了最大内存大小 maxmemory,并设置了淘汰策略式,则会尝试进行一次 Key 淘汰;
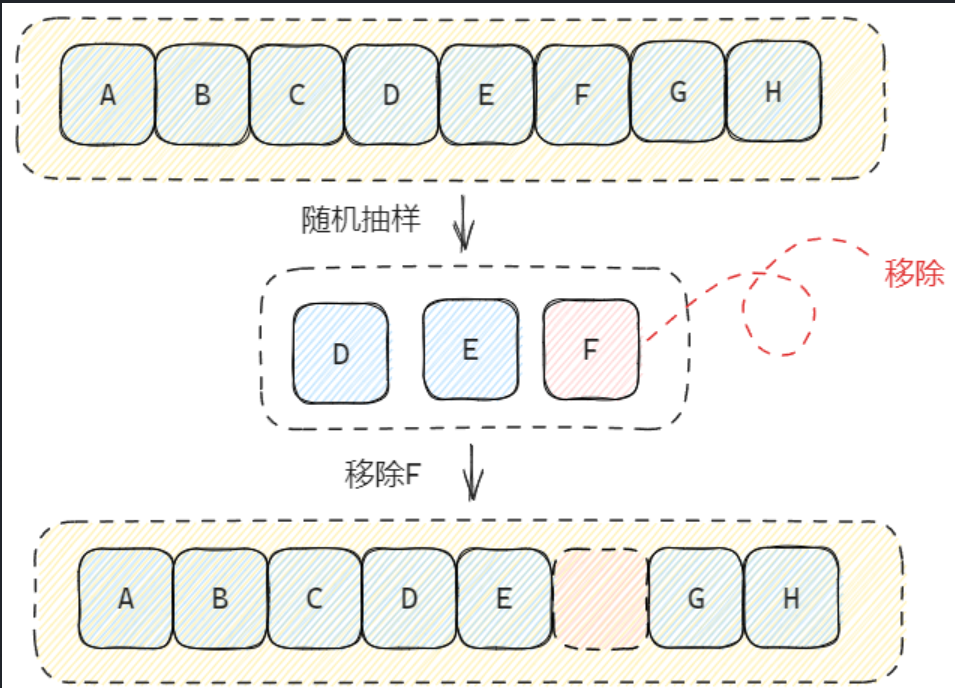
2.Redis 首先会评估已使用内存(这里不包含主从复制使用的两个缓冲区占用的内存)是否大于 maxmemory,如果没有则直接返回,否则将计算当前需要释放多少内存,随后开始根据策略淘汰符合条件的 Key;当开始进行淘汰时,将会依次对每个数据库进行抽样,抽样的数据范围由策略决定,而样本数量则由 maxmemory-samples配置决定;
3.完成抽样后,Redis 会尝试将样本放入提前初始化好 EvictionPoolLRU 数组中,它相当于一个临时缓冲区,当数组填满以后即将里面全部的 Key 进行删除。
4.若一次删除后内存仍然不足,则再次重复上一步骤,将样本中的剩余 Key 再次填入数组中进行删除,直到释放了足够的内存,或者本次抽样的所有 Key 都被删除完毕(如果此时内存还是不足,那么就重新执行一次淘汰流程)。
在抽样这一步,涉及到从字典中随机抽样这个过程,由于哈希表的 Key 是散列分布的,因此会有很多桶都是空的,纯随机效率可能会很低。因此,Redis 采用了一个特别的做法,那就是先连续遍历数个桶,如果都是空的,再随机调到另一个位置,再连续遍历几个桶……如此循环,直到结束抽样。
你可以参照源码理解这个过程:
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; /* internal hash table id, 0 or 1. */
unsigned long tables; /* 1 or 2 tables? */
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10;
// 如果字典正在迁移,则协助迁移
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1;
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0;
