VLN-R1使用 大型视觉语言模型 LVLM,实现连续环境导航。
输入“第一人称”连续视觉流,让模型学习真实导航中 “逐步感知、动态决策” 的逻辑,输出动作序列。
论文地址:VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning
代码地址:https://github.com/Qi-Zhangyang/GPT4Scene-and-VLN-R1
1、框架思路流程
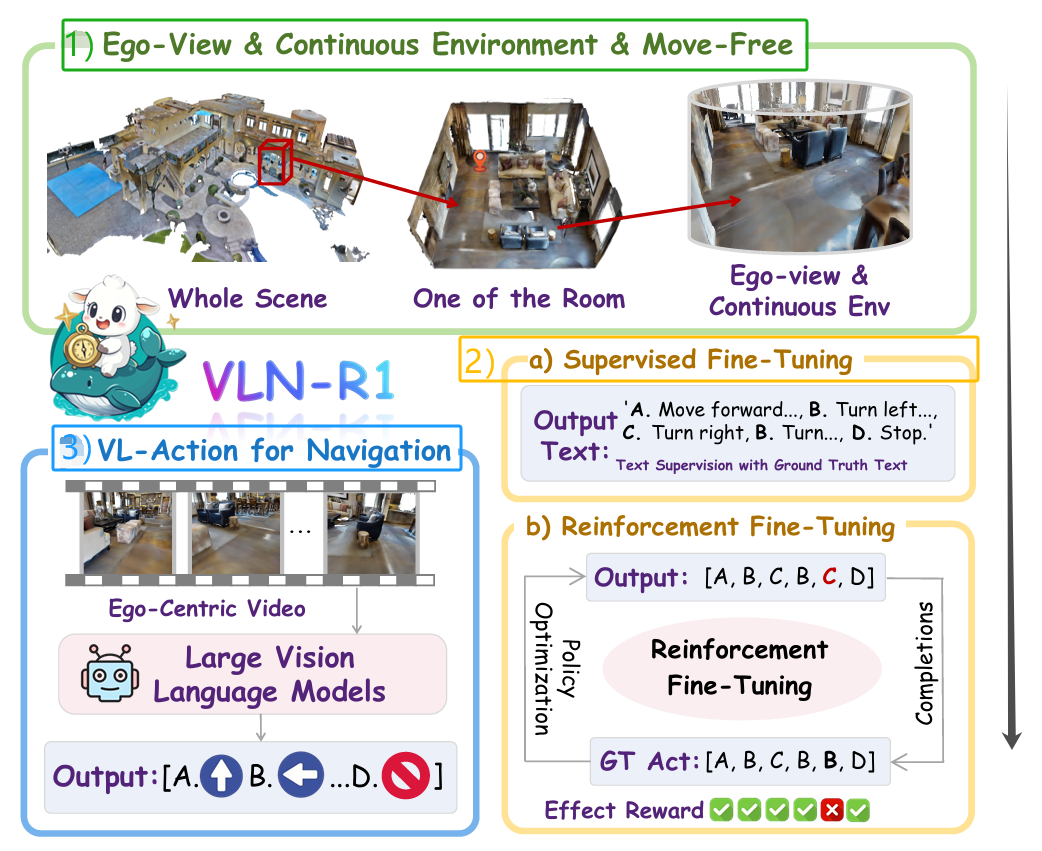
VLN-R1 的框架流程,如下图所示,让大型视觉语言模型(LVLM)作为 “第一人称智能体” ,实现端到端导航 的核心思路。
1)模型输入:智能体第一视角的连续视频帧,而非传统方法的 “全局地图 + 指令”。
- 让模型直接模拟人类 “用眼睛看环境、用语言懂指令” 的感知习惯,为后续 “视觉→动作” 的端到端映射奠定基础。
2)训练流程:两阶段优化(SFT→RFT)
- 设计 “模仿学习(SFT)+ 强化学习(RFT)” 双阶段 ,解决 “基础动作逻辑” 与 “长程误差累积” 问题。
- 有监督微调,通过 “硬监督” 让模型掌握基础动作逻辑(如 “前进、转向” 的文本表达与执行条件)。
- 强化微调,优化长距离导航的鲁棒性,解决 “一步错、步步错” 的误差累积问题。
3)动作输出:端到端视觉 - 语言动作(VL-Action)
- 直接驱动智能体的动作序列(如[A.前进 B.左转… D.停止]),而非传统方法的 “离散路径坐标”。
- 从 “视觉输入” 到 “动作输出” 无需外部转换模块,让 LVLM 真正成为 “自主决策者”;
VLN-R1思路本质是 “让 LVLM 像人类一样导航”:
- 用第一人称连续视觉替代抽象地图,贴近真实感知;
- 用两阶段训练解决 “基础学习” 与 “长程优化” 的分层需求;
- 用端到端动作输出让模型直接成为 “可执行任务的智能体”。
2、了解如何制作数据集
因为VLN-R1用到了“有监督训练”,需要知道如何制作数据集的,从提供的VLN-Ego数据集分析;
| 维度 | 传统导航数据集(如 R2R) | VLN-Ego |
|---|---|---|
| 视角 | 第三人称全局地图(鸟瞰图) | 第一人称连续视觉流(Ego-view) |
| 动作标注 | 离散位置坐标(如房间编号) | 连续动作序列(前进、转向、停止) |
