Jet-Nemotron: 高效语言模型与后神经网络架构搜索
余弦,胡庆浩,杨尚,西浩成,陈军宇,韩松,蔡汉
NVIDIA https://github.com/NVlabs/Jet- Nemotron
摘要:我们介绍了Jet- Nemotron,一个新型混合架构语言模型家族,它在准确度上与领先的完全注意力模型相当或更高,同时显著提高了生成吞吐量。Jet- Nemotron是使用后神经网络架构搜索(PostNAS)开发的,这是一种新颖的神经网络架构探索流程,能够实现高效的模型设计。与先前的方案不同,PostNAS以预训练的完全注意力模型为起点,冻结其MLP权重,允许高效探索注意力块设计。该流程包括四个关键组件:(1)学习最优完全注意力层放置和消除,(2)线性注意力块选择,(3)设计新的注意力块,以及(4)执行硬件感知超参数搜索。我们的Jet- Nemotron- 2B模型在一系列基准测试中实现了与Qwen3、Qwen2.5、Gemma3和Llama3.2相当或更高的准确度,同时提供了高达 53.6×53.6\times53.6× 生成吞吐量加速和 6.1×6.1\times6.1× 预填充加速。它还在MMLU和MMLU- Pro上的准确度高于近期先进的MoE完全注意力模型,如DeepSeek- V3- Small和Moonlight,尽管它们的规模更大,总参数为15B,激活参数为2.2B。
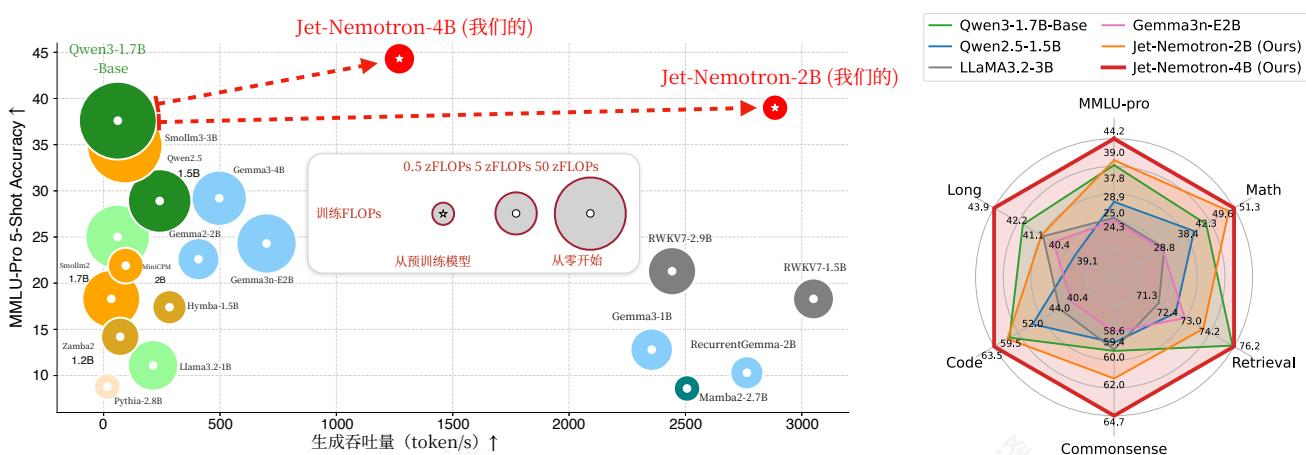
图1|Jet-Nemotron与当前最先进高效语言模型的比较。生成吞吐量在NVIDIAH100GPU上以64K个token的上下文长度进行测量。Jet-Nemotron-2B在MMLU-Pro上比Qwen3-1.7B-Base具有更高的准确率,同时实现了 47×47\times47× 更高的生成吞吐量。Jet-Nemotron-4B尽管模型规模更大,但仍比所有参数小于2B的全注意力模型实现更高的生成吞吐量。
1.引言
语言模型(LMs)的迅速崛起[1,2,3,4,5,6,7]标志着人工智能的变革时代。这些模型在广泛任务中展现出卓越的准确率。然而,由于它们带来的巨大计算和内存需求,其效率已成为一个重大问题。这个问题在长上下文生成和推理中尤为突出,其中自注意力机制[8]的计算复杂度为 O(n2)O(n^2)O(n2) ,并生成一个大的键值(KV)缓存。
为应对这一挑战,已投入大量精力通过开发复杂度降低的 O(n)O(n)O(n) 注意力机制来设计更高效的LM架构。同时,
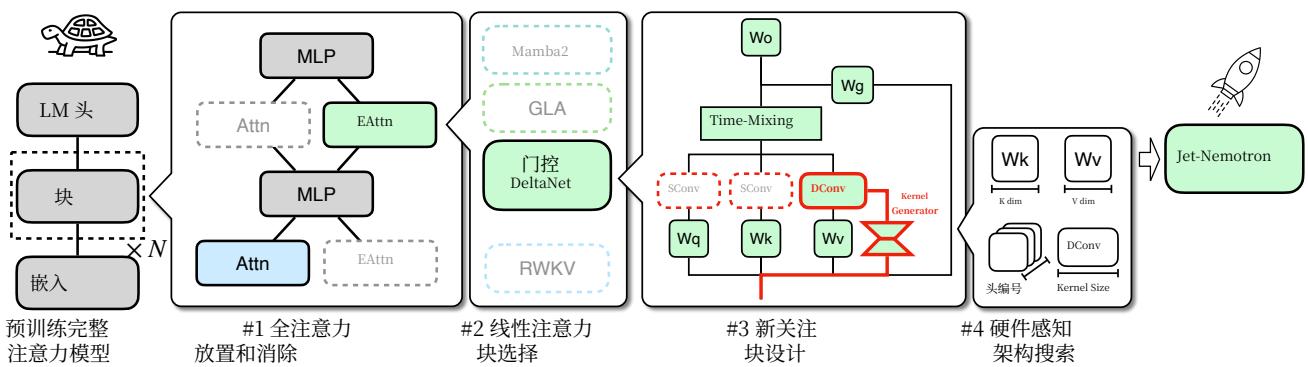
图2 | 后置神经架构搜索路线图。我们的流程从一个预训练的全注意力模型开始,并保持MLP冻结。然后,它对高效注意力块设计进行粗到细的搜索,首先确定全注意力层的最佳位置,然后选择最佳线性注意力块或使用新的线性注意力块,最后搜索最佳架构超参数。
工作重点在于构建结合全注意力机制和线性注意力机制的混合模型,以在准确性和效率之间取得平衡[15, 16, 17]。虽然这些模型在全注意力架构上提供了更高的效率,但它们的准确性仍显著落后于最先进的(SOTA)全注意力模型,特别是在MMLU(- Pro)等具有挑战性的基准测试上[18, 19],数学推理[20, 21, 22],检索[23, 24, 25]编程[26, 27, 28],以及长上下文任务[29]。
本文介绍了Jet- Nematron,一种新的LM系列,它在保持SOTA全注意力模型精度的同时,提供了卓越的效率。图1将Jet- Nematron与之前的效率LM进行了比较。值得注意的是,Jet- Nematron- 2B在MMLU- Pro上实现了比Qwen3- 1.7B- Base更高的精度[5],同时提供 47×47\times47× 在NVIDIA H100 GPU上,在64K的上下文长度下,更高的生成吞吐量。
Jet- Nematron基于后置神经架构搜索(PostNAS),这是一种新颖的神经架构探索流程(图2),它能够快速设计高效的模型架构。与主流的LM架构设计方法不同,PostNAS从一个预训练的全注意力模型开始,从中继承多层感知器(MLP)权重,并在整个过程中保持它们冻结。这种策略显著降低了训练成本,同时仍然允许对注意力块进行全面的探索。流程然后通过四个关键步骤系统地搜索最佳注意力块设计。
i) 全注意力放置与消除。在模型中保留少量全注意力层[30]对于在检索等具有挑战性的任务上保持高精度至关重要。然而,这些层的最佳放置位置尚不明确。在2.2节中,我们介绍了一种新颖的方法,通过训练一个[31](图4)一次性超网络,自动学习何时使用全注意力层。学习到的放置位置在MMLU上的精度方面显著优于常用的均匀放置策略(图5,右侧)。
ii) 线性注意力块选择。在最终确定全注意力层的放置位置后,我们进行注意力块搜索,以识别最佳的线性注意力块(第2.3节)。由于我们框架的低训练成本,我们可以系统地评估现有线性注意力块在不同任务上的精度、训练效率和推理速度。重要的是,我们的方法消除了对小型代理任务的依赖,例如训练微型语言模型(例如,50M或150M参数),确保搜索结果直接转化为最终模型精度的提升。此外,随着新的线性注意力块的出现,我们的框架可以快速评估它们与先前的设计,并在它们展现出有前景的结果时采用它们。
iii) 新的注意力块设计。我们的框架也促进了新的注意力块的快速设计。添加卷积是一种广泛使用的策略来增强线性注意力的能力[32]。然而,先前的方法仅依赖于静态卷积核,缺乏动态适应卷积核特征提取模式的能力。在2.4节中,我们介绍了一种新的线性注意力块,JetBlock(图2,#3)。JetBlock使用一个核生成器来产生基于输入的条件动态因果卷积核,然后将这些核应用于值(V)标记。此外,它移除了查询(Q)和键(K)上的冗余静态卷积,简化了计算。与先前的线性注意力块相比,

