过去几个月,我们观察到追求更强大、更具自主性人工智能(AI)的明确趋势——模型参数量与上下文长度持续扩展。我们很荣幸分享应对这些需求的最新突破,其核心是通过创新架构提升扩展效率。我们将这代基础模型命名为Qwen3-Next。
核心亮点
作为该系列首作,Qwen3-Next-80B-A3B具有以下关键创新:
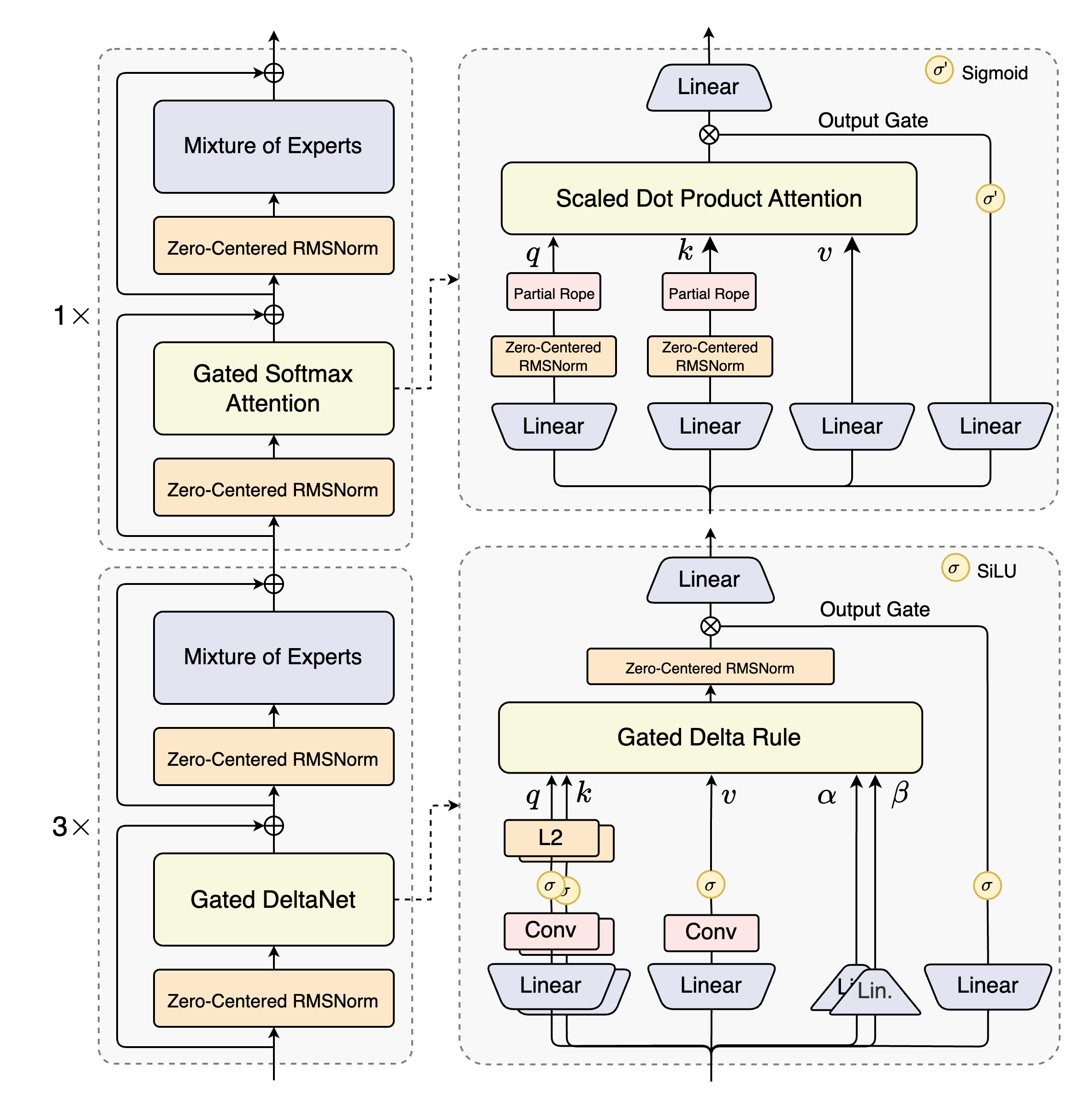
- 混合注意力机制:采用门控DeltaNet与门控注意力组合替代标准注意力,实现超长上下文的高效建模
- 超高稀疏度专家混合(MoE):MoE层激活比例极低,在保留模型能力的同时显著降低单token计算量
- 稳定性优化:包含零中心加权衰减层归一化等技术创新,确保预训练与微调过程的稳定性
- 多token预测(MTP):同步提升预训练效果与推理速度
Qwen3-Next-80B-A3B在参数量效率与推理速度方面表现突出:
- 基础版相较Qwen3-32B-Base:下游任务表现更优,总训练成本降低90%,处理32K以上上下文时推理吞吐量提升10倍
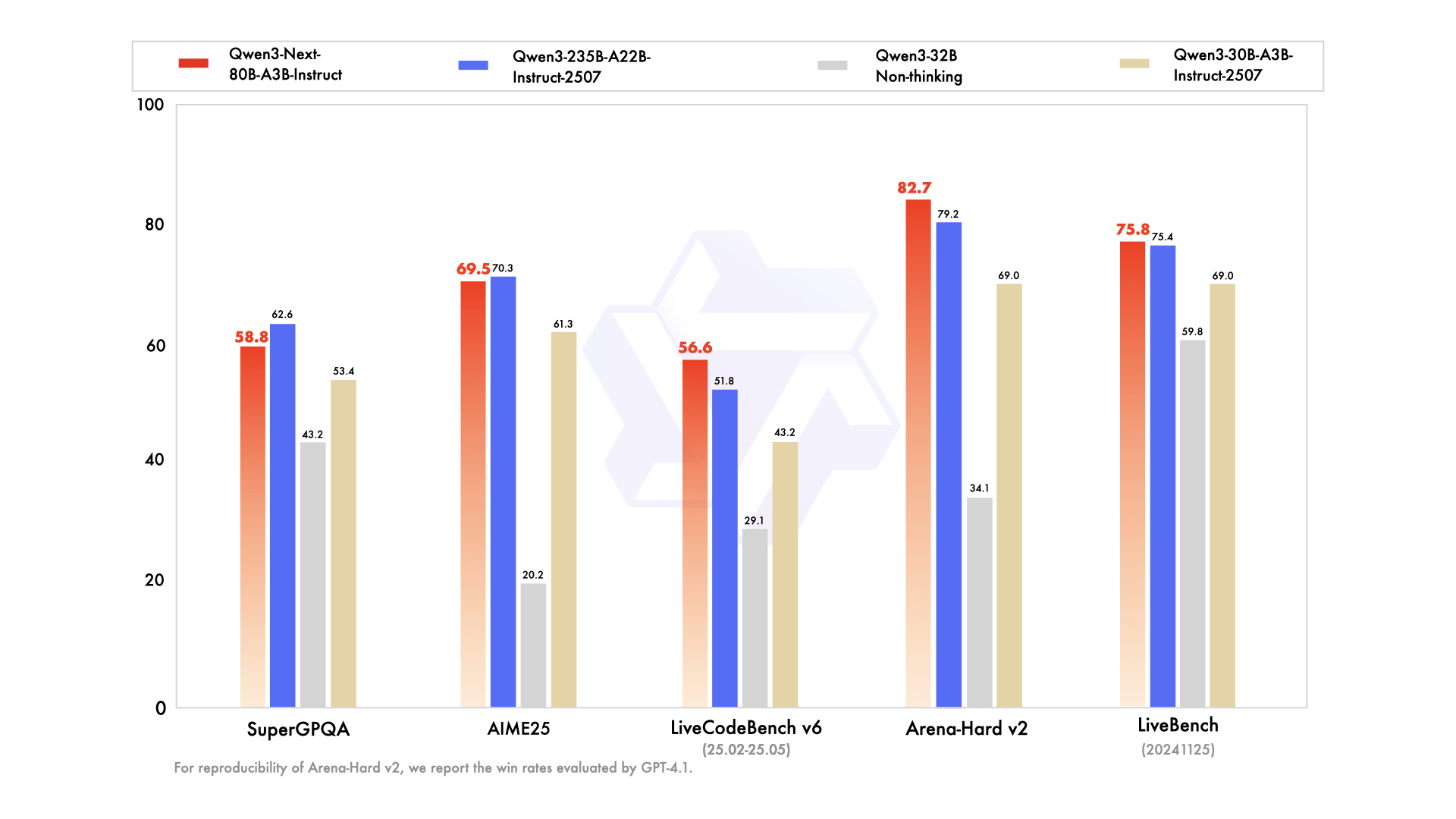
- 指令微调版在部分基准测试中与Qwen3-235B-A22B-Instruct-2507持平,且在处理256K超长上下文任务时展现显著优势
模型概览
[!注意]
Qwen3-Next-80B-A3B-Instruct 仅支持指令(非思考)模式,不会在输出中生成<think></think>块。
Qwen3-Next-80B-A3B-Instruct 具有以下特性:
- 类型:因果语言模型
- 训练阶段:预训练(15T tokens)& 后训练
- 参数总量:800亿,激活30亿
- 非嵌入参数:790亿
- 层数:48
- 隐藏维度:2048
- 混合架构:12 * (3 * (门控DeltaNet -> 混合专家) -> (门控注意力 -> 混合专家))
- 门控注意力:
- 注意力头数:查询16,键值2
- 头维度:256
- 旋转位置嵌入维度:64
- 门控DeltaNet:
- 线性注意力头数:值32,查询键16
- 头维度:128
- 混合专家系统:
- 专家总数:512
- 激活专家数:10
- 共享专家数:1
- 专家中间维度:512
- 上下文长度:原生262,144,可扩展至1,010,000 tokens
性能
| Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct | |
|---|---|---|---|---|
| Knowledge | ||||
| MMLU-Pro | 78.4 | 71.9 | 83.0 | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | 93.1 | 90.9 |
| GPQA | 70.4 | 54.6 | 77.5 | 72.9 |
| SuperGPQA | 53.4 | 43.2 | 62.6 | 58.8 |
| Reasoning | ||||
