前言
管道是进程间通信最古老的一种方式,在命令行中使用的ll | grep add筛选出add文件中的|底层就是管道。管道将一个进程的数据交给另一个进程来处理,实现不同进程间的通信。
管道根据命名方式可以分为两种:有名管道和匿名管道。
本文将分为三部分讲解管道的实现方法以及使用细节:
- 管道的原理;
- 匿名管道的接口;
- 管道的应用场景;
- 命名管道的使用和特点;
管道的原理
因为进程间具有独立性,两个独立的进程想要进行通信很难;如果想要进行通信就要让两个不同的进程都能看到并访问同一份资源。
我们知道fork()能够创建子进程,并且父子进程使用同一份代码,共用资源,那么父子进程是不是能够直接进行通信,是不是可以使用一个全局对象,让他们进行通信???
当然答案是不行的,父子进程确实可以看到同一份资源,但是如果一个进程对公共资源进行修改就会发生写实拷贝,另一个进程是看不到修改后内容的,因此也就无法进行通信了。
那是不是能通过一个磁盘上的文件,让两个进程都能向其中读取和写入。
是的,这样做当然是可以的,两个进程可以打开同一个文件,一个进程专门向里面写入,而另一个进程专门读取,这样就能实现进程间的通信了。
只不过与磁盘IO效率是很低的,写入方先将信息写入到内存缓冲区中,再刷新到文件内;读取方则要等到磁盘上的文件加载到内存中,再进行读取操作。
通过上面的操作流程我们会发现:数据都是进程写入和读取都是面向内存的,那么上面的向文件中读和写是不是有些多余了。可不可以让写入方直接写到内存中,而读取方也从内存中进行读取,这样不久不需要与外设进行IO了嘛。
确实,管道的原理就是如此,管道就是一个内存级的文件,允许两个进程共同访问这一块内存空间。
下面我将以匿名管道为例,解释一下,管道的底层逻辑:
匿名管道没有名字,所以匿名管道只能在有血缘关系的进程中使用,如:父子,孙子,兄弟…
匿名管道没有名字,两个独立的进程无法进行表示确定自己看到的是同一份文件;所以匿名管道只能通过继承的方式让父子进程能够看到同一份资源。
因为子进程会继承父进程打开的所有文件,所以只要让父进程打开一个管道文件后,通过fork()创建的主进程也能看到该管道文件。
那么父进程要以什么方式打开管道文件,读?写?
答案都不是,如果以只读或只写方式打开文件,子进程也就只能只读或只写,而我们希望的是一个进程写,另一个进程读,所以打开文件的方式应当是可读并且可写。
- 父进程打开管道文件分别以只读,只写的方式;
- 创建子进程,子进程继承父进程的管道文件;
该过程的示意图如下: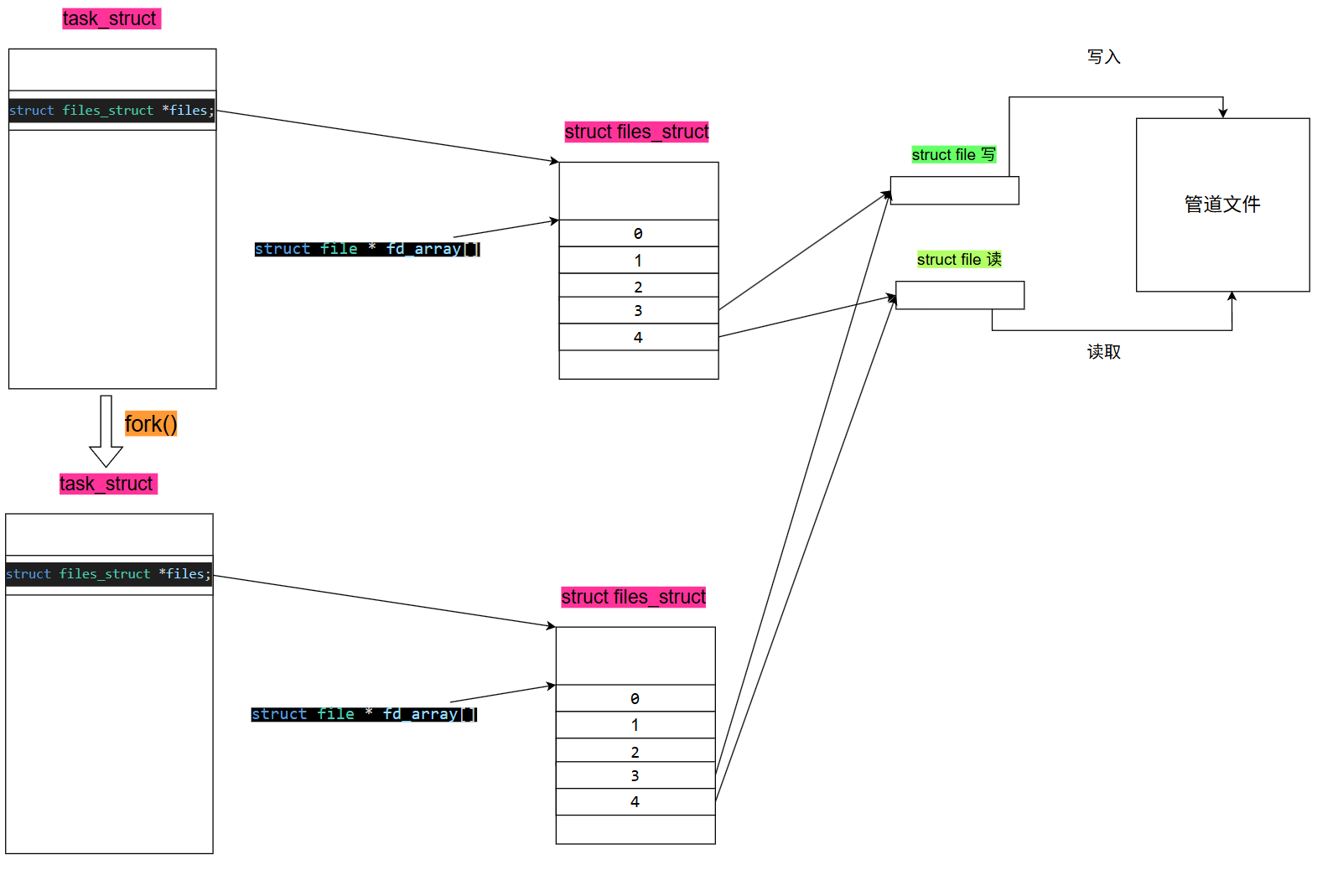
在进行编码的时候,在确定父进程和子进程的任务后,应当将不需要的接口进行关闭;比如:父进程读,子进程写,那么当父进程创建完子进程后,就应该把对应的写端关闭,子进程同样也要把读端关闭,来防止两个进程同时写入或读取,导致数据读取出错。
以上这种基于文件的通信方式,只能进行单向通信,因此将其命名位管道通信。
总结,管道通信中通信双方要做的事:
- 父进程分别以读写的方式打开一个文件,该文件是内存级文件;
fork()创建子进程,让子进程继承父进程的管道文件;- 让父子进程关闭不需要的接口,保证单向通信。
如果两个进程需要进行双向通信,可以使用两个管道来实现。
以上讲解中谈到的管道文件没有文件名,文件inode,无标识路径,是通过继承的方式来达到共享的效果的,所以被称为匿名管道。
匿名管道的接口
匿名管道的接口很简单,我们只需要让父进程打开一个管道文件就行了。
操作系统提供了一个接口int pipe(int pipefd[2]),该接口负责让操作系统提供管道文件;
- 其参数
