
1. 关系型数据库与非关系型数据库区别
在数据库世界里有两大主流阵营:
- 关系型数据库(RDBMS)
- 非关系型数据库(NoSQL)
两者的区别如下表所示:
| 特性 | 关系型(MySQL、PostgreSQL) | 非关系型(MongoDB、Redis) |
|---|---|---|
| 数据模型 | 严格表结构:行+列 | 键值、文档、列族、图等多样 |
| 事务支持 | 完整 ACID | 视产品而定,常弱事务或无事务 |
| 查询语言 | SQL | 各家自有 API/查询语法 |
| 模式(Schema) | 固定模式,字段需预定义 | 弱模式,字段可随意扩展 |
| 适用场景 | 强一致、结构化数据 | 海量、不规则或高并发场景 |
MySQL 属于关系型数据库,擅长结构化、强一致性业务(交易、订单、库存等)。如果要做秒杀缓存、实时统计,Redis/MongoDB 这类 NoSQL 可能更合适。
2. MySQL 基本组成
MySQL 内部大体分为两层:
- Server 层:负责连接、解析、优化、缓存、权限等“公共”逻辑。
- 存储引擎层:负责真正的数据读写、事务、索引。最常用的是 InnoDB,它提供了行级锁、MVCC、多版本事务等高级特性。
3. SQL 语句执行过程
执行一条 SQL 语句,会经历以下流程:
(1) 建立连接
- 客户端(命令行、JDBC、ORM 等)通过 TCP 与服务器交握。
- 账号密码验证、SSL 加密、权限检查。
(2) 语法解析(Parser)
- 词法分析:把字符串拆成“关键字、标识符、常量”。
- 语法分析:构建语法树,验证语法合法性。
- 预处理:权限、表名、字段名、函数是否存在。
(3) 查询优化(Optimizer)
- 生成候选执行计划:是否走索引、走哪个索引、使用临时表或排序。
- 成本估算:基于统计信息(表大小、索引选择性)。
- 选择最优计划。
(4) 执行器(Executor)
- 根据计划向存储引擎发送请求。
- InnoDB 根据索引定位数据页(16KB),判断是否命中 Buffer Pool,否则去磁盘。
- 读取或过滤记录,必要时做排序、分组、聚合。
(5) 返回结果
- 结果集格式化成网络数据包。
- 通过连接返回客户端。
4. MySQL索引
4.1 索引的目的
索引可以类比于书的目录,索引把数据组织成“可快速查找”的结构,从而加速查询。
按数据结构分,MySQL 常见索引有 B+树(B+Tree)索引、哈希(HASH)索引、全文(Full-Text)索引[1]。
三者的主要主要区别如下:
B+ 树索引 —— 像“电话簿”
- 形象比喻:想查“张三”的电话,你翻电话簿,先按姓氏定位大致页码,再在那一页里顺序扫几行就能找到。
- 关键特性:数据是按顺序排好的,一页接一页(有点像一本排好序的目录)。树层数少,每次只需“翻几页”就能到目标,磁盘读取次数少。
Hash 索引 —— 像“查字典”
- 形象比喻:要查“苹果”对应的单词,不用一页页翻,而是直接跳到“苹果”那一格。
- 关键特性:直接把关键字算成一个位置,一步命中。
Full-Text 索引 —— 像“书后面的词汇表”
- 形象比喻:一本大书后面的“索引页”,列出“某个词在哪几页出现过”。
- 关键特性:把长文本“切成词”并记录每个词出现在哪些行(倒排表),适合做“关键词搜索”。
4.2 为什么采用 B+ 树索引
MySQL(默认的 InnoDB 引擎)几乎所有表的主键、普通二级索引底层都是 B+ 树,为什么要采用B+ 树呢?
