网络原理——HTTP/HTTPS
文章目录
HTTP
HTTP是什么
- HTTP(超文本传输协议)是一种应用非常广泛的应用层协议
- HTTP采用的是“一问一答”结构模型
- HTTP代理对于客户端来说是正向的,对于服务器来说是反向的
- HTTP协议是文本协议(字符串),TCP,UDP和IP协议是二进制协议
- HTTP响应因为他是文本协议,所以可以直接查看文本部分内容,但是假如说包含二进制数据,需要对应程序解析之后才能看出来
- HTTP经过压缩之后,可以减小体积,节省网络带宽
- 但是也会消耗CPU和时间
HTTP请求
HTTP请求头:

认识URL
- URL基本格式

- 协议方案名:常见的有http和https
- 登录信息(认证):这个东西现在基本不会用到了
- 服务器地址:可以是IP地址,也可以是域名
- 服务器端口号:使用端口号来区分具体是哪个程序
- 带层次的文件路径:描述了你要访问服务器的哪个资源
- 查询字符串:是一种键值对结构(假如包含特殊符号,需要进行urlencode操作)
- 片段标识符:假如网页比较长,就会被分为多个片段,通过片段标识符,完成网页内部的跳转
补充:
- URL中的端口号可以省略。对于HTTP请求来说,忽略的话默认就是80端口。
对于HTTPS请求来说,忽略的话默认就是443端口 - 带层次的文件路径,虽然写法是一个类似于目录的写法。但是实际上服务器中,不一定是以目录的形式来存储资源的。这里怎么写,与服务器的代码编写形式有关
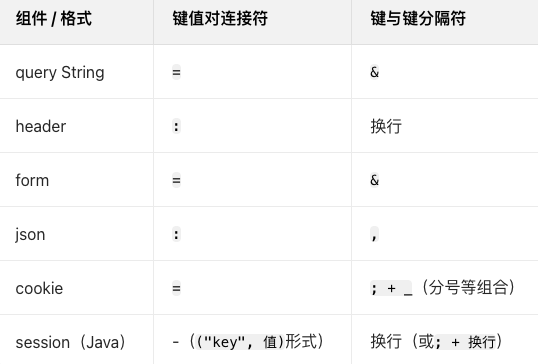
- 网络常见的键值对结构
认识方法
- 常见的方法总结
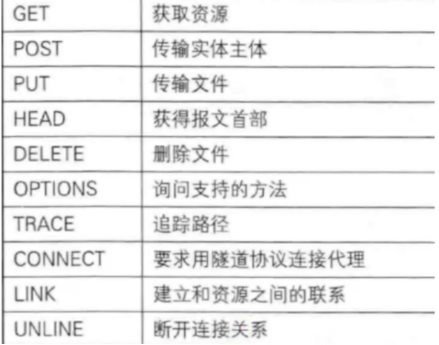
- Post,主要用于登陆和上传文件
- Get,主要用于获取资源
- 这么多http请求,分别表示不同的语义(但是除了Get和Post,其他方法使用比较混乱)
补充:
- Get和Post的区别:
- Get主要把数据放在URL的查询字符串里面;Post则是把数据放在URL的正文里面
- Get主要用于获取数据;Post主要用于提交数据
相关问题详解
- GET 请求能传递的数据量有上限, POST 传递的数据量没有上限.
- 这个说法是一个“历史遗留”
早期版本的浏览器(硬件资源非常匮乏),针对 GET 请求的 URL 的长度做出了限制.
实际上, RFC 标准文档中并没有明确规定 URL 能有多长…目前的浏览器和服务器的实现过程中, URL 可以非常长的.(甚至说可以使用 URL 传递一些图片这样的数据)
- Get请求传递数据不安全。Post请求传递数据安全
- 依据是:如果使用 GET 请求来实现登录
点击登录的时候。就会把用户名和密码放到 url 中,进一步的显示到浏览器地址栏里. (不就被别人看到了吗)相比之下,POST 则是在 body 中,不会在界面上显示出来,所以就更安全 - 但是这里的安全指的是你传递数据的时候,不容易被黑客获取,又或者是被黑客获取后不容易被破解
- 通过一些防御手段,比如针对用户名密码进行加密
此时黑客就算获取到了,要想破解也是不容易的~~ - 此处的安全性,和 post 无关。关键在于 加密.