| AIME25 | 61.3 | 20.2 | 70.3 | 69.5 |
| HMMT25 | 43.0 | 9.8 | 55.4 | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | 75.8 |
| Coding | ||||
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | 56.6 |
| MultiPL-E | 83.8 | 76.9 | 87.9 | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | 57.3 | 49.8 |
| Alignment | ||||
| IFEval | 84.7 | 83.2 | 88.7 | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | 82.7 |
| Creative Writing v3 | 86.0 | 78.3 | 87.5 | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | 87.3 |
| Agent | ||||
| BFCL-v3 | 65.1 | 63.0 | 70.9 | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | 71.3 | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | 44.0 | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | 74.6 | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | 50.0 | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | 32.5 | 13.2 |
| Multilingualism | ||||
| MultiIF | 67.9 | 70.7 | 77.5 | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | 79.4 | 76.7 |
| INCLUDE | 71.9 | 70.9 | 79.5 | 78.9 |
| PolyMATH | 43.1 | 22.5 | 50.2 | 45.9 |
*:为保证可复现性,我们报告的胜率均由GPT-4.1评估得出。
快速开始
Qwen3-Next的代码已合并至Hugging Face transformers的主分支。
pip install git+https://github.com/huggingface/transformers.git@main
若使用早期版本,将遇到以下报错:
KeyError: 'qwen3_next'