要回答这个问题,需要先从二叉树的结构开始了解。
二叉搜索树的结构如下图[2]所示:
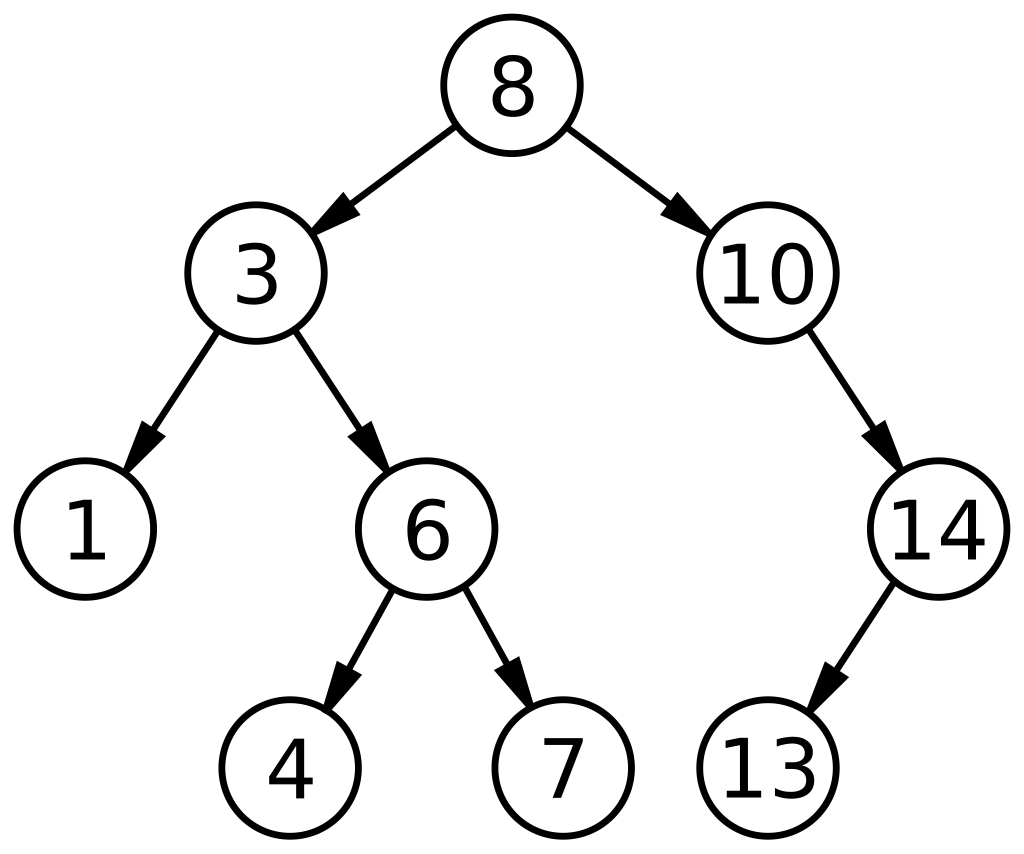
二叉搜索树的设计来自二分搜索的思路,即把值小于根节点的数值放到左侧,大于根节点的数值放到右侧,能快速进行搜索,不需要像二分搜索那样每次对中间值进行计算。
然而如果插入的数值一直大于或小于根节点,就只会在右子树/左子树一直插入,二叉树就会退化成链表。
为解决这个问题,出现了一种新的树,自平衡二叉查找树(AVL树),通过旋转的方式,每个节点的左子树和右子树的高度差不能超过 1。
![AVL树旋转示意图[2]](https://i-blog.csdnimg.cn/img_convert/e72245252fee0ec5c66c08b7d20f121b.gif)
然而,随着数据量的增大,二叉树的高度还是会不断变高,每增加一层高度,查询数据时,就需要多一次硬盘IO操作。
为了解决降低树的高度的问题,后面就出来了 B 树,它不再限制一个节点就只能有 2 个子节点,而是允许 M 个子节点 (M>2),从而降低树的高度[1]。
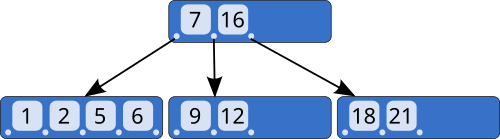
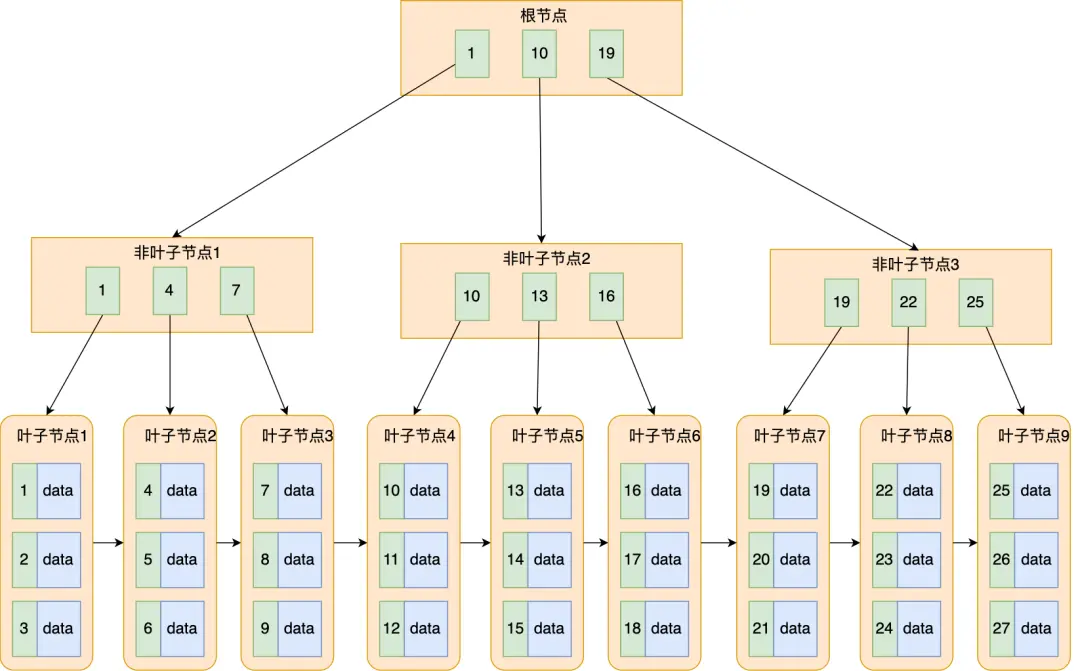
B+树在B树的基础上又进行了改良,主要的改良的规则如下:
- 非叶子节点只存放索引,叶子节点才存放实际数据(索引+记录)
- 叶子节点之间构成一个链表(Innodb进一步改成双向链表),能够快速进行相邻节点的查询
具体结构如下图[1]所示。
总结一下,MySQL 采用 B+ 树索引的原因主要有以下三点:
-
- B+ 树树高比较低,能有效减少IO操作,使查询速度变快;
-
- B+ 树叶子非叶子节点存在冗余索引,使B+树在插入、删除时效率更高;
-
- B+ 树的叶子节点通过链表连接,有利于范围查询。
此外,是按页(Page)为单位来管理存储和缓存的。默认页大小为 16 KB,一页可以容纳成百上千行的记录或索引键,在 B+ 树里,每个节点就是一页,三层 B+ 树大概只需 3~4 次 I/O 就能定位上百万行数据的位置。
4.3 索引失效情况
虽然索引能极大提升查询效率,但在某些情况下优化器无法使用索引,称为索引失效。
以下几种情况会导致索引失效:
1.使用函数或表达式
索引存储的是列的原始值,如果在查询条件中对列做了函数或运算,索引无法直接匹配:
-- 索引列 age 上有索引
SELECT * FROM users WHERE YEAR(birthday) = 1990; -- 索引失效
SELECT * FROM users WHERE age + 1 = 30; -- 索引失效
2. 隐式类型转换
当查询值类型与索引列类型不一致时,MySQL 会做类型转换,导致索引失效:
-- age 是 INT 类型
SELECT * FROM users WHERE age = '30'; -- 索引可能失效
3. 前置通配符的 LIKE 查询
B+ 树索引是按字典序有序排列的,只支持前缀匹配:
SELECT * FROM products WHERE name LIKE '%phone%'; -- 索引失效
