引言
在技术领域,我们追求用更优的算法和架构来提升系统性能。同样,在语言学习中,选择正确的“大脑处理算法”也至关重要。上一篇文章我们探讨了通过“速听”强制大脑识别“语义模块”的方法,许多朋友可能会好奇:这背后有科学依据吗?还是又一个学习圈的“玄学”?这里将进一步深入其认知科学的内核,为大家揭示这套方法为何是一种科学、高效的“认知升级”。
理论基石一:认知负荷理论 (Cognitive Load Theory)
认知负荷理论是教育心理学的核心理论之一。它指出,人类的工作记忆(Working Memory)——也就是我们大脑中用于临时处理信息的“内存”——其容量是极其有限的。当我们学习新知识时,如果信息呈现的方式过于复杂或零散,就会迅速耗尽工作记忆资源,导致学习效率低下,甚至失败。
- 逐字听力的高负荷:逐字听译正是典型的高认知负荷场景。大脑需要同时执行“接收声音 -> 识别单词 -> 提取词义 -> 存储词义 -> 组合句法 -> 理解语义”等一系列复杂操作。对于非母语者,每一步都消耗巨大资源,信息流很快就会“阻塞”工作记忆,导致“听到了但没听懂”。
- 语义模块的降负荷:语义模块,在认知科学中被称为“图式”(Schema)或“组块”(Chunk)。将多个相关联的信息单元打包成一个更高阶的“图式”,是人类大脑对抗工作记忆限制的根本策略。例如,我们记忆电话号码时,会自然地将其分为
138-XXXX-XXXX这样的组块,而不是记忆11个独立的数字。在听力中,将in order to作为一个整体模块来识别,其认知负荷远小于分别处理in、order、to三个单词。
