前言
相比单纯让机器人跳舞之类的locomotion,我个人对人形的loco-manipulation(含manipulation)更感兴趣,毕竟后者才能让机器人更好的干活,而非单纯的娱乐展示
毕竟虽然娱乐展示是不可或缺的,但真正推动社会前进的第一动力还是对生产效率的提升
然找我们做人形舞蹈定制开发的客户实在是有点多,虽然推掉了大部分的舞蹈定制,但还是有小部分盛情难却,这不,如此文的开头所说:7月份刚完成一人形舞蹈的交付
- 我在《一文通透ViT——把图片划分成一个个patch块后再做注意力计算,打破CNN在CV领域的统治地位(含Swin Transformer的详解)》的开头有说到,“长沙分部很快 要折腾两个新的具身项目了,到时候就是第二轮、第三轮的突飞猛进,至于第一轮突飞猛进是今25年6.4-7.19日 ”
- 那第二轮将开始于什么时候呢?很快了,因为自从7月份基于客户提供的G1完成一舞蹈的交付后,8月下旬已连签两个合同(一个机械臂、一个人形),客户们将在9月初 把机器寄到长沙分部
8月底又来了一个项目需求,客户还希望通过灵活的线上线下的方式,陪跑客户技术团队并让他们尽早具备机器人应用开发的能力(即指导客户的技术团队成员初步跑通训练的流程,包括指导动捕数据采集、模型强化训练等)
故,我还是不得不对人形跳舞之类的单纯locomotion继续予以高关注,并持续研究
于此,则关注到了本文要介绍的BeyondMimic、UniTracker
前者目前已开源,至于后者UniTracker
- 虽然截止到25年8.28日,该项目暂未开源,也不知他们 有无开源计划,但至少作为对本博客中locomotion系列文章的巩固——是有帮助的
- 目前该项目对外发布的视频效果 并未非常流畅,但探索的道路上,这些不完美是不可避免的,期待他们保持迭代吧
第一部分 BeyondMimic
1.1 引言、相关工作
1.1.1 引言
如BeyondMimic原论文所说,基于物理的角色动画近年来取得了显著进展 [1],[2],[3],[4],[5],能够将人体动作合成为用于全身控制的动态行为,以解决下游任务
然而,这些成功目前仍然局限于仿真环境,在仿真中,智能体拥有理想化的动力学、无限的驱动能力以及完美的观测条件,这与现实世界的人形机器人面临的未建模动力学、硬件限制和不完美的状态估计等问题截然不同
要在真实硬件上实现类似的能力,还需要两个尚未解决的关键能力:
- 一个可扩展的高质量动作追踪框架,能够将运动学参考转化为鲁棒且高度动态的动作,同时需要避免过度随机化、抖动和动作质量下降等问题;
- 一种有效的sim2real迁移方案,将学习到的运动基元蒸馏为单一策略,使其在测试时能够组合技能,实现灵活、目标驱动的控制,无需重新训练
对此,来自UC伯克利和斯坦福的研究者提出了BeyondMimic,这是一个面向现实世界的框架,能够同时解决上述两个挑战
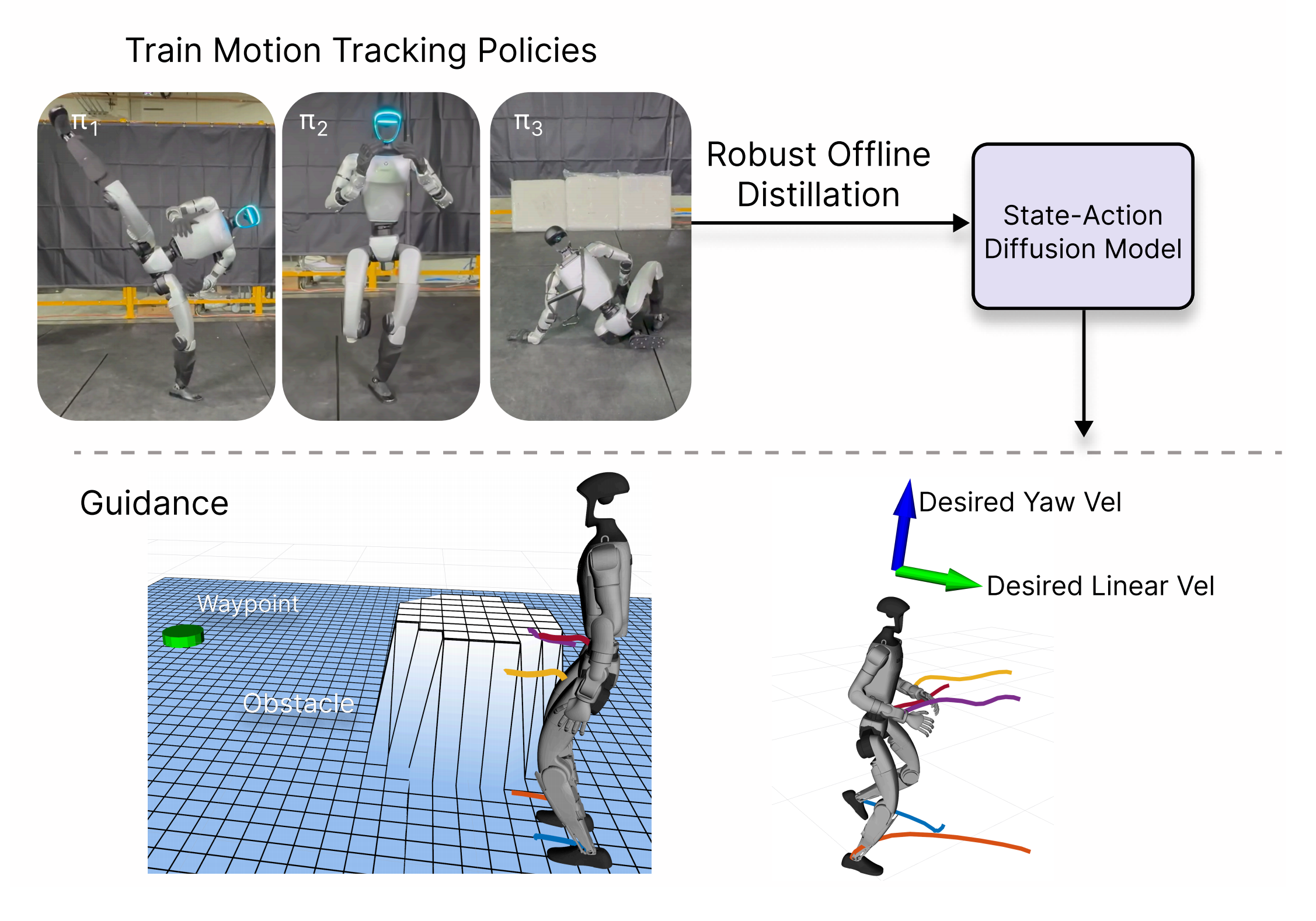
- 其对应的paper为:BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
其作者包括
