文章目录
多线程(进阶)
常见的锁策略
- 锁,不仅仅是synchronized这种锁,还有其他种类的锁
- 锁策略:锁的一种特性,指的是一类锁,不是一种具体的锁
乐观锁和悲观锁
- 乐观锁和悲观锁:是对后续锁冲突是否激烈给出的预测
- 乐观锁:如果预测接下来锁冲突的概率不大,就可以少做一些工作
- 悲观锁:如果预测接下来锁冲突的概率很大,就要多做一些工作
重量级锁和轻量级锁

自旋锁和挂起等待锁
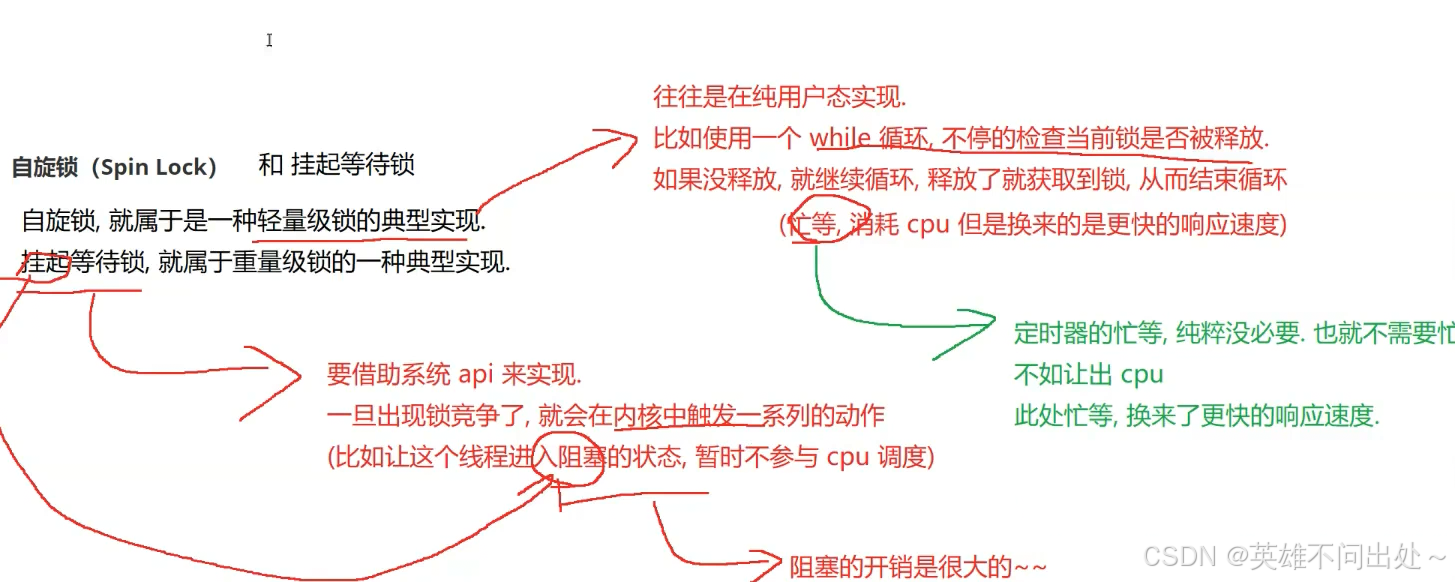
乐观锁通常是轻量级锁
悲观锁通常是重量级锁
这并不是绝对的,也有特殊情况的
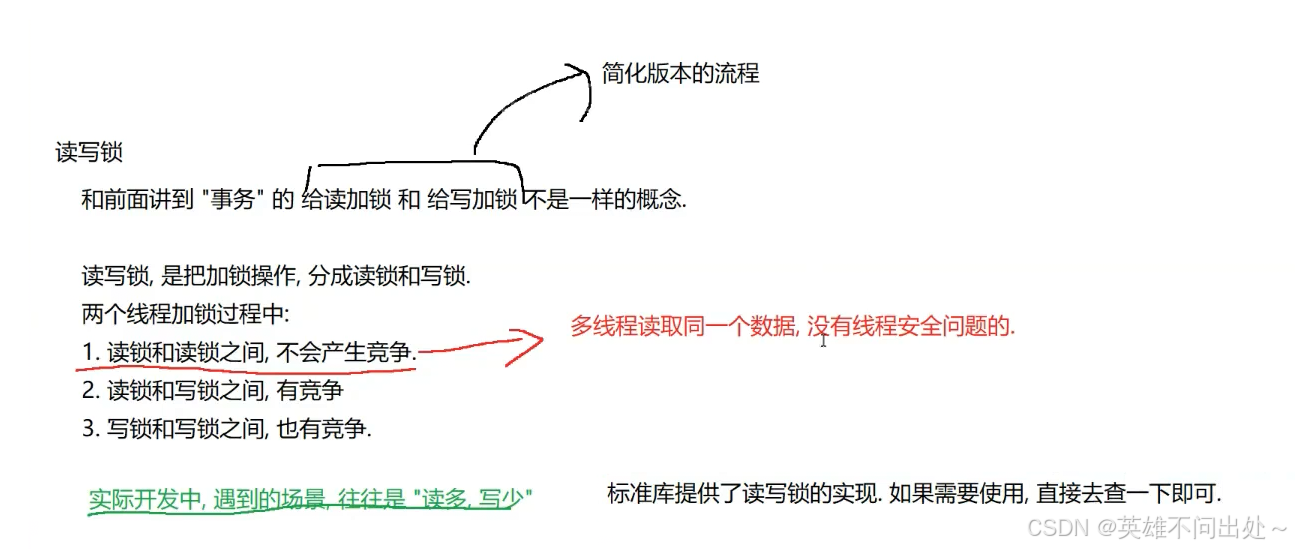
读写锁
- 数据库中也出现了读加锁和写加锁
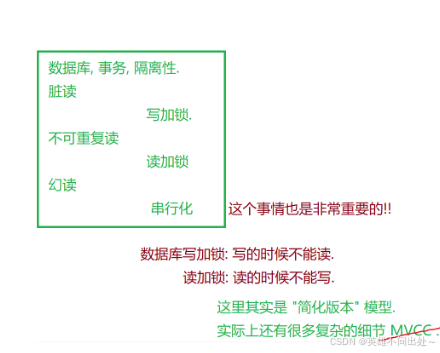
2. 读加锁:读的时候,能读,但是不能写
写加锁:写的时候,不能读,也不能写
可重入锁和不可重入锁
- 如果一个线程对同一把锁,连续进行加锁两次,不出现死锁就是可重入锁,出现死锁就是不可重入锁
公平锁和非公平锁