以下代码片段展示了如何基于给定输入内容生成模型输出。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
[!注意]
Hugging Face Transformers 目前未全面支持多令牌预测(MTP)功能。
[!注意]
效率或吞吐量的提升高度依赖具体实现方案。
建议采用专用推理框架(如 SGLang 和 vLLM)执行推理任务。
[!提示]
根据推理配置,使用flash-linear-attention和causal-conv1d可能获得更优效率。
详细安装要求和说明请参阅上述链接。
部署方案
可使用最新版 sglang 或 vllm 创建兼容 OpenAI 的 API 服务端点。
SGLang
SGLang 是面向大语言模型与视觉语言模型的高效服务框架,支持启动兼容 OpenAI API 规范的服务器。
SGLang 的 main 分支已支持 Qwen3-Next 模型,可通过源码安装:
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
以下命令将在 4 张 GPU 上启动支持 256K 上下文长度的 tensor parallel 服务,API 端点位于 http://localhost:30000/v1:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
启用 MTP 功能时推荐使用以下命令(其余参数与上方相同):
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
[!注意]
当前必须设置环境变量SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1
[!注意]
默认上下文长度为 256K。若服务启动失败,建议调整为较小值(如32768)。
vLLM
vLLM 是一个面向大语言模型的高吞吐量、内存高效的推理与服务引擎。
vLLM 可用于部署兼容 OpenAI API 协议的服务器。
vLLM 的 main 分支现已支持 Qwen3-Next 模型,可通过源码安装:
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
以下命令可用于在4块GPU上使用张量并行创建一个最大上下文长度为256K token的API端点,地址为http://localhost:8000/v1。
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
建议用于 MTP 的命令如下,其余设置与上述相同:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
[!Note]
目前需要设置环境变量VLLM_ALLOW_LONG_MAX_MODEL_LEN=1。
[!Note]
默认上下文长度为256K。若服务器启动失败,请考虑降低上下文长度至较小值(如32768)。
智能体应用
Qwen3在工具调用能力方面表现卓越。建议使用Qwen-Agent来充分发挥Qwen3的智能体能力。Qwen-Agent内置封装了工具调用模板和解析器,可大幅降低编码复杂度。