图3 | PostNAS准确率提升分解。通过将PostNAS应用于基线模型,我们在所有基准测试中都实现了显著的准确率提升。
JetBlock在较小的开销下表现出更高的准确率(表1)。
iv)硬件感知架构搜索。最后,在2.5节中,我们介绍了一种硬件感知架构搜索方法,用于识别最优的架构超参数。传统上,参数数量被用作衡量LM效率的代理指标。然而,参数数量并不直接与实际硬件上的生成效率相关。我们的硬件感知搜索发现了能够实现相似生成吞吐量、同时使用更多参数以获得更高准确率的架构超参数(表2)。
我们评估Jet- Nematron在一系列全面的基准测试中,包括MMLU(- Pro) [18, 19], 常识推理[33, 34, 35, 36, 37, 38], 数学推理[20, 21, 22, 39], 检索[23, 24, 25], 编码[26, 27, 28, 40], 以及长上下文任务[29]。我们的Jet- Nematron- 2B模型在所有基准测试中都达到了或超越了Qwen2等全注意力SOTA模型。5[4], Qwen3[5], Gemma3[41, 42]和Llama3。2[2],,同时实现了显著更高的生成吞吐量。此外,在长上下文设置中,吞吐量提升更为显著(图6)。例如,在256K的上下文长度下,Jet- Nematron- 2B相比Qwen3- 1.7B- Base实现了6。14×的预填充速度提升和53。6×的解码速度提升。我们希望我们的高效LM系列(Jet- Nematron)、新的线性注意力模块(JetBlock)以及我们的架构设计流程(PostNAS)能够为社区带来益处,并加速下一代高效LM的发展和部署。我们总结我们的主要贡献如下:
- 我们介绍了PostNAS,这是一种用于语言模型的新型模型架构探索范式。通过重用预训练的LLM,PostNAS降低了LLM架构探索的成本和风险,使语言模型的架构设计创新更快、更高效。- 我们为高效语言模型的架构设计提供了新的见解,例如注意力层在特定任务中的重要性,以及发现KV缓存大小比参数数量对生成吞吐量更为关键。- 我们介绍了一种新型线性注意力模块JetBlock,它将线性注意力与动态卷积和硬件感知架构搜索相结合。它在保持可比生成吞吐量的同时,始终显著优于之前的线性注意力模块。- 我们介绍了Jet- Nematron,这是一种新型混合架构语言模型家族,它在广泛任务中实现了卓越的准确性,并且比之前的SOTA全注意力模型(例如Qwen2.5、Qwen3、Gemma3和Llama3.2)提供显著更高的生成吞吐量。凭借其强大的准确性和卓越的推理效率,Jet- Nematron为需要高效语言模型的各种应用提供了实际效益。
2. 方法
2.1. PostNAS动机和路线图
设计新的语言模型架构具有挑战性和风险,因为预训练成本很高。此外,计算资源和训练数据的显著差距使得主要组织以外的研究人员难以匹配大型行业参与者开发的具有全注意力机制的最新技术模型的准确性[4, 41, 2]。这种差距阻碍了语言模型架构设计的创新。
本文提出了一种开发新型语言模型架构的替代策略。我们不是从头开始预训练模型,而是通过在现有的全注意力模型基础上构建来探索新型架构。这种方法显著降低了训练成本和数据需求。
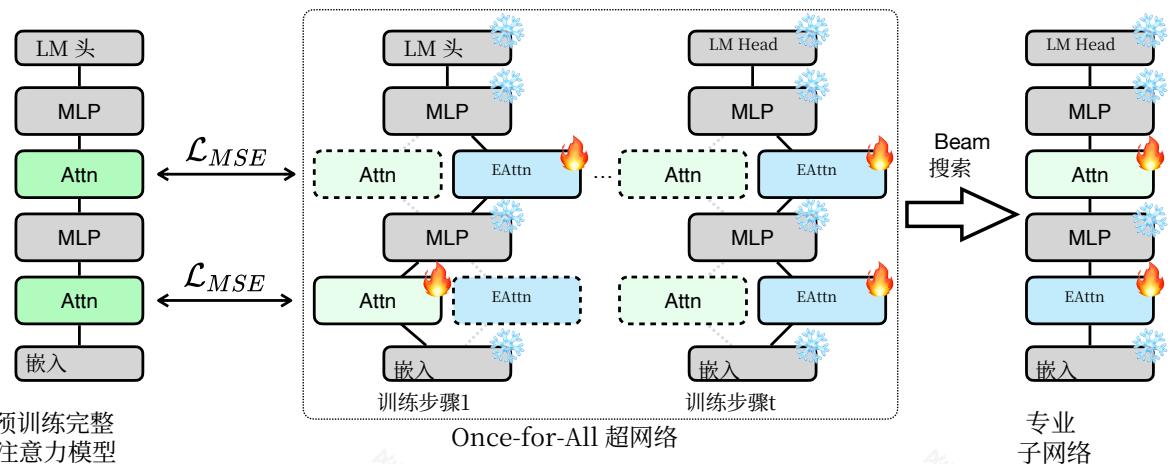
图4 | 使用PostNAS学习全注意力放置。我们训练一个一次性超级网络,并执行束搜索以识别全注意力层的最佳放置。
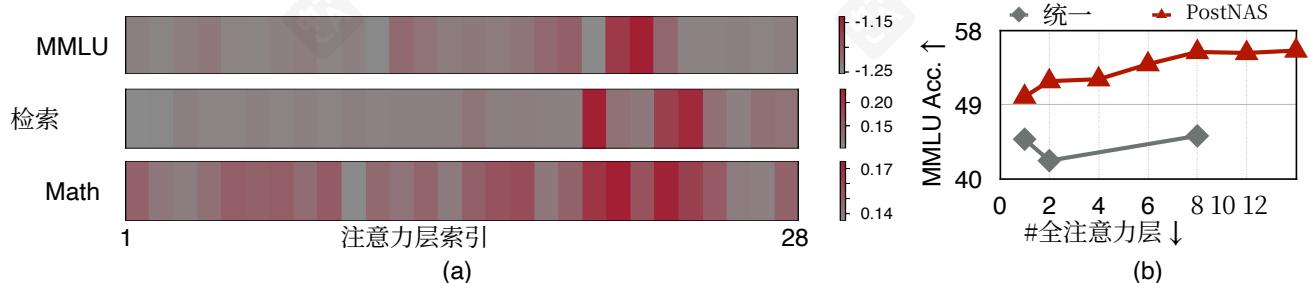
图5 | (a) Owen2.5-1.5B上的层放置搜索结果。每个网格单元表示相应注意力层的搜索目标值;较高值表示更大的重要性。(b) PostNAS与均匀放置的比较。
虽然在此框架内设计的架构从头开始训练时可能无法获得最佳结果,但我们认为它们仍然具有很高的价值。首先,如图1所示,它们在全注意力模型中可以立即带来效率和准确性的提升,转化为实际效益,如改进服务和降低运营成本。其次,我们的框架作为架构创新的快速试验平台。如果新设计在此环境中表现不佳,它在完整预训练中也很可能失败[43]。这种过滤机制帮助研究人员避免在前景不明的架构上浪费大量计算资源。
图2展示了PostNAS的路线图。从预训练的全注意力模型开始,冻结MLP权重,并通过四个关键步骤以粗到细的方式探索注意力块设计:全注意力放置和消除(第2.2节),线性注意力块选择(第2.3节),新的注意力块设计(第2.4节),以及硬件感知的架构搜索(第2.5节)。图3展示了这些步骤的精度提升分解。我们观察到所有基准测试中都存在显著的精度提升:+5.3在MMLU上,+8.4在math上,+7.8在retrieval上,和+3.2在常识推理上。
2.2.全注意力放置和消除
将少数全注意力层纳入已成为提高精度的常见策略[30,16,44,17]。标准方法在全注意力模型上均匀地应用于固定层数的子集,其余层使用线性注意力。然而,这种均匀策略是次优的,特别是在我们的设置中,我们从预训练的全注意力模型开始。
为解决此问题,我们提出了一种自动方法,用于高效确定全注意力层的放置位置。整体方法如图4所示。我们通过在预训练的全注意力模型中增加替代线性注意力路径来构建一个一次性的超级网络[45,31]。在训练过程中,我们
在每个步骤中随机采样一个活动路径,形成一个子网络,该子网络使用特征蒸馏损失进行训练 [46, 47, 48]。
训练后,我们执行束搜索 [49] 以在给定约束下(例如,两个全注意力层)确定全注意力层的最佳放置。搜索目标是任务相关的:对于MMLU,我们选择在正确答案上损失最低的配置(即最大化 - loss),而对于数学和检索任务,我们选择准确率最高的配置。如图5(b)所示,PostNAS在准确率方面显著优于均匀放置。
