
项目概述
项目背景与核心目标
在国家信创战略全面推进的背景下,数据库作为关键基础设施的自主可控已成为企业数字化转型的核心要求。Oracle数据库虽在稳定性和功能上具备优势,但存在知识产权受制于外方、许可成本高昂及运维服务响应滞后等风险,难以满足国家对关键信息基础设施安全可控的政策要求。在此背景下,迁移至国产金仓数据库(KingbaseES)成为实现技术自主可控、提升系统性能并降低长期成本的必然选择。
本次迁移的核心目标包括三个维度:其一,实现自主可控,摆脱对国外数据库产品的依赖,构建基于国产技术栈的数据库支撑体系;其二,优化系统性能,针对业务高峰期数据处理需求,通过金仓数据库的高并发处理能力与优化引擎提升查询响应速度;其三,降低总体拥有成本(TCO),减少Oracle许可费用及后续维保支出,预计可实现年均30%以上的成本节约。
项目范围界定
本次迁移项目覆盖企业核心业务系统的五大模块,包括客户管理系统、交易处理平台、财务核算系统、供应链管理模块及数据分析平台,涉及数据总量约80TB,其中结构化数据占比75%,非结构化数据占比25%。在迁移边界方面,明确以下实施范围:
- 数据迁移范围:全量迁移近3年业务数据(约50TB),历史数据(30TB)采用归档存储策略,通过查询接口按需访问;
- 接口集成范围:包含与第三方支付平台、物流系统及税务系统的12个核心集成接口改造,确保迁移后业务流程无缝衔接;
- 应用改造范围:重点调整SQL语句中Oracle特有语法(如CONNECT BY、MODEL子句),适配金仓数据库的兼容模式,涉及约2000个存储过程及触发器的重构。
政策适配性说明
金仓数据库作为国家信创工委会认证的数据库产品,其技术架构完全符合《信息安全技术 数据库管理系统安全技术要求》(GB/T 20273-2019)及《数据库自主可控评价指标》等政策标准。根据金仓官方文档《信创数据库迁移实施指南》(2024版)说明,KingbaseES已通过三级等保认证及军用信息安全产品认证,在政务、金融等关键领域的迁移案例中,均实现了与国产服务器、操作系统及中间件的无缝适配,政策合规性得到权威机构验证。这为本次迁移项目提供了坚实的政策适配基础,确保项目实施符合国家信创战略的技术路径要求。
原始数据梳理
数据对象梳理
数据对象梳理是 Oracle 到金仓数据库信创改造迁移过程中的基础环节,其核心目标是全面掌握源数据库中各类对象的结构特征与依赖关系,为后续迁移方案设计提供精准依据。该环节需系统性识别并记录数据对象的关键属性,确保迁移后数据库功能与性能的一致性。
数据对象清单获取方法
金仓数据库(KingbaseES)提供了兼容 Oracle 的数据字典视图,可直接用于提取数据对象信息。通过查询 DBA_TABLES、DBA_VIEWS、DBA_INDEXES 等视图,能够高效获取表、视图、索引等基础对象的元数据;对于程序对象与特殊对象,可进一步结合 DBA_PROCEDURES、DBA_TRIGGERS、DBA_PART_TABLES 等视图完成清单梳理。具体视图名称及字段定义可参考《KingbaseES 数据库参考手册》中“兼容 Oracle 视图”章节的详细说明,该章节明确了 Oracle 数据字典视图在 KingbaseES 中的映射关系及使用方法。
关键视图示例:
- 基础对象:
DBA_TABLES(表)、DBA_VIEWS(视图)、DBA_INDEXES(索引)- 程序对象:
DBA_PROCEDURES(存储过程/函数)、DBA_TRIGGERS(触发器)- 特殊对象:
DBA_PART_TABLES(分区表)、DBA_TEMP_TABLES(临时表)
数据对象分类梳理项
根据对象功能与结构特性,可将数据对象分为基础对象、程序对象及特殊对象三类,每类对象需重点梳理以下关键属性:
| 对象类别 | 具体对象 | 核心梳理项 |
|---|---|---|
| 基础对象 | 表 | 表名、所属模式、列定义(名称、数据类型、长度、约束)、主键/外键、存储参数(如表空间、初始大小) |
| 视图 | 视图名、所属模式、定义语句(VIEW_DEFINITION)、依赖表/视图、是否可更新 |
|
| 索引 | 索引名、所属表、索引类型(B树/哈希/位图)、包含列、是否唯一、是否分区索引 | |
| 程序对象 | 存储过程 | 名称、所属模式、输入/输出参数(类型、长度)、返回值类型、依赖对象、执行权限 |
| 函数 | 名称、所属模式、参数列表、返回值类型、确定性(DETERMINISTIC)属性、依赖对象 | |
| 特殊对象 | 分区表 | 表名、分区键(列名)、分区类型(范围/列表/哈希)、分区数量、子分区策略(如有) |
| 临时表 | 表名、作用域(SESSION/GLOBAL)、ON COMMIT 属性(DELETE ROWS/PRESERVE ROWS)、是否有索引 |
通过上述梳理,可建立完整的源数据库对象档案,为后续 schema 转换、数据迁移及兼容性验证奠定基础。梳理过程中需特别注意特殊对象的差异化属性(如分区表的分区策略、临时表的事务隔离特性),这些信息将直接影响迁移脚本的生成与目标库的性能调优。
数据量与业务关联性分析
数据量与业务关联性分析是Oracle到金仓数据库信创改造迁移实施规划的基础环节,其核心目标是通过系统化的量化评估与业务属性识别,为后续迁移策略制定、资源分配及风险管控提供决策依据。该环节需从数据量级测算与业务属性多维评估两个层面展开,形成可落地的分析成果。
数据量统计方法
数据量统计需实现对Oracle数据库中业务数据的全面量化,涵盖记录规模与存储占用两个核心维度。具体实施中,可通过Oracle内置工具与SQL查询组合完成数据采集:
- 记录行数统计:采用
SELECT COUNT(*) FROM table语句获取各表的记录数量,对于超大规模表(如亿级记录),可结合APPROX_COUNT_DISTINCT函数提升查询效率。 - 存储占用测算:通过
DBMS_SPACE系统包(如DBMS_SPACE.TABLESPACE_USAGE_METRICS、DBMS_SPACE.SPACE_USAGE)获取表空间级与对象级的存储占用详情,包括数据文件大小、已用空间、碎片空间等指标。
为确保数据可追溯与业务关联,统计结果需按**“业务模块-表名-行数-占用空间”** 标准化格式整理,形成结构化清单。典型整理样例如下表所示:
| 业务模块 | 表名 | 行数(万行) | 占用空间(GB) | 备注 |
|---|---|---|---|---|
| 用户管理 | T_USER | 1200 | 85 | 含历史用户归档数据 |
| 订单交易 | T_ORDER | 5800 | 320 | 分区表(按交易日期) |
| 商品目录 | T_PRODUCT | 850 | 42 | 含商品图片二进制数据 |
业务关联性评估
业务关联性评估需从数据动态属性与业务价值两个维度构建分析模型,通过多指标交叉判断实现业务优先级的科学划分。评估体系包含以下三个核心维度:
业务关联性三维评估框架
- 数据更新频率:区分实时更新(如订单状态表、支付流水表)与定时更新(如报表汇总表、日志归档表),实时更新表需重点关注迁移过程中的数据一致性保障。
- 查询热度:基于Oracle AWR报告或SQL Monitor工具统计,将表查询频次划分为高(日均查询>1000次)、中(日均100-1000次)、低(日均<100次)三级,高热度表需优先验证查询性能兼容性。
