条件竞争
C++的内存模型
C++都是操作系统级别的编程语言。C++标准委员会的一个目标是令C++尽量贴近计算机底层,而不必改用其他更低级的语言。
C++ 内存模型是 C++11 标准引入的核心特性之一,它定义了多线程环境下内存访问的规则,解决了 “不同线程如何观察和修改共享数据” 的根本问题。在此之前,C++ 标准未涉及并发,依赖编译器和硬件的非标准行为,导致多线程代码移植性差且易出现隐蔽 Bug(如数据竞争、指令重排导致的逻辑错误)。
C++ 内存模型的本质是为编译器和硬件设定 “行为边界”:既允许编译器进行优化(如指令重排、缓存),又强制要求在关键场景下(如原子操作、同步原语)保证数据的可见性和操作的有序性,最终确保多线程程序的正确性和可预测性。
内存模型牵涉两个方面:基本结构和并发。基本结构关系到整个程序在内存中的布局。它对并发很重要,尤其是在我们分析底层原子操作的时候,就C++而言,归根结底,基本结构就是对象和内存区域。虽然C++为对象赋予了各种性质,如类型和生存期,但C++标准只将“对象”定义为“某一存储范围”(a region of storage)。
不论对象属于什么类型,它都会存储在一个或多个内存区域中。每个内存区域或是对象/子对象,属于标量类型(scalar type),如unsigned short和my_class*,或是一串连续的位域(bit field)。位域有一项重要的性质:尽管相邻的位域分属不同对象,但照样算作同一内存区域。
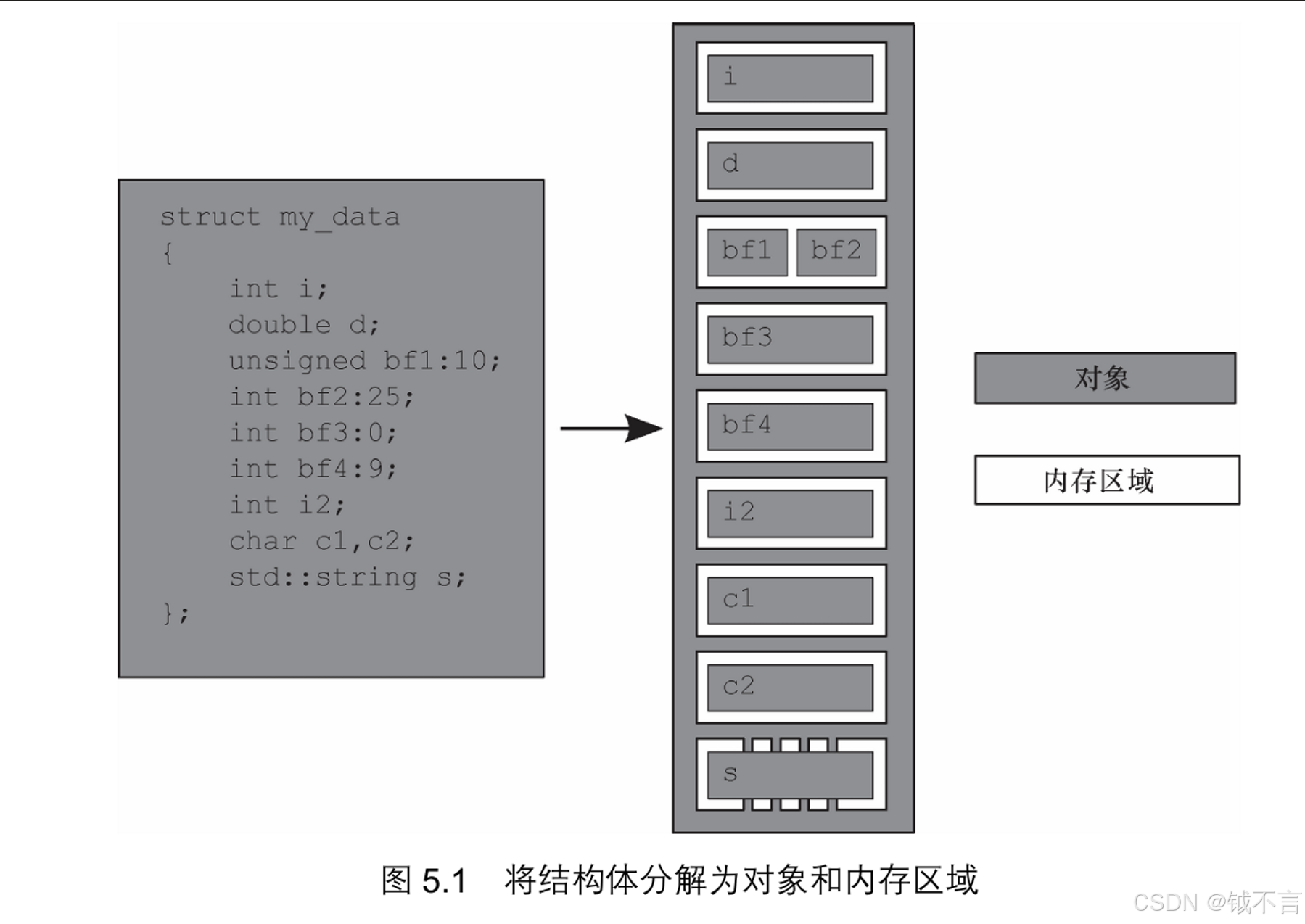
首先,整个结构体就是一个对象,它由几个子对象构成,每个数据成员即为一个子对象。位域bf1和bf2共用同一块内存区域,std::string对象s则由几块内存区域构成,别的数据成员都有各自的内存区域。
请注意,bf3是0宽度位域(其变量名被注释掉,因为0宽度位域必须匿名),与bf4 彻底分离,将bf4排除在bf3的内存区域之外,但bf3实际上并不占有任何内存区域。
我们从中总结出4个要点:每个变量都是对象,对象的数据成员也是对象;每个对象都占用至少一块内存区域;若变量属于内建基本类型(如int或char),则不论其大小,都占用一块内存区域(且仅此一块),即便它们的位置相邻或它们是数列中的元素;相邻的位域属于同一内存区域。
内存模型的规则
在深入规则前,必须先掌握几个核心术语,它们是理解内存模型的“语言”。
| 概念 | 定义与关键说明 |
|---|---|
| 数据竞争(Data Race) | 当两个线程同时访问同一共享数据,且至少有一个线程是写操作,且未通过同步机制(如原子操作、互斥锁)保护时,就会发生数据竞争。 ⚠️ 后果:C++ 标准将数据竞争的程序定义为“未定义行为(UB)”,可能导致程序崩溃、结果错误、行为不可预测。 |
| 指令重排(Instruction Reordering) | 编译器或 CPU 为优化性能,会调整代码执行顺序(只要不改变单线程内的语义)。 例:单线程中 a=1; b=2; 可能被重排为 b=2; a=1;,但多线程下可能导致其他线程观察到“b已改但a未改”的异常状态。 |
| 缓存一致性(Cache Coherence) | CPU 为提升速度会将内存数据缓存到寄存器或 L1/L2 缓存中。多线程下,一个线程修改的缓存数据可能未及时同步到主内存,导致其他线程读取到“旧值”(即“缓存可见性问题”)。 |
| 原子操作(Atomic Operation) | 不可分割的操作:要么完全执行,要么完全不执行,中间不会被其他线程打断。 例: std::atomic<int> x; x++; 是原子操作,不会出现“两个线程同时加1却只加1次”的情况。 |
| 内存序(Memory Order) | 原子操作的“附加约束”,用于控制操作的有序性(禁止哪些指令重排)和数据的可见性(何时将缓存同步到主内存)。是 C++ 内存模型的“核心调控工具”。 |
C++ 内存模型通过以下规则,在“性能优化”和“并发正确性”之间取得平衡:
1. 单线程语义保证(As-If-Serial)
这是所有优化的基础:编译器和硬件可以重排指令、使用缓存,但必须保证“单线程内的执行结果与代码顺序完全一致”。
- 例:单线程中
int a=0, b=0; a=1; b=a;,编译器不会将b=a重排到a=1之前(否则b会被赋值为 0,违背单线程语义)。 - 该规则不约束多线程:单线程语义正确的代码,多线程下若无同步,仍可能出现数据竞争。
2. 原子操作与无数据竞争保证
std::atomic 模板(定义于 <atomic> 头文件)提供的原子操作,是避免数据竞争的核心工具。其核心特性:
- 不可分割性:对同一原子对象的所有原子操作,不会被其他线程打断(如
fetch_add、compare_exchange等)。 - 无数据竞争:仅使用原子操作访问共享数据时,不会触发数据竞争(UB),程序行为可预测。
- 可配置内存序:原子操作的“有序性”和“可见性”由
std::memory_order枚举控制(见下文),默认是最严格的memory_order_seq_cst(顺序一致)。
3. 内存序(std::memory_order):控制有序性与可见性
内存序是 C++ 内存模型的“灵魂”,它允许开发者根据需求选择“严格程度”——越严格的内存序正确性越高,但性能损耗越大;越宽松的内存序性能越好,但需确保逻辑正确。
C++ 定义了 6 种内存序,可分为三大类:
(1)顺序一致序(Sequential Consistency, memory_order_seq_cst)
- 规则:所有线程观察到的“原子操作顺序”完全一致,且与代码的“全局顺序”(按程序文本的先后)一致。
- 本质:禁止所有跨原子操作的指令重排,且原子操作会强制刷新缓存(确保修改对所有线程可见)。
- 场景:对正确性要求极高、性能敏感度低的场景(如全局计数器、状态标志)。
- 示例:
#include <atomic> #include <thread> std::atomic<bool> x(false), y(false); int z = 0; void write_x() { x.store(true, std::memory_order_seq_cst); } // 1 void write_y() { y.store(true, std::memory_order_seq_cst); } // 2 void read_x_then_y() { while (!x.load(std::memory_order_seq_cst)); // 等待1完成 if (y.load(std::memory_order_seq_cst)) z++; // 3:此时y必为true(因1在2前,3在1后) } int main() { std::thread t1(write_x), t2(write_y), t3(read_x_then_y); t1.join(); t2.join(); t3.join(); assert(z == 1); // 必然成立(顺序一致序保证) }
(2)获取-释放序(Acquire-Release, memory_order_acquire / memory_order_release)
- 核心思想:通过“释放(Release)”操作和“获取(Acquire)”操作的配对,建立线程间的“同步关系”(Synchronizes-With),确保“释放前的修改对获取后可见”。
- 具体规则:
- Release 操作(写操作):
- 禁止将“Release 操作之前的指令”重排到“Release 操作之后”;
- Release 操作修改的数据,会同步到主内存(确保其他线程可见)。
- Acquire 操作(读操作):
- 禁止将“Acquire 操作之后的指令”重排到“Acquire 操作之前”;
- Acquire 操作会从主内存读取数据(确保获取最新值)。
- Release 操作(写操作):
- 关键特性:仅保证“配对的 Release-Acquire”之间的有序性,不保证“全局所有原子操作的顺序一致”(性能比
seq_cst好)。 - 场景:实现无锁数据结构(如无锁队列)、线程间传递数据。
- 示例:
#include <atomic> #include <thread> std::atomic<int> ptr(0); int data = 0; void producer() { data = 42; // 1:普通写操作 ptr.store(1, std::memory_order_release); // 2:Release 写(确保1在2前) } void consumer() { while (ptr.load(std::memory_order_acquire) != 1); // 3:Acquire 读(等待2完成) // 4:Acquire 保证3在4前,且2与3配对 → data必为42(1的修改对4可见) assert(data == 42); // 必然成立 } int main() { std::thread t1(producer), t2(consumer); t1.join(); t2.join(); return 0; }
(3)宽松序(Relaxed Order, memory_order_relaxed)
- 规则:仅保证原子操作本身的“不可分割性”,不保证任何有序性和可见性——允许指令重排,也不强制缓存同步。
- 本质:原子操作仅用于避免数据竞争,不提供线程间的同步关系。其他线程观察到的操作顺序可能是任意的。
- 场景:仅需确保“操作不可分割”,无需关心顺序的场景(如统计独立事件的计数器)。
- 示例:
#include <atomic> #include <thread> std::atomic<int> cnt(0); void increment() { // 宽松序:仅保证cnt++不可分割,但多个线程的++顺序可能被重排 cnt.fetch_add(1, std::memory_order_relaxed); } int main() { std::thread t1(increment), t2(increment); t1.join(); t2.join(); assert(cnt == 2); // 必然成立(因fetch_add是原子的,无数据竞争) return 0; }
6种内存序汇总表
| 内存序枚举值 | 适用操作类型 | 核心语义 | 性能 |
|---|---|---|---|
| memory_order_seq_cst | 读/写 | 全局顺序一致,最严格 | 最低 |
| memory_order_acquire | 读(load) | 禁止后续指令重排到前面,确保读取最新值 | 中 |
| memory_order_release | 写(store) | 禁止前面指令重排到后面,确保修改同步到主内存 | 中 |
| memory_order_acq_rel | 读-改-写(如fetch_add) | 同时具备 acquire 和 release 语义(读时 acquire,写时 release) | 中 |
| memory_order_consume | 读(load) | 仅保证“依赖于该读操作的指令”不重排(比 acquire 宽松,较少使用) | 高 |
| memory_order_relaxed | 读/写 | 仅保证原子性,无有序性和可见性约束 | 最高 |
4. 同步关系(Synchronizes-With)与可见性链
C++ 内存模型通过“同步关系”建立线程间的“可见性保证”:
- 若操作 A(线程1)和操作 B(线程2)存在 Synchronizes-With 关系,则:
- 线程1中“在 A 之前执行的所有操作”的修改,对线程2中“在 B 之后执行的所有操作”可见。
- 编译器和硬件不会将“线程1中 A 之前的指令”重排到 A 之后,也不会将“线程2中 B 之后的指令”重排到 B 之前。
常见的 Synchronizes-With 关系场景:
- 原子操作的 Release-Acquire 配对:
- 线程1的
atomic.store(..., memory_order_release)(A),与线程2的atomic.load(..., memory_order_acquire)(B),若 B 读取到 A 写入的值,则 A Synchronizes-With B。
- 线程1的
- 互斥锁(std::mutex):
- 线程1的
mutex.unlock()(释放锁,隐式 Release 语义),与线程2的mutex.lock()(获取锁,隐式 Acquire 语义),若线程2成功获取锁,则unlock()Synchronizes-Withlock()。
- 线程1的
- 条件变量(std::condition_variable):
- 线程1的
cv.notify_one()/notify_all(),与线程2的cv.wait()(成功被唤醒后),存在 Synchronizes-With 关系。
- 线程1的
5. C++ 内存模型的应用场景
无锁编程(Lock-Free Programming):
- 基于
std::atomic和内存序(如 acquire-release),实现无需互斥锁的并发数据结构(如无锁栈、无锁队列),避免锁竞争带来的性能损耗。 - 核心操作:
compare_exchange_weak/compare_exchange_strong(CAS 操作,实现“比较-替换”的原子性)。
- 基于
线程间通信:
- 通过 Release-Acquire 语义,安全地传递数据(如生产者-消费者模型中,生产者写入数据后用 Release 操作标记“数据就绪”,消费者用 Acquire 操作读取标记并获取数据)。
性能优化:
- 在无需严格顺序的场景(如计数器、统计指标),使用
memory_order_relaxed减少内存屏障(Memory Barrier)的开销(内存屏障会阻止指令重排,且可能触发缓存同步,是性能瓶颈之一)。
- 在无需严格顺序的场景(如计数器、统计指标),使用
6. 常见误区与注意事项
“原子操作一定线程安全”?
