背景意义
研究背景与意义
随着工业化进程的加快,颗粒物污染已成为全球范围内一个日益严重的环境问题。颗粒物不仅对空气质量造成影响,还对人类健康构成威胁,尤其是对呼吸系统和心血管系统的危害。为了有效监测和控制颗粒物的排放,开发高效的检测系统显得尤为重要。近年来,计算机视觉技术的快速发展为颗粒物检测提供了新的解决方案。基于深度学习的目标检测算法,尤其是YOLO(You Only Look Once)系列模型,因其高效性和实时性而受到广泛关注。
本研究旨在基于改进的YOLOv11模型,构建一个高效的颗粒物检测系统。该系统将利用一个包含3000张图像的专用数据集进行训练和测试,数据集中仅包含一种类别——颗粒物。这一单一类别的设计使得模型能够更加专注于颗粒物的特征提取与识别,从而提高检测的准确性和效率。通过对数据集的细致标注和处理,模型将能够在不同的环境条件下,准确识别和定位颗粒物。
此外,改进YOLOv11模型的引入,旨在提升检测精度和速度。YOLOv11在前代模型的基础上进行了多项优化,能够更好地处理复杂背景下的目标检测任务。通过引入更深的网络结构和更先进的特征提取技术,预计该模型将在颗粒物检测中展现出更强的鲁棒性和适应性。
综上所述,本研究不仅具有重要的理论意义,还对实际环境监测和污染控制具有积极的应用价值。通过构建高效的颗粒物检测系统,能够为环境保护提供科学依据,推动相关政策的制定与实施,从而为改善空气质量和保护公众健康贡献力量。
图片效果
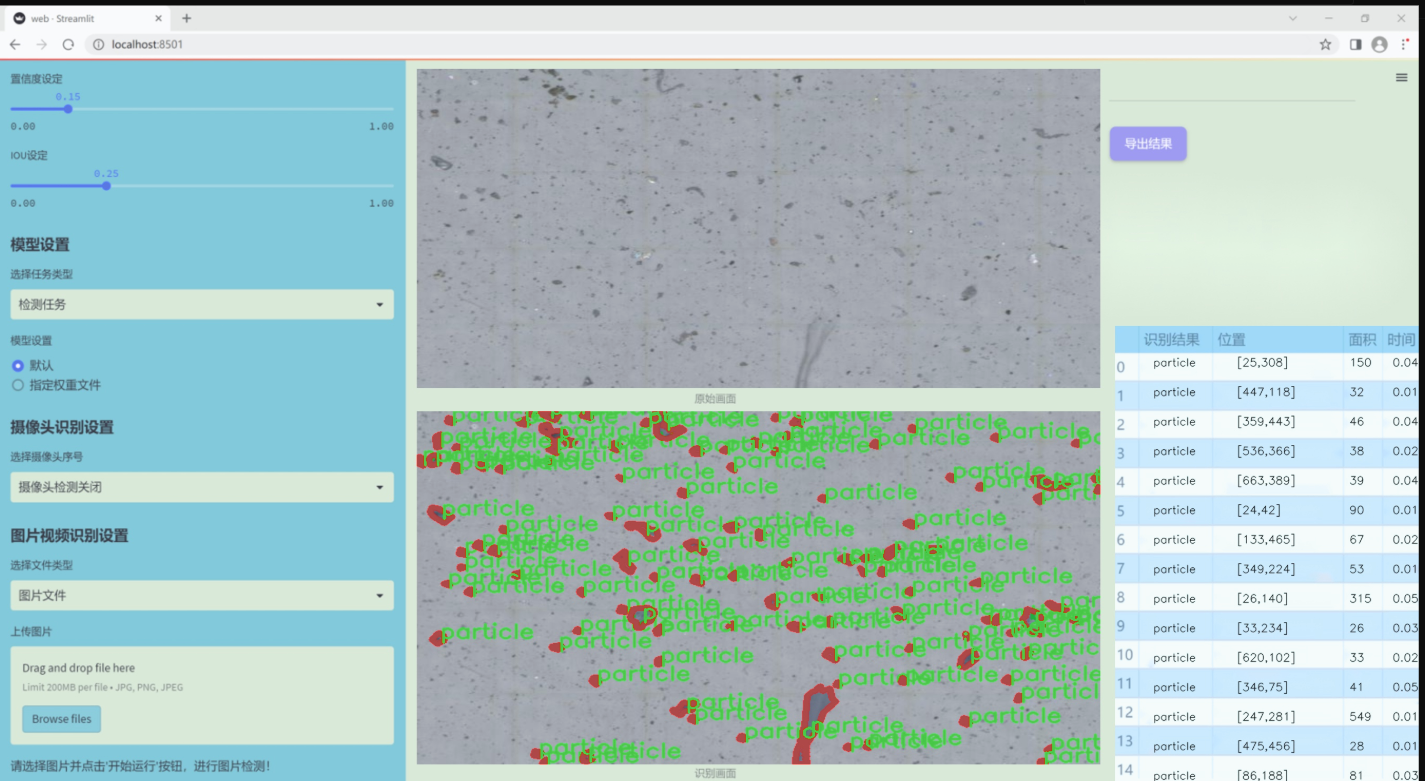
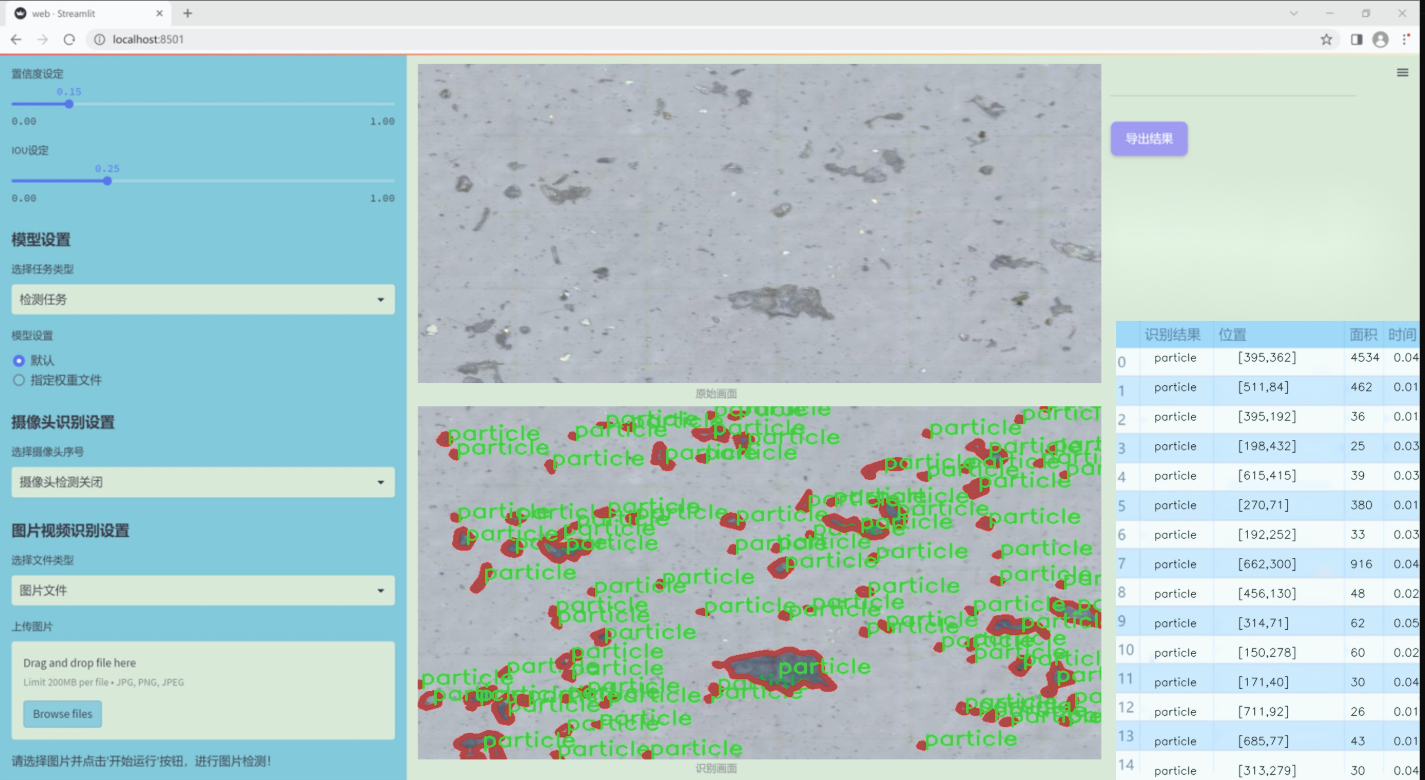
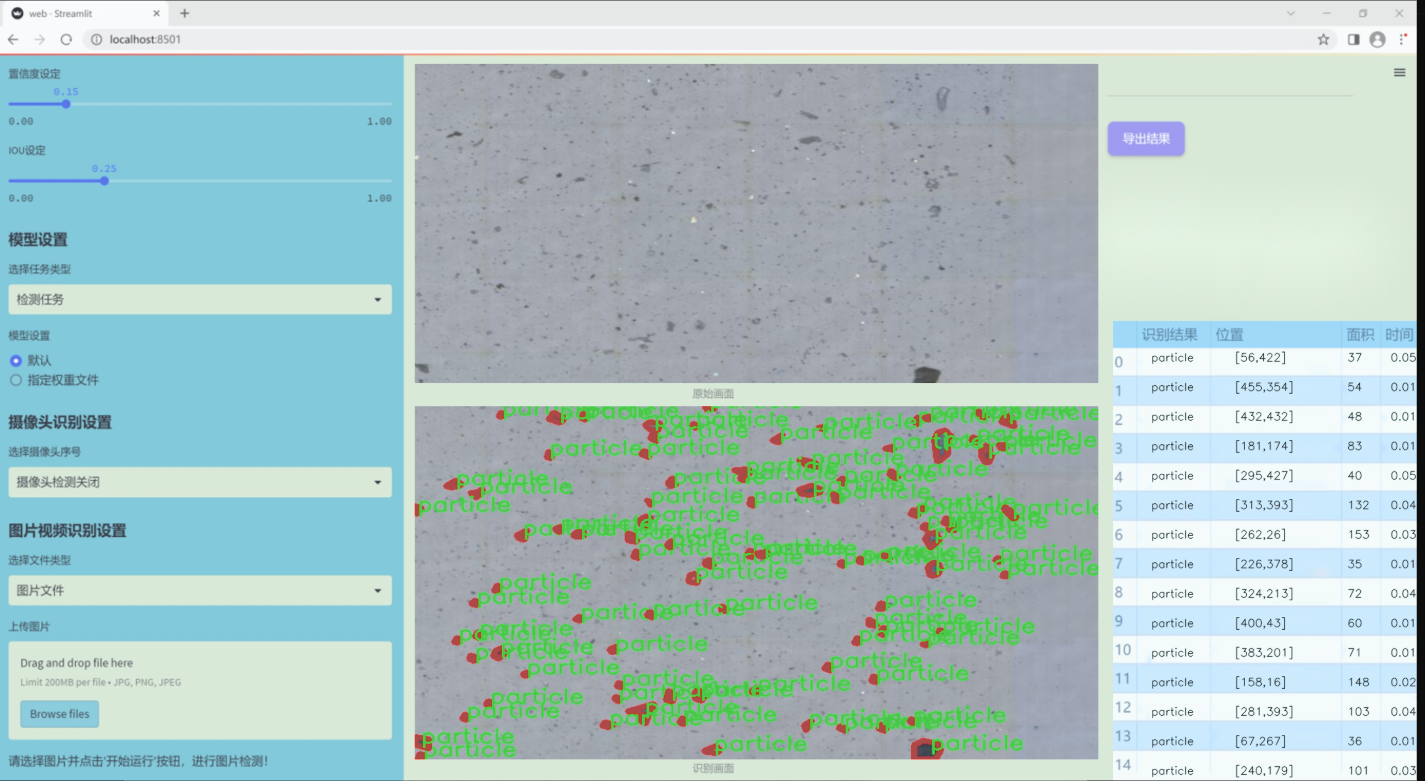
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“merged_projects_1”,旨在为改进YOLOv11的颗粒物检测系统提供高质量的训练数据。该数据集专注于颗粒物的检测,包含一个类别,即“particle”。这一类别的设定不仅简化了模型的训练过程,还使得系统在识别颗粒物时能够更加精准和高效。数据集中的样本经过精心挑选和标注,确保了每个图像都能真实反映出颗粒物的特征和多样性。
在数据集的构建过程中,研究团队注重样本的多样性和代表性,涵盖了不同环境下的颗粒物图像。这些图像来源于多种场景,包括工业生产、自然环境以及实验室设置等,确保模型在各种条件下都能保持良好的检测性能。此外,数据集中的图像质量经过严格把关,确保其清晰度和细节丰富性,以便于模型能够学习到颗粒物的细微特征。
通过使用“merged_projects_1”数据集,改进后的YOLOv11模型将能够更好地适应实际应用场景中的颗粒物检测需求。数据集的设计理念是以实用性为导向,旨在提高模型的泛化能力,使其能够在不同的环境中有效识别和定位颗粒物。这一数据集的构建不仅为研究提供了坚实的基础,也为后续的应用开发奠定了良好的数据支持,推动了颗粒物检测技术的进步与应用。




核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
from einops import rearrange
定义自定义的激活函数 h_sigmoid
class h_sigmoid(nn.Module):
