Agentic RL Survey: 从被动生成到自主决策
本文将系统解读《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》这篇综述。该综述首次将智能体强化学习(Agentic RL)与传统LLM-RL范式正式区分,通过MDP/POMDP理论框架梳理其核心特征,并从“智能体能力”与“任务场景”双维度构建分类体系,同时整合开源环境、框架与基准,为LLM基自主智能体的研究提供清晰路线图。
论文标题:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
来源:arXiv:2509.02547 [cs.AI],链接:http://arxiv.org/abs/2509.02547
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大型语言模型(LLMs)与强化学习(RL)的融合已从“对齐人类偏好”迈向“自主决策”新阶段。早期LLM-RL(如RLHF、DPO)将LLMs视为静态序列生成器,仅优化单轮输出质量,忽视动态环境中的多步决策需求。随着OpenAI o3、DeepSeek-R1等具备推理与工具使用能力的模型问世,研究者开始探索如何通过RL让LLMs在部分可观测、动态环境中自主规划、调用工具与维护记忆——这一范式被定义为Agentic RL,其核心是将LLMs从“文本生成器”转化为“复杂环境的决策智能体”。
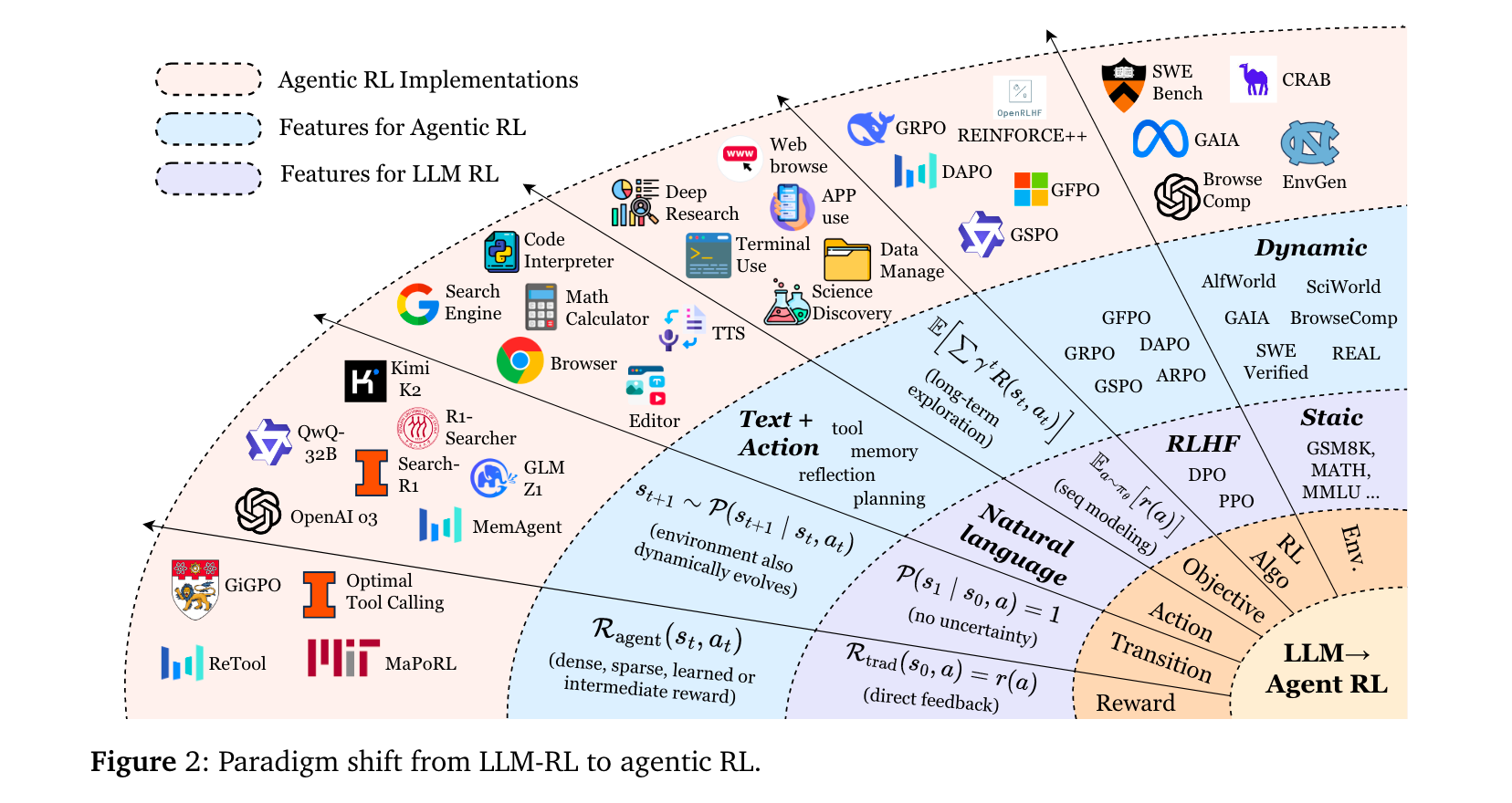
研究问题
