接上文:Hive实战(一)
介绍:数据结构、复杂数据结构、维护数据库、维护表、外部表、分区表、分区桶。
1.Hive的基础使用
Hive支持以类SQL的HQL语句来对数据进行管理。理论上,Hive支持对数据通用的增删改查操作,但是在实际使用过程中,Hive更多的是作为一个数据索引工具,对已有的数据进行索引。所以在Hive的使用过程中,更多的是使用DDL语句建表来对数据进行映射,然后使用查询语句对数据进行查询。而对数据的修改、删除等管理功能,虽然Hive也支持,但是一般很少用。
1.1 Hive的数据结构
SQL语句我们都熟悉,要使用SQL需要先建表。Hive的基础数据类型如下表:
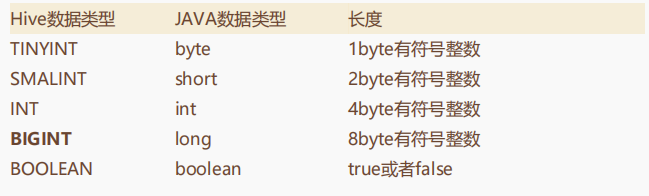
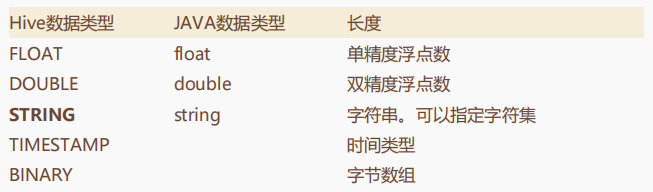
其中要注意的是加粗的那两个。
首先对于整数,hive提供了好几种类型,这几个类型的本质区别其实就在整数的范围。而Hive的这几个整数类型,其实也不是强制的。在Hive中提供了一种隐式转换的功能,所有整数类型都可以隐式的转换成一个范围更广的类型。比如TINYINT可以转换成INT, INT可以转换成BIGINT。另外,整数类型、FLOAT和STRING类型也都可以隐式转换成为DOUBLE。并且,在这些数据类型中,hive也提供了cast函数来进行强转。 例如 select cast(‘1’ as int) +3;。 这里就会将字符串1转换成数字1,这样就能进行数学计算了。但是,如果强转失败就会返回null,比如select cast(‘x’ as int)。
然后对于字符串类型,它不像MySQL的varchar,不需要指定长度。Hive中的STRING类型是一个可变的字符串,理论上他可以存储2GB的字符数。
接下来,我们就可以使用beeline工具来一个简单的建表语句试试。
create table userinfo(
name string,
age int,
salary bigint
);
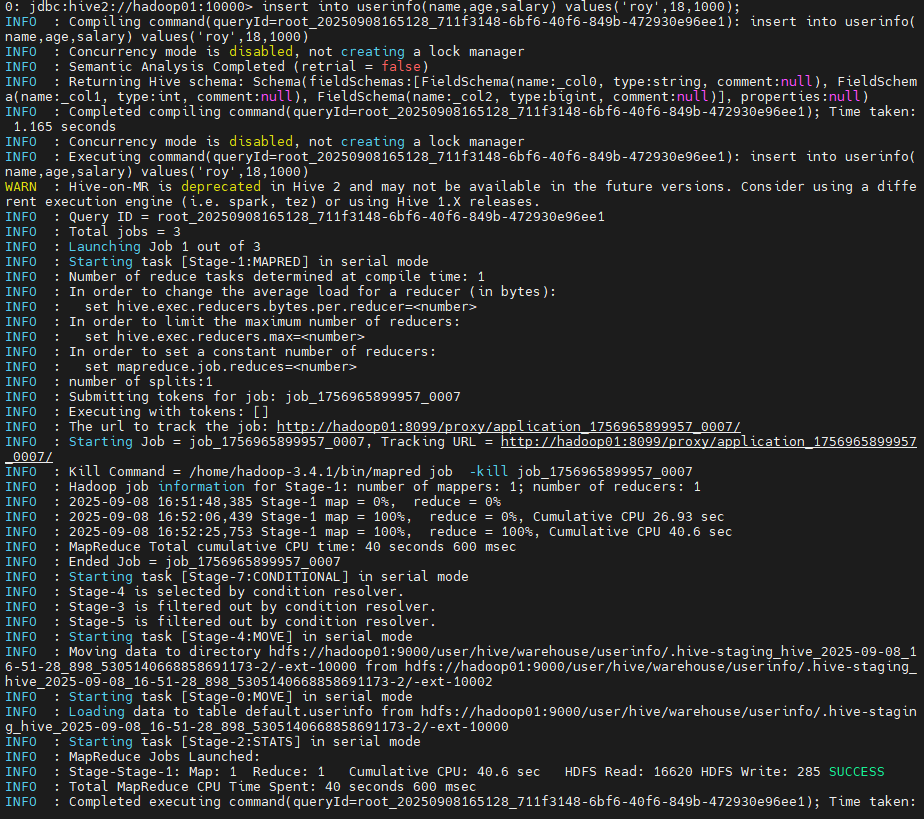
insert into userinfo(name,age,salary) values('roy',18,1000);
select * from userinfo;
注意,如果复制粘贴到命令行,最好不要用tab做缩进。直接用空格。
依次执行这些语句,会发现插入语句执行的非常慢,并且日志中看到,他会启动一个MapReduce计算,效率是非常低的。至于查询,后面会讲到,hive对简单查询可以通过文件索引直接做,但是复杂查询也还是要启动MapReduce计算的,那样查询速度就会慢很多了。
执行完这些语句后,我们来看看Hive是怎么保存数据的。
首先,到hive的Mysql元数据中去看看,里面有个tbls表,记录了建表的情况。而在tab_col_stats表中,记录了数据列的信息。元数据的表结构我们不需要过多了解,这里我们只需要大概知道,hive的元数据中保存了数据库的完整表结构。但是这里面并没有保存具体的数据。