CAS
- Compare and swap:比较和交换
比较和交换的是寄存器和内存中的值
例子:
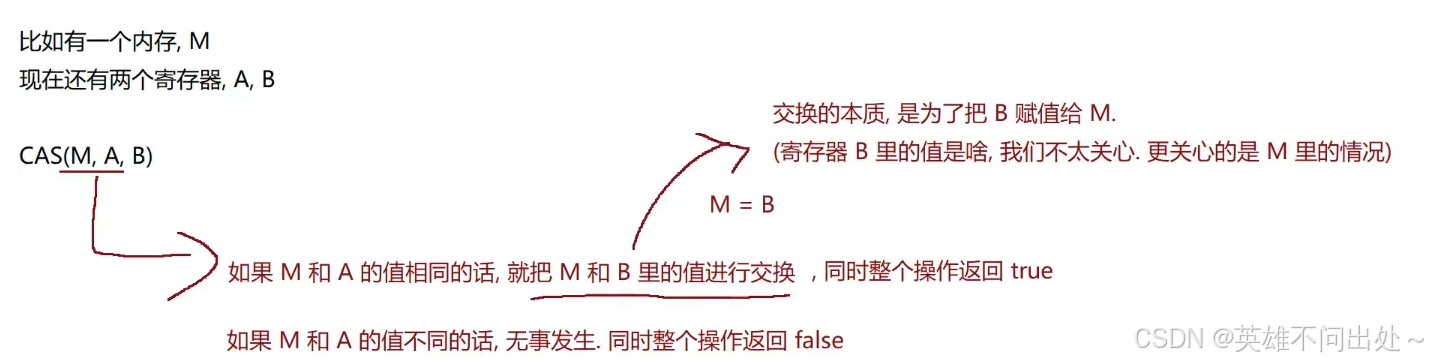
CAS的伪代码(逻辑):