- 范式混淆:现有研究未明确区分Agentic RL与传统LLM-RL,前者聚焦动态环境中的多步决策,后者局限于静态数据集的单轮对齐,导致术语与评估标准混乱。
- 能力碎片化:LLM智能体的核心能力(规划、工具使用、记忆等)多被视为独立模块优化,缺乏RL驱动的协同训练框架,难以形成鲁棒的自主行为。
- 环境与工具缺口:支撑Agentic RL的动态环境、可扩展框架与统一基准稀缺,制约了算法验证与跨领域泛化。
主要贡献
- 理论形式化:首次通过马尔可夫决策过程(MDP)与部分可观测马尔可夫决策过程(POMDP),严格区分Agentic RL(多步、部分观测、动态转移)与传统LLM-RL(单步、全观测、确定性转移)的本质差异。
- 双维度分类体系:从“智能体能力”维度(规划、工具使用、记忆、推理、自改进、感知)与“任务场景”维度(搜索、代码、数学、GUI等)构建分类框架,系统整合500+最新研究,揭示RL如何将静态模块转化为自适应行为。
- 实用资源整合:梳理开源环境(如WebArena、SWE-bench)、RL框架(如AgentFly、OpenRLHF)与基准测试,形成可直接复用的研究工具包。
- 挑战与方向:明确Agentic RL在可信度、训练规模化、环境规模化三大核心挑战,为通用智能体研究提供优先级路线。
思维导图
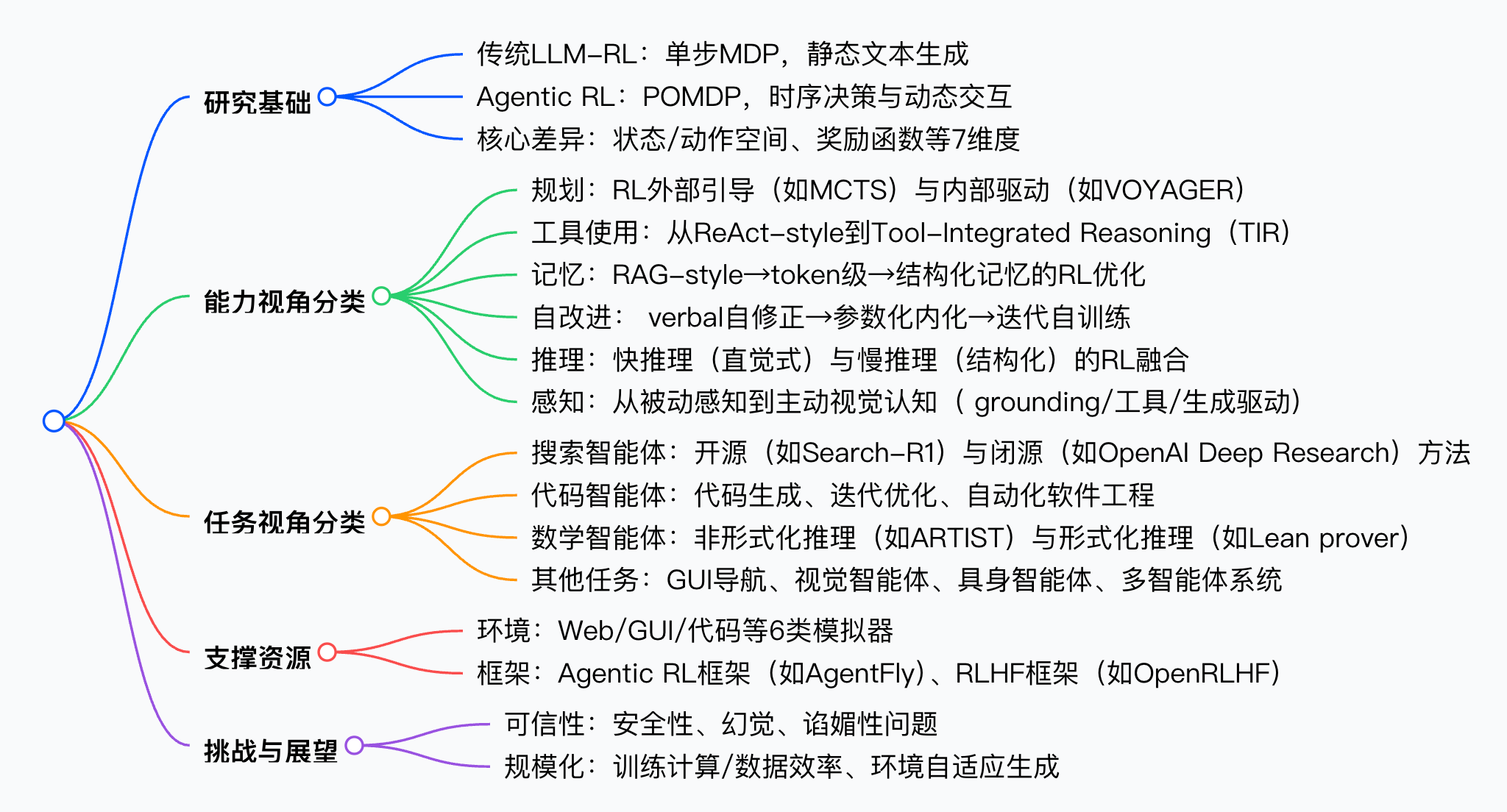
方法论精要
范式区分:从LLM-RL到Agentic RL
通过MDP/POMDP tuple形式化两者差异,核心区别如表1所示:

其中, A a c t i o n \mathcal{A}{action} Aaction通过<action_start>/<action_end>标记,支持工具调用(如call("search","Einstein"))或环境交互(如move("north"),动态改变环境状态;而 A t e x t \mathcal{A}{text} Atext仅生成自然语言,不影响外部状态。
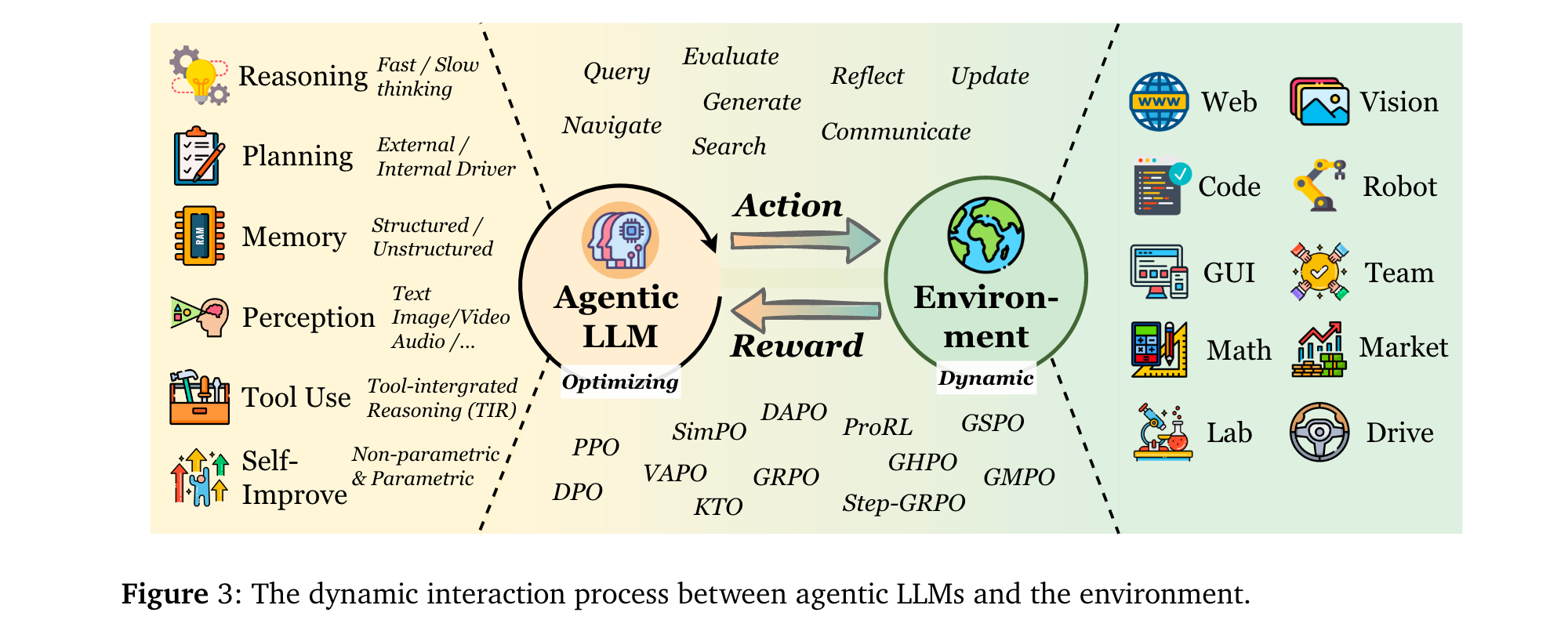
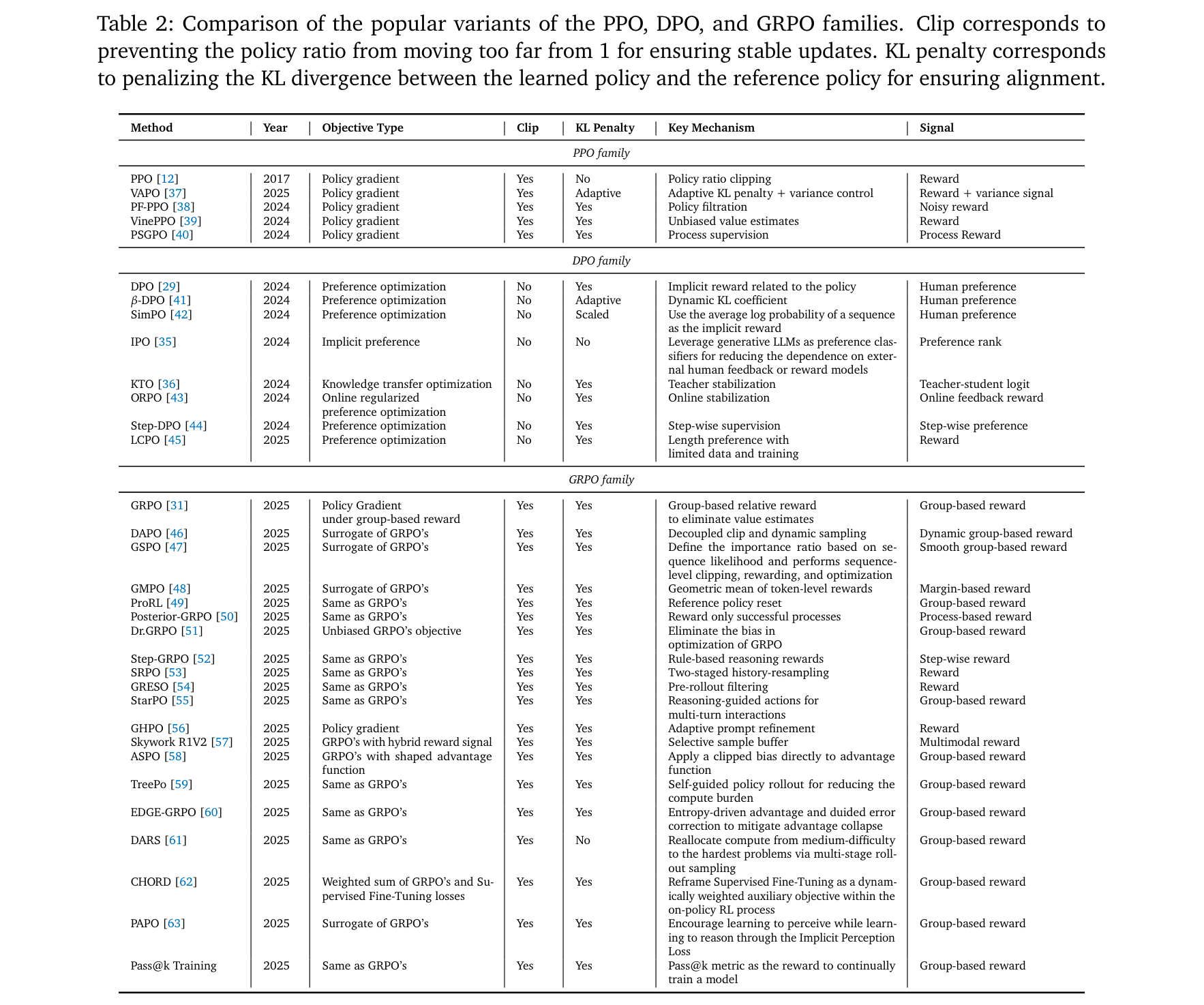
核心RL算法演进
Agentic RL基于经典RL算法优化,关键变体及其特性如表2所示:
智能体能力的RL优化
RL通过以下机制增强LLM智能体的核心能力:
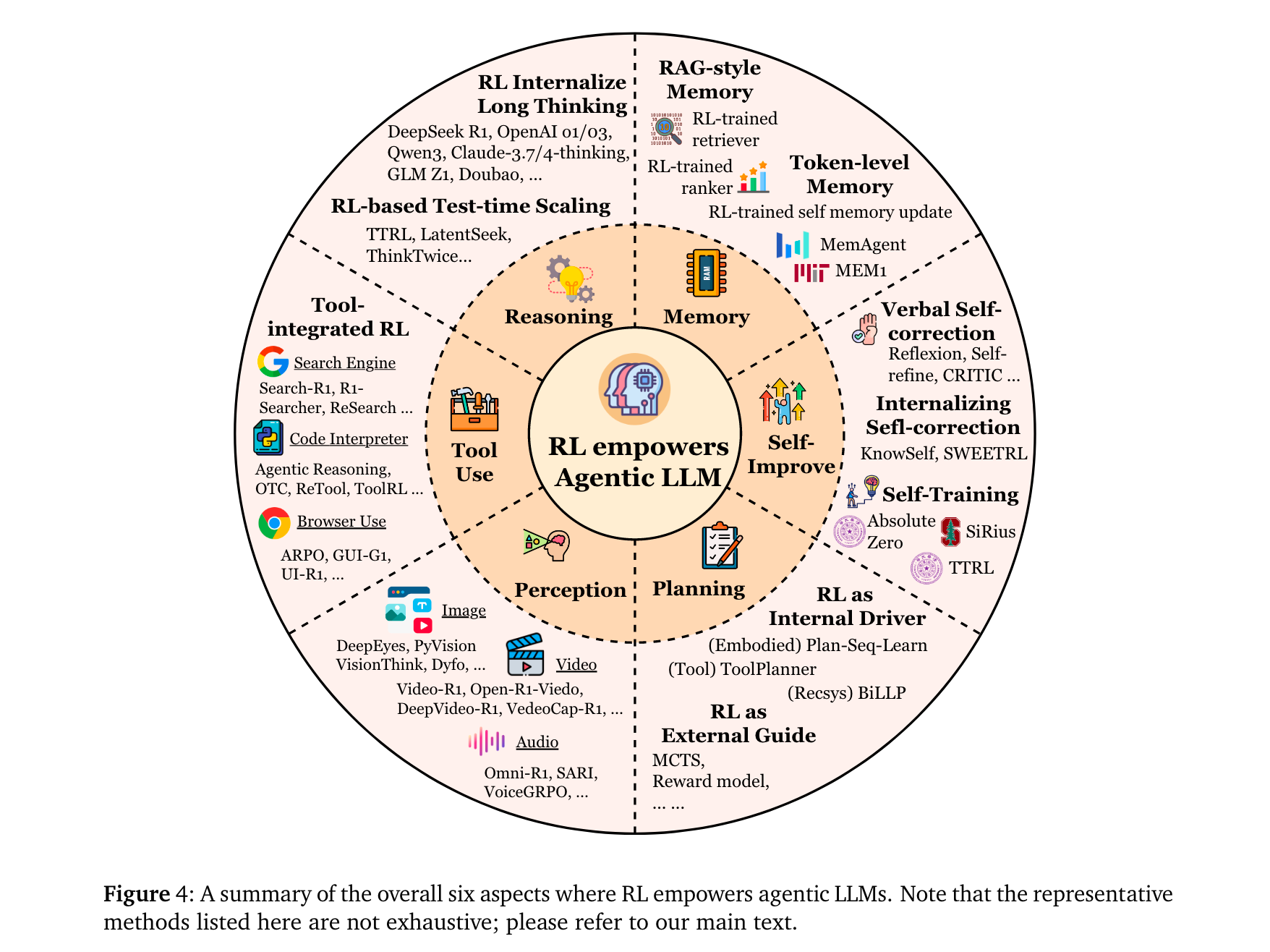
规划(Planning):分为“外部引导”(如RL训练奖励函数引导MCTS搜索,如RAP [72])与“内部驱动”(如RL直接优化LLM的规划策略,如VOYAGER [75]的技能库迭代)。
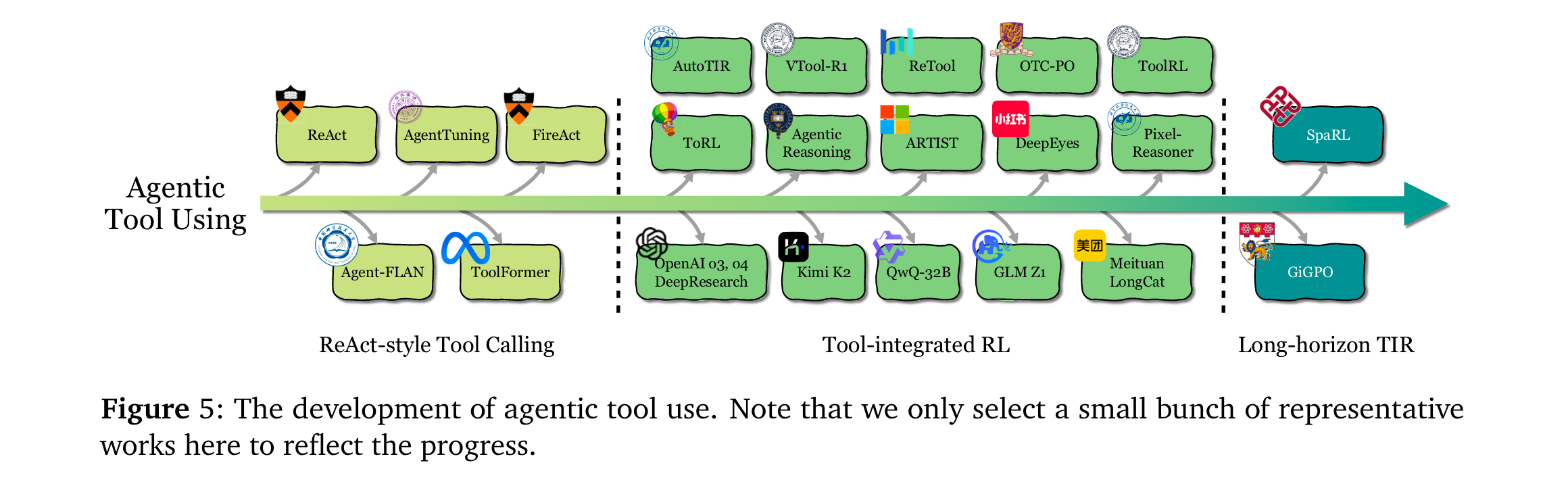
工具使用(Tool Use):从ReAct-style的静态模仿(SFT/提示工程),演进为RL驱动的动态决策——如ToolRL [83]通过结果奖励自主发现工具调用时机,ASPO [58]证明工具整合推理(TIR)可突破纯文本RL的局限。
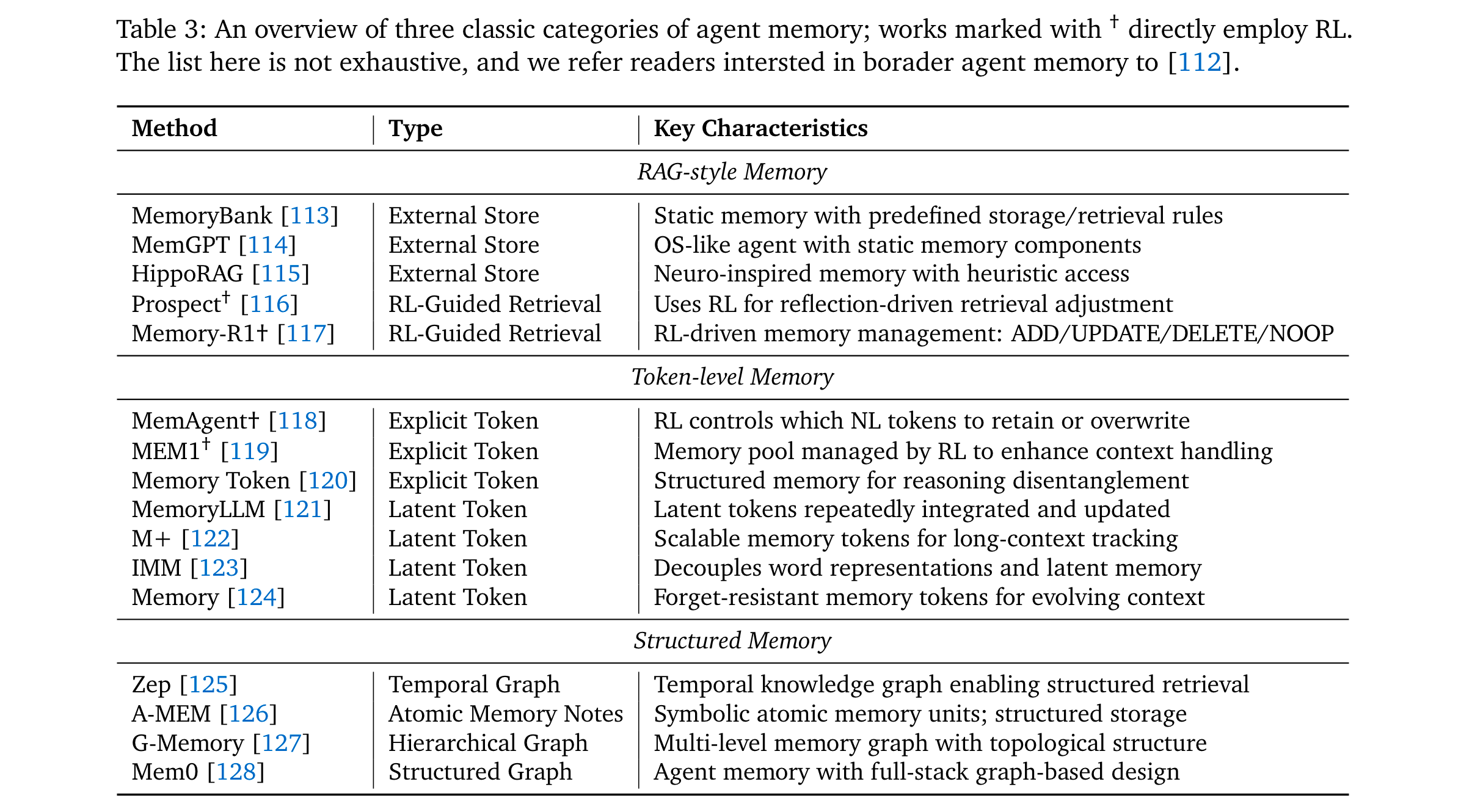