然后,到hdfs中去看下,其实这个建表语句就是在hdfs上创建了一个/user/hive/warehouse/userinfo目录。而插入数据后,在这个目录下就会出现一个000000_0的文件,里面的内容就是我们插入的数据。
hdfs dfs -ls /user/hive/warehouse/userinfo

所以,从这个示例中,我们可以知道hive大概的工作机制;就是在元数据中保存数据结构,而数据全部保存在hdfs上。当然,Hive具体如何工作的,后面会有更详细的讲解。
1.2 Hive的复杂数据结构
在几种基础类型之外,Hive还提供了三种复杂类型,用于映射更复杂的文本数据结构。

下面来一个例子理解下HIVE的复杂类型:
例如,有一组数据,结构用JSON表示是这样的:
{
"name":"roy",
"friends":["bob" , "john"],
"children":{
"yula":6,
"sophia":17
},
"address":{
"street":"lugu",
"city":"changsha"
}
}
我们需要以一个文本的形式来保留这样的数据,就会创建这样的一个测试文件test.txt。
roy,bob_john,yula:6_sophia:17,lugu_changsha
mike,lea_jacky,rita:7_king:20,chao yang_beijing
这个表述的形式就是一行代表一条数据,属性之间用逗号分隔,然后数组之间用下划线分隔,键值对之间用冒号分隔。
然后,就需要在hive中建表,来映射这样的文本结构:
create table test3(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
这个建表语句就比较复杂了,但是对照我们的数据结构,还是不难理解。
row format delimited fields terminated by ‘,’ 表示列分隔符。
collection items terminated by ‘_’ 表示 Map、Struct和Array的分隔符。
map keys terminated by ‘:’ Map中key和value的分隔符。
lines terminated by ‘\n’; 一行数据的分隔符。
然后,可以把test.txt文本直接上传到hdfs中test表所在的目录。
hadoop fs -put /home/test.txt /user/hive/warehouse/test3
接下来,直接在hive中执行select * from test3,查看所有的数据。
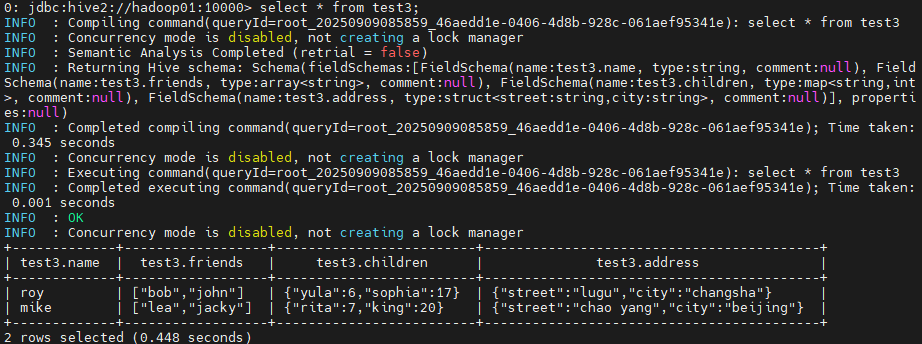
这时就可以直接在hive中查到数据了。到这里,我们一方面可以了解hive如何去映射复杂的数据结构,另一方面也能更进一步了解hive的工作机制。刚才的过程中,hive中的建表语句只是在mysql元数据中维护了test表的结构信息,而具体的数据,hive并没有自己进行维护,只是去hdfs的对应目录去读取(而且,就算要写insert语句,这样的复杂结构似乎也不好写)。其实,这也是hive最常用的工作方式,即数据已经采集到了hdfs上,然后再用hive去针对文本结构进行表映射。