| 模态对齐 | 视觉(全局)- 语言(弱对齐) | 视觉(第一人称)- 语言 - 动作(强对齐) |
| 训练目标 | 路径规划(需外部动作转换) | 端到端动作决策(直接驱动智能体) |
每条 VLN-Ego 样本包含 “指令(Instruction)- 视觉(Vision)- 动作(Action)”三元组。
2.1. 指令部分(Instruction)
- 系统提示(System Message):如
“你是一个用于导航任务的机器人,需根据第一视角画面执行动作”,模拟真实任务中的角色设定,引导模型理解 “我是谁、要做什么”; - 自然语言指令:如
“进入房间,在床脚左转,走到右侧衣柜门口停下”,用人类日常语言描述导航目标,测试模型的语言理解与场景映射能力。
2.2. 视觉部分(Vision)
包含历史观测(History Memory) 和当前观测(Current Observation),模仿人类 “记忆 + 实时感知” 的决策模式:
- 历史观测:采样长短时记忆帧(近期帧密集采样,远期帧稀疏采样),让模型同时保留:
- 短时细节(如眼前的床脚、转角);
- 长时上下文(如 “从哪个房间进入”“之前是否经过标志性物体”);
- 当前观测:智能体实时第一视角画面(如当前面对的衣柜、墙面),驱动模型 “基于当下环境做决策”。
3. 动作部分(Action)
- 基础动作空间:定义 4 个原子动作(前进、左转、右转、停止),对应物理可执行的运动(前进 25cm、左转 30°、右转 30°、停止),而非抽象指令;
- 未来动作序列标签:标注未来 6 步的专家动作序列(如
[A,B,C,B,C,D],A = 前进、D = 停止),为模型提供 “正确决策路径” 的监督信号。
下面图片是制作数据的思路流程:
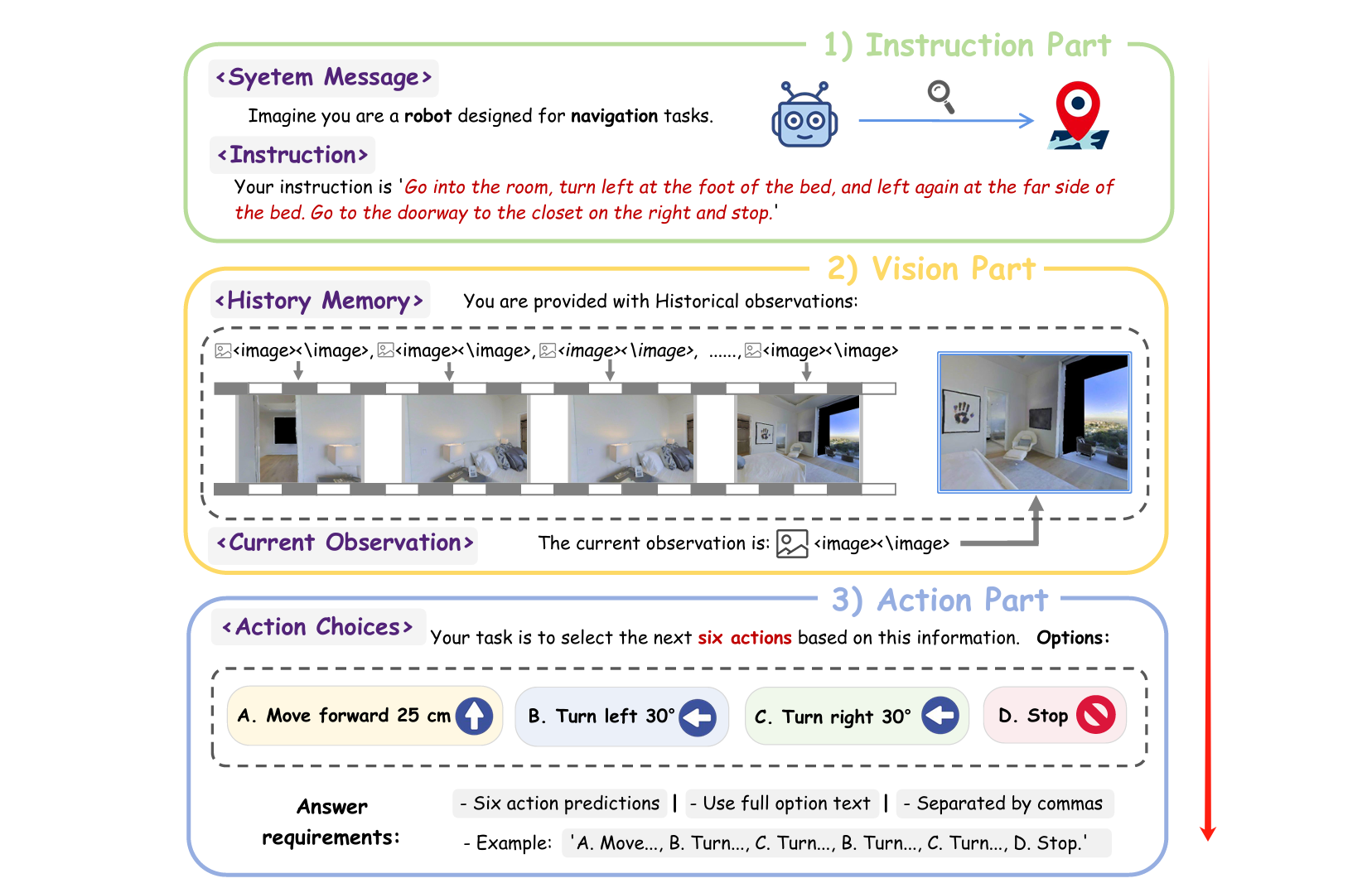
模型处理单个样本的逻辑是 **“指令理解→视觉整合→动作规划”** 的端到端闭环:
- 角色与任务对齐:通过系统提示明确 “我是导航机器人”,通过指令明确 “要完成什么任务”;
- 环境上下文构建:结合历史画面(记忆)和当前画面(实时感知),理解 “我在哪里、之前走过什么路径、现在看到什么环境”;
- 多步动作规划:基于语言指令和视觉信息,从 4 个原子动作中选择并排列出连续 6 步的可行序列,让智能体从 “当前位置” 执行动作,最终完成导航任务(如走到衣柜门口停下)。
通过模拟人类导航的 “感知 - 决策” 过程,为模型训练提供从 “模仿专家” 到 “自主优化” 的完整监督信号。