- GET 只能给服务器传输 文本数据. POST 可以给服务器传输文本 和 二进制数据.
- GET 也不是不能使用 body (body 中是可以直接放二进制的)
- GET 也可以把 二进制的数据进行 base64 转码, 放到 url 的 query string 中.
- GET 请求是幂等的. POST 请求不是幂等的. [不够准确, 但是也不是完全错]
幂等 数学概念.
输入相同的内容, 输出是稳定的.GET 和 POST 具体是否是幂等, 取决于代码的实现.
GET 是否幂等, 也不绝对. 只不过 RFC 标准文档上
建议 GET 请求实现成幂等的
- GET 请求可以被浏览器缓存, POST 不可以被缓存
- 幂等性的延续. 如果请求是幂等, 自然就可以缓存
- GET 请求可以被浏览器收藏夹收藏, POST 不能 (收藏的时候可能会丢失 body)
- 这种说法也 ok, 和技术关系不大. 看用户需求
认识状态码
认识请求头
header的整体格式是“键值对”结构
每一个键值对占一行。键和值之间用冒号进行分割
常见的请求头:
- Host:表示服务器主机地址和端口号
- Content-Length:表示body中的数据长度
- Content-Type:表示body中的数据格式
TCP 涉及到粘包问题.
HTTP 在传输层就是基于 TCP 的.使用同一个 TCP 连接,传输多个 HTTP 数据包,此时,就会使多个 HTTP 数据包在TCP 接收缓冲区中挨在一起.
接收方解析的时候,就需要能够清楚 HTTP 数据包之间的边界.
对于 GET 这种没有 body 的请求,直接使用 空行 (分隔符)
对于 POST 这种有 body 的请求,就结合 空行 和 Content-Length
- User-Agent(简称UA)
- 用于描述上网设备(包含浏览器版本,操作系统版本)
网页和浏览器经历了从简单到丰富的发展过程:
- 上古时期,网页仅含单纯文字,浏览器功能原始。后来网页内容愈发丰富,浏览器功能逐步升级,能显示图片、支持样式、JS、多媒体等,且新老浏览器曾长期并存。
- 这给网站开发者带来难题,需考虑是否兼容旧版浏览器,而
User - Agent(UA)可辅助区分,其记录了浏览器版本及支持特性。 - 如今浏览器差异大幅缩小,UA 主要用于区分 PC 端和移动端,这种区分一般用于统计,而非返回不同版本页面,因前端有“响应式网页”技术,能让同一个 HTML 良好兼容不同设备
- Referer
- 描述跳转前页面是啥
- Cookie
浏览器本地存储数据的机制
Cookie 主要有以下特点:
- 来源:通常由服务器返回,也可由页面自身生成
- 存储:存储在浏览器所在主机的硬盘上,且以域名为维度进行存储,不同域名下的 Cookie 相互独立、互不影响
- 组织形式:以键值对的形式存在,键值对由程序猿自定义,和 query string 类似
- 作用:后续再次请求该服务器时,Cookie 中的内容会自动代入到请求中发给服务器,服务器可依据 Cookie 内容进行逻辑处理
认识状态码
下面是常见的HTTP状态码:
| 状态码范围 | 类别 | 说明 | 常见状态码及含义 |
|---|---|---|---|
| 1xx | 信息性状态码 | 服务器已接收请求,正在处理 | 100 Continue(继续,客户端应继续发送请求体);101 Switching Protocols(协议切换) |
| 2xx | 成功状态码 | 请求已被服务器成功接收、理解并处理 | 200 OK(请求成功);201 Created(资源创建成功);204 No Content(请求成功但无返回内容) |
| 3xx | 重定向状态码 | 需要客户端进一步操作才能完成请求,通常用于资源跳转 | 301 Moved Permanently(永久重定向);302 Found(临时重定向);304 Not Modified(资源未修改,可使用缓存) |
| 4xx | 客户端错误状态码 | 请求存在错误,服务器无法处理 | 400 Bad Request(请求参数错误);401 Unauthorized(未认证,需登录);403 Forbidden(服务器拒绝访问);404 Not Found(资源不存在) |
| 5xx | 服务器错误状态码 | 服务器处理请求时发生内部错误 | 500 Internal Server Error(服务器内部错误);502 Bad Gateway(网关错误);503 Service Unavailable(服务器暂时不可用) |
HTTP响应

认识响应头
- 与响应头的基本格式差不多
- 类似于 Content-Type,Content-Length 等属性的含义也和请求中的含义一致.
