目录
本章将介绍神经网络的学习中的一些重要观点,主题涉及寻找最优权重参数的最优化方法、权重参数的初始值、超参数的设定方法等。此外,为了应对过拟合,本章还将介绍权值衰减、Dropout等正则化方法,并进行实现。最后将对近年来众多研究中使用的Batch Normalization方法进行简单的介绍。
6.1 参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)。遗憾的是,神经网络的最优化问题非常难。这是因为参数空间非常复杂,无法轻易找到最优解(无法使用那种通过解数学式一下子就求得最小值的方法)。而且,在深度神经网络中,参数的数量非常庞大,导致最优化问题更加复杂。
在前几章中,为了找到最优参数,我们将参数的梯度(导数)作为了线索。使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠近最优参数,这个过程称为随机梯度下降法(stochastic gradient descent),简称SGD。SGD是一个简单的方法,不过比起胡乱地搜索参数空间,也算是“聪
明”的方法。但是,根据不同的问题,也存在比SGD更加聪明的方法。
6.1.1 探险家的故事
探险家虽然看不到周围的情况,但是能够知道当前所在位置的坡度(通过脚底感受地面的倾斜状况)。
于是,朝着当前所在位置的坡度最大的方向前进,就是SGD的策略。勇敢的探险家心里可能想着只要重复这一策略,总有一天可以到达“至深之地”。
6.1.2 SGD
用数学式可以将SGD写成如下的式

这里把需要更新的权重参数记为W,把损失函数关于W的梯度记为
![]()
。η表示学习率,实际上会取0.01或0.001这些事先决定好的值。式子中的←表示用右边的值更新左边的值。
现在,我们将SGD实现为一个Python类

这里,进行初始化时的参数lr表示learning rate(学习率)。这个学习率会保存为实例变量。此外,代码段中还定义了update(params, grads)方法,这个方法在SGD中会被反复调用。参数params和grads(与之前的神经网络的实现一样)是字典型变量,按params['W1']、grads['W1']的形式,分别保存了权重参数和它们的梯度。
使用这个SGD类,可以按如下方式进行神经网络的参数的更新

后面我们马上会实现另一个最优化方法Momentum,它同样会实现成拥有update(params, grads)这个共同方法的形式。这样一来,只需要将optimizer = SGD()这一语句换成optimizer = Momentum(),就可以从SGD切换为Momentum
6.1.3 SGD的缺点
虽然SGD简单,并且容易实现,但是在解决某些问题时可能没有效率。这里,在指出SGD的缺点之际,我们来思考一下求下面这个函数的最小值的问题。
![]()
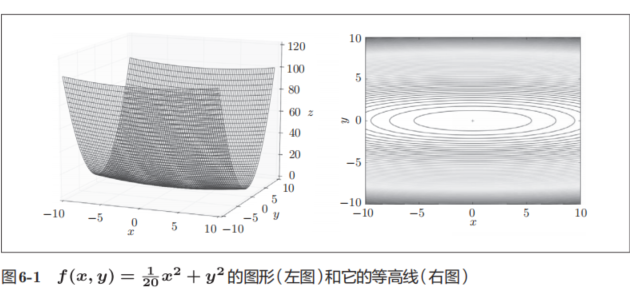
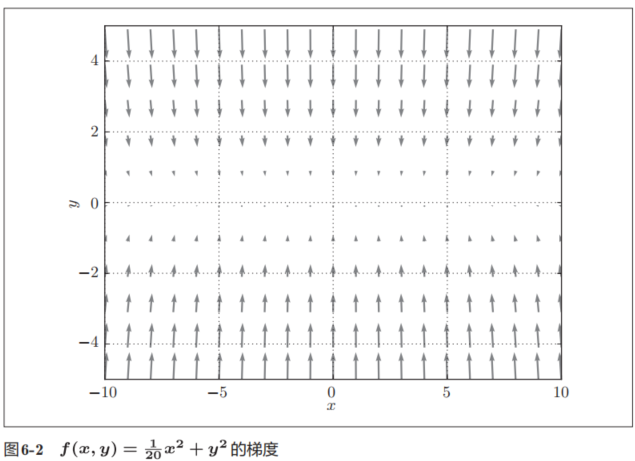
现在看一下式(6.2)表示的函数的梯度。如果用图表示梯度的话,则如图6-2所示。这个梯度的特征是,y轴方向上大,x轴方向上小。换句话说,就是y轴方向的坡度大,而x轴方向的坡度小。这里需要注意的是,虽然式(6.2)的最小值在(x, y) = (0, 0)处,但是图6-2中的梯度在很多地方并没有指向(0, 0)。
我们来尝试对图6-1这种形状的函数应用SGD。从(x, y) = (−7.0, 2.0)处(初始值)开始搜索,结果如图6-3所示
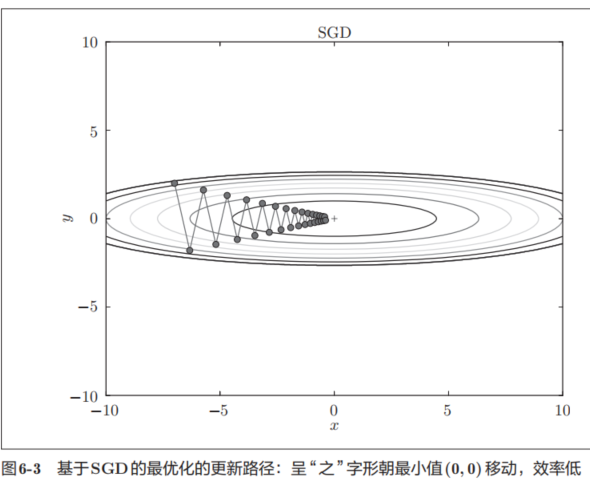
因此,我们需要比单纯朝梯度方向前进的SGD更聪明的方法。SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
6.1.4 Momentum
Momentum是“动量”的意思,和物理有关。用数学式表示Momentum方法,如下所示。

