介绍
在之前的章节中,读者已经学习了针对图像的“十八般武艺”,能够检测目标、分割物体甚至估计人体姿态。但是在真实世界中,万事万物都是运动的,因此需要掌握对视频流的“武技”。在本章中,我们将尝试理解这个运动的世界,具体来说,我们将介绍人体动作识别(human action recognition)。人体动作识别,顾名思义,是指识别视频中人类的动作,从而可以推断人物的意图和状态,为视频内容的理解提供重要信息。例如,在视频监控领域,人体动作识别可用于检测犯罪和安全事件:在体育赛事领域,人体动作识别可以用来分析运动员的技术和战术:在娱乐和广告领域,人体动作识别可以用来分析观众的反应和参与度。需要注意的是,这里讨论的是狭义的动作识别,即将动作识别理解成一个视频分类任务,如图15-1所示,而广义的动作识别则包含更细粒度的识别任务,如从视频中检测出某种动作对应的几帧。

在本章中,我们将首先介绍数据集与评测指标,然后动手学动作识别中的经典方法C3D
随便一提,不止使用C3D,我们还可以用大语言模型和图片分析模型对特定帧进行变化检测来实现视频多模态检索和动作识别,核心代码ipynb/visualrag.ipynb at main · hllqkb/ipynb
数据集和度量
目前人体动作识别常用的数据集包括以下3个。
(1)UCF101:UCF101数据集于2012年发布,它由YouTube中的部分真实世界视频组成,包含101种不同的动作类别。这些类别可以分为5种类型:人体运动、人与人交互、人与物体交互、演奏乐器和体育运动。UCF101数据集共有13320个视频片段,累计时长超过27h,所有视频的帧率固定为每秒25帧。
(2)Sports-1M:Sports-1M于2014年发布,是第一个规模较大的视频动作数据集,由超过100万个YouTube视频组成,其中标注了487种运动类别。由于类别的粒度较小,其类别间的差异较小。(3)DeepMind Kinetics human action dataset:Kinetics家族是目前应用最广泛的基准数据集。 2017年推出的Kinetics-.4004包含约24万个训练视频和2万个验证视频,涵盖400种人类动作类别,每类动作至少有400个视频片段,每个视频片段时长约为10s。随着时间的推移,Kinetics家族一直在不断扩大,2018年推出的Kinetics.-600包含超过49万个视频,2019年推出的 Kinetics-700包含超过65万个视频。
评测指标
在人体动作识别任务中,常用的评估指标如下。
精确度(accuracy)
精确度是处理分类任务最常用的评价指标,它表示分类正确的样本数占总样本数的比例。公式如下:
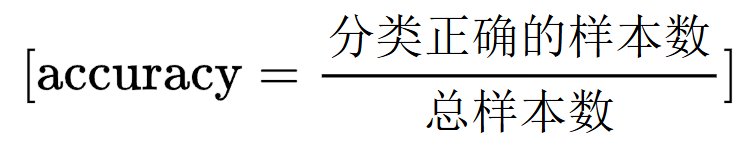
命中率(hit@k)
模型预测的前k个结果中是否包含了正确的标签。具体定义如下:
其中:
- ( M ) 是测试集中的视频序列数量;
- (
) 是第 ( m ) 个视频序列的真实动作标签;
- (
) 是模型对第 ( m ) 个视频序列预测的前 ( k ) 个标签集合;
- (
) 是指示函数(若条件满足则为1,否则为0)。
动作识别模型-C3D
视频数据不同于图像数据,它是一个连续的序列,为了识别出视频中的动作,我们需要考虑时间信息。在本节中,我们将介绍一个经典的动作识别模型C3D(convolutional 3D),它利用三维卷积网络来提取视频数据中的时空特征,从而实现高精确度的动作识别。
三维卷积
在介绍C3D之前,我们先来了解一下其核心组件 三维卷积。三维卷积是对二维卷积的自然扩展。在二维卷积中,卷积核在输入的二维数据(如图像)上滑动,计算邻近区域的加权和。而在三维卷积中,卷积核除了在宽度(W)和高度(H)上滑动外,还会在深度(D)上滑动,如图15-2所示。