因此,从认知负荷理论看,从处理“单词”升级到处理“语义模块”,是一次根本性的降载优化,完全符合大脑高效工作的基本原理。
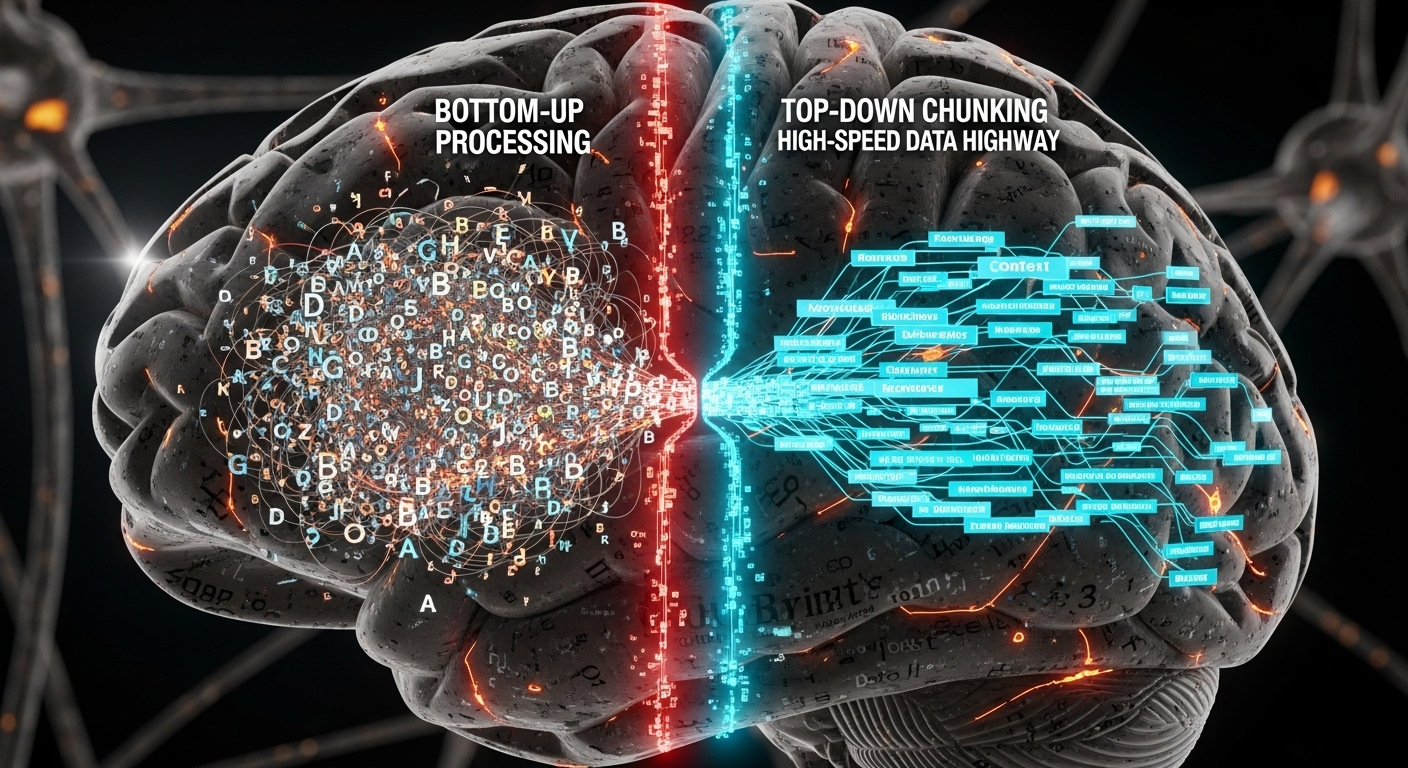
理论基石二:自上而下与自下而上的处理模型 (Top-Down vs. Bottom-Up Processing)
在认知心理学中,我们处理信息有两种基本方式:
- 自下而上 (Bottom-Up):从最小的感官输入开始,逐步构建出更高层次的理解。在听力中,这就是从音素到单词,再到句子的过程。这是最基础但最低效的处理方式。
- 自上而下 (Top-Down):利用我们已有的知识、经验和预期来指导我们对感官输入的解释。例如,根据上下文,我们能“脑补”出被噪音掩盖的单词。
一个熟练的语言使用者,会同时高效地运用这两种处理方式。而挣扎中的学习者,则过度依赖“自下而上”的模式。
“语义模块”的训练,本质上是在构建一个强大的“自上而下”处理系统。当我们大脑的“模块库”中预存了大量如 as a matter of fact 或 take into consideration 这样的“预制件”后,在听到语音流时,大脑就不再是逐个音节地被动分析,而是会主动地、自上而下地去匹配和预测这些熟悉的模块。
速听训练,正是通过施加时间压力,强制性地抑制了低效的“自下而上”处理,从而激活并强化了高效的“自上而下”的模块匹配能力。
伪科学的边界:前提与误区
尽管该方法科学有效,但如果被误用或夸大,就可能滑向“伪科学”的边缘。我们需要明确它的适用前提和潜在误区。