// 当已经采集到足够的样本,或者重试已达上限则结束采样
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
// 如果一个库的到期字典已经处理完毕,则处理下一个库
if (i >= d->ht[j].size) continue;
dictEntry *he = d->ht[j].table[i];
// 连续遍历多个桶,如果多个桶都是空的,那么随机跳到另一个位置,然后再重复此步骤
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
// 查找下一个桶
i = (i+1) & maxsizemask;
}
return stored;
}
2. LRU 实现
LRU 的全称为 Least Recently Used,也就是最近最少使用。一般来说,LRU 会从一批 Key 中淘汰上次访问时间最早的 key。
它是一种非常常见的缓存回收算法,在诸如 Guava Cache、Caffeine等缓存库中都提供了类似的实现。我们自己也可以基于 JDK 的 LinkedHashMap 实现支持 LRU 算法的缓存功能。
2.1 近似 LRU
传统的 LRU 算法实现通常会维护一个链表,当访问过某个节点后就将该节点移至链表头部。如此反复后,链表的节点就会按最近一次访问时间排序。当缓存数量到达上限后,我们直接移除尾节点,即可移除最近最少访问的缓存。
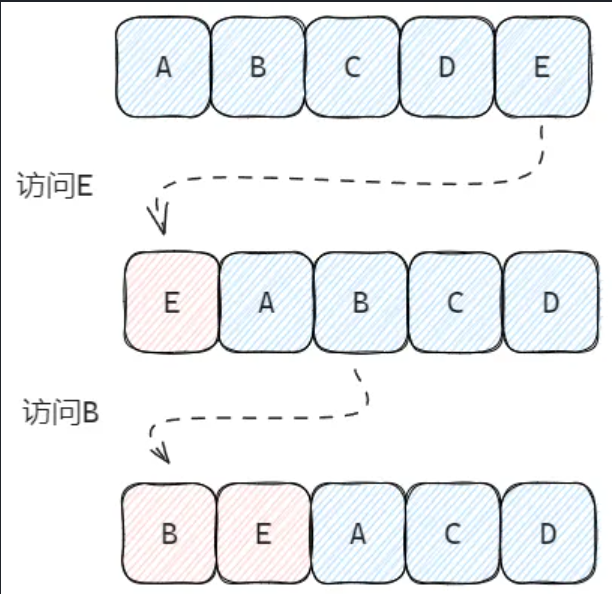
不过,对于 Redis 来说,如果每个 Key 添加的时候都需要额外的维护并操作这样一条链表,要额外付出的代价显然是不可接受的,因此 Redis 中的 LRU 是近似 LRU(NearlyLRU)。
当每次访问 Key 时,Redis 会在结构体中记录本次访问时间,而当需要淘汰 Key 时,将会从全部数据中进行抽样,然后再移除样本中上次访问时间最早的 key。
它的特点是:
仅当需要时再抽样,因而不需要维护全量数据组成的链表,这避免了额外内存消耗。
访问时仅在结构体上记录操作时间,而不需要操作链表节点,这避免了额外的性能消耗。