- 业务流程关联度:依据业务架构文档识别核心表与非核心表,核心表通常具备“不可替代性”与“流程枢纽性”特征,如用户信息表(支撑登录认证、权限管理)、订单主表(串联支付、物流、结算全流程)。
核心表标识标准可通过业务影响分析法确立,满足以下任一条件即可判定为核心表:
- 直接支撑关键业务流程(如交易下单、资金结算、用户认证)的主表;
- 数据更新频率为实时且查询热度达到“高”级别的业务表;
- 数据丢失或异常将导致业务中断超过30分钟的关键实体表(如账户余额表、库存明细表)。
通过上述数据量统计与业务关联性评估,可形成“数据量级-业务优先级”二维矩阵,为后续迁移批次划分、资源投入倾斜(如核心大表优先分配高性能服务器资源)及回滚策略制定(如核心表需设计实时同步回滚机制)提供精准依据。例如,用户表(T_USER)与订单表(T_ORDER)作为典型核心表,通常需纳入第一批次迁移范围,并配置额外的迁移验证资源。
新数据库搭建
环境要求与配置
硬件架构要求
KingbaseES数据库的硬件配置需根据目标架构(x86_64、龙芯、飞腾等)进行差异化适配,同时满足国产硬件兼容性要求。具体硬件架构支持如下:
| 硬件架构 | CPU支持类型 | 国产硬件适配要求 |
|---|---|---|
| x86_64 | Intel、AMD、海光、兆芯 | 兼容海光、兆芯等国产x86架构处理器 |
| 龙芯 | 龙芯系列处理器 | 原生支持龙芯架构(LoongArch)处理器 |
| 飞腾 | 飞腾系列处理器 | 原生支持飞腾架构(ARMv8)处理器 |
操作系统支持列表
数据库部署需基于经过兼容性认证的操作系统,推荐使用国产操作系统的稳定版本以满足信创要求。具体操作系统支持情况如下表所示:
| 操作系统类型 | 支持版本范围 | 推荐版本 |
|---|---|---|
| 商用类 | Windows Server 2012+、Linux(RHEL/SUSE/CentOS)、Unix(AIX/HP-UX/Solaris) | - |
| 国产操作系统 | 银河麒麟、统信UOS、麒麟信安、凝思等 | 银河麒麟V10 SP1 |
| 开源操作系统 | openEuler、openKylin等 | openEuler 22.03 LTS |
依赖库要求:在Linux及国产操作系统环境中,需预先安装libaio-devel、glibc-devel、gcc-c++等基础依赖库,确保数据库安装程序可正常编译依赖组件。
网络配置要求
数据库集群部署需满足以下网络环境要求,确保节点通信与服务访问的稳定性:
端口配置:默认需开放54321端口(KingbaseES数据库服务端口),建议通过防火墙策略限制端口访问源IP,增强安全性。
节点互信:主备集群环境中,需配置节点间SSH免密登录,实现自动故障转移与数据同步。具体配置步骤可参考《KingbaseES集群部署指南》中的“网络环境准备”章节,包括生成SSH密钥对、配置
authorized_keys文件权限等操作。
内核参数优化
为保障数据库性能,需调整操作系统内核参数,其中信号量参数需满足以下配置要求:
**信号量内核参数配置规范** 推荐配置值:`sysctl kernel.sem=5010 641280 5010 256` 实施步骤: 1. 检查当前参数:执行`sysctl kernel.sem`查看当前值 2. 若不满足要求,编辑`/etc/sysctl.conf`文件,添加配置项:`kernel.sem=5010 641280 5010 256` 3. 执行`sysctl -p`使配置立即生效,无需重启操作系统其他关键内核参数(如共享内存SHMMAX、文件描述符fs.file-max等)需根据数据库实例规格进行调整,建议参考KingbaseES官方优化指南进行配置。
初始化参数与流程
