第3章:LLM推理服务器(SGLang/vLLM)
欢迎回到GLM-4.5探索之旅🐻❄️
在第1章:GLM-4.5模型家族中,我们认识了系统的强大"大脑"——GLM-4.5模型本身。接着在第2章:Claude Code服务集成,我们学习了如何将本地开发环境与运行在服务器上的这个"大脑"连接,使其成为交互式助手。
但想象一下,如果成百上千人同时向GLM-4.5提问或获取代码建议会怎样?
这个超级大脑体积庞大,需要大量资源(尤其是强大GPU)才能运行。
如果每个人都直接与之对话,它可能会不堪重负导致响应变慢甚至崩溃!
这正是LLM推理服务器如SGLang和vLLM的用武之地。
什么是LLM推理服务器?
将GLM-4.5这样的大语言模型想象成一台庞大、强大但笨重复杂的机器。
它需要特殊的"工厂车间"才能高效运作。**LLM推理服务器**正是这样的专用软件框架。
它如同高性能"模型配送卡车"或智能"工厂经理":
- 从存储中提取大型GLM-4.5模型
- 高效地将这个庞然大物加载到GPU等硬件上
- 最关键的是,它能
同时服务众多用户或应用,确保响应流畅迅速
为什么需要它们?
没有专用服务器,运行GLM-4.5这样的大模型将面临诸多挑战:
- 内存管理:大模型消耗大量GPU内存,推理服务器能智能管理内存确保模型平稳运行
- 高并发处理:基础设置可能逐个处理请求导致速度缓慢,推理服务器可将请求分组批量处理
- 低延迟响应:快速获得答案很重要,这些服务器采用先进技术最小化响应时间
- 资源优化:GPU昂贵,
推理服务器确保这些强大资源物尽其用,降低运营成本
简言之,SGLang和vLLM专为现实场景中高效、快速、稳定地运行GLM-4.5等大模型而设计,即使在高负载下也能应对自如。
认识SGLang与vLLM
SGLang和vLLM是两个专为大模型服务设计的流行开源框架,共同目标是最大化吞吐量(每秒处理请求数)和最小化延迟(单次请求响应时间)。
以下是它们的核心优势对比:
| 特性 | SGLang | vLLM |
|---|---|---|
| 核心优势 | 灵活控制,结构化生成 | 高吞吐量,高效内存利用 |
| 关键技术 | 推测解码,KV缓存共享 | 分页注意力,连续批处理 |
| GLM-4.5支持 | 优秀,深度集成 | 强大,广泛应用 |
暂时不必深究"推测解码"或"分页注意力"等技术术语(我们将在第6章:推理优化技术详细探讨)。现在只需知道,这些都是让GLM-4.5运行更快的智能技巧
LLM推理服务器工作原理(简化版)
当你向运行在推理服务器上的GLM-4.5模型发送请求时,以下是简化流程:
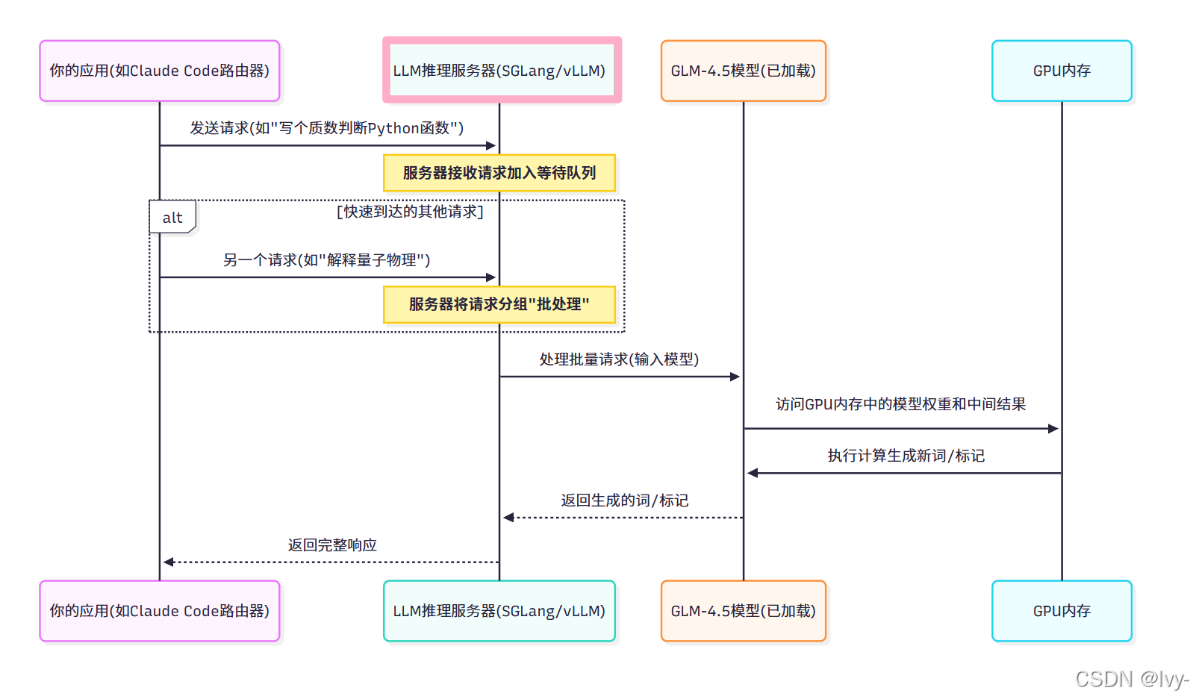
可以理解为 LLM推理服务器是给大模型加的一层负载均衡
使用SGLang和vLLM运行GLM-4.5
