VERLTOOL:打通LLM工具强化学习的“任督二脉”,实现多模态多任务统一训练
本文将聚焦VERLTOOL框架——一款专为智能体工具强化学习(ARLT)设计的开源系统。它解决了现有工具强化学习代码库碎片化、同步执行效率低、跨领域扩展性差的痛点,通过上游对齐VERL、统一工具管理、异步轨迹执行等核心设计,在数学推理、知识问答等6大任务中表现比肩专用系统,为LLM工具强化学习研究提供了高效、可扩展的基础设施。
论文标题:VERLTOOL: TOWARDS HOLISTIC AGENTIC REINFORCEMENT LEARNING WITH TOOL USE
来源:arXiv:2509.01055 [cs.AI],链接:http://arxiv.org/abs/2509.01055
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大型语言模型(LLMs)在数学推理(如AIME)、编程(如LIVECODEBENCH)等领域已取得突破性进展,这很大程度上得益于可验证奖励强化学习(RLVR) ——该范式能增强LLM的长上下文推理能力,使其展现出反思、回溯等认知行为。然而,RLVR局限于单轮交互且无工具集成,LLM如同“缸中之脑”,无法与外部环境交互,易出现过度思考、幻觉等问题。
为突破这一限制,学界提出工具强化学习(ARLT) ,让LLM通过调用代码执行、搜索引擎等外部工具实现多轮反馈交互。但现有ARLT方案存在显著系统级挑战:代码库为特定任务定制导致碎片化、同步执行产生资源闲置瓶颈、多模态工具(如图像处理)支持不足,严重阻碍了社区 adoption 与算法创新。
研究问题
- 执行效率瓶颈:多工具交互轨迹具有异步性,不同工具返回结果速度差异大,现有同步批量处理模式会产生大量 idle 时间,导致GPU/CPU资源利用率低。
- 工具管理碎片化:现有ARLT代码库多针对单一工具(如仅支持搜索或代码执行)开发,工具交互逻辑与RL训练循环强耦合,难以扩展新工具或复现跨任务结果。
- 多模态支持不足:多数RL框架仅聚焦文本模态,而新兴多模态推理智能体(如PIXELREASONER)需处理图像、视频等工具输出,现有设计无法统一适配。
主要贡献
- 上游对齐与模块化设计:将VERL(Sheng et al., 2024)作为子模块集成,确保与上游RL训练框架的兼容性,同时分离RL训练与智能体工具交互逻辑,简化维护并加速框架迭代。
- 统一工具管理系统:提出专用工具服务器与标准化API,支持代码执行、FAISS搜索、SQL数据库、图像处理等多模态工具;新增工具仅需轻量Python定义文件,大幅降低开发 overhead。
- 异步轨迹执行机制:摒弃传统同步批量处理模式,让每条轨迹生成动作后立即与工具服务器交互,消除 idle 等待时间,轨迹执行速度提升近2倍。