Qiayuan Liao∗1 , Takara E. Truong∗2 , Xiaoyu Huang∗1 , Guy Tevet2 ,
Koushil Sreenath†1 and C. Karen Liu†2 - 其对应的项目网址为:beyondmimic.github.io/
其对应的GitHub为:github.com/HybridRobotics/whole_body_tracking
具体而言
- BeyondMimic 首先引入了一套运动跟踪流程,能够在真实的人形机器人硬件上以业界领先的运动质量完成高度动态的动作,如跳跃旋转、冲刺和侧手翻。不仅仅是简单地在人形机器人上模仿这些人类动作,他们的框架还提出了一种统一的引导扩散策略,将这些动作或技能合成为新颖的动作,实现零样本、任务特定的控制,仅需简单的代价函数,即可在测试时灵活地完成下游任务,无需额外重新训练
- 且作者在完整的sim2real流程中展示了BeyondMimic:包括训练鲁棒的跟踪策略,将其蒸馏为基于扩散的控制器,并最终部署到实际硬件上
最终,他们的系统能够执行广泛的任务,从航路点导航和操纵杆远程操作到避障,同时保持原始人类动作的自然风格和动态特性
通过弥合运动跟踪和扩散策略合成在sim2real迁移中的鸿沟,BeyondMimic 为推进可泛化的全身人形机器人控制提供了切实可行的基础
1.1.2 相关工作
首先,对于运动跟踪
- 早期基于学习的方法在足式机器人控制领域主要集中于手动设计特定任务的控制器[6],[7],[8],[9],这些方法能够实现鲁棒的运动控制,但每个任务都需要大量的奖励工程,缺乏自然的运动表现,并且难以扩展到通用控制所需的多样技能
- DeepMimic[10] 提供了一种替代方案,通过学习人类运动参考,实现自然且动态可行的行为,同时降低了奖励工程的负担,尤其适用于类人机器人。自那以后,许多基于 DeepMimic 范式的跟踪框架被开发出来。早期的动作追踪方法通常依赖于一小组相似的参考动作来训练单一任务策略。这些策略在与任务特定奖励共同训练的同时,结合了DeepMimic目标,从而生成能够以一种风格完成一个任务的控制器。例如,四足行走[11]和守门[12],以及双足跳跃和奔跑[13]
- 为了实现更为动态的技能,ASAP[14]提出采用真实到仿真的管道,通过硬件实验学习增量动作模型,以提升仿真逼真度。然而,这一方法需要针对特定动作训练增量动作模型,容易对精确的短动作产生过拟合
同样,KungfuBot[15]和HuB[16]通过精心设计的领域随机化,实现了高质量的仿真到现实迁移,但仅限于单一的短动作 - 为了突破单一动作策略的局限,近期研究探索了可扩展的动作跟踪框架,能够在单一策略内学习多样化的动作
在基于物理的动画领域,PHC [17] 是该类系统的代表性成果,激发了后续机器人领域构建通用动作跟踪器的尝试
早期机器人多动作跟踪器如 OmniH2O [18,具体如下图所示]、Exbody [19] 和 HumanPlus[20],验证了该方法的可行性,但与图形学领域的对应方法相比,其动作质量存在显著下降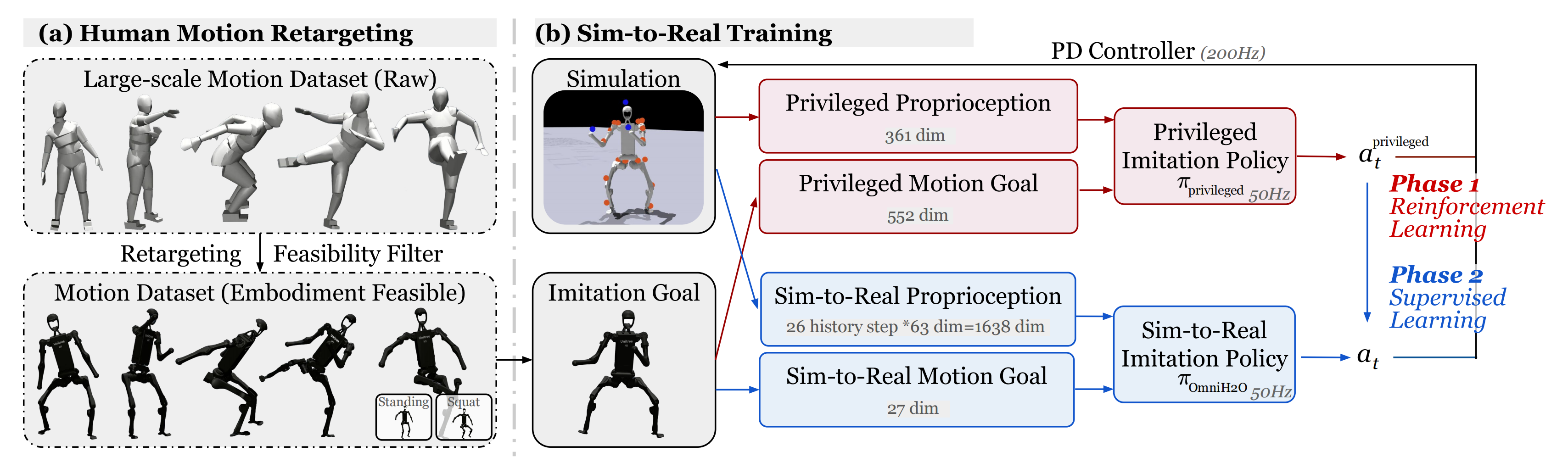