图5(a)展示了Qwen2.5- 1.5B的搜索结果。对于每一层,我们通过将该层配置为全注意力,同时将所有剩余层配置为线性注意力,从超网络中提取相应的子网络。我们在给定任务上评估每个子网络的准确率或损失,并使用热图可视化结果。我们的分析揭示了三个关键发现:
关键发现1:在预训练的全注意力模型中,并非所有注意力层都同等重要。对于MMLU,只有两层具有关键重要性,而对于检索任务,只有两到三层特别关键。
关键发现2:不同的注意力层贡献不同的能力。对MMLU准确性至关重要的层不一定是检索任务中的重要层。
关键发现3:对于数学推理等复杂任务,注意力重要性模式变得更加复杂。幸运的是,为MMLU和检索识别出的关键层集合已经涵盖了数学所需的大部分关键层。
除了这些关键发现,我们观察到在使用不同的线性注意力操作时,搜索结果保持一致。在我们的最终实验中,我们为简洁性和略微提高的训练吞吐量,在一次性超网络训练中使用GLA [11]。
2.3.线性注意力块选择
基于发现的完整注意力层放置,我们进行注意力块搜索,以识别最适合我们设置的线性注意力块。在我们的实验中,我们评估了六个SOTA线性注意力块,包括RWKV7[10], RetNet[12], Mamba2[50], GLA[11], Deltanet[51], 和Gated DeltaNet [32]。
初步效率分析后,我们观察到RWKV7与其他线性注意力模块相比,训练吞吐量显著较低,这可能是由于内核实现不够理想。因此,我们从训练实验中排除了它。结果总结在表1中,表明Gated DeltaNet在评估的线性注意力模块中实现了最佳的整体准确率。这归因于两个因素的组合:(1)数据相关的门控机制[52],该机制动态控制模型应更多地关注当前token还是历史状态,以及(2)Delta规则[53],该规则用当前token的信息增量更新历史状态,以节省有限的状态内存。因此,我们在实验中继续使用Gated DeltaNet。
2.4.新的注意力模块设计
我们提出了一种新的线性注意力模块,JetBlock,通过将动态卷积[54,55]集成到线性注意力中,来增强模型的表达能力。卷积已被证明对于许多线性注意力模块[32,56]实现高准确率至关重要。然而,现有工作通常使用静态卷积核,这些核无法根据输入调整其特征提取模式。
为了解决这一限制,我们引入了一个核生成模块,该模块根据输入特征动态生成卷积核。整体结构如图2(#3)所示。该模块与Q/K/V投影层共享相同的输入,并首先使用8的缩减率开始一个线性缩减层以提高效率。应用了SiLU激活函数[57],然后是一个最终线性层,该层输出
| Attention Block | Data-Depend Gating | Delta Rule | Throughput ↑ Training | Inference | MMLU | Accuracy ↑ Math Retrieval | Common. |
| RWKV7 [10] | ✓ | ✓ | 123 | 2,542 | - | - | - |
| RetNet [12] | 269 | 2,535 | 53.6 | 29.9 | 63.7 | ||
| Mamba2 [50] | 273 | 3,220 | 51.5 | 26.0 | 68.9 | ||
| GLA [11] | ✓ | 265 | 3,079 | 55.8 | 31.2 | 66.6 | |
| Deltanet [51] | ✓ | 254 | 2,955 | 48.9 | 27.4 | 67.9 | |
| Gated DeltaNet [32] | ✓ | ✓ | 247 | 2,980 | 55.6 | 32.3 | 69.3 |
| JetBlock | ✓ | ✓ | 233 | 2,885 | 56.3 | 32.8 | 69.9 |
| + Hardware-Aware Search | ✓ | ✓ | 227 | 2,883 | 58.1 | 34.9 | 70.4 |
表1|JetBlock的准确性和效率。JetBlock通过PostNAS中的线性注意力块选择、新的注意力块设计和硬件感知搜索进行设计。它在保持可比的训练和推理效率的同时,实现了比先前线性注意力块更高的准确率。
| dK | dV | nhead | 参数( B) | 缓存大小 (MB) | 吞吐量 (token/s) | ↑ | 检索准确率 ↑ | 数学准 确率 ↑ |
| 256 | 288 | 4 | 1.62 | 154 | 2,969 | 67.6 | 31.3 | |
| 192 | 384 | 4 | 1.64 | 154 | 2,961 | 69.3 | 32.3 | |
| 128 | 576 | 4 | 1.70 | 154 | 2,979 | 69.5 | 32.5 | |
| 256 | 144 | 8 | 1.66 | 154 | 2,986 | 68.3 | 32.1 | |
| 192 | 192 | 8 | 1.70 | 154 | 2,970 | 70.6 | 32.8 | |
| 128 | 288 | 8 | 1.74 | 154 | 2,971 | 69.6 | 33.2 | |
| 128 | 192 | 12 | 1.78 | 154 | 2,959 | 68.8 | 32.9 | |
| 96 | 256 | 12 | 1.84 | 154 | 2,955 | 69.6 | 34.8 | |
| 64 | 384 | 12 | 1.98 | 154 | 2,952 | 70.1 | 34.2 |
Table2|硬件感知架构搜索的详细结果。灰色行是原始设计[32],而蓝色行显示了我们硬件感知架构搜索产生的新设计。
卷积核权重。我们采用GatedDeltaNet进行时间混合,因为它与其他设计相比在2.3节中讨论的性能最佳。2.3.