def init(self, inplace=True):
super(h_sigmoid, self).init()
self.relu = nn.ReLU6(inplace=inplace) # 使用 ReLU6 激活函数
def forward(self, x):
return self.relu(x + 3) / 6 # h_sigmoid 的前向传播
定义自定义的激活函数 h_swish
class h_swish(nn.Module):
def init(self, inplace=True):
super(h_swish, self).init()
self.sigmoid = h_sigmoid(inplace=inplace) # 使用自定义的 h_sigmoid
def forward(self, x):
return x * self.sigmoid(x) # h_swish 的前向传播
定义 RFAConv 类
class RFAConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size, stride=1):
super().init()
self.kernel_size = kernel_size
# 权重生成模块
self.get_weight = nn.Sequential(
nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False)
)
# 特征生成模块
self.generate_feature = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU()
)
# 最终卷积层
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)
def forward(self, x):
b, c = x.shape[0:2] # 获取批次大小和通道数
weight = self.get_weight(x) # 生成权重
h, w = weight.shape[2:] # 获取特征图的高和宽
# 计算加权特征
weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2) # 归一化权重
feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) # 生成特征
weighted_data = feature * weighted # 加权特征
# 重新排列特征以适应卷积层
conv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)
return self.conv(conv_data) # 返回卷积结果
定义 SE 类 (Squeeze-and-Excitation)
class SE(nn.Module):
def init(self, in_channel, ratio=16):
super(SE, self).init()
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
b, c = x.shape[0:2] # 获取批次大小和通道数