- 最近,TWIST [21] 实现了较高质量的动作跟踪,但主要针对静态动作。同样地,CLONE [22] 和UniTracker [23] 也主要关注低动态的行走动作,并配合上半身的响应式跟踪
另一方面,GMT [24]能够处理一定的动态运动,但为了提升鲁棒性,牺牲了全局轨迹跟踪,转而采用相对速度跟踪和步态正则化奖励 - Grandia 等人 [25] 目前提出了或许是质量最高的多运动跟踪方法,但仅在小型机器人上实现,且未包含动态运动。迄今为止,尚未有在真实人形机器人硬件上实现高运动质量且支持高度动态技能的多动作跟踪
本BeyondMimic研究旨在填补这一空白,通过跟踪包含多种风格和难度、持续数分钟的人类参考动作,实现多样化的人体动作跟踪
其次,对于扩散在机器人技术与角色动画中的应用
去噪扩散模型正逐渐成为机器人技术与动画领域中强大的策略生成器,因为它们能够自然地处理多模态分布以及长时序序列
- 在角色动画中,运动学扩散模型通过文本[26]、音乐[27]、几何约束[28]或损失函数[29]等方式提供直观的条件设定。这类规划器通常与独立的低层控制器结合,用于物理执行[28]、[30]
- 然而,这种两阶段方法往往存在“规划-控制鸿沟”,即规划器生成的运动超出了控制器能够稳健跟踪的分布范围[3]。这种脆弱性还因重新规划频率选择的挑战而加剧:重新规划不够频繁时,系统难以适应环境变化;而过于频繁的重新规划则可能导致智能体无法坚持连贯的策略。虽然在线重新规划在仿真中表现出一定前景[30],但在现实世界中尚未得到验证
为避免规划与控制之间的鸿沟,另一类研究工作专注于学习一种端到端的单一策略,该策略可直接从状态映射到动作分布
- 这一方法,即DiffusionPolicy [31],自然而然地扩展到运动控制和角色控制。例如,DiffuseLoco [32] 和 BiRoDiff [33] 学习了统一的策略,能够编码广泛的技能,实现平滑的步态切换,并在四足机器人上实现了鲁棒的实际部署
同时,PDP [34] 将该框架扩展到基于物理的动画,展示了文本提示跟随和多模态行为在抗推倒恢复中的应用 - 在强化学习训练中采用扩散或流匹配策略,也在运动跟踪任务中展现出更高的总体回报和效率 [35]。然而,尽管这些策略有效,却缺乏灵活的测试时条件机制,例如基于损失引导的扩散。这是因为很难将状态空间中定义的任务目标与关节空间中定义的动作序列直接进行比较。因此,针对新任务进行条件适应通常需要重新训练
- 第三类方法试图通过对状态和动作的联合分布进行扩散,将规划器的灵活引导与端到端策略的鲁棒性相结合。这使得在测试阶段能够通过基于分类器的奖励[36]或对未来状态目标的条件约束[37]进行引导
Diffuser[36]首次将该方法应用于离线强化学习,但其鲁棒性表现有限
Decision Diffuser[37]同样对状态-动作轨迹进行建模,但最终得出结论认为这些动作缺乏鲁棒性,并用逆动力学后处理方法进行了替换
相比之下,Diffuse-CLoC[3] 利用基于 PDP [34] 的鲁棒离线蒸馏技术,并通过这种联合扩散策略在基于物理的动画中展现出强劲的性能。然而,将引导式、联合状态-动作扩散模型应用于复杂的现实世界机器人控制仍然是一个未解难题,而本工作正致力于解决这一挑战