- 跨任务验证与统一训练:在数学推理、知识问答、SQL生成、视觉推理、网页搜索、软件工程6大ARLT任务中验证,训练模型性能比肩专用系统,同时提供统一训练基础设施。
思维导图

方法论精要
1. 范式定义:从RLVR到ARLT
(1)RLVR基础
RLVR通过可验证奖励优化LLM策略,目标函数为:
max π θ E x ∼ D , y ∼ π θ ( ⋅ ∣ x ) [ R ϕ ( x , y ) ] − β D K L [ π θ ( y ∣ x ) ∥ π r e f ( y ∣ x ) ] \max_{\pi _{\theta }}\mathbb {E}_{x\sim \mathcal {D},y\sim \pi _{\theta }(\cdot | x)}\left[ R_{\phi }(x,y)\right] -\beta \, \mathbb {D}_{KL}\left[ \pi _{\theta }(y| x)\, \| \, \pi _{ref}(y | x)\right] maxπθEx∼D,y∼πθ(⋅∣x)[Rϕ(x,y)]−βDKL[πθ(y∣x)∥πref(y∣x)]
其中, π θ \pi_\theta πθ为待优化LLM策略, π r e f \pi_{ref} πref为参考模型, R ϕ R_\phi Rϕ为可验证奖励(如答案与真值匹配则为1,否则为-1), D K L D_{KL} DKL为KL散度正则项。
典型单轮轨迹仅含LLM生成结果 τ = { y } \tau=\{y\} τ={y},采用GRPO算法优化,损失函数为:
J G R P O ( θ ) = 1 G ∑ i = 1 G 1 ∣ τ i ∣ ∑ t = 1 ∣ τ i ∣ min [ r i , t ( θ ) ⋅ A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A ^ i , t ] J_{GRPO}(\theta)=\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|\tau_{i}\right|} \sum_{t=1}^{\left|\tau_{i}\right|} \min \left[r_{i, t}(\theta) \cdot \hat{A}_{i, t}, \text{clip}\left(r_{i, t}(\theta), 1-\epsilon, 1+\epsilon\right) \cdot \hat{A}_{i, t}\right] JGRPO(θ)=G1∑i=1G∣τi∣1∑t=1∣τi∣min[ri,t(θ)⋅A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)⋅A^i,t]
其中, r i , t ( θ ) r_{i,t}(\theta) ri,t(θ)为token级重要性比, A ^ i , t \hat{A}_{i,t} A^i,t为归一化优势值。