仅当所有线程都通过原子操作访问共享数据时才安全。若一个线程用原子操作,另一个线程用普通操作(如std::atomic<int> x; x = 1;(原子)和int y = x;(普通读,非原子)),仍会发生数据竞争(UB)。滥用 memory_order_seq_cst
seq_cst是最安全的内存序,但性能最差(可能插入全局内存屏障)。在明确无需全局顺序的场景(如生产者-消费者),应使用 acquire-release 以提升性能。忽略指令重排的隐蔽性
即使代码顺序清晰,编译器/CPU 仍可能重排指令。例如:// 错误示例:无同步,存在数据竞争 bool ready = false; int data = 0; void producer() { data = 42; // 可能被重排到 ready = true 之后 ready = true; } void consumer() { while (!ready); // 可能读取到 ready=true,但 data=0(重排导致) assert(data == 42); // 可能失败(UB) }修复方案:将
ready改为std::atomic<bool>,并使用 release-acquire 语义。
7.总结
C++ 内存模型的核心是“在允许优化的前提下,通过原子操作和内存序,定义多线程内存访问的规则,避免数据竞争并保证可见性和有序性”。其关键要点可归纳为:
- 单线程语义优先:优化不能破坏单线程执行结果。
- 原子操作是基础:避免数据竞争,提供不可分割的操作。
- 内存序是调控工具:通过不同内存序平衡正确性和性能,核心是 release-acquire 语义。
- 同步关系是桥梁:通过 Synchronizes-With 建立线程间的可见性保证,确保修改能被正确观察到。
理解 C++ 内存模型是编写高效、正确的多线程代码的前提,尤其在无锁编程和高性能并发场景中,其重要性更为突出。
什么是条件竞争(数据竞争)
线程安全问题的根源是 “同一内存区域的共享访问”,分离内存区域无共享,自然无安全风险。
C++ 标准明确规定:当且仅当满足以下四个条件时,即发生数据竞争:
- 两个或多个线程访问同一内存区域;
- 至少有一个线程的访问是非原子化操作(即普通变量的读写,如int a = 5、b++);
- 至少有一个线程的访问是写操作(改变内存区域的值);
- 没有任何同步措施(如互斥锁、原子操作)强制这些访问的 “先后次序”。
关键排除项:若所有访问都是 “原子操作”(如std::atomic的读写),即使无额外同步,也不构成数据竞争(原子操作本身隐含 “访问次序的控制”)。
在这里还要提及改动序列这个概念,改动序列是一种描述 “同一对象的所有写操作” 的抽象模型,核心是 “确保所有线程对‘写操作的先后次序’达成一致”。
对于 C++ 程序中的每一个对象(无论是普通变量、原子变量还是类实例),其 “改动序列” 是指:该对象在一次程序运行中,所有线程对它执行的 “写操作” 按时间顺序构成的序列,其中第一个写操作是 “对象的初始化”(如int a = 0中,=0是第一个写操作)。关键特性:
- 动态性:改动序列会随程序运行变化(如不同线程调度顺序会导致写操作次序不同);
- 一致性:在同一次程序运行中,所有线程必须 “看到相同的改动序列”—— 即对于 “线程 A 写对象 X” 和 “线程 B 写对象 X” 这两个操作,所有线程都认同 “A 先于 B” 或 “B 先于 A”,不能出现 “线程 C 认为 A 先于 B,线程 D 认为 B 先于 A” 的情况。
若多个线程对同一对象的 “改动序列认知不一致”,则必然出现数据竞争和未定义行为
改动序列的两条底层约束:
- 线程内的 “读写一致性”:若线程 T 先写对象 X,之后再读 X,则 T 必须读到 “自己写的最新值”(除非中间有其他线程的写操作被 T 观察到);例如:线程 T 写a=1,再写a=2,之后读a,必须读到 2(不能读到 1)。
- 禁止 “预测执行” 的干扰:为了保证改动序列的一致性,编译器和硬件需禁止某些 “预测执行” 优化(如 CPU 提前执行尚未确定是否需要的写操作)—— 否则可能导致 “线程看到的改动序列与实际执行次序不符”。
改动序和内存序的区别在于改动序列是描述 “单个原子对象的所有修改操作的全局唯一顺序”,是 C++ 标准为原子对象内置的 “修改历史记录”;内存序是描述 “不同原子操作之间的同步约束”,是程序员用来控制 “可见性” 和 “有序性” 的工具,依赖改动序列实现多线程同步。
数据竞争会导致未定义行为,这是 C++ 中最危险的情况之一。两种从根源上规避数据竞争的方法,方法 1:用互斥锁控制访问,方法 2:用原子操作控制访问
锁和原子操作的诞生
原子操作是不可分割的操作(indivisible operation)。在系统的任一线程内,我们都不会观察到这种操作处于半完成状态;它或者完全做好,或者完全没做。考虑读取某对象的过程,假如其内存加载行为属于原子操作,并且该对象的全部修改行为也都是原子操作,那么通过内存加载行为就可以得到该对象的初始值,或得到某次修改而完整存入的值。 与之相反,非原子操作(non-atomic operation)在完成到一半的时候,有可能为另一线程所见。
锁和原子操作的核心设计目标,都是解决多线程并发场景下的 “条件竞争(Race Condition)” 问题,二者的目标完全一致(解决条件竞争),但解决的 “粒度” 和 “层面” 不同 —— 原子操作解决 “单个变量的读 - 改 - 写” 竞争,锁解决 “一段代码(临界区)的多步操作” 竞争。
原子操作(如 CPU 提供的CAS、原子自增指令)的核心是:将 “读 - 改 - 写” 这类多步操作,通过硬件指令封装成 “不可打断的单个操作”——CPU 在执行原子指令时,会禁止线程切换或总线抢占,确保操作要么完整执行,要么完全不执行,从硬件层面直接消除条件竞争。
原子操作的局限是 “仅能处理单个变量的简单操作”;当需要保护 “多步操作、多个共享变量”(如 “先判断队列非空,再弹出队列元素”)时,原子操作无法覆盖,此时需要锁(如std::mutex)。
锁的核心逻辑是:通过 “互斥访问” 确保 “只有一个线程能进入临界区(被锁保护的代码段)”—— 即使临界区包含多步操作,也会被视为一个 “逻辑上不可分割的整体”,其他线程会被阻塞在锁外,直到持有锁的线程退出临界区并释放锁。
锁的实现必须依赖原子操作(否则无法安全解决 “锁标记竞争”),原子操作是锁的底层基石,原子操作可独立用于简单并发原子操作是 CPU 硬件指令,锁是软件层面的复合工具,二者是 “基础” 与 “应用” 的关系场景(如计数器、状态标记),无需搭配锁,锁则是原子操作的上层扩展,用于复杂临界区的互斥控制。
锁的种类
以概念进行分类
| 分类维度 | 锁类型 | 核心逻辑 | 适用场景 | 典型实现示例 | 特点总结 |
|---|---|---|---|---|---|
| 按竞争范围 | 线程锁 | 保护同一进程内线程间的共享资源 | 进程内多线程共享数据(如全局变量、堆内存) | Java: synchronized、ReentrantLock;C++: std::mutex |
基于线程ID/轻量级结构,开销小、速度快 |
| 进程锁 | 保护不同进程间的共享资源 | 跨进程共享资源(如共享内存、磁盘文件、打印机) | Linux: fcntl(文件锁)、semget(信号量);Windows: Mutex |
依赖内核/共享存储实现可见性,开销比线程锁大 | |
| 按排他性 | 互斥锁(排他锁) | 同一时间仅允许一个执行单元持有锁,其他请求阻塞 | 写操作或读写混合操作(如修改数据库记录、更新全局计数器) | Java: synchronized、ReentrantLock;MySQL InnoDB: for update |
完全排他,读请求也阻塞,安全性高但并发读效率低 |
| 共享锁(读锁) | 允许多个执行单元同时持有读锁,写操作阻塞(读-读不冲突,读-写冲突) | 读多写少场景(如查询数据库表、读取配置文件) | Java: ReentrantReadWriteLock.ReadLock;MySQL InnoDB: lock in share mode |
读操作可并发,写需等读锁释放,平衡并发效率与安全性 | |
| 按可重入性 | 可重入锁 | 同一执行单元可重复获取同一把锁,记录持有次数,释放需对应次数 | 递归函数、嵌套加锁场景(避免同一线程重复加锁死锁) | Java: synchronized、ReentrantLock;Linux: pthread_mutex_t(默认) |
避免递归死锁,逻辑灵活,需注意释放次数 |
| 不可重入锁 | 同一执行单元持有锁后,再次请求会被自身阻塞,导致死锁 | 逻辑简单、无递归/重复加锁场景 | 早期Linux: spinlock_t;自定义标志位互斥锁 |
实现简单、开销略低,易因逻辑疏忽死锁,实际开发少用 | |
| 按实现方式 | 自旋锁 | 锁被占用时,请求线程循环检查锁状态(忙等),不挂起 | 锁持有时间极短、CPU核心充足场景(如简单变量赋值) | Linux内核: spinlock_t;Java Unsafe类: compareAndSwapInt(CAS底层) |
无上下文切换开销,响应快;自旋占CPU,锁持有久则浪费资源 |
| 阻塞锁 | 锁被占用时,请求线程被挂起(运行态→阻塞态),锁释放后唤醒 | 锁持有时间较长场景(如数据库事务、IO操作) | Java: synchronized、ReentrantLock;数据库行级锁 |
不忙等、省CPU;线程挂起/唤醒需上下文切换,开销大、响应慢 | |
| 其他特殊锁 | 读写锁 | 共享锁+互斥锁组合:读用共享锁,写用排他锁,写时阻塞所有读/写 | 读多写少场景(优化读写并发效率) | Java: ReentrantReadWriteLock;C++: std::shared_mutex |
针对性优化读多写少场景,兼顾读并发与写安全 |
| 乐观锁 | 不主动加锁,假设冲突概率低,操作后通过版本号/CAS判断冲突,冲突则重试 | 并发冲突少、读多写少场景(如电商库存扣减、缓存更新) | 数据库版本号机制;Java: AtomicInteger(CAS实现) |
无锁竞争开销,并发效率高;冲突频繁时重试开销大 | |
| 悲观锁 | 假设冲突概率高,操作前主动加锁,确保资源独占至释放 | 并发冲突多、写操作频繁场景(如金融交易、订单状态更新) | Java: synchronized、ReentrantLock;MySQL: for update |
安全性高、避免冲突;锁竞争导致线程阻塞,并发效率低 | |
| 分布式锁 | 分布式系统中,借助分布式存储(如Redis/ZooKeeper)实现全局锁可见性 | 多节点共享资源同步(如多服务器操作同一数据库记录、分布式缓存更新) | Redis: SET NX EX命令;ZooKeeper: 临时顺序节点;数据库唯一索引锁 |
需解决锁超时、脑裂、重入性问题,实现比单机锁复杂 |
C++中的锁
| 类别 | 组件名称 | 所属头文件 | 引入版本 | 功能说明 |
|---|---|---|---|---|
| 基础互斥锁类型 | mutex |
<mutex> |
C++11 | 提供最基本的互斥功能,实现排他性锁定(同一时间仅一个线程可持有) |
timed_mutex |
<mutex> |
C++11 | 带超时功能的互斥锁,支持在指定时间内尝试获取锁,超时后不阻塞 | |
recursive_mutex |
<mutex> |
C++11 | 可重入互斥锁,允许同一线程多次锁定(需对应次数解锁),避免递归场景死锁 | |
recursive_timed_mutex |
<mutex> |
C++11 | 带超时功能的可重入互斥锁,结合recursive_mutex和timed_mutex特性 |
|
shared_mutex |
<shared_mutex> |
C++17 | 共享互斥锁(读写锁),支持共享锁(多线程读)和排他锁(单线程写) | |
shared_timed_mutex |
<shared_mutex> |
C++14 | 带超时功能的共享互斥锁,支持超时获取共享锁或排他锁 | |
| 互斥锁管理工具 | lock_guard |
<mutex> |
C++11 | 基于作用域的RAII锁包装器,构造时加锁,析构时解锁,不可手动控制 |
scoped_lock |
<mutex> |
C++17 | 多锁管理的RAII包装器,自动按安全顺序加锁,避免死锁 | |
unique_lock |
<mutex> |
C++11 | 可移动的灵活锁包装器,支持手动加锁/解锁、超时等待、延迟加锁等操作 | |
shared_lock |
<mutex> |
C++14 | 配合shared_mutex使用的共享锁包装器,用于获取共享锁(多线程读场景) |
|
| 锁定策略标签 | defer_lock |
<mutex> |
C++11 | 标签:构造锁时延迟加锁,需后续手动调用lock() |
try_to_lock |
<mutex> |
C++11 | 标签:构造时尝试加锁,失败不阻塞,需通过owns_lock()判断结果 |
|
adopt_lock |
<mutex> |
C++11 | 标签:接管已有锁,假设当前线程已持有锁,避免重复加锁 | |
| 通用锁定算法 | try_lock |
<mutex> |
C++11 | 函数模板:尝试获取多个锁,失败则释放已获取的锁,返回失败锁索引(非阻塞) |
lock |
<mutex> |
C++11 | 函数模板:按安全顺序锁定多个锁,阻塞直到所有锁获取成功,避免死锁 | |
| 单次初始化工具 | once_flag |
<mutex> |
C++11 | 辅助类:与call_once配合,标记函数是否已执行 |
call_once |
<mutex> |
C++11 | 函数模板:确保传入的函数仅执行一次,多线程环境下保证唯一性 |
- 若为RAII 智能锁(如std::lock_guard、std::unique_lock):只要构造时成功加锁(或后续持有了锁),析构时必然解锁,这是其核心特性;
- 若为原始锁 / 非 RAII 锁(如std::mutex、pthread_mutex_t):构造仅初始化锁状态,加锁 / 解锁需完全手动控制,析构时不涉及解锁操作,需开发者自行保证 “加锁 - 解锁” 的配对。
- 当锁的设计目的是 “允许所有权转移”(无论是为了灵活手动控制锁生命周期,还是为了管理共享锁的独立所有权)时,通常支持移动语义;当锁的设计目的是 “绑定作用域、简化管理”(无需转移所有权)时,通常不支持移动语义。
C++中的原子操作
| 类别 | 名称 | 说明 | 引入版本 |
|---|---|---|---|
| 核心概念 | 原子操作 | 提供细粒度的不可分割操作,支持无锁并发编程,避免数据竞争 | - |
| 原子类型 | std::atomic |
类模板,针对bool、整型、浮点型(C++20起)和指针类型有特化 | C++11 |
std::atomic_ref |
类模板,对非原子对象提供原子操作 | C++20 | |
| 原子类型操作 | atomic_is_lock_free |
检查原子类型的操作是否无锁 | C++11 |
atomic_storeatomic_store_explicit |
原子地将原子对象的值替换为非原子参数 | C++11 | |
atomic_loadatomic_load_explicit |
原子地获取原子对象中存储的值 | C++11 | |
atomic_exchangeatomic_exchange_explicit |
原子地替换值并返回旧值 | C++11 | |
atomic_compare_exchange_weakatomic_compare_exchange_weak_explicitatomic_compare_exchange_strongatomic_compare_exchange_strong_explicit |
比较并交换操作,相等则交换,否则加载当前值 | C++11 | |
atomic_fetch_addatomic_fetch_add_explicit |
原子加法,返回旧值 | C++11 | |
atomic_fetch_subatomic_fetch_sub_explicit |
原子减法,返回旧值 | C++11 | |
atomic_fetch_andatomic_fetch_and_explicit |
原子位AND运算,返回旧值 | C++11 | |
atomic_fetch_oratomic_fetch_or_explicit |
原子位OR运算,返回旧值 | C++11 | |
atomic_fetch_xoratomic_fetch_xor_explicit |
原子位XOR运算,返回旧值 | C++11 | |
atomic_fetch_maxatomic_fetch_max_explicit |
原子取最大值,返回旧值 | C++26 | |
atomic_fetch_minatomic_fetch_min_explicit |
原子取最小值,返回旧值 | C++26 | |
atomic_waitatomic_wait_explicit |
阻塞线程直到被通知且原子值改变 | C++20 | |
atomic_notify_one |
通知一个在atomic_wait中阻塞的线程 |
C++20 | |
atomic_notify_all |
通知所有在atomic_wait中阻塞的线程 |
C++20 | |
| 标志类型和操作 | std::atomic_flag |
无锁布尔原子类型 | C++11 |
atomic_flag_test_and_setatomic_flag_test_and_set_explicit |
原子地将标志设为true并返回旧值 | C++11 | |
atomic_flag_clearatomic_flag_clear_explicit |
原子地将标志设为false | C++11 | |
atomic_flag_testatomic_flag_test_explicit |
原子地返回标志的值 | C++20 | |
atomic_flag_waitatomic_flag_wait_explicit |
阻塞线程直到被通知且标志改变 | C++20 | |
atomic_flag_notify_one |
通知一个在atomic_flag_wait中阻塞的线程 |
C++20 | |
atomic_flag_notify_all |
通知所有在atomic_flag_wait中阻塞的线程 |
C++20 | |
| 初始化 | atomic_init |
默认构造的原子对象的非原子初始化(C++20弃用) | C++11 |
ATOMIC_VAR_INIT |
静态存储原子变量的常量初始化(C++20弃用) | C++11 | |
ATOMIC_FLAG_INIT |
将std::atomic_flag初始化为false |
C++11 | |
| 内存同步顺序 | std::memory_order |
定义原子操作的内存排序约束 | C++11 |
kill_dependency |
从依赖树中移除对象(C++26弃用) | C++11 | |
atomic_thread_fence |
通用内存排序屏障同步原语 | C++11 | |
atomic_signal_fence |
线程与自身信号处理程序间的屏障 | C++11 | |
| C兼容性(C++23起) | _Atomic |
宏,使_Atomic(T)等同于std::atomic<T> |
C++23 |
补充说明:
- 所有原子操作定义于头文件
<atomic>,C兼容性宏在<stdatomic.h>中 - 带
_explicit后缀的函数允许显式指定内存顺序(std::memory_order),不带后缀的使用默认顺序 atomic_flag是唯一保证无锁的原子类型,其他atomic类型可能依赖平台实现- 内存同步顺序(
memory_order)控制原子操作的可见性和顺序性,是并发编程正确性的关键 - C++20及后续版本对原子操作进行了扩展,增加了等待/通知机制和更多操作类型
这些原子操作组件为C++并发编程提供了底层支持,可用于实现高效的无锁数据结构和线程同步机制。
锁的原理
锁的核心原理是借助操作系统 / 硬件提供的 “原子操作” 和 “线程调度机制”,在多线程环境中实现对共享资源的 “互斥访问控制”—— 本质是通过底层机制确保 “只有一个线程能成功获取锁标记”,未获取到标记的线程则被系统挂起(阻塞),直到锁被释放后再重新竞争。
锁的本质是一个 “共享的锁标记”(比如一个内存中的整数,0表示未锁定,1表示已锁定)。但多线程同时尝试修改这个标记时,会出现 “竞争条件”(比如两个线程同时看到0,都试图改成1,导致 “锁被同时获取” 的错误)。
而CPU 提供的原子操作(Atomic Operation)能解决这个问题 —— 原子操作是 “不可中断的操作”,要么完全执行,要么完全不执行,中间不会被其他线程打断。常见的原子操作包括 “原子比较并交换(CAS)”“原子自增 / 自减” 等,是实现锁的底层基石。
锁的 “获取” 本质是 “线程对锁状态的修改”(例如:将 “未锁定” 状态改为 “已锁定”)。如果这个修改操作不是原子的,就会出现 “线程 A 判断锁为未锁定,但还没来得及修改,线程 B 也判断锁为未锁定,最终两者同时拿到锁” 的致命漏洞。
而 CAS 是硬件级原子操作(CPU 通过cmpxchg等指令直接实现,不依赖操作系统调度),能确保 “比较锁状态” 和 “修改锁状态” 这两步操作的原子性 —— 这是锁实现的 “安全底线”。
多线程并发中,每个线程都有自己的 CPU 缓存(L1/L2/L3),如果锁状态仅存在于某个线程的缓存中,其他线程无法感知,会导致 “锁状态不可见”(例如:线程 A 已释放锁,但线程 B 的缓存中锁状态仍为 “已锁定”,导致 B 一直等待)。
CAS 操作在硬件层面会触发 “缓存一致性协议”(如 MESI 协议):当线程通过 CAS 修改内存中的锁状态时,会强制将修改后的新值 “刷新到主内存”,并使其他线程缓存中的旧锁状态 “失效”—— 其他线程下次读取锁状态时,会从主内存重新加载最新值,从而保证了锁状态在多线程间的 “可见性”。
锁本身不会 “主动控制数据访问”—— 锁只是一个 “互斥标记”,它能实现 “只有持有锁的线程访问数据”,本质是开发者遵守了一个核心约定:
- 所有访问 “受保护共享数据” 的线程,都必须先调用lock()获取锁,访问完成后调用unlock()释放锁。
如果有线程 “绕过锁” 直接访问数据(比如之前提到的 “泄露数据指针到锁作用域外”),即使锁存在,也会导致并发安全问题。锁的作用是 “提供互斥机制”,而 “将数据访问与锁绑定” 是开发者的责任。
虽然核心都是“原子操作+线程调度”,但不同锁类型的逻辑侧重不同,适应不同场景:
| 锁类型 | 核心原理 | 适用场景 |
|---|---|---|
| 自旋锁(SpinLock) | 仅基于原子CAS操作,获取不到锁时自旋(不阻塞) | 锁持有时间极短(如微秒级) |
| 互斥锁(std::mutex) | 结合原子操作+操作系统阻塞/唤醒,获取不到锁时阻塞(放弃CPU) | 锁持有时间较长(如毫秒级) |
| 共享锁(std::shared_mutex) | 区分“读锁”和“写锁”:读锁可多线程共享(原子计数),写锁独占(互斥) | 读多写少场景(如缓存、配置) |
| 递归锁(std::recursive_mutex) | 内部维护“持有线程ID”和“递归计数”,同一线程可多次lock(计数+1) | 递归函数中需要加锁的场景 |
锁的使用
锁的使用有下面这几点需要注意的地方:
- 不得向锁的作用域之外传递 “指向受保护共享数据的指针 / 引用”,具体包含三种禁止场景:
- 不通过 “函数返回值” 传递指针 / 引用(比如成员函数不能返回&data);
- 不将指针 / 引用保存到 “对外可见的内存”(比如全局变量、静态变量、类的公有成员);
- 不将指针 / 引用作为参数,传递给 “使用者提供的外部函数”(比如回调函数、第三方函数)—— 因为这些函数的逻辑不可控,可能泄露数据。
这本质上是由锁的工作原理和并发安全的核心要求共同决定的 —— 即确保 “受保护的共享数据” 始终处于锁的控制范围内,避免出现 “数据脱离锁保护” 的情况(即无锁状态下的并发访问)。锁的核心作用是通过 “互斥” 保证共享数据的访问原子性:只有持有锁的线程才能读写数据,其他线程必须等待锁释放。但如果出现 “指向受保护数据的指针 / 引用泄露到锁的作用域之外”,就会导致其他线程可能在不持有锁的情况下访问该数据,从而破坏锁的互斥性,引发数据竞争(Data Race)。
锁管理器的使用
下面是C++锁管理器的源码:
lock_guard:
_EXPORT_STD template <class _Mutex>
class _NODISCARD_LOCK lock_guard { // class with destructor that unlocks a mutex
public:
using mutex_type = _Mutex;
explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) { // construct and lock
_MyMutex.lock();
}
lock_guard(_Mutex& _Mtx, adopt_lock_t) noexcept // strengthened
: _MyMutex(_Mtx) {} // construct but don't lock
~lock_guard() noexcept {
_MyMutex.unlock();
}
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
_Mutex& _MyMutex;
};
scoped_lock:
template <class _Mutex>
class _NODISCARD_LOCK scoped_lock<_Mutex> {
public:
using mutex_type = _Mutex;
explicit scoped_lock(_Mutex& _Mtx) : _MyMutex(_Mtx) { // construct and lock
_MyMutex.lock();
}
explicit scoped_lock(adopt_lock_t, _Mutex& _Mtx) noexcept // strengthened
: _MyMutex(_Mtx) {} // construct but don't lock
~scoped_lock() noexcept {
_MyMutex.unlock();
}
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
private:
_Mutex& _MyMutex;
};
unique_lock:
_EXPORT_STD template <class _Mutex>
class unique_lock { // whizzy class with destructor that unlocks mutex
public:
using mutex_type = _Mutex;
unique_lock() noexcept = default;
_NODISCARD_CTOR_LOCK explicit unique_lock(_Mutex& _Mtx)