1.2 可扩展运动追踪
在本节中,作者详细介绍了用于训练运动追踪策略的可扩展流程。该流程在采用相同的马尔可夫决策过程(MDP)和超参数的情况下,能够从仅有几分钟的参考运动中生成高质量的仿真到现实策略,展现了在多样化运动场景下的可扩展性
需要注意的是,由于我们的追踪框架不包含历史信息,为了表述清晰,公式中省略了时间步。我们使用下标
表示参考运动中的相关量。除非另有说明,本节中所有数值均以世界坐标系表示
1.2.1 跟踪目标
作者从重定向后的参考动作开始,将其表示为广义位置和速度的关键帧。利用正向运动学,为每个身体
获得其位姿
和twist
,其中
是所有机器人身体的集合。目标是在硬件上以全局坐标高保真地复现参考动作
在训练过程中,为了增强鲁棒性而引入的扰动,以及sim2real的差距,通常会导致不可避免的整体漂移。为了在允许漂移的同时保持运动风格,控制器不应跟踪绝对的身体姿态
因此,作者选择一个锚定刚体,通常为根部或躯干,并将运动参考锚定到期望的跟踪目标,如下所示:
- 对于锚定刚体,直接使用参考运动:
- 对于非锚定刚体
,期望的姿态计算为
,其中
是参考运动中锚定刚体的姿态,而
,其中
这种混合变换通过保持高度、对齐偏航角以及在机器人下方平移原点,将运动转换到机器人的局部坐标系中。最后,期望的速度保持不变,即
,
机器人通常具有许多紧密排列的部件。因此,跟踪所有部件既低效又常常没有必要。相反,作者选择目标部件的一个子集,将运动跟踪目标表述为
1.2.2 观测
作者将策略观测空间构建为一个单步向量,由三个部分组成
- 参考相位
作者包含来自参考动作的关节位置和速度,,仅作为相位信息;策略本身并不用于直接跟踪关节值这些参数
- 锚点姿态跟踪误差
包含锚点主体的姿态跟踪误差,,其由三维位置误差和旋转误差矩阵的前两列组成[38]。由于参考运动在世界坐标系中预定义,该项隐式地为平衡提供了方向,并为修正漂移提供了全局位置
- 其他本体感知
作者包含用根坐标系表示的机器人根部扭转、关节位置
和速度
,以及前一个动作
完整的观测空间定义为
请注意,当无需进行位置漂移补偿或无法获得可靠的状态估计时,可以省略线性分量(即的平移部分和
的线性分量)
此外,作者采用非对称的 actor–critic 方法以提升训练效率。除了策略观测外,critic 还接收相对于锚点的每个身体部分的相对姿态,使其能够直接在笛卡尔空间中估算各身体部位的跟踪误差
1.2.3 关节阻抗与动作
在动画和机器人领域,添加关节阻抗是一种标准方法
- 许多角色动画研究 [10],[17],[34] 采用高阻抗以实现精确跟踪,从而有效地将自由空间中的控制简化为近似运动学问题
然而,在这种高阻抗设置下训练的策略通常并不适合在硬件上部署,因为它们会放大传感器噪声,降低吸收冲击所需的被动顺应性,并且阻碍了从当前和先前指令中隐式获取力矩信 - 相比之下,作者依据 Raibert 等人 [39] 的方法,启发式地设置关节刚度和阻尼:
,
,其中
为固有频率,
为阻尼比,
为第
个关节的等效惯量关节
作者选择阻尼比(过阻尼),而不是Raibert等人[39]中采用的1 (临界阻尼),因为仅考虑电机转子而忽略表观连杆惯量时,惯量通常被低估