- CAS其实是一个cpu指令(一个cpu指令就可以完成上述的比较和交换的逻辑),单个cpu指令是原子的,一定程度上就可以代替加锁,为线程安全问题引入了新思路
- 基于CAS实现线程安全的方式也称为无锁编程
优点:保证了线程安全,同时避免了阻塞(效率提高了)
缺点:代码会更复杂,不好理解.
只能够适合一些特定的场景,没有锁的普适性

CAS实现的原子性
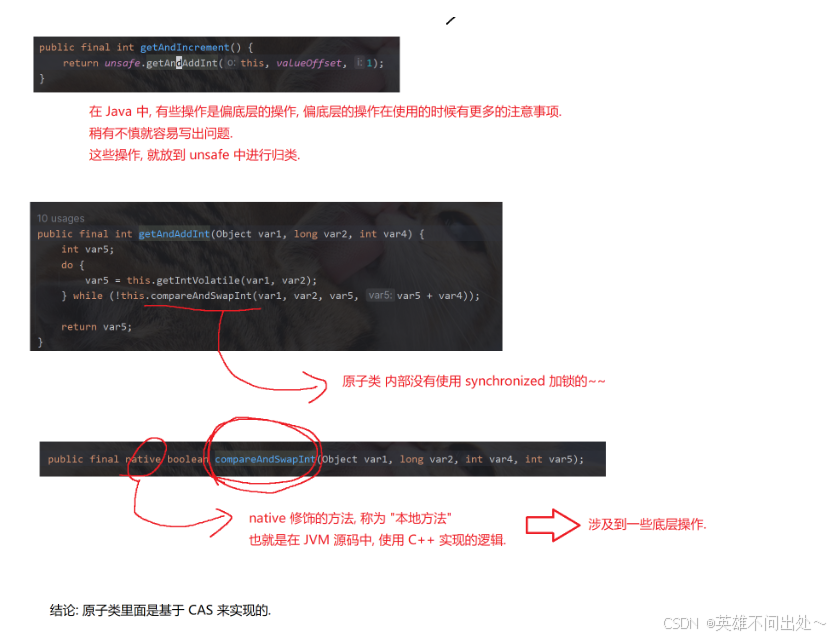

举个自增操作的例子:

自增产生线程不安全的原因是穿插执行了
加锁是通过阻塞的方式阻止了穿插执行,而CAS是通过重试的方式阻止了穿插执行
CAP这里循环判定,如果值是有变化了,就是存在其他线程在这里穿插执行了,所以这里更新了一下值
CAS实现自旋锁
- 纯用户态实现的自旋锁,适合比较乐观的场景


ABA问题

- ABA问题可能会产生bug

- ABA问题通常情况下不会有bug,但是极端情况下就不好说了
例子:
这个时候是执行正确的,

但是此时来了一个t3线程,我实际上要取500,但是这里扣了1000

- 如何解决ABA问题呢?

- 小结:面试中容易考到

synchronized的原理
- synchronized背后的一些问题(面试中常见的问题)