我们将动态卷积核应用于值(V)标记,因为将它们应用于查询(Q)或键(K)标记几乎没有好处。此外,我们发现一旦对V应用动态卷积,就可以移除Q和K上的静态卷积,而对最终模型精度的影响可以忽略不计。我们在最终实验中采用了这种设计,因为它在效率上略有改进。表1将JetBlock与之前的线性注意力块进行了比较。它在数学推理和检索任务上的精度优于GatedDeltaNet,同时保持了相似的效率。
2.5.硬件感知架构搜索
在最终确定宏观架构,特别是全注意力层的放置,并选择线性注意力块后,我们进行硬件感知架构搜索,以优化核心架构超参数,包括键/值维度和注意力头的数量。
传统上,参数规模是用于指导模型架构设计的主要效率指标。然而,这种方法并不理想,因为参数数量与硬件效率没有直接关联。我们通过将生成吞吐量作为选择架构超参数的直接目标来解决这一局限性。我们发现:
| Type | Model | Params (B) | Cache Size (MB) | Throughput (token/s) | MMLU Acc. ↑ | MMLU-Pro Acc. ↑ | BBH Acc. ↑ |
| O(n²) | Qwen2.5-1.5B [4] | 1.5 | 1,792 | 241 | 59.5 | 28.9 | 44.1 |
| Qwen3-1.7B-Base [5] | 1.7 | 7,168 | 61 | 60.3 | 37.8 | 54.2 | |
| Llama3.2-3B [2] | 1.0 | 7,168 | 60 | 54.9 | 25.0 | 47.1 | |
| MiniCPM-2B-128K [58] | 2.8 | 23,040 | 18 | 46.0 | 18.0 | 36.5 | |
| MobileLLM-1.5B [59] | 1.5 | 4,320 | 101 | 26.0 | 9.4 | 27.2 | |
| Smollm2-1.7B [60] | 1.7 | 12,288 | 32 | 48.5 | 18.3 | 35.1 | |
| DeepSeek-V3-Small@1.3T [6] | 2.2/15 | - | - | 53.3 | - | - | |
| 月光@1.2T [61] | 2.2/15 | - | - | 60.4 | 28.1 | 43.2 | |
| O(n) | Mamba2-2.7B [50] | 2.7 | 80 | 2,507 | 25.1 | 8.6 | 25.7 |
| RWKV7-1.5B [10] | 1.5 | 24 | 3,050 | 41.0 | 13.4 | 15.9 | |
| Rec.Gemma-2B [62] | 2.0 | 16 | 2,355 | 28.6 | 12.8 | 33.3 | |
| Hybrid | Gemma3n-E2B [42] | 2.0 | 768 | 701 | 53.9 | 24.3 | 45.1 |
| Hymba-1.5B [44] | 1.5 | 240 | 180 | 49.7 | 17.4 | 29.8 | |
| Zamba2-1.2B [16] | 1.2 | 6,114 | 71 | 43.1 | 14.2 | 19.6 | |
| Jet-Nemotron-2B | 2.0 | 154 | 2,885 | 60.8 | 39.0 | 58.3 | |
| Jet-Nemotron-4B | 4.0 | 258 | 1,271 | 65.2 | 44.2 | 65.0 |
表3|MMLU(- Pro)和BBH上的结果。DeepSeek- V3- Small@1.3T和Moonlight@1.2T是具有2.2B激活参数和15B总参数的MoE模型,分别使用1.3T和1.2T的tokens进行训练。
关键发现4:KV缓存大小是影响长上下文和长生成吞吐量的最关键因素。当KV缓存大小保持不变时,具有不同参数数量的模型表现出相似的生成吞吐量(表2)。
这是因为解码阶段通常是内存带宽受限而不是计算受限。在长上下文场景中,KV缓存通常比模型权重占用更多内存。减小其大小可以减少每步解码的内存传输时间,并支持更大的批处理大小,从而提高生成吞吐量。
基于发现4,我们固定KV缓存大小以匹配原始设计,并在键维度、值维度和注意力头数量上进行小规模网格搜索。表2总结了结果,其中所有变体都使用相同的线性注意力块(即GatedDeltaNet),但配置不同。蓝色行代表我们的最终设计,而灰色行对应原始设计。我们的最终配置在保持原始生成吞吐量的同时,集成了更多参数并提高了准确性。从表1,我们可以看到我们的PostNAS硬件感知搜索提高了JetBlock的准确性,同时保持了训练和推理吞吐量。
3.实验
3.1.设置
Jet- Nemotron模型家族。我们构建了两个不同参数规模的Jet- Nemotron版本:Jet- Nemotron- 2B和Jet- Nemotron- 4B。我们使用检索任务来指导全注意力层的放置,使用MMLU任务来指导滑动窗口注意力(SWA)层的放置。Jet- Nemotron- 2B基于Qwen2.5- 1.5B[4],,其中包含两个全注意力层(编号15和20)用于检索任务,以及两个滑动窗口注意力(SWA)层(编号21和22)用于多选题任务如MMLU。我们发现多选题主要依赖于softmax操作的模式匹配特性来将答案的知识路由到其选项。SWA有效保留了在这些任务上的准确性。其余的注意力层被替换为JetBlock。类似地,Jet- Nemotron- 4B基于Qwen2.5- 3B,并包含三个全注意力层(编号18、21、33)和七个SWA层(编号6、17、20、22、23、26和28)。我们在附录A.1.
| Type | 模型 | 吞吐量 (token/s)↑ | 准确率↑ | |||||
| Avg. | GSM8K | MATH | MathQA | MMLU-Stem | GPQA | |||
| O(n²) | Qwen2.5-1.5B [4] | 241 | 38.4 | 62.4 | 13.1 | 34.4 | 52.7 | 29.4 |
| Qwen3-1.7B-Base [5] | 61 | 42.3 | 62.8 | 16.7 | 46.0 | 50.8 | 27.9 | |
| LLama3.2-3B [2] | 60 | 28.8 | 25.8 | 8.6 | 34.2 | 45.3 | 30.1 | |
| MiniCPM-2B-128K [58] | 18 | 27.6 | 39.2 | 5.9 | 28.5 | 36.3 | 28.1 | |
| Smollm2-1.7B [60] | 32 | 28.9 | 30.3 | 9.2 | 33.7 | 41.3 | 30.1 | |
| O(n) | Mamba2-2.7B [50] | 2,507 | 16.6 | 3.0 | 3.9 | 24.3 | 26.6 | 25.3 |
| RWKV7-1.5B [10] | 2,669 | 18.3 | 5.6 | 0.8 | 27.2 | 34.9 | 23.0 | |
| Roc-Comma 2B [69] | 3,255 | 20.8 | 13.9 | 7.6 | 25.3 | 28.5 | 28.6 | |
| 混合 | Gemma3n-E2B [42] | 701 | 28.3 | 24.9 | 10.1 | 31.1 | 45.7 | 31.8 |
| Hymba-1.5B [44] | 180 | 23.1 | 17.9 | 0.8 | 28.0 | 40.9 | 27.9 | |
| Zamba2-1.2B [16] | 71 | 24.8 | 28.1 | 5.9 | 20.0 | 36.5 | 27.7 | |
| Jet-Nemotron-2B | 2,885 | 49.6 | 76.2 | 23.3 | 53.8 | 62.7 | 32.1 | |
| Jet-Nemotron-4B | 1,271 | 51.3 | 78.7 | 25.2 | 52.5 | 65.6 | 34.6 | |
Table4|数学任务结果。
训练细节。训练分为两个阶段。在第一阶段,我们冻结MLP并使用蒸馏损失训练模型。在第二阶段,我们进行全模型训练。在第一阶段,我们使用Nemotron- CC[63]和Redstone- QA[64]作为我们的预训练语料库,并训练Jet- Nemotron模型50B个token。这也是我们在第2节中执行PostNAS的设置。在第二阶段,我们将更多来自数学[65]和编程[66,67]领域的高质量数据纳入我们的数据混合中。然后,模型在350B个token上进行训练。我们在附录A.2.
评估详情。我们在主流基准设置下评估Jet- Nemotron:MMLU(- Pro)[18,19]数学推理[18,20,21,22],常识推理[33,34,35,36,37,38],检索[23,24,25]编码[26,27,28,40],和长上下文任务[29]。我们将我们的模型与最先进的全注意力模型[2,4,5],线性注意力模型[10,50],和混合模型[41,44]进行比较。我们为GSM8K[22]和MATH[18]采用4- shot评估,为GPQA[20]和MMLU- Pro[19]采用5- shot评估。我们使用EvalPlus[40]和CRUXEval[28]的官方实现进行编码任务。对于所有其他任务,我们使用零样本设置。所有评估都基于LM- Evaluation- Harness[68]。
吞吐量测试平台。我们的吞吐量评估是在一台配备8个NVIDIA H100 GPU、2个Intel Xeon Platinu m8480C(112核)CPU和2TB RAM的DGX H100服务器上进行的。为了公平和一致的比较,我们采用了最新可用的软件版本。具体来说,我们的环境包括Pytorch 2.7.0和Triton 3.3.0。我们实现了带有FlashAttention 2.7的全注意力块。4[69]以及带有Flash- Linear- Attention 0.2的线性注意力块。1[70]。模型推理基于Transformers 4.52.0实现[71]。上下文长度为64K,除非特别说明,每个模型都在单个H100 GPU上进行测试。我们在表3中报告了64K输入上下文的缓存大小。在测试吞吐量时,我们采用chunk- prefilling[72]并在GPU内存约束下搜索块大小,以最大化每个模型的批处理大小。通过这种方式,我们测量了设备上最高可达到的解码吞吐量。我们列出了每个模型使用的批处理大小,见附录A.3。
3.2.主要精度结果
MMLU(- Pro)和BBH的结果。表3比较了Jet- Nemotron与最先进的高效语言模型。Jet- Nemotron- 2B实现了 47×47\times47× 更高的吞吐量,并且 47×47\times47× 比Qwen3- 1.7B- Base具有更小的缓存大小,同时在MMLU、MMLU- Pro和BBH上提供了显著更好的精度。Jet- Nemotron- 2B甚至优于最近的MoE模型,如DeepSeek- V3- Small[6]和Moonlight[61],它们具有更大的激活参数(2.2B)和远大的总参数(15B)。当扩展到4B参数时,Jet- Nemotron- 4B仍然保持对Qwen3- 1.7B- Base的吞吐量优势。与其他线性注意力和混合模型相比,Jet- Nemotron也实现了显著更高的精度。
数学任务的结果。表格4报告了我们在数学任务上的结果。Jet- Nemotron- 2B达到了平均
Table5|在常识任务上的结果
| 模型 | 吞吐量 (token/s)↑ | 准确率↑ | |||||||
| Avg. | ARC-c | ARC-e | PIQA | Wino. | OBQA | BoolQ | TruthQA | ||
| Qwen2.5-1.5B [4] | 241 | 59.4 | 45.4 | 71.2 | 75.8 | 63.8 | 40.2 | 72.8 | 46.6 |
| Qwen3-1.7B-Base [5] | 61 | 60.0 | 44.9 | 68.6 | 75.5 | 63.8 | 39.0 | 79.0 | 48.8 |
| Llama3.2-3B [2] | 60 | 59.9 | 46.6 | 72.0 | 78.0 | 69.3 | 40.4 | 73.9 | 39.3 |
| MiniCPM-2B-128K [58] | 18 | 57.6 | 41.0 | 69.4 | 75.5 | 63.8 | 40.6 | 74.7 | 38.3 |
| Smollm2-1.7B [60] | 32 | 59.7 | 47.0 | 73.3 | 77.7 | 66.2 | 44.6 | 72.5 | 36.7 |
