目录
一、元字符(Metacharacters)
(1)通配符 .
- .即为通配符、万能符或通配元字符
- 匹配一个除了换行符\n以外任何符号
s = "apple ape agree age amaze animate advertise a\ne"
ret = re.findall("a.e",s)
print(ret)
// 结果
['ape', 'age', 'aze', 'ate']
(2)字符集 []
匹配一个中括号中出现的任意原子符号
s ="apple ape agree age amaze animate advertise a\ne a&e a@e a6e a9e"
r = re.findall("a.e", s)
r = re.findall("a[pgz]e",s)
r = re.findall("a[a-z]e",s)
r = re.findall("a[^a-z]e",s)
r = re.findall("a[0-9]e", s)
print(r)注意:当在中括号里面的开始加上^,则表示除了括号中的内容剩下的可取,如a[^a-z]e
(3)重复元字符
| 元字符 | 说明 |
| {n,m} | 数量范围贪婪符,指定左边原子的数量范围,有{n},{n,},{,m},{n,m}四种写法,其中n与m必须是非负整数。
|
| * | 指定左边原子出现0次或多次,等同{0,} |
| + | 指定左边原子出现1次或者多次,等同于{1,} |
| ? | 指定左边原子出现0次或者1次,等同于{0,1} |
注意:
重复默认为贪婪匹配,可以通过在重复符右边加一个?取消贪婪匹配,按照非贪婪模式匹配
(4)^和$
reg为正则表达式,str为字符串。
- ^:匹配字符串的开始
如果reg中以^开始,则表示str中的字符开始得和reg开始相同str = "/abc/def/yuan/blog/1990/2/xxx/yyy" reg = "^/yuan/blog/[0-9]{4}/[0-9]{1,2}" ret = re.findall(reg,path) // ret: ['/yuan/blog/1990/2'] - $:匹配字符串的末尾
如果reg中以$结尾,则表示str中的字符结尾不能再有其他内容了str = "/abc/def/yuan/blog/1990/2" reg = "/yuan/blog/[0-9]{4}/[0-9]{1,2}/$" ret = re.findall(reg,path) // ret: ['/yuan/blog/1990/2']
(5)转义符\
- 赋予某些普通符号特殊功能
元字符 描述 \d匹配一个数字原子,等价于 [0-9]。\D匹配一个非数字原子。等价于 [^0-9]或[^\d],包括空格。\w匹配一个包括下划线的单词原子。等价于 [A-Za-z0-9_]。\W匹配任何非单词字符。等价于 [^A-Za-z0-9_]或[^\w]。\n匹配一个换行符 \t匹配一个制表符,tab键 \s匹配一个任意空白字符原子,包括空格、制表符、换页符等等。 \S匹配一个任意非空白字符原子。 \b匹配一个单词边界原子,也就是指单词和非单词原子值间的位置。单词原子包括a-z、A-Z、0-9 \B匹配一个非单词边界原子,等价于
[^\b]。在python语言中\也是转义符,为了防止\在re处理前被python处理,所以得再多加一个\;也可以再前面加个r即可
import re s = "yuan 23 rain 188 alvin 5 eric 9999" ret = re.findall("\\d+",s); ret = re.findall(r"\d+",s); // 也可以使用rs = "The cat set on the caterpillar.I love cat!" ret = re.findall(r"cat\b",s) // ['cat','cat'] - 取消特殊功能符号以普通化
元字符都是特殊功能符号
s = "https://wwwwxxx.com/,https://www.baidu.com/,yuan,rain,http://www.jd.com/,https://www.taobao.com" ret = re.findall(r"http?://www\.[a-z]*?\.com",s) // ['https://wwwwxxx.com/','https://www.baidu.com/','https://www.taobao.com']
(6)()分组与优先提取
- 分组:
s = "apple banana peach orange aaa appleappleapple appleapple" ret = re.findall("(?:apple){2,3}",s) // ['appleappleapple','appleapple'] - 优先提取:从规则中提取内容
取消优先提取 ?:text = """ Visit us at user@qq.com for more info. Contact support at support@qq.com. Also,check out admin@my163.com and info@163.com """ re.findall(r"\b[\w.-]+@\w*163\.com\b",txt) // ['admin@my163.com','info@163.com'] re.findall(r"\b([\w.-]+)@\w*163\.com\b",txt) // ['admin','info']
(7)| 或
text = "I like apple,banana,and orange.I also enjoy grapes."
pattern = r"apple|banana|orange"
matches = re.findall(pattern,text) // ['apple','banana','orange']text = """
Visit us at example.com for more information.
You can also check out mysite.cn and partner-site.com.
Don't forget about blog-example.com or support@service.cn.