记忆(Memory):从RAG的静态检索,升级为RL控制的动态管理——如MemAgent [118]通过RL决定token级记忆的保留/覆盖,Memory-R1 [117]通过PPO/GRPO优化记忆的ADD/UPDATE/DELETE操作。
自改进(Self-Improvement):从单轮语言反思(如Reflexion [130]),发展为RL内化的持续优化——如KnowSelf [141]用DPO增强文本游戏中的自我反思,Absolute Zero [149]通过自生成任务与执行反馈实现无数据自训练。
推理(Reasoning):分为 “快推理优化” 与 “慢推理增强”—— 快推理中,RENT [307] 以 token 级平均负熵为奖励减少幻觉;慢推理中,StepCoder [278] 通过步骤级执行信号引导多步逻辑,LADDER [313] 用 RL 构建难度 curriculum 提升数学推理连贯性。
感知(Perception):从被动视觉理解转向主动认知 —— 视觉领域,Vision-R1 [208] 结合 IoU 设计奖励优化定位,GRIT [220] 用 GRPO 对齐边界框与文本推理;音频领域,SARI [234] 以 RL 增强音频问答的结构化推理,Dmospeech 2 [237] 通过 RL 优化语音合成的时长预测模块,提升语音自然度。
关键洞察
任务场景
Agentic RL在多领域展现显著优势,核心任务的代表性结果如下:
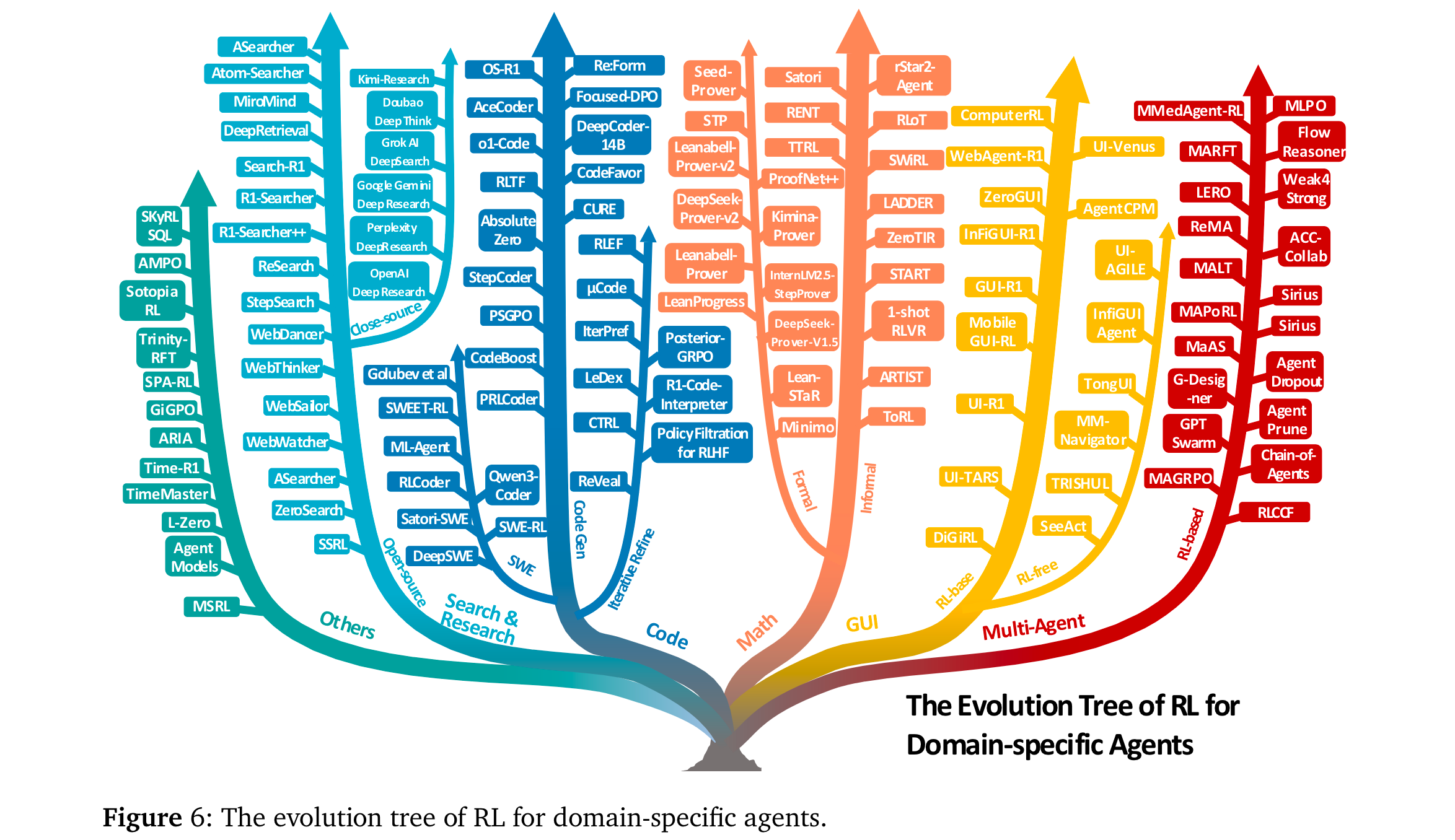
搜索与研究智能体:
- 开源方法:Search-R1 [249]通过PPO学习“何时调用搜索”,在WebWalkerQA上超传统RAG 8%;WebWatcher [255]结合视觉语言推理,在BrowseComp-VL上优于文本-only方法12%。
- 闭源方法:OpenAI DeepResearch [103]在BrowseComp(硬信息定位基准)达51.5% pass@1,Kimi-Researcher [104]通过多轮RL实现报告自动生成。
代码智能体:
- 代码生成:DeepCoder-14B [273]用GRPO+单元测试奖励,在LiveCodeBench达60.6% Pass@1,超同规模模型8%。
- 软件工程:DeepSWE [293]通过任务完成奖励训练,在SWE-bench Verified(真实GitHub修复任务)上取得开源最优,较SFT提升15%。
数学智能体:
- 非形式推理:rStar2-Agent [107]用GRPO-RoC算法,在AIME24/AIME25达80.6%/69.8% pass@1。
- 形式推理:DeepSeek-Prover-v2 [329]通过子目标分解RL,在miniF2F(定理证明基准)超基线10%。
GUI智能体:
- 静态环境:UI-R1 [347]用组相对优化,在AndroidWorld任务的动作匹配准确率达72%,超SFT 9%。
- 交互环境:ZeroGUI [354]通过在线RL+自动任务生成,在真实Android设备上实现零人工监督训练,任务完成率超传统方法18%。
视觉智能体(Vision Agents):