数据库初始化配置是Oracle向金仓数据库迁移后的基础环节,其参数设置与流程执行直接影响数据库性能表现及稳定性。以下从核心参数配置、标准化流程及验证方法三个维度展开说明。
核心初始化参数配置
金仓数据库的初始化参数需结合业务场景进行针对性调整,以下为关键参数及推荐配置:
| 参数名称 | 推荐值 | 含义说明 | 调整依据 |
|---|---|---|---|
max_connections |
1000 | 数据库最大并发连接数 | 根据业务高峰期并发用户量动态调整,建议预留20%冗余 |
work_mem |
64MB | 单个排序/哈希操作的内存上限 | 依据典型查询的排序数据量设置,OLTP场景建议4MB-64MB |
注:参数调整需遵循《KingbaseES初始化配置手册》中的性能调优指南,避免过度分配导致内存资源竞争。
初始化操作流程
1. 环境变量配置
首先需设置金仓数据库的环境变量,确保命令行工具可正常调用:
操作命令:export PATH=$KINGBASE_HOME/bin:$PATH
说明:将金仓数据库二进制可执行目录添加至系统PATH变量,其中$KINGBASE_HOME为数据库安装路径(如/opt/kingbase/es/V8)。
2. 数据库实例初始化
通过initdb命令完成数据库目录初始化,需指定场景化优化参数:
操作命令:initdb --scenario-tuning=oltp -D /data/kingbase
关键参数:--scenario-tuning=oltp启用OLTP场景优化,自动调整连接池、缓存策略等底层参数;-D指定数据存储目录(需提前创建并授权)。
3. 数据库服务启动
初始化完成后,通过sys_ctl工具启动数据库实例:
操作命令:sys_ctl start -D /data/kingbase
状态验证:执行sys_ctl status -D /data/kingbase确认服务是否正常运行,返回"server is running"表示启动成功。
参数有效性验证
初始化参数配置后需通过官方工具进行验证,确保实际生效值与预期一致:
- 命令行验证:执行
sys_controldata /data/kingbase可查看静态参数(如max_connections)的硬编码值,动态参数需通过sys_psql -c "show work_mem;"查询。 - 手册参考:完整验证步骤及参数解读可参照《KingbaseES初始化配置手册》第3.2节"初始化参数校验流程",该方法已通过金仓数据库官方兼容性认证。
通过以上标准化流程,可确保金仓数据库初始化配置符合业务场景需求,为后续应用迁移奠定稳定运行基础。
兼容性评估
语法与函数差异
在 Oracle 到金仓数据库(KingbaseES)的信创改造迁移过程中,SQL 语法与内置函数的差异是需要重点关注的核心问题。这些差异可能导致迁移后业务逻辑异常或查询结果不一致,需通过针对性调整确保兼容性。
SQL 语法差异
递归查询语法是典型差异点之一。Oracle 中通过 CONNECT BY PRIOR 实现层级数据查询,而 KingbaseES 需采用 SQL 标准的 WITH RECURSIVE 语法替代。例如,查询部门层级结构时:
Oracle 语法:
SELECT dept_id, parent_id, dept_name FROM departments START WITH parent_id IS NULL CONNECT BY PRIOR dept_id = parent_id;KingbaseES 改写示例:
WITH RECURSIVE dept_recursive AS ( -- 初始查询:根节点(无父部门) SELECT dept_id, parent_id, dept_name FROM departments WHERE parent_id IS NULL UNION ALL -- 递归查询:子节点关联父节点 SELECT d.dept_id, d.parent_id, d.dept_name FROM departments d JOIN dept_recursive dr ON d.parent_id = dr.dept_id ) SELECT dept_id, parent_id, dept_name FROM dept_recursive;
正则函数参数差异
正则表达式函数的参数处理逻辑存在显著差异,尤以 match_param 参数最为突出。Oracle 的 REGEXP_INSTR 等函数支持通过 match_param 指定匹配模式(如 'i' 表示忽略大小写),但 KingbaseES 因正则元语法实现不同,需采用替代方案。
以 REGEXP_INSTR 为例,其在 Oracle 与 KingbaseES 中虽标记为“兼容,但有差异”,主要差异源于数据类型(如 time 类型处理)和 match_param 语义[1]。例如,Oracle 中忽略大小写查找字符串位置:
-- Oracle:返回 'Kingbase' 在 'OracleToKingbase' 中的起始位置(忽略大小写)
SELECT REGEXP_INSTR('OracleToKingbase', 'king', 1, 1, 0, 'i') FROM DUAL; -- 结果为 8
而 KingbaseES 中需改用 REGEXP_LIKE 实现忽略大小写匹配判断,若需获取位置信息,需结合其他函数或调整正则表达式:
-- KingbaseES:判断是否包含忽略大小写的 'king'
SELECT CASE WHEN REGEXP_LIKE('OracleToKingbase', 'king', 'i') THEN 1 ELSE 0 END AS is_match; -- 结果为 1
字符函数兼容情况简表
| 序号 | Oracle 函数名 | KingbaseES 是否兼容 | 差异核心原因 |
|---|---|---|---|
| 1 | CHR | 兼容,但有差异 | 正则 match_param 语义不同 |
| 2 | REGEXP_INSTR | 兼容,但有差异 | 数据类型(如 time)及正则元语法差异 |
| 3 | REPLACE | 兼容,但有差异 | 正则 match_param 处理逻辑不同 |
日期函数兼容情况
多数日期函数在 KingbaseES 中可直接使用或仅需微调:
- SYSDATE:完全兼容,均返回当前系统日期时间。
- TO_DATE:格式字符串需保持一致,例如
TO_DATE('2023-01-01','YYYY-MM-DD')在两者中行为一致。 - ADD_MONTHS:标记为“兼容”,但具体实现细节未明确,建议迁移后通过边界值测试验证(如月底日期处理)。
数据类型与对象兼容性
Oracle 与 KingbaseES 在数据类型与对象模型上存在一定差异,迁移过程中需针对特有类型、对象定义及序列语法进行针对性适配,以确保应用功能的一致性。
特有数据类型迁移方法
对于 Oracle 特有数据类型,需采用特定转换策略:BFILE 类型需转换为 KingbaseES 的 BYTEA 类型,并通过存储文件路径实现外部数据引用;XMLType 类型则迁移为 KingbaseES 的 XML 类型,同时需使用 XPath 函数替代原 Oracle 中的 XML 处理逻辑。此外,数值类型中需特别注意 numeric(38, 0) 的映射,在 GIS 迁移等场景下,需通过编辑数据类型映射文件将其明确映射为 int 类型,而非默认的 numeric 类型,以避免潜在的性能或兼容性问题。