pipefd[2]是输出型参数,用来获取管道文件的输入输出文件描述符,其中pipefd[0]是读文件描述符,而pipefd[1]是写文件描述符。 - 返回值表示管道文件是否创建成功,0表示创建成功,-1表示创建失败。
找后面关于管道的应用场景中会详细介绍该接口如何使用。
管道的特点
管道也是有大小的,通过ulimit -a查看用户进程资源限制:
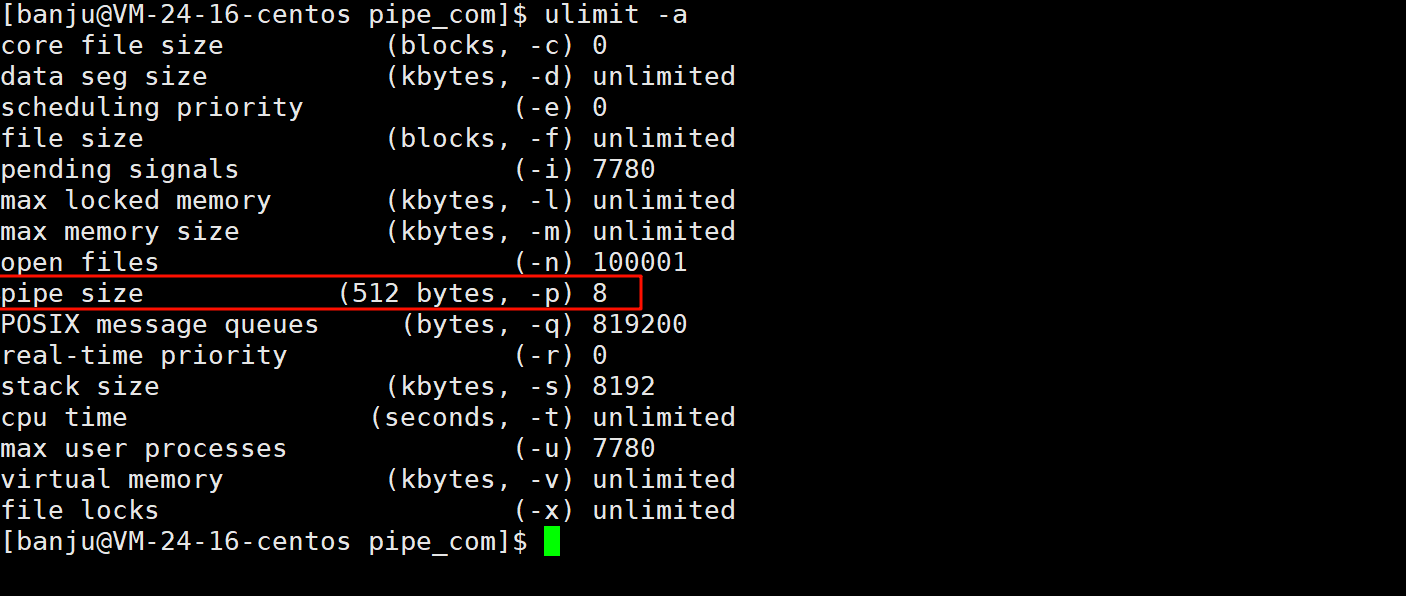
上面的pipe size指的是一个管道可容纳的最大数据量。
在管道中还有一个大小,被称为PIPE_BUF,该值是一个临界值,一般是4kb,如果一次向管道中写入的数据超过了PIPE_BUF的大小,系统就不会保证原子性,可以理解为操作系统会将发送的数据分成多份,此时如果有其他进程也在向里面写就会导致数据不一致问题。
- 对于匿名管道来说,只有具有血缘关系的进程才能进行通信;
- 管道只能进行单向通信;
- 对于管道的使用父子进程会进行协同的,当一个进程在向管道中写入时,另一个进程就不能读,同样如果一个进程在进行读取,并一个叫进程也不能进行写入,会阻塞在哪里,知道另一方使用完后,才使用;
- 管道时面向字节流的,向管道中写入和读取的都是字符串;
- 管道时基于文件的,管道文件的生命周期随进程。
管道的使用很多种情况:
- 读端和写端都正常,可以进行通信;
- 读端正常,写端关闭,读端就会读到0,表示管道为空,此时就不会阻塞了;
- 写端正常,读端关闭,读端已经没了,写端也就没有用了,此时操作系统会直接杀死正在向管道中进行写入的进程,是通过向进程发送13号信号杀死的。
管道的应用场景
命令行
在命令行中可以使用管道对资源进行筛选,如ll | grep test会将ll的输出结果给后面的指令,让后面的指在进行操作,能够起到对输出资源筛选的目的。
简单的求和程序
下面借助管道实现一个简单的求个程序:
- 子进程负责接受读取用户的输入,将读取到的数据交给父进程;
- 父进程对接收到的数据进行处理,并将结果打印到显示器上。
- 主函数
main()函数,创建管道文件,创建子进程,让父子进程分流,执行相应的函数:
int main()
{
if(n < 0) return 1;
pid_t id = fork();
if(id == 0)
{
close(fd[0]); // 让子进程负责写
Write(fd[1]);
exit(0);
}
close(fd[1]); // 父进程负责读
Read(fd[0]);
}
- 编写子进程的
Write函数,读取用户的数据,并将其写入到管道文件中:
void Write(int wfd)
{
while(true)
{
std::string buffer;
getline(std::cin , buffer);
// 向管道中写入数据
write(wfd , buffer.c_str() , buffer.size());
}
}
- 父进程从管道中读取,并将读取到的数据内容进行提取,保证计算的参数只有两个:
int Get_value(char* buffer , int n , int* x , int* y)
{
int flag = 0 , index = 0;
while(index < n )
{
char ch = buffer[index];
if(isspace(ch))
{
index ++;
continue;
}
if(!isdigit(ch)) return -1;
// 该位置是数字进行读取
int tmp = 0;
while(isdigit(buffer[index])) tmp = tmp*10 + buffer[index++] - '0';
if(flag == 0 ) *x = tmp;
else *y = tmp;
flag++;
}