3、基于可验证奖励的强化学习(RLVR)
想象你教机器人导航时,传统方法(RLHF) 像请人类当评委:人类看机器人动作,主观说 “这样做对 / 不对”。
但导航任务里,“正确动作” 其实是客观存在的(比如 “前进 25cm→左转 30°” 就是标准答案)。
RLVR 干的事儿,就是用 “客观答案” 当考官,让模型直接学 “什么动作绝对正确”。
核心区别:RLHF vs RLVR
| 对比维度 | 传统 RLHF(从人类反馈学习) | RLVR(基于可验证奖励) |
|---|---|---|
| “考官” 是谁 | 人类(主观判断 “喜欢哪个动作”) | 客观答案(比如 “正确动作序列”) |
| 奖励特点 | 软奖励(如 “这个动作比另一个好一点”) | 硬奖励(非对即错,正确得 1,错误得 0) |
| 适用场景 | 无明确标准答案的任务(如聊天) | 有明确标准答案的任务(如导航、数学) |
RLVR 的 “优化公式”:让模型学 “做对题”+“别跑题”
RLVR 的目标是让模型生成的动作序列,既接近正确答案,又别太离谱(和原来的参考模型差异太大)。
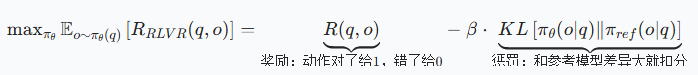
- 奖励项( R(q, o) ):导航任务中,若模型输出的动作序列(o)和真实序列(比如 “前进→左转→停止”)完全一致,得 1;否则得 0。像考试判卷,对就满分,错就 0 分。
- 惩罚项(KL 散度):防止模型 “为了做对题,学出奇怪动作”。比如参考模型原本知道 “左转 30°”,新模型突然学出 “左转 90°”(虽然可能凑巧做对当前题,但泛化性差),KL 散度会给这种 “离群” 行为扣分,让模型慢慢学 “合理动作”。
导航任务中的应用:动作序列的 “对与错”
比如指令是 “走到衣柜门口停下”,真实动作序列是 [前进、左转、前进、停止]:
- 模型 A 输出
[前进、左转、前进、停止]→ 奖励 1,KL 惩罚低(和参考模型接近)→ 优化方向:多学这类序列。 - 模型 B 输出
[前进、右转、前进、停止]→ 奖励 0,KL 惩罚可能高(动作方向错了)→ 优化方向:少学这类序列。
4、组相对策略优化(GRPO):让模型 “自己和自己比着学”
传统强化学习(如 PPO)需要额外训练一个 “评论模型”(判断动作好不好),但大型模型参数太多,训练评论模型很麻烦。
GRPO 想了个招:让模型自己生成多个候选动作序列,互相比较选最优,不用额外模型!