当然,要完整这样的映射,我们这个简单的例子还是不够的,比如文件地址、数据来源等,hive都提供了更复杂的映射方式,后面也会有更具体的讲解,在这里,我们只需要理解hive的工作机制。
接下来,可以尝试下访问这些复杂结构中的各个数据。
select name,friends[1],children['yula'],address.city from test3;
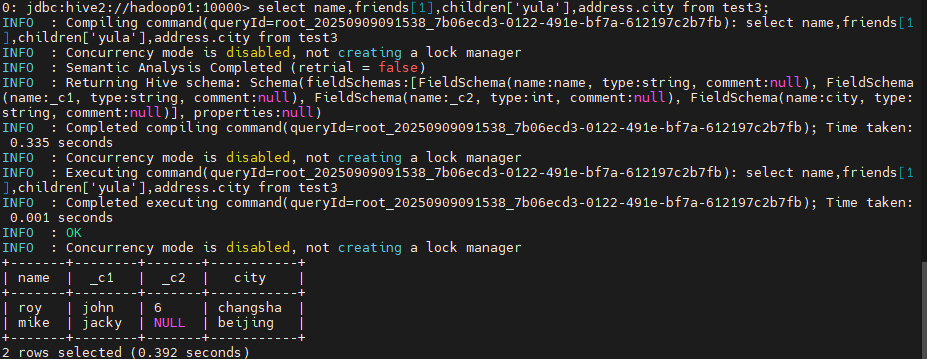
这些复杂结构的访问方式也不用强记,大都跟java中对应类型的访问方式类似。
小结:
从这个简单的示例中,我们了解了hive的数据类型,能够在hive中正确维护表结构。另外,也基本上理解了hive的工作方式。
hive的元数据中维护表结构,而表结构本质上就是对文件的一种映射关系。具体的数据以文件的形式放在hdfs对应的目录里。hive中的一个表实际上就对应hdfs中的一个目录,hive中的hql语句操作的就是这个目录中的文本文件。
而在hive的所有功能当中,其实最重要的就是通过DDL建表语句来保留对数据文件的映射关系,然后通过查询语句来对数据文件进行统计。而对数据的修改则不是hive的强项,通常都是由其他大数据计算框架,比如spark、hadoop、flink等这些框架来计算。
那接下来,我们就从DDL和查询这两个方向,继续深入学习下hive的使用方式。
2.Hive-DDL
2.1 维护数据库
跟mysql类似,hive中也有库的概念。默认会创建一个default数据库。
Hive中的完整建库语句如下:
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
这其中,中括号的部分都是可选指令。比如 if not exists表示当前库不存在的时候才创建,存在时就不去覆盖已有的数据库。
我们执行这样的语句:
create database db_hive; --创建库
show databases; --查询所有库
desc database db_hive; -- 描述库 这里可以看到对应的hdfs路径。
从这里可以看到,hive中创建的库,和表相似,也是对应一个hdfs上的路径。唯一的不同,只是这个目录名字是在数据库名后加了个.db后缀。 后面使用use db_hive,就可以切换到这个数据库,在这个库里的表就会创建在自己对应的目录里。
然后,删除库的语句:
drop database db_hive; --删除库
drop database db_hive cascade; --强制删除
这些基本的语句都跟mysql很类似。而hive中的库与mysql中的库也有点区别,hive中的库可以添加一些属性。
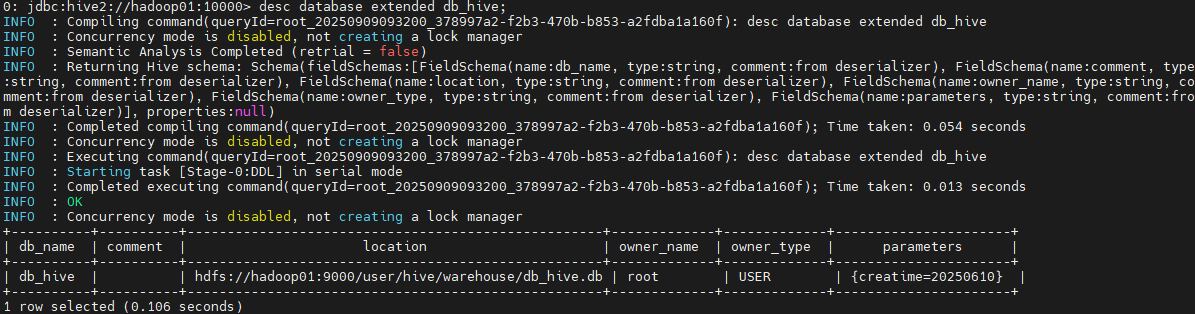
alter database db_hive set dbproperties('creatime'='20250610'); --添加属性
desc database extended db_hive; --查看数据库信息,extended就可以查到设置的这些属性。