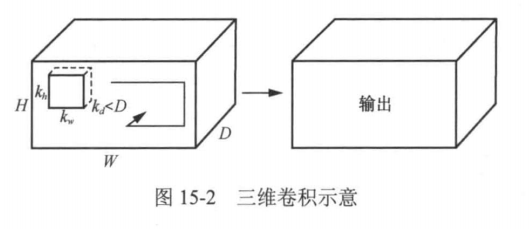
这里深度通常对应于视频帧的时间维度。给定视频序列S(假设其中的图像均为灰度图),将其理解成一个三阶张量,对其进行三维卷积的数学表达式为
其中:
是输入的三维数据(如视频的帧序列或体积数据)。
是三维卷积核(滤波器)。
是输出特征图的坐标 ((i, j, k)) 处的值。
分别表示卷积核在三个维度上的索引。
。三维卷积的补零、步长等操作与二维卷积类似,这里不做展开。下面展示一个简易的
三维卷积的例子
import torch
import torch.nn as nn
# -------------------------
# 1. 构造一个 3D 卷积层
# -------------------------
conv3d = nn.Conv3d(
in_channels=1, # 输入通道 (比如灰度体数据)
out_channels=2, # 输出通道数
kernel_size=3, # 卷积核 3x3x3
stride=1,
padding=1 # 保持尺寸
)
# -------------------------
# 2. 输入数据 (batch_size, C, D, H, W)
# -------------------------
# batch = 1, channel = 1, depth=16, height=64, width=64
x = torch.randn(1, 1, 16, 64, 64)
print("输入大小:", x.shape)
# -------------------------
# 3. 前向传播
# -------------------------
y = conv3d(x)
print("输出大小:", y.shape)
三维卷积与二维卷积相比,其主要优势在于能够直接处理视频数据的时间维度信息。二维卷积只在空间上进行操作,因此在图像上卷积后还需要设计融合时间信息的方法。而三维卷积能够直接捕捉视频序列的时间连续性,从而更有效地识别并分析动态场景和行为。这使得三维卷积在动作识别和其他视频分析任务中具有显著优势。
C3D模型
正因为三维卷积的优势,Du Tran等人于2014年提出直接使用三维卷积网络来提取视频数据中的时空特征,从而实现高精确度的视频动作识别。他们提出的C3D模型是一个端到端的三维卷积网络,由8个卷积层、5个池化层、2个全连接层和1个softmax层组成,其网络架构如图15-3所示。
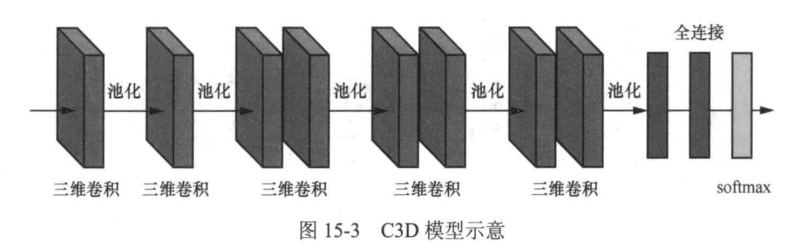
C3D模型的输入是16×112×112×3的视频数据,其中16表示输入的视频序列长度,112表示视频帧的宽度和高度,3表示视频帧的通道数。根据对二维卷积神经网络的研究发现,小的感受野(3×3卷积核)配合更深的网络架构可以获得最佳结果。因此,在C3D的架构搜索研究中,Du Tran等人将空间感受野固定为3×3,只改变三维卷积核的时间深度,并且通过实验发现,3×3×3的卷积核效果最好。 Du Tran等人通过在另一数据集上可视化学习到的特征来定性评估C3D的通用性,确认这些特征是否适合视频分析。具体来说,他们从 UCF101数据集随机挑选了10万个视频序列,使用C3D提取这些序列的特征,并使用t-SNE将特征映射到二维空间。图15-4展示了结果

同一动作的序列显示相同颜色。结果表明,C3D提取的特征区分明显,表明其能够有效地提取视频数据里面的时空特征。
C3D代码实现
首先下载数据集UCF101
下载后解压
tar -xzvf UCF101.tar.xz解压后目录类似:
当然还没完成!