响应中的 Content-Type 常见取值有以下几种:
- text/html : body 数据格式是 HTML
- text/css : body 数据格式是 CSS
- application/javascript : body 数据格式是 JavaScript
- application/json : body 数据格式是 JSON
认识响应正文(body)
- 正文规格取决于Content-Type
- text/html
<!DOCTYPE html>
<html>
<head>
<meta charset=utf-8>
<meta http-equiv=X-UA-Compatible content="IE=edge">
<style>
body,
#app {
height: 100%;
margin: 0px;
padding: 0px;
}
.chromeframe {
margin: 0.2em 0;
background: #ccc;
color: #000;
padding: 0.2em 0;
}
#loader-wrapper {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 999999;
}
</style>
</head>
<body>
<div id="app"></div>
</body>
</html>
- text/css
@font-face {
font-family: element-icons;
src: url(../../static/fonts/element-icons.53
......
- application/javascript
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([["app"], {
0: function(t,
......
- application/json
{"msg":"操作成功","code":200,"permissions":[] }
通过不同的方式构造HTTP请求
| 构造方式 | 技术基础/核心概念 | 工作原理 | 优缺点 | 适用场景 |
|---|---|---|---|---|
| form表单构造 | HTML的<form>标签,用于收集用户输入并发送请求 |
通过action指定请求URL,method指定请求方法(GET/POST等),表单元素(如<input>)收集数据,点击提交按钮时发送请求。 |
优点:使用简单,适合初学者,页面表单直观;缺点:通常会导致页面刷新,数据传输格式有限。 | 简单数据提交场景,如用户注册、登录、留言反馈(对页面刷新无严格限制)。 |