当然,有利就有弊,这种实现方式也决定 Redis 的 LRU 是并不是百分百准确的,被淘汰的 Key 未必真的就是所有 Key 中最后一次访问时间最早的。
2.2 抽样大小
根据上述的内容,我们不难理解,当抽样的数量越大,LRU 淘汰 Key 就越准确,相对的开销也更大。因此,Redis 允许我们通过 maxmemory-samples 配置采样数量(默认为 5),从而在性能和精度上取得平衡。
3. LFU 实现
LFU 全称为 Least Frequently Used ,也就是最近最不常用。它的特点如下:
- 同样是基于抽样实现的近似算法,maxmemory-samples 对其同样有效。
- 比较的不是最后一次访问时间,而是数据的访问频率。当淘汰的时候,优先淘汰范围频率最低 Key。
- 它的实现与 LRU 基本一致,但是在计数部分则有所改进。
3.1 概率计数器
在 Redis 用来存储数据的结构体 redisObj 中,有一个 24 位的 lru数值字段:
当使用 LRU 算法时,它用于记录最后一次访问时间的时间戳。
当使用 LFU 算法时,它被分为两部分,高 16 位关于记录最近一次访问时间(Last Decrement Time),而低 8 位作为记录访问频率计数器(Logistic Counter)。
LFU 的核心就在于低 8 位表示的访问频率计数器(下面我们简称为 counter),是一个介于 0 ~ 255 的特殊数值,它会每次访问 Key 时,基于时间衰减和概率递增机制动态改变。
这种基于概率,使用极小内存对大量事件进行计数的计数器被称为莫里斯计数器,它是一种概率计数法的实现。
3.2 时间衰减
每当访问 Key 时,根据当前实际与该 Key 的最后一次访问时间的时间差对 counter 进行衰减。
衰减值取决于 lfu_decay_time 配置,该配置表示一个衰减周期。我们可以简单的认为,每当时间间隔满足一个衰减周期时,就会对 counter 减一。
比如,我们设置 lfu_decay_time为 1 分钟,那么如果 Key 最后一次访问距离现在已有 3 分 30 秒,那么 counter 就需要减 3。