- 锁的变化:
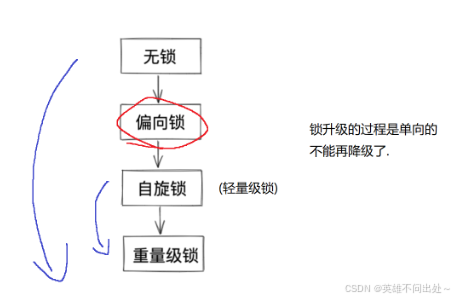
锁升级
偏向锁的例子:
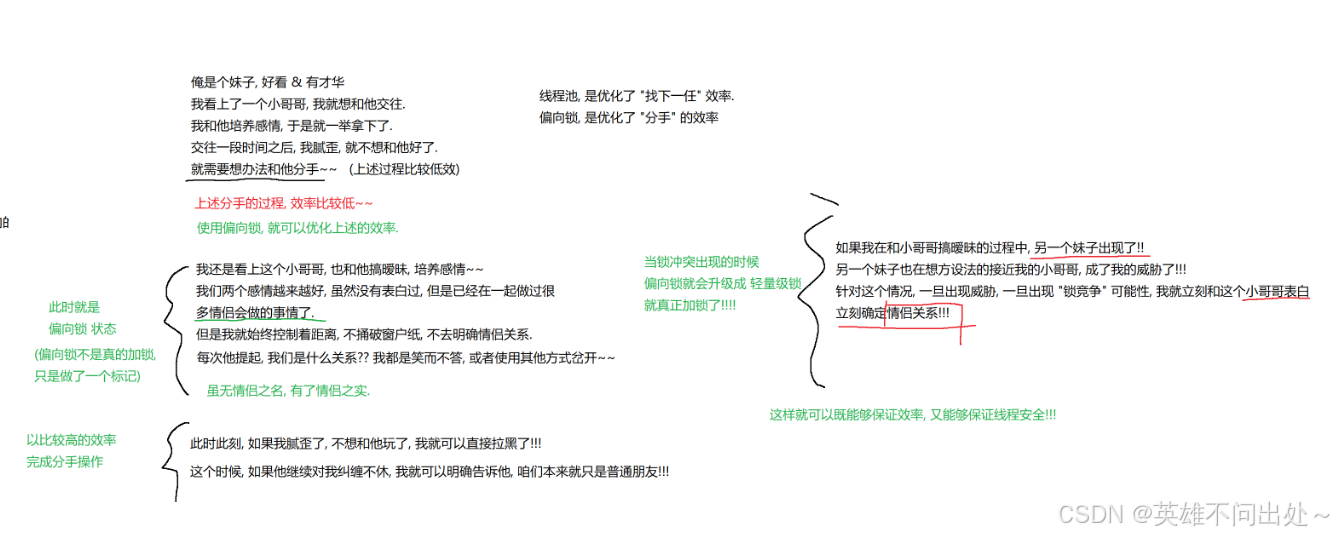
偏向锁的核心思想,就是’’ 懒汉模式 ‘’ 的另一种体现,能不加锁就不加锁,加锁就意味着有开销
偏向锁,如果没有人竞争这个锁,synchronized就标记一下,不加锁,就加上一个标记,这时如果要解锁也会更加高效,后续如果有锁竞争了就立马加上锁,也保证了线程安全问题
如果出现一次锁冲突就升级为自旋锁,如果遇到更多的冲突就再次升级为重量级锁
- 为什么要有锁升级呢?
为了让性能和线程安全之间更好地权衡
锁消除
- 锁消除也是一种编译器的优化手段(在编译过程中的消除锁)
- 编译器会自动对你写的加锁代码做出判定,如果编译器觉得你这个场景不需要加锁,就会把你写的synchronized给优化掉

锁粗化
- 锁的粒度细,需要每次都加锁和解锁
- 锁的粒度粗,只需要一次加锁和解锁

JUC(java.util.concurrent)中常见的类
Callable接口
- Callable接口:可以返回结果,对比Runnable来说,Runnable并不返回结果
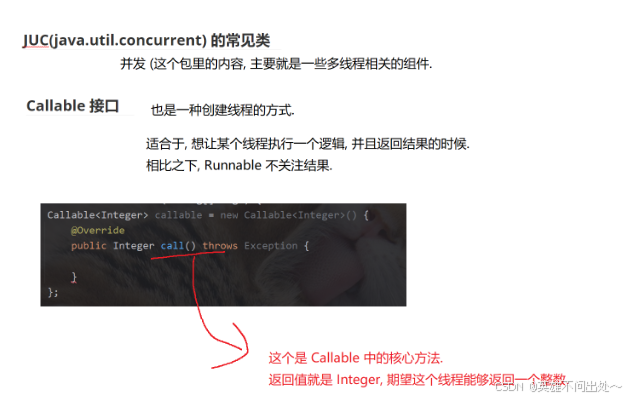
- Callable的实现方法
让Callable计算结果更加方便
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Demo30 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 定义一个任务
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for(int i = 0;i <= 1000;i++){
sum += i;
}
return sum;
}
};
// 把任务放到线程中执行
FutureTask<Integer> futureTask = new FutureTask<>(callable);
// 无法直接把callable放入Thread的构造方法中
Thread t = new Thread(futureTask);
t.start();
// 这里的get能够获取到call中的返回结果
// 因为是并发执行,执行到线程中的get方法时,t线程还没有执行完
// get就会阻塞等待
System.out.println(futureTask.get());
}
}