| ajax构造 | AJAX(异步JavaScript和XML,现多结合JSON),实现无刷新数据交互。 | 通过XMLHttpRequest或fetch API创建请求对象,配置请求参数(方法、URL等),发送请求,异步接收并处理响应,动态更新页面。 |
优点:异步请求,无页面刷新,提升用户体验,可灵活交互;缺点:存在跨域限制,复杂场景代码维护成本高。 | 动态更新页面内容的场景,如实时数据展示、表单验证、单页应用(SPA)交互。 |
| Java Socket构造 | Java的Socket网络编程机制,手动按照HTTP协议规范构造请求。 | 创建与服务器的TCP连接,手动拼接HTTP请求报文(请求行、请求头、请求体),通过输出流发送,再通过输入流读取并解析响应。 | 优点:高度灵活可控,可自定义请求内容,不受浏览器同源策略限制;缺点:开发难度大,需深入理解HTTP协议,代码量大。 | 需高度定制HTTP请求或非浏览器环境(如Java后台程序)与其他服务器通信,如网络爬虫、自定义HTTP客户端工具。 |
HTTPS
- 之前讲的HTTP内容也适用于HTTPS,HTTPS主要是多了一个“加密”机制
加密
- 在密码学中,使用密钥加密,主要有两种方式
- 对称加密:加密和解密,使用同一个密钥
- 非对称加密:有两个密钥,一个是公钥,一个是私钥。公钥是公开的,私钥是自己留着的
加密过程
对称密钥加密和非对称密钥加密是两种主流的加密技术,核心区别在于密钥的使用方式,适用于不同的场景。以下是详细讲解:
对称密钥加密
- 核心特点:
- 同一密钥:加密和解密使用相同的密钥(也称为“共享密钥”)。
- 效率高:加密解密速度快,适合处理大量数据。
- 工作流程:
- 发送方和接收方提前约定并安全保存同一个密钥。
- 发送方用密钥加密明文,得到密文。
- 发送方将密文传输给接收方。
- 接收方用同一个密钥解密密文,得到明文。
非对称密钥加密
- 核心特点:
- 密钥对:使用一对密钥(公钥+私钥),公钥公开,私钥保密。
- 加密解密规则:用公钥加密的数据,只能用对应的私钥解密;用私钥加密的数据,只能用对应的公钥解密(可用于签名)。
- 工作流程(以通信为例):
- 接收方生成一对密钥(公钥A + 私钥A),将公钥A公开,私钥A自己保存。
- 发送方获取公钥A,用公钥A加密明文,得到密文。
- 发送方将密文传输给接收方。
- 接收方用自己的私钥A解密密文,得到明文。
对比总结
| 维度 | 对称密钥加密 | 非对称密钥加密 |
|---|---|---|
| 密钥数量 | 1个共享密钥 | 2个(公钥+私钥) |
| 密钥保密性 | 密钥必须保密 | 公钥公开,私钥保密 |
| 速度 | 快(适合大量数据) | 慢(适合小数据) |