"""
ret = re.findall(r"\b[\w.-]+\.cn|\b[\w.-]+\.com", text)
// ['example.com', 'mysite.cn', 'partner-site.com', 'blog-example.com', 'service.cn']
ret = re.findall(r"\b[\w.-]+\.(com|cn)", text)
// 优先提取:['com', 'cn', 'com', 'com', 'cn']
ret = re.findall(r"\b[\w.-]+\.(?:com|cn)", text)
// ?:取消优先提取 ['example.com', 'mysite.cn', 'partner-site.com', 'blog-example.com', 'service.cn']二、python 模块中的常用函数
re模块中的常用函数:
| 函数 | 描述 |
|---|---|
findall |
按指定的正则模式查找文本中所有符合正则模式的匹配项,以列表格式返回结果。 |
search |
在字符串中任何位置查找首个符合正则模式的匹配项,存在则返回 re.Match 对象,不存在返回 None。 |
match |
判定字符串开始位置是否匹配正则模式的规则,匹配则返回 re.Match 对象,不匹配返回 None。 |
split |
按指定的正则模式来分割字符串,返回一个分割后的列表。 |
sub |
把字符串按指定的正则模式查找符合正则模式的匹配项,并可以替换一个或多个匹配项成其他内容。 |
compile |
compile 方法用于编译正则表达式模式,从而生成一个正则表达式对象。这个对象可以重用,使得在多个匹配操作中更高效。 |
三、Java 模块中的常用函数
java.util.regex 包是 Java 标准库中用于支持正则表达式操作的包。
java.util.regex 包主要包括以下三个类:
- Pattern 类:pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
- Matcher 类:Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
- PatternSyntaxException:PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误
import java.util.regex.Pattern;
public class Test66 {
public static void main(String[] args) {
//先写个字符串
String content="I am noob "+"from runoob.com.";
System.out.println(content);
//定义正则表达式规则
String pattern= ".*runoob.*";
boolean isMatch= Pattern.matches(pattern,content);
System.out.println("字符串中是否包含了 'runoob' 子字符串? " + isMatch);
}
}Matcher类
索引方法提供了有用的索引值,精确表明输入字符串中在哪能找到匹配:
| 方法 | 说明 |
|---|---|
| public int start() | 返回以前匹配的初始索引。 |
| public int start(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引。 |
| public int end() | 返回最后匹配字符之后的偏移量。 |
| public int end(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的最后字符之后的偏移量。 |
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test33 {
public static void main(String[] args) {
String str="cat cat cat cattie cat";
String patte1="\\bcat\\b";
Pattern p=Pattern.compile(patte1);
Matcher m=p.matcher(str);
int count=0;
while(m.find()){
count++;
System.out.println("Match number "+count);
System.out.println("start(): "+m.start());
System.out.println("end(): "+m.end());
}
}
}
| 方法 | 说明 |
|---|---|
| matches() | 尝试将整个输入序列与模式匹配。要求整个字符串完全匹配才返回 true。 |
| lookingAt() | 尝试从输入序列的起始位置开始匹配。即使整个序列不完全匹配,只要前缀部分符合模式也返回 true。 |
String s1="foo";
String s2="fooooooooooooooo";
String s3="oooooofoooo";
Pattern p=Pattern.compile(s1);
Matcher m1=p.matcher(s2);
Matcher m2=p.matcher(s3);
System.out.println(m1.lookingAt());//true
System.out.println(m2.lookingAt());//false
System.out.println(m1.matches());//false
System.out.println(m2.matches());//false| 方法 | 说明 |
|---|---|
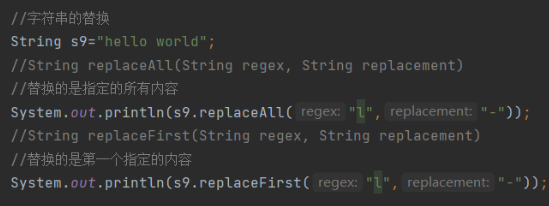
| String replaceAll(String regex, String replacement) | 替换所有的指定内容 |
| String replaceFirst(String regex, String replacement) | 替换首个内容 |
PatternSyntaxException类
PatternSyntaxException 是一个非强制异常类,它指示一个正则表达式模式中的语法错误。
PatternSyntaxException 类提供了下面的方法来帮助我们查看发生了什么错误。
| 方法 | 说明 |
|---|---|
| public String getDescription() | 获取错误的描述 |
| public int getIndex() | 获取错误的索引 |
| public String getPattern() | 获取错误的正则表达式模式 |
| public String getMessage() | 返回多行字符串,包含语法错误及其索引的描述、错误的正则表达式模式和模式中错误索引的可视化指示 |