(2)ARLT扩展
ARLT将单轮轨迹扩展为多轮动作-观测序列,轨迹定义为:
τ = { a 0 , o 0 , a 1 , o 1 , . . . , a n − 1 , o n − 1 , a n } \tau=\{a_0, o_0, a_1, o_1, ..., a_{n-1}, o_{n-1}, a_n\} τ={a0,o0,a1,o1,...,an−1,on−1,an}
+ a i a_i ai:LLM生成的动作token(可能触发工具调用)
+ o i o_i oi:工具返回的观测token(文本/图像/视频等多模态)
+ n n n:交互步数
工具调用通过停止token识别:每个工具 T k T_k Tk对应预定义停止token集合 S k \mathbb{S}_k Sk(如代码解释器为"</python>",搜索工具为"</search>"),若 a i a_i ai以 S k \mathbb{S}_k Sk结尾,则触发工具 T k T_k Tk。
由于观测token o i o_i oi与当前优化的 π θ \pi_\theta πθ无关(Off-Policy),训练时需屏蔽,因此ARLT的GRPO损失调整为:
J G R P O − A R L T ( θ ) = 1 G ∑ i = 1 G 1 ∑ j = 0 n ∣ a j ∣ ∑ j = 0 n ∑ t = T j T j + ∣ a j ∣ min [ r i , t ( θ ) ⋅ A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A ^ i , t ] J_{GRPO-ARLT}(\theta)=\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\sum_{j=0}^{n}\left|a_{j}\right|} \sum_{j=0}^{n} \sum_{t=T_{j}}^{T_{j}+\left|a_{j}\right|} \min \left[r_{i, t}(\theta) \cdot \hat{A}_{i, t}, \text{clip}\left(r_{i, t}(\theta), 1-\epsilon, 1+\epsilon\right) \cdot \hat{A}_{i, t}\right] JGRPO−ARLT(θ)=G1∑i=1G∑j=0n∣aj∣1∑j=0n∑t=TjTj+∣aj∣min[ri,t(θ)⋅A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)⋅A^i,t]
其中, T j T_j Tj为动作段 a j a_j aj的首个token索引,仅对动作token计算损失。
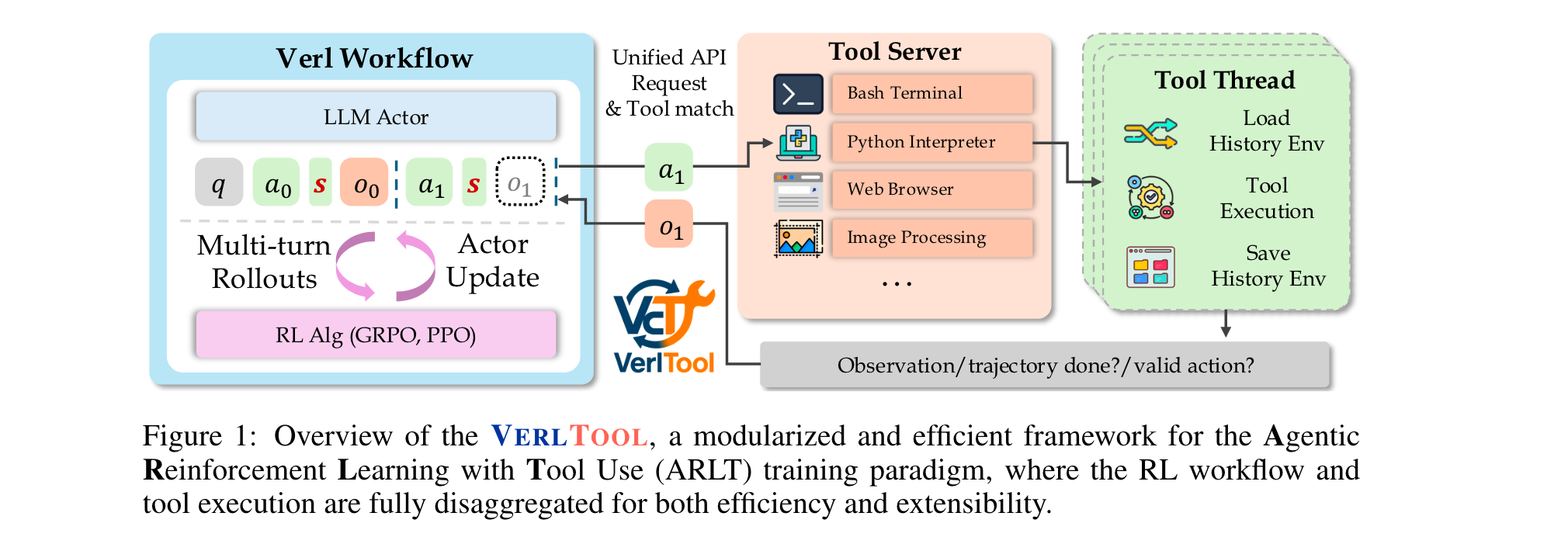
2. 框架架构:模块化与解耦设计