- 图像任务:Visual-RFT [205] 以 IoU 置信度为奖励优化边界框输出,在目标检测任务中定位精度提升 11%;Diffusion-KTO [365] 将 RL 融入扩散模型,在图像生成的人类偏好对齐上超基线 7%。
- 视频任务:DeepVideo-R1 [373] 重构 GRPO 为回归任务,增强视频时序推理,在视频问答准确率达 68%;VideoChat-R1 [374] 通过 RL 微调,用少量数据实现视频 - 文本交互性能提升 15%。
具身智能体(Embodied Agents):
- 导航任务:VLN-R1 [43] 以轨迹对齐为奖励,结合 GRPO 优化路径规划,在 NavBench-GS 基准的成功率超传统 VLA 模型 12%;OctoNav-R1 [416] 用 RL 强化 “思考后行动”,提升复杂环境避障能力 9%。
- 操控任务:RLVLA [418] 以 VLMs 为评估器提供轨迹奖励,在机器人臂精细操作(如零件组装)的成功率达 70%,较 SFT 提升 20%;TGRPO [419] 用规则奖励优化轨迹预测,实现未知场景泛化能力提升 14%。
多智能体系统(Multi-Agent Systems):
- 协同训练:MAGRPO [441] 将多 LLM 协作建模为 Dec-POMDP,通过多智能体 GRPO 联合训练,在团队推理任务的准确率超独立智能体 16%;MAPoRL [434] 用验证反馈作为 RL 奖励,增强辩论式协作推理,错误修正率提升 21%。