自然频率设置为相对较低的10 Hz,这有助于在保持适度增益的同时实现柔顺性
策略动作被设计为归一化的关节位置设定值:,其中
为策略动作输出,
为常数标称关节构型,
,其中
表示关节
的最大允许关节力矩
该启发式假设接触通常发生在 附近,并且机器人硬件设计确保最大关节力矩与期望负载成正比。在低增益时,这些设定值并非用作期望位置目标;相反,它们作为生成期望力矩的中间变量,并且有意不受关节运动学极限的裁剪
1.2.4 奖励
作者以简单、直观且通用的方式设计奖励,包括
- 任务奖励作为正向、统一的奖励加权,并在任务空间中表达
- 最小化正则化惩罚,以避免损害跟踪性能
任务奖励是身体跟踪奖励
- 首先,作者根据期望的
和实际的
姿态与切向,针对每个目标身体b ∈Btarget 计算误差指标:
,以及
,假设方向误差较小
- 然后,在所有目标身体上计算均方误差:
接着,每个误差指标使用高斯型指数函数进行归一化:,其中
是通过经验确定的标称误差
综合任务奖励定义如下:
在正则化方面,作者仅包含三项对仿真到现实对齐至关重要的惩罚项。其中,关节限位惩罚rlimit 鼓励关节位置保持在软限位范围内。动作速率惩罚 rsmooth 鼓励连续动作的平滑性,避免策略产生过度抖动
为惩罚自碰撞,作者统计自接触力超过预设阈值的刚体数量,作为总惩罚rcontact,统计对象为 b /∈ Bee ⊆ B,其中 Bee为末端执行器刚体集合
最终的总奖励定义为
其中,,定义了奖励权重
可选地,可以为锚体 添加全局跟踪奖励,其结构与
相同,但使用
和
1.2.5 终止与重置
一次试验在两种情况下终止,表明发生了跌倒或跟踪失败:
当锚定体
的高度或姿态(仅考虑俯仰和横滚)误差超过预设阈值时
- 或(2)当任何末端执行器体
的高度与参考轨迹有显著偏离时
在每次回合重置时,运动阶段会从整个参考轨迹中自适应采样(下节马上会讲,对应于原论文第 III-F 节)。机器人被初始化到相应的参考构型和速度,同时施加额外的随机扰动以增强鲁棒性
1.2.6 自适应采样
训练长序列的运动不可避免地会遇到一个问题,即并非所有片段的难度都相同。因此,以往工作中常用的对整个轨迹进行均匀采样的方法 [14],[34],[17],往往会对简单片段过度采样,而对难度较高的片段采样不足,导致奖励的方差增大,训练效率降低
因此,自适应地在更难的区域进行更频繁的采样是自然而然的。为实现这一目标,作者将整个运动的起始索引划分为 S 个每秒为一组的区间,并根据经验失败统计数据对这些区间进行采样
设 和
分别表示在第
个区间内开始的实验次数和失败次数。为防止因短期波动导致采样出现离散跳变,失败率通过指数移动平均方法在时间上进行平滑处理
由于故障更有可能是由于终止前不久采取的次优动作引起的,作者采用了一个具有指数衰减核的非因果卷积,其中
为衰减率,以对近期发生的故障赋予更高的权重。最终从Bin s 中采样的概率为
其中, 是第
个区间的平滑失败率。我们进一步将概率
与均匀分布混合,以保持对较易区间的覆盖并减轻灾难性遗忘,使用
,其中
为均匀采样比例。起始区间随后从
中抽取,优先考虑具有挑战性的区域
1.2.7 域随机化