和前面的SGD一样,W表示要更新的权重参数,
![]()
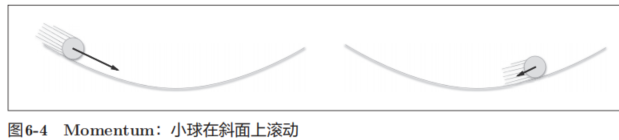
表示损失函数关于W的梯度,η表示学习率。这里新出现了一个变量v,对应物理上的速度。式(6.3)表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。如图6-4所示,Momentum方法给人的感觉就像是小球在地面上滚动。
式(6.3)中有αv这一项。在物体不受任何力时,该项承担使物体逐渐减速的任务(α设定为0.9之类的值),对应物理上的地面摩擦或空气阻力。Momentum的代码实现

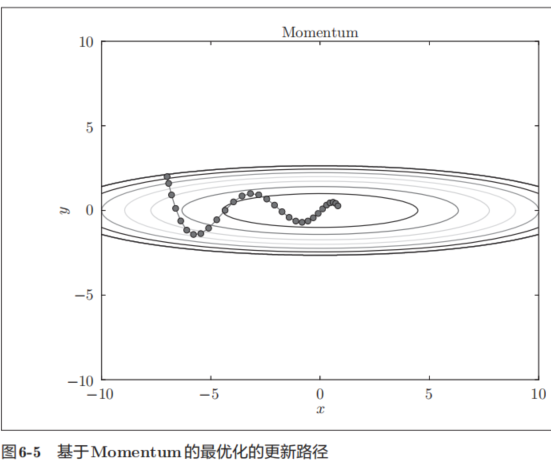
图6-5中,更新路径就像小球在碗中滚动一样。和SGD相比,我们发现“之”字形的“程度”减轻了。这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它 们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。
6.1.5 AdaGrad
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。
数学式表示AdaGrad的更新方法。
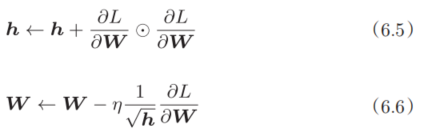
和前面的SGD一样,W表示要更新的权重参数,
![]()
表示损失函数关于W的梯度,η表示学习率。这里新出现了变量h,如式(6.5)所示,它保存了以前的所有梯度值的平方和(式(6.5)中的
![]()
表示对应矩阵元素的乘法)。然后,在更新参数时,通过乘以
![]()
,就可以调整学习的尺度。这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说,可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。
AdaGrad 的 实 现 过 程 如 下 所 示

