目录
5.将之前的训练结果转化为dataframe数据类型,将第五列按照大小排序
机器学习中的 TF-IDF:从原理到实践的文本特征提取利器
在机器学习处理文本数据的过程中,如何将纷繁复杂的文字转化为计算机能理解的数字特征,是一个至关重要的问题。而 TF-IDF 作为一种经典的文本特征提取方法,凭借其简单高效的特点,在自然语言处理领域占据着重要地位。本文将带您深入了解 TF-IDF 的原理、实现步骤、优缺点以及应用场景。
一.TF-IDF算法介绍
- TF-IDF用于从文章中提取核心关键词,由两部分组成:TF(词频)和IDF(逆文档频率)。
- TF(词频):某个词在文章中出现的次数除以文章总词数。例如,若“人工智能”在1000词的文章中出现50次,其TF值为0.05。
- IDF(逆文档频率):衡量词的区分能力,公式为log(语料库文档总数 / 包含该词的文档数 + 1)。若某词在语料库中罕见,其IDF值较高。
- TF-IDF:TF-IDF 值就是词频与逆文档频率的乘积,即 TF - IDF = TF×IDF。它综合考虑了词语在单个文档中的出现频率以及在整个文档集合中的分布情况。一个词语的 TF-IDF 值越高,就意味着它在当前文档中出现的频率较高,同时在其他文档中出现的频率较低,因此这个词语更能代表当前文档的特征。
二、TF-IDF 的核心原理
TF-IDF 的核心思想是:如果一个词语在一篇文档中出现的频率高,并且在其他文档中出现的频率低,那么这个词语就具有很好的区分能力,适合用来作为该文档的特征词。
从数学角度来看,词频(TF)衡量了词语在文档内的局部重要性,逆文档频率(IDF)衡量了词语在文档集合中的全局重要性。通过将两者相乘,得到的 TF-IDF 值既考虑了词语在当前文档中的突出程度,又考虑了词语在整个文档集合中的独特性。这样就能够过滤掉一些常见的、在大多数文档中都出现的词语(如 “的”“是”“在” 等虚词),而保留那些对特定文档更具代表性的词语。
例如,在一篇关于 “人工智能在医疗领域应用” 的文档中,“人工智能” 和 “医疗” 这两个词语的词频可能较高,同时在其他非相关主题的文档中出现的频率较低,因此它们的 TF-IDF 值会较高,适合作为该文档的特征词;而像 “的” 这样的虚词,虽然在该文档中的词频可能很高,但由于在几乎所有文档中都频繁出现,其 IDF 值会很低,因此 TF-IDF 值也会很低,不会被当作重要特征。
三、TF-IDF 的实现步骤
要实现 TF-IDF 特征提取,通常需要按照以下步骤进行:
(一)数据预处理
首先需要对原始文本数据进行预处理,这一步骤的目的是去除噪声,规范文本格式,为后续的处理做准备。主要包括以下操作:
- 分词:将连续的文本分割成一个个独立的词语,对于中文文本,常用的分词工具如 jieba;对于英文文本,可以直接根据空格和标点符号进行分割。
- 去除停用词:停用词是指那些在文本中出现频率很高,但对文本主题没有实质意义的词语,如中文的 “的”“了”“在” 等,英文的 “the”“a”“is” 等。可以通过加载预设的停用词表,将文本中的停用词去除。
- 大小写转换(针对英文):将英文文本中的所有词语统一转换为小写或大写,以避免 “Machine” 和 “machine” 被当作不同的词语处理。
- 词形还原 / 词干提取(针对英文):将词语还原为其基本形式,例如将 “running” 还原为 “run”,“better” 还原为 “good”,以减少词语的变体形式。
(二)计算词频(TF)
对于预处理后的每一篇文档,统计每个词语在该文档中出现的次数,然后除以该文档中词语的总数,得到每个词语在该文档中的词频。
(三)计算逆文档频率(IDF)
首先统计整个文档集合中的总文档数,然后对于每个词语,统计包含该词语的文档数,再根据 IDF 的计算公式计算出每个词语的逆文档频率。
(四)计算 TF-IDF 值
将每个词语在对应文档中的词频与逆文档频率相乘,得到该词语在该文档中的 TF-IDF 值。这样,每一篇文档就可以表示为一个由 TF-IDF 值组成的向量,向量的维度等于词汇表的大小(即所有文档中不重复词语的总数)。
(五)应用场景下的处理
在实际应用中,还可以根据具体需求对 TF-IDF 向量进行进一步的处理,例如进行归一化操作,使不同文档的 TF-IDF 向量具有可比性;或者选择 TF-IDF 值较高的词语作为文档的关键特征,减少向量的维度。
四、TF-IDF 的优缺点
(一)优点
- 简单直观:TF-IDF 的原理简单易懂,计算过程也不复杂,容易实现和理解。
- 效果较好:在很多文本分类、信息检索等任务中,TF-IDF 都能取得不错的效果,能够有效提取文本的关键特征。
- 计算高效:相比一些复杂的文本特征提取方法(如词嵌入),TF-IDF 的计算速度更快,对硬件资源的要求较低,适合处理大规模的文本数据。
- 可解释性强:TF-IDF 值的高低直接反映了词语对文档的重要程度,我们可以很直观地知道哪些词语是文档的关键特征。
(二)缺点
- 忽略词语顺序:TF-IDF 只考虑了词语在文档中出现的频率,而忽略了词语之间的顺序关系。例如,“我爱中国” 和 “中国爱我” 这两个句子,用 TF-IDF 表示后可能是相同的向量,但它们的语义却完全不同。