作者采用了三种域随机化参数:地面摩擦系数、默认关节位置 (同时作用于动作和观测,实际上模拟了关节偏置校准误差),以及躯干的质心位置
此外,作者在训练过程中引入了环境扰动,以促使机器人学习对环境变化具有鲁棒性的策略
// 待更
第二部分 UniTracker——面向人形全身运动追踪器的学习:为解决师生框架的局限性,将CVAE集成到学生策略架构中
2.1 引言、相关工作、问题表述
2.1.1 引言
如UniTracker原论文所说,近期的研究探索了多种针对人形机器人全身控制器的控制接口,这些接口大致可以分为稠密控制信号和稀疏控制信号
- 稠密信号(如遥操作[1,2,3,4,5,6]、离线动作数据集[7,8,9,10,11,12,13]以及基于视频的动作估计[14,15])能够提供丰富的轨迹级信息
- 相比之下,稀疏信号(如高层任务指令和基于虚拟现实的引导[16,17])仅提供极少的信息,往往导致动作质量下降
在本UniTracker的研究中,作者专注于通用全身动作跟踪任务,其中输入为参考动作序列,目标是通过单一策略实现对该序列的鲁棒且富有表现力的跟踪
广泛采用的一种运动跟踪策略学习范式是教师-学生框架
- 在该范式中,教师策略首先利用完整的特权观测,在仿真环境中精确跟踪参考动作
- 随后,学生策略仅基于部署时可用的部分观测,学习模仿教师策略
尽管该教师-学生框架行之有效,但现有实现方式,特别是采用简单MLP(多层感知机)结构的DAgger架构[18],存在三大显著局限
- 首先,在蒸馏过程中,这些方法常常无法保留原始参考动作中固有的多样性,导致行为趋于平均化且表现力不足
- 其次,受限于其有限的表示能力,此类模型通常在面对未见过的动作序列时泛化能力较差
- 第三,训练过程中缺乏全局上下文信息,导致如方向漂移等问题,以及全局行为上的更大不一致性,这些问题在策略部署到真实人形机器人上时尤为突出
为了解决现有师生框架的上述局限性,来自1 Shanghai Jiao Tong Univeristy, 2 Shanghai Artificial Intelligence Laboratory, 3 Peking University, 4 Zhejiang University, 5 The Hong Kong University of Science and Technology (Guangzhou), 6 ShanghaiTech University的研究者提出了UniTracker——一个统一且具表现力的全身跟踪框架,将条件变分自编码器(CVAE)[19]集成到学生策略架构中

- 其对应的论文为:UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
其对应的作者包括
Kangning Yin1,2∗, Weishuai Zeng2,3∗, Ke Fan1,2, Zirui Wang2,4
Qiang Zhang5,Zheng Tian6, Jingbo Wang2, Jiangmiao Pang2, Weinan Zhang1,2 - 其项目网址为:Humanoid-UniTracker/