: _Pmtx(_STD addressof(_Mtx)), _Owns(false) { // construct and lock
_Pmtx->lock();
_Owns = true;
}
_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, adopt_lock_t) noexcept // strengthened
: _Pmtx(_STD addressof(_Mtx)), _Owns(true) {} // construct and assume already locked
unique_lock(_Mutex& _Mtx, defer_lock_t) noexcept
: _Pmtx(_STD addressof(_Mtx)), _Owns(false) {} // construct but don't lock
_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, try_to_lock_t)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock()) {} // construct and try to lock
template <class _Rep, class _Period>
_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, const chrono::duration<_Rep, _Period>& _Rel_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_for(_Rel_time)) {} // construct and lock with timeout
template <class _Clock, class _Duration>
_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, const chrono::time_point<_Clock, _Duration>& _Abs_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_until(_Abs_time)) {
// construct and lock with timeout
#if _HAS_CXX20
static_assert(chrono::is_clock_v<_Clock>, "Clock type required");
#endif // _HAS_CXX20
}
_NODISCARD_CTOR_LOCK unique_lock(unique_lock&& _Other) noexcept : _Pmtx(_Other._Pmtx), _Owns(_Other._Owns) {
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
unique_lock& operator=(unique_lock&& _Other) noexcept /* strengthened */ {
if (this != _STD addressof(_Other)) {
if (_Owns) {
_Pmtx->unlock();
}
_Pmtx = _Other._Pmtx;
_Owns = _Other._Owns;
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
return *this;
}
~unique_lock() noexcept {
if (_Owns) {
_Pmtx->unlock();
}
}
unique_lock(const unique_lock&) = delete;
unique_lock& operator=(const unique_lock&) = delete;
void lock() { // lock the mutex
_Validate();
_Pmtx->lock();
_Owns = true;
}
_NODISCARD_TRY_CHANGE_STATE bool try_lock() {
_Validate();
_Owns = _Pmtx->try_lock();
return _Owns;
}
template <class _Rep, class _Period>
_NODISCARD_TRY_CHANGE_STATE bool try_lock_for(const chrono::duration<_Rep, _Period>& _Rel_time) {
_Validate();
_Owns = _Pmtx->try_lock_for(_Rel_time);
return _Owns;
}
template <class _Clock, class _Duration>
_NODISCARD_TRY_CHANGE_STATE bool try_lock_until(const chrono::time_point<_Clock, _Duration>& _Abs_time) {
#if _HAS_CXX20
static_assert(chrono::is_clock_v<_Clock>, "Clock type required");
#endif // _HAS_CXX20
_Validate();
_Owns = _Pmtx->try_lock_until(_Abs_time);
return _Owns;
}
void unlock() {
if (!_Pmtx || !_Owns) {
_Throw_system_error(errc::operation_not_permitted);
}
_Pmtx->unlock();
_Owns = false;
}
void swap(unique_lock& _Other) noexcept {
_STD swap(_Pmtx, _Other._Pmtx);
_STD swap(_Owns, _Other._Owns);
}
_Mutex* release() noexcept {
_Mutex* _Res = _Pmtx;
_Pmtx = nullptr;
_Owns = false;
return _Res;
}
_NODISCARD bool owns_lock() const noexcept {
return _Owns;
}
explicit operator bool() const noexcept {
return _Owns;
}
_NODISCARD _Mutex* mutex() const noexcept {
return _Pmtx;
}
private:
_Mutex* _Pmtx = nullptr;
bool _Owns = false;
void _Validate() const { // check if the mutex can be locked
if (!_Pmtx) {
_Throw_system_error(errc::operation_not_permitted);
}
if (_Owns) {
_Throw_system_error(errc::resource_deadlock_would_occur);
}
}
};
shared_lock:
_EXPORT_STD template <class _Mutex>
class shared_lock { // shareable lock
public:
using mutex_type = _Mutex;
shared_lock() noexcept = default;
_NODISCARD_CTOR_LOCK explicit shared_lock(mutex_type& _Mtx)
: _Pmtx(_STD addressof(_Mtx)), _Owns(true) { // construct with mutex and lock shared
_Mtx.lock_shared();
}
shared_lock(mutex_type& _Mtx, defer_lock_t) noexcept
: _Pmtx(_STD addressof(_Mtx)), _Owns(false) {} // construct with unlocked mutex
_NODISCARD_CTOR_LOCK shared_lock(mutex_type& _Mtx, try_to_lock_t)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared()) {} // construct with mutex and try to lock shared
_NODISCARD_CTOR_LOCK shared_lock(mutex_type& _Mtx, adopt_lock_t) noexcept // strengthened
: _Pmtx(_STD addressof(_Mtx)), _Owns(true) {} // construct with mutex and adopt ownership
template <class _Rep, class _Period>
_NODISCARD_CTOR_LOCK shared_lock(mutex_type& _Mtx, const chrono::duration<_Rep, _Period>& _Rel_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared_for(_Rel_time)) {
// construct with mutex and try to lock for relative time
}
template <class _Clock, class _Duration>
_NODISCARD_CTOR_LOCK shared_lock(mutex_type& _Mtx, const chrono::time_point<_Clock, _Duration>& _Abs_time)
: _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared_until(_Abs_time)) {
// construct with mutex and try to lock until absolute time
#if _HAS_CXX20
static_assert(chrono::is_clock_v<_Clock>, "Clock type required");
#endif // _HAS_CXX20
}
~shared_lock() noexcept {
if (_Owns) {
_Pmtx->unlock_shared();
}
}
_NODISCARD_CTOR_LOCK shared_lock(shared_lock&& _Other) noexcept : _Pmtx(_Other._Pmtx), _Owns(_Other._Owns) {
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
shared_lock& operator=(shared_lock&& _Right) noexcept {
if (_Owns) {
_Pmtx->unlock_shared();
}
_Pmtx = _Right._Pmtx;
_Owns = _Right._Owns;
_Right._Pmtx = nullptr;
_Right._Owns = false;
return *this;
}
shared_lock(const shared_lock&) = delete;
shared_lock& operator=(const shared_lock&) = delete;
void lock() { // lock the mutex
_Validate();
_Pmtx->lock_shared();
_Owns = true;
}
_NODISCARD_TRY_CHANGE_STATE bool try_lock() { // try to lock the mutex
_Validate();
_Owns = _Pmtx->try_lock_shared();
return _Owns;
}
template <class _Rep, class _Period>
_NODISCARD_TRY_CHANGE_STATE bool try_lock_for(const chrono::duration<_Rep, _Period>& _Rel_time) {
// try to lock the mutex for _Rel_time
_Validate();
_Owns = _Pmtx->try_lock_shared_for(_Rel_time);
return _Owns;
}
template <class _Clock, class _Duration>
_NODISCARD_TRY_CHANGE_STATE bool try_lock_until(const chrono::time_point<_Clock, _Duration>& _Abs_time) {
// try to lock the mutex until _Abs_time
#if _HAS_CXX20
static_assert(chrono::is_clock_v<_Clock>, "Clock type required");
#endif // _HAS_CXX20
_Validate();
_Owns = _Pmtx->try_lock_shared_until(_Abs_time);
return _Owns;
}
void unlock() { // try to unlock the mutex
if (!_Pmtx || !_Owns) {
_Throw_system_error(errc::operation_not_permitted);
}
_Pmtx->unlock_shared();
_Owns = false;
}
void swap(shared_lock& _Right) noexcept {
_STD swap(_Pmtx, _Right._Pmtx);
_STD swap(_Owns, _Right._Owns);
}
mutex_type* release() noexcept {
_Mutex* _Res = _Pmtx;
_Pmtx = nullptr;
_Owns = false;
return _Res;
}
_NODISCARD bool owns_lock() const noexcept {
return _Owns;
}
explicit operator bool() const noexcept {
return _Owns;
}
_NODISCARD mutex_type* mutex() const noexcept {
return _Pmtx;
}
private:
_Mutex* _Pmtx = nullptr;
bool _Owns = false;
void _Validate() const { // check if the mutex can be locked
if (!_Pmtx) {
_Throw_system_error(errc::operation_not_permitted);
}
if (_Owns) {
_Throw_system_error(errc::resource_deadlock_would_occur);
}
}
};
| 操作类型 | lock_guard |
scoped_lock |
unique_lock |
shared_lock |
|---|---|---|---|---|
| 构造方式 | 1. 接收_Mutex&:自动调用lock()加锁2. 接收 _Mutex& + adopt_lock_t:复用已加锁的mutex(不自动加锁) |
1. 接收_Mutex&:自动调用lock()加锁2. 接收 _Mutex& + adopt_lock_t:复用已加锁的mutex3. 可变参数版(标准特性):接收多个mutex,自动按安全顺序加锁(避免死锁) |
1. 默认构造(无关联mutex) 2. _Mutex&:自动加锁3. _Mutex& + adopt_lock_t:复用已加锁4. _Mutex& + defer_lock_t:延迟加锁(不自动加锁)5. _Mutex& + try_to_lock_t:尝试加锁(返回是否成功)6. 带超时: try_lock_for/try_lock_until(相对/绝对时间) |
1. 默认构造(无关联mutex) 2. _Mutex&:自动调用lock_shared()加共享锁3. _Mutex& + adopt_lock_t:复用已加的共享锁4. _Mutex& + defer_lock_t:延迟加锁5. _Mutex& + try_to_lock_t:尝试加共享锁6. 带超时: try_lock_for/try_lock_until(共享锁超时) |
| 加锁操作 | 仅构造时自动加锁(无手动加锁接口) | 仅构造时自动加锁(无手动加锁接口,多mutex版自动按顺序加锁) | 1. lock():手动独占加锁2. try_lock():手动尝试独占加锁3. try_lock_for()/try_lock_until():超时尝试独占加锁 |
1. lock():手动加共享锁(内部调用lock_shared())2. try_lock():手动尝试共享锁3. try_lock_for()/try_lock_until():超时尝试共享锁 |
| 解锁操作 | 仅析构时自动解锁(无手动解锁接口) | 仅析构时自动解锁(无手动解锁接口) | 1. unlock():手动独占解锁2. 析构时自动解锁(仅当 owns_lock()为true) |
1. unlock():手动共享解锁(内部调用unlock_shared())2. 析构时自动解锁(仅当 owns_lock()为true) |
| 所有权转移 | 不可复制、不可移动 | 不可复制、不可移动 | 可移动(支持移动构造/移动赋值)、不可复制 | 可移动(支持移动构造/移动赋值)、不可复制 |
| 辅助操作 | 无(极简设计) | 无(极简设计,多mutex场景自动处理顺序) | 1. swap():交换两个unique_lock的关联mutex和持有状态2. release():解除与mutex的关联(返回mutex指针,不解锁)3. owns_lock():判断是否持有锁4. mutex():返回关联的mutex指针 |
1. swap():交换两个shared_lock的关联mutex和持有状态2. release():解除与mutex的关联(不解锁)3. owns_lock():判断是否持有共享锁4. mutex():返回关联的mutex指针 |
| 适用Mutex类型 | 仅支持独占互斥体(如std::mutex、std::recursive_mutex) |
仅支持独占互斥体(多参数版支持多个独占互斥体) | 仅支持独占互斥体(如std::mutex、std::recursive_mutex) |
仅支持共享互斥体(如std::shared_mutex、std::shared_timed_mutex) |
从上我们能够看出,锁管理器核心作用是 “帮你管理 mutex 的生命周期”(比如析构时自动解锁,避免漏解锁),所谓的所有权转移转移的是这个管理生命周期的权力,锁的底层根本原则:最终解锁 mutex 的线程,必须和当初加锁 mutex 的线程是同一个并没有改变,因此跨线程转移不是为了 “抢原线程的锁”,而是为了让 “加锁” 和 “解锁” 匹配到 “最该执行它们的线程”,例如线程 A “延迟加锁”,线程 B 负责 “加锁 + 解锁”(最常见),线程 A 不需要直接操作共享资源,只是负责 “启动任务”,但需要确保任务执行时锁是安全的。此时线程 A 可以创建一个未加锁的 unique_lock,转移给线程 B,由线程 B 完成加锁和解锁
死锁
死锁的本质是 “多个线程互相持有对方需要的资源(互斥锁),且都不愿释放,导致永久等待”,通常发生在 “线程需同时锁定多个互斥锁” 的场景中。
死锁处理
死锁是多线程/进程并发场景中,多个线程因互相等待对方持有的资源而永久阻塞的状态。处理死锁的机制可分为预防(避免发生)、避免(动态规避)、检测(发现已发生)、解除(恢复正常) 四大核心策略,每种策略的设计思路、适用场景和实现成本差异显著。以下从“策略定义、核心原理、实现方式、优缺点”四个维度详细解析:
一、死锁预防(Deadlock Prevention):从根源杜绝条件(资源申请前)
死锁的发生需满足四个必要条件(缺一不可):1. 资源互斥(资源只能被一个线程占用);2. 持有并等待(线程持有部分资源,同时等待其他资源);3. 不可剥夺(线程已持有的资源不能被强制收回);4. 循环等待(多个线程形成资源等待闭环)。
预防策略的核心:通过破坏上述四个必要条件中的任意一个,从根源上阻止死锁发生。
1. 破坏“资源互斥”条件
- 原理:允许多个线程同时访问资源(即取消资源的“互斥性”),消除死锁的第一个前提。
- 实现方式:
- 仅适用于“可共享使用”的资源(如只读文件、共享缓存)——例如,多个线程同时读取同一个配置文件,无需互斥锁定。
- 对“不可共享”的资源(如打印机、独占数据库连接)无效,因为这类资源必须互斥访问(否则会导致数据错乱)。
- 优缺点:
- 优点:实现简单,无额外开销;
- 缺点:适用范围极窄,仅支持只读/可共享资源,无法解决多数场景(如写操作、独占资源)的死锁问题。
2. 破坏“持有并等待”条件
- 原理:要求线程在开始执行前,一次性申请所有需要的资源;若无法获取全部资源,则不持有任何资源,直接阻塞等待。
- 实现方式:
- 线程启动时,提前声明所需的所有资源(如“线程A需资源1和资源2”),由资源管理器统一检查:若所有资源均空闲,则一次性分配;否则线程进入等待队列,直到所有资源可用。
- 典型案例:早期批处理系统中,作业提交时需声明所有所需硬件资源(如CPU、内存、外设),系统分配全部资源后才开始执行。
- 优缺点:
- 优点:彻底杜绝“持有部分资源等待其他资源”的场景,逻辑简单;
- 缺点:1. 资源利用率极低(线程可能提前申请很久后才使用的资源,导致资源长期闲置);2. 线程启动前需预知所有资源,灵活性差(如动态生成的资源无法提前声明)。
3. 破坏“不可剥夺”条件
- 原理:允许系统在特定条件下,强制收回线程已持有的资源(类似“抢占式调度”),让线程释放资源后重新竞争。
- 实现方式:
- 基于“优先级”剥夺:若高优先级线程申请的资源被低优先级线程持有,系统强制收回低优先级线程的资源,分配给高优先级线程;低优先级线程则需重新申请资源。
- 基于“超时”剥夺:线程持有资源超过指定时间(如100ms)仍未释放,系统自动收回资源,分配给等待队列中的其他线程。
- 优缺点:
- 优点:适用于“资源可被安全剥夺”的场景(如内存页、CPU时间片);
- 缺点:1. 部分资源无法被安全剥夺(如打印机正在打印文档,强制剥夺会导致输出错乱);2. 需额外记录资源使用状态(如“资源是否处于可剥夺状态”),实现复杂度高。
4. 破坏“循环等待”条件
- 原理:对所有资源进行全局编号,要求线程必须按“编号递增”的顺序申请资源(如先申请编号1的资源,再申请编号2的资源,禁止反向申请),从而避免多个线程形成等待闭环。
- 实现方式:
- 资源编号:系统对所有资源类型分配唯一编号(如“CPU=1,内存=2,打印机=3,数据库连接=4”);
- 申请规则:线程申请资源时,必须先获取编号更小的资源,再申请编号更大的资源;释放时按“编号递减”顺序释放。
- 示例:若线程A需“内存(2)”和“打印机(3)”,必须先申请内存,再申请打印机;线程B需“打印机(3)”和“内存(2)”,则必须先申请内存(2)——若A已持有内存,B会阻塞等待内存,无法持有打印机后再等内存,从而避免循环等待。
- 优缺点:
- 优点:资源利用率高于“一次性申请”,实现难度低于“不可剥夺”,是预防策略中最实用的方式;
- 缺点:1. 资源编号需全局固定,难以动态调整(新增资源需插入合适编号,可能影响已有线程);2. 线程需按编号顺序申请,可能导致“资源闲置”(如线程需编号4的资源,但必须先申请编号1-3的闲置资源,造成浪费)。
二、死锁避免(Deadlock Avoidance):动态判断安全状态(资源申请时)
死锁预防通过“破坏必要条件”实现,但会牺牲资源利用率或灵活性;而死锁避免的核心是:不破坏必要条件,而是在资源分配时动态判断“分配后是否会进入死锁风险状态”,仅在安全时分配资源。
其关键是“安全状态”的定义:系统中存在一个“安全序列”(如线程T1→T2→T3),按此序列分配资源,每个线程都能获得所需的全部资源并顺利完成,最终释放所有资源,则系统处于安全状态;反之则为不安全状态(可能发生死锁)。
核心算法:银行家算法(Banker’s Algorithm)
银行家算法是死锁避免的经典实现,灵感来源于“银行贷款”——银行需确保贷款后仍有足够资金满足其他客户的需求,避免无法兑现。其核心是“预分配检查”,分为两步:
1. 数据结构准备
算法需维护四个核心数据结构(以进程和资源为例):
- 可用资源向量(Available):系统中每种资源的空闲数量(如Available[1]=3表示“资源1有3个空闲”);
- 最大需求矩阵(Max):每个进程对每种资源的最大需求(如Max[P1][2]=5表示“进程P1最多需要5个资源2”);
- 已分配矩阵(Allocation):每个进程已持有的每种资源数量(如Allocation[P1][2]=3表示“进程P1已持有3个资源2”);
- 需求矩阵(Need):每个进程仍需的每种资源数量(Need = Max - Allocation,如P1对资源2的Need=5-3=2)。
2. 资源分配检查逻辑
当进程P请求资源Request时,系统按以下步骤判断是否分配:
- 合法性检查:若Request > Need[P](请求超过最大需求),或Request > Available(请求超过空闲资源),直接拒绝;
- 安全性检查:假设分配Request给P,更新Available(Available = Available - Request)、Allocation(Allocation[P] = Allocation[P] + Request)、Need(Need[P] = Need[P] - Request),然后检查“更新后的系统是否处于安全状态”:
- 遍历所有进程,找到“Need ≤ Available”且“未完成”的进程,标记为“可完成”,并将其已分配资源释放(Available = Available + Allocation[P]);
- 重复上述步骤,若所有进程都能被标记为“可完成”,则系统安全,允许分配;否则撤销假设,拒绝分配。
优缺点
- 优点:无需破坏死锁必要条件,资源利用率高于“预防策略”,且能动态规避死锁风险;
- 缺点:1. 需提前知道每个进程的“最大资源需求”(实际场景中难以精准预测);2. 算法复杂度高(每次分配需遍历所有进程和资源,适合小规模系统);3. 仅适用于“资源数量固定、进程数量固定”的静态场景(如批处理系统),不适合动态创建进程/资源的场景(如分布式系统)。
三、死锁检测(Deadlock Detection):发现已发生的死锁(死锁发生后)