核心思路:“多候选对比” 替代 “外部评委”
假设模型要处理指令 “进入房间左转”,GRPO 让模型一次性生成 8 个不同的动作序列候选(比如有的先前进再左转,有的直接左转),然后:
- 给每个候选打分(用 RLVR 的硬奖励,对或错);
- 算 “相对优势”:比组内平均水平好多少(比如候选 A 得分比组内平均高,就有正优势);
- 调整模型参数:让有正优势的序列更可能被生成,同时限制和参考模型的差异。
长距离导航时,一步错可能步步错。GRPO 让模型同时生成多个 “动作序列方案”,比如:
- 方案 1:
[前进、左转、前进、停止](正确,奖励 1) - 方案 2:
[前进、右转、前进、停止](错误,奖励 0) - 方案 3:
[左转、前进、前进、停止](错误,奖励 0)
通过对比,模型会发现 “方案 1” 更优,优先强化它的生成概率。
这样,即使某一步容易出错(比如 “什么时候左转”),多候选对比能帮模型找到 “整体更对” 的序列,减少长程导航的误差累积。
- RLVR 像 “客观考官”,定义 “什么动作是对的”;
- GRPO 像 “智能教练”,教模型 “怎么找到对的动作,还能稳定学习”。
5、有监督微调(SFT)阶段:学习基础导航
给它第一视角的 “视频片段”(比如在房间里走的画面)、人类指令(比如 “走到衣柜门口停下”),让它预测未来 6 步该做什么动作(前进、左转等)。
- 输入:
- 语言指令(Instruction):自然语言描述目标(如 “在床脚左转,走到衣柜门口”);
- 视觉信息(Vision):
- 历史观测(History Memory):过去的第一视角画面(走过的路径);
- 当前观测(Current Observation):现在看到的画面(眼前的环境);
- 输出:未来 6 步的动作序列(如
A. 前进25cm, B. 左转30°, ..., D. 停止); - 成功标准:执行完动作序列后,机器人停止位置与目标的距离在阈值内(比如≤50 厘米)。
VLN-R1 的长短时记忆采样
把历史画面分成 **“短时记忆” 和 “长时记忆”** 两部分采样:
- 短时记忆:最近 M 步内,每s1帧采一次(比如每 1-2 帧采 1 张)→ 保留眼前细节(如当前房间的床、衣柜位置);
- 长时记忆:更早的历史帧,每 s2帧采一次(比如每 5-10 帧采 1 张)→ 保留整体路径上下文(如 “从客厅进来,已经走过 2 个房间”)。