| 核心优势 | 效率高 | 无需传递密钥,支持签名 |
| 典型用途 | 数据传输加密、文件加密 | 密钥交换、数字签名、身份验证 |
| 代表算法 | AES、DES | RSA、ECC |
中间人攻击
- 具体过程:
- 服务器具有非对称加密算法的公钥S,私钥S’
- 中间人具有非对称加密算法的公钥M,私钥M’
- 客户端向服务器发起请求,服务器明文传送公钥S给客户端
- 中间人劫持数据报文,提取公钥S并保存好,然后将被劫持报文中的公钥S替换成为自己的公钥M,并将伪造报文发给客户端
- 客户端收到报文,提取公钥M(自己当然不知道公钥被更换过了),自己形成对称秘钥X,用公钥M加密X,形成报文发送给服务器
- 中间人劫持后,直接用自己的私钥M’进行解密,得到通信秘钥X,再用曾经保存的服务端公钥S加密后,将报文推送给服务器
- 服务器拿到报文,用自己的私钥S’解密,得到通信秘钥X
- 双方开始采用X进行对称加密,进行通信。但是一切都在中间人的掌握中,劫持数据,进行窃听甚至修改,都是可以的
引入证书
- 服务端在使用HTTPS前,需要向CA机构申领一份数字证书,数字证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明服务端公钥的权威性
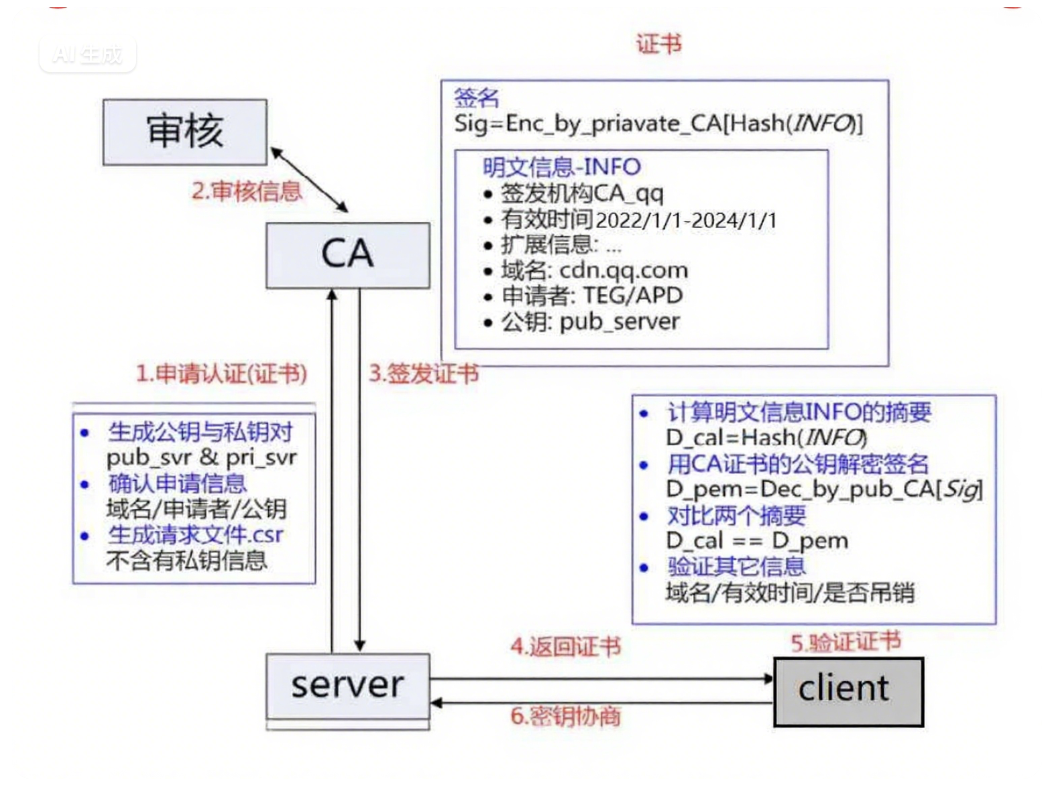
这个证书可以理解成是一个结构化的字符串,里面包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- ……
需要注意的是:申请证书的时候,需要在特定平台生成,会同时生成一对儿密钥对儿,即公钥和私钥。这对密钥对儿就是用来在网络通信中进行明文加密以及数字签名的
理解数据签名
当服务端申请CA证书的时候,CA机构会对该服务端进行审核,并专门为该网站形成数字签名,过程如下:
- CA机构拥有非对称加密的私钥A和公钥A’
- CA机构对服务端申请的证书明文数据进行hash,形成数据摘要
- 然后对数据摘要用CA私钥A’加密,得到数字签名S
服务端申请的证书明文和数字签名S 共同组成了数字证书,这样一份数字证书就可以颁发给服务端了
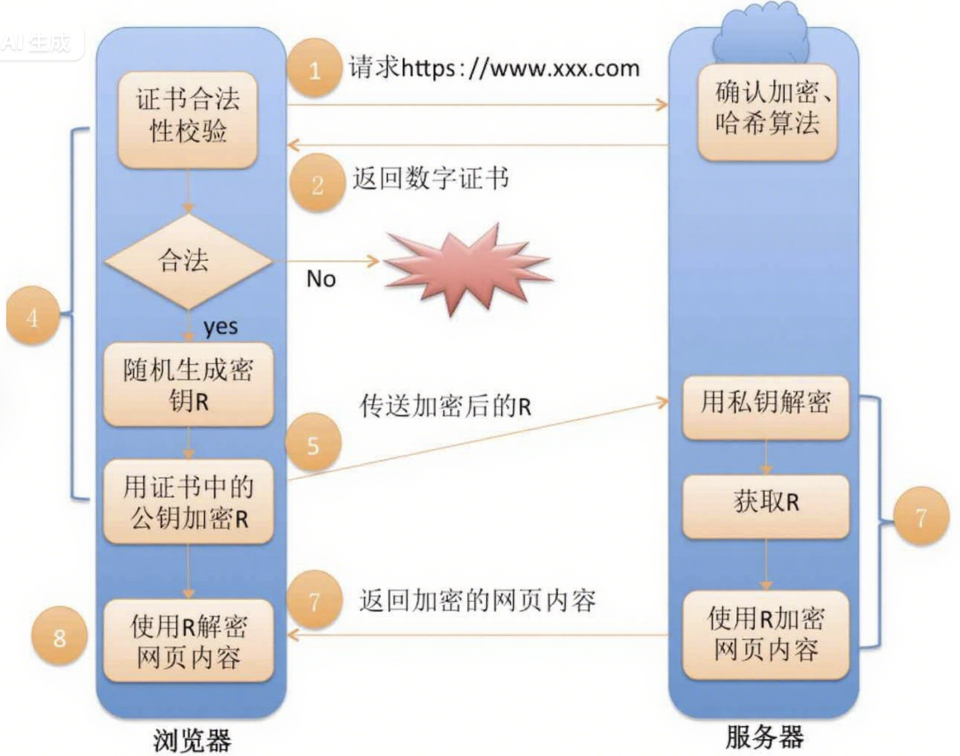
证书解决中间人攻击
- 在客户端和服务器刚一建立连接的时候,服务器给客户端返回一个证书
- 这个证书包含了刚才的公钥,也包含了网站的身份信息
当客户端获取到这个证书之后,会对证书进行校验(防止证书是伪造的)
- 判定证书的有效期是否过期
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)