预防和避免策略的核心是“阻止死锁发生”,但实现成本高或适用场景有限;而死锁检测的思路是:不主动阻止死锁,而是允许死锁发生,通过特定机制定期检测,一旦发现死锁则触发后续处理。
该策略适用于“死锁概率低、资源利用率要求高”的场景(如多线程应用、分布式系统)。
核心机制:资源分配图与死锁判定
死锁检测的核心是“资源分配图(Resource Allocation Graph, RAG)”,通过图的结构判断是否存在“循环等待”(死锁的核心特征)。
1. 资源分配图的构成
RAG是一个有向图,包含两种节点和两种边:
- 节点:
- 进程节点(P1, P2, …, Pn):表示正在运行的进程;
- 资源节点(R1, R2, …, Rm):表示系统中的资源类型(每个资源节点旁的数字表示该类型的资源数量)。
- 边:
- 申请边(P→R):表示进程P向资源R发起申请(若R有空闲资源,申请边会转为分配边);
- 分配边(R→P):表示资源R已分配给进程P。
2. 死锁判定规则
- 若资源分配图中不存在“循环”,则系统无死锁;
- 若资源分配图中存在“循环”,且每个资源节点的“资源数量=1”(即资源不可共享),则循环对应死锁(此时循环是死锁的充分必要条件);
- 若资源分配图中存在循环,但部分资源节点的“资源数量>1”,则循环不一定是死锁(需进一步检查:是否存在“每个进程在循环中都无法获取足够资源”的情况)。
检测时机
死锁检测的频率需平衡“开销”与“死锁影响范围”:
- 定期检测:如每隔10秒检测一次(适合死锁概率低的场景,减少检测开销);
- 事件触发检测:当进程申请资源被拒绝时触发检测(此时该进程可能成为死锁的一部分,检测针对性更强);
- 资源耗尽时检测:当系统资源利用率极低(如CPU空闲率高但进程阻塞多)时检测,避免无效等待。
优缺点
- 优点:无需提前预测资源需求,实现灵活,资源利用率高,适合复杂动态场景;
- 缺点:1. 允许死锁发生,可能导致部分进程永久阻塞,影响业务(需配合“解除策略”);2. 检测算法有一定开销(尤其分布式系统中,需跨节点同步资源状态)。
四、死锁解除(Deadlock Resolution):恢复正常运行(死锁检测后)
死锁检测的后续步骤是“死锁解除”,即通过特定手段打破死锁循环,让系统恢复正常。其核心是“牺牲部分资源/进程,释放被占用的资源,让其他进程继续执行”。
核心策略
1. 资源剥夺(Resource Preemption)
- 原理:强制剥夺死锁进程持有的部分资源,分配给其他死锁进程,打破循环等待。
- 实现方式:
- 选择“剥夺代价最小”的资源:如剥夺“已持有时间最短”“剩余运行时间最长”的进程的资源,减少对系统的影响;
- 避免“饥饿”:记录进程被剥夺的次数,避免某个进程反复被剥夺资源(如超过3次则优先不剥夺)。
- 适用场景:资源可被安全剥夺的场景(如内存、CPU时间片),不适用于不可剥夺资源(如打印机)。
2. 进程终止(Process Termination)
- 原理:终止部分死锁进程,释放其持有的所有资源,让其他死锁进程获取资源后继续执行。
- 实现方式:
- 终止“代价最小”的进程:按“进程优先级(低优先级先终止)、运行时间(刚启动的先终止)、业务重要性(非核心进程先终止)”等指标排序,选择对系统影响最小的进程终止;
- 逐步终止:先终止一个进程,检测死锁是否解除;若未解除则继续终止下一个,避免一次性终止过多进程。
- 优缺点:
- 优点:实现简单,能快速打破死锁;
- 缺点:终止进程会导致其未完成的任务丢失,可能引发业务中断(需配合“任务重试机制”)。
3. 进程回滚(Process Rollback)
- 原理:将死锁进程“回滚到某个未发生死锁的历史状态”(需提前记录进程的状态快照),释放回滚过程中持有的资源,让进程重新执行。
- 实现方式:
- 系统定期为进程保存“检查点(Checkpoint)”:记录进程的寄存器状态、内存数据、资源持有情况;
- 死锁发生时,选择死锁进程,将其恢复到“未申请引发死锁的资源”的检查点,释放该资源,让进程重新申请资源(避免再次触发死锁)。
- 优缺点:
- 优点:无需终止进程,避免任务丢失;
- 缺点:1. 需额外存储检查点数据,占用内存;2. 回滚和重新执行会增加系统开销;3. 检查点的选择难度高(需确保回滚后不再次触发死锁)。
五、总结:四大策略的对比与适用场景
| 策略类型 | 核心思路 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 死锁预防 | 破坏死锁必要条件 | 从根源杜绝死锁,逻辑简单 | 资源利用率低、灵活性差 | 对安全性要求极高、资源类型简单的场景(如嵌入式系统) |
| 死锁避免 | 动态判断安全状态 | 资源利用率高,无需破坏条件 | 需预知最大需求,复杂度高 | 资源/进程数量固定、需求可预测的静态场景(如批处理系统) |
| 死锁检测 | 允许发生,定期检测 | 灵活性高,资源利用率最高 | 死锁发生后影响业务 | 死锁概率低、业务可容忍短暂阻塞的场景(如多线程应用、分布式系统) |
| 死锁解除 | 打破死锁循环(剥夺/终止/回滚) | 快速恢复系统,配合检测使用 | 可能丢失任务、引发饥饿 | 死锁已发生,需紧急恢复的场景(如服务器、数据库系统) |
在实际工程中,单一策略往往无法满足需求,通常会组合使用多种策略(如:用“资源编号”预防大部分死锁,用“定期检测”应对漏网之鱼,用“进程终止”解除已发生的死锁),平衡“安全性”“资源利用率”和“实现成本”。
C++中的死锁处理
C++本身只提供了死锁预防的方法,另外三种需要自己写逻辑去处理:
破坏互斥条件
原理是避免资源的独占性(即允许多个线程同时访问资源)。局限性是仅适用于 “非独占资源”(如只读数据),对 “独占资源”(如写操作、硬件设备)无效(因为独占是资源的固有属性)。也就是使用共享锁(std::shared_mutex)替代独占锁(std::mutex),实现 “多读单写”:
- 读线程:通过std::shared_lockstd::shared_mutex获取共享锁,多个读线程可同时持有。
- 写线程:通过std::unique_lockstd::shared_mutex获取独占锁,仅允许一个写线程持有(此时所有读线程阻塞)
破坏持有并等待条件
线程要么 “一次性申请所有需要的资源”,要么 “释放已持有资源后再申请新资源”,避免 “持有部分资源等待另一部分”。为解决 “多互斥锁同时加锁的死锁问题”,C++ 标准库提供了两种核心工具,核心思路是 “保证多互斥锁的加锁顺序统一,且具备‘要么全锁、要么全不锁’的原子性”。
- 方案 1:C++11 的std::lock() + std::lock_guard
std::lock()是一个函数,可接收多个互斥锁作为参数,原子化地同时锁住所有互斥锁,且内部会自动协调加锁顺序,避免死锁。
配合std::lock_guard(RAII 类,自动解锁)使用时,需用std::adopt_lock标记 “互斥锁已被std::lock()锁住,lock_guard仅接管所有权,不重复加锁”。 - 方案 2:C++17 的std::scoped_lock(简化版)
std::scoped_lock是 C++17 新增的 RAII 类模板,整合了std::lock()的加锁逻辑和std::lock_guard的自动解锁功能,支持可变参数(可同时锁多个互斥锁),用法更简洁。
破坏不可剥夺条件
允许 “抢占” 已分配的资源(即线程持有资源时,若其他线程需要,可强制释放)。使用std::unique_lock的尝试锁定接口(try_lock、try_lock_for、try_lock_until),避免无限阻塞,也就是线程尝试获取锁,若失败则主动释放已持有锁,稍后重试(而非等待)。也就是给锁分配编号(如mtx1编号 1,mtx2编号 2),所有线程严格按 “编号从小到大” 的顺序申请锁。所有线程必须遵守同一编号规则,即使某个线程仅需编号大的锁,也无需申请小的(但不能反向)。
破坏循环等待条件
给所有资源(锁)分配唯一编号,线程必须按 “编号递增” 的顺序申请资源,避免循环等待(如线程 1 持编号 1 的锁,只能等编号 > 1 的锁;线程 2 持编号 2 的锁,只能等编号 > 2 的锁,不会反向等待)。
互斥和同步的实现
在操作系统中,互斥(解决“竞争”问题,确保临界资源同一时间仅被一个进程/线程访问)和同步(解决“协作”问题,确保进程/线程按预期顺序执行)的实现,需依托硬件机制、软件算法或操作系统提供的工具。不同实现方法的核心差异在于底层依赖、开销、安全性和适用场景,以下从“软件实现”“硬件实现”“操作系统级工具”三大维度详细拆解:
一、软件实现方法(无硬件/OS支持,纯逻辑设计)
软件实现不依赖特殊硬件或操作系统接口,仅通过进程/线程的代码逻辑(如循环检测、标志位判断)实现互斥/同步。但普遍存在忙等(Busy Waiting) 问题(进程未获取资源时反复检测,浪费CPU资源),且部分算法仅适用于特定场景(如单CPU、固定进程数)。
1. 单标志位算法(适用于2个进程的互斥)
- 核心思想:用一个共享标志位
turn表示“当前允许进入临界区的进程ID”,进程需先检查turn是否等于自身ID,若否则循环等待。 - 实现逻辑(以进程P0和P1为例):
// 共享变量:turn=0(初始允许P0进入) while (turn != 0); // P0的进入区:等待turn为0 // --- 临界区(访问共享资源)--- turn = 1; // P0的退出区:将权限交给P1 while (turn != 1); // P1的进入区:等待turn为1 // --- 临界区 --- turn = 0; // P1的退出区:将权限交回P0 - 特点:
- ✅ 实现简单,确保互斥(同一时间仅一个进程进入临界区);
- ❌ 强制“交替进入”,缺乏灵活性(如P0执行完后无任务,P1仍需等待P0设置
turn=1); - ❌ 存在忙等,不适用于多进程场景。
2. 双标志位先检查后修改算法(2进程互斥,改进灵活性)
- 核心思想:为每个进程设置独立标志位
flag[i](flag[i]=true表示进程i想进入临界区),进程进入前先检查对方是否“想进入”,若否则自己进入。 - 实现逻辑:
// 共享变量:flag[0]=false, flag[1]=false(初始均不想进入) flag[0] = true; // P0的进入区:声明“我想进入” while (flag[1] == true); // 检查P1是否想进入,是则等待 // --- 临界区 --- flag[0] = false; // P0的退出区:声明“我已退出” flag[1] = true; // P1的进入区:声明“我想进入” while (flag[1] == true); // 检查P0是否想进入,是则等待 // --- 临界区 --- flag[1] = false; // P1的退出区:声明“我已退出” - 特点:
- ✅ 无需强制交替,进程可主动申请进入;
- ❌ 存在“死锁”风险(如P0和P1同时设置
flag=true,随后互相检查对方标志位,陷入永久等待); - ❌ 仍有忙等问题。
3. 双标志位先修改后检查算法(解决死锁,Peterson算法雏形)
- 核心思想:在“双标志位”基础上,增加“谦让机制”——进程声明“想进入”后,主动将
turn设为对方ID(表示“如果对方也想进,让对方先”),再检查对方状态。 - 实现逻辑(Peterson算法,2进程通用):
// 共享变量:flag[0]=flag[1]=false,turn=-1 flag[0] = true; // P0:声明想进入 turn = 1; // P0:谦让,让P1优先 while (flag[1] && turn == 1); // 若P1想进且当前该P1进,则等待 // --- 临界区 --- flag[0] = false; // P0:退出 flag[1] = true; // P1:声明想进入 turn = 0; // P1:谦让,让P0优先 while (flag[0] && turn == 0); // 若P0想进且当前该P0进,则等待 // --- 临界区 --- flag[1] = false; // P1:退出 - 特点:
- ✅ 严格满足互斥、无死锁、无饥饿(2进程公平交替);
- ❌ 仅支持2个进程,无法扩展到多进程;
- ❌ 仍有忙等,不适用于CPU密集型场景。
4. 面包店算法(多进程互斥,软件实现的“终极方案”)
- 核心思想:模拟“面包店取号”逻辑——进程进入前先“取号”(号数递增,确保唯一),取号后按“号数从小到大”进入临界区;若号数相同,按进程ID从小到大排序。
- 实现逻辑(N个进程通用):
// 共享变量:number[N] = {0}(每个进程的号数,初始为0),choosing[N] = {false}(是否在取号) choosing[i] = true; // 进程i:开始取号 number[i] = max(number[0..N-1]) + 1; // 取“当前最大号+1”,确保号数唯一 choosing[i] = false; // 进程i:取号结束 // 检查所有其他进程j:若j在取号,等待;若j号数更小,或号数相同但jID更小,等待 for (int j = 0; j < N; j++) { while (choosing[j]); while (number[j] != 0 && (number[j] < number[i] || (number[j] == number[i] && j < i))); } // --- 临界区 --- number[i] = 0; // 进程i:退出,重置号数 - 特点:
- ✅ 支持任意数量进程,严格互斥、无死锁、无饥饿(按号数公平调度);
- ❌ 实现复杂(需遍历所有进程),且存在严重忙等(多进程时等待时间长);
- ❌ 依赖“号数递增”的原子性(若多进程同时取号,需确保
max(number)计算正确,单CPU下可行,多CPU下可能出错)。
二、硬件实现方法(依托CPU指令,解决忙等/原子性问题)
软件实现的核心痛点是“忙等”和“操作非原子性”(如“检查+修改”无法一步完成,导致死锁)。硬件实现通过CPU提供的原子指令(指令执行过程不可中断),直接保证“检查+修改”的原子性,同时可减少忙等(或转为“阻塞等待”)。
1. 测试并设置指令(Test-and-Set, TAS)
- 核心思想:提供一条原子指令
TAS(lock),功能是“先读取lock的值,再将lock设为1”(读取和修改一步完成,不可中断)。lock=0表示“资源空闲”,lock=1表示“资源占用”。 - 实现逻辑(互斥):
// 共享变量:lock = 0(初始空闲) while (TAS(lock) == 1); // 进入区:若lock=1(已占用),循环等待;否则原子设为1(占用) // --- 临界区 --- lock = 0; // 退出区:释放资源,设为0 - 特点:
- ✅ 实现简单,支持任意进程数,严格保证互斥(原子指令避免非原子操作);
- ❌ 仍存在忙等(进程未获取资源时,反复执行TAS指令,浪费CPU);
- ✅ 适用于单CPU和多CPU(原子指令由CPU硬件保证,多CPU下也能避免冲突)。
2. 交换指令(Swap)
- 核心思想:提供原子指令
Swap(a, b),功能是“交换变量a和b的值”(交换过程不可中断)。用一个共享变量lock(0=空闲,1=占用)和进程私有变量key(初始设为1),通过交换实现互斥。 - 实现逻辑(互斥):
// 共享变量:lock = 0;私有变量:key = 1(每个进程独立拥有) key = 1; while (key == 1) { Swap(lock, key); // 进入区:原子交换lock和key。若lock=0(空闲),交换后key=0,退出循环;否则key=1,继续循环 } // --- 临界区 --- Swap(lock, key); // 退出区:交换lock和key(此时key=0,交换后lock=0,释放资源) - 特点:
- 与TAS完全等价,仅指令形式不同;
- ✅ 原子性保证互斥,支持多进程/多CPU;
- ❌ 同样存在忙等问题,本质是“自旋等待”(Spin Waiting)。
3. 比较并交换指令(Compare-and-Swap, CAS)
- 核心思想:提供原子指令
CAS(addr, old_val, new_val),功能是“比较内存地址addr的值与old_val:若相等,将addr设为new_val(返回true);否则不修改(返回false)”。比TAS更灵活,可实现“条件修改”。 - 实现逻辑(互斥+减少忙等):
// 共享变量:lock = 0(0=空闲,1=占用) while (CAS(lock, 0, 1) == false) { // 优化:若CAS失败(资源占用),可调用OS的“阻塞”接口(如sleep),避免忙等 sleep(10); // 让出CPU,10ms后唤醒重试 } // --- 临界区 --- lock = 0; // 退出区:释放资源 - 特点:
- ✅ 原子性强,支持“条件修改”,可通过“阻塞”优化忙等(转为阻塞等待,不浪费CPU);
- ✅ 是现代多核CPU的核心指令(如x86的
cmpxchg),也是JavaAtomicInteger、C++std::atomic等并发工具的底层实现; - ❌ 若多线程高频竞争,仍可能出现“ABA问题”(需通过“版本号”解决,如
AtomicStampedReference)。
三、操作系统级实现方法(提供高级工具,彻底解决忙等/易用性)
硬件实现虽解决了原子性,但“忙等”和“手动管理lock”仍增加开发复杂度。操作系统通过提供内核级工具,将“等待逻辑”交由内核管理(进程未获取资源时转为“阻塞态”,释放CPU),同时支持灵活的同步逻辑。
1. 信号量(Semaphore):万能工具(互斥+同步)
信号量是由Dijkstra提出的核心同步机制,本质是一个受保护的整数变量S,仅支持两种原子操作:P(S)(申请资源)和V(S)(释放资源),操作逻辑由操作系统内核保证原子性。
核心定义:
P(S)(Proberen,荷兰语“测试”):若S>0,则S=S-1(成功申请资源,继续执行);若S≤0,则进程转为“阻塞态”,加入信号量的等待队列。V(S)(Verhogen,荷兰语“增量”):若S≤0,则从等待队列唤醒一个进程(使其转为就绪态);无论如何,S=S+1(释放资源)。
实现互斥(用二元信号量,
S=1,1=空闲,0=占用):semaphore S = 1; // 初始化信号量,对应1个临界资源 // 进程A/B的代码 P(S); // 进入区:申请资源。若S=0(已占用),阻塞 // --- 临界区(访问共享资源)--- V(S); // 退出区:释放资源。若有进程阻塞,唤醒一个实现同步(用计数信号量,
S=0,控制进程执行顺序):
例:要求“进程B必须在进程A执行完步骤X后才能执行步骤Y”:semaphore S = 0; // 初始化S=0,进程B初始无法执行 // 进程A // ... 执行步骤X ... V(S); // A执行完X后,释放信号量(S=1),唤醒B // 进程B P(S); // B执行Y前,申请信号量。若A未执行V(S),B阻塞 // ... 执行步骤Y ...特点:
- ✅ 万能性:可实现互斥(二元信号量)、同步(计数信号量)、资源限制(如
S=5表示允许5个进程同时访问); - ✅ 无忙等:进程未获取资源时由内核阻塞,释放CPU(比硬件实现更高效);
- ❌ 需手动保证
P(S)和V(S)的配对(漏写V(S)会导致死锁,多写V(S)会导致信号量异常); - ✅ 适用于所有场景(单进程/多进程、单CPU/多CPU)。
- ✅ 万能性:可实现互斥(二元信号量)、同步(计数信号量)、资源限制(如
2. 互斥锁(Mutex Lock):专为互斥设计
互斥锁是信号量的“简化版”,仅用于解决临界资源互斥访问(本质是二元信号量的封装),接口更直观(lock()/unlock()),且内置“所有权”机制(只有加锁的进程能解锁,避免误操作)。
实现逻辑:
mutex_t lock; // 初始化互斥锁(默认未加锁) lock(&lock); // 进入区:加锁。若已加锁,进程阻塞 // --- 临界区 --- unlock(&lock); // 退出区:解锁。若有进程阻塞,唤醒一个与信号量的区别:
特性 互斥锁(Mutex) 信号量(Semaphore) 核心用途 仅用于临界资源互斥 互斥、同步、资源限制(多用途) 所有权 加锁进程必须解锁(所有权唯一) 无所有权(A加锁,B可解锁) 接口 简单(lock/unlock) 灵活(P/V操作) 适用场景 单临界资源互斥(如共享内存) 复杂协作(如进程顺序控制) 特点:
- ✅ 易用性高,避免信号量的“误解锁”问题;
- ✅ 无忙等(内核阻塞),支持“可重入”(同一进程可多次加锁,需对应次数解锁,如
pthread_mutex_t的PTHREAD_MUTEX_RECURSIVE属性); - ❌ 功能单一,无法实现同步(如无法控制进程执行顺序)。
3. 条件变量(Condition Variable):配合互斥锁实现同步
条件变量本身不实现互斥,而是配合互斥锁,解决“进程等待某个条件成立”的同步问题(如“缓冲区非空”“资源可用”)。核心是“等待-唤醒”机制:进程等待条件时,释放互斥锁(允许其他进程修改条件);条件成立时,由其他进程唤醒。
核心接口(以POSIX为例):
pthread_cond_wait(cond, mutex):等待条件cond成立。执行时会原子释放互斥锁mutex,并将进程加入等待队列;被唤醒后,重新获取mutex再返回。pthread_cond_signal(cond):唤醒等待队列中的一个进程。pthread_cond_broadcast(cond):唤醒等待队列中的所有进程。
实现同步示例(生产者-消费者问题:消费者需等待“缓冲区非空”):
mutex_t mutex; // 保护缓冲区的互斥锁 cond_t not_empty; // 条件:缓冲区非空 int buffer[10]; // 共享缓冲区 int count = 0; // 缓冲区元素个数 // 消费者进程 pthread_mutex_lock(&mutex); while (count == 0) { // 检查条件:缓冲区为空,需等待 pthread_cond_wait(¬_empty, &mutex); // 释放mutex,等待被唤醒;唤醒后重新加锁 } // --- 临界区:从缓冲区取数据,count-- --- pthread_mutex_unlock(&mutex); // 生产者进程 pthread_mutex_lock(&mutex); // --- 临界区:向缓冲区存数据,count++ --- if (count == 1) { // 条件成立(缓冲区从空变非空),唤醒消费者 pthread_cond_signal(¬_empty); } pthread_mutex_unlock(&mutex);特点:
- ✅ 高效解决“条件等待”问题,避免进程反复检查条件(减少忙等);
- ✅ 必须与互斥锁配合(确保“检查条件”和“修改条件”的原子性);
- ❌ 不单独使用,需结合互斥锁,适用于复杂同步场景(如生产者-消费者、读者-写者)。
4. 管程(Monitor):封装互斥与同步(高级抽象)
管程是Dijkstra提出的“更高层次的同步机制”,本质是将“共享资源+操作资源的函数+同步逻辑”封装为一个模块,确保“同一时间仅一个进程进入管程执行函数”(内置互斥),同时通过“条件变量”实现同步。
核心特性:
- 封装性:共享资源和操作函数被封装在管程内部,外部进程仅能通过管程提供的函数访问资源(避免直接操作资源导致的错误);
- 互斥性:管程内置“互斥锁”,进程调用管程函数时自动加锁,函数执行完自动解锁(无需手动管理
lock/unlock); - 同步性:管程内部可定义条件变量,进程可在条件不成立时“等待”(释放互斥锁),条件成立时“唤醒”。
实现示例(管程解决生产者-消费者问题):
// Java中的管程(synchronized关键字+wait/notify实现) class BufferMonitor { private int[] buffer = new int[10]; private int count = 0; // 生产者函数:向缓冲区存数据(管程自动互斥) public synchronized void put(int data) throws InterruptedException { while (count == buffer.length) { wait(); // 缓冲区满,等待“非满”条件(释放锁) } buffer[count++] = data; notify(); // 唤醒等待“非空”的消费者 } // 消费者函数:从缓冲区取数据(管程自动互斥) public synchronized void take() throws InterruptedException { while (count == 0) { wait(); // 缓冲区空,等待“非空”条件(释放锁) } int data = buffer[--count]; notify(); // 唤醒等待“非满”的生产者 return data; } } // 生产者进程 class Producer implements Runnable { private BufferMonitor monitor; public void run() { for (int i = 0; i < 100; i++) { monitor.put(i); // 调用管程函数,自动加锁 } } } // 消费者进程 class Consumer implements Runnable { private BufferMonitor monitor; public void run() { for (int i = 0; i < 100; i++) { monitor.take(); // 调用管程函数,自动加锁 } } }特点:
- ✅ 易用性极高:开发者无需关注互斥锁的手动管理,仅需聚焦“条件等待”逻辑;
- ✅ 安全性强:封装性避免了共享资源的误操作,内置互斥确保临界区安全;
- ✅ 现代语言原生支持:如Java的
synchronized方法/块、C#的lock语句、Python的threading.Lock+Condition,本质都是管程的实现; - ❌ 依赖语言/OS支持,无底层硬件依赖(是高级抽象,底层仍基于信号量或互斥锁实现)。
四、各类实现方法的对比与适用场景
| 实现层级 | 具体方法 | 核心优势 | 核心劣势 | 适用场景 |
|---|---|---|---|---|
| 软件 | 面包店算法 | 无硬件/OS依赖,多进程支持 | 忙等严重,实现复杂 | 无OS支持的嵌入式系统 |
| 硬件 | TAS/Swap/CAS | 原子性强,多CPU支持 | 忙等(需手动优化) | 内核级底层同步(如自旋锁) |
| 操作系统 | 信号量 | 万能(互斥+同步) | 需手动配对P/V,易出错 | 内核/用户态复杂协作 |
| 操作系统 | 互斥锁 | 易用,有所有权,无忙等 | 仅支持互斥 | 用户态临界资源互斥(如线程) |
| 操作系统 | 条件变量 | 高效解决条件等待 | 需配合互斥锁,不单独使用 | 生产者-消费者、读者-写者等 |
| 操作系统 | 管程 | 封装性好,易用安全 | 依赖语言/OS支持 | 现代编程语言的并发开发 |
综上,软件实现仅适用于无OS/硬件支持的极简场景,硬件实现是内核底层的基础,而操作系统级工具(尤其是管程和互斥锁+条件变量)是现代应用开发中解决互斥与同步的主流选择——它们平衡了易用性、安全性和效率,避免了底层细节的复杂管理。
能否跨线程解锁?为什么?