VERLTOOL采用“RL工作流-工具服务器”二分架构,通过统一API连接,核心组件如下:
| 组件 | 功能描述 |
|---|---|
| Verl Workflow | 负责RL全流程:多轮轨迹生成、LLM Actor更新、优势计算与策略优化(支持GRPO/DAPO) |
| Tool Server | 管理工具生命周期:接收动作请求、调度工具执行、返回观测结果,支持并行与分布式部署 |
| 统一API | 标准化动作-观测交互协议,屏蔽不同工具的底层差异,实现“工具即插件” |
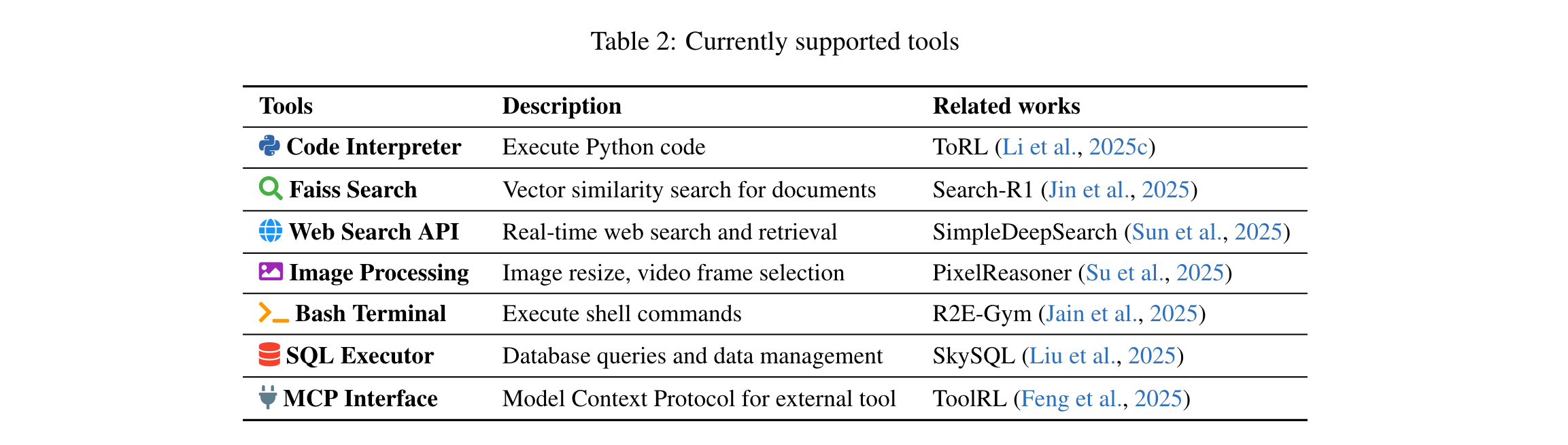
3. 关键技术:效率与扩展性优化
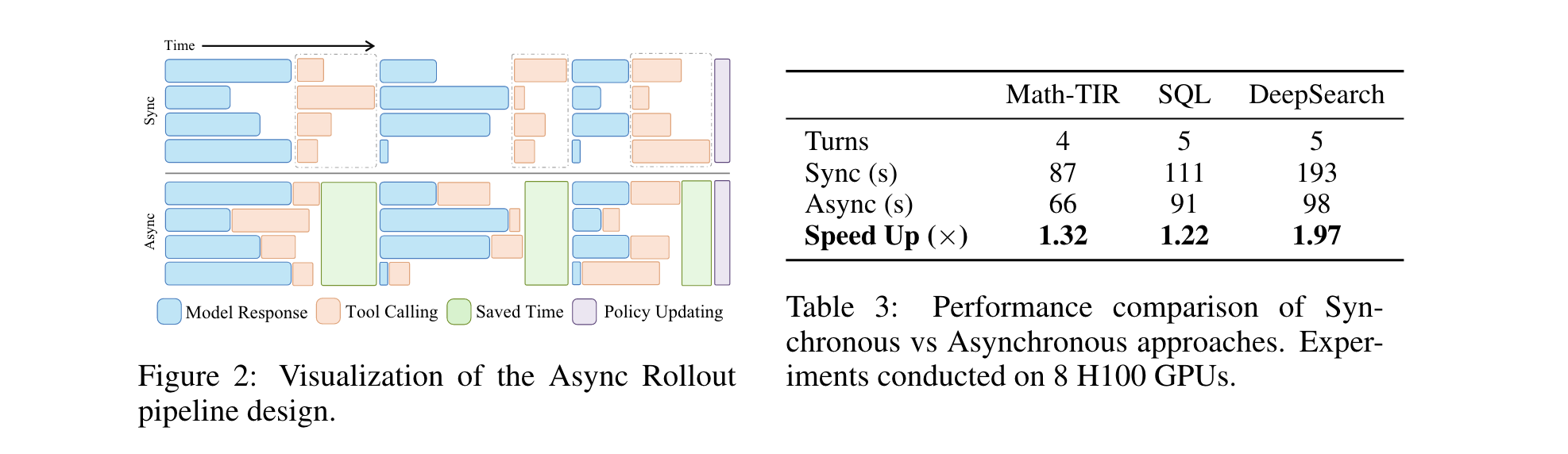
(1)异步轨迹执行
- 问题:同步批量处理需等待批次内所有轨迹生成动作后才调用工具,导致工具执行期间GPU/CPU闲置。
- 方案:每条轨迹生成动作后立即通过API发送至Tool Server,工具执行与下一条轨迹的动作生成并行进行(如图2所示)。
- 效果:在8张H100 GPU上,DeepSearch任务轨迹执行时间从193s降至98s,提速1.97倍;Math-TIR与SQL任务分别提速1.32倍、1.22倍。
(2)并行工具服务器后端
Tool Server提供两种并行执行模式,适配不同工具需求:
- 多线程(ThreadPoolExecutor):适用于轻量工具(如FAISS搜索、SQL查询),通过Python多线程并行处理工具请求,低开销且易部署。
- Ray分布式执行:适用于计算密集型工具(如图像处理、代码执行),基于Ray(Moritz et al., 2017)实现跨机器/GPU节点的分布式执行,支持容错与资源动态调度。
(3)工具插件化设计
所有工具继承自统一的BaseTool类,需实现4个核心方法即可集成,示例代码如图3所示:
parse_action(a):解析LLM动作 a a a,判断是否触发当前工具,返回解析结果与有效性标识。load_env(trajectory_id):加载指定轨迹的环境状态(如SQL任务的数据库连接、搜索任务的历史查询)。conduct_action():执行工具逻辑,返回观测 o o o、轨迹终止标识(done)与动作有效性标识(is_valid)。save_env(trajectory_id, env):保存轨迹的最新环境状态,支持多轮交互的状态延续。

(4)多模态Token处理
为避免动作与观测token拼接时的Off-Policy偏差,采用分离tokenization策略:
- 先分别对LLM动作(如
"</python>")和工具观测(如"\n<result>")进行tokenization; - 再拼接token序列,确保边界符号的token ID一致(如Qwen2.5 tokenizer下,分离处理可避免联合tokenization导致的ID偏移)。