| Mamba2-2.7B [50] | 1,507 | 57.2 | 42.1 | 70.5 | 76.1 | 62.7 | 41.4 | 71.5 | 36.1 |
| RWKV7-1.5B [10] | 3,050 | 59.7 | 46.3 | 75.7 | 77.4 | 67.6 | 45.4 | 70.5 | 34.7 |
| Rec.Gemma-2B [69] | 1,355 | 46.5 | 29.4 | 41.5 | 66.6 | 54.1 | 37.0 | 72.0 | 34.7 |
| Gemma3n-E2B [42] | 701 | 58.6 | 43.2 | 73.1 | 77.0 | 60.8 | 40.8 | 76.0 | 39.1 |
| Hymba-1.5B [44] | 180 | 61.2 | 46.9 | 76.9 | 77.7 | 66.2 | 41.0 | 80.8 | 39.0 |
| Zamba2-1.2B [16] | 71 | 58.0 | 44.4 | 66.8 | 77.4 | 65.6 | 42.8 | 70.8 | 38.5 |
| Jet-Nemotron-2B | 1,885 | 62.0 | 48.6 | 74.8 | 75.4 | 65.8 | 40.6 | 81.2 | 47.8 |
| Jet-Nemotron-4B | 1,271 | 64.7 | 51.7 | 79.2 | 78.1 | 70.5 | 43.6 | 83.0 | 46.6 |
| Type | 模型 | 吞吐量 (token/s)↑ | 准确率↑ | |||
| Avg. | FDA | SWDE | Squad | |||
| O(n²) | Qwen2.5-1.5B [4] | 241 | 72.4 | 82.8 | 86.3 | 48.1 |
| Qwen3 -1.7B-基座 [5] | 61 | 76.1 | 81.8 | 89.2 | 57.2 | |
| Llama3.2-3B [2] | 60 | 71.3 | 82.3 | 89.6 | 56.4 | |
| MiniCPM-2B-128K [58] | 18 | 72.6 | 72.3 | 86.4 | 59.1 | |
| Smollm2-1.7B [60] | 32 | 68.9 | 78.1 | 82.4 | 46.3 | |
| O(n) | Mamba2.2-7B [50] | 2,007 | 57.0 | 51.7 | 74.3 | 45.1 |
| RWKV7-1.5B [10] | 3,050 | 58.6 | 54.5 | 73.3 | 48.0 | |
| Rec.Gemma-2.6B [62] | 2,355 | 68.8 | 62.3 | 86.4 | 57.8 | |
| Hybrid | Gemma3n-1.2B [73] | 701 | 74.0 | 77.3 | 86.4 | 58.2 |
| Hymba-1.5B [44] | 180 | 57.1 | 46.6 | 74.4 | 50.2 | |
| Zamba2-1.2B [16] | 71 | 66.4 | 73.8 | 80.7 | 44.8 | |
| Jet-Nemotron-2B | 2,885 | 74.2 | 80.4 | 85.7 | 56.6 | |
| Jet-Nemotron-4B | 1,271 | 76.2 | 82.5 | 89.7 | 56.4 | |
Table6|检索任务结果。
准确率为49.6,比Qwen3- 1.7B- Base高6.3,同时 47×47\times47× 更快。相比之下,先前的线性注意力机制和混合模型在数学任务上远远落后于Qwen3。
常识推理任务结果。Table5总结了常识推理任务的结果。Qwen2.5和Qwen3在这个领域相对较弱。尽管如此,以Qwen2.5- 1.5B为起点的Jet- Nemotron- 2B仍然表现出色,平均准确率达到62.0,优于所有基线模型。
检索任务结果。Table6展示了检索任务的结果。Jet- Nemotron- 2B除Qwen3- 1.7B- Base外优于所有基线。当扩展到4B时,Jet- Nemotron- 4B实现了76.2的最佳平均准确率,同时仍保持了 21×21\times21× 与Qwen3相比的速度提升。
编码任务结果。Table7显示了编码任务的结果。Jet- Nemotron- 2B的平均准确率高于所有基线。Jet- Nemotron- 4B在所有编码任务中实现了更高的准确率,同时在生成吞吐量方面对Qwen3- 1.7B- Base等领先LM仍保持显著优势。
长上下文任务的结果。线性架构和混合架构的一个常见问题是它们在长上下文任务上的准确性。在表8中,我们在LongBench[29]上评估了长达64K的上下文长度。我们的发现
Table7|在编码任务上的结果。
Table8|长上下文任务上的结果。
| Type | 模型 | 吞吐量 (token/s) ↑ | 准确率 ↑ | |||
| Avg. | EvalPlus | CRUXEval-I-cot | CRUXEval-O-cot | |||
| O(n²) | Qwen2.5-1.5B [4] | 241 | 52.0 | 54.3 | 56.0 | 45.8 |
| Qwen3-1.7B-Base [5] | 61 | 58.9 | 62.8 | 60.4 | 53.4 | |
| Llama3.2-3B [2] | 60 | 44.0 | 35.5 | 54.7 | 41.7 | |
| MiniCPM-2B-128K [58] | 18 | 34.2 | 40.7 | 29.9 | 31.9 | |
| Smollm2-1.7B [60] | 32 | 36.2 | 20.6 | 49.5 | 38.6 | |
| O(n) | Mamba2-2.7B [50] | 2,507 | 14.0 | 12.0 | 9.3 | 20.7 |
| RWKV7-1.5B [10] | 3,050 | 13.2 | 16.8 | 8.0 | 14.7 | |
| Rec.Gemma-2.6B [63] | 2,355 | 36.8 | 29.5 | 46.7 | 34.2 | |
| 混合 | Gemma3n-E2B [73] | 701 | 40.4 | 29.6 | 49.9 | 41.6 |
| Hymba-1.5B [44] | 180 | 30.3 | 31.3 | 32.2 | 27.5 | |
| Zamba2-1.2B [16] | 71 | 20.1 | 12.7 | 21.1 | 26.4 | |
| Jet-Nemotron-2B | 2,885 | 59.5 | 60.8 | 61.1 | 56.7 | |
| Jet-Nemotron-4B | 1,271 | 63.5 | 65.6 | 65.9 | 59.0 | |
| Type | 模型 | 吞吐量 (token/s) ↑ | 准确率 ↑ | |||||
| Avg. | Few-Shot | Code | Sum. | Single-Doc | Multi-Doc | |||
| O(n²) | Qwen2.5-1.5B [4] | 241 | 39.1 | 63.9 | 57.2 | 26.3 | 28.3 | 19.9 |
| Qwen3-1.7B-Base [5] | 61 | 42.2 | 68.8 | 48.1 | 26.8 | 36.6 | 30.6 | |
| Llama3.2-3B [2] | 60 | 39.9 | 65.2 | 58.0 | 24.3 | 27.6 | 24.6 | |
| MiniCPM-2B-128K [58] | 18 | 41.1 | 57.3 | 59.6 | 26.7 | 33.4 | 29.6 | |
| Smollm2-1.7B [60] | 32 | 21.3 | 38.9 | 28.6 | 16.0 | 13.2 | 9.8 | |
| O(n) | Mamba2-2.7B [50] | 2,507 | 10.3 | 6.4 | 30.2 | 9.1 | 3.5 | 2.5 |
| RWKV7-1.5B [10] | 3,050 | 14.2 | 10.6 | 21.1 | 18.1 | 12.8 | 8.7 | |
| Rec.Gemma-2.6B [62] | 2,355 | 24.1 | 31.8 | 56.7 | 12.9 | 9.2 | 9.6 | |
| 混合 | Gemma2-2.6B [73] | 388 | 22.9 | 28.7 | 52.0 | 12.6 | 13.9 | 7.3 |
| Gemma3n-E2B [73] | 701 | 40.4 | 56.4 | 67.2 | 25.6 | 29.3 | 28.6 | |
| Hymba-1.5B [44] | 180 | 28.0 | 36.1 | 53.5 | 51.8 | 14.0 | 19.8 | |
| Zamba2-1.2B [16] | 71 | 9.2 | 10.0 | 20.1 | 10.2 | 3.8 | 1.7 | |
| Jet-Nemotron-2B | 2,885 | 41.1 | 68.7 | 58.1 | 26.0 | 30.8 | 21.9 | |
| Jet-Nemotron-4B | 1,271 | 43.9 | 69.7 | 63.2 | 26.4 | 32.5 | 27.5 | |
表明Jet- Nemotron- 2B,具有两个完整注意力层,实现了与Qwen2.5- 1.5B和Gemma3n- E2B等领先模型相当的性能,这些模型具有多得多的此类层。此外,我们的Jet- Nemotron- 4B超过了Qwen3- 1.7B- Base,同时在生成吞吐量上实现了 21×21\times21× 加速。这些结果显著推进了长上下文任务中效率- 准确性权衡的前沿。
摘要:结合之前的结果,Jet- Nemotron- 2B和Jet- Nemotron- 4B在所有六个评估域中表现与先进的全注意力模型(Qwen3- 1.7B- Base)相当或更好。具有显著更少的全注意力层和更小的KV缓存大小,Jet- Nemotron- 2B和Jet- Nemotron- 4B分别提供 47×47\times47× 和 21×21\times21× 更高的生成吞吐量。
3.3.效率基准测试结果。
Figure6展示了Qwen3- 1.7B- Base和Jet- Nemotron- 2B在不同上下文长度下的吞吐量比较。在预填充阶段,Jet- Nemotron- 2B在较短的上下文长度(4K和8K)下最初比Qwen3- 1.7B- Base快1.14和1.15倍。这可以通过设计更好的JetBlock内核实现来进一步改进。随着上下文长度的增加,线性
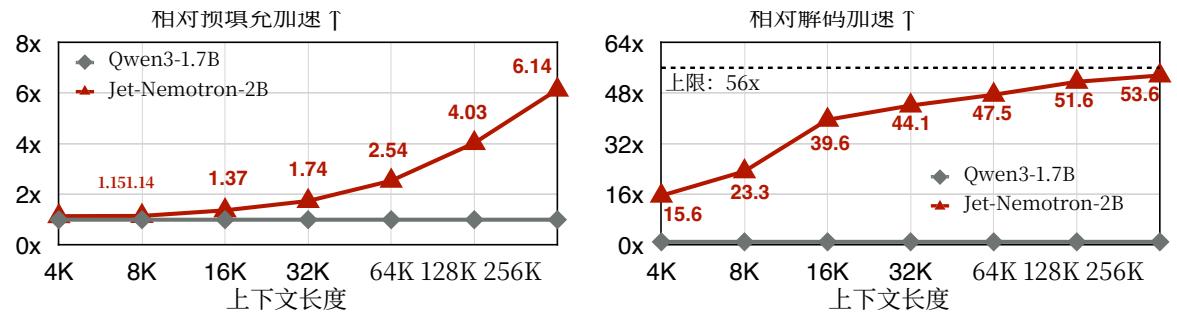
图6|不同上下文长度下的效率比较。Jet-Nemotron-2B在预填充方面比Qwen3-1.7B-Base快了 6.14×6.14\times6.14× 倍,在解码方面快了 53.6×53.6\times53.6× 倍。
注意力带来的优势变得明显,使得Jet- Nemotron- 2B在256K上下文长度下实现了 6.14×6.14\times6.14× 倍加速。
在解码阶段,Jet- Nemotron- 2B持续大幅优于Qwen3- 1.7B- Base。由于Jet- Nemotron- 2B包含2个完整的注意力层,每组有2个键值状态,其理论最大加速比是 14×4=5614\times 4 = 5614×4=56 倍,而Qwen3- 1.7B- Base有28个完整的注意力层,每层包含8组键值状态。在我们的吞吐量测试平台中,Jet- Nemotron- 2B在4K上下文长度下实现了 15.6×15.6\times15.6× 倍的加速,在256K上下文长度下实现了高达 53.6×53.6\times53.6× 倍的加速,几乎达到了理论上限。
4.相关工作
大型语言模型(LLMs)强大但计算密集,促使许多研究工作构建高效的模型架构。一条研究线专注于设计高效的线性注意力块[9,10,11,12,32,50,51,74,75,76,77,78,79,80,81,82,83,82,84]或对数线性注意力[85]块来替代全注意力块。正交地,另一条研究线试图结合全注意力和线性注意力来构建混合模型[13,15,16,17,44,86,87,88]。这些研究通常专注于预训练设置,并且它们的精度落后于领先的全注意力模型。最近,有一些工作致力于将LLM线性化,用线性注意力替代全注意力[9,90,91,92,93,94,95,96]。然而,由于评估特定配置的开销很大,它们的模型架构没有得到很好的优化,因此它们的结果仍然劣于SOTA全注意力模型。