对于这个问题我们直接基于源码分析。
锁的定义和加锁
锁的定义:
//用于实现乐观自旋锁队列机制
struct optimistic_spin_queue {
/*
* Stores an encoded value of the CPU # of the tail node in the queue.
* If the queue is empty, then it's set to OSQ_UNLOCKED_VAL.
*/
atomic_t tail;//包含一个原子变量tail,存储队列尾节点所在 CPU 编号的编码值
//当队列为空时,tail被设置为OSQ_UNLOCKED_VAL(解锁状态值)
};
//Linux 内核中最基础的双向链表结构
struct list_head {
struct list_head *next, *prev;//通过next和prev指针实现双向链接
//采用 "侵入式" 设计,可嵌入到任意结构体中实现链表功能
//内核提供了丰富的宏操作函数来操作这种链表
};
//用于锁依赖关系跟踪(lockdep 机制)
struct lockdep_map {
struct lock_class_key *key;//key和class_cache用于锁分类和缓存
struct lock_class *class_cache[NR_LOCKDEP_CACHING_CLASSES];
const char *name;//name存储锁的名称
//wait_type_outer和wait_type_inner描述锁的等待上下文
u8 wait_type_outer; /* can be taken in this context */
u8 wait_type_inner; /* presents this context */
u8 lock_type;//表示锁的类型
/* u8 hole; */
//配置CONFIG_LOCK_STAT后,还会记录锁操作的 CPU 和指令指针(ip),主要用于检测内核中的死锁和锁使用不当问题
#ifdef CONFIG_LOCK_STAT
int cpu;
unsigned long ip;
#endif
};
struct mutex {
atomic_long_t owner;//记录当前持有锁的线程 ID(或特殊标记值),用于跟踪锁的所有权
raw_spinlock_t wait_lock;//原始自旋锁,保护等待队列的操作
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; //可选的乐观自旋队列,用于在锁持有者即将释放锁时进行自旋等待优化
#endif
struct list_head wait_list;//等待队列,记录等待获取该锁的线程
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;//magic用于调试互斥锁
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;//dep_map用于锁依赖关系跟踪
#endif
};
#else /* !CONFIG_PREEMPT_RT */
/*
* Preempt-RT variant based on rtmutexes.
*/
#include <linux/rtmutex.h>
struct mutex {
struct rt_mutex_base rtmutex;//基于实时互斥锁(rtmutex)实现,内部包含rt_mutex_base结构体
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;//同样保留了dep_map用于调试锁的分配关系
#endif
};
#endif /* CONFIG_PREEMPT_RT */
#endif /* __LINUX_MUTEX_TYPES_H */
//实时互斥锁的基础数据结构
struct rt_mutex_base {
raw_spinlock_t wait_lock;//用于保护等待队列的原始自旋锁
struct rb_root_cached waiters;//使用红黑树(rb_root_cached)管理等待该互斥锁的进程
struct task_struct *owner;//指向当前持有该互斥锁的进程(task_struct)
};
//带缓存的红黑树根节点结构
struct rb_root_cached {
struct rb_root rb_root;//红黑树的根节点
struct rb_node *rb_leftmost;//缓存的最左节点(通常是最小值节点),用于加速查找操作
};
加锁:
void __sched mutex_lock(struct mutex *lock)
{
//提示内核当前进程可能进入睡眠状态,用于辅助内核进行调度决策和锁调试。
might_sleep();
//采用 "快速路径 + 慢速路径"
if (!__mutex_trylock_fast(lock))
//慢速路径通常会涉及进程状态切换、加入等待队列、调度让出 CPU 等操作
__mutex_lock_slowpath(lock);
}
EXPORT_SYMBOL(mutex_lock);
-------------------------------------------------------------------------------
//快速路径
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;///通过current获取当前进程指针(转换为unsigned long类型)
unsigned long zero = 0UL;//定义zero作为比较基准值
//调试检查,确保锁的magic字段与自身指针一致,用于检测锁的异常状态
MUTEX_WARN_ON(lock->magic != lock);
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr))//
return true;
return false;
}
//这是一个原子的 "比较并交换"(Compare-and-Swap)操作函数
//针对 atomic_long_t 类型的原子变量进行操作,用于多线程 / 并发环境中安全地更新共享数据
//函数名中的 acquire 表示该操作具有获取语义(acquire semantics),
//确保后续的内存操作不会被重排到这个原子操作之前,常用于同步机制中获取锁的场景
static __always_inline bool
atomic_long_try_cmpxchg_acquire(atomic_long_t *v, long *old, long new)
{
//先调用 instrument_atomic_read_write 进行两次 instrumentation(可能是用于调试、跟踪或检测原子操作)
instrument_atomic_read_write(v, sizeof(*v));
instrument_atomic_read_write(old, sizeof(*old));
//最终调用 raw_atomic_long_try_cmpxchg_acquire 执行实际的原子操作
return raw_atomic_long_try_cmpxchg_acquire(v, old, new);
}
//整体来看,这是一套用于在原子读写操作时进行内存检查的框架,目前可能处于未完全实现或调试阶段,实际检查逻辑尚未完善。
static __always_inline void instrument_atomic_read_write(const volatile void *v, size_t size)
{
kasan_check_write(v, size);
kcsan_check_atomic_read_write(v, size);
}
static inline bool kasan_check_write(const volatile void *p, unsigned int size)
{
return true;
}
#define kcsan_check_atomic_read_write(...) do { } while (0)
//根据系统是否为 64 位(CONFIG_64BIT),分别调用 64 位版本(raw_atomic64_try_cmpxchg_acquire)
//或 32 位版本(raw_atomic_try_cmpxchg_acquire)。
static __always_inline bool
raw_atomic_long_try_cmpxchg_acquire(atomic_long_t *v, long *old, long new)
{
#ifdef CONFIG_64BIT
return raw_atomic64_try_cmpxchg_acquire(v, (s64 *)old, new);
#else
return raw_atomic_try_cmpxchg_acquire(v, (int *)old, new);
#endif
}
static __always_inline bool
// Linux 内核中原子操作相关的函数实现,功能是对 64 位原子变量执行条件比较并交换(Compare-and-Swap, CAS)操作,
//且带有获取语义(acquire semantics)的内存屏障。
raw_atomic64_try_cmpxchg_acquire(atomic64_t *v, s64 *old, s64 new)
{
//首先检查是否有架构特定的arch_atomic64_try_cmpxchg_acquire实现,若有则直接调用
#if defined(arch_atomic64_try_cmpxchg_acquire)
return arch_atomic64_try_cmpxchg_acquire(v, old, new);
//若没有,则检查是否有arch_atomic64_try_cmpxchg_relaxed(宽松语义版本),
//若有则调用它并手动添加获取语义的内存屏障__atomic_acquire_fence()
#elif defined(arch_atomic64_try_cmpxchg_relaxed)
bool ret = arch_atomic64_try_cmpxchg_relaxed(v, old, new);
__atomic_acquire_fence();
return ret;
//若前两者都没有,则尝试调用通用的arch_atomic64_try_cmpxchg实现
#elif defined(arch_atomic64_try_cmpxchg)
return arch_atomic64_try_cmpxchg(v, old, new);
//若以上架构特定实现都不存在,则使用基础的raw_atomic64_cmpxchg_acquire进行操作
#else
s64 r, o = *old;//保存期望值o
r = raw_atomic64_cmpxchg_acquire(v, o, new);//执行比较交换操作
if (unlikely(r != o))//如果交换失败(返回值r不等于期望值o),则更新old指针指向的值为实际值r
*old = r;
return likely(r == o);//返回操作是否成功(r == o表示成功)
#endif
}
static __always_inline bool arch_atomic64_try_cmpxchg(atomic64_t *v, s64 *old, s64 new)
{
return arch_try_cmpxchg(&v->counter, old, new);
}
#define arch_try_cmpxchg(ptr, oldp, new) \
({ \
__typeof__(ptr) __oldp = (__typeof__(ptr))(oldp); \
__typeof__(*(ptr)) __old = *__oldp; \
__typeof__(*(ptr)) __new = (new); \
__typeof__(*(ptr)) __prev; \
int __cc; \
\
switch (sizeof(*(ptr))) { \
case 1: \
case 2: { \
__prev = arch_cmpxchg((ptr), (__old), (__new)); \
__cc = (__prev != __old); \
if (unlikely(__cc)) \
*__oldp = __prev; \
break; \
} \
case 4: { \
asm volatile( \
" cs %[__old],%[__new],%[__ptr]\n" \
: [__old] "+d" (*__oldp), \
[__ptr] "+Q" (*(ptr)), \
"=@cc" (__cc) \
: [__new] "d" (__new) \
: "memory"); \
break; \
} \
case 8: { \
asm volatile( \
" csg %[__old],%[__new],%[__ptr]\n" \
: [__old] "+d" (*__oldp), \
[__ptr] "+QS" (*(ptr)), \
"=@cc" (__cc) \
: [__new] "d" (__new) \
: "memory"); \
break; \
} \
default: \
__cmpxchg_called_with_bad_pointer(); \
} \
likely(__cc == 0); \
})
static __always_inline s64
raw_atomic64_cmpxchg_acquire(atomic64_t *v, s64 old, s64 new)
{
#if defined(arch_atomic64_cmpxchg_acquire)
return arch_atomic64_cmpxchg_acquire(v, old, new);
#elif defined(arch_atomic64_cmpxchg_relaxed)
s64 ret = arch_atomic64_cmpxchg_relaxed(v, old, new);
__atomic_acquire_fence();
return ret;
#elif defined(arch_atomic64_cmpxchg)
return arch_atomic64_cmpxchg(v, old, new);
#else
return raw_cmpxchg_acquire(&v->counter, old, new);
#endif
-------------------------------------------------------------------------------
//慢速路径
__mutex_lock_slowpath(struct mutex *lock)
{
//TASK_UNINTERRUPTIBLE 表示获取锁的过程中,当前线程会进入不可中断状态
//这意味着线程在获取到锁之前会进入睡眠状态,不会响应信号唤醒
//_RET_IP_ 通常用于传递调用者的返回地址,用于调试和跟
__mutex_lock(lock, TASK_UNINTERRUPTIBLE, 0, NULL, _RET_IP_);
}
//__sched 是内核宏,用于标记调度相关的函数,会影响函数的栈帧处理和调度行为
//struct mutex *lock:指向要操作的互斥锁结构体
//unsigned int state:进程在等待锁时的状态(如 TASK_INTERRUPTIBLE)
//unsigned int subclass:锁的子类,用于锁依赖检查
//struct lockdep_map *nest_lock:嵌套锁的调试信息
//unsigned long ip:调用者的指令指针(用于调试和跟踪)
static int __sched
__mutex_lock(struct mutex *lock, unsigned int state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip)
{
return __mutex_lock_common(lock, state, subclass, nest_lock, ip, NULL, false);
}
static __always_inline int __sched
__mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
//阶段1:初始化与参数处理
DEFINE_WAKE_Q(wake_q); // 定义唤醒队列(用于批量唤醒线程)
struct mutex_waiter waiter; // 定义当前线程的等待节点
struct ww_mutex *ww; // 用于 Wound-Wait 锁(一种避免死锁的机制)
unsigned long flags; // 用于保存中断状态
int ret; // 返回值
// 处理 Wound-Wait 上下文(若不使用则置空)
if (!use_ww_ctx)
ww_ctx = NULL;
might_sleep(); // 告知内核该函数可能导致线程睡眠(用于调试和抢占管理)
// 调试检查:验证锁的 magic 字段(确保锁未被破坏)
MUTEX_WARN_ON(lock->magic != lock);
// 若使用 Wound-Wait 机制,获取对应的 ww_mutex 结构体
ww = container_of(lock, struct ww_mutex, base);
if (ww_ctx) {
// 检查是否重复获取同一 Wound-Wait 锁(避免死锁)
if (unlikely(ww_ctx == READ_ONCE(ww->ctx)))
return -EALREADY;
/*
* Reset the wounded flag after a kill. No other process can
* race and wound us here since they can't have a valid owner
* pointer if we don't have any locks held.
*/
// 重置 Wound-Wait 上下文的 "wounded" 标记(用于死锁恢复)
if (ww_ctx->acquired == 0)
ww_ctx->wounded = 0;
//如果该宏已定义(通常在开启内核锁调试功能时会定义),则会执行nest_lock = &ww_ctx->dep_map;这行代码,
//将nest_lock指针指向ww_ctx结构体中的dep_map成员,dep_map通常用于跟踪锁的依赖关系,帮助检测死锁等问题。
#ifdef CONFIG_DEBUG_LOCK_ALLOC
nest_lock = &ww_ctx->dep_map;
#endif
}
//阶段 2:快速尝试获取锁(无竞争路径
preempt_disable(); // 禁用抢占(避免获取锁的过程被其他线程打断)
// 锁依赖跟踪(用于调试死锁)
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
// 跟踪锁竞争开始
trace_contention_begin(lock, LCB_F_MUTEX | LCB_F_SPIN);
// 尝试快速获取锁:先直接尝试,失败则乐观自旋
if (__mutex_trylock(lock) || mutex_optimistic_spin(lock, ww_ctx, NULL)) {
// 成功获取锁:更新调试信息,处理 Wound-Wait 上下文
lock_acquired(&lock->dep_map, ip);
if (ww_ctx)
ww_mutex_set_context_fastpath(ww, ww_ctx);
trace_contention_end(lock, 0); // 结束竞争跟踪
preempt_enable(); // 启用抢占
return 0; // 成功返回
}
//阶段 3:获取等待队列锁并再次尝试
// 获取等待队列的保护锁(raw_spinlock),并保存中断状态
raw_spin_lock_irqsave(&lock->wait_lock, flags);
// 持有等待锁后再次尝试获取锁(可能上一个持有者刚释放)
if (__mutex_trylock(lock)) {
if (ww_ctx)
__ww_mutex_check_waiters(lock, ww_ctx, &wake_q); // 处理 Wound-Wait 等待者
goto skip_wait; // 跳转到成功流程
}
//阶段 4:加入等待队列并阻塞等待
// 初始化等待节点(关联当前线程)
debug_mutex_lock_common(lock, &waiter);
waiter.task = current; // current 是当前线程的结构体指针
if (use_ww_ctx)
waiter.ww_ctx = ww_ctx; // 关联 Wound-Wait 上下文
// 记录锁竞争信息(调试用)
lock_contended(&lock->dep_map, ip);
// 根据是否使用 Wound-Wait,将等待节点加入队列
if (!use_ww_ctx) {
// 普通锁:按 FIFO 顺序加入等待队列尾部
__mutex_add_waiter(lock, &waiter, &lock->wait_list);
} else {
// Wound-Wait 锁:按特殊顺序加入,处理可能的死锁场景
ret = __ww_mutex_add_waiter(&waiter, lock, ww_ctx, &wake_q);
if (ret)
goto err_early_kill; // 若失败,跳转到错误处理
}
// 设置当前线程状态为阻塞(TASK_INTERRUPTIBLE 或 TASK_UNINTERRUPTIBLE)
set_current_state(state);
trace_contention_begin(lock, LCB_F_MUTEX);
// 循环等待,直到获取锁或被中断
for (;;) {
// 再次尝试获取锁(可能刚被释放)
if (__mutex_trylock(lock))
goto acquired; // 成功获取,跳转到处理流程
// 检查是否有信号需要处理(如中断等待)
if (signal_pending_state(state, current)) {
ret = -EINTR;
goto err; // 被信号中断,跳转到错误处理
}
// 处理 Wound-Wait 机制的“伤害”检查(避免死锁)
if (ww_ctx) {
ret = __ww_mutex_check_kill(lock, &waiter, ww_ctx);
if (ret)
goto err;
}
// 释放等待队列锁,允许其他线程修改队列,并唤醒需要唤醒的线程
raw_spin_unlock_irqrestore_wake(&lock->wait_lock, flags, &wake_q);
// 调度切换:当前线程让出 CPU,进入睡眠
schedule_preempt_disabled();
// 被唤醒后,检查是否为等待队列中的第一个节点
first = __mutex_waiter_is_first(lock, &waiter);
// 重新设置线程状态为阻塞
set_current_state(state);
// 再次尝试获取锁(可能被上一个持有者“移交”)
if (__mutex_trylock_or_handoff(lock, first))
break; // 获取成功,退出循环
// 若为第一个等待节点,再次尝试乐观自旋(优化短等待)
if (first) {
trace_contention_begin(lock, LCB_F_MUTEX | LCB_F_SPIN);
if (mutex_optimistic_spin(lock, ww_ctx, &waiter))
break; // 自旋成功,退出循环
trace_contention_begin(lock, LCB_F_MUTEX);
}
// 重新获取等待队列锁,继续循环
raw_spin_lock_irqsave(&lock->wait_lock, flags);
}
// 重新获取等待队列锁,准备处理获取成功后的逻辑
raw_spin_lock_irqsave(&lock->wait_lock, flags);
acquired:
//阶段 5:获取锁后的清理与返回
// 将线程状态设置为运行中
__set_current_state(TASK_RUNNING);
// 处理 Wound-Wait 机制的等待者检查(若需要唤醒其他线程)
if (ww_ctx) {
if (!ww_ctx->is_wait_die && !__mutex_waiter_is_first(lock, &waiter))
__ww_mutex_check_waiters(lock, ww_ctx, &wake_q);
}
// 将当前线程的等待节点从队列中移除
__mutex_remove_waiter(lock, &waiter);
debug_mutex_free_waiter(&waiter); // 清理调试信息
skip_wait:
// 记录锁获取成功的调试信息
lock_acquired(&lock->dep_map, ip);
trace_contention_end(lock, 0); // 结束竞争跟踪
// 处理 Wound-Wait 锁的获取成功逻辑
if (ww_ctx)
ww_mutex_lock_acquired(ww, ww_ctx);
// 释放等待队列锁,唤醒需要唤醒的线程,并恢复中断状态
raw_spin_unlock_irqrestore_wake(&lock->wait_lock, flags, &wake_q);
preempt_enable(); // 启用抢占
return 0; // 成功返回
err:
// 重置线程状态为运行中
__set_current_state(TASK_RUNNING);
// 从等待队列中移除当前线程的节点
__mutex_remove_waiter(lock, &waiter);
err_early_kill:
// 结束竞争跟踪,记录错误
trace_contention_end(lock, ret);
// 释放等待队列锁,恢复中断状态,并唤醒相关线程
raw_spin_unlock_irqrestore_wake(&lock->wait_lock, flags, &wake_q);
debug_mutex_free_waiter(&waiter); // 清理调试信息
mutex_release(&lock->dep_map, ip); // 释放锁依赖跟踪
preempt_enable(); // 启用抢占
return ret; // 返回错误码(如 -EINTR 表示被信号中断)
}
通过上面的调用我们可以知道大致的调用流程如下:
mutex_lock() // 入口函数
├─ __mutex_trylock_fast() // 快速路径:原子尝试获取锁
│ └─ atomic_long_try_cmpxchg_acquire() // 原子CAS操作(核心:修改owner字段)
│ └─ raw_atomic_long_try_cmpxchg_acquire() // 适配32/64位系统
│ └─ arch_atomic64_try_cmpxchg() // 架构相关实现(如x86的cs/csg指令)
└─ __mutex_lock_slowpath() // 快速路径失败,进入慢速路径
└─ __mutex_lock() // 封装慢速路径参数
└─ __mutex_lock_common() // 慢速路径核心:自旋+阻塞+唤醒逻辑
├─ 阶段1:初始化参数(Wound-Wait上下文、等待节点)
├─ 阶段2:再次尝试获取锁+乐观自旋
├─ 阶段3:获取wait_lock保护等待队列,再次尝试加锁
├─ 阶段4:加入等待队列,阻塞睡眠
└─ 阶段5:唤醒后获取锁,清理资源并返回
其中_mutex_lock_common的详细流程如下:
这个流程中比较重要的决策点如下:
- 锁获取尝试:3处尝试获取锁(快速路径/持有队列锁/循环内)
- 队列加入策略:普通 FIFO vs Wound-Wait 优先级排序
- 死锁处理:Wound-Wait 算法决策(标记 wounded/返回 EDEADLK)
- 唤醒优化:批量唤醒代替逐个唤醒
- 锁交接:直接传递锁给下一个等待者
锁获取尝试
下面是尝试获取锁的源码 :
static inline bool __mutex_trylock(struct mutex *lock)
{
return !__mutex_trylock_common(lock, false);
}
static inline struct task_struct *__mutex_trylock_common(struct mutex *lock, bool handoff)
{
unsigned long owner, curr = (unsigned long)current;
owner = atomic_long_read(&lock->owner);
for (;;) { /* must loop, can race against a flag */
unsigned long flags = __owner_flags(owner);
unsigned long task = owner & ~MUTEX_FLAGS;
if (task) {
if (flags & MUTEX_FLAG_PICKUP) {
if (task != curr)
break;
flags &= ~MUTEX_FLAG_PICKUP;
} else if (handoff) {
if (flags & MUTEX_FLAG_HANDOFF)
break;
flags |= MUTEX_FLAG_HANDOFF;
} else {
break;
}
} else {
MUTEX_WARN_ON(flags & (MUTEX_FLAG_HANDOFF | MUTEX_FLAG_PICKUP));
task = curr;
}
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &owner, task | flags)) {
if (task == curr)
return NULL;
break;
}
}
return __owner_task(owner);
}
通过尝试获取锁的代码可以知道,最终还是调用原子CAS操作。
队列加入策略
FIFO策略:
//这个函数的作用是维护互斥锁的等待队列,当有任务尝试获取已被持有的互斥锁时,
//会被封装成等待者加入队列,直到互斥锁被释放。
//struct mutex *lock:指向互斥锁结构体的指针
//struct mutex_waiter *waiter:指向等待者结构体的指针
//struct list_head *list:指向等待队列的链表头
static void
__mutex_add_waiter(struct mutex *lock, struct mutex_waiter *waiter,
struct list_head *list)
{
//如果开启了CONFIG_DETECT_HUNG_TASK_BLOCKER配置,
//会调用hung_task_set_blocker设置阻塞器类型为互斥锁,用于检测 hung task(僵死任务)
#ifdef CONFIG_DETECT_HUNG_TASK_BLOCKER
hung_task_set_blocker(lock, BLOCKER_TYPE_MUTEX);
#endif
debug_mutex_add_waiter(lock, waiter, current);//调试用函数,用于记录等待者信息
list_add_tail(&waiter->list, list);//将等待者添加到等待队列的尾部
if (__mutex_waiter_is_first(lock, waiter))//检查当前等待者是否为队列中的第一个
//如果是第一个等待者,则通过__mutex_set_flag设置MUTEX_FLAG_WAITERS标志,表明该互斥锁现在有等待者
__mutex_set_flag(lock, MUTEX_FLAG_WAITERS);
}
//将一个等待者(waiter)添加到互斥锁(lock)的等待队列中
//基于 ww_acquire_ctx 上下文(ww_ctx)的优先级进行排序
//实现了 Wait-Die 和 Wound-Wait 两种死锁避免策略
static inline int
__ww_mutex_add_waiter(struct MUTEX_WAITER *waiter,
struct MUTEX *lock,
struct ww_acquire_ctx *ww_ctx,
struct wake_q_head *wake_q)
{
struct MUTEX_WAITER *cur, *pos = NULL;
bool is_wait_die;
if (!ww_ctx) {//若没有上下文(!ww_ctx),直接添加等待者并返回
__ww_waiter_add(lock, waiter, NULL);
return 0;
}
//区分两种策略:is_wait_die标记当前使用 Wait-Die 还是 Wound-Wait 策略
is_wait_die = ww_ctx->is_wait_die;
/*
* Add the waiter before the first waiter with a higher stamp.