SELECT * FROM products WHERE name LIKE 'iPhone%'; -- 索引可用
4. OR 条件未覆盖索引列
如果 OR 条件中有列不在同一索引中,MySQL 会放弃使用索引:
SELECT * FROM users WHERE age = 30 OR city = 'Beijing'; -- 索引可能失效
5. 隐式计算导致范围查询失效
对索引列进行运算后再比较,会让索引失效:
SELECT * FROM orders WHERE price * 0.9 > 100; -- 索引失效
6. 数据量过小
如果表记录数很少,优化器可能认为全表扫描比走索引更快,此时也会忽略索引。
5. MySQL 事务
5.1 事务的基本特性
事务(Transaction)是保证数据一致性和可靠性的重要机制。事务可以理解为一组操作的集合,这些操作要么全部成功,要么全部失败,不会出现部分执行的情况。
事物具备以下四大特性(ACID)
| 特性 | 含义 | InnoDB 实现方式 |
|---|---|---|
| Atomicity(原子性) | 事务中的操作要么全部提交,要么全部回滚 | Undo 日志 + 回滚机制 |
| Consistency(一致性) | 事务前后,数据库必须处于一致状态 | 约束、触发器、事务隔离保证 |
| Isolation(隔离性) | 并发事务之间互不干扰 | 锁机制、MVCC(多版本并发控制) |
| Durability(持久性) | 事务提交后数据永久保存在数据库中 | Redo 日志 + 刷盘机制 |
5.2 事务的基本操作
MySQL 提供几条基本语句来控制事务:
-- 开始事务
START TRANSACTION; -- 或 BEGIN;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
示例:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 如果两条都成功
COMMIT;
-- 如果发生错误
ROLLBACK;
这个例子演示了转账操作的原子性:资金要么成功转出并入账,要么全部不执行。
5.3 事务隔离级别
当多个事务并发执行的时候,会引发脏读、不可重复读、幻读这些问题,
- 脏读:读到其他事务未提交的数据;
- 不可重复读:同一个事务里,两次读取同一行,结果不一样;
- 幻读:同一个事务里,两次按相同条件查,第一次没有的行,第二次多出“幻影行”。
通俗理解:
- 脏读:别人还没交,我就偷看了
- 不可重复读:别人改了我看的那行
- 幻读:别人插了我查不到的新行
那为了避免这些问题,SQL 提出了四种隔离级别,分别是读未提交、读已提交、可重复读、串行化,从左往右隔离级别顺序递增,隔离级别越高,意味着性能越差[1]。
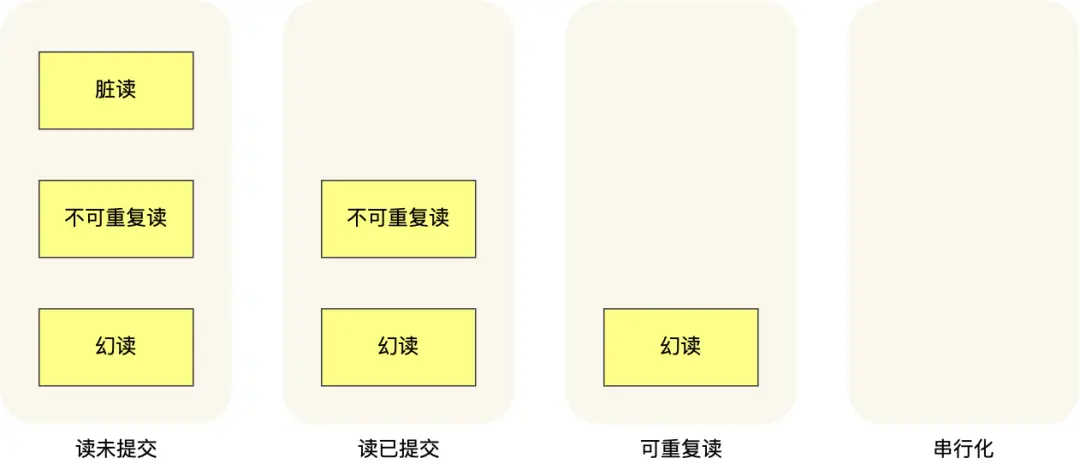
- 读未提交:可以看到其他事务尚未提交的修改,相当于几乎不隔离。
- 读已提交:只能看到已经提交的其他事务修改结果,避免脏读。
- 可重复读:保证同一事务内,多次读取同一行数据结果一致,即快照读,InnoDB 默认隔离级别。
- 串行化:所有事务按顺序串行执行,好比加全表锁。