我们还需要把文件夹名字从UCF101改成UCF-101
我们还需要UCF101数据集所需的训练列表文件
https://www.crcv.ucf.edu/data/UCF101/UCF101TrainTestSplits-RecognitionTask.zip
把zip解压到UCF101的根目录下,不能放在UCF101目录下,因为是txt文件不是avi
运行中我们可能遇到视频编解码功能已被弃用的报错
PyTorch 推荐使用新的 TorchCodec 库来处理视频编解码。您可以安装它:
pip install torchcodec然后我们要下载预训练权重
预训练权重文件在深度学习中具有重要的作用,尤其是在处理图像和视频等任务时。其主要用途和优点包括:
1. 加速训练过程
• 使用预训练权重可以显著减少模型的训练时间,因为网络已经学习到了一些通用特征。
2. 提高模型性能
• 预训练模型通常在大规模数据集上进行训练,能够捕捉到丰富的特征表示,从而在特定任务上表现更好。
3. 减少过拟合风险
• 在小数据集上训练时,使用预训练权重可以帮助模型更好地泛化,降低过拟合的风险。
4. 迁移学习
• 预训练权重使得迁移学习成为可能,用户可以在一个领域(如图像分类)上训练得到的模型权重,再将其应用于另一个相关领域(如物体检测或视频分析)。
是否可以不使用预训练权重直接训练?
当然可以!直接从头开始训练一个模型是可行的,尤其是在以下情况下:
• 大数据集: 如果你有足够大的数据集进行训练,模型可以自主学习到有效的特征。
• 特定任务: 对于某些特定任务,预训练的特征可能并不适用,此时从头开始训练可能会更有效。
• 实验需求: 在一些研究或实验中,你可能希望观察从零开始训练的效果,以了解模型的学习能力。
但是一般来说,使用预训练权重会更加高效,特别是在数据量有限的情况下。
为了减少训练时间和提升效果我们使用预训练模型
预训练模型下载
Download pretrained model from BaiduYun or GoogleDrive. Currently only support pretrained model for C3D.
从百度云或谷歌网盘下载预训练模型。
代码
本来我是打算直接手写复现的,不过一直有各种问题,为了节约时间我们可以直接用别人复现好的代码进行学习和使用
git clone https://github.com/Niki173/C3D.git操作流程
创建一个data文件夹,一个models文件夹,把下载的UCF-101文件夹放在data文件内,把下载的预训练权重文件放在models文件内。然后修改mypath.py文件相关的路径,inference.py文件标签路径,然后运行train.py文件便可。
我的mypath.py
class Path(object):
@staticmethod
def db_dir(database):
if database == 'ucf101':
# folder that contains class labels
root_dir = 'data/UCF-101'
# Save preprocess data into output_dir
output_dir = 'data/ucf101'
return root_dir, output_dir
elif database == 'hmdb51':
# folder that contains class labels
root_dir = '/Path/to/hmdb-51'
output_dir = '/path/to/VAR/hmdb51'
return root_dir, output_dir
else:
print('Database {} not available.'.format(database))
raise NotImplementedError
@staticmethod
def model_dir():
return 'models/c3d-pretrained.pth'运行train.py文件
由于我们使用了预训练模型训练效果和速度更好了许多

然后我们再用这个模型进行推理运行inference.py得到结果

这里还有个有趣的游戏demojfzhang95/project-demo: An Online Web Game "You Perform, I Guess!" based on C3D Model
小结
本章介绍了人体动作识别的基本原理、常用的数据集和评测指标,并详细分析了一个经典的动作识别模型一C3D。C3D模型利用三维卷积网络来提取视频数据中的时空特征,从而实现高精确度的动作识别。最后,我们展示了如何在UCF101数据集上训练和验证C3D模型,取得了不错的效果。回顾我们的动手学旅程,从图像的基础处理到图像及视频的语义理解,我们都在不停地贴近真实世界,而真实世界是三维的,因此接下来我们将介绍场景重建,探索计算机视觉算法在三维世界中的应用。