2.2 维护表
表可以认为是Hive中最为重要的一个组件,因为他实际上维护了hive中的表与hdfs上的数据文件映射关系,数据文件的形式是很多样的,所以hive中的表也需要设计得非常复杂,来映射各种不同的数据文件。
简单的建表语句之前已经接触过了,这里就先列出一下hive中完整的可选建表语句:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
同样,其中中括号的是可选项,其他就是必选的了。从中括号的数量也能看出hive中的表比库复杂多了。这些中括号中,有很多是直接一看就能明白的。比如:
(1)[IF NOT EXISTS] 表示表不存在时才建表;
(2)[(col_name data_type)] 表示表的字段;
(3)[COMMENT table_comment] 表的描述信息;
(4)[ROW FORMAT row_format] 表的行格式,还包含了复杂数据结构的分隔符,这个之前已经接触过了;
(5)[LOCATION hdfs_path] 表对应的hdfs路径;
(6)[TBLPROPERTIES (property_name=property_value, …)] 表的额外属性;
(7)[AS select_statement] AS后跟查询语句,根据查询语句的结果建表;
(8)[STORED AS file_format] 表的文件存储格式。有三种格式可选:TESTFILE(文本),SEQUENCEFILE(二进制序列文件)、RCFILE(列式存储格式文件)。最常用的就是文本类型,这样可以在hdfs上直接看到数据内容。而如果需要压缩,可以使用SEQUENCEFILE。
而复杂点的是下面这几个选项:
(1)[EXTERNAL] 表示是不是外部表;
(2)[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)] 维护分区表;
(3)[CLUSTERED BY (col_name, col_name, …) ] ,[SORTED BY (col_name[ASC|DESC], …)] INTO num_buckets BUCKETS]。这两个可选项是维护分桶表。
接下来简单介绍下hive中对表的维护。关于hive的外部表、分区表和分桶表,会在后面一一介绍。
重命名表:
ALTER TABLE table_name RENAME TO new_table_name;
更新列:
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type[COMMENT col_comment] [FIRST|AFTER column_name]
增加或替换列:
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
add表示是增加列。replace columns 表示替换表的所有列,相当于对表结构进行重建。
并且对表结构的修改都只是修改hive的元数据,hdfs上的数据文件不会改动。
2.3 外部表
什么是外部表?