通俗理解:
- 读未提交:我连草稿都能看到
- 读已提交:只看别人交的作业
- 可重复读:我只看自己的拍照副本
- 串行化:大家排队,一个个来
5.4 InnoDB 事务实现原理
为满足事务的四大特性,InnoDB采用以下方式进行实现。
1. Undo 日志
- 用于回滚事务和支持MVCC;
- 每条修改都会先记录 Undo 日志,如果事务回滚,数据库根据日志恢复数据。
2. Redo 日志
- 用于保证 提交后数据持久性;
- 先写日志再刷磁盘,保证即使系统崩溃也不会丢数据。
3. MVCC(多版本并发控制)
- 支持非阻塞读,减少锁冲突;
- 查询时读取符合快照版本的数据,保证一致性和隔离性。
4. 锁机制
- 使用锁机制避免写冲突,支持高并发事务操作。
6. MySQL 锁机制
事务的隔离性离不开锁。锁(Lock)用于协调并发访问,防止数据冲突。
6.1 锁分类
按照作用范围,MySQL的锁可分为全局锁、表级锁和行级锁。
| 分类 | 说明 |
|---|---|
| 全局锁 | 影响整个库,备份场景使用 |
| 表级锁 | 影响整张表 |
| 行级锁 | 仅锁住被访问行,InnoDB 主要依赖行锁 |
行级锁进一步包括记录锁(Record Lock)、间隙锁(Gap Lock)和临键锁(Next-Key Lock)。
1. Record Lock(记录锁)
- 只锁中选中的那条索引记录。
- 其他事务可以插入同一区间的“新行”。
- 适合需要精确修改、删除特定行时。
2. Gap Lock(间隙锁)
- 锁的是“间隙”而不含两边的现有记录。
- 阻止其他事务在这个空隙插入新行,但不影响读取。
- 目的是防止出现“幻影行”。
3. Next-Key Lock(临键锁)
- 记录锁 + 间隙锁的组合:锁住匹配的行以及相邻的前后区间。
- 在 InnoDB 的 可重复读隔离级别下默认采用,以防止“幻读”。
- 锁定的是左闭右开区间
[当前索引值, 下一个索引值)。
直观理解:
- Record:点 → 只管自己
- Gap:缝 → 不许插
- Next-Key:点 + 缝 → 自己也管,缝也堵
在可重复读级别下,InnoDB默认给范围条件加 Next-Key Lock,从而防止幻读。当条件能精确命中唯一索引行时,Next-Key 会“退化”为 Record Lock,以提高并发。
6.2 InnoDB 行锁原理
InnoDB 采用索引项加锁,而不是对物理记录加锁,这意味着:
- 锁是依附于索引的,查询条件必须用到索引才能精确加锁,否则可能退化为表锁;
- 行锁依赖索引键值,多行加锁时基于B+树结构遍历。
因此,当索引失效时,加锁一旦退化成表锁,将整张表锁住,从而造成其它业务受阻。
6.3 死锁及解决方案
在并发事务下可能出现死锁:两个事务互相等待对方释放资源,最终都无法推进。
InnoDB 对死锁处理:
- 自动死锁检测:回滚代价最小事务;
- 等待超时:innodb_lock_wait_timeout 控制。当一个事务的等待时间超过该值后,就对这个事务进行回滚
7. MySQL 日志
日志在 MySQL 中扮演事务恢复、数据一致性、复制与优化等多重角色。
7.1 日志的分类
MySQL 主要有三类日志:
| 日志类型 | 作用 | 特点 | 默认/引擎依赖 |
|---|---|---|---|
| Redo 日志 | 保证事务提交后数据持久性 | 顺序写、物理日志、InnoDB 引擎实现 | InnoDB 默认 |
| Undo 日志 | 支持事务回滚 & MVCC | 记录修改前版本、逻辑日志 | InnoDB 默认 |
| Binlog(二进制日志) | 数据复制 & 增量备份 | 逻辑日志、记录事务操作 | 全局可开,InnoDB/Mysql 通用 |
7.2 Redo 日志
- 作用:保证 持久性(Durability),即使系统崩溃,也能恢复已提交事务;
- 实现机制:
- 写入 Redo 日志缓冲区(Log Buffer);
- 定期刷新到磁盘(Log File),遵循 WAL(Write-Ahead Logging)原则:先写日志,再写数据页;
- 崩溃重启时,通过重放日志恢复提交事务;
7.3 Undo 日志
- 作用:
- 支持 事务回滚;
- 支持 MVCC 快照读;
- 原理:
- 每条修改前,把旧值写入 Undo 日志;
- 查询快照或回滚时,通过 Undo 恢复旧版本;
7.4 Binlog(二进制日志)
- 作用:
- 主从复制:将主库变更同步到从库;
- 增量备份:可以按 Binlog 回放数据;
- 类型:
- Statement(语句模式):记录 SQL 语句;
- Row(行模式):记录每行数据变化;
- Mixed(混合模式):语句 + 行模式结合;
7.5 日志之间的关系
事务提交流程示意图:
[事务操作] --> 写 Undo 日志 --> 修改缓冲区
|
v
写 Redo 日志
|
v
刷数据页到磁盘
|
v
提交完成
|
v
写 Binlog(逻辑日志)
日志机制与前面讲的事务、锁密切相关:
- 事务原子性靠 Undo 回滚;
- 事务持久性靠 Redo 日志刷盘;
- 隔离性 & 并发靠 MVCC + 锁,但日志提供快照和恢复能力;
- 主从复制与备份靠 Binlog 实现。
8. MySQL 缓存
缓存是数据库性能优化的重要环节,它可以大幅减少磁盘 I/O,提高查询速度。MySQL 提供了多种内部缓存机制,同时应用层也常用 Redis/Memcached 等外部缓存。
8.1 为什么需要缓存
- 磁盘 I/O 成本高,尤其是机械硬盘;
- 查询热点数据反复访问,如果每次都读磁盘,性能瓶颈明显;
- 缓存能提高响应速度、减轻数据库压力,尤其在高并发场景。
通俗理解:缓存就像书桌上的笔记本,常用信息不用每次去图书馆翻书。
8.2 MySQL 内部缓存机制
InnoDB 采用 **Buffer Pool(缓冲池)**作为缓存机制
- 作用:
- 缓存数据页(默认 16 KB)和索引页;
- 支持 MVCC 查询、事务回滚;
- 特点:
- 热点页尽量常驻内存,减少磁盘访问;
- 数据页修改先写 Buffer Pool,再异步刷新到磁盘(结合 Redo 日志保证持久性);
- 配置:
innodb_buffer_pool_size = 4G # 根据内存大小调整
8.3 外部缓存
在 MySQL 之上,通常会加 Redis/Memcached 做热点数据缓存:
- 热点数据、会话信息、排行榜等;