* Waiters without a context are skipped to avoid starving
* them. Wait-Die waiters may die here. Wound-Wait waiters
* never die here, but they are sorted in stamp order and
* may wound the lock holder.
*/
//遍历现有等待队列,按照上下文优先级(stamp)寻找插入位置
for (cur = __ww_waiter_last(lock); cur;
cur = __ww_waiter_prev(lock, cur)) {
if (!cur->ww_ctx)
continue;
if (__ww_ctx_less(ww_ctx, cur->ww_ctx)) {
/*
* Wait-Die: if we find an older context waiting, there
* is no point in queueing behind it, as we'd have to
* die the moment it would acquire the lock.
*/
//对 Wait-Die 策略:
//若发现更旧的上下文,直接终止当前等待者(避免死锁)
//确保让更年轻的等待者终止
if (is_wait_die) {
int ret = __ww_mutex_kill(lock, ww_ctx);//处理等待者的终止逻辑
if (ret)
return ret;
}
break;
}
pos = cur;
/* Wait-Die: ensure younger waiters die. */
__ww_mutex_die(lock, cur, ww_ctx, wake_q);//处理等待者的终止逻辑
}
__ww_waiter_add(lock, waiter, pos);//实际执行添加等待者到队列的操作
/*
* Wound-Wait: if we're blocking on a mutex owned by a younger context,
* wound that such that we might proceed.
*/
//对 Wound-Wait 策略:
//若阻塞在更年轻的上下文拥有的锁上,会 "伤害"(wound)该上下文,使其释放锁
if (!is_wait_die) {
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
/*
* See ww_mutex_set_context_fastpath(). Orders setting
* MUTEX_FLAG_WAITERS vs the ww->ctx load,
* such that either we or the fastpath will wound @ww->ctx.
*/
smp_mb();//内存屏障(smp_mb()):确保多处理器环境下的内存可见性
__ww_mutex_wound(lock, ww_ctx, ww->ctx, wake_q);//Wound-Wait 策略中 "伤害" 其他上下文的逻辑
}
return 0;
}
死锁处理
死锁处理的关键函数如下:
__ww_mutex_add_waiter 按 stamp 排序插入等待者(确保老任务优先)
__ww_mutex_check_kill 检查死锁风险,触发 Wait/Die 或 Wound 操作
__ww_mutex_check_waiters 锁释放时检查是否有老任务在等待,标记当前任务为 wounded(需回滚)
ww_mutex_lock_acquired 成功获取锁后更新上下文(记录 acquired 计数)
//这段代码是 Linux 内核中与 ww_mutex(wait/wound mutex,等待 / 伤害互斥锁)相关的函数,
//主要用于检查是否需要终止当前进程对互斥锁的获取尝试,以解决潜在的死锁问题。
//当检测到潜在死锁时,让优先级较低的进程主动放弃("伤害" 自己),释放已获取的资源,从而避免死锁。
//这种机制在需要获取多个锁的场景(如图形驱动)中特别有用。
static inline int
__ww_mutex_check_kill(struct MUTEX *lock, struct MUTEX_WAITER *waiter,
struct ww_acquire_ctx *ctx)
{
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
struct ww_acquire_ctx *hold_ctx = READ_ONCE(ww->ctx);
struct MUTEX_WAITER *cur;
if (ctx->acquired == 0)//如果当前上下文 (ctx) 未获取任何锁,直接返回 0(无需处理)
return 0;
if (!ctx->is_wait_die) {//若当前不是 "等待死亡" 模式 (is_wait_die)
if (ctx->wounded)//若上下文已标记为 "受伤"(wounded),则调用__ww_mutex_kill 终止获取
return __ww_mutex_kill(lock, ctx);
return 0;
}
//若持有锁的上下文 (hold_ctx) 存在且优先级低于当前上下文,终止当前获取
if (hold_ctx && __ww_ctx_less(ctx, hold_ctx))//
return __ww_mutex_kill(lock, ctx);
/*
* If there is a waiter in front of us that has a context, then its
* stamp is earlier than ours and we must kill ourself.
*/
//检查等待队列中排在当前等待者前面的实体,若有带上下文的等待者,由于其优先级更高,当前进程需要终止获取
for (cur = __ww_waiter_prev(lock, waiter); cur;
cur = __ww_waiter_prev(lock, cur)) {
if (!cur->ww_ctx)
continue;
return __ww_mutex_kill(lock, ctx);
}
return 0;
}
//函数接收三个参数:互斥锁结构体指针lock、获取上下文ww_ctx和唤醒队列wake_q
static void
__ww_mutex_check_waiters(struct MUTEX *lock, struct ww_acquire_ctx *ww_ctx,
struct wake_q_head *wake_q)
{
struct MUTEX_WAITER *cur;
//使用lockdep_assert_wait_lock_held进行锁状态断言,确保当前持有等待锁
lockdep_assert_wait_lock_held(lock);
//通过循环遍历互斥锁的所有等待者(MUTEX_WAITER结构体)
for (cur = __ww_waiter_first(lock); cur;
cur = __ww_waiter_next(lock, cur)) {
//跳过没有等待上下文(ww_ctx)的等待者
if (!cur->ww_ctx)
continue;
//对每个有效等待者,调用两个关键函数:
//__ww_mutex_die:可能处理等待者退出场景
//__ww_mutex_wound:实现 "wound-wait"(伤害 - 等待)死锁避免策略
if (__ww_mutex_die(lock, cur, ww_ctx, wake_q) ||
__ww_mutex_wound(lock, cur->ww_ctx, ww_ctx, wake_q))
break;//一旦上述两个函数有一个返回真,就跳出循环
}
}
//主要功能是在成功获取 ww_mutex 锁后进行状态记录和调试检查。
static __always_inline void
ww_mutex_lock_acquired(struct ww_mutex *ww, struct ww_acquire_ctx *ww_ctx)
{
#ifdef DEBUG_WW_MUTEXES
/*
* If this WARN_ON triggers, you used ww_mutex_lock to acquire,
* but released with a normal mutex_unlock in this call.
*
* This should never happen, always use ww_mutex_unlock.
*/
DEBUG_LOCKS_WARN_ON(ww->ctx);//检查ww->ctx是否已存在,防止用普通mutex_unlock释放 ww_mutex 锁
/*
* Not quite done after calling ww_acquire_done() ?
*/
//检查ww_ctx->done_acquire状态,确保与ww_acquire_done()调用逻辑一致
DEBUG_LOCKS_WARN_ON(ww_ctx->done_acquire);
//处理竞争锁情况,验证竞争锁的一致性,确保在处理 - EDEADLK 错误后正确解锁其他资源
if (ww_ctx->contending_lock) {
/*
* After -EDEADLK you tried to
* acquire a different ww_mutex? Bad!
*/
DEBUG_LOCKS_WARN_ON(ww_ctx->contending_lock != ww);
/*
* You called ww_mutex_lock after receiving -EDEADLK,
* but 'forgot' to unlock everything else first?
*/
DEBUG_LOCKS_WARN_ON(ww_ctx->acquired > 0);
ww_ctx->contending_lock = NULL;
}
/*
* Naughty, using a different class will lead to undefined behavior!
*/
//验证上下文与锁的 ww_class 匹配,防止不同类别锁混用导致未定义行为
DEBUG_LOCKS_WARN_ON(ww_ctx->ww_class != ww->ww_class);
#endif
//增加上下文中已获取锁的计数(ww_ctx->acquired++)
ww_ctx->acquired++;
//记录当前锁与上下文的关联(ww->ctx = ww_ctx)
ww->ctx = ww_ctx;
这里用到了两种策略:wait-die 和 wound-wait 是数据库并发控制中用于解决死锁问题的两种经典策略,主要应用于多事务同时请求锁(如行级锁)的场景。它们通过基于事务优先级的规则来决定事务是等待还是终止,从而避免死锁的产生。
核心背景:死锁的成因
当多个事务相互持有对方需要的锁,并等待对方释放时,就会形成死锁。例如:
- 事务 T1 持有资源 R1 的锁,等待获取 R2 的锁;
- 事务 T2 持有资源 R2 的锁,等待获取 R1 的锁;
此时 T1 和 T2 相互等待,陷入死锁。
wait-die 和 wound-wait 均通过事务优先级(通常是事务的启动时间,早启动的事务优先级更高)来制定规则,让其中一个事务放弃等待,从而打破死锁。
1. wait-die(等待-死亡)策略
规则:低优先级事务等待,高优先级事务终止低优先级事务。
具体逻辑:
当事务 T1 请求事务 T2 已持有的锁时:
- 若 T1 的优先级 高于 T2(T1 启动更早):T1 不等待,直接终止(杀死)T2,T2 释放锁后,T1 获取锁继续执行。(T2 被“杀死”后可重试)
- 若 T1 的优先级 低于 T2(T1 启动更晚):T1 选择等待,直到 T2 释放锁。
特点:
- 高优先级事务不会等待低优先级事务,避免了高优先级事务被“饿死”。
- 低优先级事务可能被多次终止(如果反复遇到更高优先级的事务),但逻辑简单,实现成本低。
2. wound-wait(伤害-等待)策略
规则:高优先级事务等待,低优先级事务终止自己。
具体逻辑:
当事务 T1 请求事务 T2 已持有的锁时:
- 若 T1 的优先级 高于 T2:T1 不终止 T2,而是选择等待 T2 释放锁。
- 若 T1 的优先级 低于 T2:T1 主动终止(“伤害”自己),释放已持有的锁,让 T2 继续执行。(T1 被终止后可重试)
特点:
- 低优先级事务主动牺牲,避免了高优先级事务被终止的情况。
- 高优先级事务可能因等待低优先级事务而延迟,但减少了事务的终止次数(尤其是高优先级事务的稳定性更好)。
批量唤醒
//解锁原始自旋锁、恢复中断状态并处理唤醒
static inline
void raw_spin_unlock_irqrestore_wake(raw_spinlock_t *lock, unsigned long flags,
struct wake_q_head *wake_q)
{
guard(preempt)();//内核中的抢占保护机制,确保解锁过程不被抢占
raw_spin_unlock_irqrestore(lock, flags);//解锁自旋锁并恢复之前保存的中断状态
if (wake_q) {
wake_up_q(wake_q);//唤醒队列中的等待进程
wake_q_init(wake_q);//重新初始化唤醒队列
}
}
//唤醒通过wake_q_head结构管理的一系列任务(进程),将它们从等待状态转为可运行状态。
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {//从等待队列头部(head->first)开始遍历所有节点
struct task_struct *task;
//使用container_of宏从队列节点反向获取包含它的task_struct(进程描述符)
task = container_of(node, struct task_struct, wake_q);
node = node->next;
/* pairs with cmpxchg_relaxed() in __wake_q_add() */
//通过WRITE_ONCE原子操作清除任务的队列指针,确保并发安全
WRITE_ONCE(task->wake_q.next, NULL);
/* Task can safely be re-inserted now. */
/*
* wake_up_process() executes a full barrier, which pairs with
* the queueing in wake_q_add() so as not to miss wakeups.
*/
//调用wake_up_process()实际唤醒进程
wake_up_process(task);
//调用put_task_struct()减少进程的引用计数,完成资源清理
put_task_struct(task);
}
}
int wake_up_process(struct task_struct *p)
{
return try_to_wake_up(p, TASK_NORMAL, 0);
}
int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
guard(preempt)();
int cpu, success = 0;
wake_flags |= WF_TTWU;
//函数分为两大核心场景:唤醒当前任务(p == current) 和
//唤醒其他任务(跨 CPU / 远程任务),逻辑围绕 “状态校验→锁保护→唤醒操作” 展开。
if (p == current) {
/*
* We're waking current, this means 'p->on_rq' and 'task_cpu(p)
* == smp_processor_id()'. Together this means we can special
* case the whole 'p->on_rq && ttwu_runnable()' case below
* without taking any locks.
*
* Specifically, given current runs ttwu() we must be before
* schedule()'s block_task(), as such this must not observe
* sched_delayed.
*
* In particular:
* - we rely on Program-Order guarantees for all the ordering,
* - we're serialized against set_special_state() by virtue of
* it disabling IRQs (this allows not taking ->pi_lock).
*/
WARN_ON_ONCE(p->se.sched_delayed);
if (!ttwu_state_match(p, state, &success))
goto out;
trace_sched_waking(p);
ttwu_do_wakeup(p);
goto out;
}
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with smp_store_mb()
* in set_current_state() that the waiting thread does.
*/
scoped_guard (raw_spinlock_irqsave, &p->pi_lock) {
smp_mb__after_spinlock();
if (!ttwu_state_match(p, state, &success))
break;
trace_sched_waking(p);
/*
* Ensure we load p->on_rq _after_ p->state, otherwise it would
* be possible to, falsely, observe p->on_rq == 0 and get stuck
* in smp_cond_load_acquire() below.
*
* sched_ttwu_pending() try_to_wake_up()
* STORE p->on_rq = 1 LOAD p->state
* UNLOCK rq->lock
*
* __schedule() (switch to task 'p')
* LOCK rq->lock smp_rmb();
* smp_mb__after_spinlock();
* UNLOCK rq->lock
*
* [task p]
* STORE p->state = UNINTERRUPTIBLE LOAD p->on_rq
*
* Pairs with the LOCK+smp_mb__after_spinlock() on rq->lock in
* __schedule(). See the comment for smp_mb__after_spinlock().
*
* A similar smp_rmb() lives in __task_needs_rq_lock().
*/
smp_rmb();
if (READ_ONCE(p->on_rq) && ttwu_runnable(p, wake_flags))
break;
#ifdef CONFIG_SMP
/*
* Ensure we load p->on_cpu _after_ p->on_rq, otherwise it would be
* possible to, falsely, observe p->on_cpu == 0.
*
* One must be running (->on_cpu == 1) in order to remove oneself
* from the runqueue.
*
* __schedule() (switch to task 'p') try_to_wake_up()
* STORE p->on_cpu = 1 LOAD p->on_rq
* UNLOCK rq->lock
*
* __schedule() (put 'p' to sleep)
* LOCK rq->lock smp_rmb();
* smp_mb__after_spinlock();
* STORE p->on_rq = 0 LOAD p->on_cpu
*
* Pairs with the LOCK+smp_mb__after_spinlock() on rq->lock in
* __schedule(). See the comment for smp_mb__after_spinlock().
*
* Form a control-dep-acquire with p->on_rq == 0 above, to ensure
* schedule()'s deactivate_task() has 'happened' and p will no longer
* care about it's own p->state. See the comment in __schedule().
*/
smp_acquire__after_ctrl_dep();
/*
* We're doing the wakeup (@success == 1), they did a dequeue (p->on_rq
* == 0), which means we need to do an enqueue, change p->state to
* TASK_WAKING such that we can unlock p->pi_lock before doing the
* enqueue, such as ttwu_queue_wakelist().
*/
WRITE_ONCE(p->__state, TASK_WAKING);
/*
* If the owning (remote) CPU is still in the middle of schedule() with
* this task as prev, considering queueing p on the remote CPUs wake_list
* which potentially sends an IPI instead of spinning on p->on_cpu to
* let the waker make forward progress. This is safe because IRQs are
* disabled and the IPI will deliver after on_cpu is cleared.
*
* Ensure we load task_cpu(p) after p->on_cpu:
*
* set_task_cpu(p, cpu);
* STORE p->cpu = @cpu
* __schedule() (switch to task 'p')
* LOCK rq->lock
* smp_mb__after_spin_lock() smp_cond_load_acquire(&p->on_cpu)
* STORE p->on_cpu = 1 LOAD p->cpu
*
* to ensure we observe the correct CPU on which the task is currently
* scheduling.
*/
if (smp_load_acquire(&p->on_cpu) &&
ttwu_queue_wakelist(p, task_cpu(p), wake_flags))
break;
/*
* If the owning (remote) CPU is still in the middle of schedule() with
* this task as prev, wait until it's done referencing the task.
*
* Pairs with the smp_store_release() in finish_task().
*
* This ensures that tasks getting woken will be fully ordered against
* their previous state and preserve Program Order.