通常我们在hive中创建的表,包括我们之前创建的表,默认都是内部表或者称为管理表。hive在维护这些表时同样会去维护表的数据文件。如果在hive中删除一个内部表,那表对应的hdfs文件也会删除。而我们知道,hive最擅长的是对数据进行查询,而不是管理。他的数据通常需要与别的工具共享。而这种内部表,是不适合与其他工具共享数据的。
而外部表就表示hive并不真正拥有这些表中的数据。在hive中删除这张表,只会删除hive自己的元数据信息,而并不会真正删除hdfs上的文件。当然,如果在hive中删除数据,那hdfs文件中的数据还是会一起删除掉的。
例如使用hive做日志数据搜索,通常需要其他工具将应用的日志集中收集到HDFS文本文件中,然后再用hive来分析。这个时候,显然还是使用外部表比内部表更合适。其实在Hive的大部分应用场景中,外部表用得比内部表更多。
内部表与外部表的相互转换
(1)查询表的类型:
desc formatted userinfo;

(2)内部表修改为外部表:
desc formatted userinfo; alter table userinfo set tblproperties('EXTERNAL'='TRUE');
desc formatted userinfo;

(3)外部表修改为内部表:
alter table userinfo set tblproperties('EXTERNAL'='FALSE');
desc formatted userinfo;
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写!
2.4 分区表
之前我们已经知道,Hive中的一个表实际对应HDFS文件系统上的一个独立的文件夹,文件夹下的所有文本就是Hive中的表数据。而分区表同样也是对应HDFS上的一个文件夹,不过,在分区表中增加了分区的概念,每个分区对应文件夹中的一个子目录。利用分区表,可以把一个大的数据集根据业务需要分割成效的数据集。然后在查询时,也可以在where子语句中选择执行的分区。
**建表:**下面我们来建立一个分区表:部门信息以及他们的办公室。
create table deptinfo(
deptno int, dname string, officeroom string
)
partitioned by (year string)
row format delimited fields terminated by ',';
注意,分区字段不能是表中已经存在的列。
建完表之后,可以到HDFS上看一下,此时并没有创建deptinfo表的目录。

查数据: 然后我们在服务器本地准备几个数据文件。
dept_1.txt
10,ACCOUNTING,2700
15,RESEARCH,2800
20,SALES,2900
25,MANAGER,2700
30,DEV,2600
35,TEST,2600
dept_2.txt
10,ACCOUNTING,1700
15,RESEARCH,1800
20,SALES,1900
25,MANAGER,1700
30,DEV,1600
35,TEST,1600
dept_3.txt
10,ACCOUNTING,2700
15,RESEARCH,2800
20,SALES,2900
25,MANAGER,2700
30,DEV,2600
35,TEST,2600
然后将文件导入分区表:
load data local inpath '/home/dept_1.txt' into table deptinfo partition(year='2025');
load data local inpath '/home/dept_2.txt' into table deptinfo partition(year='2024');