数据类型差异与兼容策略
不同数据类型在语法支持和隐式转换规则上存在差异,需重点关注以下方面:
- 数值类型:KingbaseES V9 不支持 bool 类型到 text 类型的隐式转换,涉及 like 等依赖此转换的操作时需显式处理数据类型。例如,需通过
CAST(bool_col AS TEXT)方式手动转换后再执行字符串匹配操作。 - JSON 类型:在 Oracle 模式下,KingbaseES 支持
->->>操作符及ARRAY_TO_JSONJSON_ARRAYAGGJSON_OBJECTAGG等函数,但需注意部分函数的参数处理逻辑可能存在细微差异,建议迁移后进行功能验证。 - 函数兼容性:部分函数因数据类型差异可能导致结果不同,如
REGEXP_INSTR函数在处理 time 类型数据时,需确认 KingbaseES 的类型处理逻辑是否与 Oracle 一致,并根据实际场景调整参数或转换数据类型。
对象类型定义转换
Oracle 的对象类型定义语法需调整以适配 KingbaseES。例如,Oracle 中 CREATE TYPE emp_type AS OBJECT (id INT, name VARCHAR2(50)) 的对象类型定义,在 KingbaseES 中需修改为 CREATE TYPE emp_type AS COMPOSITE TYPE (id INT, name VARCHAR2(50)),通过 COMPOSITE TYPE 关键字替代 OBJECT 实现对象类型的兼容定义。
序列语法兼容性
序列对象在迁移中具有较高兼容性,Oracle 中常用的 CREATE SEQUENCE seq_name START WITH 1 INCREMENT BY 1 NOCACHE 语法在 KingbaseES 中可直接使用,无需调整。具体兼容性细节可参考《KingbaseES 对象兼容指南》中的“序列”章节,确保序列的缓存策略、步长等属性在迁移后保持一致。
迁移关键注意事项:
- 编辑数据类型映射文件时,需参考官方数据类型映射指南,确保 numeric(38, 0) 等特殊类型正确映射。
- 对象类型转换后,需检查依赖该类型的存储过程、函数是否同步调整了引用语法。
- 涉及 JSON 或 XML 操作的业务逻辑,建议在测试环境中通过典型用例验证功能正确性。
| 数据类型名 | KingbaseES V9 处理方式 | 说明 |
|---|---|---|
| bool | 不支持隐式转换为 text | like 操作需显式转换 CAST(bool AS TEXT) |
| numeric(38, 0) | 映射为 int 类型 | GIS 迁移中需通过配置文件指定 |
| BFILE | 转换为 BYTEA 并存储文件路径 | 需同步迁移外部文件至目标存储路径 |
| XMLType | 迁移为 XML 类型,使用 XPath 函数处理 | 替代 Oracle 特有的 XML 操作函数 |
数据迁移方案
ETL工具选择与配置
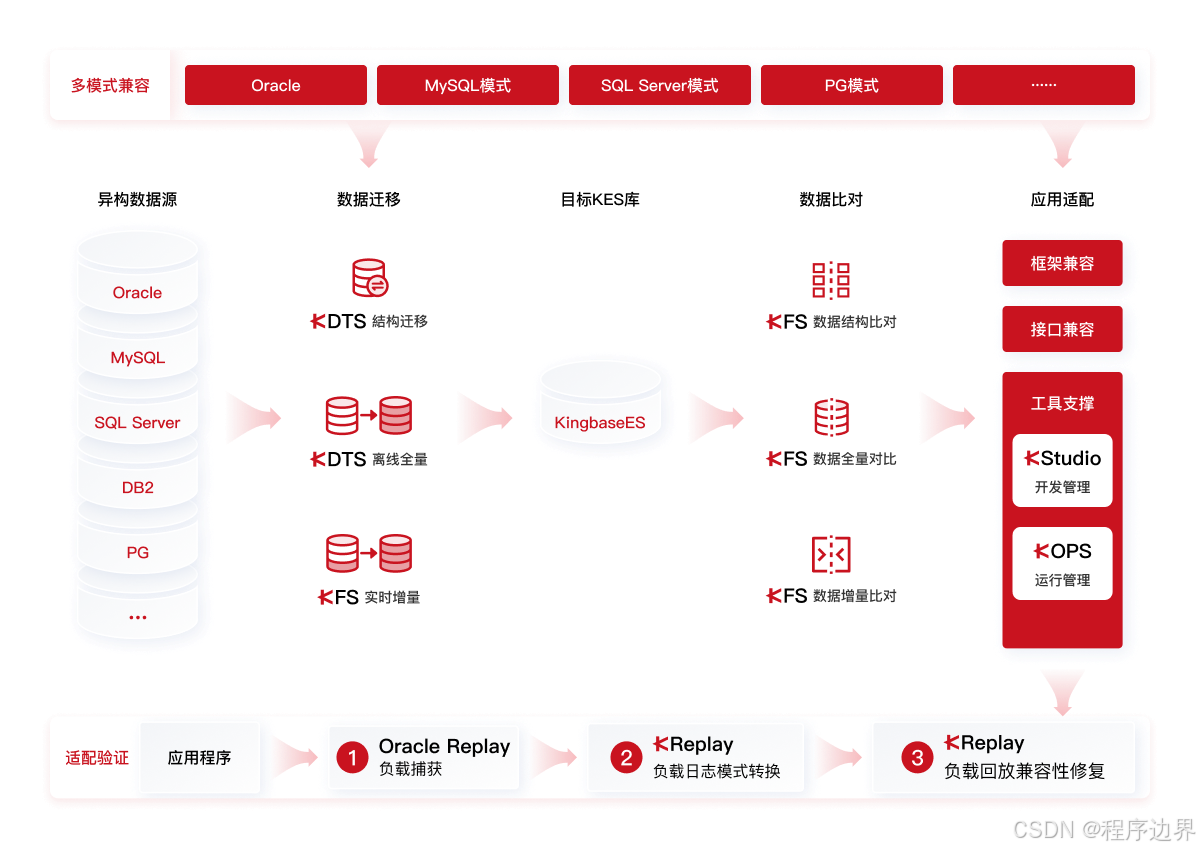
在Oracle到金仓数据库的信创改造迁移中,ETL工具是实现数据迁移的核心组件,可通过其完成初始数据搬迁至异构目标数据库的过程[1]。综合迁移需求与工具特性,KDTS(金仓数据迁移工具) 被选为本次迁移的核心工具,其支持Oracle至KingbaseES的异构数据库迁移,并提供“迁移部分表”“按条件迁移”等精细化功能[2]。以下从工具安装、数据源配置及任务调度三方面展开实施配置。