我们的工作也与神经架构搜索(NAS)[45,97,98,99,100],相关,这是一种强大的技术,用于探索架构设计空间并发现新的模型结构。特别是,硬件感知神经架构搜索[45]能够通过训练一次性超网络[31],或利用逐层蒸馏[101,102],等方式,开发针对目标硬件优化的专用模型架构。然而,由于预训练的成本过高,NAS在大语言模型(LLMs)时代很少被应用。最近的努力主要集中在构建灵活的LLM架构[103,104],这些架构可以生成具有不同深度和宽度的各种子网络,以适应不同的硬件平台。尽管如此,这些子网络的架构骨干保持不变,完全依赖于全注意力层。
5.结论
我们介绍了Jet- Nemotron,一种新的混合架构语言模型系列,其性能优于最先进的全注意力模型——包括Qwen3、Qwen2.5、Gemma3和Llama3.2——同时实现了显著的效率提升,在H100 GPU上(256K上下文长度,最大批处理大小)的生成吞吐量高达 53.6×53.6\times53.6× 倍。Jet- Nemotron得益于两项关键创新:(1)后神经架构搜索,这是一种适用于任何预训练Transformer模型的高效后训练架构适应管道;以及(2)JetBlock,一种新型的线性注意力块,其性能显著优于Mamba2、GLA和GatedDeltaNet等先前的设计。广泛的实证结果表明,Jet- Nemotron在广泛的基准测试中实现了显著的效率提升,同时保持了准确性。此外,Jet- Nemotron显著降低了LLM架构探索的成本和风险,推动了语言模型设计更快、更高效的创新。
[1] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few- shot learners. Advances in neural information processing systems, 33:1877- 1901, 2020. [2] Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. [3] Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, et al. Nematron- 4 340b technical report. arXiv preprint arXiv:2400.11704, 2024. [4] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024. [5] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025. [6] Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek- v3 technical report. arXiv preprint arXiv:2412.19437, 2024. [7] Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. [8] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. [9] Angelos Katharopoulos, Apoory Vyas, Nikolaos Pappas, and Francois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156- 5165. PMLR, 2020. [10] Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, et al. Rwkv- 7’ goose" with expressive dynamic state evolution. arXiv preprint arXiv:2505.14456, 2025. [11] Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware- efficient training. arXiv preprint arXiv:2312.06635, 2023. [12] Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023. [13] Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, et al. Minimax- 01: Scaling foundation models with lightning attention. arXiv preprint arXiv:2501.08313, 2025. [14] Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax- m1: Scaling test- time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585, 2025. [15] Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, and Furu Wei. You only cache once: Decoder- decoder architectures for language models. Advances in Neural Information Processing Systems, 37:7339- 7361, 2024. [16] Paolo Glorioso, Quentin Anthony, Yury Tokpanov, Anna Golubeva, Vasudev Shyam, James Whittington, Jonathan Pilault, and Beren Millidge. The zamba2 suite: Technical report. arXiv preprint arXiv:2411.15242, 2024. [17] Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. Samba: Simple hybrid state space models for efficient unlimited context language modeling. arXiv preprint arXiv:2406.07522, 2024. [18] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020. [19] Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu- pro: A more robust and challenging multi- task language understanding benchmark. In The Thirty- eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. [20] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate- level google- proof q&a benchmark. In First Conference on Language Modeling, 2024.
[21] Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel- Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation- based formalisms. arXiv preprint arXiv:1905.13319, 2019. [22] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. [23] Simran Arora, Brandon Yang, Sabri Eyuboglu, Avanika Narayan, Andrew Hajel, Immanuel Trummer, and Christopher Ré. Language models enable simple systems for generating structured views of heterogeneous data lakes. Proc. VLDB Endow., 17(2):92- 105, October 2023. [24] Colin Lockard, Prashant Shiralkar, and Xin Luna Dong. OpenCeres: When open information extraction meets the semi- structured web. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), June 2019. [25] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of EMNLP, 2016. [26] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021. [27] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert- Voss, William Hebgen Guss, Alex Nichol, Alex Paimo, Nicholas Tezak, Jie Tang, Igor Babuschkin, Suchir Palaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021. [28] Alex Gu, Baptiste Roziere, Hugh James Leather, Armando Solar- Lezama, Gabriel Synnaeve, and Sida Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. In Forty- first International Conference on Machine Learning, 2024. [29] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3119- 3137, Bangkok, Thailand, August 2024. Association for Computational Linguistics.[30] Roger Waleffe, Wonmin Byteon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, et al. An empirical study of mamba- based language models. arXiv preprint arXiv:2406.07887, 2024. [31] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once- for- all: Train one network and specialize it for efficient deployment. arXiv preprint arXiv:1908.09791, 2019. [32] Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. arXiv preprint arXiv:2412.06464, 2024. [33] Christopher Clark, Kenton Lee, Ming- Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of NAACL- HLT, 2019. [34] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018. [35] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of AAAI, 2020. [36] Hector Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Proceedings of KR, 2012. [37] Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022.