- 验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到一个 hash 值(称为数据摘要),设为 hash1。然后计算整个证书的 hash 值,设为 hash2。对比 hash1 和 hash2 是否相等。如果相等,则说明证书是没有被篡改过的
中间人有没有可能篡改该证书?
- 中间人篡改了证书的明文
- 由于他没有CA机构的私钥,所以无法hash之后用私钥加密形成签名,那么也就没法办法对篡改后的证书形成匹配的签名
- 如果强行篡改,客户端收到该证书后会发现明文和签名解密后的值不一致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间人
中间人整个掉包证书?
- 因为中间人没有CA私钥,所以无法制作假的证书(为什么?)
- 所以中间人只能向CA申请真证书,然后用自己申请的证书进行掉包
- 这个确实能做到证书的整体掉包,但是别忘记,证书明文中包含了域名等服务端认证信息,如果整体掉包,客户端依旧能够识别出来。
- 永远记住:中间人没有CA私钥,所以对任何证书都无法进行合法修改,包括自己的
常见问题详解
- 为什么摘要内容在网络传输的时候一定要加密形成签名?
- 理解判定证书篡改的过程: (这个过程就好比判定这个身份证是不是伪造的身份证)
- 假设我们的证书只是一个简单的字符串hello,对这个字符串计算 hash 值 (比如 md5),结果为BC4B2A76B9719D91
- 如果 hello 中有任意的字符被篡改了,比如变成了 hella,那么计算的 md5 值就会变化很大. BDBD6F9CF512F2D8
- 然后我们可以把这个字符串 hello 和哈希值 BC4B2A76B9719D91 从服务器返回给客户端,此时客户端如何验证 hello 是否是被篡改过?
- 那么就只要计算 hello 的哈希值,看看是不是 BC4B2A76B9719D91 即可.
- 但是还有个问题,如果黑客把 hello 篡改了,同时也把哈希值重新计算下,客户端就分辨不出来了呀.
- 所以被传输的哈希值不能传输明文,需要传输密文.
- 所以,对证书明文 (这里就是 “hello”) hash 形成散列摘要,然后 CA 使用自己的私钥加密形成签名,将 hello 和加密的签名合起来形成 CA 证书,颁发给服务端,当客户端请求的时候,就发送给客户端,中间人截获了,因为没有 CA 私钥,就无法更改或者整体掉包,就能安全的证明,证书的合法性。
- 最后,客户端通过操作系统里已经存的了的证书发布机构的公钥进行解密,还原出原始的哈希值,再进行校验
- 为什么签名不直接加密,而是要先 hash 形成摘要?
- 缩小签名密文的长度,加快数字签名的验证签名的运算速度
完整流程