y = self.gap(x).view(b, c) # 全局平均池化并展平
y = self.fc(y).view(b, c, 1, 1) # 通过全连接层
return y # 返回通道注意力
定义 RFCBAMConv 类
class RFCBAMConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size=3, stride=1):
super().init()
self.kernel_size = kernel_size
# 特征生成模块
self.generate = nn.Sequential(
nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),
nn.BatchNorm2d(in_channel * (kernel_size ** 2)),
nn.ReLU()
)
# 权重生成模块
self.get_weight = nn.Sequential(nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid())
self.se = SE(in_channel) # Squeeze-and-Excitation 模块
# 最终卷积层
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)
def forward(self, x):
b, c = x.shape[0:2] # 获取批次大小和通道数
channel_attention = self.se(x) # 计算通道注意力
generate_feature = self.generate(x) # 生成特征
h, w = generate_feature.shape[2:] # 获取特征图的高和宽
generate_feature = generate_feature.view(b, c, self.kernel_size ** 2, h, w) # 重新排列特征
# 重新排列特征以适应卷积层
generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size)
# 计算加权特征
unfold_feature = generate_feature * channel_attention
max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True) # 最大特征
mean_feature = torch.mean(generate_feature, dim=1, keepdim=True) # 平均特征
receptive_field_attention = self.get_weight(torch.cat((max_feature, mean_feature), dim=1)) # 计算感受野注意力
conv_data = unfold_feature * receptive_field_attention # 加权特征
return self.conv(conv_data) # 返回卷积结果
代码说明:
激活函数:
h_sigmoid 和 h_swish 是自定义的激活函数,分别实现了 h-sigmoid 和 h-swish 的前向传播。