[38] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of EMNLP, 2018. [39] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. [40] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty- seventh Conference on Neural Information Processing Systems, 2023. [41] Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025. [42] Fnu Devvrit, Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit Dhillon, Yulia Tsvetkov, Hannaneh Hajishirzi, Sham Kakade, Ali Farhadi, and Prateek Jain. Matformer: Nested transformer for elastic inference. In Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@NeurIPS 2023), 2023. [43] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8697- 8710, 2018. [44] Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih- Yang Liu, Matthijs Van Keirsbikli, Min- Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid- head architecture for small language models. arXiv preprint arXiv:2411.13676, 2024. [45] Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv preprint arXiv:1812.00332, 2018. [46] Geoffrey Hinton, Oriol Vinyales, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. [47] Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. In Proceedings of ICLR, 2024. [48] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minfilm: Deep self- attention distillation for task- agnostic compression of pre- trained transformers. Advances in neural information processing systems, 33:5776- 5788, 2020. [49] Alex Graves. Sequence transduction with recurrent neural networks. In Proceedings of the Workshop on Representation Learning (ICML2012), 2012. [50] Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. arXiv preprint arXiv:2405.21060, 2024. [51] Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. arXiv preprint arXiv:2406.06484, 2024. [52] Jos Van Der Westhuizen and Joan Lasenby. The unreasonable effectiveness of the forget gate. arXiv preprint arXiv:1804.04849, 2018. [53] DL Prados and SC Kak. Neural network capacity using delta rule. Electronics Letters, 25(3):197- 199, 1989. [54] Felix Wu, Angela Fan, Alexei Baevski, Yann N Dauphin, and Michael Auli. Pay less attention with lightweight and dynamic convolutions. arXiv preprint arXiv:1901.10430, 2019. [55] Han Cai, Muyang Li, Qinsheng Zhang, Ming- Yu Liu, and Song Han. Condition- aware neural network for controlled image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7194- 7203, 2024. [56] Han Cai, Junyan Li, Muyan Hu, Chuang Gan, and Song Han. Efficientvit: Lightweight multi- scale attention for high- resolution dense prediction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 17302- 17313, 2023. [57] Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid- weighted linear units for neural network function approximation in reinforcement learning. Neural networks, 107:3- 11, 2018. [58] Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024. [59] Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, et al. Mobilellm: Optimizing sub- billion parameter language models for on- device use cases. In Forty- first International Conference on Machine Learning, 2024.
[60] Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martin Blazquez, Guilherme Penedo, Lewis Tunstall, Andres Marafioti, Hynek Kydlicek, Agustin Piqueres Lajarin, Vaibhav Srivastav, et al. Smollm2: When smol goes big- data- centric training of a small language model. arXiv preprint arXiv:2502.02737, 2025. [61] Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982, 2025. [62] Aleksandar Botev, Soham De, Samuel L Smith, Anushan Fernando, George- Cristian Muraru, Ruba Haroun, Leonard Berrada, Razvan Pascanu, Pier Giuseppe Sessa, Robert Dadashi, et al. Recurrentgamma: Moving past transformers for efficient open language models. arXiv preprint arXiv:2404.07839, 2024. [63] Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kleegl, Mostafa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Nematron- cc: Transforming common crawl into a refined long- horizon pretraining dataset. arXiv preprint arXiv:2412.02595, 2024. [64] Yaoyao Chang, Lei Cui, Li Dong, Shaohan Huang, Yangyu Huang, Yupan Huang, Scarlett Li, Tengchao Lv, Shuming Ma, Qinzheng Sun, et al. Redstone: Curating general, code, math, and qa data for large language models. arXiv preprint arXiv:2412.03398, 2024. [65] Fan Zhou, Zengzhi Wang, Nikhil Ranjan, Zhoujun Cheng, Liping Tang, Guowei He, Zhengzhong Liu, and Eric P Xing. Megamath: Pushing the limits of open math corpora. arXiv preprint arXiv:2504.02807, 2025. [66] Loubna Ben Allal, Anton Lozhkov, Guilherme Penedo, Thomas Wolf, and Leandro von Werra. Smollm- corpus, July 2024. [67] Kazuki Fujii, Yukito Tajima, Sakae Mizuki, Hinari Shimada, Taihei Shiotani, Koshiro Saito, Masanari Ohi, Masaki Kawamura, Taishi Nakamura, Takumi Okamoto, et al. Rewriting pre- training data boosts llm performance in math and code. arXiv preprint arXiv:2505.02881, 2025. [68] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawka, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The language model evaluation harness. 07 2024. [69] Tri Dao. Flashattention- 2: Faster attention with better parallelism and work partitioning. In The Twelfth International Conference on Learning Representations, 2024. [70] Songlin Yang and Yu Zhang. Fla: A triton- based library for hardware- efficient implementations of linear attention mechanism, January 2024. [71] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, et al. Transformers: State- of- the- art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020. [72] Amey Agrawal, Nitin Kedla, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming Throughput- Latency tradeoff in LLM inference with SarathiServe. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117- 134, Santa Clara, CA, July 2024. USENIX Association.[73] Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Leonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024. [74] Zhen Qin, Songlin Yang, and Yiran Zhong. Hierarchically gated recurrent neural network for sequence modeling. Advances in Neural Information Processing Systems, 36:33202- 33221, 2023. [75] Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021. [76] Weizhe Hua, Zihang Dai, Hanxiao Liu, and Quoc Le. Transformer quality in linear time. In International conference on machine learning, pages 9099- 9117. PMLR, 2022. [77] Zhen Qin, Yuxin Mao, Xuyang Shen, Dong Li, Jing Zhang, Yuchao Dai, and Yiran Zhong. You only scan once: Efficient multi- dimension sequential modeling with lightnet. arXiv preprint arXiv:2405.21022, 2024. [78] Zhen Qin, Weixuan Sun, Hu Deng, Dongxu Li, Yunshen Wei, Baohong Lv, Junjie Yan, Lingpeng Kong, and Yiran Zhong. cosformer: Rethinking softmax in attention. In International Conference on Learning Representations, 2022. [79] Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020. [80] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020.
[81] Yu Zhang, Songlin Yang, Ruijie Zhu, Yue Zhang, Leyang Cui, Yiqiao Wang, Bolun Wang, Freda Shi, Bailin Wang, Wei Bi, Peng Zhou, and Guohong Fu. Gated slot attention for efficient linear- time sequence modeling. In Proceedings of NeurIPS, 2024. [82] Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sammi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620, 2024. [83] Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test- time training done right. arXiv preprint arXiv:2505.23884, 2025. [84] Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024. [85] Han Guo, Songlin Yang, Tarushii Goel, Eric P Xing, Tri Dao, and Yoon Kim. Log- linear attention. arXiv preprint arXiv:2506.04761, 2025. [86] Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibabashi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, et al. Nematron- h: A family of accurate and efficient hybrid mamba- transformer models. arXiv preprint arXiv:2504.03624, 2025. [87] Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev- Shwartz, et al. Jamba: A hybrid transformer- mamba language model. arXiv preprint arXiv:2403.19887, 2024. [88] Jusen Du, Weigao Sun, Disen Lan, Jiaxi Hu, and Yu Cheng. Mom: Linear sequence modeling with mixture- of- memories. arXiv preprint arXiv:2502.13685, 2025. [89] Junxiong Wang, Daniele Paliotta, Avner May, Alexander Rush, and Tri Dao. The mamba in the llama: Distilling and accelerating hybrid models. Advances in Neural Information Processing Systems, 37:62432- 62457, 2024. [90] Michael Zhang, Simran Aroca, Rahul Chalamala, Benjamin Frederick Spector, Alan Wu, Krithik Ramesh, Aaryan Singhal, and Christopher Re. Lolecats: On low- rank linearizing of large language models. In The Thirteenth International Conference on Learning Representations, 2024. [91] Disen Lan, Weigao Sun, Jiaxi Hu, Jusen Du, and Yu Cheng. Liger: Linearizing large language models to gated recurrent structures. In International conference on machine learning, 2025. [92] Jungo Kasai, Hao Peng, Yihe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolos Pappas, Yi Mao, Weizhu Chen, and Noah A Smith. Finetuning pretrained transformers into rnns. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10630- 10643, 2021. [93] Aviv Bick, Kevin Li, Eric P. Xing, J Zico Kolter, and Albert Gu. Transformers to SSMs: Distilling quadratic knowledge to subquadratic models. In The Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. [94] Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, and Thomas Kollar. Linearizing large language models. arXiv preprint arXiv:2405.06640, 2024. [95] Hanting Chen, Liu Zhicheng, Xutao Wang, Yuchuan Tian, and Yunhe Wang. Dijiang: Efficient large language models through compact kernelization. In International Conference on Machine Learning, pages 7103- 7117. PMLR, 2024. [96] Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Re. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry. In The Twelfth International Conference on Learning Representations, 2024. [97] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016. [98] Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, and Jun Wang. Efficient architecture search by network transformation. In Proceedings of the AAAI conference on artificial intelligence, 2018. [99] Xuan Shen, Pu Zhao, Yifan Gong, Zhenglun Kong, Zheng Zhan, Yushu Wu, Ming Lin, Chao Wu, Xue Lin, and Yanzhi Wang. Search for efficient large language models. Advances in Neural Information Processing Systems, 37:139294- 139315, 2024. [100] Youpeng Zhao, Ming Lin, Huadong Tang, Qiang Wu, and Jun Wang. Merino: Entropy- driven design for generative language models on iot devices. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 22840- 22848, 2025. [101] Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assaf, Mohammed Dabbah, Ido Galil, Amnon Geifman, Yonatan Geifman, Izhak Golan, et al. Puzzle: Distillation- based nas for inference- optimized llms. In Forty- second International Conference on Machine Learning, 2025.