实验洞察
1. 实验设置
(1)任务与工具映射
VERLTOOL在6类ARLT任务中验证,每类任务对应特定工具与评估基准,具体如下:
| 任务名称 | 核心工具 | 训练数据集 | 评估基准 |
|---|---|---|---|
| VT-Math(数学推理) | Python代码解释器 | DeepMath(He et al., 2025) | GSM8K、MATH-500、AIME24、AMC23等 |
| VT-Search(知识QA) | FAISS搜索+Wikipedia | Search-R1数据集(Jin et al., 2025) | NQ、TriviaQA、HotpotQA、Musique等 |
| VT-SQL(NL2SQL) | SQL执行器 | SkyRL-SQL(Liu et al., 2025) | Spider(Dev/Test/Realistic)、Spider-DK/Syn |
| VT-VisualReasoner(视觉推理) | 图像处理器(缩放/帧选择) | Pixel-Reasoner数据集(Su et al., 2025) | V* Bench(Wu & Xie, 2024) |
| VT-DeepSearch(网页搜索) | Google Search API(SERPER) | SimpleDeepSearcher+WebSailor(Sun et al., 2025; Li et al., 2025b) | GAIA(Mialon et al., 2023)、HLE(Phan et al., 2025) |
| VT-SWE(软件工程) | Bash终端+代码执行器 | R2E-Lite(Jain et al., 2025) | SWE-Verified |
(2)模型与训练配置
- 基础模型:Qwen2.5系列(Math-1.5B/7B、Coder-7B、VL-7B)、Qwen3-8B
- RL算法:GRPO(Shao et al., 2024)、DAPO(Dong et al., 2025)
- 硬件:8张H100 GPU,训练批大小、学习率等参数因任务调整(详见Table 9)
2. 核心实验结果
(1)性能比肩专用系统
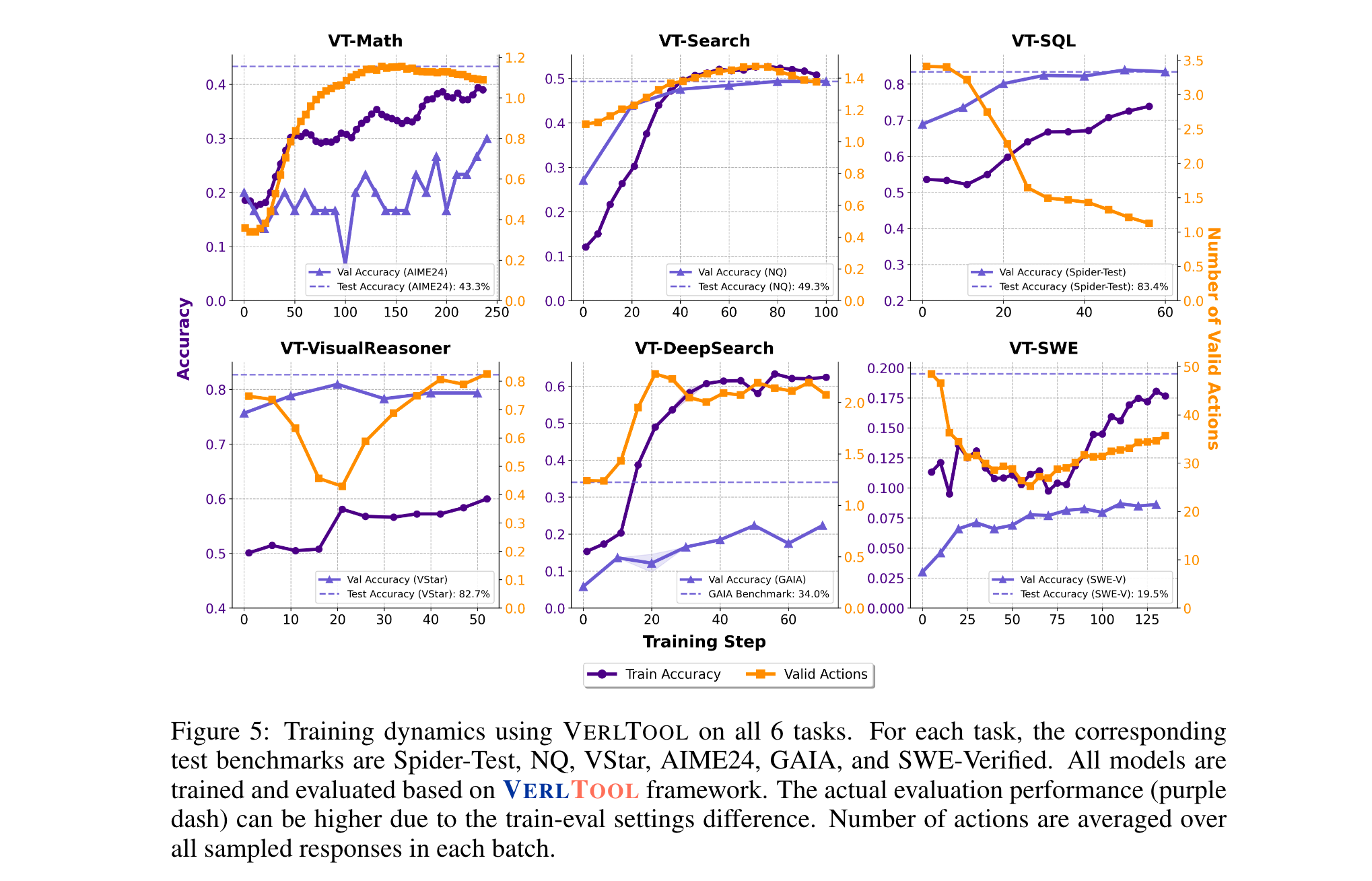
VERLTOOL训练的模型在所有任务中表现与专用系统相当,部分任务更优:
- VT-Math:Qwen2.5-Math-7B+DAPO在AIME24达36.7%,AMC23达75%,平均性能62.2%,超过ToRL-7B(61.1%)与SimpleRL-Zoo-7B(58.2%)。
- VT-Search:Qwen2.5-7B+GRPO在General QA(NQ/TriviaQA/PopQA)平均达55.5%,Multi-Hop QA(HotpotQA/2Wiki等)平均达38.2%,整体平均45.9%,显著优于Search-R1-base(GRPO:35.0%)。