return flag == 2 ? 0 : -1;
}
void Read(int rfd)
{
while(true)
{
char buffer[1024];
int n = read(rfd , buffer , sizeof(buffer));
buffer[n] = 0;
// 读取buffer中的数字
int x , y;
int flag = Get_value(buffer , n , &x , &y);
std::cout << " get a task " << buffer << std::endl;
if(flag == -1) std::cout << " err import" << std::endl;
else std::cout << " answer is :" << x + y << std::endl;
}
}
以上就是通过管道将获取数据与计算数据的工作进行分开,交给不同的进程来完成。
进程池
进程池就是提前创建出一对进程,当有任务需要进程来完成的时候,就可以直接将任务给对应的进程而不用再创建进程了,下面简单实现一个线程池功能。
要保证父进程能够与所有子进程将进行通信,那么就必须与每一个子进程建立管道。
首先我们需要一个结构体能够描述各个子进程,这样父进程才能管理子进程:
设置一个channel结构体:
其内部成员包含:
- 一个文件描述符
wfd,用来记录父进程通过那个文件描述符向该子进程的管道中写入; - 一个
slaverid_记录子进程的PID,如果父进程要等待该子进程能找到其PID; - 最后一个
process_name_存储子进程的名称。
struct channel
{
channel(int fd , pid_t slaverid , std::string name)
:wfd_(fd) , slaverid_(slaverid) , process_name_(name)
{}
int wfd_;
pid_t slaverid_;
std::string process_name_;
};
设置进程池的类:
class process_poll
{
public:
process_poll(int sz = 10) // sz表示进程池中进程的个数
:sz_(sz), isrunning_(false)
{}
private:
std::vector<channel> channels; // 用来存储每个进程的信息
int sz_;
};
启动进程池,即创建子进程及通信管道:
class process_poll
{
public:
int Run()
{
// 启动线程池, 创建sz个线程
for(int i = 0 ; i < sz_ ; i++)
{
int fd[2] = {};
int n = pipe(fd); // 创建管道
if(n < 0) return -1;
pid_t id = fork(); // 创建子进程
if(id == 0)
{
dup2(fd[0] , 0); // 将子进程的0文件描述符用fd[0]替代,让子进程的标准输入设置为管道
close(fd[1]); // 关闭写
slaver();
}
close(fd[0]); // 父进程关闭读
std::string name = "process" + std::to_string(i + 1);
channel tmp(fd[1] , id , name);
channels.push_back(tmp); // 存储子进程的信息
sleep(1);
}
}
private:
std::vector<channel> channels; // 用来存储每个进程的信息
int sz_;
};