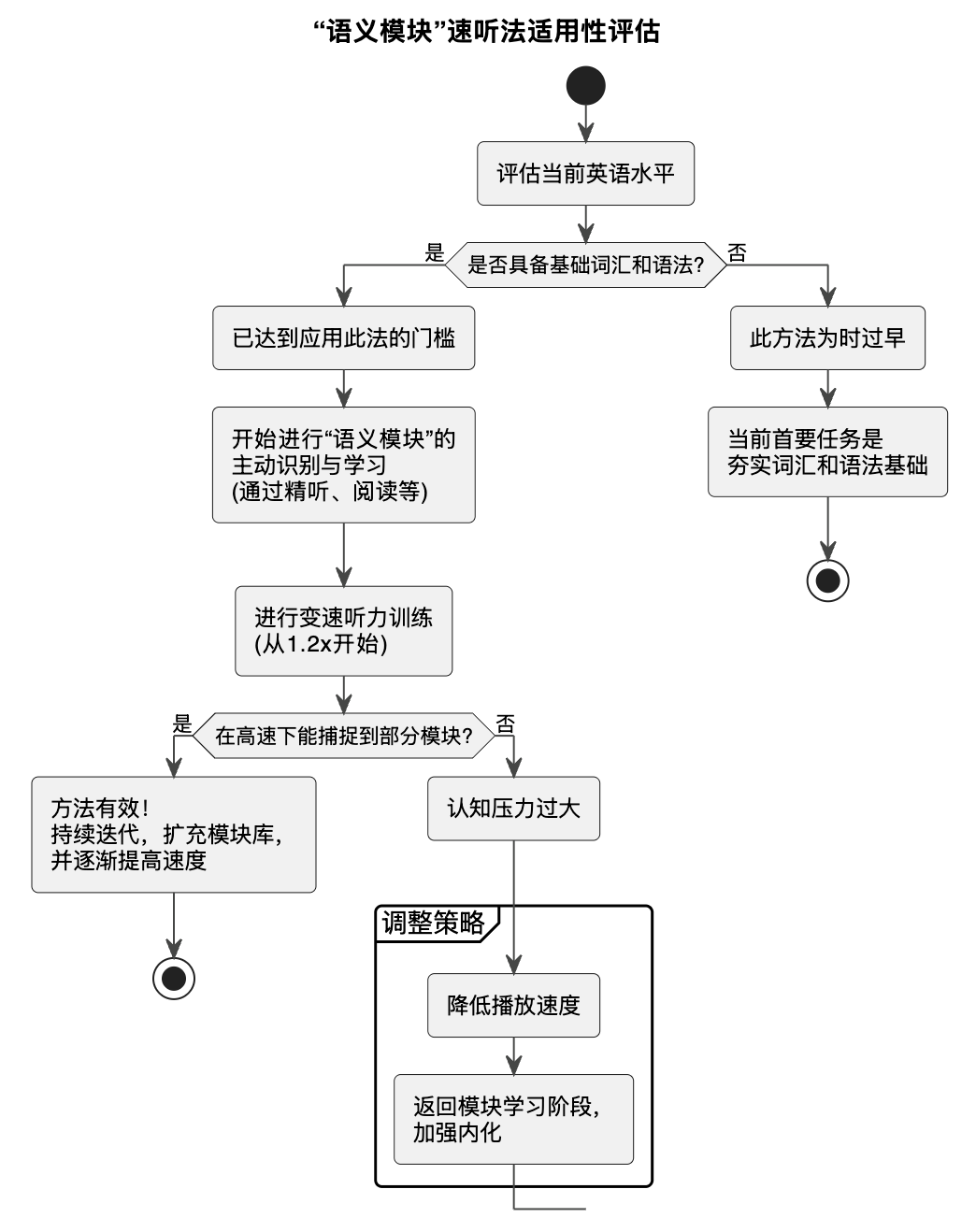
- 前提:它不是零基础的“万能药”。语义模块的识别,建立在对构成模块的基础单词有基本认知之上。如果连
look,forward,to都不认识,就不可能将looking forward to识别为一个模块。因此,此方法更适合已经有一定词汇语法基础,但听力理解遇到瓶颈的学习者,用于实现能力跃迁。 - 误区:速度是手段,而非目的。速听的价值在于“施压”,而非“求快”。如果只是盲目地用2倍速听,却不做任何模块识别和内化的刻意练习,那结果只会是听天书,毫无效果。训练的核心在于“识别模块”,速度只是达成这个目标的催化剂。
- 误区:忽略了主动构建的过程。高效的“模块库”不会自动建成。它需要学习者通过精听、跟读、总结等方式,主动地去识别、学习和内化这些语言模块。
为了更清晰地展示其适用路径,我们可以构建一个决策流程图。
结论:是科学的“性能调优”,而非“魔法”
综上所述,“通过速听构建语义模块”的听力训练法,绝非伪科学。它深深植根于认知科学的认知负荷理论、组块理论以及信息处理模型,是一套旨在优化我们大脑语言处理“算法”的科学方法论。
它不是一蹴而就的魔法,而是一项需要前提、需要刻意练习的“系统性能调优”工程。对于那些已经完成了基础“代码编写”(词汇和语法积累),但程序运行效率不高(听力理解慢、跟不上)的学习者来说,这套方法无疑提供了一条清晰、科学且高效的优化路径,能够帮助大家真正实现从“听见”到“听懂”的质的飞跃。