👉 比喻:像拍照,短时是 “连拍最近的关键画面”,长时是 “间隔拍几张之前的场景”,让模型既知道 “现在在哪”,也知道 “怎么来的”。
SFT 阶段用交叉熵损失,强制模型的输出和 “专家演示的真实动作序列” 对齐。
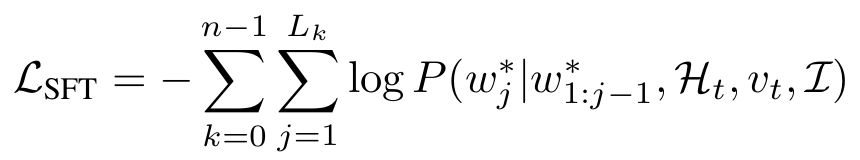
模型每生成一个动作 token(比如 “A”“Move”“forward”),都要和专家标注的 “正确 token” 对比,对不上就扣分。
SFT 阶段的目标不是让模型 “完美导航”,而是学会最基础的 “视觉 - 语言 - 动作” 映射
这些基础能力是后续强化微调(RFT) 的前提 ——RFT 会让模型在 “长距离导航” 中优化决策,但如果 SFT 没学好基础动作,RFT 也无从谈起。
6、强化微调(RFT)阶段:让模型从 “模仿专家” 到 “自主优化长程决策”
RFT 是 VLN-R1 训练的第二阶段,核心解决 SFT 的 “长距离导航缺陷”:
SFT 让模型学会了基础动作逻辑,但面对多步连续导航时,容易出现 “一步错、步步错” 的误差累积 (比如中间转错方向,后面路径全偏离)。
RFT 通过强化学习,让模型在 “试错中自主优化”,学会动态调整策略,减少长程导航的错误累积。要让模型学会:
- 动态调整:遇到 “专家没教过的场景”(如沙发位置变化),能自主调整动作;
- 减少误差累积:即使某一步小错(如左转角度差 10°),后续能修正,而非一路错到底;
- 策略优化:从 “被动模仿” 变成 “主动找更优动作序列”。
关键机制 1:时间衰减奖励(TDR)—— 给 “近期动作” 更高权重
人类导航时,刚做的动作对当前状态影响更大(比如刚左转转错了,马上会偏离路线),而远期动作的影响会被 “后续动作” 稀释。
TDR 模拟这一逻辑,给近期动作的奖励 / 惩罚更高权重。通俗理解:“近期错了更要命”
👉 TDR 的作用:精准惩罚 “早期关键错误”,鼓励模型优先优化近期动作(比如第一步、第二步),减少长程误差的根源。
关键机制 2:GRPO 算法 —— 让模型 “自己和自己比着学”
传统强化学习(如 PPO)需要额外训练 “评论模型”(判断动作好不好),但大型模型参数太多,训练评论模型效率低。
RFT 用 GRPO(组相对策略优化),让模型生成多个候选动作序列,互相对比选最优,无需额外模型。
GRPO 工作流程
- 生成多候选:针对同一指令 + 视觉输入,模型生成 G 个动作序列候选(比如 8 个不同的 6 步序列);