*/
smp_cond_load_acquire(&p->on_cpu, !VAL);
cpu = select_task_rq(p, p->wake_cpu, &wake_flags);
if (task_cpu(p) != cpu) {
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
wake_flags |= WF_MIGRATED;
psi_ttwu_dequeue(p);
set_task_cpu(p, cpu);
}
#else
cpu = task_cpu(p);
#endif /* CONFIG_SMP */
ttwu_queue(p, cpu, wake_flags);
}
out:
if (success)
ttwu_stat(p, task_cpu(p), wake_flags);
return success;
}
try_to_wake_up 是 Linux 内核调度器的核心函数之一,作用是尝试将指定睡眠状态的任务(进程/线程)唤醒,使其进入可运行状态并参与 CPU 调度。以下从核心逻辑、关键分支、核心机制三方面简要解析:
一、函数核心参数与返回值
struct task_struct *p:要唤醒的目标任务结构体(内核中描述任务的核心数据结构,包含任务状态、CPU 亲和性、调度信息等)。unsigned int state:唤醒条件——仅当目标任务的当前状态与state匹配时才执行唤醒(避免误唤醒不匹配状态的任务,如仅唤醒TASK_INTERRUPTIBLE状态的任务,而非TASK_UNINTERRUPTIBLE)。int wake_flags:唤醒标志,控制唤醒过程的细节(如是否允许任务迁移到其他 CPU、是否标记唤醒统计等,函数内默认添加WF_TTWU标志表示“这是一次try_to_wake_up触发的唤醒”)。- 返回值
int success:1表示唤醒成功,0表示唤醒失败(如任务状态不匹配、任务已在运行队列等)。
二、核心逻辑分支解析
函数分为两大核心场景:唤醒当前任务(p == current) 和 唤醒其他任务(跨 CPU/远程任务),逻辑围绕“状态校验→锁保护→唤醒操作”展开。
1. 特殊场景:唤醒当前任务(p == current)
当前任务(正在执行 try_to_wake_up 的任务)理论上已在运行队列或正在运行,无需复杂的跨 CPU 操作,逻辑简化:
- 状态校验:通过
ttwu_state_match检查任务状态是否与state匹配,不匹配则直接返回失败(success=0)。 - 跳过锁保护:当前任务的
on_rq(是否在运行队列)和task_cpu(p)(所属 CPU)均为已知(当前 CPU),无需加锁避免竞争。 - 执行唤醒:调用
ttwu_do_wakeup完成唤醒(本质是确保任务处于可运行状态并更新调度统计),并通过trace_sched_waking输出调度跟踪日志(用于调试/性能分析)。
2. 常规场景:唤醒其他任务(跨 CPU/远程任务)
唤醒非当前任务时,需处理多 CPU 竞争、任务状态一致性、CPU 迁移等问题,核心步骤如下:
(1)锁保护:避免并发竞争
通过 scoped_guard (raw_spinlock_irqsave, &p->pi_lock) 加锁:
p->pi_lock:任务的优先级继承锁(用于解决实时任务的优先级反转问题),此处主要用于保护任务状态(__state)、on_rq(运行队列标志)等关键字段的并发访问。raw_spinlock_irqsave:禁用本地中断并加自旋锁,确保锁持有期间无中断干扰(避免死锁,因为中断可能触发其他调度操作)。
(2)状态与运行队列校验
- 状态匹配校验:再次调用
ttwu_state_match检查任务状态(加锁后校验,确保状态未被并发修改),不匹配则解锁并返回失败。 - 运行队列校验:
- 通过
smp_rmb()内存屏障确保:先读取任务状态(p->__state),再读取p->on_rq(避免 CPU 指令重排序导致误判“任务不在运行队列”)。 - 若
p->on_rq为真(任务已在运行队列)且ttwu_runnable判定任务已可运行,则无需重复唤醒,解锁返回。
- 通过
(3)多 CPU 场景处理(CONFIG_SMP 开启时)
若内核支持多 CPU,需处理“任务正在其他 CPU 调度中”的情况:
- 标记唤醒中状态:将任务状态设为
TASK_WAKING(避免其他操作误处理该任务,同时允许提前解锁pi_lock,减少锁持有时间)。 - 远程 CPU 唤醒优化:
- 若目标任务正在其他 CPU 上执行调度(
p->on_cpu为真),调用ttwu_queue_wakelist将任务加入远程 CPU 的唤醒列表,并通过 IPI(跨 CPU 中断)通知远程 CPU 处理,避免当前 CPU 自旋等待(提升性能)。 - 若无法通过唤醒列表优化,则通过
smp_cond_load_acquire自旋等待,直到目标任务的on_cpu变为0(确保远程 CPU 已完成对该任务的调度操作,避免并发修改)。
- 若目标任务正在其他 CPU 上执行调度(
- CPU 迁移决策:调用
select_task_rq选择合适的 CPU(结合任务的 CPU 亲和性、负载均衡等策略),若目标 CPU 与当前所属 CPU 不同,则:- 若任务处于 I/O 等待状态(
p->in_iowait),停止 I/O 等待统计。 - 标记
WF_MIGRATED标志,表示任务将迁移,并调用set_task_cpu修改任务的所属 CPU。
- 若任务处于 I/O 等待状态(
(4)入队唤醒
最后调用 ttwu_queue 将任务加入目标 CPU 的运行队列(或唤醒列表),完成唤醒的核心操作(后续由调度器从运行队列中选择任务执行)。
三、核心机制与设计思路
内存屏障与并发安全:
- 大量使用
smp_rmb()、smp_acquire__after_ctrl_dep()等内存屏障,避免多 CPU 下的指令重排序导致的状态误判(如确保“先读状态、再读运行队列标志”的顺序)。 - 自旋锁(
pi_lock)+ 中断禁用,确保关键字段(状态、CPU 归属)的并发修改安全。
- 大量使用
性能优化:
- 区分“当前任务”和“其他任务”,简化当前任务的唤醒逻辑,减少锁开销。
- 多 CPU 场景下通过“唤醒列表 + IPI”替代自旋等待,减少 CPU 空转。
状态一致性:
- 唤醒前严格校验任务状态(
ttwu_state_match),避免误唤醒;唤醒中标记TASK_WAKING,防止并发操作干扰。
- 唤醒前严格校验任务状态(
锁交接
static inline bool __mutex_trylock_or_handoff(struct mutex *lock, bool handoff)
{
return !__mutex_trylock_common(lock, handoff);
}
static inline struct task_struct *__mutex_trylock_common(struct mutex *lock, bool handoff)
{
unsigned long owner, curr = (unsigned long)current;//当前任务的指针(转换为 unsigned long)
owner = atomic_long_read(&lock->owner);//存储锁当前的持有者信息(包含任务指针和标志位)
for (;;) { /* must loop, can race against a flag */
unsigned long flags = __owner_flags(owner);//通过__owner_flags 和位运算分离出标志位和任务指针
unsigned long task = owner & ~MUTEX_FLAGS;
if (task) {//若已有持有者(task 非空)
if (flags & MUTEX_FLAG_PICKUP) {//处理 MUTEX_FLAG_PICKUP 标志(锁交接场景)
if (task != curr)
break;
//清除flags中与MUTEX_FLAG_PICKUP对应的位,同时保留 flags 中原有的其他标志位。
flags &= ~MUTEX_FLAG_PICKUP;
} else if (handoff) {
//处理 MUTEX_FLAG_HANDOFF 标志(锁传递机制)
if (flags & MUTEX_FLAG_HANDOFF)
break;
//将 MUTEX_FLAG_HANDOFF 这个标志位添加到 flags 变量中,同时保留 flags 中原有的其他标志位。
flags |= MUTEX_FLAG_HANDOFF;
} else {
break;
}
} else {//若锁未被持有(task 为空)
//检查标志位合法性
MUTEX_WARN_ON(flags & (MUTEX_FLAG_HANDOFF | MUTEX_FLAG_PICKUP));
task = curr;//将当前任务设为潜在持有者
}
//使用 atomic_long_try_cmpxchg_acquire 尝试原子更新锁的持有者
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &owner, task | flags)) {
if (task == curr)
return NULL;//成功获取锁时返回 NULL,否则返回当前持有者
break;
}
}
return __owner_task(owner);
}
这里涉及到了两个概念,分别是锁交接和锁传递,在并发编程和数据库事务管理中,锁交接(Lock handoff) 和 锁传递(lock passing) 是两种与锁的持有权转移相关的机制,用于优化并发性能或解决特定场景下的锁竞争问题。它们的核心思想是通过安全地转移锁的持有权,减少锁的释放与重新获取带来的开销,或避免不必要的等待。
1. 锁交接(Lock Handoff)
定义:当一个事务(或线程)完成对资源的操作后,不直接释放锁,而是将锁的持有权定向传递给另一个正在等待该锁的特定事务(或线程),而非让所有等待者竞争。
适用场景:
- 数据库中,当一个事务释放行锁时,直接将锁交给下一个等待该锁的事务(通常是优先级较高或等待时间最长的事务)。
- 并发编程中,线程完成任务后,将锁的持有权转交给排队等待的线程。
优势:
- 减少锁的竞争开销:避免了锁释放后多个等待者同时争抢导致的上下文切换或调度开销。
- 提高公平性:可以按等待顺序或优先级定向传递,避免某些线程长期饥饿。
- 提升效率:跳过“释放锁→唤醒所有等待者→重新竞争”的过程,直接交接锁,减少延迟。
示例:
数据库中,事务T1持有行R的排他锁,事务T2和T3正在等待该锁。当T1完成后,不释放锁让T2和T3竞争,而是直接将锁交给等待队列中优先级最高的T2,T2无需重新申请即可继续执行。
2. 锁传递(Lock Passing)
定义:在特定协作场景下(如父子线程、事务嵌套或分布式系统中),一个线程(或事务)将自己持有的锁主动传递给另一个协作实体,接收方直接获得锁的持有权,原持有方则释放锁。
适用场景:
- 线程池中,父线程将任务及相关资源的锁传递给子线程,避免子线程重新申请锁。
- 分布式事务中,跨节点传递锁的持有权(需配合分布式锁管理器)。
- 嵌套事务中,外层事务将锁传递给内层事务,确保资源访问的连续性。
优势:
- 避免协作实体间的锁竞争:协作双方通过显式传递锁,减少重复申请/释放的开销。
- 保证操作的原子性:在传递过程中,锁的持有权无缝转移,避免中间状态被其他实体干扰。
示例:
线程A持有资源R的锁,完成部分操作后,需要线程B继续处理同一资源。线程A通过锁传递机制将R的锁直接交给线程B,线程B无需等待即可操作R,线程A则释放锁。
两者的核心区别
| 维度 | 锁交接(Lock Handoff) | 锁传递(Lock Passing) |
|---|---|---|
| 触发时机 | 锁的原持有方完成操作后,被动选择等待者交接 | 原持有方主动将锁传递给协作实体(如子线程、嵌套事务) |
| 目标对象 | 不确定的等待者(通常按规则选择,如优先级、顺序) | 明确的协作对象(预先确定的线程或事务) |
| 典型场景 | 多个竞争实体争抢同一锁(如数据库行锁等待队列) | 协作实体间的资源交接(如线程协作、分布式事务) |
总结
锁交接和锁传递均通过优化锁的持有权转移方式,减少并发场景下的锁竞争开销。其中:
- 锁交接侧重于“公平高效地分配锁给等待者”,适用于多实体竞争同一资源的场景;
- 锁传递侧重于“协作实体间的锁无缝转移”,适用于已知协作关系的场景。
两种机制的最终目的都是提升并发效率,减少不必要的等待和资源争抢。
解锁
void __sched mutex_unlock(struct mutex *lock)
{
#ifndef CONFIG_DEBUG_LOCK_ALLOC
if (__mutex_unlock_fast(lock))
return;
#endif
__mutex_unlock_slowpath(lock, _RET_IP_);
}
EXPORT_SYMBOL(mutex_unlock);
static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigned long ip)
{
struct task_struct *next = NULL;
DEFINE_WAKE_Q(wake_q);
unsigned long owner;
unsigned long flags;
mutex_release(&lock->dep_map, ip);
/*
* Release the lock before (potentially) taking the spinlock such that
* other contenders can get on with things ASAP.
*
* Except when HANDOFF, in that case we must not clear the owner field,
* but instead set it to the top waiter.
*/
owner = atomic_long_read(&lock->owner);
for (;;) {
MUTEX_WARN_ON(__owner_task(owner) != current);
MUTEX_WARN_ON(owner & MUTEX_FLAG_PICKUP);
if (owner & MUTEX_FLAG_HANDOFF)
break;
if (atomic_long_try_cmpxchg_release(&lock->owner, &owner, __owner_flags(owner))) {
if (owner & MUTEX_FLAG_WAITERS)
break;
return;
}
}
raw_spin_lock_irqsave(&lock->wait_lock, flags);
debug_mutex_unlock(lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter =
list_first_entry(&lock->wait_list,
struct mutex_waiter, list);
next = waiter->task;
debug_mutex_wake_waiter(lock, waiter);
wake_q_add(&wake_q, next);
}
if (owner & MUTEX_FLAG_HANDOFF)
__mutex_handoff(lock, next);
raw_spin_unlock_irqrestore_wake(&lock->wait_lock, flags, &wake_q);
}
我们通过前面的代码已经知道当没有锁竞争时就会走快速路径,有锁竞争(加锁时需等待、解锁时需唤醒等待者)时就会走慢路径,不过最终加解锁的操作是一致的,因此我们这里只需关注慢路径即可。
汇总
多线程获取锁过程中锁的状态变化及处理机制分析
1. 锁的初始状态
- 空闲状态:
mutex->owner = 0(OSQ_UNLOCKED_VAL),表示锁未被持有。 - 等待队列:
mutex->wait_list为空,osq.tail标记为解锁状态。
2. 加锁流程(快速路径)
步骤:
- 原子操作尝试获取锁
- 通过
atomic_long_try_cmpxchg_acquire()尝试将mutex->owner从0设置为当前线程的地址(curr)。 - 成功:锁状态变为 已锁定(
owner = current),线程直接获得锁。 - 失败:锁已被其他线程持有,进入慢速路径。
- 通过
关键机制:
- 原子性:通过 CPU 指令(如
cmpxchg)确保多线程竞争下的原子操作。 - 内存屏障:
acquire语义防止后续指令重排序到锁获取之前。
3. 加锁流程(慢速路径)
当快速路径失败时,线程进入慢速路径:
阶段 1: 二次尝试与乐观自旋
- 禁用抢占:
preempt_disable()避免被其他线程打断。 - 锁依赖跟踪:记录锁获取信息(用于死锁检测)。
- 二次尝试:
- 再次调用
__mutex_trylock()尝试获取锁(可能锁已释放)。 - 若失败,尝试 乐观自旋(
mutex_optimistic_spin):- 检查锁持有者是否正在运行(通过
owner字段)。 - 若持有者即将释放锁,当前线程自旋等待(避免睡眠开销)。
- 自旋成功则直接获得锁。
- 检查锁持有者是否正在运行(通过
- 再次调用
阶段 2: 加入等待队列
- 获取队列锁:通过
raw_spin_lock_irqsave()锁定mutex->wait_lock,保护等待队列。 - 初始化等待节点:
- 创建
mutex_waiter结构,关联当前线程。 - 根据锁类型(普通/Wound-Wait)将节点加入队列:
- 普通锁:按 FIFO 顺序插入
wait_list尾部。 - Wound-Wait 锁:按优先级插入(避免死锁)。
- 普通锁:按 FIFO 顺序插入
- 创建
- 设置线程状态:
- 标记线程为
TASK_UNINTERRUPTIBLE(不可中断睡眠)。
- 标记线程为
阶段 3: 阻塞与唤醒
- 循环等待:
- 释放
wait_lock,调用schedule_preempt_disabled()让出 CPU,线程进入睡眠。 - 被唤醒时,检查是否为队列首节点(优先获取锁)。
- 释放
- 锁释放时的唤醒:
- 锁持有者释放锁时,唤醒等待队列中的首个线程。
- 被唤醒线程重新尝试获取锁(通过
__mutex_trylock_or_handoff)。
阶段 4: 获取锁后的清理
- 更新锁状态:
- 设置
mutex->owner = current。 - 若为 Wound-Wait 锁,更新上下文(
ww_ctx)。
- 设置
- 移除等待节点:
- 从
wait_list中移除当前线程的mutex_waiter。
- 从
- 释放队列锁:
- 通过
raw_spin_unlock_irqrestore_wake()解锁wait_lock,并唤醒其他可能线程。
- 通过
- 启用抢占:
preempt_enable()。
4. 锁状态变化总结
| 阶段 | 锁状态 | 关键操作 |
|---|---|---|
| 初始状态 | owner = 0,wait_list 为空 |
- |
| 快速路径成功 | owner = current |
原子操作 cmpxchg |
| 慢速路径(入队) | owner 不变,wait_list 新增节点 |
加入等待队列,线程睡眠 |
| 锁释放后唤醒 | owner = 0 → owner = new_thread |
唤醒队列首节点,原子操作获取锁 |
| 获取锁完成 | owner = current,wait_list 更新 |
移除等待节点,更新锁状态 |
5. 流程示意图
快速路径
│
├─ 成功 → 获得锁(owner = current)
│
└─ 失败 → 慢速路径
│
├─ 二次尝试/乐观自旋 → 成功 → 获得锁
│
└─ 失败 → 加入等待队列 → 睡眠 → 被唤醒 → 获取锁 → 清理队列
多线程释放锁过程分析
1. 锁的初始状态
- 已锁定状态:锁被当前线程持有,
owner字段包含当前线程地址和状态标志 - 等待队列:可能存在等待线程(通过
MUTEX_FLAG_WAITERS标志标识)
2. 解锁流程(快速路径)
核心逻辑:
- 原子操作尝试释放:
- 使用
atomic_long_try_cmpxchg_release()原子操作 - 尝试将
owner从当前线程值直接置为0(空闲状态)
- 使用
- 成功条件:
- 无等待线程(无
MUTEX_FLAG_WAITERS标志) - 无锁交接需求(无
MUTEX_FLAG_HANDOFF标志)
- 无等待线程(无
- 结果:
- 锁状态立即变为空闲(
owner=0) - 无需唤醒其他线程,直接返回
- 锁状态立即变为空闲(
优化意义:
- 无竞争场景下仅需1条原子指令
- 避免获取队列锁的开销
- 内存屏障(release语义)确保临界区操作完成
3. 解锁流程(慢速路径)
当存在等待线程或需要锁交接时进入慢速路径:
阶段1:安全释放所有权
- 验证持有者身份:
- 调试检查确保只有锁持有者能解锁
- 防止非法解锁操作
- 处理特殊标志:
MUTEX_FLAG_HANDOFF:标记需要直接交接锁MUTEX_FLAG_WAITERS:标记存在等待线程
- 原子更新状态:
- 清除当前线程信息,保留标志位
- 循环尝试直到成功更新
阶段2:唤醒等待线程
- 获取队列锁:
- 使用
raw_spin_lock_irqsave()锁定等待队列 - 保护队列操作免受并发干扰
- 使用
- 选择唤醒对象:
- 从等待队列头部选取第一个等待者(FIFO顺序)
- 符合锁的公平性原则
- 加入唤醒队列:
- 使用
wake_q_add()将唤醒任务加入批量唤醒队列 - 避免立即唤醒造成的锁竞争
- 使用
阶段3:锁交接处理
- 特殊场景:当检测到
MUTEX_FLAG_HANDOFF标志时 - 直接交接:将锁所有权赋予等待队列首位的线程
- 避免竞争:跳过常规竞争流程,减少上下文切换
阶段4:完成释放
- 释放队列锁:解除对等待队列的保护
- 批量唤醒:通过
wake_up_q()唤醒所有待唤醒线程 - 状态更新:
- 无交接:锁变为空闲状态(
owner=0) - 有交接:锁由新线程持有(
owner=new_task)
- 无交接:锁变为空闲状态(
4. 锁状态变化过程
| 阶段 | 锁状态 | 关键操作 |
|---|---|---|
| 初始状态 | `owner = current | flags` |
| 快速路径成功 | owner = 0 |
原子操作清除owner |
| 慢速路径(无等待) | owner = 0 |
清除owner,保留标志位 |
| 慢速路径(有等待) | owner = next_task(或0) |
唤醒队列首节点 |
| 锁交接场景 | `owner = next_task | flags` |
5. 流程示意图
解锁开始
│
├─ 快速路径尝试 → 成功 → 锁释放完成
│
└─ 失败 → 慢速路径
│
├─ 安全释放所有权(处理标志位)
│
├─ 获取队列锁 → 选取首个等待者 → 加入唤醒队列
│
├─ 检测交接标志 → 执行锁交接
│
└─ 释放队列锁 → 批量唤醒等待者
整合分析
| 关键处理机制类别 | 具体机制名称 | 核心说明 |
|---|---|---|
| 锁获取与竞争处理相关机制 | 1. 乐观自旋(Optimistic Spinning) | - 目的:减少上下文切换开销(适用于锁持有时间短的场景) - 触发条件:锁持有者正在运行,且无更高优先级线程竞争 - 实现:通过 osq 队列管理自旋线程,避免缓存行颠簸 |
| 2. 等待队列管理 | - 数据结构:基于双向链表(list_head)实现 FIFO 队列 - 保护机制:通过 wait_lock(自旋锁)确保队列操作的原子性 |
|