3. 创建线程的方法:

ReentrantLock
- ReentrantLock:也是可重入锁,使用效果上和synchronized效果是相似的
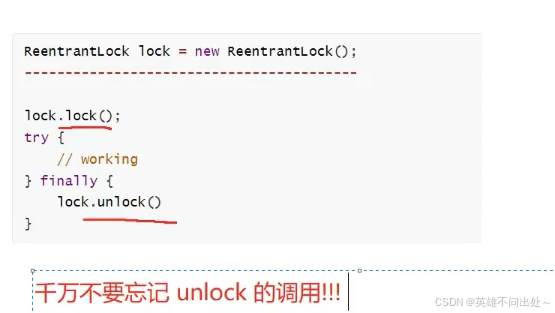
- 优势:
ReentranLock有两种加锁的方式:lock和tryLock
lock是加锁失败就一直阻塞等待
tryLock是加锁失败,就放弃加锁
tryLock就有更多的操作空间了
ReentranLock提供了公平锁的实现(默认情况下是非公平锁)

3. 我们应该首选synchronized,因为ReentrantLock使用起来更复杂,尤其是容易忘记unlock,另外synchronized有一系列的优化手段
信号量Semaphore
- 信号量就是一个计数器,描述了可用资源的个数
每次申请一个可用资源,计数器都-1(P操作)
每次释放一个可用资源,计数器都+1(V操作)
(这里的+1和-1都是原子的)
例子:有多少个车位,这里的车位就是一种信号量

2. 锁就是二元信号量

这样信号量就可以表示锁
而锁不能代替信号量
锁是特殊的信号量
- 信号量的使用
如果遇到需要申请资源的场景可以使用信号量
import java.util.concurrent.Semaphore;
public class Demo32 {
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(4);
semaphore.acquire();
System.out.println("P 操作!");
semaphore.acquire();
System.out.println("P 操作!");
semaphore.acquire();
System.out.println("P 操作!");
semaphore.acquire();
System.out.println("P 操作!");
// 最后一个阻塞等待
semaphore.acquire();
System.out.println("P 操作!");
semaphore.release();
}
}
CountDownLatch
- 用来判断当前任务是否都完成了

- CountDownLatch的两个方法:

- CountDownLatch的使用:把大的任务拆分成多个小任务
import java.util.concurrent.CountDownLatch;
public class Demo33 {
public static void main(String[] args) throws InterruptedException {
// 10个选手参赛,await就会在10次调用完countDown之后才能继续执行
CountDownLatch count = new CountDownLatch(10);
for(int i = 0;i < 9;i++){
int id = i;
Thread t = new Thread(()->{
System.out.println("Thread " + id);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 表示当前这个任务已经执行完毕了
count.countDown();
});
t.start();
}
// 等待所有任务执行完毕,才能往下执行
// a -> all
count.await();
System.out.println("所有任务都完成了!");
}
}
线程安全的集合类
多线程使用ArrayList
- synchronizedList:相当于是在ArrayList外面套了一个synchronized
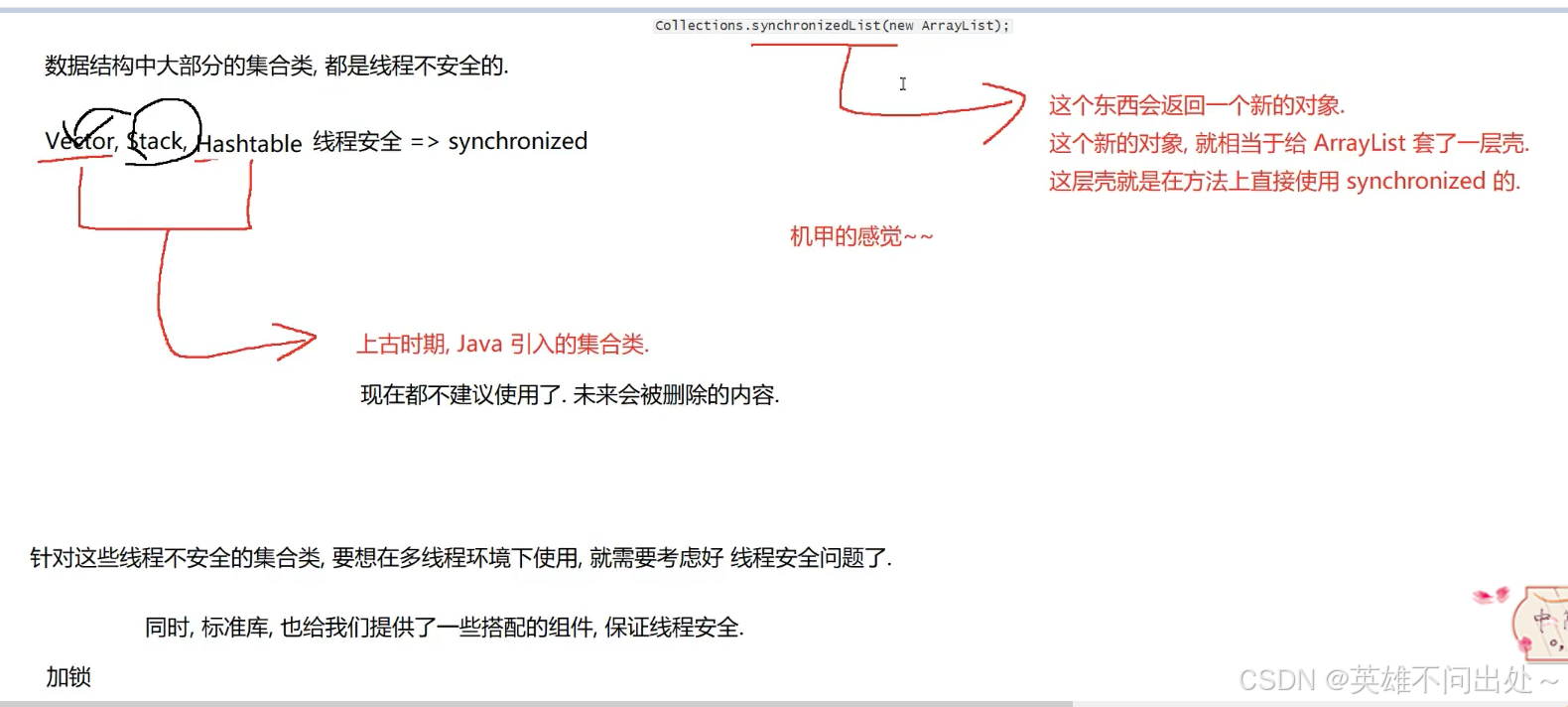
2.CopyOnWriteArrayList:写时拷贝
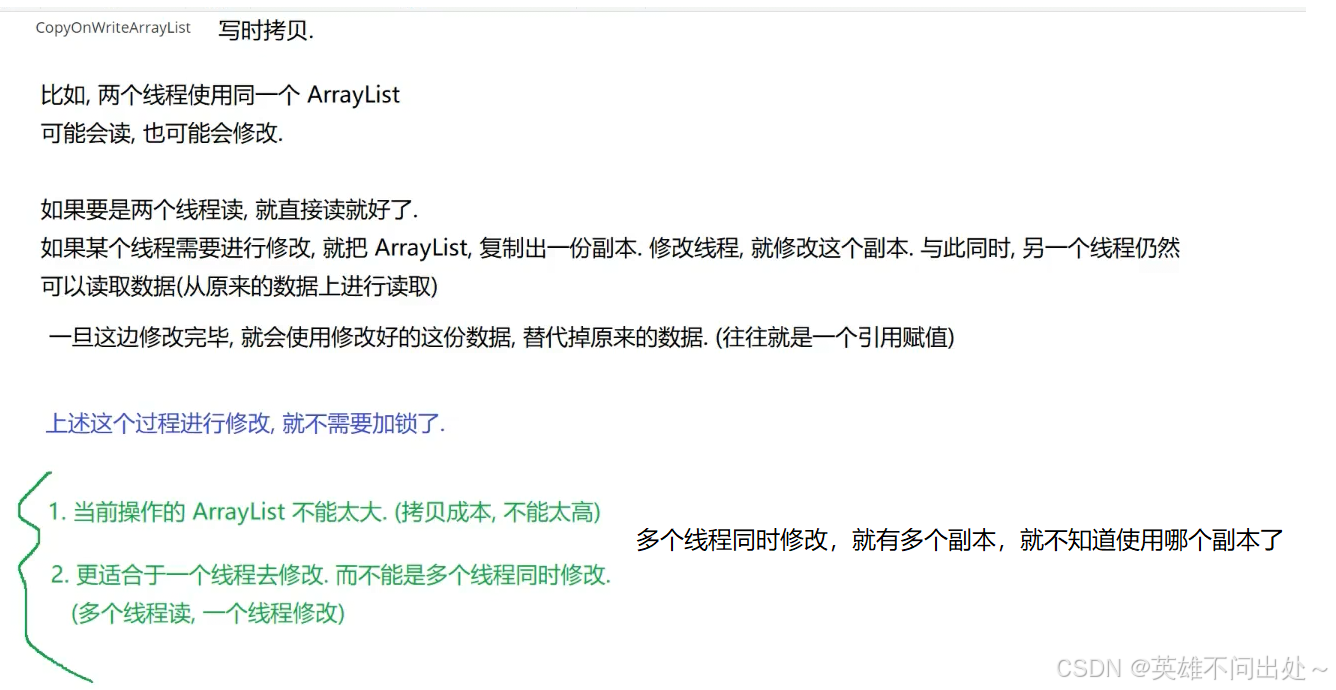
写时拷贝的使用场景:

3. 多线程使用队列

4. 多线程使用哈希表

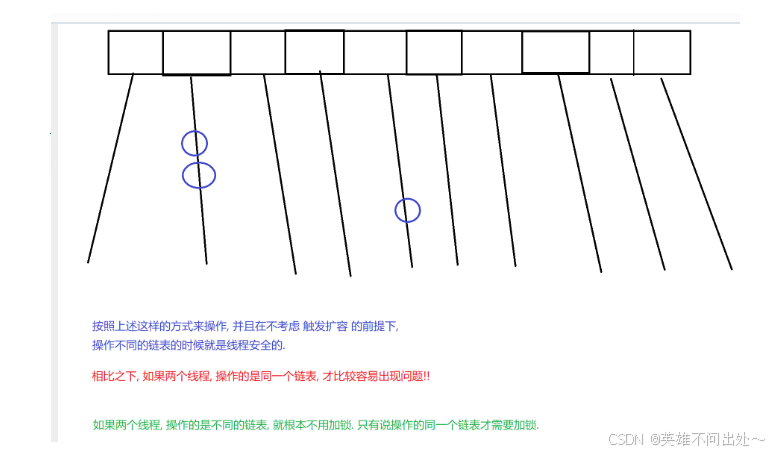
ConcurrentHashMap的改进的方面:
1.ConcurrentHashMap最核心的改进(在HashMap的基础上进行的改进)就是把全局的一把大锁,该进成了每一个链表是一把独立小锁,这样大大地降低了锁冲突的概率
一个哈希表中有很多这样的链表,两个线程刚好同时访问一个链表的概率就比较小

对第3点的补充:
写和写之间是要进行加锁的
针对第一点,每个链表都是一把小锁,需要我们把每个链表的头节点作为一个锁对象,因为synchronized可以把任何对象作为锁对象

- ConcurrentHashMap针对扩容操作做出了单独的优化
缺点:

解决方法:一旦要扩容,确实是要搬运的,不是一次操作中搬运全部,而是分成多次来搬运。每次只搬运一部分数据,避免了这单次操作太卡顿
ConcurrentHashMap和HashMap基本使用上是完全一样的,只不过对于加锁的方式改变了,还有一些对HashMap的优化