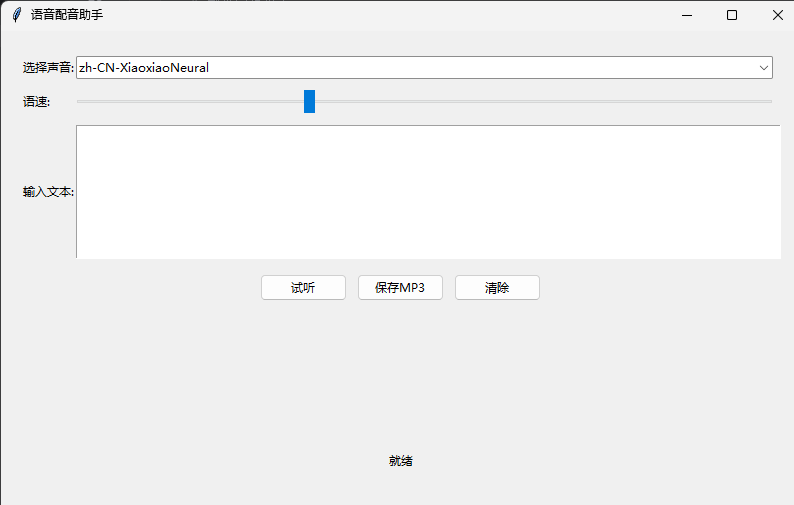
功能特性
✅ 多种中文语音选择(微软Edge TTS引擎)
✅ 语速调节(0.5倍速到2倍速)
✅ 文本输入和编辑
✅ 实时试听功能
✅ 保存为MP3文件
✅ 简洁易用的GUI界面
安装依赖
pip install edge-tts pygame
使用方法
运行程序:
python voice_assistant.py
界面操作:
选择声音: 从下拉菜单选择喜欢的语音
调节语速: 使用滑块调整语速(左慢右快)
输入文本: 在文本框中输入要转换的文字
试听: 点击"试听"按钮预览生成的语音
保存: 点击"保存MP3"将语音保存为文件
清除: 点击"清除"清空文本框
支持的声音
晓晓 (zh-CN-XiaoxiaoNeural) - 女声
晓伊 (zh-CN-XiaoyiNeural) - 女声
云健 (zh-CN-YunjianNeural) - 男声
云希 (zh-CN-YunxiNeural) - 男声
云夏 (zh-CN-YunxiaNeural) - 男声
云扬 (zh-CN-YunyangNeural) - 男声
技术栈
Python 3.6+
tkinter (GUI界面)
edge-tts (文本转语音)
pygame (音频播放)
asyncio (异步处理)
打包成EXE
用下面代码:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import threading
import os
import edge_tts
import asyncio
import tempfile
import subprocess
import platform
class VoiceAssistant:
def __init__(self, root):
self.root = root
self.root.title("语音配音助手")
self.root.geometry("800x600")
# 音频播放设置
self.audio_player = self.get_audio_player()
# 创建主框架
main_frame = ttk.Frame(root, padding="20")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 配置网格权重
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
main_frame.rowconfigure(4, weight=1)
# 声音选择
ttk.Label(main_frame, text="选择声音:").grid(row=0, column=0, sticky=tk.W, pady=5)
self.voice_var = tk.StringVar()
self.voice_combo = ttk.Combobox(main_frame, textvariable=self.voice_var, state="readonly")
self.voice_combo.grid(row=0, column=1, sticky=(tk.W, tk.E), pady=5)
# 语速调节
ttk.Label(main_frame, text="语速:").grid(row=1, column=0, sticky=tk.W, pady=5)
self.speed_var = tk.DoubleVar(value=1.0)
self.speed_scale = ttk.Scale(main_frame, from_=0.5, to=2.0, variable=self.speed_var,
orient=tk.HORIZONTAL)
self.speed_scale.grid(row=1, column=1, sticky=(tk.W, tk.E), pady=5)
ttk.Label(main_frame, textvariable=tk.StringVar(value="慢")).grid(row=1, column=2, sticky=tk.W, pady=5)
ttk.Label(main_frame, textvariable=tk.StringVar(value="快")).grid(row=1, column=3, sticky=tk.W, pady=5)
# 文本输入
ttk.Label(main_frame, text="输入文本:").grid(row=2, column=0, sticky=tk.W, pady=5)
self.text_input = tk.Text(main_frame, height=10, wrap=tk.WORD)
self.text_input.grid(row=2, column=1, columnspan=3, sticky=(tk.W, tk.E, tk.N, tk.S), pady=5)
# 按钮框架
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=3, column=0, columnspan=4, pady=10)
ttk.Button(button_frame, text="试听", command=self.preview_audio).pack(side=tk.LEFT, padx=5)
ttk.Button(button_frame, text="保存MP3", command=self.save_audio).pack(side=tk.LEFT, padx=5)
ttk.Button(button_frame, text="清除", command=self.clear_text).pack(side=tk.LEFT, padx=5)
# 状态标签
self.status_var = tk.StringVar(value="就绪")
ttk.Label(main_frame, textvariable=self.status_var).grid(row=4, column=0, columnspan=4, pady=5)
# 加载可用声音
self.load_voices()
def load_voices(self):
"""加载可用的声音列表"""
try:
# 这里可以添加更多声音选项
voices = [
"zh-CN-XiaoxiaoNeural", # 晓晓-女声
"zh-CN-XiaoyiNeural", # 晓伊-女声
"zh-CN-YunjianNeural", # 云健-男声
"zh-CN-YunxiNeural", # 云希-男声
"zh-CN-YunxiaNeural", # 云夏-男声
"zh-CN-YunyangNeural" # 云扬-男声
]
self.voice_combo['values'] = voices
self.voice_combo.set(voices[0]) # 默认选择第一个声音
except Exception as e:
messagebox.showerror("错误", f"加载声音列表失败: {e}")
async def generate_audio_async(self, text, voice, rate, output_file):
"""异步生成音频文件"""
try:
communicate = edge_tts.Communicate(text, voice, rate=rate)
await communicate.save(output_file)
return True, ""
except Exception as e:
return False, str(e)
def generate_audio(self, text, voice, rate, output_file):
"""生成音频文件"""
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
success, error = loop.run_until_complete(
self.generate_audio_async(text, voice, rate, output_file)
)
return success, error
finally:
loop.close()
def preview_audio(self):
"""试听功能"""
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要转换的文本")
return
voice = self.voice_var.get()
rate = f"+{(self.speed_var.get() - 1) * 100:.0f}%"
self.status_var.set("正在生成试听音频...")
# 在新线程中生成音频
threading.Thread(target=self._preview_thread, args=(text, voice, rate), daemon=True).start()
def _preview_thread(self, text, voice, rate):
"""试听线程"""
try:
# 创建临时文件
with tempfile.NamedTemporaryFile(suffix='.mp3', delete=False) as tmp_file:
temp_path = tmp_file.name
# 生成音频
success, error = self.generate_audio(text, voice, rate, temp_path)
if success:
# 在主线程中播放音频
self.root.after(0, lambda: self._play_audio(temp_path))
self.root.after(0, lambda: self.status_var.set("试听音频生成完成"))
else:
self.root.after(0, lambda: messagebox.showerror("错误", f"生成音频失败: {error}"))
self.root.after(0, lambda: self.status_var.set("生成失败"))
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("错误", f"试听过程中发生错误: {e}"))
self.root.after(0, lambda: self.status_var.set("错误"))
def get_audio_player(self):
"""获取系统音频播放器"""
system = platform.system()
if system == "Windows":
return "start"
elif system == "Darwin": # macOS
return "afplay"
else: # Linux
return "aplay"
def _play_audio(self, file_path):
"""播放音频"""
try:
if self.audio_player == "start": # Windows
subprocess.Popen(["cmd", "/c", "start", "", "/min", file_path],
shell=True, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
else: # macOS or Linux
subprocess.Popen([self.audio_player, file_path],
stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
# 延迟后清理文件
def cleanup():
try:
os.unlink(file_path)
except:
pass
self.root.after(10000, cleanup) # 10秒后清理
except Exception as e:
messagebox.showerror("错误", f"播放音频失败: {e}")
def save_audio(self):
"""保存MP3文件"""
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要转换的文本")
return
# 选择保存路径
file_path = filedialog.asksaveasfilename(
defaultextension=".mp3",
filetypes=[("MP3文件", "*.mp3"), ("所有文件", "*.*")],
title="保存音频文件"
)
if not file_path:
return
voice = self.voice_var.get()
rate = f"+{(self.speed_var.get() - 1) * 100:.0f}%"
self.status_var.set("正在生成并保存音频...")
# 在新线程中保存音频
threading.Thread(target=self._save_thread, args=(text, voice, rate, file_path), daemon=True).start()
def _save_thread(self, text, voice, rate, file_path):
"""保存线程"""
try:
success, error = self.generate_audio(text, voice, rate, file_path)
if success:
self.root.after(0, lambda: messagebox.showinfo("成功", f"音频已保存到: {file_path}"))
self.root.after(0, lambda: self.status_var.set("保存完成"))
else:
self.root.after(0, lambda: messagebox.showerror("错误", f"保存音频失败: {error}"))
self.root.after(0, lambda: self.status_var.set("保存失败"))
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("错误", f"保存过程中发生错误: {e}"))
self.root.after(0, lambda: self.status_var.set("错误"))
def clear_text(self):
"""清除文本"""
self.text_input.delete("1.0", tk.END)
self.status_var.set("已清除文本")
def main():
root = tk.Tk()
app = VoiceAssistant(root)
root.mainloop()
if __name__ == "__main__":
main()pyinstaller --onefile --windowed --name="语音配音助手" voice_assistant.py