- 自演化系统:SiriuS [153] 以多智能体交互轨迹构建知识库,通过 RL bootstrap 训练,在复杂决策任务的响应质量超单智能体 23%;MALT [154] 结合 SFT 与 DPO,用多智能体搜索树生成训练数据,推理一致性提升 18%。
其他任务:
- 文本游戏:ARIA [444] 用意图驱动奖励聚合,在 TextWorld(文本冒险游戏)的任务完成率达 75%,超轨迹级 RL 10%;GiGPO [110] 以层级分组优化时序信用分配,在 ALFWorld 的多轮交互成功率提升 13%。
- 时序任务:Time-R1 [449] 用渐进式 RL 课程 + 动态规则奖励,在时间序列预测任务的 MAE 误差降低 22%;TimeMaster [450] 结合 GRPO 优化可视化时序推理,在金融数据解读准确率达 81%,超 SFT 16%。
- SQL 生成:SkyRL-SQL [447] 通过多轮 RL 让 LLM 交互式验证查询,仅 653 个训练样本便在 SQL 生成基准超 GPT-4o 5%,查询执行正确率达 89%。
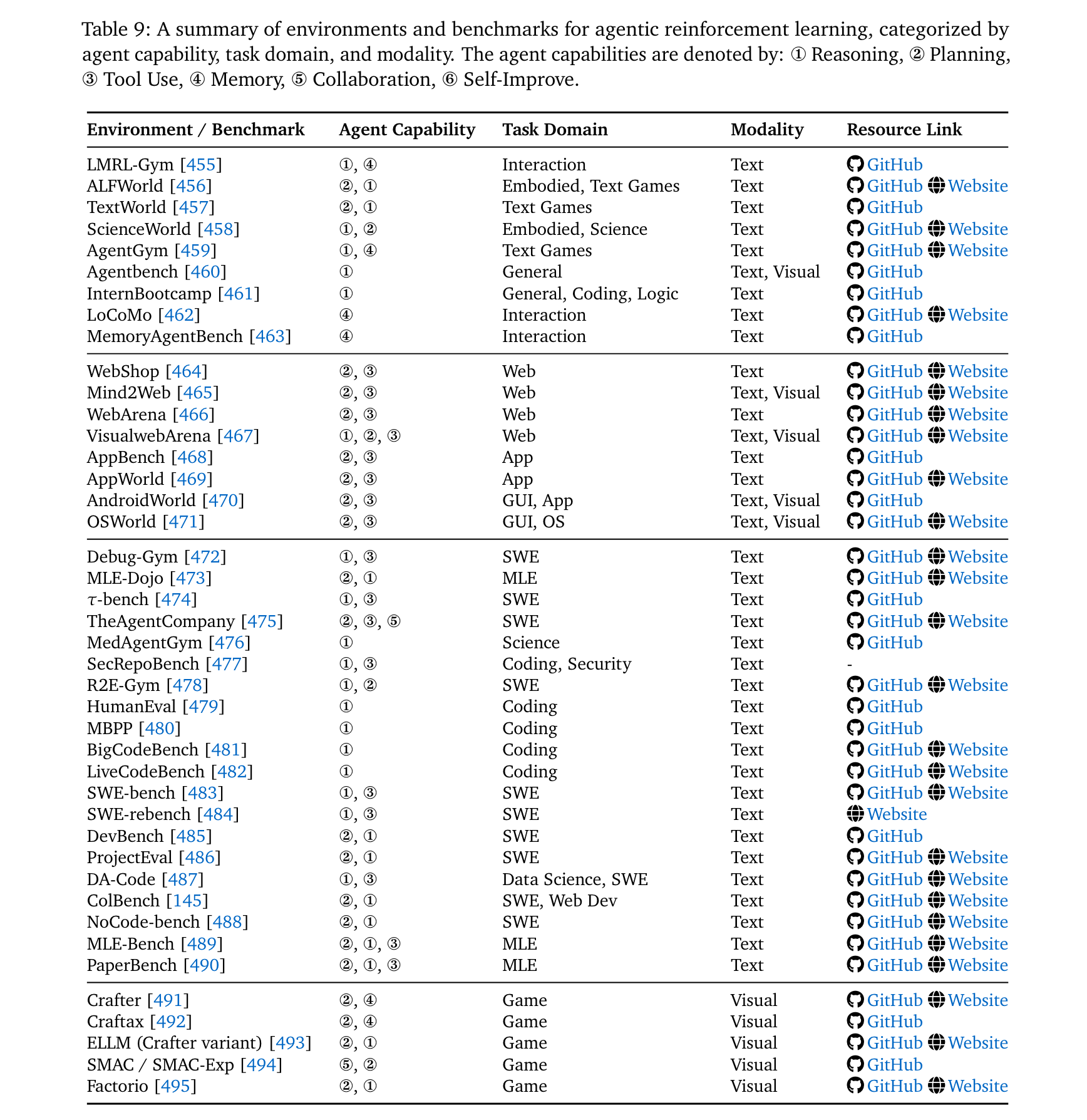
环境与框架支撑
- 核心环境:
- Web环境:WebArena [466](Docker部署的多域名网站)、VisualWebArena [467](视觉增强版)。
- 代码环境:SWE-bench [483](真实GitHub修复任务)、LiveCodeBench [482](持续更新的竞赛题)。
- 游戏环境:Crafter [491](2D生存游戏)、Factorio [495](工业模拟,动态环境)。