[102] Pavlo Molchanov, Jimmy Hall, Hongxu Yin, Jan Kautz, Nicolo Fusi, and Arash Vahdat. Lana: latency aware network acceleration. In European Conference on Computer Vision, pages 137- 156. Springer, 2022. [103] Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, and Pavlo Molchanov. Flextron: Many- in- one flexible large language model. arXiv preprint arXiv:2406.10260, 2024. [104] Ruisi Cai, Saurav Muralidharan, Hongxu Yin, Zhangyang Wang, Jan Kautz, and Pavlo Molchanov. Llamaflex: Many- in- one llms via generalized pruning and weight sharing. In The Thirteenth International Conference on Learning Representations, 2023. [105] Joshua Ainslie, James Lee- Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. Gqa: Training generalized multi- query transformer models from multi- head checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895- 4901, 2023.
A.实验细节
A.1.最终模型架构
最终的Jet- Nematron模型由多个块堆叠组成,每个块包含一个多层感知器(MLP)层和一个注意力层。注意力层从三种类型中选择:全注意力、滑动窗口注意力和JetBlock。详细的架构配置在表中呈现9。
| Jet-Nematron-2B | Jet-Nematron-4B | |
| 总区块数 | 28 | 36 |
| 全注意力层 | 15,20 | 18,21,22,28,33 |
| 滑动窗口注意力层 | 21,22 | 17,20,23,24,26 |
| 词汇量 | 151,643 | 151,643 |
| 隐藏大小 | 1,536 | 2,048 |
| MLP Intermediate Size | 8,960 | 11,008 |
Table9|Jet-Nematron系列的总体模型架构。
全注意力机制和滑动窗口注意力层使用分组查询注意力[105]并配置如表10所示。对于滑动窗口注意力层,Jet- Nematron- 2B中的窗口大小设置为1,152,Jet- Nematron- 4B中设置为2,048。
表10|Jet-Nematron模型中全注意力层的配置
| 全神贯注 / SWA | Jet-Nematron-2B | Jet-Nematron-4B |
| 注意力头数量 | 12 | 16 |
| Q/K/V的维度 | 128 | 128 |
| K/V头数量 | 2 | 2 |
| 位置嵌入 | RoPE | RoPE |
JetBlock的配置显示在表11:
表11|JetBlock的配置。
| JetBlock | Jet-Nematron-2B | Jet-Nematron-4B |
| Q/K Dimension | 96 | 128 |
| V Dimension | 256 | 256 |
| Head Number | 12 | 16 |
| Convolution Kernel Size | 4 | 4 |
| DConv Generator Hidden Size | 32 | 32 |
A.2.实验成本
A.2. 实验成本Table 12 总结了 PostNAS 的成本和训练 Jet-Nematron-2B 模型的成本。我们使用了 32 个 H100 GPU 并行运行。报告的 GPU 小时已经考虑了设备总数。
A.3.吞吐量测量
A.3. 吞吐量测量在整个实验过程中,我们测量了 Jet-Nematron 和基线模型在单个 H100 GPU 上的最大可达预填充和解码吞吐量。这是通过调整 chunk Préfilling 中的 chunk 大小来实现的 [72] 以在不牺牲预填充吞吐量的情况下最大化解码批处理大小。我们在表中列出了每个模型的优化批处理大小和相应的 chunk 大小 13。预填充的上下文长度为 64K。由于 KV 缓存内存主导了推理期间的 GPU 使用,通过减少每个序列的内存占用,较小的缓存允许更多序列并行处理,从而大大提高生成吞吐量。
表12|PostNAS的实验成本和训练Jet-Nemotron-2B模型的成本。
| Tokens (B) | ZFLOPs | 时间 (H100 GPU 小时) | ||
| PostNAS | 全注意力放置和消除 | 50 | 0.8 | 808 |
| 线性注意力模块选择 | 50 | 4.0 | 3120 | |
| 新注意力模块设计 | 50 | 0.8 | 624 | |
| 硬件感知架构搜索 | 50 | 7.2 | 5616 | |
| 训练 | Stage1 | 50 | 0.8 | 624 |
| Stage2 | 350 | 5.6 | 7536 |
| 模型 | 批大小 | 块大小 |
| Qwen2.5-1.5B | 32 | 4,096 |
| Qwen3.1.7B | 8 | 4,096 |
| Llama3.2-1B | 32 | 4,096 |
| MiniCPM-2B-128K | 2 | 2,048 |
| Pythia-2.8B | 2 | 16,384 |
| Smollm2-1.7B | 4 | 16,384 |
| Mamba2-2.7B | 128 | 1,024 |
| RWKV7-1.5B | 256 | 2,048 |
| Rec.Gemma-2B | 128 | 512 |
| Gemma3n-E2B | 64 | 4,096 |
| Gemma2-2.6B | 16 | 2,048 |
| Hymba-1.5B | 64 | 512 |
| Mamba2-1.2B | 8 | 8,192 |
| Jet-Nemotron-2B | 128 | 1,024 |
| Jet-Nemotron-4B | 64 | 512 |
Table 13 | 效率测量中的超参数。We adjust the chunk size to maximize decoding batch size without compromising prefilling throughput.
B. 额外结果
B.1. 训练数据上的控制研究
为了排除训练数据的影响,我们持续地在Jet- Nemotron的训练数据集上预训练基线模型(Qwen2.5、RWKV- 7和Mamba- 2),以提供更全面的评估。表14中的结果表明,Jet- Nemotron- 2B的性能明显优于所有这些微调后的基线模型。
| Model | MMLU | Math | Commonsense | 检索 |
| Qwem2.5-1.5B-continual | 56.7 | 37.6 | 59.8 | 71.5 |
| Mamba2-2.7B-continual | 41.0 | 22.5 | 56.9 | 55.9 |
| RWKV7-1.5B-持续 | 49.8 | 25.2 | 59.3 | 57.2 |
| Jet-Nemotron-2B | 59.6 | 40.2 | 61.7 | 73.6 |
表14 | 训练数据控制研究. 所有模型都在第3.1节中讨论的Jet- Nemotron阶段- 2训练语料库上进行预训练或持续预训练。3.1.
B.2. 低端硬件上的吞吐量结果
我们测量了Jet- Nemotron- 2B和Qwen2.5- 1.5B在NVIDIA Jetson Orin(32GB)和NVIDIA RTX 3090 GPU上的吞吐量,上下文长度为64K。表15中的结果显示Jet- Nemotron- 2B在Jetson Orin和RTX 3090 GPU上分别比Qwen2.5- 1.5B快8.84×和6.50×倍。
| 硬件 | Qwen2.5-1.5B (Tokens/s) | Jet-Nemotron-2B (Tokens/s) | 加速比 |
| Orin | 6.22 | 55.00 | 8.84 |
| 3090 | 105.18 | 684.01 | 6.50 |
在JetsonOrin(32GB)和NVIDIARTX3090GPU上的表15|吞吐量结果。