| 3. Wound-Wait 死锁避免 | - 场景:用于嵌套锁获取(如 ww_mutex 场景) - 机制:① 高优先级线程可“伤害”(wound)低优先级线程,强制其释放锁;② 等待节点按优先级插入队列,避免循环等待 |
|
| 4. 锁依赖跟踪(Lockdep) | - 目的:检测死锁和锁使用违规 - 实现:通过 lockdep_map 记录锁的获取顺序和上下文 |
|
| 5. 中断处理 | - 禁用中断:操作等待队列时通过 irqsave 禁用中断,避免并发问题 - 信号处理:若线程状态为 TASK_INTERRUPTIBLE,信号可中断等待(返回 -EINTR) |
|
| 锁释放与状态管理相关机制 | 1. 标志位语义 | - WAITERS:标记存在等待线程,避免不必要的唤醒检查 - HANDOFF:标记需要直接交接锁,优化特定场景性能 - PICKUP:调试用标志,标记等待线程准备接收锁 |
| 2. 唤醒优化 | - 精准唤醒:只唤醒等待队列首节点,保证公平性 - 批量处理:延迟唤醒减少锁争用 - 无竞争快速返回:无等待线程时直接退出解锁流程 |
|
| 3. 锁交接机制 | - 核心操作:直接将锁的所有权转移给指定线程 - 优势:避免新线程重新竞争锁,减少开销 - 典型场景:优先级继承、死锁避免 |
|
| 4. 安全防护 | - 身份验证:严格验证解锁者身份(确保当前线程为锁持有者) - 状态检测:通过调试断言检测非法锁状态 - 原子性保证:采用原子操作确保锁状态转换的一致性 |
补充说明
- 锁状态转换逻辑:整体通过原子操作(如
atomic_long_try_cmpxchg_release)和队列管理实现“空闲(owner=0)→ 锁定(owner=current)→ 释放(唤醒等待者/交接锁)”的状态流转。 - 竞争处理分层:无竞争时走“快速路径”(单原子指令获取/释放锁);有竞争时结合“乐观自旋”(减少睡眠)和“等待队列”(保证公平性)平衡性能与正确性。
- 性能优化核心:乐观自旋减少上下文切换、等待队列锁(wait_lock)精细化控制并发、批量唤醒避免“惊群”,共同实现低竞争场景高效、高竞争场景稳定。
两段代码均操作同一个 struct mutex 结构体实例(互斥锁的核心表示),下面的关键字段在两者间传递状态:
| 字段名 | 加锁慢路径(__mutex_lock_common)中的操作 |
解锁慢路径(__mutex_unlock_slowpath)中的操作 |
|---|---|---|
lock->owner |
加锁成功后,设置为当前线程(current);标记锁持有者 |
解锁时,检查持有者是否为当前线程;更新为“无持有者”或移交锁 |
lock->wait_lock |
加锁时,通过该自旋锁保护等待队列(wait_list)的修改 |
解锁时,通过该自旋锁安全访问/修改等待队列 |
lock->wait_list |
加锁失败时,将当前线程的 mutex_waiter 节点加入该队列 |
解锁时,检查该队列是否非空,唤醒第一个等待线程 |
MUTEX_FLAG_HANDOFF |
加锁时,可能设置“锁交接”标记(用于直接移交锁给等待者) | 解锁时,检查该标记,通过 __mutex_handoff 完成锁移交 |
加锁慢路径负责 “把线程放进等待队列”,解锁慢路径负责 “把线程从等待队列里唤醒,二者共同完成 “竞争 - 等待 - 唤醒” 的核心流程:
| 维度 | __mutex_lock_slowpath 系列(加锁慢路径) |
__mutex_unlock_slowpath(解锁慢路径) |
|---|---|---|
| 核心职责 | 处理锁竞争:线程加锁失败时,安全加入等待队列并阻塞 | 处理锁释放:锁持有者释放时,安全唤醒等待队列中的线程 |
| 依赖的状态 | 读取 lock->owner/lock->wait_list,修改等待队列 |
读取 lock->wait_list/lock->owner,修改持有者和唤醒队列 |
| 逻辑衔接 | “入队等待”的终点,为解锁的“唤醒”提供等待队列 | “唤醒出队”的起点,消费加锁时构建的等待队列 |
| 共同目标 | 确保 mutex 在有竞争场景下的正确性、高效性(减少上下文切换) | 确保 mutex 在有竞争场景下的正确性、高效性(减少上下文切换) |
两段代码还在高级机制和调试体系上保持一致:
- 锁交接(Handoff):
加锁时,若线程是等待队列的第一个节点,可能触发 “锁交接”(避免唤醒后再次竞争);解锁时,__mutex_unlock_slowpath 会检查 MUTEX_FLAG_HANDOFF 标记,调用 __mutex_handoff 直接将锁移交第一个等待线程,跳过再次竞争,提升效率。 - 调试与跟踪:
两者均调用同一套调试接口(如 mutex_acquire_nest/mutex_release 跟踪锁依赖、debug_mutex_* 检查锁状态)和竞争跟踪接口(trace_contention_begin/trace_contention_end),确保调试信息的一致性。
回答
这个问题的本质就是别的线程可以在另一个线程持有锁的时候通过修改owner字段为自己让这个锁归自己所有吗?因为锁是共享资源,锁的获取本质也是把owner字段的内容修改成线程自己,因为所有线程想访问资源都要经过获取锁这一步。
在正常的锁设计与使用逻辑中,其他线程不可以通过直接修改owner字段的方式“抢占”另一个线程已持有的锁。这种强行修改owner的行为会彻底破坏锁的安全性、原子性与状态一致性,导致锁机制失效并引发严重的并发问题。以下从锁的设计原理、操作约束和潜在风险三方面详细解释:
一、核心原因:owner字段的操作被严格限制为“原子且符合协议”
锁的owner字段(用于标记当前持有者)并非普通变量,其读写操作被原子指令(如CAS、原子交换、原子比较等)和锁的核心协议严格保护,本质是为了确保“锁的获取/释放是唯一且有序的”。具体约束包括:
1. owner的修改必须通过“原子操作”实现
正常情况下,线程获取锁时对owner的修改(如从“空闲”设为“自己”),依赖硬件提供的原子指令(如x86的cmpxchg、ARM的LDREX/STREX),确保同一时间只有一个线程能成功修改owner。
若线程不通过原子指令,直接暴力修改owner(如强制写入自己的线程ID),会导致竞态条件:例如两个线程同时修改owner,最终可能出现“两个线程都认为自己持有锁”的情况,进而同时进入临界区,引发数据错乱(如变量值被覆盖、链表结构破坏等)。
2. owner的修改必须遵循“锁的获取协议”
锁的设计是一个闭环协议:线程必须通过“请求→检查→竞争(自旋/等待)→确认持有”的合法流程获取锁,而非跳过流程直接修改owner。例如:
- 当锁已被线程A持有时,线程B若想获取锁,会先通过原子操作检查
owner是否为“空闲”; - 若发现
owner是线程A,线程B会进入“乐观自旋”或“等待队列”(而非强行改owner); - 只有当线程A主动释放锁(通过原子操作将
owner设为“空闲”或移交他人),线程B才有机会通过合法流程竞争到锁。
直接修改owner会跳过这个协议,导致锁的“持有者身份”与“实际临界区执行”脱节(比如线程A还在执行临界区,线程B却强行将owner改为自己,两者同时操作共享资源)。
二、锁的防护机制会阻止/检测非法修改owner
为了防止非法修改owner,主流锁实现(如Linux内核的mutex、用户态的pthread_mutex_t)都内置了安全防护逻辑,即使线程尝试强行修改,也会被拦截或触发错误:
1. owner字段的访问权限限制
- 在内核态锁(如Linux
mutex)中,owner通常是struct task_struct *类型(指向当前持有锁的线程结构体),普通线程无法直接访问或修改内核空间的owner变量(需通过内核提供的mutex_lock/mutex_unlock接口操作); - 在用户态锁(如
pthread_mutex_t)中,owner可能被封装在私有结构体中(如GCC的pthread_mutex_t内部包含__data.__owner),且库函数会通过原子操作和断言检测非法修改(例如解锁时若发现owner不是当前线程,会返回EPERM错误)。
2. 锁的一致性检测(如Lockdep、调试断言)
- 之前提到的锁依赖跟踪(Lockdep) 会记录
owner的合法变更路径,若检测到owner被非持有线程修改,会触发调试断言(如内核BUG_ON)或打印错误日志; - 许多锁实现会在调试模式下添加检查:例如解锁时验证“当前线程 ==
owner”,若不满足则直接崩溃(防止非法解锁),同理,非法修改owner也会被这类检查捕获。
三、强行修改owner的严重后果
即使绕过防护机制(如内核态下通过非法内存访问修改owner),强行抢占锁也会导致不可控的并发问题:
- 临界区数据竞争:原持有线程仍在执行临界区(操作共享资源),新“抢占”线程也进入临界区,导致数据被随机覆盖、结构破坏(如链表断链、计数器值异常);
- 锁状态紊乱:锁除了
owner,还有等待队列、标志位(如WAITERS、HANDOFF)等状态。仅修改owner会导致这些状态与owner不一致(例如等待队列中仍有线程等待,但owner已被强行更换),进而引发死锁(等待队列线程永无唤醒机会)或“惊群”(批量唤醒无效线程); - 调试困难:这类非法操作引发的问题(如偶发的数据错乱、死锁)无法通过常规的锁依赖工具(如Lockdep)检测,定位问题会极其困难。
结论
不可以,也不应该通过修改owner字段抢占已被持有的锁。
锁的设计初衷是通过“原子操作+协议约束+安全防护”保证并发安全,强行修改owner会彻底破坏这一基础,导致数据竞争、死锁等严重问题。正常情况下,线程必须通过合法接口(如lock()/unlock()),遵循“空闲则获取、繁忙则等待”的逻辑竞争锁,这是并发编程的核心原则。
从代码的角度回答
锁所有权获取机制分析
核心结论
不可以。其他线程无法在锁被持有时通过直接修改owner字段来获取锁所有权。这是由以下多重保护机制保证的:
1. 原子操作保护
- 关键机制:所有对
owner字段的修改都通过原子操作完成 - 具体实现:
- 加锁时使用
atomic_long_try_cmpxchg_acquire() - 解锁时使用
atomic_long_try_cmpxchg_release()
- 加锁时使用
- 保护效果:
- 确保
owner修改是原子性的(要么完全成功,要么完全失败) - 防止多线程同时修改导致状态不一致
- 确保
2. 状态验证机制
加锁流程验证:
// 快速路径检查 if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr)) // 慢速路径二次验证 if (__mutex_trylock(lock))- 必须验证
owner为0(空闲状态)才能获取锁 - 若
owner非0(已被持有),所有获取尝试都会失败
- 必须验证
解锁流程验证:
// 严格检查解锁者身份 MUTEX_WARN_ON(__owner_task(owner) != current);- 解锁时必须验证当前线程是合法持有者
- 非法解锁操作会触发内核警告
3. 标志位语义约束
owner字段包含三种状态标志:
MUTEX_FLAG_WAITERS(0x01):存在等待线程MUTEX_FLAG_HANDOFF(0x02):需要交接锁MUTEX_FLAG_PICKUP(0x04):等待线程准备接收锁
保护效果:
- 标志位与线程指针共同编码(指针地址低2位用作标志)
- 非持有线程无法正确设置/识别这些标志
- 非法修改会导致状态不一致和操作失败
4. 队列锁保护
- 核心机制:
wait_lock自旋锁保护所有队列操作 - 保护范围:
- 等待队列(
wait_list)的增删改查 - 唤醒操作(
wake_q管理) - 锁交接(
__mutex_handoff)
- 等待队列(
- 工作流程:
raw_spin_lock_irqsave(&lock->wait_lock, flags); // 获取锁 // 临界区操作 raw_spin_unlock_irqrestore_wake(...); // 释放锁+唤醒 - 保护效果:
- 确保等待队列修改的原子性
- 防止并发操作导致队列状态损坏
5. 锁交接机制
唯一合法的所有权转移途径:
- 持有线程设置
MUTEX_FLAG_HANDOFF标志 - 在解锁流程中调用
__mutex_handoff(lock, next) - 原子操作将
owner更新为新线程地址
关键约束:
- 只有当前持有者才能启动交接
- 只能交接给等待队列首位的合法等待者
- 交接过程受
wait_lock保护
攻击场景模拟分析
假设恶意线程尝试直接修改owner:
场景1:快速路径攻击
- 尝试原子操作设置
owner=恶意线程地址 - 结果:因当前
owner≠0(已被持有),cmpxchg操作失败
- 尝试原子操作设置
场景2:绕过验证攻击
- 尝试直接修改内存中的
owner值 - 结果:
- 破坏标志位导致状态不一致
- 后续合法操作触发
MUTEX_WARN_ON警告 - 等待线程无法被正常唤醒
- 尝试直接修改内存中的
场景3:伪造交接
- 尝试设置
MUTEX_FLAG_HANDOFF标志 - 结果:
- 解锁流程会验证
__owner_task(owner)==current - 非持有者操作立即被检测
- 触发内核警告或错误处理
- 解锁流程会验证
- 尝试设置
总结
- 原子操作是基础保护,确保状态修改的完整性
- 状态验证在关键路径全程存在,防止非法获取
- 标志位编码将线程指针与状态绑定,增加伪造难度
- 队列锁保护核心数据结构,确保操作序列化
- 合法所有权转移仅能通过持有者启动的交接流程
这些机制共同构成严密的保护体系,确保:
- 锁所有权始终合法传递
- 非持有线程无法篡改锁状态
- 系统在检测到异常时能安全处理
因此,在多线程环境下,其他线程不可能通过直接修改owner字段来非法获取锁所有权。
C++通过移动语义移交锁控制权
要理解 C++ 中通过移动语义移交锁控制权的原理,核心是要区分两个关键概念:
- 非法抢占:其他线程直接修改锁的
owner字段强行夺权(这是锁设计明确禁止的,会破坏互斥性); - 合法移交:持有锁的线程主动将控制权转移给其他线程,整个过程由锁的封装逻辑(而非外部线程)安全管控。
C++ 的锁控制权移交,本质是后者——通过「锁管理类」的移动语义,实现锁所有权的合法转移,而非外部线程强行修改 owner。下面从「设计原理」「具体实现」「安全保障」三个层面拆解:
一、先明确:C++ 中“移交锁”的不是锁本身,而是“锁的管理权限”
C++ 标准库中,直接代表“互斥锁实体”的类(如 std::mutex、std::recursive_mutex)本身是不可移动、不可复制的——因为它们是“物理锁”,负责维护 owner、等待队列等核心状态,若允许移动,会导致锁的状态混乱(比如多个线程同时关联同一个“移动后的锁”)。
而支持移动语义的是「锁管理类」(如 std::unique_lock、std::scoped_lock 不支持,std::unique_lock 支持)——这类类本身不存储锁的核心状态,仅通过指针/引用关联到一个 std::mutex 实体,并记录“当前是否持有该锁”的状态。
移动语义移交的,正是这个「管理类的权限」:持有锁的线程将自己的 std::unique_lock 对象“移动”给其他线程,本质是告诉锁:“我不再持有你了,由新的管理类对应的线程来持有”。
二、移动语义移交锁控制权的具体实现逻辑
以最典型的 std::unique_lock 为例,其移动语义的实现逻辑可拆解为 3 步,核心是**“主动释放-安全交接”**,而非“强行修改 owner”:
1. 前提:只有“当前持有锁的线程”能发起移交
移动操作(移动构造/移动赋值)必须在持有锁的线程内部执行——因为只有这个线程能合法操作 std::unique_lock 对象(该对象本身不具备线程安全性,开发者需保证它在单线程内被操作)。
比如:
#include <mutex>
#include <thread>
std::mutex mtx; // 不可移动的锁实体
void thread1(std::unique_lock<std::mutex>&& lock) {
// thread1 先通过 lock 持有 mtx
std::unique_lock<std::mutex> my_lock = std::move(lock); // 移动构造:移交控制权
// 此时 my_lock 持有 mtx,原 lock 变为“未持有状态”(内部标记为 false)
}
int main() {
// 主线程先获取锁
std::unique_lock<std::mutex> main_lock(mtx);
// 主线程主动将锁的管理权限通过移动语义传递给 thread1
std::thread t(thread1, std::move(main_lock));
t.join();
return 0;
}
2. 移动过程:仅转移“管理状态”,不修改锁实体的核心逻辑
std::unique_lock 的移动构造/移动赋值函数,内部做的事情非常明确,且不会让外部线程直接修改 std::mutex 的 owner 字段:
- 源对象(如
main_lock):将其内部的「锁关联指针」(指向mtx)和「持有状态标记」(owns_lock()的返回值)转移给目标对象(如my_lock); - 源对象自身:清空「锁关联指针」(改为
nullptr),并将「持有状态标记」设为false(表示它不再持有锁); - 目标对象(如
my_lock):接收「锁关联指针」和「持有状态标记」,此时它成为mtx的合法持有者。
整个过程中,std::mutex 实体的 owner 字段(如果内部实现有这个字段)的更新,是由 std::unique_lock 的移动逻辑间接触发的——但这个更新是“合法的”:因为源线程已经主动放弃了所有权,锁的内部逻辑会确认“源线程确实持有锁”后,才将 owner 更新为目标线程,而非目标线程强行修改。
3. 核心约束:确保“同一时间只有一个持有者”
移动语义能安全移交的关键,是 std::unique_lock 的设计强制了「独占所有权」:
- 一个
std::unique_lock对象要么“持有锁”,要么“不持有”(非此即彼); - 移动后,源对象必然“不持有”,目标对象“持有”——不会出现两个对象同时认为自己持有锁的情况;
std::mutex本身的互斥逻辑(如lock()/unlock())会配合管理类,确保只有“持有管理类”的线程能调用unlock()(否则会触发未定义行为)。
三、与“直接修改 owner”的本质区别
| 对比维度 | 直接修改 owner 字段(非法) |
C++ 移动语义移交(合法) |
|---|---|---|
| 发起者 | 其他线程(非锁持有者) | 当前锁持有者(唯一合法发起者) |
| 操作逻辑 | 强行覆盖 owner,无视锁的内部状态 |
主动转移管理权限,由锁的封装逻辑确认合法性 |
| 安全性 | 破坏互斥性(可能多个线程同时持有锁) | 确保独占性(同一时间只有一个合法持有者) |
| 依赖基础 | 绕过锁的设计规则,依赖“内存直接修改” | 基于锁管理类的封装,遵循锁的内部协议 |
总结
C++ 中通过移动语义移交锁控制权,本质是**“锁持有者主动将管理权限转移给其他线程”**,而非“外部线程强行修改 owner”:
- 移动的是「锁管理类」(如
std::unique_lock),而非「锁实体」(如std::mutex); - 整个过程由持有锁的线程发起,源管理类主动放弃权限,目标管理类合法接收;
- 锁实体(
std::mutex)的owner字段(若有)由内部逻辑安全更新,确保互斥性不被破坏。
这种设计既满足了“控制权移交”的需求,又严格遵守了锁的核心原则——互斥性和安全性。
值得注意的是,主动放弃锁的权限(包括常规释放、定向移交控制权),其底层核心操作必然依赖“合法的解锁逻辑”,但具体实现会根据“放弃权限的方式”(常规释放 vs 定向移交)略有差异,并非简单的“解锁后让所有线程竞争”,而是会结合锁的设计语义(如C++移动语义、内核锁的定向交接)确保控制权安全转移。
要理解这一点,需要先明确两个关键前提:
- 任何锁的所有权变更(包括“放弃”和“移交”),都必须遵循锁的原子性和安全性设计——不能直接修改
owner字段,必须通过锁本身提供的“合法接口”完成(否则会破坏锁的互斥性,导致数据竞争)。 - “主动放弃权限”本质是“释放对锁的所有权”,而“解锁操作”的核心功能就是“将锁的所有权从当前持有者释放”,因此所有合法的权限放弃都以解锁逻辑为基础,只是释放后锁的“去向”不同(是回到“空闲状态供竞争”,还是“定向交给特定线程”)。
接下来结合你之前关注的C++移动语义和锁移交场景,具体拆解:
1. 常规场景:主动放弃权限 = 直接解锁(锁回到空闲状态)
如果只是“单纯放弃锁权限”(不指定移交对象),比如线程执行完临界区后释放锁,此时的“放弃”就是标准的解锁操作:
- 底层会通过原子操作修改锁的状态(如将
owner设为nullptr、清除“锁定标志位”),并唤醒等待队列中的线程(或允许其他线程竞争)。 - 例如C++的
std::mutex::unlock()、std::unique_lock::unlock(),本质都是“主动放弃当前线程的锁所有权”,让锁回到可被其他线程获取的状态。
2. 特殊场景:定向移交权限(如C++移动语义)= 解锁逻辑 + 所有权转移标记
我们之前关注的“C++通过移动语义移交锁控制权”,本质是“有条件的主动放弃”——原线程放弃权限,但不是将锁释放到“公共竞争池”,而是定向交给另一个线程(通过移动锁对象的“所有权状态”实现)。其核心依然依赖解锁逻辑,但多了一层“状态同步”:
以std::unique_lock(可移动的锁包装器)为例,移动语义的移交过程是这样的:
- 原锁对象(移动源)的操作:移动时,原
unique_lock会主动“放弃对锁的控制权”——这一步并非直接调用unlock()(因为锁本身可能还在“锁定状态”,只是所有权要转移),而是通过修改自身的“持有状态标记”(比如将内部的“是否持有锁”标志设为false),表示“我不再拥有这个锁的所有权,后续不会对锁执行解锁”。
(如果原unique_lock持有锁,移动后它的析构函数也不会解锁——因为所有权已移交,避免重复解锁)。 - 目标锁对象(移动目标)的操作:移动后,目标
unique_lock会继承原对象的“持有状态”(比如将“是否持有锁”标志设为true),表示“我现在拥有这个锁的所有权,后续需要由我执行解锁”。 - 底层锁的状态:整个移动过程中,底层的
std::mutex本身始终处于“锁定状态”(没有被释放到空闲),只是“谁有权解锁它”的所有权从原线程转移到了目标线程。而最终目标线程要“真正放弃权限”时,依然需要调用unlock()(或依赖unique_lock析构时自动解锁)——这才是底层锁的“解锁操作”。
3. 内核级锁的定向移交(如Linux的mutex交接)= 解锁 + 定向唤醒
类似内核中的“锁交接机制”(如你之前提到的“Wound-Wait”或“优先级继承”场景),线程主动放弃权限时,也是“解锁操作 + 定向同步”的组合:
- 持有锁的线程先执行解锁逻辑(原子修改
owner为“待移交”状态,而非直接设为空闲); - 同时通过等待队列的管理,定向唤醒指定的目标线程(而非唤醒所有等待线程),并将锁的
owner直接设为目标线程; - 整个过程中,锁不会进入“公共竞争状态”,而是从原持有者“无缝移交”给目标线程——但“放弃权限”的起点,依然是原线程的解锁操作(释放对
owner的独占权)。
总结
“主动放弃锁权限”必然以“解锁操作”为核心基础,但具体表现形式会根据场景不同而变化:
- 常规释放:解锁后锁回到“空闲状态”,允许所有线程竞争;
- 定向移交(如C++移动语义、内核锁交接):解锁逻辑 + 额外的“所有权标记/定向唤醒”,确保锁从原线程精准转移到目标线程,避免公共竞争。
核心原则是:任何权限放弃都必须通过锁的合法接口完成,不能直接修改owner;解锁操作是“释放所有权”的唯一合法途径,只是锁的“去向”由具体场景的同步逻辑决定。