load data local inpath '/home/dept_3.txt' into table deptinfo partition(year='2023');
注意:分区表加载数据时,必须要指定分区。
导入成功后,先到hdfs上看一下他是如何组织的hdfs数据文件:

他是以分区字段作为目录,然后将数据文件上传到了对应的目录。
可以先查一下deptinfo表的数据:
select * from deptinfo;
select * from deptinfo where year='2025';
select * from deptinfo where year='2025' or year='2024';
可以看到,分区列可以像数据列一样进行查询。
**管理分区:**接下来可以用以下这些语句来对分区进行管理。
#创建分区
hive>alter table deptinfo add partition(year='2022');
hive>alter table deptinfo add partition(year='2021')partition(year='2020');
#删除分区
hive>alter table deptinfo drop partition(year='2021'),partition(year='2020');
#查看分区表的分区情况
hive>show partitions deptinfo;
#查看表结构
hive>desc formatted deptinfo;

另外,在分区表的基础上,还可以对分区字段再继续做二级分区。例如我们这个示例中,已经按年进行了分区,在分区后,还可以添加一个按月的二级分区。
动态分区: 我们之前的分区表,都是以静态方式分配好分区。但是,实际使用时,我们往往希望就按照数据的某一个字段值来分区,并且事先也并不知道要分多少个区。比如之前的部门信息表,就希望按照officeroom字段来分区。这种就称为动态分区。
我们来创建另外一张分区表,对部门信息按照deptno进行分区。
create table deptinfo_dep(
dname string, officeroom string
)
partitioned by (deptno int)
row format delimited fields terminated by ',';
然后我们尝试从deptinfo表把数据全部转移过来。
那如果可以指定deptno的分区键,就可以这样转移。这样Hive会给deptinfo_dep表创建一个deptno=70的分区。
insert into table deptinfo_dep partition(deptno='70') select dname,officeroom from deptinfo; --执行mapreduce转移数据。
但是现在如果想要把deptinfo表的数据全部迁移过来,不知道要创建多少分区。这时要怎么写呢?可不可以这样写:
insert into table deptinfo_dep partition(deptno) select dname,officeroom,deptno from deptinfo;
不指定分区键的值,然后在后面的select语句中,会默认以最后一个字段作为分区键去创建对应的分区。但是这个语句执行后,会报错:

从字面上就能看到,这是因为Hive的动态分区默认是strict严格模式,这种模式下必须指定分区键的值。可以执行后面的set语句将hive.exec.dynamic.partition.mode属性的值调整为nonstrict。
那接下来在hive中执行这个语句 set hive.exec.dynamic.partition.mode=nonstrict 后,就可以执行上面的动态分区语句了。
然后在执行这个语句的过程中,会启动一个MapReduce程序来做计算,但是在日志的开头,还会有几个提示:

很显然,这几个参数是跟MapReduce任务相关的几个属性。比如我们这个场景,数据量非常小,那reduce其实就启动一个效率能高一点,其中多个reduce反而降低了整个处理效率。那就可以通过这些参数来对MapReduce计算过程进行微调。
另外还有几个与动态分区有关的参数,也总结一下:
#是否开启动态分区功能,默认true
hive> set hive.exec.dynamic.partition;
hive.exec.dynamic.partition=true
#在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000
hive> set hive.exec.max.dynamic.partitions;
hive.exec.max.dynamic.partitions=1000
#在每个执行MR的节点上,最大可以创建多少个动态分区。
hive> set hive.exec.max.dynamic.partitions.pernode;
hive.exec.max.dynamic.partitions.pernode=100
#整个MR Job中,最大可以创建多少个HDFS文件。
hive> set hive.exec.max.created.files;
hive.exec.max.created.files=100000
#当有空分区生成时,是否抛出异常
hive> set hive.error.on.empty.partition;
hive.error.on.empty.partition=false
最后,关于分区表,应该要注意到,采用静态分区时,大部分情况下都不会产生MR的计算过程,也就是说通过hive自己的元数据就能够处理简单的分区表。而采用动态分区后,大部分情况下都会产生MR的计算。这对资源和性能都是有损耗的,所以在使用过程中应该要酌情考虑。
2.5 分桶表
分区表提供了一个隔离数据和优化查询的遍历方式。不过,并非所有的数据集合都可以形成合理的分区。在分区的基础上,Hive可以进一步组织成桶,对数据文件进行更细粒度的数据范围划分。
分区针对的是数据的存储路径,而分桶针对的是数据文件。
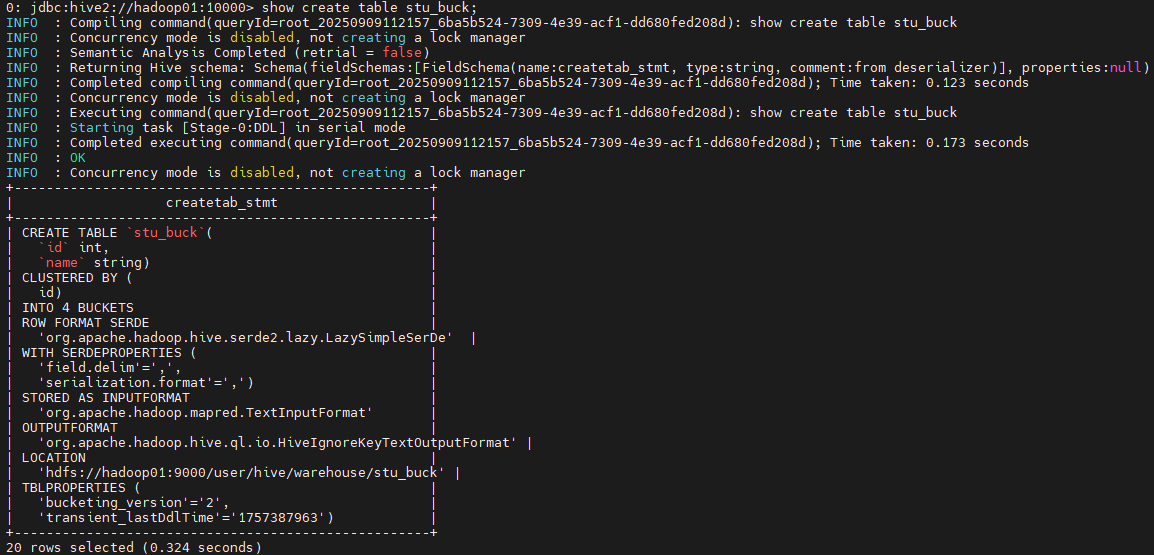
创建分桶表: 按照ID分桶,分成4个桶。
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by ',';
插入数据: 这次我们直接从hdfs把数据导入到hive。
insert into stu_buck values (1,'s1');
insert into stu_buck values (2,'s2');
关于分桶表,可以看到,简单的insert语句,也需要启动一个MapReduce任务来计算。这就是因为Hive的元数据已经不足以支撑分桶逻辑的判断了。
另外,在Hdfs上可以看到,分桶表对应了四个分桶文件,然后每次计算时,都会重新产生新的分桶文件。

Hive在分桶时, 会对分桶字段的值进行hash计算。然后对桶的个数取余,以此来决定记录存放在哪个桶里。在计算过程中,建议将reduce的个数设置为-1,这样可以让job自行决定需要用多少个reduce。
随机抽样: 对于非常大的数据集,Hive还支持按通进行随意抽样,以满足某些只需要少量有代表性数据的场景。
select * from stu_buck tablesample(bucket 1 out of 4 on id);
这个tablesample表示在对id的四个分桶中抽取第一个分桶里的随机数据。
最后,补充一个指令,可以查看hive中的建表情况:
show create table stu_buck;
关于Hive的表结构管理,还有另外很重要的一块功能就是Hive与其他数据平台的数据互通,比如HBase。后续文章继续介绍。