在第2章我们简要介绍了用SGLang启动GLM-4.5服务器的方法,现在同时看看vLLM的实现方式。
这些命令将GLM-4.5模型作为服务运行,使其可通过网络地址(如http://你的服务器IP:8000)访问。
使用SGLang
运行GLM-4.5需要先安装sglang(如第2章所述,pip install sglang)。
启动服务器命令:
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5 \
--served-model-name glm-4.5 \
--port 8000 \
--host 0.0.0.0
参数说明:
--host 0.0.0.0:使服务器可从任何网络地址访问。若仅限本机访问可使用127.0.0.1
运行后,GLM-4.5"大脑"就开始监听请求了
使用vLLM
类似SGLang,vLLM也提供模型服务命令。需先安装vllm(pip install vllm)。
启动GLM-4.5-Air模型的示例命令:
vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 8 \
--served-model-name glm-4.5-air
参数说明:
--tensor-parallel-size 8:高级设置,指示vLLM使用8块GPU分布式运行模型,可加速推理或运行更大模型
SGLang和vLLM都提供更多性能调优、内存管理和功能支持的选项,可在GLM-4.5项目的example/claude_code/README.md和example/AMD_GPU/README.md中查看详细配置。
小结
本章探索了LLM推理服务器,特别是SGLang和vLLM。
我们了解到这些软件框架如同GLM-4.5模型的"智能管家",高效加载模型、管理宝贵GPU内存、智能处理并发请求,确保GLM-4.5"大脑"能快速可靠地服务众多用户。
它们是实现GLM-4.5实时交互的核心引擎。
现在我们已经理解如何高效服务GLM-4.5模型,接下来让我们看看模型如何理解并执行复杂指令,特别是需要使用外部"工具"或通过推理解决问题的场景。
第4章:工具与推理解析器
在第3章:LLM推理服务器(SGLang/vLLM)中,我们了解到SGLang等强大的LLM推理服务器如何让GLM-4.5"大脑"实现高速高效运行,轻松应对高并发请求。
但仅有速度还不足以成为真正的智能助手。想象你向专家求助时,他们有时会直接给出答案,有时则需要:
- 使用工具:比如拿出计算器解决数学问题、上网搜索信息或编写运行代码验证想法
- 显式思考:通过头脑风暴、步骤规划或将复杂问题拆解后再给出最终答案
作为高级智能体的GLM-4.5模型同样需要这种能力
它需要判断何时使用外部工具,何时进入"思考模式"。这正是工具与推理解析器的用武之地。
什么是工具与推理解析器?