截止到25年8月底,为开源,且不确定其是否有开源计划,回头我再问下相关作者
通过对受未来运动参考条件约束的结构化潜在空间进行显式建模,UniTracker使策略即使在部分观测条件下,也能生成多样且高保真的行为
- 从概率角度来看,潜在变量捕捉了从观测到动作映射中固有的不确定性,使策略能够对可能的运动行为建模分布,而不仅仅收敛于单一的确定性输出。这一能力增强了运动表现力,并显著提升了在多样且未见过的运动模式下的泛化能力
- 此外,基于CVAE的框架还有效解决了全局上下文缺失这一难题——这一问题在部署过程中常表现为方向漂移及其他全局不一致性
为此,作者在训练阶段采用了任务感知特征建模:编码器利用具有特权的全局信息观测进行训练,以推断结构化的潜在表示;
同时,先验网络则仅基于部署时可用的部分观测数据进行同步训练(相当于基于CVAE的学生策略以实现部分观测下的部署)
总之,这两种分布通过KL散度目标进行对齐。因此,尽管最终部署的策略在部分可观测的环境下运行,但由于训练过程中潜在空间受到了全局上下文的指导,策略依然能从中获益。这种对全局信息的隐式融入,使得在实际环境中表现出的行为更加连贯且具备全局一致性
====
简言之,通过CVAE建模实现多样性感知和全局上下文整合的策略:采用条件变分自编码器(CVAE)以捕捉动作多样性并编码全局上下文,通过将具备全局信息的编码器与部分观测先验对齐,从而实现更具表现力的行为并减少全局不一致性 - 最后,尽管基于CVAE的通用策略在广泛的动作范围内表现出色,但并不需要也不现实地期望它能够完美跟踪所有可能的参考序列——尤其是那些罕见、高度动态或远离训练分布的序列
为应对这些具有挑战性的情况,作者引入了一个快速自适应阶段,以任务为中心对通用策略进行微调
说白了,就是用于特定动作快速微调的轻量级快速自适应阶段
该自适应过程利用基础策略的表达能力和通用性,实现了在极短训练时间内的快速专业化
且他们的框架支持单序列自适应和批量自适应两种方式,从而在处理多个复杂动作时实现可扩展的精细优化。这个最终阶段通过将通用策略的实际适用性扩展到边缘案例,进一步突显了他们三阶段训练框架的模块化和灵活性
2.1.2 相关工作:遥操作、离线运动数据集、基于视频的运动估计、高层任务指令
全身控制对于使人形机器人能够执行各种复杂任务至关重要
- 在强化学习兴起之前,研究人员主要依赖传统的基于优化的控制方法来实现人形机器人的全身控制[31,32,33,34,35,36,37]
这些方法通常需要对机器人及其环境进行明确的数学建模,并通过实时优化来计算机器人的下一个动作。然而,此类方法往往难以适应环境变化,导致鲁棒性有限。此外,它们在在线执行过程中会带来较大的计算负担 - 为克服这些局限性,强化学习(RL)作为一种强有力的替代方案出现,能够通过与环境的直接交互学习自适应、鲁棒的控制策略,而无需依赖显式建模
目前,基于强化学习的人形机器人全身控制器可根据其控制信号的来源进行分类,包括
- 遥操作[1,2,3,4,5,6]
遥操作是指通过人类输入实时直接控制人形机器人,通常借助动作捕捉系统或可穿戴传感器,使机器人能够高保真地模仿人类动作。该领域的代表性工作包括Twist[1]和H2O[4],二者均采用了两阶段的师生框架。主要区别在于策略观测空间的设计 - 离线运动数据集[7,8,10,11]