RFAConv:
该类实现了一种卷积操作,使用自适应权重生成特征并进行加权。它通过 get_weight 和 generate_feature 两个模块来生成权重和特征,最后通过卷积层输出结果。
SE (Squeeze-and-Excitation):
该类实现了通道注意力机制,通过全局平均池化和全连接层来计算每个通道的重要性。
RFCBAMConv:
该类结合了特征生成、通道注意力和感受野注意力,最终通过卷积层输出加权后的特征图。
这个程序文件定义了几个深度学习模块,主要用于图像处理和特征提取,具体包括RFAConv、RFCBAMConv和RFCAConv等类。以下是对代码的详细讲解。
首先,程序导入了必要的库,包括PyTorch和一些自定义的模块。h_sigmoid和h_swish是两个激活函数的实现,分别对应于H-sigmoid和H-swish。这些激活函数在深度学习中常用于提高模型的非线性表达能力。
RFAConv类是一个卷积模块,它的构造函数接收输入通道数、输出通道数、卷积核大小和步幅作为参数。这个模块的主要功能是生成特征并进行加权卷积。它首先通过get_weight生成一个权重矩阵,然后通过generate_feature生成特征。接着,将特征和权重进行逐元素相乘,最后将结果重排并通过卷积层得到最终输出。
SE类实现了Squeeze-and-Excitation(SE)机制,它通过全局平均池化和全连接层来生成通道注意力权重。这种机制可以增强模型对重要特征的关注。
RFCBAMConv类是一个结合了RFAConv和SE机制的模块。它在生成特征后,利用SE机制计算通道注意力,并将其应用于生成的特征。接着,使用最大池化和平均池化计算的特征生成一个接收场注意力权重,并将其应用于特征数据,最后通过卷积层输出结果。
RFCAConv类是一个更复杂的模块,它结合了RFAConv和通道注意力机制。它首先生成特征,然后通过自适应平均池化计算特征的高和宽方向的特征。接着,将这些特征通过卷积层生成通道注意力,并将其应用于生成的特征。最终,通过卷积层输出结果。
整体来看,这个文件实现了一些先进的卷积操作和注意力机制,旨在提高卷积神经网络在图像处理任务中的性能。每个模块都通过组合不同的特征生成和注意力机制,旨在提取更丰富的特征信息,从而提升模型的表达能力和性能。
10.4 test_selective_scan_speed.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def build_selective_scan_fn(selective_scan_cuda: object = None, mode=“mamba_ssm”, tag=None):
“”"
构建选择性扫描函数,使用PyTorch的自定义自动求导功能。
参数:
selective_scan_cuda: CUDA实现的选择性扫描函数
mode: 模式选择
tag: 标签,用于标识
"""
class SelectiveScanFn(torch.autograd.Function):
@staticmethod
def forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):
"""
前向传播函数,计算选择性扫描的输出。