工具安装步骤
KDTS工具的安装需完成环境准备与基础配置,具体步骤如下:
安装包获取
通过官方渠道下载KDTS安装包,下载链接:https://pan.baidu.com/s/19kne0fuESTDSoSD9RWMVYQ,提取码:fxti[2]。JDK环境配置
安装并配置JDK 1.8及以上版本,确保环境变量JAVA_HOME指向JDK安装路径,验证命令:java -version需返回1.8+版本信息。环境变量设置
解压安装包后,配置KDTS_HOME环境变量指向工具根目录,例如:- Windows系统:
set KDTS_HOME=C:\\kingbase\\kdts - Linux系统:
export KDTS_HOME=/opt/kingbase/kdts
- Windows系统:
数据源配置
数据源配置是确保ETL工具与源端Oracle、目标端金仓数据库建立连接的关键步骤,需分别配置连接参数并验证连通性。
Oracle源端配置
连接URL格式:jdbc:oracle:thin:@//ip:port/service_name
其中,ip为Oracle数据库服务器IP地址,port为监听端口(默认1521),service_name为数据库服务名。金仓目标端配置
连接URL格式:jdbc:kingbase8://ip:port/dbname
其中,ip为金仓数据库服务器IP地址,port为服务端口(默认54321),dbname为目标数据库名称。配置文件示例
在KDTS安装目录下的conf/datasource.xml文件中添加数据源配置:<!-- Oracle数据源配置 --> <datasource id="oracle_source"> <type>oracle</type> <url>jdbc:oracle:thin:@//192.168.1.100:1521/orcl</url> <username>system</username> <password>oracle123</password> </datasource> <!-- 金仓数据源配置 --> <datasource id="kingbase_target"> <type>kingbase8</type> <url>jdbc:kingbase8://192.168.1.200:54321/kingbase</url> <username>sysdba</username> <password>kingbase123</password> </datasource>
任务调度配置
通过KDTS的“定时任务”功能可实现自动化数据迁移,需配置全量迁移、增量同步策略及异常处理机制,确保数据一致性与迁移连续性。
迁移策略设置
- 每日全量迁移:在KDTS控制台“定时任务”模块新建任务,触发时间设为每日凌晨2:00,执行全量数据抽取与加载,覆盖源端全表数据。
- 每小时增量同步:创建增量任务,触发周期设为每小时整点,通过CDC(变更数据捕获)机制捕获Oracle的增量数据(如新增、更新记录)并同步至金仓数据库。
异常处理配置
- 失败重试机制:在任务配置界面设置“失败重试次数”为3次,重试间隔5分钟,避免因网络波动等临时故障导致迁移中断。
- 告警通知:启用“告警通知”功能,配置SMTP邮件服务器(如SMTP服务器地址:smtp.example.com,端口:25)及短信网关,当任务连续失败3次时自动发送告警信息至管理员。
通过上述步骤,可完成KDTS工具的部署与配置,为Oracle到金仓数据库的全量迁移与增量同步提供稳定、自动化的执行环境。