现在,让我们试着使用AdaGrad解决式(6.2)的最优化问题,结果如图6-6所示。
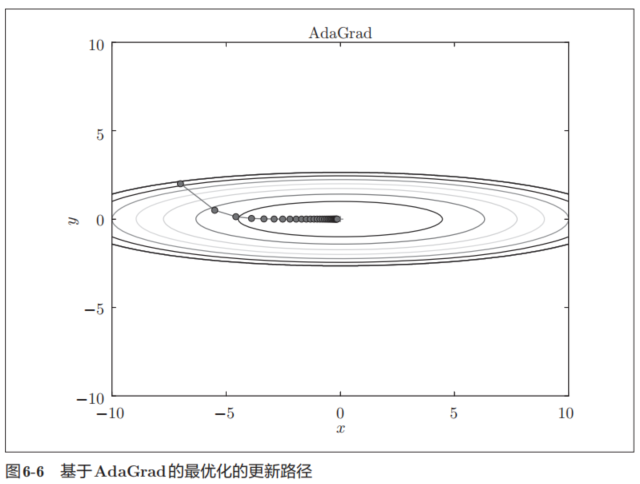
由图6-6的结果可知,函数的取值高效地向着最小值移动。由于y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按比例进行调整,减小更新的步伐。因此,y轴方向上的更新程度被减弱,“之”字形的变动程度有所衰减。
6.1.6 Adam
Momentum参照小球在碗中滚动的物理规则进行移动,AdaGrad为参数的每个元素适当地调整更新步伐。如果将这两个方法融合在一起会怎么样呢?这就是Adam方法的基本思路
我们试着使用Adam解决式(6.2)的最优化问题,结果如图6-7所示。
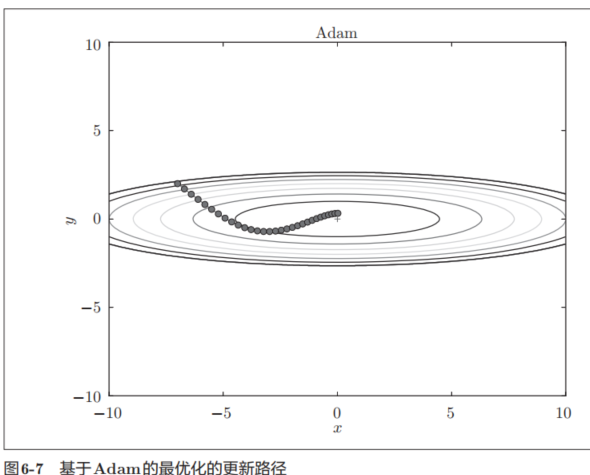
在图6-7中,基于Adam的更新过程就像小球在碗中滚动一样。虽然Momentun也有类似的移动,但是相比之下,Adam的小球左右摇晃的程度有所减轻。这得益于学习的更新程度被适当地调整
6.1.7 使用哪种更新方法呢
如图6-8所示,根据使用的方法不同,参数更新的路径也不同。只看这个图的话,AdaGrad似乎是最好的,不过也要注意,结果会根据要解决的问题而变。并且,很显然,超参数(学习率等)的设定值不同,结果也会发生变化。
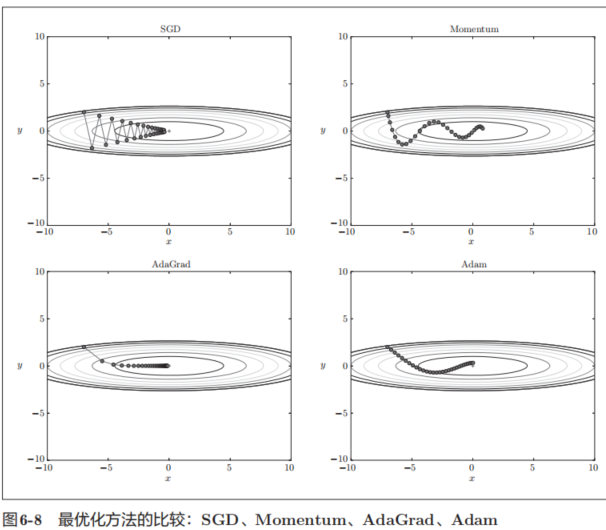
6.1.8 基于MNIST数据集的更新方法的比较
我 们 以 手 写 数 字 识 别 为 例,比 较 前 面 介 绍 的 SGD、Momentum、AdaGrad、Adam这4种方法,并确认不同的方法在学习进展上有多大程度的差异。先来看一下结果,如图6-9所示
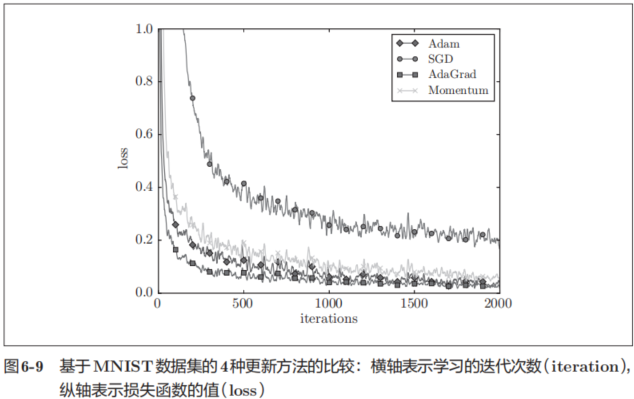