编写主函数,使用进程池,此处简单一点,父进程向子进程发送两个随机数,让子进程输出结果:
#include <iostream>
#include "process_poll.hpp"
int main()
{
process_poll pp;
pp.Run();
// 向线程池中发送数据
int n = pp.size();
srand((unsigned int)time(nullptr));
while(true)
{
// 向线程池中发送数据
// 此处就简单一点发送两个随机数给子进程,让子进程来计算结果
int x = rand()%100 , y = rand()%100;
int i = rand()%n; // 表示向哪一个进程中发送数据
std::string message = std::to_string(x) + " " + std::to_string(y);
write(pp[i] , message.c_str() , message.size());
sleep(1);
}
return 0;
}
子进程对数据进行处理:
class process_poll
{
privete:
void slaver()
{
char buffer[1024];
while(1)
{
buffer[0] = 0;
int n = read(0 , buffer , sizeof(buffer));
buffer[n] = 0;
int i = 0 , x = 0 , y = 0;
std::cout << " " << getpid() << " get a message : " << buffer;
while(i < n && isdigit(buffer[i])) x = x*10 + buffer[i++] - '0';
while(i < n && isspace(buffer[i])) i++;
while(i < n && isdigit(buffer[i])) y = y*10 + buffer[i++] - '0';
std::cout << " , the answer is : " << x + y << std::endl; \
}
}
}
以上就是线程池设定和使用的方式,最后还有一个收尾工作,将子进程释放:
class process_poll
{
public:
~process_poll()
{
for(auto& ch: channels) close(ch.wfd_);
for(auto& ch: channels) waitpid(ch.slaverid_ , nullptr , 0);
}
private:
std::vector<channel> channels; // 用来存储每个进程的信息
int sz_;
}
上面代码中:父进程先关闭每个进程的写端,所有子进程的写端都关闭完后,再进程等待。
思考能否以下面方式实现:在关闭对应写端之后就直接进行进程等待。
~process_poll()
{
for(auto& ch: channels)
{
close(ch.wfd_);
waitpid(ch.slaverid_ , nullptr , 0);
}
}
答案是不行的,因为上面代码中有一个小细节,就是父进程中含有每一个子进程管道的写端,那么后面创建的子进程会继承父进程的文件信息,后面的子进程也含有前面已经开辟的子进程的写端,一次如果使用上述处理方式,就会导致子进程的写端并没有全部关闭,还会一直阻塞在read上,而父进程又阻塞在waitpid上,导致整个程序都阻塞住。
- 但是正着不行,反过来,从后往前就可以将
close和waitpid放到一起了; - 或者在创建子进程的时候,将前面子进程的写端关闭.