3.3 概率递增
在完成衰减后,Redis 将根据 lfu_log_factor 配置对应概率值对 counter 进行递增。
这里直接放上源码:
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
// 若已达最大值 255,直接返回
if (counter == 255) return 255;
// 获取一个介于 0 到 1 之间的随机值
double r = (double)rand()/RAND_MAX;
// 根据当前 counter 减去初始值得到 baseval
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
// 使用 baseval*server.lfu_log_factor+1 得到一个概率值 p
double p = 1.0/(baseval*server.lfu_log_factor+1);
// 当 r < p 时,递增 counter
if (r < p) counter++;
return counter;
}
简而言之,直接从代码上理解,我们可以认为 counter和 lfu_log_factor 越大,则递增的概率越小: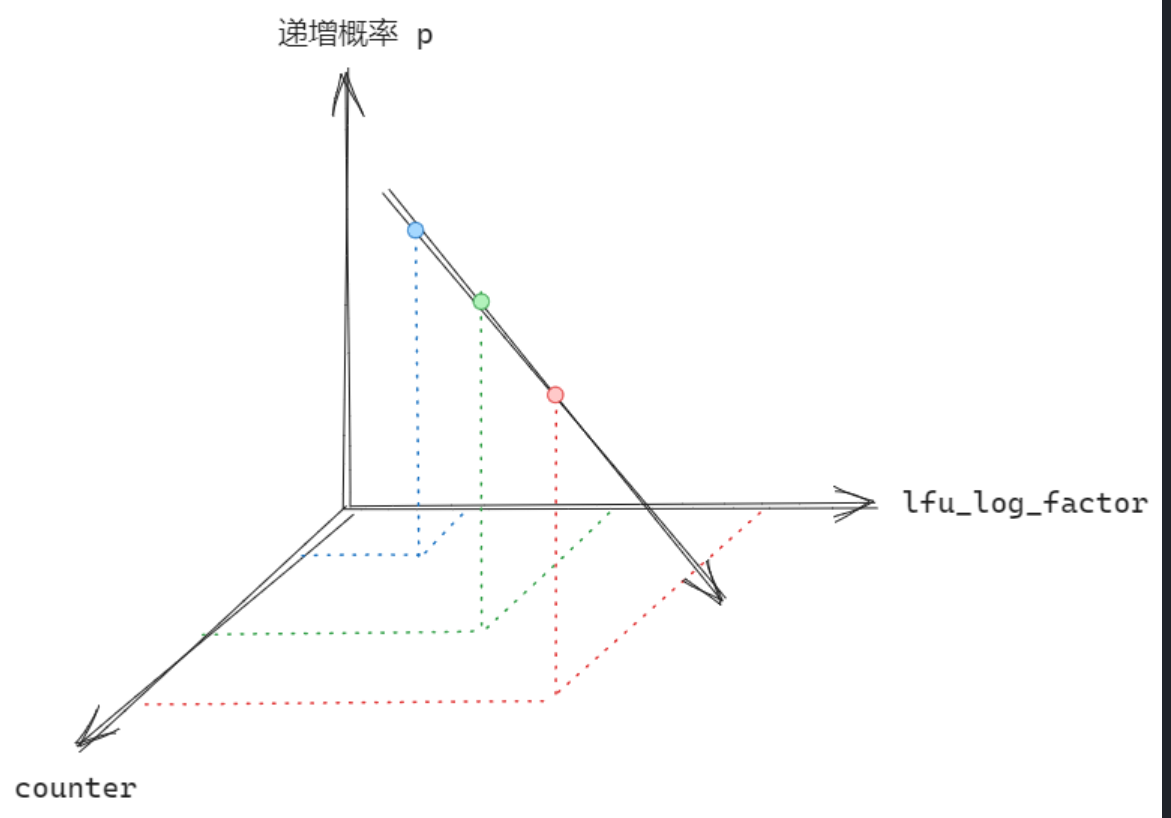
当然,实际上也要考虑到访问次数对其的影响,Redis 官方给出了相关数据: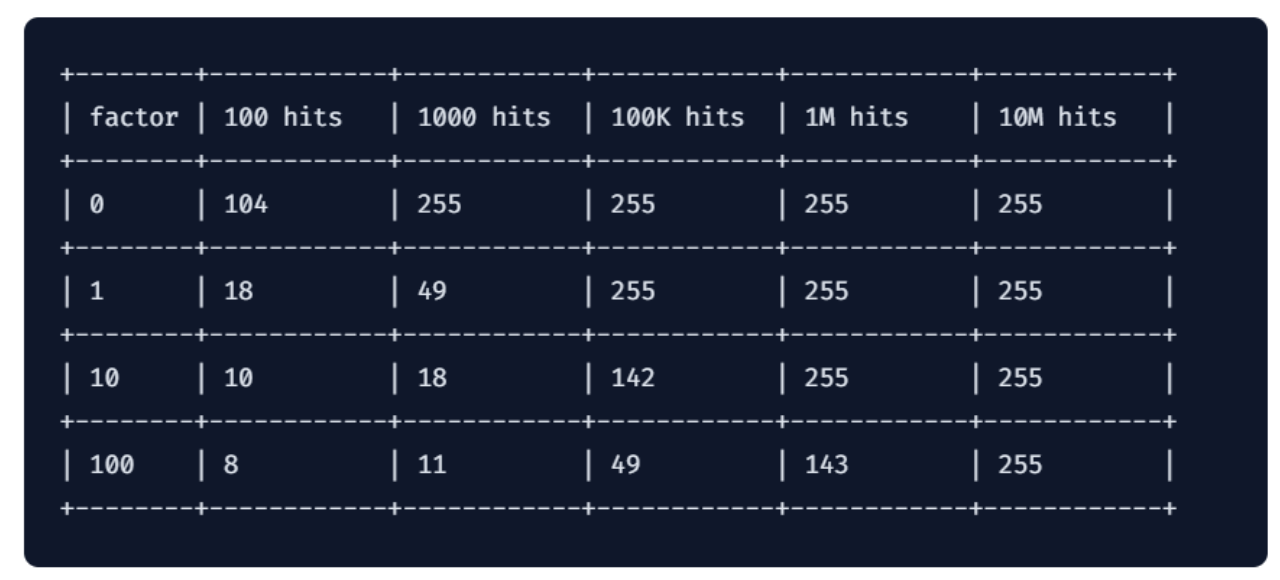
3.4 计数器的初始值
为了防止新的 Key 由于 counter 为 0 导致直接被淘汰,Redis 会默认将 counter设置为 5。
3.5 抽样大小的选择
值得注意的是,当数据量比较大的时候,如果抽样大小设置的过小,因为一次抽样的样本数量有限,冷热数据因为时间衰减导致的权重差异将会变得不明显,此时 LFU 算法的优势就难以体现,即使的相对较热的数据也有可能被频繁“误伤”。
所以,如果你选择了 LFU 算法作为淘汰策略,并且同时又具备比较大的数据量,那么不妨将抽样大小也设置的大一些。