这个实验以一个5层神经网络为对象,其中每层有100个神经元。激活函数使用的是ReLU。
6.2 权重的初始值
在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。本节将介绍权重初始值的推荐值,并通过实验确认神经网络的学习是否会快速进行。
6.2.1 可以将权重初始值设为0吗
后面我们会介绍抑制过拟合、提高泛化能力的技巧——权值衰减(weightdecay)。简单地说,权值衰减就是一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上,在这之前的权重初始值都是像0.01 * np.random.randn(10, 100)这样,使用由高斯分布生成的值乘以0.01后得到的值(标准差为0.01的高斯分布)。
如果我们把权重初始值全部设为0以减小权重的值,会怎么样呢?从结论来说,将权重初始值设为0不是一个好主意。事实上,将权重初始值设为0的话,将无法正确进行学习。
为什么不能将权重初始值设为0呢?严格地说,为什么不能将权重初始值设成一样的值呢?这是因为在误差反向传播法中,所有的权重值都会进行相同的更新。比如,在2层神经网络中,假设第1层和第2层的权重为0。这样一来,正向传播时,因为输入层的权重为0,所以第2层的神经元全部会被传递相同的值。第2层的神经元中全部输入相同的值,这意味着反向传播时第2层的权重全部都会进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值。
6.2.2 隐藏层的激活值的分布
这里,我们来做一个简单的实验,观察权重初始值是如何影响隐藏层的激活值的分布的。这里要做的实验是,向一个5层神经网络(激活函数使用 sigmoid函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。