- 算奖励:用 TDR 给每个候选打分(比如候选 1 得分 4.2,候选 2 得分 3.8);
- 算 “相对优势”:对比组内平均,判断每个候选 “比平均好多少”(比如候选 1 得分比组内平均高 0.5,优势为正);
- 优化策略:调整模型参数,让优势高的候选更可能被生成,同时用 KL 散度限制与 “参考模型”(SFT 后的模型)的差异,避免学出 “离谱动作”。
| 对比维度 | SFT(有监督微调) | RFT(强化微调) |
|---|---|---|
| 学习方式 | 模仿专家(有监督,交叉熵损失) | 自主试错(强化学习,奖励驱动) |
| 优化目标 | 对齐专家动作序列(短距离精准) | 优化长程奖励(减少误差累积) |
| 关键输入 | 专家标注的 “真实动作序列” | 动态计算的 “奖励信号”(TDR) |
| 解决问题 | 基础动作逻辑(看画面、懂指令、做动作) | 长距离导航鲁棒性(修正累积误差) |
7、实验验证与效果
数据集:
- 使用 VLN-Ego作为训练数据集,其中有监督微调(SFT)阶段采用来自 R2R 和 RxR 数据集的 180 万样本,
- 强化微调(RFT)阶段则从每个数据集中随机选取 1 万样本,总计 2 万样本用于训练。
- 智能体仅通过第一视角视频导航至目标点,若在阈值距离内停止,该导航回合即视为成功。
使用VLN-CE 指标进行评估:
- 成功率(SR)、最优成功率(OS)、路径长度加权成功率(SPL) 衡量导航准确性;
- 导航误差(NE)、轨迹长度(TL) 评估导航效率。
所有距离测量结果均以米(m) 为单位报告。
训练细节:
- 训练了 Qwen2-VL-2B 和 Qwen2-VL-7B 模型,其中 7B 模型通过 DeepSpeed ZeRO-3 优化部署在 8 张 NVIDIA A800 GPU 上。
- 训练期间,图像被调整至最大分辨率 65536 像素,以每个实例 16 张图像的批次处理,生成约 4.1K tokens。
- 有监督微调(SFT)采用 5e-6 的学习率,搭配余弦调度(10% 预热),每 GPU 批次大小为 2,通过 4 步梯度累积实现全局批次大小 64,完成 1 个 epoch 需 36 小时。
- 强化微调(RFT)将学习率降至 1e-6,搭配 0.01 的权重衰减和 β=0.04,配置 GRPO 时每个提示生成 8 个样本,每 GPU 批次大小为 1(无梯度累积),完成 1 个 epoch 约需 12 小时。