参数:
ctx: 上下文对象,用于保存状态
u: 输入张量
delta: 增量张量
A, B, C: 状态转移矩阵
D: 可选的偏置项
z: 可选的张量
delta_bias: 可选的增量偏置
delta_softplus: 是否使用softplus激活
return_last_state: 是否返回最后的状态
nrows: 行数
backnrows: 回溯行数
返回:
out: 输出张量
last_state: 最后状态(可选)
"""
# 确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if z is not None and z.stride(-1) != 1:
z = z.contiguous()
# 处理输入维度
if B.dim() == 3:
B = rearrange(B, "b dstate l -> b 1 dstate l")
ctx.squeeze_B = True
if C.dim() == 3:
C = rearrange(C, "b dstate l -> b 1 dstate l")
ctx.squeeze_C = True
# 检查输入形状的有效性
assert u.shape[1] % (B.shape[1] * nrows) == 0
assert nrows in [1, 2, 3, 4] # 限制行数为1到4
# 处理后向传播行数
if backnrows > 0:
assert u.shape[1] % (B.shape[1] * backnrows) == 0
assert backnrows in [1, 2, 3, 4]
else:
backnrows = nrows
ctx.backnrows = backnrows
# 根据模式调用不同的CUDA实现
if mode in ["mamba_ssm"]:
out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)
else:
raise NotImplementedError
ctx.delta_softplus = delta_softplus
ctx.has_z = z is not None
last_state = x[:, :, -1, 1::2] # 获取最后状态
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out if not return_last_state else (out, last_state)
@staticmethod
def backward(ctx, dout, *args):
"""
反向传播函数,计算梯度。
参数:
ctx: 上下文对象
dout: 输出的梯度
返回:
各输入的梯度
"""
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
# 调用CUDA实现的反向传播
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, ctx.backnrows
)
return (du, ddelta, dA, dB, dC, dD if D is not None else None, ddelta_bias if delta_bias is not None else None)