- 常用模式:
- Cache Aside(应用先查缓存,未命中再查数据库,并写回缓存);
- Write Through(写数据库同时更新缓存);
9. MySQL 常用语句
MySQL 提供了丰富的 SQL 语法,常用语句可以分为数据定义(DDL)、数据操作(DML)、数据查询(DQL)、事务控制和权限管理几大类。
9.1 数据库与表操作(DDL)
1. 数据库操作
-- 创建数据库
CREATE DATABASE IF NOT EXISTS test_db CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-- 删除数据库
DROP DATABASE IF EXISTS test_db;
-- 使用数据库
USE test_db;
-- 查看数据库列表
SHOW DATABASES;
2. 表操作
-- 创建表
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
-- 删除表
DROP TABLE IF EXISTS users;
-- 查看表结构
DESCRIBE users;
-- 修改表结构(添加列、修改列类型、删除列)
ALTER TABLE users ADD COLUMN age INT;
ALTER TABLE users MODIFY COLUMN name VARCHAR(100);
ALTER TABLE users DROP COLUMN age;
9.2 数据操作(DML)
1. 插入数据
-- 单条插入
INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com');
-- 多条插入
INSERT INTO users (name, email) VALUES
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com');
2. 更新数据
UPDATE users
SET name = 'Alice Zhang'
WHERE id = 1;
3. 删除数据
DELETE FROM users
WHERE id = 3;
-- 删除所有行
DELETE FROM users; -- 注意,表结构保留
TRUNCATE TABLE users; -- 删除表内数据 + 重置自增
9.3 数据查询(DQL)
1. 基础查询
SELECT * FROM users;
SELECT id, name FROM users WHERE age > 18 ORDER BY name ASC LIMIT 10;
2. 聚合查询
SELECT COUNT(*) AS total_users FROM users;
SELECT AVG(age) FROM users WHERE age IS NOT NULL;
SELECT gender, COUNT(*) FROM users GROUP BY gender;
3. 多表查询
-- 内连接
SELECT u.id, u.name, o.order_id
FROM users u
JOIN orders o ON u.id = o.user_id;