命名管道的使用和特点
上面所说的匿名管道只能实现具有血缘关系的进行间进行通信,因此如果希望两个毫不相关的进程也能实现通信,可以采用命名管道的方式。
命名管道和普通文件最大的区别就是:命名管道是内存级别的,不需要将其中的数据写入到外设中,不用与外设进行交互。
命名管道有inode,文件名,路径,所以可以让两个进程来确定看到同一份资源。
- 在Linux中提供接口,
int mkfifo(const char* pathname , mode_t mode)来创建管道文件,; - 创建完管道文件后,通信双方打开文件后就可以进行通信了。
- 使用
int unlink(const char* pathname)来关闭管道文件.
可以将有名管道的创建和关闭封装成函数,这样我们就不需要担心,命名管道空间不被释放的问题了:
class Name_Pipe
{
public:
Name_Pipe(const std::string& path_name , int mode)
:path_name_(path_name) , mode_(mode)
{
// 创建管道文件
int n = mkfifo(path_name_.c_str() , mode_);
if(n < 0)
{
cout << "mkfifo error : message " << strerror(errno) << endl;
exit(-1);
}
}
~Name_Pipe()
{
// 关闭管道文件
int n = unlink(path_name_.c_str());
if(n < 0)
{
cout << "unlink error : message " << strerror(errno) << endl;
exit(-1);
}
}
private:
std::string path_name_; // 管道名称
int mode_; // 管道权限
};
通过上面的类,让两个进程中的一个创建管道文件即可,这样两个进程向使用普通文件一个使用管道文件进行通信了,下面假设server负责创建管道,并进行读取:
const string file_name = "./pipe_file"; // 文件名
const int mode = 0666; // 管道文件的权限
int main()
{
Name_Pipe np(file_name , 0666); // 创建管道文件
// 打开管道文件 ,server负责读取
int fd = open(file_name.c_str() , O_RDONLY);
if(fd < 0)
{
cout << "open failed " << endl;
exit(1);
}
// 从文件中读取
char buffer[1024];
buffer[0] = 0;
int n = read(fd , buffer , sizeof(buffer));
if(n > 0)
{
buffer[n] = 0;
// 使用读取到的数据
// ......
}
return 0;
}
通过上面的代码,我们确实也可以在目录下看到成功创建的管道文件:
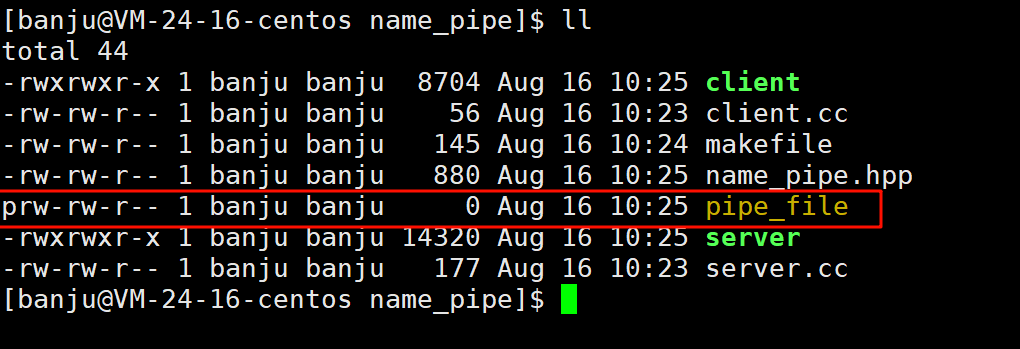
下面简单实现客户端发送数据的代码:
int main()
{
const string path_name = "./pipe_file";
int fd = open(path_name.c_str() , O_WRONLY);
string message;
// 填充数据
// ......
// 发送数据
write(fd , message.c_str() , message.size());
return 0;
}