将这些解析器视为运行在推理服务器上的GLM-4.5模型内置的特殊"过滤器"或"解释器"。就像为GLM-4.5专家配备"智能眼镜",帮助其识别对话或问题中的特定线索,提示:"该使用工具了!“或"这个问题需要深入思考!”
在托管GLM-4.5模型的推理服务器(如SGLang/vLLM)中,这些组件被明确标识为glm45解析器。
让我们具体解析:
1. 工具解析器
- 功能:使GLM-4.5模型理解何时及如何与外部工具交互
- 类比:如同你朋友突然看到脑中弹出"网络搜索"或"运行代码"按钮。工具解析器帮助模型将内部"想法"转化为外部工具命令
- 示例:
- 提问:"东京当前天气如何?“借助工具解析器,GLM-4.5会意识到需要调用"天气API”(外部工具)获取信息
- 提问:"编写计算10的阶乘并返回结果的Python脚本"模型可能先写脚本,然后通过工具解析器决定用代码解释器工具执行脚本获取结果
2. 推理解析器
- 功能:帮助GLM-4.5进入复杂问题的"思考模式",在最终答案前生成内部思考、计划或分步推理
- 类比:如同朋友深呼吸后,在白板上草图构思,通过逻辑推演解决难题。推理解析器帮助模型结构化这种内部思考过程
- 示例:
- 提问:"规划巴黎三日艺术美食游详细行程"这不是简单查询。在推理解析器引导下,GLM-4.5可能先构建:
- “首日:抵达、卢浮宫、晚餐”
- “次日:奥赛博物馆、本地市场、烹饪课”
- “第三日:罗丹博物馆、告别晚宴”
经过内部优化后才呈现完整行程
- 提问:"调试这段复杂代码"模型可能分析代码、定位问题、假设解决方案并在脑中模拟执行步骤后才给出修复建议
- 提问:"规划巴黎三日艺术美食游详细行程"这不是简单查询。在推理解析器引导下,GLM-4.5可能先构建:
这些解析器共同使GLM-4.5成为能应对各类任务的万能助手,远超简单问答范畴。
GLM-4.5如何使用这些解析器
当在SGLang等推理服务器上启动GLM-4.5模型时,通过特定命令激活这些glm45解析器即可解锁魔法。
回顾前几章的SGLang服务器启动命令,现在加入关键解析器参数:
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
# ... (第3章的其他参数)
--served-model-name glm-4.5 \
--port 8000 \
--host 0.0.0.0
新增内容解析:
--tool-call-parser glm45:启用GLM-4.5专用工具调用逻辑。当模型生成类似工具命令的输出时,该解析器能理解并协助服务器执行--reasoning-parser glm45:启用GLM-4.5的专用推理模式,允许模型在最终答案前输出内部思考步骤,供Claude Code等应用展示
包含这两个参数就相当于激活了GLM-4.5模型的"专家能力"——使用工具和深度思考。
(完整命令可查看项目的example/claude_code/README.md文件)
底层原理:解析器工作流程
假设你通过Claude Code等应用连接GLM-4.5服务器,提出需要工具和思考的复杂问题。以下是工具与推理解析器在LLM推理服务器中的简化工作序列:
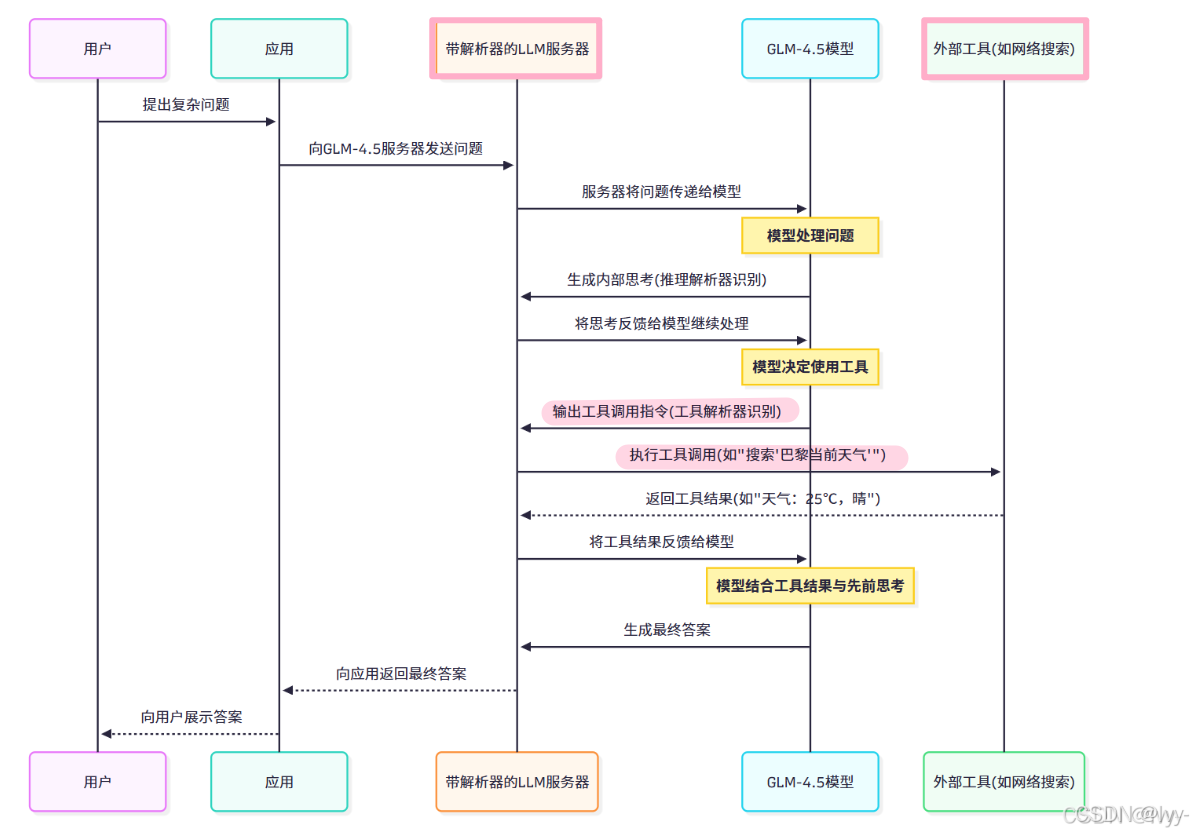
(模型通知服务器调用外部工具,服务器收到工具结果后,反馈给模型)
流程解析:
- 用户通过应用提问
- 应用将问题发送至启用解析器的LLM服务器
- GLM-4.5模型开始处理。推理解析器协助生成分步思考
- 思考过程中工具解析器识别外部工具需求,模型可能调用工具(如网络搜索或代码解释器)
- LLM服务器作为桥梁,将工具指令传递给外部工具执行,并将结果返回模型
- GLM-4.5模型结合工具结果与思考过程,形成最终智能响应
- 最终答案经服务器和应用返回用户
整个过程使GLM-4.5不再是简单文本生成器,而成为能动态多步解决问题、与外界交互的真正智能体。
小结
第3章介绍了GLM-4.5大模型推理服务器SGLang和vLLM的关键作用及工作原理。
阐述LLM推理服务器如同"智能管家",通过高效内存管理、批量处理和资源优化,使GLM-4.5模型能稳定处理高并发请求。
比较了SGLang(灵活控制)和vLLM(高吞吐量)的特性差异,并给出两种服务器的启动命令。
第4章聚焦工具与推理解析器,说明这些组件如何帮助GLM-4.5判断何时使用外部工具(如天气API)或进入深度思考模式。
通过添加"–tool-call-parser"和"–reasoning-parser"参数,可激活模型的专家级能力。
文章还展示了推理服务器处理复杂请求的完整工作流程,从用户提问到最终响应。
本章探索了工具与推理解析器。我们了解到这些glm45组件是LLM推理服务器中的关键模块,赋予GLM-4.5模型使用外部工具(如网络搜索或代码执行)和结构化"思考模式"处理复杂问题的能力。激活这些解析器后,GLM-4.5就能充分发挥其作为高级智能体的全部潜力。
现在我们已经理解GLM-4.5的思考与工具使用机制,接下来让我们看看如何通过配置部署确保其性能与功能的最优化。