离线运动数据集由预先收集的人类或人形机器人运动序列组成,这些数据被用作训练控制策略进行动作模仿的参考
代表性工作有Exbody[11]和Exbody2[10],其方法首先精心整理离线运动数据集,然后尽可能将上半身和下半身动作解耦,旨在保持下半身的稳定性,同时鼓励上半身的多样性和表现力
此外,最新的工作GMT[12]首次展示了通过单一统一策略跟踪8,000种动作 - 基于视频的运动估计[14,15][5,6]
基于视频的运动估计方法利用视频中的视觉输入提取人体运动数据,然后用于引导人形机器人控制策略。这一方法使得能够从大规模、多样化的动作来源中进行学习,而无需直接依赖人类示范
具有代表性的工作是 VideoMimic [14],其提出了一个真实-仿真-真实(real-to-sim-to-real)流程,用于建模机器人及其周围环境 - 以及高层任务指令[16,17]
任务指令指的是高层次、稀疏的控制信号,用于指定期望的结果或目标,例如行走方向或目标位置,而非详细的关节级动作,从而通过抽象实现高效的全身控制
代表性工作包括 Hover [16] 和HugWBC [17]
Hover 将多种控制模式统一到单一策略中,实现了各模式之间的无缝切换,同时保留了每种模式的优势,因此为类人机器人控制提供了强健且可扩展的解决方案
2.1.3 问题表述
作者将类人机器人全身运动追踪的问题表述为一个以目标为条件的RL任务,其中
- 策略π 被训练用于在全身层面追踪参考运动
- 状态
包括机器人的本体感知信息
以及目标
,后者指定了所有身体部位的目标状态
- 奖励函数
,以智能体的本体感知和目标状态为定义,提供稠密信号以引导策略优化
为了更好地关注全身层面的运动追踪,作者将29 自由度DoF的Unitree G1 机器人[20] 的手腕关节固定,将动作空间减少至23 维
动作指定目标关节位置,通过PD 控制器执行以驱动机器人。对于策略优化,作者采用近端策略优化PPO[21],以最大化期望的累计折扣奖励
2.2 UniTracker的整体方法论
2.2.1 仿人动作数据集整理
大规模的人形动作数据集为训练通用动作追踪器提供了动力。作者的数据集主要来源于公开可用的AMASS [22] 数据集,经过筛选,去除了包含交互的片段和少于10 帧的序列
- 最终得到的训练集包含11,313 个人体动作,使用SMPL [23] 参数进行表示。SMPL 模型通过形状参数
、姿态参数
和根部平移
来参数化人体
表示SMPL 函数,其中
将SMPL 参数映射为三角形人体网格的顶点位置
且作者为了弥合SMPL 人体模型与人形机器人之间的体现差距,他们采用了受H2O [4] 启发的两阶段重定向方法
- 首先,精心选择了16 个对应的身体连接,并通过最小化静止姿态下所选连接之间的距离,优化人形机器人的形状参数
- 其次,利用优化后的
以及数据集中原始的姿态
和位移
,作者对人形机器人的根部位移、根部朝向和关节位置进行梯度下降,以在整个序列中最小化所选连接之间的距离
且还添加了额外的正则项,以避免激进行为并确保时序平滑
// 待更