在 VLN-CE R2R 验证不可见集(Val-Unseen)上的对比:
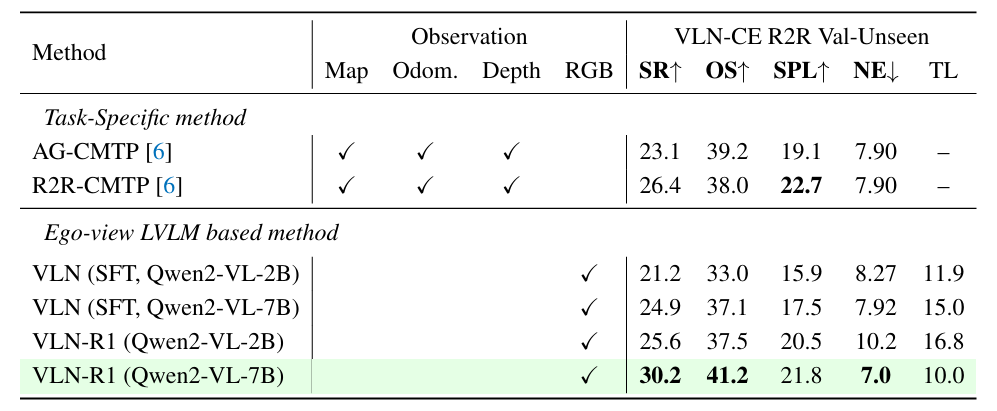
- “VLN(SFT)” 指的是第一阶段有监督微调后的结果。
- 经过强化微调(RFT)后,2B 模型的性能与 7B 模型相近。
在 VLN-CE RxR 验证不可见集(Val-Unseen)上的对比:
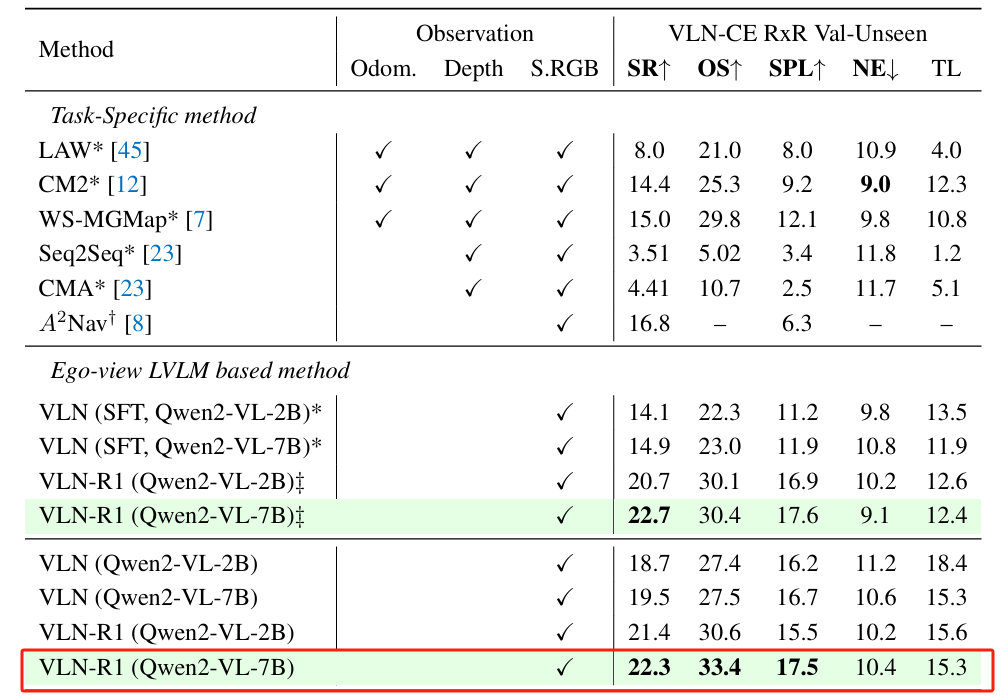
- ∗:仅在 VLN-CE R2R 上训练。
- ‡表示有监督微调(SFT)仅在 R2R 上训练,而强化微调(RFT)纳入了来自 RxR 的数据。
- 在 R2R 预训练后,仅用少量数据就能在 RxR 上取得良好结果
VLN R1 能够在连续环境中导航,最终到达目标位置:

分享完成~
相关文章推荐:
UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】具身导航 VLN 最新论文汇总 | Vision-and-Language Navigation-CSDN博客
【机器人】复现 UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】复现 WMNav 具身导航 | 将VLM集成到世界模型中-CSDN博客
【机器人】复现 SG-Nav 具身导航 | 零样本对象导航的 在线3D场景图提示-CSDN博客
【机器人】复现 3D-Mem 具身探索和推理 | 3D场景记忆 CVPR 2025 -CSDN博客
【机器人】复现 Embodied-Reasoner 具身推理 | 具身任务 深度推理模型 多模态场景 长远决策 多轮互动_embodied reasoner-CSDN博客
【机器人】DualMap 具身导航 | 动态场景 开放词汇语义建图 导航系统-CSDN博客
【机器人】ForesightNav | 高效探索 动态场景 CVPR2025_pointnav中的指标介绍-CSDN博客
【机器人】复现 HOV-SG 机器人导航 | 分层 开放词汇 | 3D 场景图-CSDN博客
【机器人】复现 DOV-SG 机器人导航 | 动态开放词汇 | 3D 场景图-CSDN博客
【机器人】复现 Aether 世界模型 | 几何感知统一 ICCV 2025-CSDN博客
【机器人】Aether 多任务世界模型 | 4D动态重建 | 视频预测 | 视觉规划 -CSDN博客