def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False, return_last_state=False, nrows=1, backnrows=-1):
"""
包装选择性扫描函数的调用,简化接口。
"""
return SelectiveScanFn.apply(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state, nrows, backnrows)
return selective_scan_fn
代码说明
导入必要的库:引入了PyTorch和相关的功能模块。
构建选择性扫描函数:build_selective_scan_fn函数用于创建一个选择性扫描的自定义函数。
前向传播:forward方法实现了选择性扫描的前向计算,处理输入张量的连续性和形状,并根据不同的模式调用相应的CUDA实现。
反向传播:backward方法实现了梯度计算,调用CUDA实现的反向传播函数,返回各输入的梯度。
简化接口:selective_scan_fn函数是对选择性扫描函数的包装,简化了调用方式。
这个核心部分的代码实现了选择性扫描的前向和反向传播,适用于深度学习中的状态转移计算。
这个程序文件 test_selective_scan_speed.py 主要用于测试和比较不同选择性扫描(Selective Scan)算法的速度和性能。它包含了一些自定义的前向和反向传播函数,利用 PyTorch 框架实现高效的计算。
首先,文件导入了必要的库,包括 PyTorch、Einops、时间处理和部分函数工具。接着,定义了一个 build_selective_scan_fn 函数,用于构建选择性扫描的前向和反向传播函数。这个函数使用了 PyTorch 的自定义自动求导功能,允许在 GPU 上高效执行计算。
在 SelectiveScanFn 类中,定义了 forward 和 backward 静态方法。forward 方法处理输入数据,执行选择性扫描的前向计算,返回计算结果。它支持多种模式(如 “mamba_ssm”、“sscore” 等),并根据输入的形状和类型进行必要的调整和检查。backward 方法则实现了反向传播,计算梯度。
接下来,定义了 selective_scan_ref 函数,这是一个参考实现,用于验证自定义选择性扫描的正确性。它通过逐步计算状态并结合输入的权重矩阵,生成输出。
此外,文件中还定义了 selective_scan_easy 和 selective_scan_easy_v2 函数,这些函数提供了更简化的选择性扫描实现,支持批处理和多种输入格式。
最后,test_speed 函数是文件的核心部分,它设置了一系列测试参数,包括数据类型、序列长度、批大小等。然后,它生成随机输入数据,并调用不同的选择性扫描实现进行性能测试。通过多次运行这些实现,记录执行时间,以便比较不同实现的速度。
整个文件的结构和实现方式旨在通过自定义 CUDA 核心函数来优化选择性扫描操作,以便在处理大规模数据时提高效率。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