- 缺乏语义理解:TF-IDF 无法捕捉词语之间的语义关联,例如 “电脑” 和 “计算机” 是同义词,但在 TF-IDF 中它们会被当作两个不同的词语处理,无法体现它们的语义相似性。
- 对稀有词敏感:对于一些在文档中出现次数很少但可能很重要的稀有词,TF-IDF 可能无法很好地捕捉其重要性。因为稀有词的词频较低,即使其 IDF 值较高,TF-IDF 值也可能不高。
- 依赖文档集合:IDF 值的计算依赖于整个文档集合,当文档集合发生变化时,IDF 值也会发生变化,从而影响 TF-IDF 值的结果。
五、TF-IDF 的应用场景
TF-IDF 凭借其自身的特点,在自然语言处理领域有着广泛的应用:
(一)文本分类
在文本分类任务中,TF-IDF 可以将文本转化为特征向量,然后结合分类算法(如朴素贝叶斯、支持向量机等)对文本进行分类。例如,垃圾邮件识别就是一个典型的文本分类应用,通过提取邮件文本的 TF-IDF 特征,可以有效地区分垃圾邮件和正常邮件。
(二)信息检索
在搜索引擎中,TF-IDF 常被用来计算查询词与文档之间的相关性。当用户输入查询词后,搜索引擎会计算每个文档中查询词的 TF-IDF 值,然后根据 TF-IDF 值的高低对文档进行排序,将相关性最高的文档呈现给用户。
(三)关键词提取
TF-IDF 可以用来提取文档的关键词,选择 TF-IDF 值较高的词语作为文档的关键词,能够很好地概括文档的主题。这在文献管理、自动摘要等场景中非常有用。
(四)文本相似度计算
通过计算两篇文档的 TF-IDF 向量之间的余弦相似度,可以衡量两篇文档的相似程度。这在文本去重、抄袭检测等任务中有着重要的应用。
六、TF-IDF 的拓展与改进
虽然 TF-IDF 存在一些缺点,但研究者们也提出了一些拓展和改进方法:
(一)加权 TF-IDF
在传统的 TF-IDF 中,词频是简单的词语出现次数除以文档总词数。而加权 TF-IDF 则对词频进行了一些调整,例如使用对数词频(TF = log (1 + 词频)),可以避免词频过大对结果的影响;或者使用二进制词频(如果词语在文档中出现则为 1,否则为 0),只关注词语是否出现,而不关注出现的次数。
(二)结合语义信息
为了弥补 TF-IDF 缺乏语义理解的缺点,可以将 TF-IDF 与词向量等语义表示方法结合起来。例如,先通过 TF-IDF 筛选出重要的词语,然后将这些词语的词向量进行加权平均(权重为 TF-IDF 值),得到文档的语义向量。
(三)动态 IDF 计算
传统的 IDF 计算是基于整个文档集合的,但在一些动态变化的场景中(如实时更新的新闻数据),可以采用动态 IDF 计算方法,根据新加入的文档不断更新 IDF 值,使 TF-IDF 能够适应数据的变化。
七、总结
TF-IDF 作为一种经典的文本特征提取方法,以其简单、高效、可解释性强等优点,在自然语言处理领域得到了广泛的应用。它通过综合考虑词语的词频和逆文档频率,能够有效地提取文本中的关键特征,为文本分类、信息检索、关键词提取等任务提供有力的支持。
当然,TF-IDF 也存在一些不足之处,如忽略词语顺序、缺乏语义理解等。但随着技术的发展,研究者们不断对其进行拓展和改进,使其能够更好地适应不同的应用场景。
在实际应用中,我们需要根据具体的任务需求和数据特点,选择合适的文本特征提取方法。对于一些对计算效率要求较高、对语义理解要求不高的场景,TF-IDF 仍然是一个非常不错的选择。而对于那些需要深入理解文本语义的场景,则可以考虑结合词嵌入等更先进的方法。
希望通过本文的介绍,您对 TF-IDF 有了更深入的了解,能够在实际的机器学习项目中灵活运用这一强大的文本特征提取工具。
八.简单案例
task2_1.txt内容如下
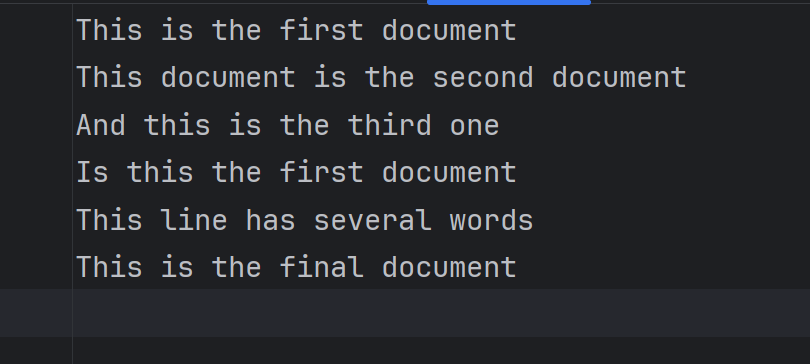
1.导入相关库
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd2.读取文件返回内容列表,每一行内容为列表的一个元素
file=open('task2_1.txt','r')
corpus=file.readlines()3.创建模型并训练
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpus)
print(tfidf)4.打印关键词
wordlist=vectorizer.get_feature_names()
print(wordlist)5.将之前的训练结果转化为dataframe数据类型,将第五列按照大小排序
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
feature = df.sort_values(by=5,ascending=False)
print(feature.iloc[:,5])
final 0.694384
document 0.411950
is 0.355752
the 0.355752
this 0.308237
and 0.000000
first 0.000000
has 0.000000
line 0.000000
one 0.000000
second 0.000000
several 0.000000
third 0.000000
words 0.000000
Name: 5, dtype: float64