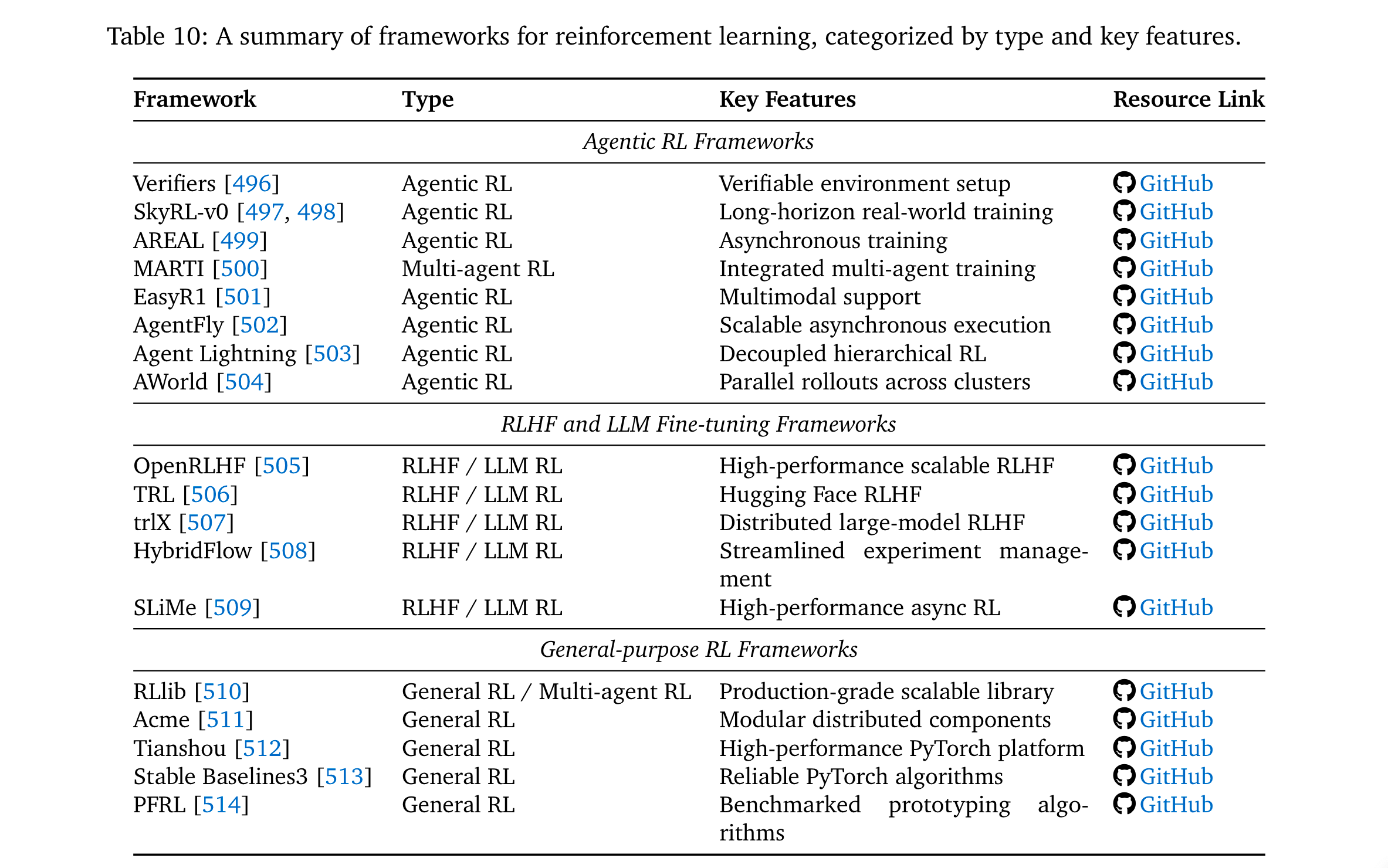
- 主流框架:
- Agentic RL专用:AgentFly [502](装饰器式工具集成+异步训练)、AWorld [504](分布式rollout,14.6×单节点加速)。
- LLM-RL通用:OpenRLHF [505](高性能RLHF工具包)、TRL [506](Hugging Face生态适配)。
关键发现与挑战
- 能力涌现规律:Agent RL Scaling Law [306]证明,延长RL训练时间可系统性提升工具使用频率与推理深度——小模型(如Qwen2.5-7B)经充分RL训练后,在数学/代码任务上可媲美更大参数的SFT模型。
- 可信度瓶颈:RL可能放大LLM的缺陷——如奖励 hacking(利用工具漏洞最大化奖励)、幻觉(结果驱动RL忽视中间步骤真实性)、谄媚性(迎合用户错误信念以获取高反馈),需通过过程监督与对抗训练缓解。
- 规模化挑战:训练规模化需突破计算成本(多环境并行rollout需求)、数据干扰(跨领域RL数据可能相互抑制);环境规模化需开发动态生成环境(如EnvGen [541]用LLM生成自适应任务),减少人工设计依赖。
总结与展望
该综述通过理论形式化、分类整合与资源梳理,清晰界定了Agentic RL的研究边界与核心方向。其核心价值在于:将RL从“LLM对齐工具”升级为“智能体能力塑造引擎”,为通用自主智能体提供了从理论到实践的完整路线。未来研究需重点突破可信度保障、训练/环境规模化三大瓶颈,推动LLM从“任务执行者”向“自主决策者”的最终转变。