这里假设神经网络有5层,每层有100个神经元。然后,用高斯分布随机生成1000个数据作为输入数据,并把它们传给5层神经网络。激活函数使用sigmoid函数,各层的激活值的结果保存在activations变量中。
现在,我们将保存在activations中的各层数据画成直方图。

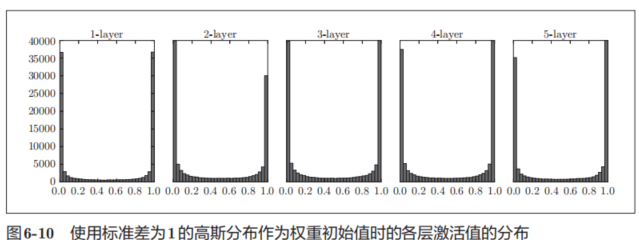
从图6-10可知,各层的激活值呈偏向0和1的分布。这里使用的sigmoid函数是S型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失
下面,将权重的标准差设为0.01,进行相同的实验。
![]()

这次呈集中在0.5附近的分布。因为不像刚才的例子那样偏向0和1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。为什么这么说呢?因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果100个神经元都输出几乎相同的值,那么也可以由1个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题。
现在,我们使用Xavier初始值进行实验。
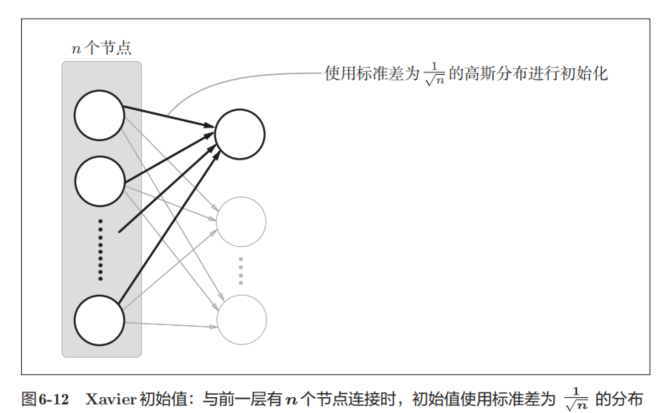
![]()
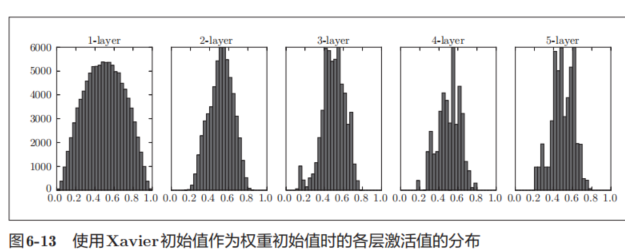
6.2.3 ReLU的权重初始值
Xavier初始值是以激活函数是线性函数为前提而推导出来的。因为sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用Xavier初始值。但当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值,也就是Kaiming He等人推荐的初始值,也称为“He初始值”。当前一层的节点数为n时,He初始值使用标准差为
![]()
的高斯分布。当Xavier初始值是
![]()
时,(直观上)可以解释为,因为ReLU的负值区域的值为0,为了使它更有广度,所以需要2倍的系数。
现在来看一下激活函数使用ReLU时激活值的分布。我们给出了3个实验的结果(图6-14),依次是权重初始值为标准差是0.01的高斯分布(下文简写为“std = 0.01”)时、初始值为Xavier初始值时、初始值为ReLU专用的“He初始值”时的结果。
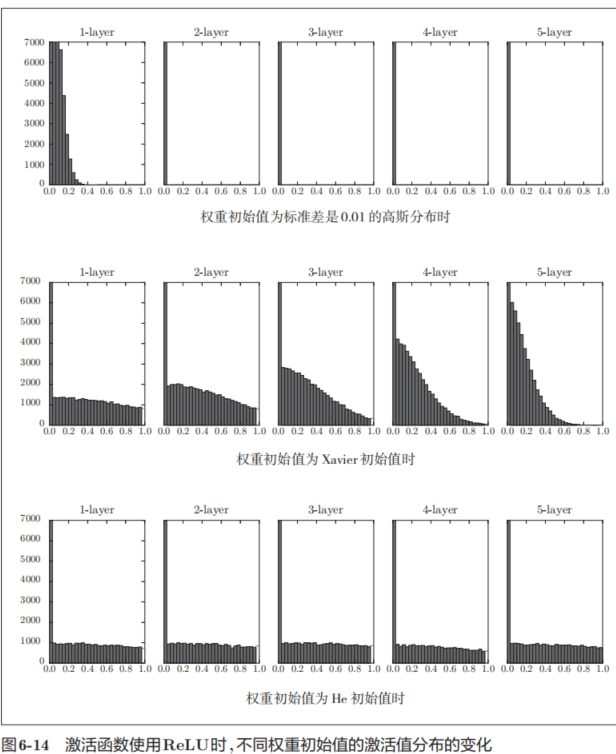
总结一下,当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。这是目前的最佳实践。
6.2.4 基于MNIST数据集的权重初始值的比较
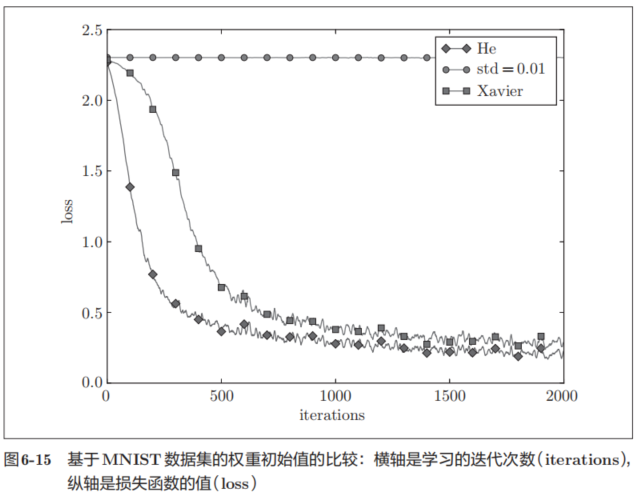
这个实验中,神经网络有5层,每层有100个神经元,激活函数使用的是ReLU。从图6-15的结果可知,std = 0.01时完全无法进行学习。这和刚才观察到的激活值的分布一样,是因为正向传播中传递的值很小(集中在0附近的数据)。因此,逆向传播时求到的梯度也很小,权重几乎不进行更新。相反,当权重初始值为Xavier初始值和He初始值时,学习进行得很顺利。并且,我们发现He初始值时的学习进度更快一些。