您可通过MCP配置文件定义可用工具,使用Qwen-Agent集成工具,或自行集成其他工具。
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
处理超长文本
Qwen3-Next原生支持高达262,144个token的上下文长度。
当对话总长度(包括输入和输出)远超此限制时,我们建议使用RoPE缩放技术来有效处理长文本。
我们已通过YaRN方法验证了模型在百万级token上下文长度下的性能表现。
目前transformers、vllm和sglang等多个推理框架已支持YaRN技术。
对于支持框架而言,通常有两种启用YaRN的方法:
- 修改模型文件:
在config.json文件中添加rope_scaling字段:{ ..., "rope_scaling": { "rope_type": "yarn", "factor": 4.0, "original_max_position_embeddings": 262144 } }
-传递命令行参数:
对于 vllm,你可以使用
shell VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
对于sglang,你可以使用
shell SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
[!NOTE]
所有知名的开源框架均采用静态YaRN实现,这意味着缩放因子不随输入长度变化,可能对较短文本的性能产生影响。
建议仅在需要处理长上下文时添加rope_scaling配置项。
同时推荐根据实际需求调整factor参数。例如,若应用场景的典型上下文长度为524,288个token,将factor设为2.0更为合适。
长上下文性能表现
我们在RULER基准测试的100万token版本上对模型进行了评估。
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
- 注:Qwen3-Next版本测试时启用了YaRN技术,Qwen3-2507版本测试时启用了双分块注意力机制
- 由于评估耗时较长,每个长度使用260个样本进行测试(13个子任务,每个任务20个样本)
最佳实践
为获得最佳性能,建议采用以下配置:
采样参数设置:
- 推荐使用
温度系数=0.7、TopP=0.8、TopK=20及MinP=0 - 在支持框架中,可将
存在惩罚参数设置在0到2之间以减少无休止重复。但需注意,较高数值可能导致偶尔出现语种混杂现象及模型性能轻微下降
- 推荐使用
输出长度建议:对于大多数查询场景,推荐使用16,384个token的输出长度,该长度对指令模型完全够用
标准化输出格式:基准测试时建议通过提示词规范模型输出
- 数学题:在提示词中加入"请分步骤推理,并将最终答案置于\boxed{}中"
- 选择题:在提示词中添加以下JSON结构以标准化响应:“请在
answer字段中仅显示选项字母,例如"answer": "C"”