-- 左连接
SELECT u.id, u.name, o.order_id
FROM users u
LEFT JOIN orders o ON u.id = o.user_id;
4. 子查询与 EXISTS
-- 子查询
SELECT name FROM users
WHERE id IN (SELECT user_id FROM orders WHERE amount > 100);
-- EXISTS
SELECT name FROM users u
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.amount > 100
);
9.4 事务控制语句
-- 开启事务
START TRANSACTION; -- 或 BEGIN;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
-- 设置隔离级别
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
9.5 索引操作
-- 创建索引
CREATE INDEX idx_name ON users(name);
-- 删除索引
DROP INDEX idx_name ON users;
-- 查看表索引
SHOW INDEX FROM users;
9.6 权限与用户管理
-- 创建用户
CREATE USER 'test_user'@'localhost' IDENTIFIED BY 'password';
-- 授权
GRANT SELECT, INSERT, UPDATE ON test_db.* TO 'test_user'@'localhost';
-- 撤销权限
REVOKE INSERT ON test_db.* FROM 'test_user'@'localhost';
-- 删除用户
DROP USER 'test_user'@'localhost';
9.7 数据库管理与运维
-- 查看当前连接
SHOW PROCESSLIST;
-- 查看表大小
SELECT table_name, table_rows, data_length, index_length
FROM information_schema.tables
WHERE table_schema = 'test_db';
-- 备份与恢复(CLI 命令)
-- 备份
mysqldump -u root -p test_db > test_db.sql
-- 恢复
mysql -u root -p test_db < test_db.sql
参考
[1] 小林coding-图解MySQL:https://www.xiaolincoding.com/mysql/index/index_interview.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E5%88%86%E7%B1%BB
[2] wiki二叉搜索树:https://zh.wikipedia.org/wiki/%E4%BA%8C%E5%85%83%E6%90%9C%E5%B0%8B%E6%A8%B9