- VT-SQL:Qwen2.5-Coder-7B+GRPO在Spider-Test达83.4%,Spider-Realistic达81.3%,与SkyRL-SQL-7B(85.2%/81.1%)性能持平。
- VT-VisualReasoner:Qwen2.5-VL-7B+GRPO(Complex)在V* Bench达82.7%,接近Pixel-Reasoner-7B(84.3%),远超GPT-4o(62.8%)与Gemini-2.5-Pro(79.2%)。
(2)异步执行效率优势
对比同步与异步轨迹执行的耗时(8张H100 GPU),异步模式在所有任务中均实现提速,尤其在工具响应慢的DeepSearch任务中优势最显著:
| 任务 | 同步耗时(s) | 异步耗时(s) | 提速倍数 |
|---|---|---|---|
| Math-TIR | 87 | 66 | 1.32 |
| SQL | 111 | 91 | 1.22 |
| DeepSearch | 193 | 98 | 1.97 |
(3)多模态工具适配性
VERLTOOL成功支持文本(代码/SQL/搜索)、视觉(图像处理)、系统级(Bash)多模态工具:
- 视觉推理任务中,智能体可动态调用图像缩放、帧选择工具,迭代处理视觉信息,解决GPT-4o等模型无法动态交互图像的问题。
- 软件工程任务中,通过Bash终端与代码执行器,智能体实现代码调试、测试验证的多轮交互,Qwen3-8B在SWE-Verified达10.4分,接近OpenHands-7B-Agent(11.0分)。
3. 关键发现
- 工具使用的任务依赖性:不同任务的工具交互步数差异显著——数学推理仅需1-4轮,而软件工程需超100轮;SQL任务中,模型训练后会减少工具调用(因记忆常见查询结果),而DeepSearch任务工具调用随训练增加(需依赖实时信息)。
- 奖励设计的重要性:无针对性奖励会导致工具使用行为退化——如VT-VisualReasoner若仅用准确率奖励,工具调用频率会在数步RL训练后降至0;需结合好奇心奖励( r c u r i o s i t y r_{curiosity} rcuriosity)与惩罚项( r p e n a l t y r_{penalty} rpenalty)才能维持有效工具交互。
- 涌现的智能体行为:训练后的模型展现出超越简单工具调用的复杂行为——数学智能体通过代码执行验证计算并回溯错误,搜索智能体根据检索结果优化查询词,软件工程智能体结合代码分析与增量修复实现调试。
4. 局限性与未来方向
- 现有工具仍局限于“调用-响应”模式,未支持工具间协作(如用搜索结果指导SQL查询);
- 多模态观测的奖励设计仍依赖人工规则,需探索自适应奖励模型;
- 分布式训练时的轨迹状态同步仍有优化空间,可进一步提升大规模任务的扩展性。